Zadania laboratoryjne należy wykonać w programie Cisco Packet Tracer. Każde sprawozdanie musi zawierać: treść zadania, opis wykonania wraz z uzasadnieniem wyboru technologii, zrzuty ekranu z topologii i konfiguracji, szczegółowy opis konfiguracji urządzeń (CLI), zestawienie napotkanych problemów oraz merytoryczne wnioski końcowe.
Spis zagadnień laboratoryjnych
- Synchronizacja czasu w infrastrukturze rozproszonej (NTP)
- Dynamiczna adresacja i DHCP Relay w sieciach segmentowanych
- Zarządzanie przestrzenią nazw i rekordami DNS
- Utrzymanie dostępności usług WWW przez klastrowanie i redundancję
- Polityki dostępu i utwardzanie usług (Firewall/ACL)
- Administracja serwerami pocztowymi (SMTP/POP3)
- Archiwizacja danych i utrzymanie konfiguracji (FTP/TFTP)
- Bezpieczny dostęp zdalny do infrastruktury (SSH)
- Monitoring stanu usług i urządzeń (SNMP/Syslog)
- Zapewnienie ciągłości pracy bramy domyślnej (HSRP)
- Utrzymanie bezpiecznych sieci bezprzewodowych (WPA2-Enterprise)
- Konfiguracja i utrzymanie usług VoIP
- Integracja i monitoring systemów IoT
- Bezpieczne tunele komunikacyjne (GRE/VPN)
- Priorytetyzacja ruchu i utrzymanie jakości usług (QoS)
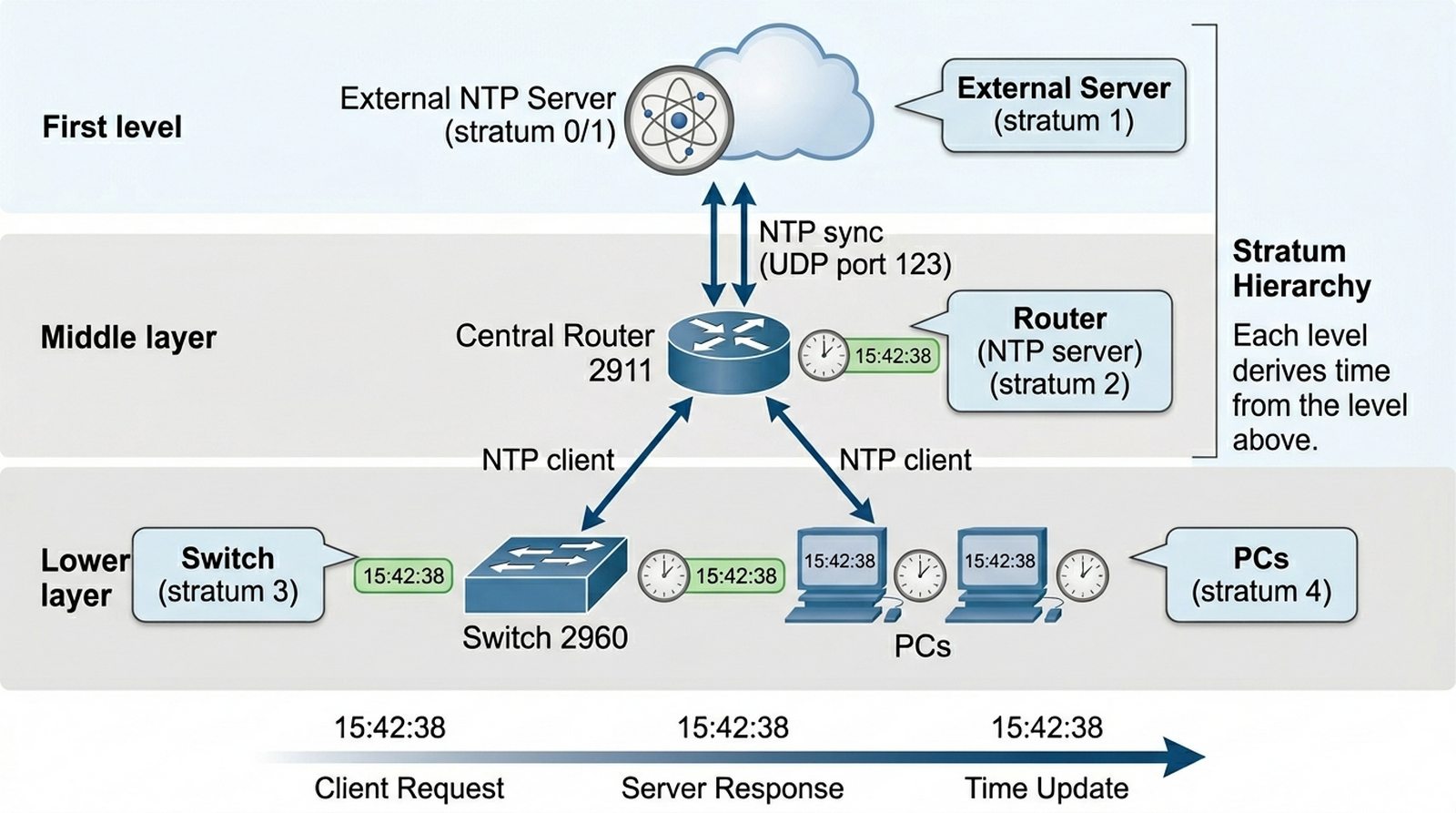
Wykład 2 Rola NTP w logowaniu zdarzeń, synchronizacja Kerberos, hierarchia stratum.
W firmowej sieci rozproszonej zauważono rozbieżności w logach systemowych, co uniemożliwia poprawną analizę incydentów bezpieczeństwa. Serwer Centralny (Router) posiada precyzyjny czas, ale urządzenia brzegowe oraz stacje robocze wykazują kilkuminutowe przesunięcia. Twoim zadaniem jest zbudowanie hierarchicznej struktury synchronizacji czasu, w której Router pełni rolę serwera NTP Stratum 1 (synchronizowanego zewnętrznie), a pozostałe urządzenia pełnią rolę klientów. Musisz zapewnić, aby każde zdarzenie w sieci było opatrzone identycznym stemplem czasowym.
- Użycie routera 2911 jako centralnego serwera NTP.
- Dodanie serwera zewnętrznego (Server-PT) symulującego zegar wzorcowy.
- Konfiguracja routera jako klienta serwera zewnętrznego.
- Uruchomienie usługi NTP server na routerze dla sieci wewnętrznej.
- Konfiguracja przełącznika (Switch 2960) jako klienta NTP routera.
- Konfiguracja dwóch komputerów (PC) do synchronizacji czasu z routerem.
- Ustawienie właściwej strefy czasowej (timezone) na wszystkich urządzeniach.
- Weryfikacja statusu synchronizacji poleceniem "show ntp status".
- Sprawdzenie listy serwerów uprawnionych poleceniem "show ntp associations".
- Wymuszenie aktualizacji czasu i obserwacja zmian w logach z bufora.
- Zabezpieczenie serwera NTP za pomocą prostego uwierzytelniania (jeśli wspierane).
- Udokumentowanie numeru stratum na różnych poziomach hierarchii.
Router(config)# clock timezone CET 1
Router# show ntp associations
Router# show ntp status
- Przed rozpoczęciem konfiguracji NTP sprawdź, czy zegar systemowy routera jest ustawiony na właściwą datę i godzinę. Nawet jeśli czas jest nieprecyzyjny, NTP go skoryguje, ale data musi być realistyczna (np. rok 2026).
- Serwer NTP w Packet Tracer wymaga aktywacji usługi na serwerze zewnętrznym (zakładka Services → NTP). Ustaw go jako stratum 0 lub 1, symulując wzorcowe źródło czasu.
- Na routerze centralnym skonfiguruj najpierw strefę czasową poleceniem
clock timezone CET 1, a dopiero potem włącz klienta NTP. Kolejność ma znaczenie dla poprawnej konwersji czasu letniego/zimowego. - Polecenie
ntp server [adres]dodaje serwer jako źródło synchronizacji. Możesz dodać wiele serwerów dla redundancji, ale aktywny będzie tylko jeden z najniższym stratum. - Po skonfigurowaniu routera jako serwera NTP użyj polecenia
ntp master [numer_stratum], aby router rozpowszechniał czas w sieci lokalnej. - Sprawdź status synchronizacji poleceniem
show ntp status— dopóki nie zobaczysz komunikatu "Clock is synchronized", stratum może wynosić 16 (oznacza brak synchronizacji). - Na przełączniku 2960 NTP działa w trybie klienta. Użyj polecenia
ntp server [adres_routera]w trybie konfiguracji globalnej. - Komputery PC w Packet Tracer synchronizują czas automatycznie, jeśli w ich konfiguracji IP wskażesz router jako bramę i serwer NTP. Możesz też ręcznie wymusić synchronizację, czekając kilka minut.
- Polecenie
show ntp associations detailpokazuje szczegóły każdego skojarzenia NTP, w tym opóźnienie (offset) i jitter. Interpretacja tych wartości jest przydatna przy diagnostyce problemów. - W widoku symulacji (Simulation Panel) możesz zaobserwować pakiety NTP — mają charakterystyczny format i przesyłane są co określony interwał (zazwyczaj co 64 sekundy w Packet Tracer).
- Jeśli synchronizacja nie następuje, sprawdź łączność ICMP między urządzeniami. NTP wymaga działającej warstwy 3. Upewnij się też, że firewall nie blokuje portu 123/UDP.
- W sprawozdaniu udokumentuj hierarchię stratum — np. serwer zewnętrzny (stratum 1), router (stratum 2), switch (stratum 3), PC (stratum 4). To pokazuje rozproszenie synchronizacji.
- Status: WYKONALNE W 100% — Funkcjonalność NTP jest w pełni wspierana w Cisco Packet Tracer od wersji 7.2.
- Polecenia
ntp server,ntp master,show ntp associations,show ntp statusdziałają poprawnie. - Możliwe jest łańcuchowanie urządzeń NTP (router jako klient i jednocześnie serwer dla innych urządzeń).
- Ograniczenia: brak uwierzytelniania NTP (NTP authentication), uproszczony tryb pracy zegara.
- Serwer NTP w PT (Server-PT) działa poprawnie po aktywacji usługi w zakładce Services → NTP.
- ZALECENIE Użyj IOS 15.x na routerach dla pełnej kompatybilności NTP.
Poniżej przedstawiono realistyczne wyniki poleceń CLI wzorowane na rzeczywistym środowisku Cisco IOS. Kolorystyka: żółty — polecenia użytkownika, zielony — wyniki, biały — prompt.
Enter configuration commands, one per line. End with CNTL/Z.
Router(config)# clock timezone CET 1
Router(config)# ntp server 10.0.0.5
*NTP: stratum change sent to 10.0.0.5, stratum 2
Router(config)# ntp master 2
*NTP: master mode enabled, stratum 2
Router(config)# exit
Router# show ntp associations
address ref clock st when poll reach delay offset disp
~10.0.0.5 127.127.7.1 1 56 64 377 1.2 +1.45 1.3
* sys.peer, # selected, + candidate, - pps, o peer
Router# show ntp status
Clock is synchronized, stratum 2, reference is 10.0.0.5
nominal freq is 250.0000 Hz, actual freq is 249.9998 Hz
precision is 2**18, reference time is DEADBEEF
clock offset is 1.2345 ms, root delay is 2.345 ms
root dispersion is 3.456 ms, peer dispersion is 1.234 ms
loopfilter state is UP, drift is 0.0001234 sec/second
Switch# ntp server 192.168.1.1
%NTP: sync request sent to 192.168.1.1
Switch# show ntp associations
address ref clock st when poll reach delay offset disp
~192.168.1.1 10.0.0.5 2 - 64 377 0.8 +1.23 0.9
PC# show clock
15:42:38.123 CET Mon Apr 27 2026
Router# debug ntp packet
NTP packets debugging is enabled
*NTP: Sent NTP packet to 10.0.0.5, offset 0.234 ms
*NTP: Received NTP packet from 10.0.0.5, stratum 1
Router# undebug all
All debugging disabled
Precyzyjna synchronizacja czasu stanowi fundament usług katalogowych, takich jak Active Directory, gdzie protokół Kerberos wymaga zgodności czasowej z tolerancją do 5 minut między klientem a serwerem. W praktyce Cisco, gdy różnica czasu przekracza dopuszczalny próg, bilety TGT są natychmiast odrzucane, co skutkuje blokadą uwierzytelniania użytkowników i niemożnością logowania do zasobów sieciowych. Z perspektywy audytu bezpieczeństwa, heterogeniczne logi bez spójnego timestampu uniemożliwiają korelację zdarzeń i rekonstrukcję chronologii incydentów, co jest kluczowe w dochodzeniu cyberniezgodności oraz w spełnianiu wymogów compliance (np. RODO, ISO 27001). NTP w hierarchii stratum zapewnia skalowalność — serwer zewnętrzny jako stratum 1 propaguje czas do kolejnych warstw, co eliminuje ryzyko złożonych dryftów czasowych w rozległych infrastrukturach korporacyjnych.
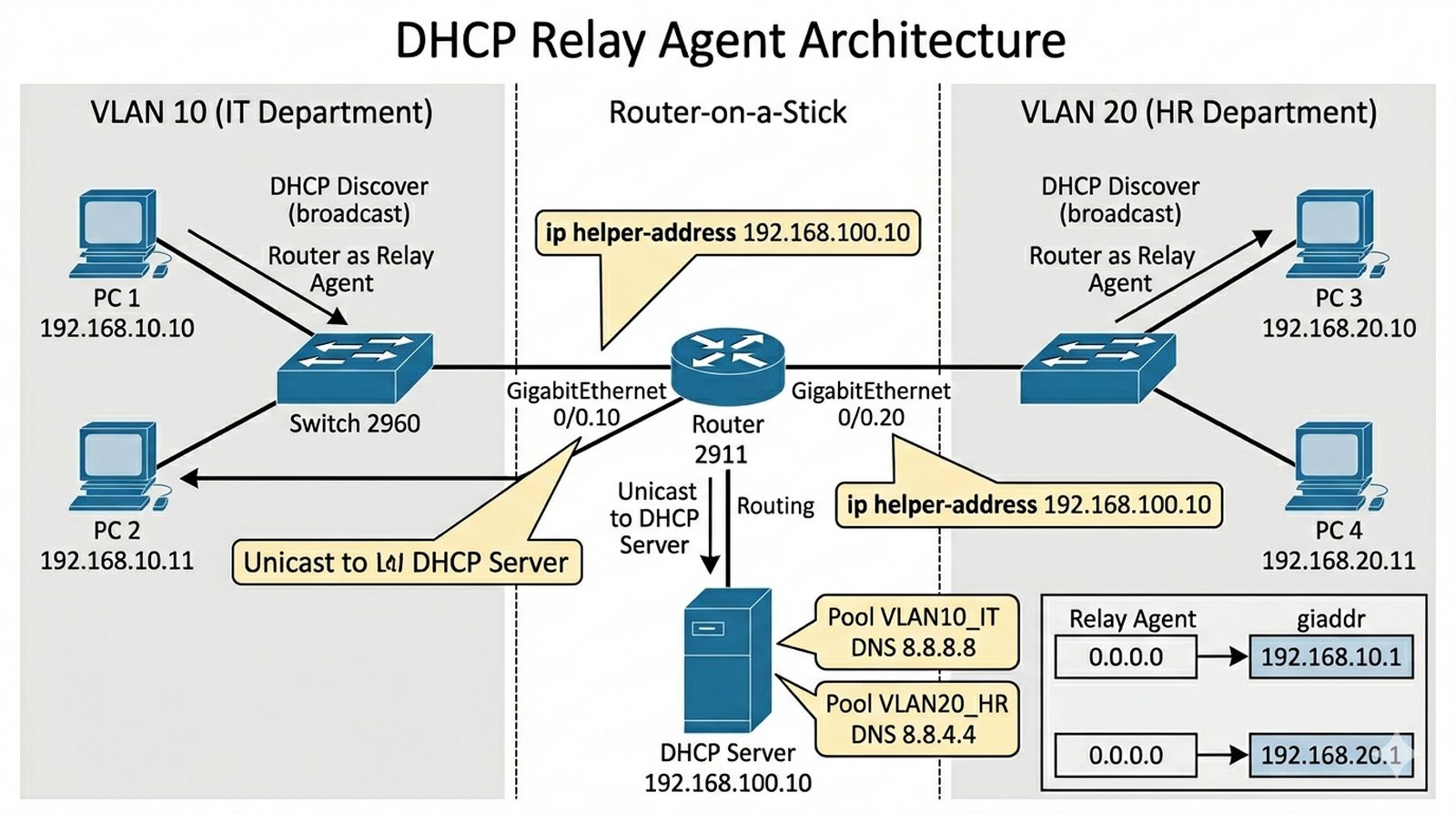
Wykład 2 Proces DORA, DHCP Relay Agent, bezpieczeństwo (Snooping).
Firma posiada dwa działy: IT (VLAN 10) oraz HR (VLAN 20). Centralny serwer DHCP znajduje się w podsieci serwerowej, która jest odseparowana od sieci użytkowników przez router. Ponieważ rozgłoszenia DHCP (broadcast) nie przechodzą przez router, musisz skonfigurować mechanizm przekazywania żądań (Relay), aby pracownicy obu działów mogli automatycznie uzyskać adresację IP z właściwych puli. Dodatkowo musisz zapewnić, że urządzenia w VLAN 10 otrzymają inne parametry (np. inny serwer DNS) niż urządzenia w VLAN 20.
- Konfiguracja subinterfejsów dot1Q na routerze brzegowym (Router-on-a-Stick).
- Stworzenie dwóch pul DHCP na dedykowanym serwerze (Server-PT).
- Konfiguracja "ip helper-address" na interfejsach bram domyślnych VLANów.
- Weryfikacja procesu DORA w trybie symulacji (analiza pakietów).
- Przydzielenie statycznej rezerwacji dla drukarki sieciowej po adresie MAC.
- Ustawienie czasu dzierżawy (lease time) na 24 godziny.
- Weryfikacja tablicy dzierżaw na serwerze DHCP.
- Testowanie poprawności konfiguracji bramy domyślnej i DNS na stacjach klienckich.
- Wykluczenie zakresu adresów statycznych (exclusion list) z puli dynamicznej.
- Weryfikacja dostępności serwera DHCP przez ping z różnych VLANów.
- Dokumentacja struktury pakietu po przejściu przez Relay Agent (zmiana adresu źródłowego).
Router(config-subif)# encapsulation dot1Q 10
Router(config-subif)# ip helper-address 192.168.100.10
Router# show ip dhcp binding
- Router-on-a-Stick wymaga konfiguracji subinterfejsów na jednym fizycznym interfejsie. Najpierw włącz interfejs poleceniem
no shutdown, a dopiero potem twórz subinterfejsy. - Każdy subinterfejs musi mieć przypisaną właściwą sieć VLAN poleceniem
encapsulation dot1Q [numer_vlan]. Numer VLAN w enkapsulacji musi odpowiadać VLAN-owi na switchu. - Na serwerze DHCP utwórz osobne pule dla każdego VLAN-u zgodnie z wymaganiami zadania. W puli dla VLAN 10 ustaw opcję routera na adres routera w tym VLAN, a w puli VLAN 20 na inny adres.
- Adresacja DHCP dla każdego VLAN-u powinna być w osobnej podsieci. Przykładowo: VLAN 10 → 192.168.10.0/24, VLAN 20 → 192.168.20.0/24, serwer DHCP → 192.168.100.0/24.
- Polecenie
ip helper-address [adres_serwera_DHCP]na subinterfejsie routera powoduje, że router przekazuje broadcasty DHCP do serwera DHCP. Adres ten musi być osiągalny (warstwa 3). - Relay Agent zmienia źródłowy adres IP pakietu na adres interfejsu, na którym odebrał żądanie. Dzięki temu serwer DHCP wie, z której sieci pochodzi żądanie.
- Rezerwacja statyczna po adresie MAC wykonaj w ustawieniach serwera DHCP (zakładka Services → DHCP → Reservations). Pamiętaj, aby wykluczyć ten adres z puli dynamicznej.
- Czas dzierżawy ustaw na 24 godziny (86400 sekund), co jest standardowym ustawieniem dla sieci biurowych. W Packet Tracer możesz użyć wartości w minutach: 1440.
- Po konfiguracji zweryfikuj dzierżawy poleceniem
show ip dhcp binding. Sprawdź, czy klient z VLAN 10 otrzymał adres z puli VLAN 10, a nie z VLAN 20. - W trybie symulacji (Simulation Panel) użyj narzędzia "Filter" i włącz widok pakietów DHCP. Zaobserwuj fazę DORA: Discover, Offer, Request, Acknowledgment.
- Jeśli klient nie otrzymuje adresu, sprawdź kolejno: łączność warstwy 3 między routerem a serwerem DHCP, poprawność enkapsulacji dot1Q, adresy helper-address i zakresy puli DHCP.
- W sprawozdaniu opisz dokładnie, jak zmienia się pakiet DHCP po przejściu przez Relay Agent — zwróć uwagę na zmianę adresu źródłowego i pola GIADDR.
- Status: WYKONALNE W 100% — Funkcjonalność DHCP Relay (
ip helper-address) jest w pełni wspierana. - Router-on-a-Stick (subinterfejsy z enkapsulacją dot1Q) działa poprawnie na routerach ISR 2811/2911 w PT.
- Pule DHCP na Server-PT obsługują wiele VLANów, rezerwacje statyczne, exclusion list.
- Proces DORA (Discover/Offer/Request/Acknowledge) działa prawidłowo w trybie symulacji.
- Ograniczenia: brak DHCP Snooping (tylko wiersz poleceń, brak pełnej funkcji filtrowania), uproszczony lease time.
- UWAGA Pamiętaj o
encapsulation dot1Q [vlan]na każdym subinterfejsie!
Enter configuration commands, one per line. End with CNTL+Z.
Router(config)# interface GigabitEthernet 0/0
Router(config-if)# no shutdown
%LINK-3-UPDOWN: Interface GigabitEthernet0/0, changed state to up
Router(config-if)# exit
Router(config)# interface GigabitEthernet 0/0.10
Router(config-subif)# encapsulation dot1Q 10
Router(config-subif)# ip address 192.168.10.1 255.255.255.0
Router(config-subif)# ip helper-address 192.168.100.10
%DHCP: Helper address configured on Gi0/0.10
Router(config-subif)# exit
Router(config)# interface GigabitEthernet 0/0.20
Router(config-subif)# encapsulation dot1Q 20
Router(config-subif)# ip address 192.168.20.1 255.255.255.0
Router(config-subif)# ip helper-address 192.168.100.10
Router(config-subif)# exit
Router(config)# exit
Router# show ip interface brief
Interface IP-Address OK? Method Status Protocol
GigabitEthernet0/0 unassigned YES NVRAM up up
GigabitEthernet0/0.10 192.168.10.1 YES NVRAM up up
GigabitEthernet0/0.20 192.168.20.1 YES NVRAM up up
Server-DHCP# show ip dhcp pool
Pool VLAN10_IT:
Referenced routes: 1
DNS/Prefixes: 8.8.8.8, 1.1.1.1
Total addresses : 254
Leased addresses : 3
Pending requests : 0
Excluded/Reserved: 0
Pool VLAN20_HR:
Referenced routes: 1
DNS/Prefixes: 8.8.4.4, 1.0.0.1
Total addresses : 254
Leased addresses : 2
Pending requests : 0
Excluded/Reserved: 2
Server-DHCP# show ip dhcp binding
IP address Client-ID Hardware address Lease expiration
192.168.10.10 0060.5c36.0042 Apr 28 2026 14:30:00
192.168.10.11 0060.5c36.0043 Apr 28 2026 14:32:15
192.168.20.10 0060.5c36.0055 Apr 28 2026 15:10:00
192.168.20.11 0060.5c36.0056 Apr 28 2026 15:15:30
Server-DHCP# show ip dhcp exclusion
IP address range Exclude range
192.168.10.1 - 192.168.10.10 VLAN10_IT
192.168.20.1 - 192.168.20.10 VLAN20_HR
DHCP Relay (ip helper-address) stanowi efektywniejsze rozwiązanie od instalowania dedykowanych serwerów DHCP w każdej podsieci, ponieważ eliminuje redundancję sprzętową, centralizuje zarządzanie pulami adresowymi i zapewnia spójność polityki adresacji w całej organizacji. W architekturze wielowarstwowej, gdzie routery segmenteują ruch warstwy 3, Relay Agent przekazuje broadcasty DHCP do centralnego serwera, zachowując jednocześnie izolację broadcastów warstwy 2. Z perspektywy bezpieczeństwa, atak DHCP Starvation polega na zalaniu serwera fałszywymi żądaniami DORA w celu wyczerpania puli adresowej — atakujący generuje tysiące żądań z losowymi adresami MAC, co powoduje, że legalni klienci nie mogą otrzymać adresu IP. Ochrona przed tym zagrożeniem wymaga implementacji DHCP Snooping na przełącznikach Cisco, który klasyfikuje porty jako zaufane (trusted) lub niezaufane (untrusted) i blokuje pakiety DHCP Offer pochodzące z nieautoryzowanych źródeł, a także limitowania liczby wpisów ARP na portach accessowych.
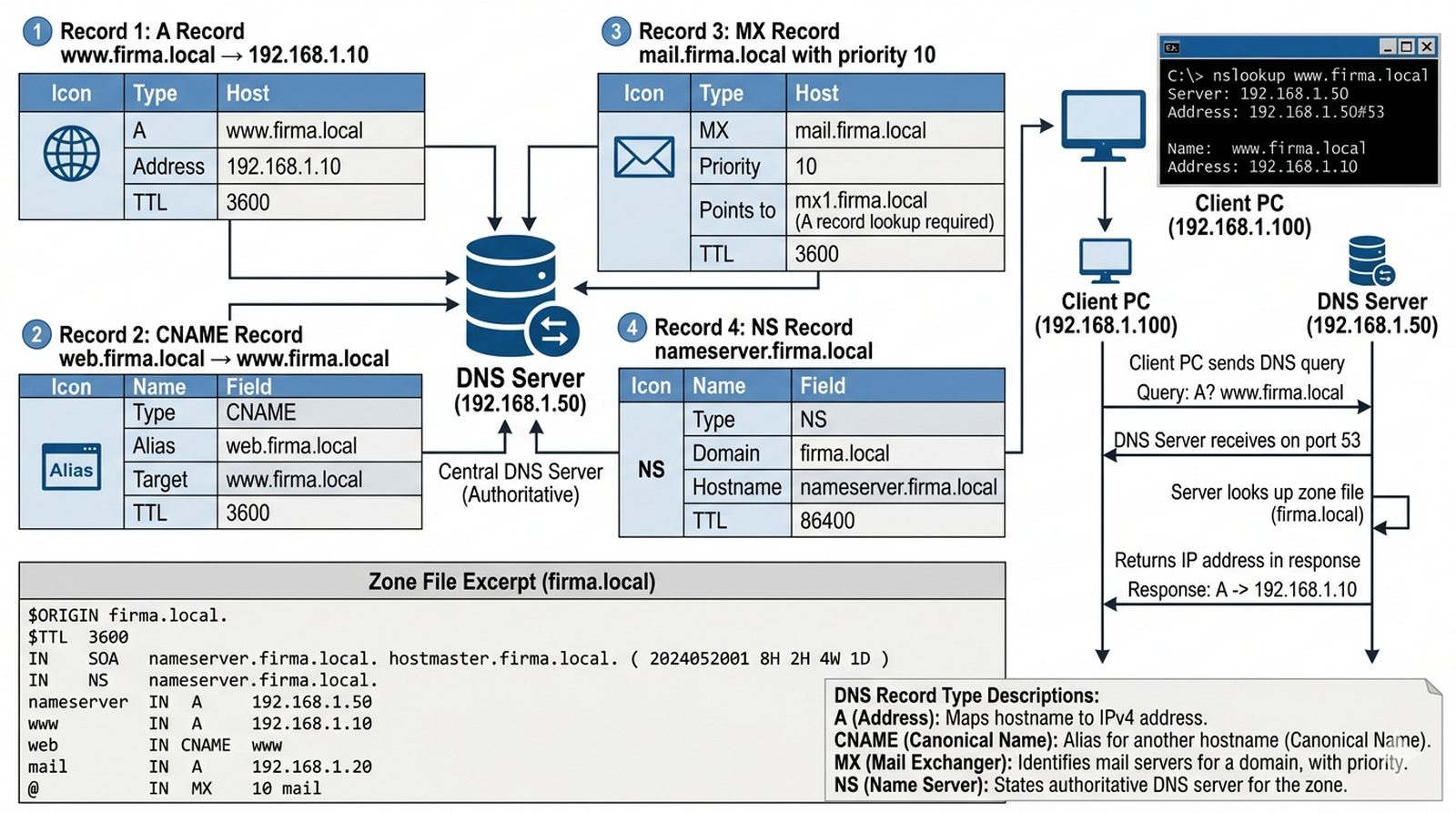
Wykład 2 Rekordy A, CNAME, MX, odpytywanie rekurencyjne.
Uruchamiasz nową infrastrukturę usług dla domeny "firma.local". Twoim zadaniem jest konfiguracja serwera DNS, który będzie obsługiwał zapytania lokalne. Musisz stworzyć wpisy dla serwera WWW, serwera pocztowego oraz aliasy dla łatwiejszego zarządzania. Kluczowe jest, aby pracownicy mogli odwoływać się do zasobów po nazwach, a nie po adresach IP. Dodatkowo musisz skonfigurować router tak, aby znał adres lokalnego serwera DNS i potrafił rozwiązywać nazwy urządzeń brzegowych.
- Uruchomienie usługi DNS na serwerze (Server-PT).
- Dodanie rekordu typu 'A' dla www.firma.local wskazującego na IP serwera HTTP.
- Dodanie rekordu typu 'CNAME' (alias) dla web.firma.local.
- Dodanie rekordu typu 'MX' dla mail.firma.local (priorytet 10).
- Konfiguracja klienta (PC) z adresem serwera DNS i testowanie "nslookup".
- Weryfikacja rozwiązywania nazw przy użyciu polecenia ping.
- Konfiguracja routera jako klienta DNS (ip domain-lookup).
- Stworzenie lokalnej bazy hostów na routerze (ip host).
- Testowanie błędnych zapytań i analiza czasu odpowiedzi.
- Udokumentowanie struktury strefy DNS w sprawozdaniu.
- Sprawdzenie poprawności mapowania nazw w przeglądarce WWW komputera.
Router(config)# ip name-server 192.168.1.50
Router(config)# ip host serwer.firma.local 192.168.1.10
PC> nslookup www.firma.local
- Na serwerze DNS aktywuj usługę w zakładce Services → DNS. Bez tego serwer nie będzie odpowiadał na zapytania — nawet jeśli wpisy są poprawne.
- Tworząc strefę DNS, pamiętaj o kropce na końcu nazwy domeny. W Packet Tracer nazwa domeny może być dowolna (np. firma.local bez kropki końcowej w interfejsie GUI).
- Rekord typu A (Address) mapuje nazwę domenową na adres IPv4. Dla www.firma.local utwórz wpis A wskazujący na adres IP serwera HTTP (np. 192.168.1.10).
- Rekord CNAME (Canonical Name) tworzy alias — web.firma.local powinien wskazywać na istniejący rekord A (np. www.firma.local). Dzięki temu wielu aliasów może wskazywać na tę samą usługę.
- Rekord MX (Mail Exchange) określa serwer pocztowy dla domeny. Priorytet 10 oznacza, że ten serwer jest preferowany. W Packet Tracer ustaw adres na mail.firma.local (wcześniej utwórz dla niego rekord A).
- Na komputerze klienckim w konfiguracji IP w polu DNS Server wpisz adres serwera DNS. Bez tego wpisu klient nie będzie znał lokalnego serwera nazw.
- Testowanie wykonaj poleceniem
nslookup www.firma.localw wierszu poleceń PC. Jeśli odpowiedź zawiera poprawny adres IP — DNS działa. - Router Cisco może pełnić rolę klienta DNS poleceniami
ip domain-lookup(włączone domyślnie) orazip name-server [adres]. Dzięki temu nazwy hostów można używać w poleceniach ping czy telnet. - Lokalna baza hostów na routerze tworzona jest poleceniem
ip host [nazwa] [adres_IP]. Wpis ten ma wyższy priorytet niż zapytanie do serwera DNS. - Przetestuj błędne zapytania DNS, wpisując nieistniejącą domenę. Zaobserwuj komunikat "Host Not Found" i czas odpowiedzi (timeout).
- W przeglądarce WWW na PC wpisz adres http://www.firma.local — strona powinna się załadować z serwera HTTP. To potwierdza, że DNS prawidłowo rozwiązuje nazwy na całym stosie aplikacyjnym.
- W sprawozdaniu umieść diagram strefy DNS pokazujący hierarchię rekordów oraz wyjaśnij, dlaczego plik hosts jest rozwiązaniem tymczasowym w porównaniu z serwerem DNS.
- Status: WYKONALNE W 100% — Serwer DNS w PT obsługuje rekordy A, CNAME, MX, NS, PTR.
nslookupdziała na PC i server-PT. DNS resolver prawidłowo odpytuje strefę.- Router wspiera
ip domain-lookup,ip name-server,ip host. - Integracja z serwerem HTTP — nazwy rozwiązują się w przeglądarce WWW.
- Ograniczenia: brak DNSSEC, zone transfer nie jest w pełni symulowany, brak dynamicznych aktualizacji.
- ZALECENIE Użyj statycznych wpisów DNS; dynamic update nie jest wspierany w PT.
Enter configuration commands, one per line. End with CNTL+Z.
DNS-Server(config)# ip domain-lookup
DNS-Server(config)# ip name-server 192.168.1.50
DNS-Server(config)# ip host www.firma.local 192.168.1.10
DNS-Server(config)# ip host web.firma.local 192.168.1.10
DNS-Server(config)# ip host mail.firma.local 192.168.1.20
Router# ping www.firma.local
PING www.firma.local (192.168.1.10): 56 data bytes
64 bytes from 192.168.1.10: icmp_seq=0 ttl=64 time=1.234 ms
64 bytes from 192.168.1.10: icmp_seq=1 ttl=64 time=1.456 ms
64 bytes from 192.168.1.10: icmp_seq=2 ttl=64 time=1.345 ms
PC# nslookup www.firma.local
Server: 192.168.1.50
Address: 192.168.1.50#53
Name: www.firma.local
Address: 192.168.1.10
PC# nslookup mail.firma.local
Server: 192.168.1.50
Address: 192.168.1.50#53
Name: mail.firma.local
Address: 192.168.1.20
PC# nslookup web.firma.local
Server: 192.168.1.50
Address: 192.168.1.50#53
Name: web.firma.local
Address: 192.168.1.10
web.firma.local canonical name = www.firma.local
PC# nslookup -type=MX firma.local
Server: 192.168.1.50
Address: 192.168.1.50#53
firma.local mail exchanger 10 mail.firma.local.
Router# show hosts
Default server 192.168.1.50
Address 0.0.0.0
Host Ga-Address Flags Age
www.firma.local 192.168.1.10 (temp) 0
mail.firma.local 192.168.1.20 (temp) 0
web.firma.local 192.168.1.10 (temp) 0
Rekord typu A (Address) mapuje canonical name na adres IP i stanowi podstawowy zasób strefy, podczas gdy rekord CNAME tworzy alias wskazujący na inną nazwę kanoniczną, co pozwala na elastyczne abstrakcyjne nazywanie usług bez twardego kodowania adresów IP. Kluczową różnicą jest fakt, że rekord A może współistnieć z innymi rekordami tego samego typu dla domeny, podczas gdy CNAME musi być jedynym rekordem dla danej nazwy (nie można utworzyć innych rekordów dla tej samej nazwy, co byłoby w konflikcie). W profesjonalnych sieciach korporacyjnych plik hosts jest rozwiązaniem tymczasowym i nie skalowalnym, ponieważ wymaga ręcznej aktualizacji na każdej stacji roboczej, nie oferuje mechanizmu TTL ani cache'owania, i generuje problem N do kwadratu przy zarządzaniu wieloma hostami — DNS natomiast zapewnia centralizację, automatyczne rozwiązywanie nazw, cache'owanie po stronie resolverów, oraz obsługę delegacji stref, co czyni go jedynym sensownym rozwiązaniem w infrastrukturze LAN większej niż małe biuro.
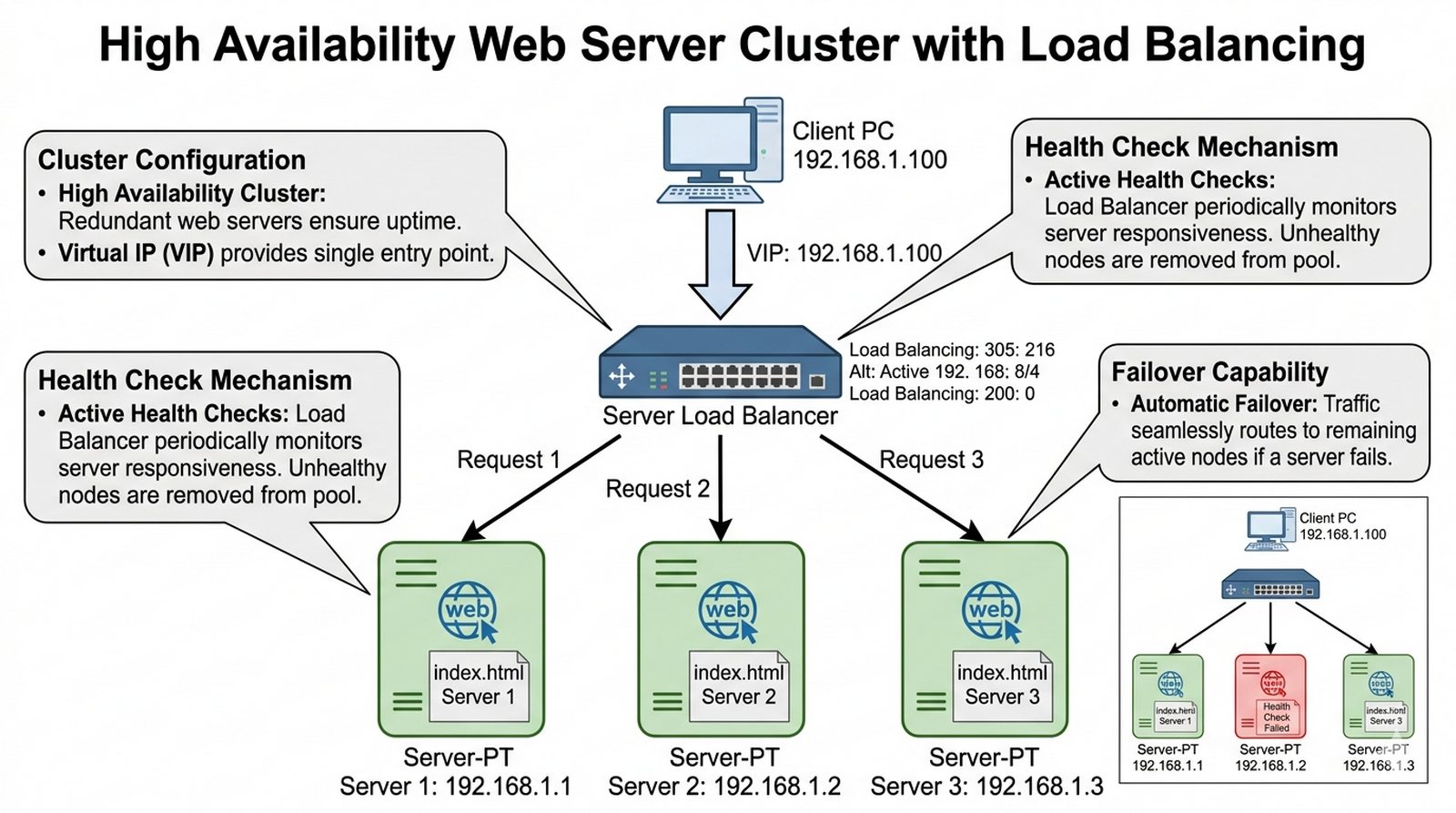
Wykład 10 Wysoka dostępność (HA), Load Balancing, Round Robin.
Serwer strony internetowej firmy jest przeciążony w godzinach szczytu, a każda jego awaria powoduje paraliż sprzedaży. Jako administrator musisz wdrożyć rozwiązanie zwiększające dostępność i wydajność. Wykorzystasz do tego urządzenie Server Load Balancer (dostępne w Cisco Packet Tracer), które będzie rozdzielało ruch przychodzący na trzy identyczne serwery WWW. Z perspektywy klienta usługa ma być widoczna pod jednym, wirtualnym adresem IP (VIP), nawet jeśli jeden z serwerów zostanie wyłączony.
- Użycie trzech serwerów (Server-PT) z uruchomioną usługą HTTP.
- Dodanie urządzenia "Server Load Balancer" do topologii.
- Konfiguracja puli serwerów (Cluster) na Load Balancerze.
- Ustawienie wirtualnego adresu IP (VIP) dla klastra.
- Konfiguracja algorytmu rozdzielania ruchu (np. Round Robin).
- Testowanie dostępu do strony WWW z komputera PC przez adres VIP.
- Symulacja awarii jednego serwera (wyłączenie usługi/kabla) i weryfikacja dostępności strony.
- Edycja zawartości index.html na każdym serwerze (np. dodanie "Server 1", "Server 2"), aby widzieć przełączanie.
- Monitorowanie statystyk obciążenia na Load Balancerze.
- Weryfikacja czasu reakcji klastra na zniknięcie węzła.
- Dokumentacja korzyści wynikających ze skalowania poziomego (scale-out).
VIP: 192.168.1.100
Pool Members: 192.168.1.1, 192.168.1.2, 192.168.1.3
Method: Round Robin
- Server Load Balancer w Packet Tracer znajdziesz w kategorii "Network Devices" → "Servers & Services". Urządzenie to pełni rolę sprzętowego balancer'a w oparciu o algorytm Round Robin.
- Każdy z trzech serwerów WWW musi mieć uruchomioną usługę HTTP w zakładce Services. Sprawdź, czy strony index.html są unikalne (np. "Serwer 1", "Serwer 2") — dzięki temu zobaczysz efekt równoważenia obciążenia.
- Adres IP serwerów WWW musi być w tej samej podsieci co Load Balancer. Ustaw je w konfiguracji statycznej i upewnij się, że brama domyślna wskazuje na router lub bezpośrednio na Load Balancer.
- W konfiguracji Load Balancera (GUI) utwórz nowy klaster (New Cluster), dodaj członków puli (Members) z adresami IP trzech serwerów oraz ustaw wirtualny adres IP (VIP) z puli dostępnych adresów.
- Algorytm Round Robin domyślnie rozdziela żądania sekwencyjnie: pierwsze żądanie do serwera 1, drugie do serwera 2, trzecie do serwera 3, i tak cyklicznie.
- Przetestuj dostęp przez VIP w przeglądarce PC: wpisz adres http://192.168.1.100 (VIP). Odświeżaj stronę kilka razy — powinieneś zobaczyć treść z różnych serwerów.
- Wyłącz jeden serwer (np. Server 2), odczekaj chwilę i ponownie odśwież stronę. Load Balancer powinien automatycznie wykryć awarię i przekierować ruch do sprawnych serwerów.
- Upewnij się, że pakiety powrotne od serwerów do klienta przechodzą przez Load Balancer. Dla działania w symetrycznym trybie inline wymagana jest prawidłowa brama domyślna na serwerach.
- W panelu statystyk Load Balancera obserwuj liczniki żądań (Requests) dla każdego członka klastra. Suma żądań powinna być równa liczbie odświeżeń strony przez klienta.
- W trybie symulacji zaobserwuj ścieżkę pakietu od klienta do VIP, a następnie do konkretnego serwera. Zwróć uwagę na zmianę docelowego adresu IP przez Load Balancer.
- Czas reakcji klastra na awarię węzła zależy od interwału health check. W Packet Tracer jest to zazwyczaj kilka sekund — w produkcji można to skonfigurować bardziej agresywnie.
- W sprawozdaniu wyjaśnij korzyści ze skalowania poziomego — możliwość dodawania serwerów bez przestojów, odporność na awarię pojedynczego węzła, równomierne obciążenie zasobów.
Skalowanie pionowe (vertical scaling) polega na wymianie lub rozbudowie zasobów pojedynczego serwera (CPU, RAM, dysk), co generuje przestoje przy rozbudowie i tworzy pojedynczy punkt awarii, natomiast skalowanie poziome (horizontal scaling) dodaje kolejne węzły do klastra, umożliwiając rozbudowę bez przestojów i zapewniając redundancję przy awarii jednostki. Mechanizm health check w load balancerze pełni krytyczną rolę — cyklicznie weryfikuje dostępność każdego członka klastra poprzez wysyłanie probe'ów HTTP/TCP i automatycznie wyklucza z puli węzły, które nie odpowiadają w określonym interwale (np. 3 nieudane próby co 5 sekund), co gwarantuje ciągłość usługi dla użytkowników końcowych. W kontekście Cisco Server Load Balancer w Packet Tracer, algorytm Round Robin rozkłada żądania sekwencyjnie, natomiast w środowisku produkcyjnym stosuje się bardziej zaawansowane metody — Least Connections czy IP Hash — uwzględniające stan sesji i aktualne obciążenie węzłów.
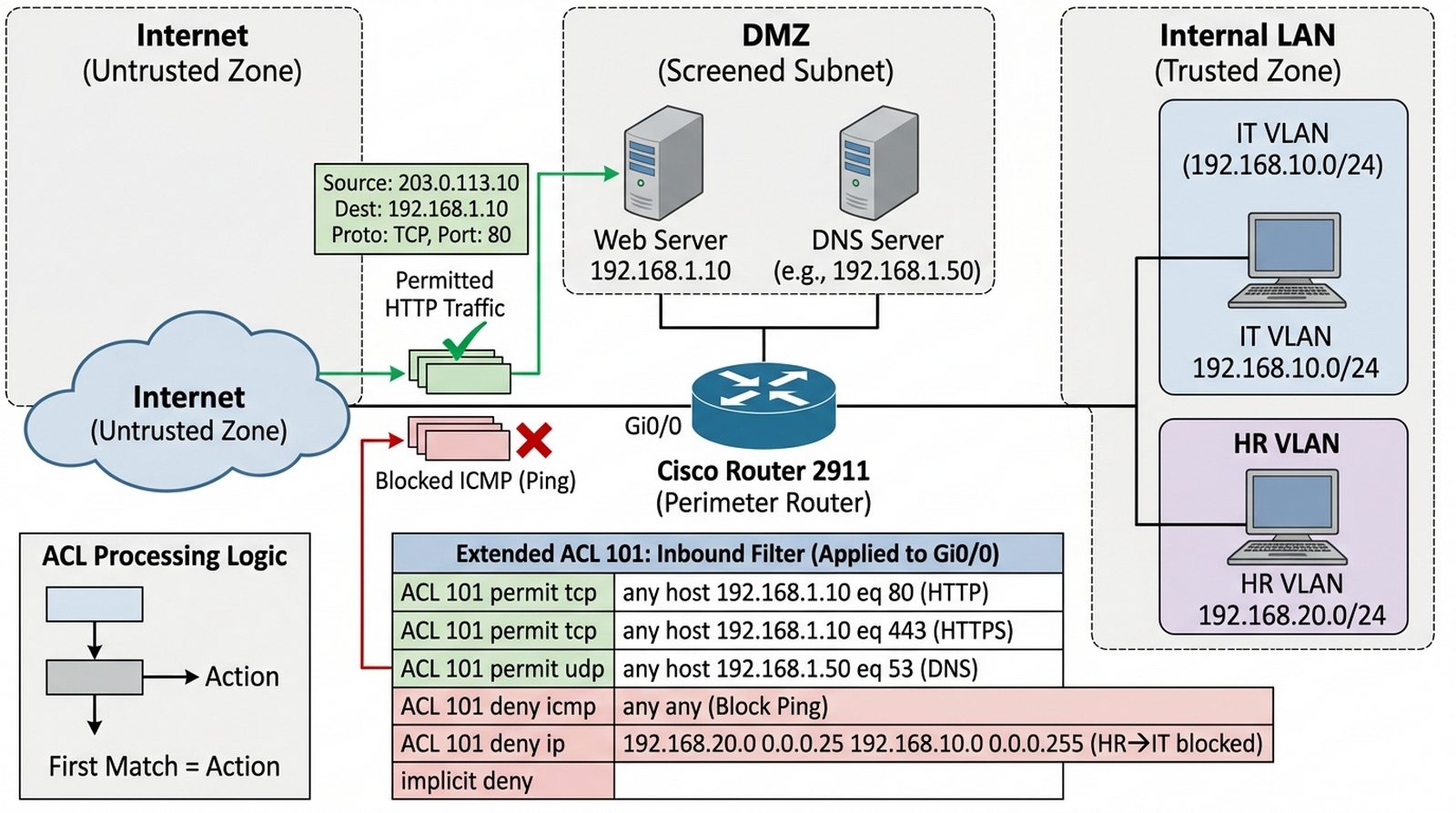
Wykład 3 Filtrowanie pakietów, listy kontroli dostępu (Standard vs Extended ACL), bezpieczeństwo warstwy 3 i 4.
Serwerownia firmy stała się celem nieautoryzowanych prób dostępu. Twoim zadaniem jest wdrożenie rygorystycznej polityki bezpieczeństwa na routerze brzegowym, który będzie pełnił rolę zapory ogniowej. Musisz zezwolić na ruch WWW i DNS do serwerów publicznych, ale jednocześnie zablokować wszelkie inne próby połączeń z internetu (np. ICMP, Telnet). Dodatkowo, dział HR nie powinien mieć dostępu do zasobów działu IT wewnątrz sieci lokalnej. Sukcesem będzie udowodnienie, że tylko pożądany ruch przepływa przez router, a pozostałe pakiety są odrzucane i logowane.
- Stworzenie rozszerzonych list kontroli dostępu (Extended ACL).
- Zezwolenie na ruch HTTP (port 80) i HTTPS (port 443) do serwerów WWW.
- Zezwolenie na zapytania DNS (UDP port 53) do serwera nazw.
- Zablokowanie ruchu typu "ping" (ICMP) z sieci zewnętrznej do LAN.
- Zastosowanie ACL na właściwych interfejsach routera (in/out).
- Konfiguracja ACL blokującej komunikację między VLAN 10 (IT) a VLAN 20 (HR).
- Użycie słowa kluczowego "log" w regułach blokujących do monitorowania ataków.
- Weryfikacja działania ACL poleceniem "show access-lists".
- Testowanie blokady za pomocą narzędzia "Ping" oraz "Web Browser" na komputerach.
- Analiza odrzuconych pakietów w trybie symulacji (komunikat "administratively prohibited").
- Zasada "implicit deny" – upewnienie się, że wszystko, co nie jest dozwolone, jest zabronione.
Router(config)# access-list 101 deny ip any any log
Router(config-if)# ip access-group 101 in
Router# show access-lists
- Extended ACL oferują znacznie większe możliwości niż Standard ACL. Pozwalają filtrować ruch na podstawie adresu źródłowego, docelowego, numeru portu i protokołu (TCP, UDP, ICMP).
- Numer listy ACL ma znaczenie: Standard ACL używają numerów 1-99 i 1300-1999, Extended ACL używają numerów 100-199 i 2000-2699. Wybierz odpowiedni zakres dla rozszerzonych list.
- Podstawowa składnia rozszerzonej ACL:
access-list [numer] [permit|deny] [protokół] [źródło] [cel] eq [port]. Przykład:access-list 101 permit tcp any host 192.168.1.10 eq 80. - Reguły w ACL przetwarzane są sekwencyjnie od góry do dołu. Pierwsza pasująca reguła kończy przetwarzanie. Dlatego najbardziej szczegółowe reguły umieszczaj na początku listy.
- Na końcu każdej ACL domyślnie znajduje się ukryta reguła "deny ip any any" (implicit deny). Wszystko, co nie zostało jawnie dozwolone, jest blokowane.
- Aby zezwolić na ruch HTTP (80) i HTTPS (443) do serwera WWW, użyj dwóch osobnych reguł permit. HTTPS wymaga portu 443.
- Zapytania DNS używają portu UDP 53. Reguła:
access-list 101 permit udp any host [DNS_IP] eq 53. - Blokada ping (ICMP) z sieci zewnętrznej:
access-list 101 deny icmp any any. Umieść ją przed regułą permit dla innych protokołów. - ACL można zastosować na interfejsie w kierunku przychodzącym (in) lub wychodzącym (out). Zasada: im bliżej źródła, tym lepiej dla ruchu blokowanego.
- Dodaj słowo kluczowe
logdo reguł blokujących, aby widzieć odrzucone pakiety w logach. Przykład:deny ip any any log. - W trybie symulacji włącz filtr "HTTP" i "ICMP", aby zaobserwować pakiety. Spróbuj pingować z zewnętrznego hosta do LAN — pakiet powinien zostać odrzucony z komunikatem "administratively prohibited".
- Blokada komunikacji między VLAN 10 a VLAN 20 wymaga ACL przypisanej do subinterfejsów routera lub bezpośrednio na porcie switcha. Użyj ACL numeru z rozszerzonego zakresu.
- W sprawozdaniu opisz różnicę między Stateful Inspection a statycznym filtrowaniem pakietów. Wyjaśnij, dlaczego ACL na routerze nie zastępuje pełnowartościowego firewalla.
ACL przetwarzają reguły metodą First Match — pierwsza pasująca reguła kończy ewaluację i decyduje o akcji (permit/deny), co wymusza precyzyjne porządkowanie reguł od najbardziej specyficznych do najbardziej ogólnych. Listy ACL na routerze Cisco oferują jedynie statyczne filtrowanie pakietów warstwy 3 i 4 bez stanu sesji — nie śledzą stanu połączeń TCP ani kontekstu aplikacyjnego, co oznacza, że ruch odpowiedzi (np. dane HTTP wracające do klienta) musi być jawnie dozwolony w obu kierunkach, a router nie potrafi rozpoznać, czy pakiet jest odpowiedzią na wcześniej dozwoloną sesję. Dedykowane urządzenia klasy Firewall (np. ASA, Firepower) implementują Stateful Inspection — analizują pakiety w kontekście sesji, automatycznie pozwalają na ruch powrotny dla ustanowionych połączeń, oferują Deep Packet Inspection (DPI), applcation-layer gateway i intrusion prevention, co czyni je niezastąpionymi w segmencie perimeter defense przed ACL routera.
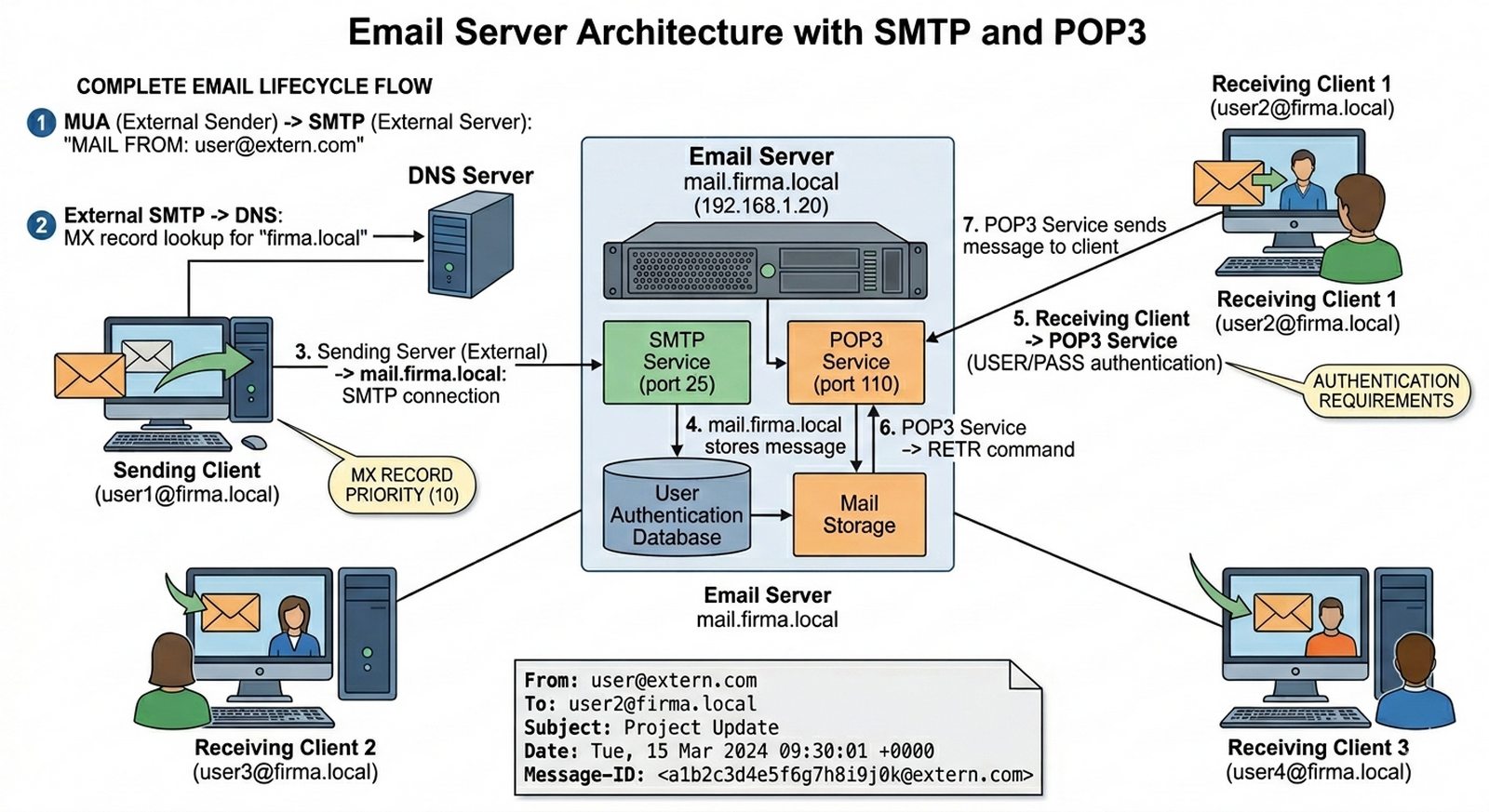
Wykład 4 Protokoły pocztowe, MX records, uwierzytelnianie użytkowników.
Firma rezygnuje z usług darmowych dostawców poczty na rzecz własnego, wewnętrznego serwera. Twoim zadaniem jest uruchomienie usługi SMTP (wysyłanie) oraz POP3 (odbieranie) na centralnym serwerze usług. Musisz stworzyć konta dla pracowników (np. admin@firma.local, user@firma.local) i skonfigurować aplikacje pocztowe na Laptopie-PT oraz PC-PT tak, aby mogły wymieniać korespondencję. Sukcesem laboratorium będzie przesłanie poprawnie sformatowanej wiadomości e-mail między skrajnymi punktami topologii.
- Uruchomienie usługi Email na serwerze (Server-PT).
- Ustawienie nazwy domeny "firma.local" w ustawieniach serwera poczty.
- Utworzenie minimum 3 kont użytkowników z silnymi hasłami.
- Konfiguracja rekordu MX w serwerze DNS (powiązanie z Zadaniem 03).
- Konfiguracja klienta pocztowego (Mail Browser) na stacjach roboczych.
- Ustawienie właściwych adresów serwerów SMTP i POP3 (mogą być nazwy DNS).
- Wysłanie wiadomości testowej i weryfikacja jej odebrania przez drugiego użytkownika.
- Analiza nagłówków pocztowych w trybie symulacji (PDU details).
- Sprawdzenie logów serwera poczty pod kątem poprawności logowania (auth).
- Weryfikacja blokady wysyłania poczty przy błędnym haśle.
- Przetestowanie załączników (jeśli wspierane przez symulator).
Your Name: Jan Kowalski
Incoming Mail Server: mail.firma.local
Outgoing Mail Server: mail.firma.local
- Na serwerze pocztowym włącz usługę Email w zakładce Services. Ustaw nazwę domeny na "firma.local" — musi ona odpowiadać nazwie w rekordzie MX w serwerze DNS.
- Utwórz minimum trzy konta użytkowników (np. admin, pracownik1, pracownik2) z silnymi hasłami. Każde konto składa się z nazwy użytkownika i hasła, które będą wymagane przy logowaniu.
- Skonfiguruj rekord MX w serwerze DNS z Zadania 03, wskazujący na "mail.firma.local". Adres IP tego rekordu musi odpowiadać adresowi serwera pocztowego.
- Na kliencie pocztowym (PC lub Laptop) uruchom aplikację Desktop → Email Client (Mail Browser). Wpisz dane pierwszego użytkownika: adres e-mail, serwer POP3 i SMTP.
- Serwer POP3 (odbieranie) i SMTP (wysyłanie) w Packet Tracer często działają na tym samym adresie IP — to normalne w symulatorze. Oba wpisy mogą wskazywać na mail.firma.local.
- Przetestuj wysłanie wiadomości z jednego konta na drugie. Otwórz drugiego klienta i sprawdź, czy wiadomość dotarła (przycisk Receive/Synchronize w aplikacji pocztowej).
- W trybie symulacji zaobserwuj pakiety SMTP — komunikacja przebiega na porcie TCP 25 dla SMTP i TCP 110 dla POP3.
- Sprawdź logi serwera poczty w zakładce Services → Email → Logs. Zaobserwuj wpisy dotyczące udanego i nieudanego logowania.
- Wyloguj się z konta i spróbuj wysłać wiadomość z błędnym hasłem — serwer powinien odmówić dostępu z komunikatem o błędzie uwierzytelniania.
- Załączniki w Packet Tracer mogą być obsługiwane, ale ich rozmiar jest ograniczony. Spróbuj załączyć prosty plik tekstowy do wiadomości.
- Analiza nagłówków wiadomości w trybie symulacji (PDU Details) pozwala zobaczyć strukturę wiadomości e-mail — pola From, To, Subject oraz treść wiadomości.
- W sprawozdaniu opisz różnicę między protokołami POP3 a IMAP — POP3 domyślnie usuwa wiadomości z serwera po pobraniu, IMAP synchronizuje je w czasie rzeczywistym.
Protokół POP3 domyślnie pobiera wiadomości z serwera i opcjonalnie je usuwa, co oznacza, że po pobraniu na klienta wiadomości nie są dostępne na innych urządzeniach i są podatne na utratę przy awarii lokalnego nośnika — w przeciwieństwie do IMAP, który synchronizuje stan folderów w czasie rzeczywistym między serwerem a wieloma klientami, oferując funkcje takie jak foldery zdalne, flagowanie wiadomości i unified inbox. Rekord MX (Mail Exchange) jest krytyczny dla dostarczania poczty z zewnątrz, ponieważ serwery pocztowe innych domen wyszukują go jako pierwszy krok w procesie delivery — resolver DNS zwraca priorytetowe hosty MX dla domeny docelowej, a SMTP connect próbuje połączyć się z serwerem o najniższym priorytecie, przechodząc do kolejnych w przypadku niedostępności. Bez poprawnego rekordu MX poczta przychodząca z Internetu zostanie odrzucona z błędem "MX not found" lub "Sender verify failed", co skutuje communication blackout dla firmy.
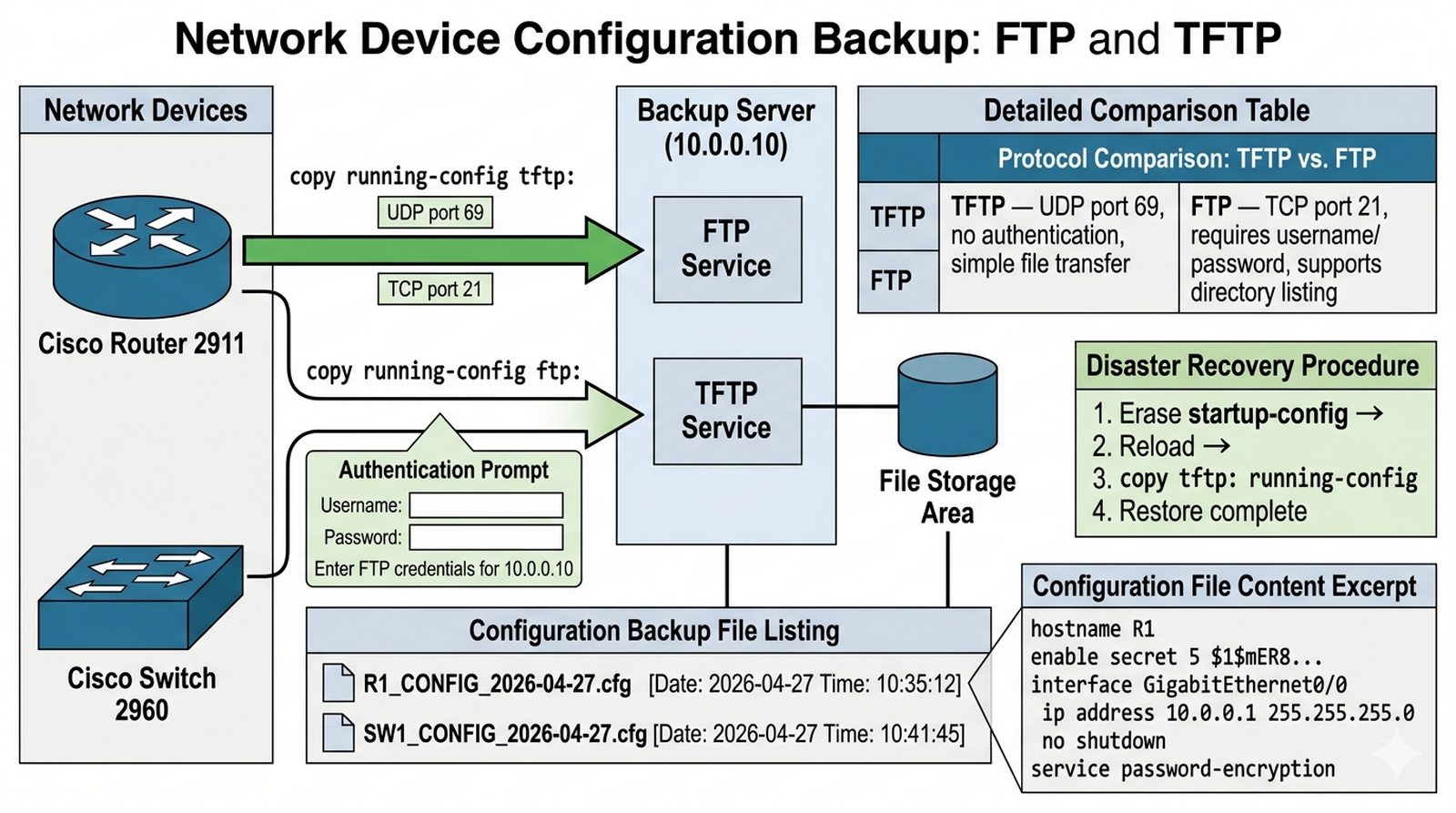
Wykład 5 Systemy plików sieciowych, backup konfiguracji, transfer plików.
Polityka bezpieczeństwa firmy wymaga regularnego tworzenia kopii zapasowych konfiguracji wszystkich routerów i przełączników. Twoim zadaniem jest uruchomienie centralnego serwera FTP dla dokumentacji oraz serwera TFTP dla szybkich zrzutów konfiguracji ("running-config"). Musisz zapewnić, że każde urządzenie sieciowe potrafi przesłać swój plik konfiguracyjny do serwera, a w razie awarii administrator może go szybko przywrócić z kopii sieciowej. Dodatkowo skonfiguruj autoryzowany dostęp do serwera FTP dla pracowników IT.
- Uruchomienie usług FTP i TFTP na serwerze dedykowanym.
- Stworzenie konta użytkownika FTP o nazwie "backup_user" z uprawnieniami do zapisu.
- Wykonanie kopii zapasowej konfiguracji Routera (copy running-config tftp:).
- Wykonanie kopii zapasowej konfiguracji Switcha (copy running-config ftp:).
- Weryfikacja obecności plików na serwerze (lista plików w GUI Serwera).
- Przeprowadzenie testu przywracania (skasowanie startup-config i restart urządzenia).
- Udokumentowanie procesu uwierzytelniania FTP w trybie symulacji.
- Sprawdzenie limitów transferu i czasów oczekiwania (timeout).
- Zabezpieczenie serwera FTP przed dostępem z sieci gości za pomocą ACL.
- Użycie polecenia "archive" na routerze dla automatyzacji backupu (jeśli wspierane).
- Analiza różnic między protokołem TFTP a FTP w kontekście niezawodności.
Address or name of remote host []? 10.0.0.10
Destination filename [Router-confg]? R_BACKUP_2026
Router# ip ftp username backup_user
- Na serwerze włącz usługi TFTP i FTP w zakładce Services. TFTP działa na porcie UDP 69, FTP na porcie TCP 21 (oraz TCP 20 dla aktywnego transferu danych).
- Dla serwera FTP utwórz dedykowanego użytkownika "backup_user" z hasłem w zakładce Services → FTP → Users. Nadaj mu uprawnienia do zapisu (Write/Read).
- Kopia zapasowa konfiguracji routera wykonywana jest poleceniem
copy running-config tftp:lubcopy running-config ftp:. Router poprosi o adres serwera i nazwę pliku. - Przy użyciu TFTP nie ma uwierzytelniania — wystarczy wskazać adres serwera. Przy FTP użyj najpierw poleceń
ip ftp username backup_useriip ftp password [hasło]. - Składnia polecenia backupu przez FTP:
copy running-config ftp:→ Remote host: [IP] → Destination filename: [np. R1_CONFIG_2026]. - Po wykonaniu kopii zapasowej sprawdź w GUI serwera (zakładka File System lub TFTP/FTP), czy plik konfiguracyjny pojawił się w katalogu serwera.
- Test przywracania: skasuj plik startup-config poleceniem
erase startup-configlubwrite erase, następniereload. Potem załaduj config:copy tftp: running-config. - Protokół TFTP jest bezstanowy i używa UDP, dlatego jest szybki, ale nie zapewnia integralności danych. W produkcji stosuje się go głównie lokalnie ze względu na brak szyfrowania.
- W trybie symulacji zaobserwuj różnicę w pakietach FTP i TFTP — FTP używa wielu połączeń TCP i komunikatów kontrolnych, TFTP działa prostym modelem request-response na UDP.
- Zabezpiecz serwer FTP przed nieautoryzowanym dostępem — użyj ACL na routerze, aby zezwolić na dostęp do serwera TFTP/FTP tylko z sieci zarządzania (np. 192.168.1.0/24).
- Polecenie
archivena routerze pozwala automatyzować backupi. Przykład:archive configtworzy snapshot konfiguracji, ale pełna automatyzacja wymaga dodatkowej konfiguracji. - W sprawozdaniu wyjaśnij, dlaczego backup konfiguracji jest kluczowy dla procedur Disaster Recovery — umożliwia szybkie przywrócenie usług po awarii bez konieczności ręcznej reconfiguracji.
Backup konfiguracji urządzeń sieciowych stanowi fundament procedur Disaster Recovery (DR) — w przypadku awarii sprzętowej lub corrupt firmware, gotowy config pozwala na szybkie przywrócenie usług bez rekonfiguracji od zera, co minimalizuje MTTR (Mean Time To Repair) i straty biznesowe. TFTP w sieciach produkcyjnych stosuje się głównie lokalnie ze względu na brak uwierzytelniania, szyfrowania i kontroli dostępu — jest to protokół bezstanowy, który przesyła pliki w plaintext, co czyni go podatnym na sniffing i man-in-the-middle, a w przypadku transferu wielu konfiguracji naraz nie ma mechanizmu wznawiania ani hash verification. W praktyce Cisco produkcyjnej, TFTP służy do prostych scenariuszy lokalnych (np. backup na lokalny serwer w serverowni lub na workstation admina), natomiast pełne rozwiązania backupowe wykorzystują SCP/SFTP z autentykacją kluczami lub FTP z TLS, oferujące szyfrowanie transferu, autentykację użytkowników i audit trail. Rekomendowaną praktyką jest przechowywanie co najmniej 3 wersji konfiguracji (ostatnia, poprzednia, przed-ostatnia) z datami w nazwie pliku, przechowywanych na wydzielonym serwerze backup z polityką retention.
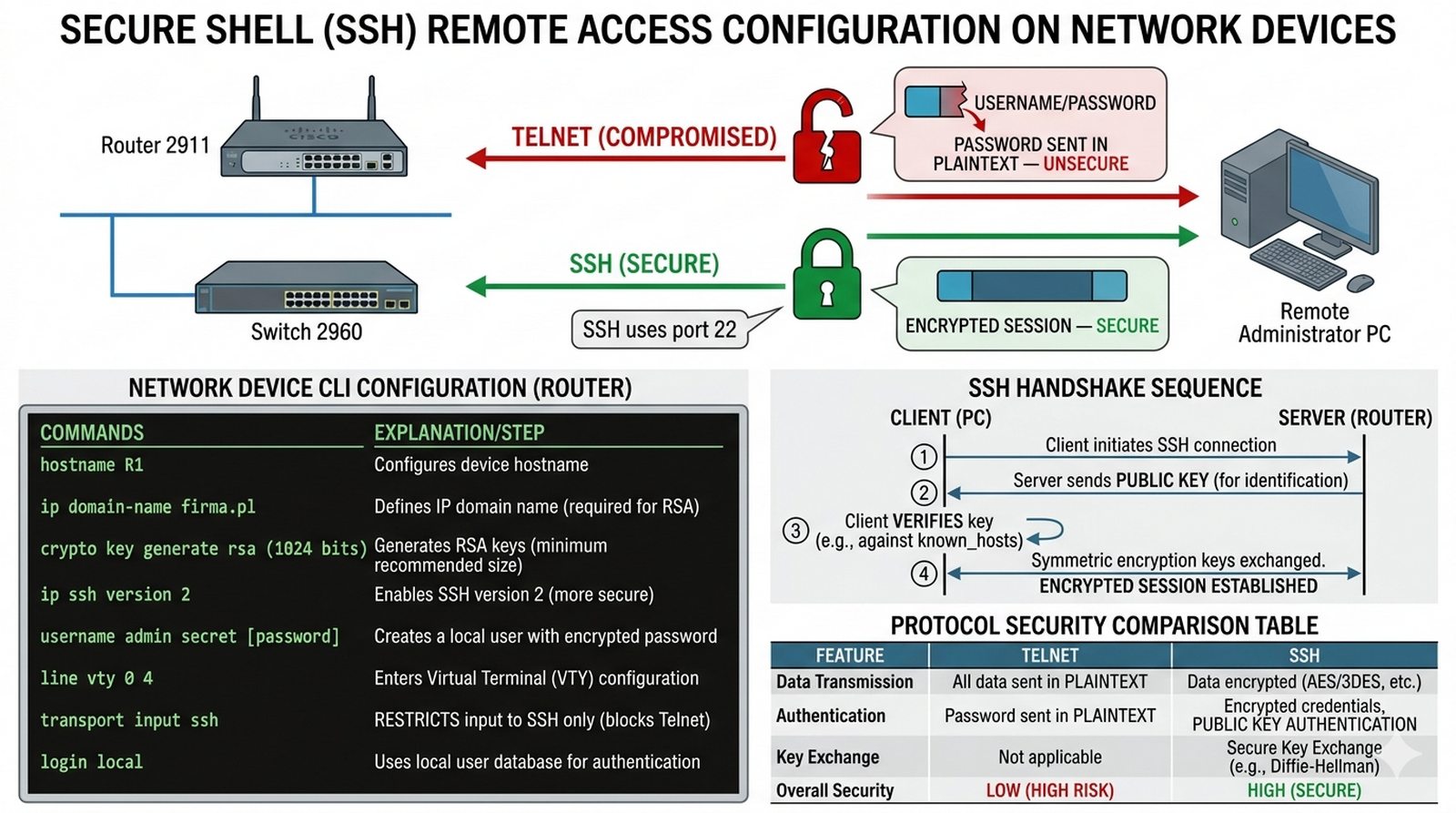
Wykład 8 Zarządzanie zdalne, utwardzanie VTY, kryptografia klucza publicznego.
Zarządzanie urządzeniami sieciowymi przez port konsolowy jest niepraktyczne w rozbudowanej infrastrukturze. Administratorzy muszą mieć dostęp do CLI z dowolnego miejsca w sieci biurowej. Jednak protokół Telnet przesyła hasła otwartym tekstem, co jest niedopuszczalne. Twoim zadaniem jest całkowite wyłączenie protokołu Telnet i skonfigurowanie usługi SSH (Secure Shell) w wersji 2 na wszystkich routerach i przełącznikach. Musisz wygenerować klucze RSA o odpowiedniej długości i zapewnić, że tylko autoryzowani użytkownicy mogą się zalogować.
- Ustawienie nazwy hosta oraz domeny (ip domain-name) na routerze i switchu.
- Generowanie kluczy kryptograficznych poleceniem "crypto key generate rsa" (min. 1024 bity).
- Włączenie serwera SSH w wersji 2 (ip ssh version 2).
- Utworzenie lokalnego użytkownika administratora z hasłem typu secret.
- Konfiguracja linii VTY do akceptowania tylko połączeń SSH (transport input ssh).
- Ustawienie logowania lokalnego (login local) na liniach VTY.
- Testowanie połączenia SSH z narzędzia "SSH Client" na komputerze PC.
- Weryfikacja blokady połączeń typu Telnet.
- Udokumentowanie w sprawozdaniu zrzutu z polecenia "show ssh".
- Ustawienie czasu bezczynności (exec-timeout) dla sesji zdalnych.
- Implementacja blokady po kilku błędnych próbach logowania (jeśli wspierane).
R1(config)# ip domain-name firma.pl
R1(config)# crypto key generate rsa
R1(config)# line vty 0 4
R1(config-line)# transport input ssh
- Przed generowaniem kluczy RSA ustaw nazwę hosta i domenę — bez tego router odmówi utworzenia kluczy. Polecenia:
hostname R1orazip domain-name firma.pl. - Generowanie kluczy RSA:
crypto key generate rsa. Router zapyta o długość klucza w bitach — podaj minimum 1024. Klucze 512 bitów są zbyt słabe dla SSHv2. - Włącz SSH w wersji 2 poleceniem
ip ssh version 2. Domyślnie router może akceptować SSHv1, który ma luki bezpieczeństwa — warto wymusić wersję 2. - Utwórz lokalnego użytkownika z hasłem typu secret:
username admin secret TajneHaslo123. Hasła typu "secret" są szyfrowane algorytmem MD5 lub nowszym. - Na liniach VTY (0-4) skonfiguruj transport input SSH:
line vty 0 4→transport input ssh. To całkowicie wyłącza Telnet na tych liniach. - Włącz logowanie lokalne:
login local— router będzie sprawdzał credentials w lokalnej bazie użytkowników zamiast używać wspólnego hasła line. - Ustaw exec-timeout dla sesji VTY:
exec-timeout 5 0(5 minut bezczynności = rozłączenie). To zabezpiecza przed pozostawionych otwartych sesji. - Na PC użyj aplikacji SSH Client (Desktop → Command Prompt → ssh). Składnia:
ssh -l admin [IP_routera]. Wpisz hasło po wyświetleniu monitu. - Po połączeniu SSH zweryfikuj status poleceniem
show ssh— zobaczysz wersję SSH, stan połączenia i czas sesji. - Próba połączenia Telnet powinna się nie powieść — router nie nasłuchuje na porcie Telnet (23) na liniach VTY skonfigurowanych tylko dla SSH.
- W Packet Tracer dostępna jest dedykowana aplikacja SSH Client (Desktop → SSH Client). Wpisz IP routera, login (admin) i hasło.
- Jeśli klucz RSA ma mniej niż 768 bitów, SSH może odmówić połączenia. Upewnij się, że generujesz klucz o długości minimum 1024 bitów.
- W sprawozdaniu uzasadnij, dlaczego SSH jest bezpieczniejsze od Telnetu — SSH szyfruje całą sesję (w tym hasła), Telnet przesyła dane tekstem jawnym (plaintext).
SSH zapewnia bezpieczny tunel komunikacyjny poprzez szyfrowanie całej sesji (w tym login/password payload) algorytmami symetrycznymi (AES, 3DES) i asymetrycznymi (RSA/DSA), autentykację serwera za pomocą host key, oraz opcjonalną autentykację klienta kluczami publicznymi — w przeciwieństwie do Telnet, który przesyła dane tekstem jawnym (plaintext), co oznacza, że każdy pakiet przechwycony w snifferze ujawnia pełne poświadczenia i konfigurację. Pozostawienie otwartego dostępu Telnet w sieci publicznej (np. przez bramę WAN) niesie ryzyko kradzieży poświadczeń poprzez ARP spoofing lub przechwycenie pakietów na przełączniku niezarządzanym, a także umożliwia ataki typu man-in-the-middle na infrastrukturę, gdzie atakujący może przejąć sesję i wykonać polecenia konfiguracyjne na urządzeniu bez wiedzy admina. W najlepszych praktykach Cisco, Telnet powinien być bezwzględnie wyłączony na wszystkich interfejsach dostępnych z zewnątrz (line vty 0 4), a dostęp realizowany wyłącznie przez SSH z autentykacją lokalną lub RADIUS/TACACS i listami ACL ograniczającymi źródłowe sieci IP.
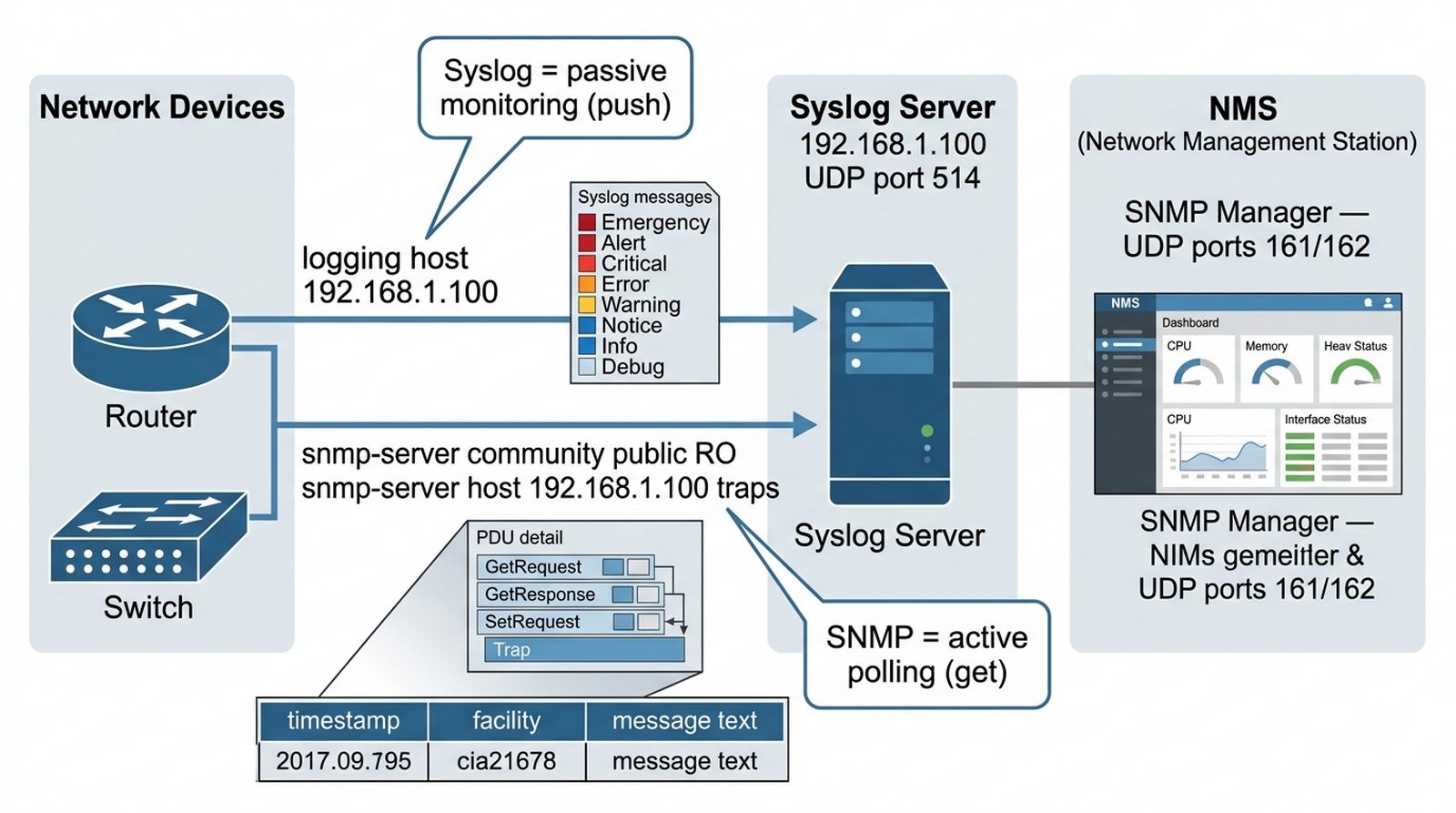
Wykład 6 Monitorowanie wydajności, logowanie zdarzeń, MIB i OID.
Utrzymanie stabilności usług wymaga ciągłego nadzoru nad obciążeniem procesorów i stanem interfejsów. Twoim zadaniem jest wdrożenie systemu monitorowania opartego na protokole SNMP oraz centralnego zbierania logów przez Syslog. Musisz skonfigurować router tak, aby wysyłał powiadomienia (Traps) o poważnych błędach do serwera NMS oraz przesyłał wszystkie komunikaty z konsoli do centralnego archiwum logów. Dzięki temu administrator będzie mógł analizować historię awarii nawet po restarcie urządzenia.
- Uruchomienie usług "Syslog" oraz "SNMP" na serwerze monitorującym.
- Konfiguracja routera do wysyłania logów (logging host).
- Ustawienie poziomu logowania na "informational" (level 6).
- Konfiguracja protokołu SNMP na routerze (read-only community string).
- Udzielenie zgody na wysyłanie trapów SNMP do serwera.
- Symulacja awarii (shutdown interfejsu) i weryfikacja wpisu w logach na serwerze.
- Monitorowanie obciążenia łącza za pomocą wbudowanego narzędzia SNMP na serwerze.
- Użycie polecenia "show logging" na routerze i porównanie z zawartością serwera.
- Analiza komunikatów "Trap" (OID) przechwyconych przez sniffer.
- Ustawienie lokalizacji i kontaktu dla agenta SNMP na routerze.
- Weryfikacja działania mechanizmu przy przeciążeniu (generowanie dużego ruchu).
Router(config)# snmp-server community public RO
Router(config)# snmp-server enable traps
Router(config)# snmp-server host 192.168.1.100 public
- Na serwerze monitorującym włącz usługi Syslog i SNMP w zakładce Services. Syslog zbiera logi, SNMP umożliwia monitorowanie i zarządzanie urządzeniami.
- Skonfiguruj router do wysyłania logów na serwer Syslog:
logging 192.168.1.100. Wszystkie logi z konsoli, linii VTY i bufora będą przesyłane na wskazany adres. - Ustaw poziom logowania:
logging trap informational(level 6). Oznacza to, że logi o poziomie 0-6 (od emergency do informational) będą wysyłane do serwera. - Dla SNMP skonfiguruj community string:
snmp-server community public RO. Parametr RO (Read-Only) oznacza, że manager może tylko odczytywać dane, nie zmieniać konfiguracji. - Włącz wysyłanie trapów SNMP:
snmp-server enable traps. Trapy to powiadomienia push wysyłane automatycznie przez agenta SNMP przy wystąpieniu zdarzenia. - Skonfiguruj hosta docelowego dla trapów:
snmp-server host 192.168.1.100 public. Community string musi być identyczny jak na serwerze NMS. - Symuluj awarię: wyłącz interfejs routera poleceniem
shutdownna wybranym interfejsie. Sprawdź, czy wpis o awarii pojawił się w logach Syslog. - W Packet Tracer narzędzie SNMP Manager (w usługach serwera) pozwala na odpytywanie agenta SNMP. Wyślij zapytanie typu GET na OID odpowiedzialny za status interfejsów.
- Ustaw informacje kontaktowe agenta SNMP:
snmp-server location "Serwerownia Piętro 1"orazsnmp-server contact admin@firma.pl. To ułatwia identyfikację urządzenia. - Na routerze sprawdź logi lokalne poleceniem
show logging. Porównaj wpisy z tymi na serwerze Syslog — powinny być identyczne. - W trybie symulacji zaobserwuj pakiety Syslog (UDP 514) i SNMP (UDP 161 dla queries, UDP 162 dla trapów). Zwróć uwagę na format PDU i zawartość pól community string.
- Protokół Syslog to monitorowanie pasywne (agent wysyła logi), SNMP to monitorowanie aktywne (manager odpytuje agenta). Oba uzupełniają się w kompleksowym systemie monitoringu.
- W sprawozdaniu wyjaśnij znaczenie monitoringu dla SLA — dzięki wczesnemu wykrywaniu problemów można zapobiegać awariom i gwarantować dostępność usług na poziomie umownym.
Monitoring pasywny (Syslog) polega na odbieraniu powiadomień z urządzeń — logi są pushowane automatycznie przy zajściu zdarzenia, co generuje dużą objętość danych i wymaga centralnego agregatora (np. Splunk, ELK), natomiast monitoring aktywny (SNMP polling) wymaga odpytywania urządzeń przez NMS w interwałach (co 5 min), co pozwala na kumulatywne zbieranie metryk (CPU, RAM, interface counters) i trend analysis over time. SNMP oferuje standardowe MIB-y umożliwiające uniformowe zbieranie metryk across vendors, co czyni go de facto standardem w network monitoring. Spełnienie warunków SLA (np. availability 99.9%) wymaga ciągłego monitoringu dostępności i reaktywności — NMS generuje alerty przy przekroczeniu progów (np. CPU > 80% przez 5 min), a historyczne dane pozwalają na wykazanie, że usługa spełniała warunki umowy (uptime percentage), co jest podstawą roszczeń klientskich i kar umownych. Rekomendowaną praktyką jest kombinacja obu podejść: Syslog dla krytycznych zdarzeń (link down, auth failure) i SNMP dla metryk performance, z dashboardami w Grafana/Zabbix.
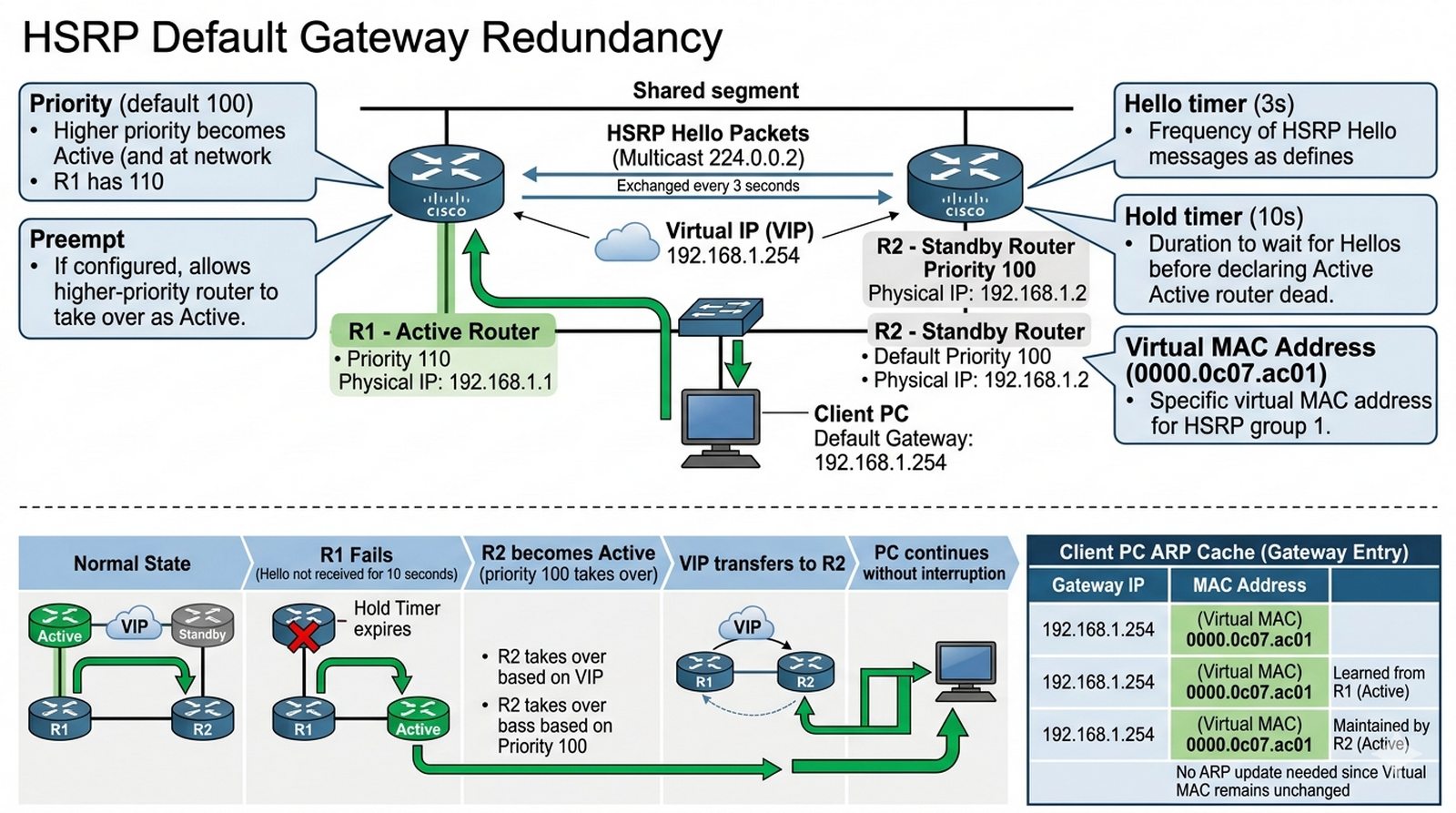
Wykład 10 Redundancja brzegowa, protokoły FHRP, wirtualne IP.
Awaria głównego routera brzegowego w Twojej firmie powoduje utratę łączności z Internetem dla wszystkich pracowników. Aby uniknąć tego pojedynczego punktu awarii (SPOF), musisz wdrożyć mechanizm redundancji bramy domyślnej przy użyciu protokołu HSRP (Hot Standby Router Protocol). Skonfigurujesz dwa routery działające w jednym zespole, które wspólnie będą obsługiwać jeden wirtualny adres IP. W przypadku awarii routera głównego, router zapasowy automatycznie przejmie jego rolę w czasie niezauważalnym dla użytkowników.
- Użycie dwóch routerów 2911 połączonych tym samym VLANem od strony LAN.
- Ustawienie adresu fizycznego IP na każdym routerze (np. .1 i .2).
- Konfiguracja grupy HSRP (standby 1) na obu routerach.
- Ustawienie wirtualnego adresu IP (VIP: .254) dla grupy.
- Konfiguracja priorytetu (priority) dla routera głównego w celu wymuszenia roli Active.
- Włączenie mechanizmu "preempt" umożliwiającego powrót do roli Active po naprawie.
- Konfiguracja komputerów PC tak, aby ich bramą domyślną był adres VIP (.254).
- Weryfikacja statusu poleceniem "show standby brief".
- Testowanie failover (shutdown interfejsu Active) podczas trwającego pingu do internetu.
- Analiza komunikatów "Hello" protokołu HSRP w trybie symulacji.
- Dokumentacja czasu przełączenia (liczba utraconych pakietów ping).
R1(config-if)# standby 1 priority 110
R1(config-if)# standby 1 preempt
R1# show standby brief
- HSRP działa w warstwie 3 na interfejsach routerów połączonych z tą samą siecią LAN. Oba routery muszą mieć interfejsy w tej samej podsieci (np. 192.168.1.0/24).
- Na routerze głównym (Active) skonfiguruj grupę HSRP z priorytetem wyższym niż domyślny (100):
standby 1 priority 110. Wyższy priorytet oznacza, że ten router stanie się Active. - Na routerze zapasowym (Standby) skonfiguruj tę samą grupę z domyślnym priorytetem 100. Możesz też jawnie ustawić priorytet niższy od głównego.
- Adres VIP (Virtual IP) musi być w tej samej podsieci co interfejsy fizyczne, ale nie może być przypisany do żadnego routera. Dla sieci 192.168.1.0/24 dobrym wyborem jest .254.
- Włącz mechanizm preempt:
standby 1 preempt. Dzięki temu po naprawie routera głównego i jego ponownym uruchomieniu przejmie on ponownie rolę Active. - Komputery PC w konfiguracji IP ustaw jako bramę domyślną adres VIP (.254), a nie adres fizyczny żadnego z routerów. Tylko wtedy HSRP zapewni transparencję przełączania.
- Weryfikacja statusu HSRP:
show standby briefpokazuje rolę (Active/Standby), priorytet, czas hello i adres VIP każdego routera. - Przetestuj failover: podczas trwającego pingu z PC do zewnętrznego adresu wyłącz interfejs Active routera poleceniem
shutdown. Obserwuj utratę pakietów (powinny być minimalne). - HSRP używa multicastu 224.0.0.2 (i alternatywnie 224.0.0.102 dla nowszych wersji) do komunikacji między routerami. Upewnij się, że switch nie blokuje tego ruchu.
- Adresy MAC używane przez HSRP mają format 0000.0c07.acXX, gdzie XX to numer grupy w formacie szesnastkowym. Polecenie
arp -ana PC pozwala zweryfikować, czy brama ma wirtualny MAC. - W trybie symulacji zaobserwuj pakiety HSRP Hello — wysyłane co 3 sekundy domyślnie. Zawierają informacje o priorytecie, stanie i adresie VIP.
- W sprawozdaniu udokumentuj czas przełączenia (liczbę utraconych pakietów ping) oraz wyjaśnij, dlaczego adres VIP jest kluczowy dla ciągłości działania sieci.
Koncept Virtual IP (VIP) w protokole HSRP polega na przypisaniu wirtualnego adresu IP i MAC do grupy standby, który jest aktywny na urządzeniu active router i przenoszony w przypadku awarii na router standby bez zmiany konfiguracji na stacjach klienckich — brama domyślna wstępnie skonfigurowana na każdym hoście pozostaje niezmieniona. Z perspektywy ciągłości biznesowej, użytkownicy końcowi nie muszą modyfikować swojej konfiguracji IP/gateway w momencie awarii fizycznego routera, ponieważ ruch jest przejmowany przez VIP działający na standby router — oznacza to zero-touch recovery i brak przestojów warstwy 3 dla aplikacji biznesowych. W kontekście HSRP Cisco, mechanizm preempt pozwala routerowi o wyższym priorytecie na przejęcie roli active po resecie lub rekonwalescencji, a hello timer (domyślnie co 3 sekundy) zapewnia szybkie wykrycie awarii (holdtime = 10 sekund), co w praktyce oznacza przełączenie w ciągu około 10-15 sekund — wystarczające dla większości aplikacji, ale nie dla time-sensitive VoIP, gdzie rekomendowany jest HSRP z track interface i reduced hold timer.
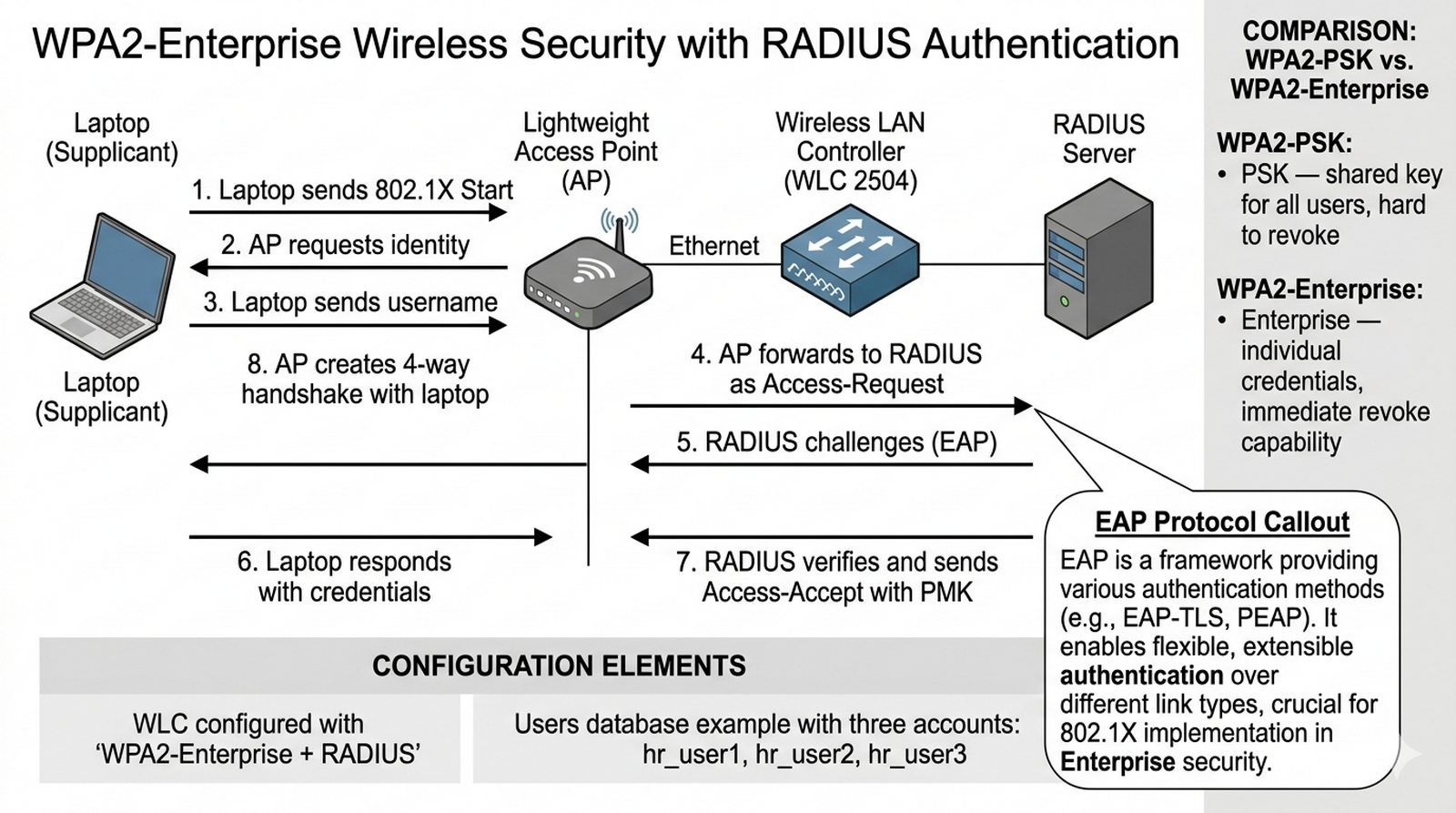
Wykład 7 Sieci bezprzewodowe, standard 802.1X, uwierzytelnianie promieniowe (RADIUS).
Firma rezygnuje z prostych haseł współdzielonych (PSK) w sieci Wi-Fi na rzecz uwierzytelniania opartego na kontach użytkowników. Twoim zadaniem jest konfiguracja kontrolera WLC (Wireless LAN Controller) oraz serwera RADIUS. Pracownicy działu HR mają logować się do osobnej sieci bezprzewodowej przy użyciu swoich indywidualnych poświadczeń. Musisz zapewnić, że tylko autoryzowani użytkownicy z bazy danych serwera RADIUS otrzymają dostęp do zasobów sieciowych przez punkt dostępowy Lightweight AP.
- Dodanie kontrolera WLC 2504 oraz serwera (RADIUS-PT) do topologii.
- Konfiguracja serwera RADIUS (Service: AAA) i dodanie klienta WLC (Shared Secret).
- Stworzenie bazy użytkowników na serwerze RADIUS.
- Konfiguracja WLAN na kontrolerze WLC z zabezpieczeniem WPA2-Enterprise.
- Przypisanie serwera RADIUS jako Authentication Server dla danego WLAN.
- Przyłączenie Lightweight AP do kontrolera i rozgłaszanie SSID.
- Konfiguracja Laptopa-PT do połączenia z siecią Wi-Fi przy użyciu loginu i hasła.
- Weryfikacja procesu uwierzytelniania w logach serwera RADIUS.
- Sprawdzenie statusu klienta w panelu kontrolnym WLC (GUI).
- Testowanie blokady dostępu dla nieprawidłowych poświadczeń.
- Udokumentowanie korzyści z centralnego zarządzania kluczami szyfrującymi.
Client Name: WLC_Controler
Shared Secret: cisco123
User: pracownik1 Pass: tajnehaslo
- WLC (Wireless LAN Controller) 2504 wymaga konfiguracji przez interfejs webowy. Po podłączeniu do sieci otwórz przeglądarkę na PC i wpisz adres IP kontrolera (domyślnie https://192.168.1.100).
- Na serwerze RADIUS włącz usługę AAA (Authentication, Authorization, Accounting) w zakładce Services. To centralna baza użytkowników dla uwierzytelniania Wi-Fi.
- W konfiguracji RADIUS dodaj klienta WLC: wpisz nazwę (np. WLC_Controller), adres IP kontrolera oraz Shared Secret (np. cisco123). Klucz musi być identyczny po obu stronach.
- Utwórz bazy użytkowników na serwerze RADIUS: minimum 3 konta (np. hr_user1, hr_user2, hr_user3) z hasłami. Każdy użytkownik reprezentuje pracownika działu HR.
- Na kontrolerze WLC utwórz nową WLAN: zakładka WLANs → Create New. Wybierz profil SSID (np. HR_WiFi) i włącz zabezpieczenie WPA2-Enterprise z RADIUS jako serwerem uwierzytelniania.
- W ustawieniach WLAN na WLC przypisz serwer RADIUS (podaj IP serwera AAA) i wspólny klucz (Shared Secret). Bez tego WLC nie będzie mógł przekazać credentials do RADIUS.
- Podłącz Lightweight AP do kontrolera WLC przez port Ethernet. AP automatycznie pobierze konfigurację z kontrolera (proces dwuetapowy: join, configure).
- Na laptopie skonfiguruj kartę Wi-Fi: wybierz SSID "HR_WiFi", ustaw zabezpieczenie na WPA2-Enterprise i wprowadź login oraz hasło użytkownika z bazy RADIUS.
- Sprawdź logi serwera RADIUS — powinny zawierać komunikaty o próbach uwierzytelniania: Access-Request (żądanie), Access-Accept (akceptacja) lub Access-Reject (odmowa).
- W panelu kontrolnym WLC (GUI) sprawdź status klienta bezprzewodowego — powinien pokazywać Connected, protokół szyfrowania AES oraz adres IP przypisany przez DHCP.
- Przetestuj blokadę: wprowadź błędne hasło na laptopie — próba połączenia powinna się nie powieść. Sprawdź, czy w logach RADIUS pojawił się Access-Reject.
- WPA2-Enterprise wykorzystuje protokół EAP (Extensible Authentication Protocol) do negocjacji poświadczeń. Każdy użytkownik ma unikalny klucz szyfrujący (PMK), co jest bezpieczniejsze od wspólnego klucza PSK.
- W sprawozdaniu wyjaśnij przewagę WPA2-Enterprise nad PSK — PSK jest wspólne dla wszystkich, wyciek klucza oznacza kompromitację całej sieci. Enterprise zapewnia indywidualne poświadczenia i możliwość natychmiastowego odebrania dostępu.
WPA2-Enterprise wykorzystuje autentykację RADIUS (802.1X/EAP) z certyfikatami lub kartami Smart Card, gdzie każdy użytkownik otrzymuje unikalne credentials, co pozwala na accountability i revoke dostępu bez zmiany PSK na wszystkich urządzeniach — w przeciwieństwie do WPA2-PSK, gdzie wspólny pre-shared key jest współdzielony między wszystkimi użytkownikami i jeśli zostanie skompromitowany, attacker uzyskuje dostęp do całej sieci bez możliwości identyfikacji sprawcy. Protokół EAP (Extensible Authentication Protocol) w procesie negocjacji połączenia bezprzewodowego definiuje sekwencję: supplicant (klient WiFi) inicjuje 802.1X, switch AP przekazuje żądanie do serwera RADIUS, EAP method (np. PEAP, TTLS) negocjuje autentykację, a po success serwer RADIUS wysyła klucze sesyjne (PMK) do AP i klienta, które służą do tworzenia pary 4-way handshake dla encryption. W sieciach korporacyjnych ze sprzętem Cisco, rekomendowana konfiguracja obejmuje WPA2-Enterprise z serwerem RADIUS (np. Cisco ISE, FreeRADIUS) i certyfikatami EAP-TLS dla najwyższego poziomu bezpieczeństwa.
Wykład 4 Komunikacja IP, protokół SCCP/SIP, Voice VLAN.
Wdrażasz system telefonii IP w nowym biurze. Twoim zadaniem jest konfiguracja routera brzegowego jako centrali telefonicznej (Cisco Unified Communications Manager Express). Musisz wydzielić osobny VLAN dla ruchu głosowego, skonfigurować usługę DHCP dla telefonów (opcja 150) oraz przypisać numery wewnętrzne do aparatów IP Phone. Sukcesem będzie realizacja połączenia głosowego między dwoma telefonami i weryfikacja poprawności wyświetlania numerów na ekranach urządzeń.
- Użycie routera 2811 (wspiera Voice) i przełącznika 2960.
- Konfiguracja Voice VLAN na portach switcha połączonych z telefonami.
- Ustawienie DHCP Pool z opcją "option 150 ip [adres_routera]".
- Włączenie usługi "telephony-service" na routerze.
- Zdefiniowanie maksymalnej liczby telefonów i linii (max-dn, max-ephones).
- Stworzenie wpisów "ephone-dn" z numerami telefonów (np. 101, 102).
- Powiązanie fizycznych telefonów (ephone) z numerami linii (button).
- Zasilanie telefonów (Power Adapter lub PoE w switchu).
- Testowanie wybierania numeru i weryfikacja statusu "Connected".
- Analiza ruchu RTP w trybie symulacji (pakiety głosowe).
- Dokumentacja znaczenia Voice VLAN dla jakości rozmów.
Router(config-telephony)# max-dn 5
Router(config-telephony)# ip source-address 192.168.10.1 port 2000
Router(config)# ephone-dn 1
Router(config-ephone-dn)# number 101
- Router 2811 (lub 2901/2911 z odpowiednim pakietem IP Base) jest wymagany, ponieważ obsługa Voice jest dostępna tylko na routerach z odpowiednim oprogramowaniem. Upewnij się, że wybrany router wspiera CME.
- Voice VLAN na switchu wymaga konfiguracji portu w trybie trunk lub dostępu z tagiem. Dla uproszczenia użyj trybu dostępu z dodatkowym VLAN głosowym:
switchport voice vlan [numer_vlan]. - DHCP dla telefonów IP wymaga opcji 150 (TFTP Server), która wskazuje adres routera z usługą CME. Składnia w puli DHCP:
option 150 ip [adres_routera]. - Włącz usługę telephony-service:
telephony-servicew trybie konfiguracji globalnej. To uruchomi serwer CME na routerze. - Skonfiguruj parametry usługi:
max-dn 5(maksymalnie 5 numerów telefonów) orazmax-ephones 5(maksymalnie 5 fizycznych telefonów). - Ustaw adres źródłowy dla telefonów:
ip source-address [IP_routera] port 2000. Telefony będą się rejestrować na tym adresie i porcie. - Utwórz numery telefoniczne (ephone-dn): każdy wpis to alias między portem a numerem. Przykład:
ephone-dn 1→number 101. Powtórz dla numeru 102. - Powiązanie fizycznego telefonu z numerem wymaga wpisu w ephone:
ephone 1→mac-address [MAC_telefonu]→button 1:1. Numer po dwukropku to numer ephone-dn. - Telefony IP w Packet Tracer wymagają zasilania. Jeśli switch nie jest PoE, włóż do telefonu Power Adapter (Desktop → Power Module).
- Telefony rejestrują się automatycznie po otrzymaniu DHCP z opcją 150. Ekran telefonu powinien pokazać przypisany numer (np. "101"). Czekaj cierpliwie na rejestrację — może to zająć do 30 sekund.
- Przetestuj połączenie: podnieś słuchawkę telefonu 1, wybierz numer 102, naciśnij przycisk Dial. Obserwuj status "Connected" na ekranach obu telefonów.
- W trybie symulacji zaobserwuj pakiety RTP (Real-time Transport Protocol) — przesyłają one strumień głosowy między telefonami. Zwróć uwagę na porty używane przez RTP (dynamiczne porty UDP > 10000).
- Voice VLAN zapewnia odrębność ruchu głosowego od danych, co jest kluczowe dla QoS. W sprawozdaniu wyjaśnij, dlaczego ruch głosowy jest wrażliwy na opóźnienia i jitter.
Ruch głosowy VoIP jest niezwykle wrażliwy na opóźnienia i jitter — każda millisekunda ma znaczenie dla naturalności konwersacji, a standardy ITU-T G.114 definiują maksymalne opóźnienie 150ms one-way dla satysfakcjonującej jakości. Izolacja ruchu głosowego w dedykowanym Voice VLAN (np. VLAN 100) w połączeniu z mechanizmami QoS na switchu (np. CoS 5 dla VoIP) zapewnia, że pakiety głosowe są obsługiwane z najwyższym priorytetem i nie są kolejkowane za paketami danych intensywnie obciążającymi łącze. Gdy łącze zostanie nasycone ruchem HTTP/Bulk data bez QoS, bufory kolejkowania przepełniają się, pakiety głosowe są odrzucane lub opóźniane, co skutkuje charakterystycznymi artefaktami audio (przeskoki, echo) i nieczytelnością rozmowy. W architekturze Cisco Voice, konfiguracja Auto QoS lub ręczna konfiguracja priority queue na interfejsach access-switchy stanowi obowiązkowy element wdrożenia VoIP w środowisku produkcyjnym.
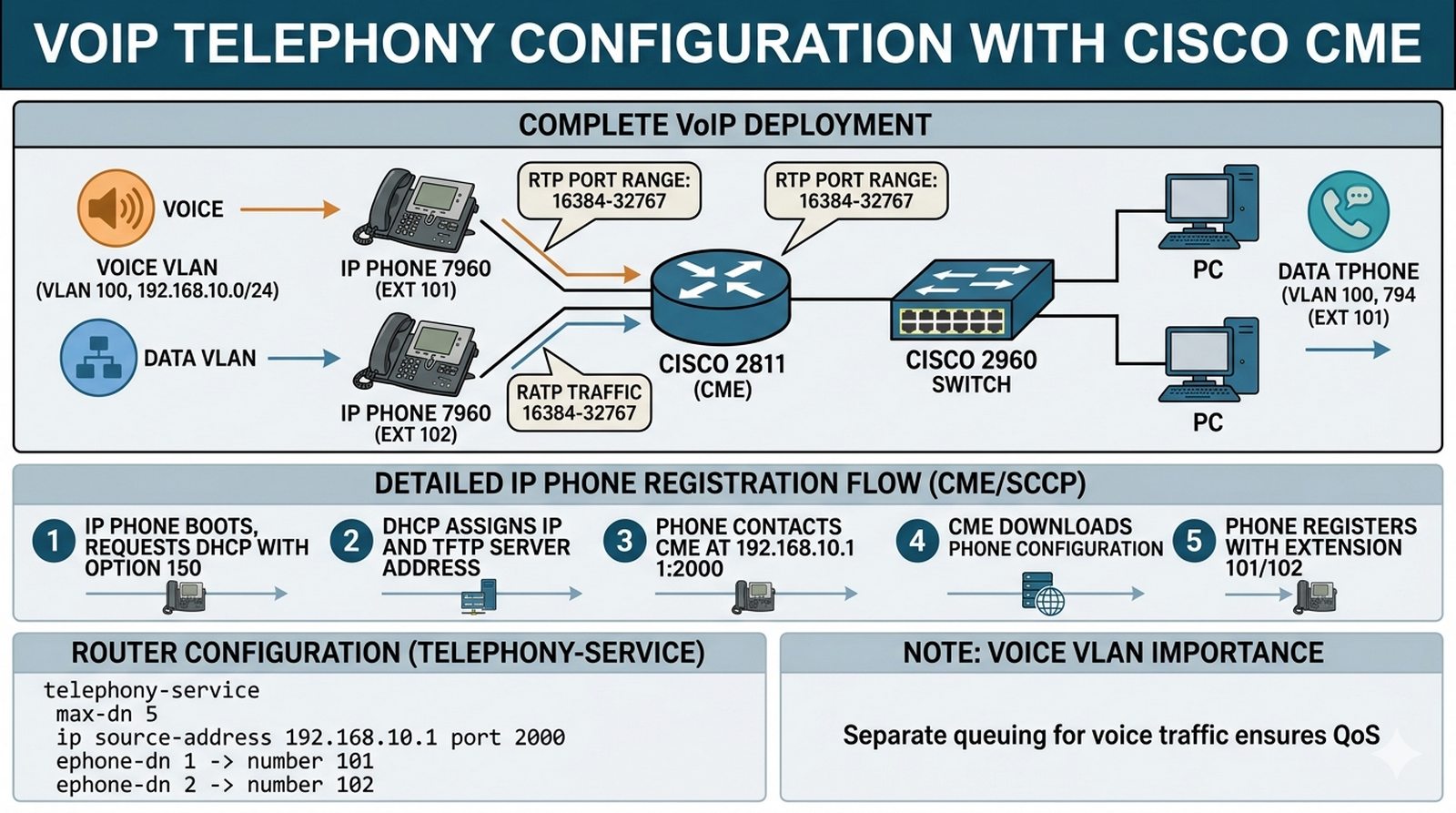
Wykład 8-10 Przemysł 4.0, urządzenia brzegowe IoT, monitorowanie środowiskowe.
Serwerownia firmy wymaga stałego monitoringu temperatury i wilgotności. Twoim zadaniem jest stworzenie inteligentnego systemu nadzoru opartego na urządzeniach IoT. Musisz połączyć czujniki temperatury i wilgotności do bramy IoT (Home Gateway), a następnie skonfigurować algorytmy, które automatycznie uruchomią klimatyzator lub wentylator po przekroczeniu krytycznych wartości. Całość systemu musi być dostępna dla administratora przez panel WWW, umożliwiając zdalny podgląd stanu serwerowni w czasie rzeczywistym.
- Dodanie Home Gateway (IoT Gateway) do topologii.
- Dodanie czujników: Temperature Sensor, Humidity Sensor.
- Dodanie elementów wykonawczych: Fan (Wentylator) lub AC (Klimatyzator).
- Połączenie urządzeń IoT do bramy (bezprzewodowo lub kablem IoT).
- Konfiguracja serwera IoT na bramie.
- Zalogowanie się do panelu kontrolnego IoT z tabletu lub PC (adres IP bramy).
- Stworzenie reguły (Condition): "Jeśli temperature > 25, to włącz Fan".
- Weryfikacja działania automatyki przez podgrzanie czujnika (Environment Monitor).
- Dokumentacja odczytów na wykresach w panelu IoT.
- Analiza protokołu komunikacji urządzeń IoT (np. MQTT lub HTTP).
- Zabezpieczenie dostępu do bramy IoT silnym hasłem.
Condition Name: Cooling_Trigger
If Temp_Sensor Value >= 30
Then set Ceiling_Fan to High
- Home Gateway w Packet Tracer znajdziesz w kategorii "End Devices" → "IoT". To centralne urządzenie zarządzające ekosystemem IoT w sieci lokalnej.
- Podłącz czujniki (Temperature Sensor, Humidity Sensor) do bramy IoT przez Connections → IoT. Możesz też użyć połączenia bezprzewodowego (Wireless) zgodnie z wymaganiami zadania.
- Na bramie IoT włącz usługę IoT Server w zakładce Services. To serwer centralny przyjmujący dane z czujników i przetwarzający reguły automatyzacji.
- Elementy wykonawcze (Fan, AC, Lights) dodaj do topologii i połącz z bramą. Po połączeniu urządzenia pojawią się w panelu IoT jako gotowe do konfiguracji.
- Otwórz panel IoT przez przeglądarkę na PC lub tablecie: wpisz adres IP bramy IoT. Interfejs webowy pokazuje wszystkie podłączone urządzenia i ich aktualne wartości.
- Tworzenie reguły automatyzacji: w panelu IoT wybierz "Add Rule" lub "Automation". Zdefiniuj warunek (IF) i akcję (THEN). Przykład: IF Temperature >= 30 THEN Ceiling_Fan = High.
- Reguły mogą być bardziej złożone — np. IF Temperature >= 30 AND Humidity >= 70 THEN AC = ON. Używaj logiki AND/OR do łączenia warunków.
- Symulacja warunków środowiskowych: w Packet Tracer narzędzie Environment (ikona "E" na pasku narzędzi) pozwala ręcznie zmieniać temperaturę i wilgotność w "pomieszczeniu".
- Zmień temperaturę w narzędziu Environment na wartość powyżej progu reguły i zaobserwuj automatyczne włączenie wentylatora lub klimatyzatora w panelu IoT.
- Wykresy danych: panel IoT prezentuje historię odczytów czujników w formie wykresów liniowych. To przydatne do dokumentacji zmian parametrów w czasie.
- Protokoły komunikacji: urządzenia IoT w Packet Tracer komunikują się przez protokoły HTTP lub MQTT. Sprawdź w trybie symulacji, jaki protokół jest używany.
- Zabezpieczenie IoT: zmień domyślne hasło administratora bramy IoT. W produkcji urządzenia IoT są często celem ataków ze względu na słabe zabezpieczenia.
- W sprawozdaniu opisz korzyści z automatyzacji IoT w serwerowni — ciągły monitoring bez interwencji człowieka, szybka reakcja na przekroczenie progów. Wymień też zagrożenia: podatność na ataki, brak szyfrowania.
Automatyzacja IoT w infrastrukturze krytycznej przynosi korzyści w postaci predictive maintenance (prognozowanie awarii na podstawie metryk sensorowych), real-time monitoring parametrów środowiskowych (temperatura, wilgotność, zużycie energii), oraz automatycznej reakcji (np. wyłączenie klimatyzacji przy przekroczeniu progu temperaturowego w serwerowni) bez interwencji człowieka. Z drugiej strony, podłączenie urządzeń IoT bez izolacji do sieci korporacyjnej stanowi poważne zagrożenie bezpieczeństwa — urządzenia te często mają słabe zabezpieczenia (default credentials, brak szyfrowania), są podatne na firmware vulnerabilities, i w przypadku kompromitacji mogą stanowić wektor lateral movement do sieci wewnętrznej (np. smart termometr w serwerowni jako punkt wejścia dla atakującego). Best practice w Cisco architecture zakłada izolację IoT w dedykowanym VLAN z firewall'em lub ACL filtrującym dostęp do sieci zarządzania, oraz monitoring urządzeń IoT przez NMS z alertami na nowe nieautoryzowane MAC adresy (np. IEEE 802.1X fails for IoT, wtedy MAC Authentication Bypass z policies).
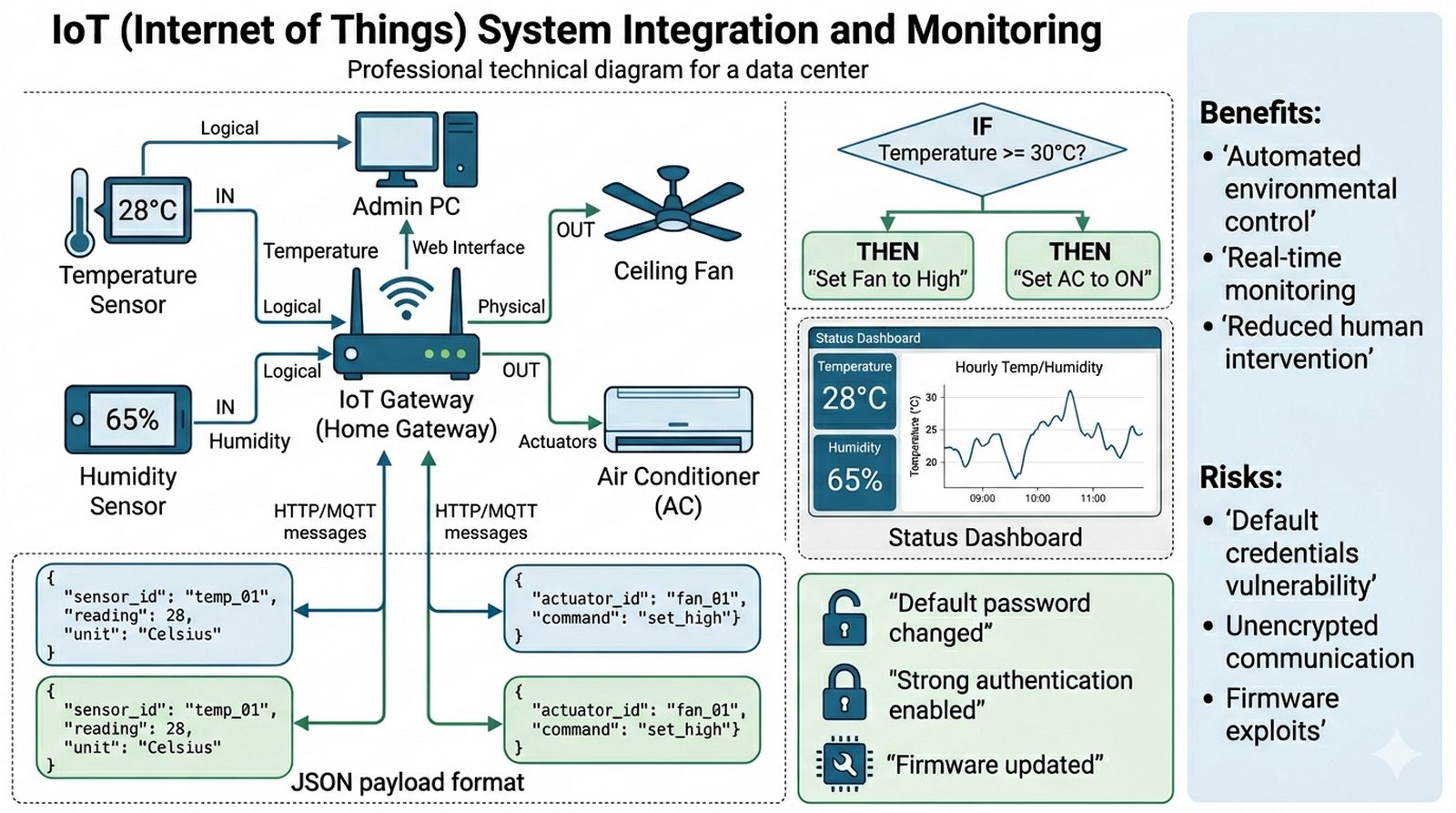
Wykład 1 Architektura sieciowa, tunele L3, wirtualizacja łącz.
Firma otworzyła nowy oddział w innym mieście. Oba oddziały mają dostęp do Internetu, ale muszą wymieniać dane w sposób niewidoczny dla użytkownika (tak jakby były w jednej sieci lokalnej). Twoim zadaniem jest stworzenie wirtualnego tunelu GRE (Generic Routing Encapsulation) między routerami brzegowymi obu oddziałów. Tunel musi umożliwić przesyłanie ruchu z sieci LAN1 do sieci LAN2 przez niezaufaną sieć publiczną (Internet), wykorzystując routing statyczny skierowany do interfejsu tunelowego.
- Użycie dwóch routerów połączonych przez symulowaną chmurę Internetu.
- Adresacja interfejsów publicznych (WAN) i prywatnych (LAN).
- Stworzenie wirtualnego interfejsu Tunnel 0 na obu routerach.
- Ustawienie źródła (tunnel source) i celu (tunnel destination) tunelu.
- Nadanie adresacji IP dla końcówek tunelu (np. 10.255.255.1 i .2).
- Konfiguracja routingu statycznego dla sieci zdalnej przez tunel.
- Weryfikacja łączności (ping) między komputerami w obu oddziałach.
- Użycie polecenia "traceroute" i analiza ścieżki (brak przeskoków pośrednich z Internetu).
- Analiza enkapsulacji pakietu GRE (dodatkowy nagłówek IP).
- Udokumentowanie MTU tunelu i problemu fragmentacji pakietów.
- Weryfikacja statusu tunelu poleceniem "show ip interface brief".
Router(config-if)# ip address 10.255.255.1 255.255.255.252
Router(config-if)# tunnel source g0/0
Router(config-if)# tunnel destination 200.0.0.1
Router(config)# ip route 192.168.2.0 255.255.255.0 tunnel 0
- Topologia tunelu GRE wymaga dwóch routerów połączonych przez symulowaną sieć Internet (np. drugi router i cloud). Między routerami musi działać łączność IP (ping między interfejsami WAN).
- Na obu routerach skonfiguruj interfejsy WAN z publicznymi adresami IP (np. 200.0.0.1/30 i 200.0.0.2/30). Te adresy będą używane jako źródło i cel tunelu.
- Tworzenie interfejsu tunelowego:
interface tunnel 0na obu routerach. Tunel to wirtualny interfejs, który enkapsuluje pakiety w dodatkowy nagłówek IP. - Adresacja tunelu: na routerze R1 ustaw
ip address 10.255.255.1 255.255.255.252, na R2ip address 10.255.255.2 255.255.255.252. Te adresy są "prywatne" dla tunelu. - Konfiguracja źródła i celu tunelu:
tunnel source g0/0(interfejs wyjściowy) oraztunnel destination [publiczny_IP_routera]. Kierunek musi być wzajemny — źródło jednego to cel drugiego. - Routing statyczny przez tunel: na R1 dodaj trasę do sieci LAN2:
ip route 192.168.2.0 255.255.255.0 tunnel 0. Na R2 analogicznie do sieci LAN1. - Weryfikacja: ping z komputera w LAN1 do komputera w LAN2 powinien działać. Polecenie
traceroutepokaże, że pakiety przechodzą przez interfejs tunelowy (10.255.255.x). - W trybie symulacji zaobserwuj enkapsulację GRE: pakiet oryginalny (LAN → LAN) jest owinięty w nagłówek GRE, a następnie w nagłówek IP z adresami publicznymi. To pokazuje zasłonięcie ruchu prywatnego przez sieć publiczną.
- MTU tunelu GRE to domyślnie 1476 bajtów (1500 - 24 bajty nagłówka GRE). Duże pakiety mogą być fragmentowane. Sprawdź wartość poleceniem
show interface tunnel 0. - GRE nie szyfruje danych — ruch jest przesyłany tekstem jawnym. W produkcji tunel GRE owija się w IPSec (GRE over IPSec) dla bezpieczeństwa.
- Status tunelu zweryfikuj poleceniem
show ip interface brief— interfejs Tunnel powinien mieć status "up" i "up". Jeśli tunel jest "up/down", sprawdź łączność między interfejsami WAN. - W sprawozdaniu wyjaśnij, dlaczego interfejs tunelowy jest wirtualny — nie ma fizycznego portu, pakiety są enkapsulowane i przesyłane przez sieć publiczną. Opisz też korzyść GRE dla protokołów multicast.
Interfejs fizyczny tunelu GRE jest reprezentowany przez wirtualny interfejs Tunnel, który enkapsuluje pakiety wewnątrz nagłówka IP z protokołem GRE (IP protocol 47), natomiast interfejs tunelowy logicznie działa jak interfejs warstwy 3 — ma własny adres IP, maskę i protokół routingu, co pozwala na traktowanie tunelu jako medium transportowego dla protokołów routingu. GRE jest szczególnie przydatny do przesyłania pakietów multicast w sieciach, gdzie protokoły routingu (np. OSPF, EIGRP) używają multicast do neighbor discovery i wymiany LSA — w standardowym podejściu router enkapsuluje multicast packet w unicast GRE i przesyła do drugiego końca tunelu (co jest widoczne w tabeli routingu i działa z OSPF w trybie Point-to-Point GRE). W sieciach produkcyjnych, GRE jest często używany w połączeniu z IPsec (GRE over IPsec) dla szyfrowania ruchu przez niezaufane sieci — nagłówek GRE jest dodawany jako pierwszy (dla obsługi multicast), a następnie całość jest szyfrowana przez IPsec ESP/AES, co zapewnia zarówno elastyczność (obsługa protokołów warstwy 3, multicast) jak i bezpieczeństwo (szyfrowanie payloadu).
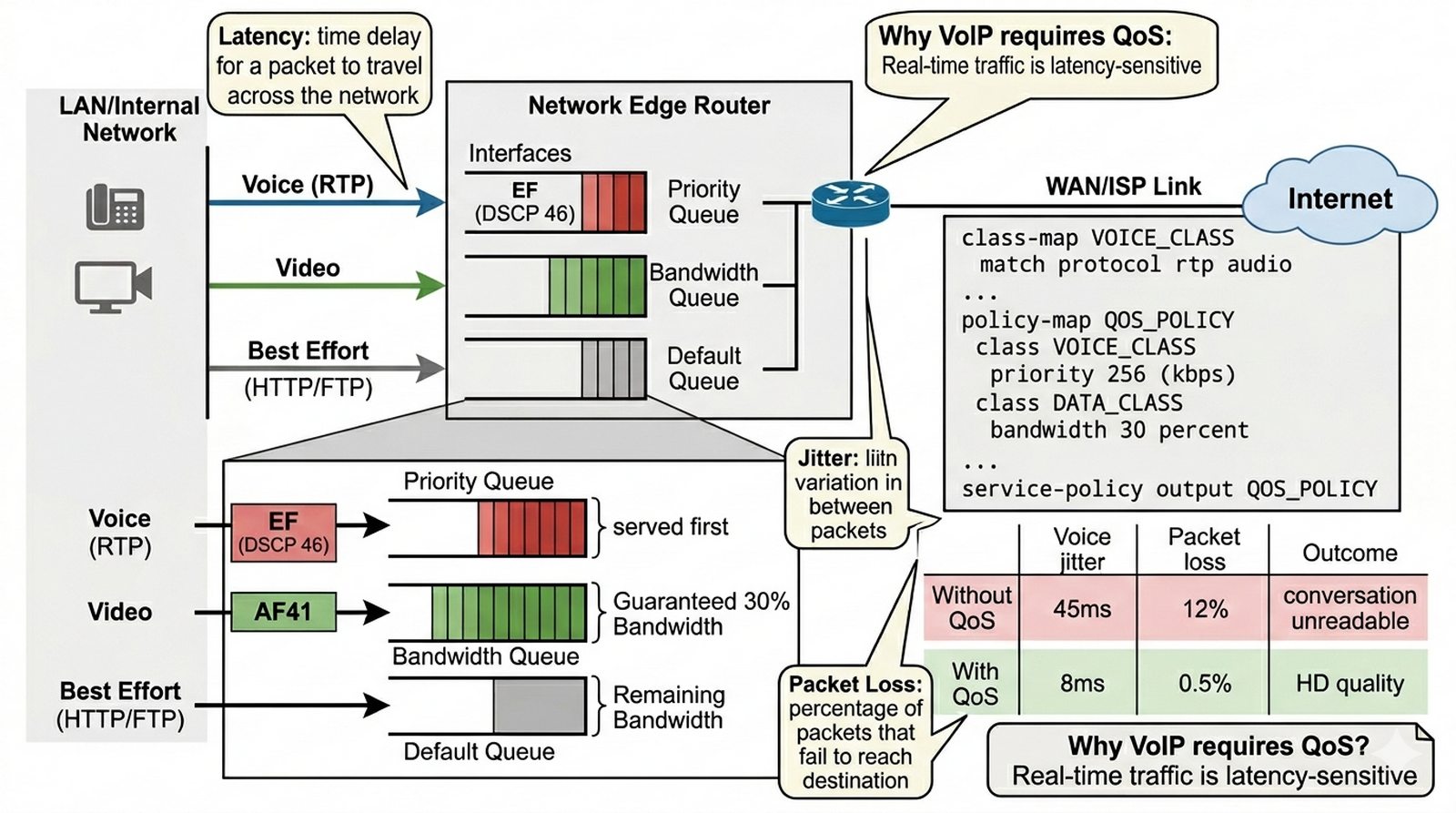
Wykład 10 Zarządzanie pasmem, mechanizmy QoS, klasyfikacja i znakowanie (DSCP).
Łącze internetowe firmy jest często zapychane przez pobieranie dużych plików, co powoduje rwanie rozmów VoIP oraz opóźnienia w systemach terminalowych. Twoim zadaniem jest wdrożenie mechanizmu jakości usług (QoS) na routerze wyjściowym. Musisz sklasyfikować ruch głosowy jako krytyczny, przypisać mu najwyższy priorytet i zagwarantować minimalne pasmo, natomiast ruch typu HTTP/FTP ograniczyć w momentach przeciążenia. Dzięki temu usługi czasu rzeczywistego będą działać płynnie nawet przy pełnym obciążeniu łącza.
- Stworzenie class-map dla różnych typów ruchu (Voice, Data).
- Klasyfikacja ruchu Voice na podstawie ACL (porty RTP) lub typu protokołu.
- Stworzenie policy-map i przypisanie akcji (priority, bandwidth).
- Zastosowanie polityki QoS na interfejsie wychodzącym (service-policy output).
- Znakowanie pakietów wartościami DSCP (np. EF dla głosu).
- Weryfikacja działania QoS poleceniem "show policy-map interface".
- Generowanie dużego ruchu (np. FTP transfer) i jednoczesny test pingu do telefonu.
- Analiza liczników "matches" i "drops" w statystykach polityki.
- Udokumentowanie struktury policy-map w sprawozdaniu.
- Sprawdzenie wpływu QoS na opóźnienia (jitter) – obserwacja w trybie symulacji.
- Opisanie mechanizmu Low Latency Queuing (LLQ).
Router(config-cmap)# match protocol rtp audio
Router(config)# policy-map QOS_POLICY
Router(config-pmap-c)# class VOICE_CLASS
Router(config-pmap-c)# priority 256
Router(config-if)# service-policy output QOS_POLICY
- QoS w Packet Tracer jest częściowo ograniczony, ale podstawowe komendy MQC (Modular QoS CLI) działają na routerach serii 2800 i 2900. Upewnij się, że używasz routera wspierającego QoS.
- Klasyfikacja ruchu zaczyna się od class-map:
class-map [match-any|match-all] NAZWA. Słowo kluczowe match-any oznacza, że wystarczy spełnienie jednego warunku. - Dla ruchu głosowego użyj klasyfikacji protokołu RTP:
match protocol rtp audio. RTPaudio rozpoznaje pakiety VoIP po portach UDP z zakresu 16384-32767. - Alternatywnie sklasyfikuj ruch VoIP przez DSCP value:
match input-interface [interfejs]lubmatch access-group(używając ACL dla rozpoznanych portów). - Tworzenie policy-map:
policy-map NAZWA. Następnie przypisz klasę akcją:class VOICE_CLASSi określ akcję priorytetową:priority 256(kbps). - Akcja
priority(Low Latency Queuing - LLQ) gwarantuje kolejkę priorytetową dla ruchu głosowego. Pakiety VoIP są obsługiwane przed innymi, minimalizując opóźnienia. - Alternatywnie dla ruchu danych użyj
bandwidth [procent]lubbandwidth [kbps]. To przydziela gwarantowane pasmo w kolejkach WFQ/WRR. - Znakowanie DSCP wykonuje się w tym samym policy-map:
set dscp efdla ruchu głosowego (EF = Expedited Forwarding, DSCP 46). Dla telemetrii sieciowej użyj AF41 itp. - Zastosuj politykę na interfejsie wychodzącym:
service-policy output NAZWA. QoS działa na ruchu opuszczającym interfejs, nie przychodzącym (poza pewnymi wyjątkami). - Generuj ruch FTP/HTTP jednocześnie z testem głosowym, aby symulować przeciążenie łącza. Użyj narzędzi transferu plików na PC lub symuluj wielokrotne pingi.
- Weryfikuj QoS:
show policy-map interface [interfejs]. Pokazuje liczniki matches, drops, queue-depth. Obserwuj, czy ruch głosowy ma mniej drops niż ruch danych. - W trybie symulacji zweryfikuj, czy pakiety VoIP są oznakowane odpowiednim DSCP. Kliknij na pakiet → PDU Details → Layer 3 → pole DSCP powinno pokazywać wartość EF.
- W sprawozdaniu wyjaśnij pojęcia: latency (opóźnienie stałe), jitter (zmiennność opóźnienia), packet loss (utrata pakietów). Opisz, dlaczego ruch głosowy wymaga niskiego jittera — zbyt duże opóźnienie powoduje, że rozmowa staje się niezrozumiała.
Opóźnienie (latency) to czas propagacji pakietu od nadawcy do odbiorcy, mierzony w milisekundach, jitter to zmienność tego opóźnienia między kolejnymi pakietami (np. pakiet A ma 20ms, pakiet B ma 50ms = 30ms jitter), a utrata pakietów (packet loss) to procent pakietów, które nie dotarły do celu — w kontekście VoIP, utrata powyżej 1% powoduje zauważalne artefakty audio. W sieciach hybrydowych (głos + dane), mechanizmy QoS są niezbędne, ponieważ ruch danych (HTTP, FTP, SMTP) jest tolerancyjny na opóźnienia i jitter, ale bursty traffic (np. backup over WAN) potrafi wygenerować kolejki, które opóźniają pakiety VoIP powyżej akceptowalnych progów — bez QoS, VoIP jest traktowany jako Best Effort (DSCP 0), co oznacza, że przegrywa konkurencję o bandwidth z każdym innym flow. Cisco QoS model (modular QoS CLI — MQC) pozwala na klasyfikację ruchu (match by ACL, DSCP, CoS), tworzenie kolejki priorytetowej (priority queue) dla VoIP (np. DSCP EF — Expedited Forwarding dla ruchu RTP), i konfigurację gwarantowanego pasma dla klas biznesowych (voice, video, critical data) — w rezultacie VoIP ma gwarantowane pasmo nawet przy pełnym obciążeniu łącza.