Te zadania musisz wykonać z realnym środowisku sprzętowym albo skorzystać z wirtualizacji (VirtualBox, GNS3, EVE-NG itp)
Objętość sprawozdania ok. 15-20 stron A4 (Times New Roman 12 pkt, odstęp 1,5 wiersza, marginesy 2,5 cm), strona tytułowa (autor, temat, cel, zakres), szczegółowy opis zagadnienia teoretycznego, dokumentacja techniczna: schematy logiczne i fizyczne, ilustracje (fotografie infrastruktury w przypadku realnego sprzętu, zrzuty ekranu w przypadku symulatorów czy VM), tabele adresacji i zestawienia urządzeń, dokładny opis i uzasadnienie konfiguracji każdego z urządzeń, napotkane problemy i sposoby ich rozwiązania, spis treści, spis tabel i ilustracji, bibliografia techniczna.
Jeśli dołączasz fotografie czy konfiguracje realnego sprzętu, środowiska pamiętaj o RODO - usuń dane identyfikacyjne czy podobne.
Wysyłaj w postaci opisu w PDF plus ewentualne załączniki (np. konfiguracje, listingi), całość możesz spakować do ZIP.
Spis zadań laboratoryjnych
- Zadanie 1: Konfiguracja usług DHCP i DNS w systemie RouterOS
- Zadanie 2: Zarządzanie czasem i synchronizacja NTP
- Zadanie 3: Bezpieczny dostęp zdalny (SSH) i hardening routera
- Zadanie 4: Implementacja tunelu VPN (Site-to-Site IPsec)
- Zadanie 5: Monitoring sieci za pomocą SNMP i Zabbix
- Zadanie 6: Centralizacja logów systemowych (Syslog)
- Zadanie 7: Wdrożenie serwera pocztowego (Postfix/Dovecot)
- Zadanie 8: Bezpieczeństwo poczty e-mail (SPF, DKIM, DMARC)
- Zadanie 9: Serwer plików Samba i integracja z Active Directory
- Zadanie 10: Udostępnianie zasobów dyskowych przez NFS i iSCSI
- Zadanie 11: Serwer WWW Nginx jako Reverse Proxy i Load Balancer
- Zadanie 12: Automatyzacja konfiguracji sieciowej za pomocą Ansible
- Zadanie 13: Wdrożenie klastra Kubernetes (K3s) w środowisku lab
- Zadanie 14: Diagnostyka i audyt bezpieczeństwa (Nmap/Wireshark)
- Zadanie 15: Wysoka dostępność usług i redundancja (VRRP)
Wykład 1 Zarządzanie adresacją IP, protokół DHCP, hierarchia DNS i rozwiązywanie nazw w sieciach lokalnych.
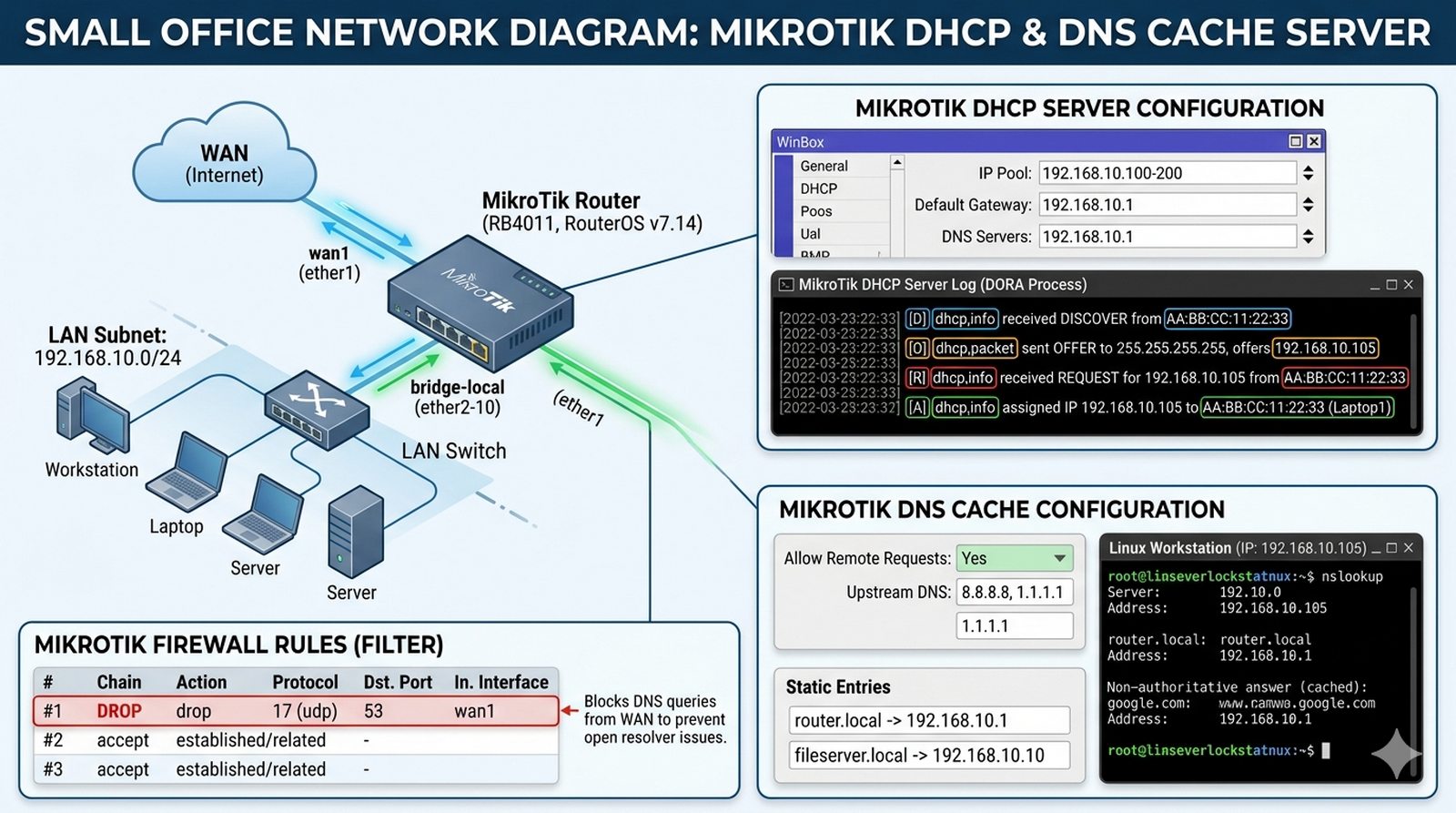
W nowo powstałym biurze firmy potrzeba zapewnić automatyczną konfigurację IP dla wszystkich stacji roboczych, aby użytkownicy mogli od razu pracować bez ręcznego wpisywania adresów i parametrów sieciowych. Administrator musi skonfigurować router MikroTik jako serwer DHCP, który przydziela adresy IP z puli 100-200 oraz automatycznie przekazuje bramę domyślną i serwery DNS. Jednocześnie router powinien pełnić rolę lokalnego serwera DNS z cache, aby przyspieszyć rozwiązywanie nazw domenowych używanych w sieci LAN i umożliwić definiowanie własnych nazw dla lokalnych usług, takich jak serwer plików czy drukarka sieciowa. Twoim zadaniem jest skonfigurować obie usługi na routerze MikroTik, przetestować ich działanie z klienta Linux oraz zabezpieczyć serwer DNS przed dostępem z sieci WAN. Na koniec musisz udokumentować proces DORA i zweryfikować rozpoznawanie nazw DNS z klienta Linux.
- Konfiguracja interfejsu LAN z adresem 192.168.10.1/24.
- Utworzenie puli adresowej (IP Pool) dla klientów: 192.168.10.100 - 192.168.10.200.
- Konfiguracja serwera DHCP na interfejsie LAN z czasem dzierżawy 12h.
- Zdefiniowanie sieci DHCP (Network) z bramą domyślną i serwerem DNS.
- Konfiguracja serwera DNS z włączoną opcją "Allow Remote Requests".
- Dodanie statycznego wpisu DNS dla nazwy "router.local" wskazującego na 192.168.10.1.
- Zabezpieczenie serwera DNS przed atakami z sieci WAN (Firewall drop input 53/udp).
- Weryfikacja tabeli dzierżaw (Leases) po podłączeniu klienta Linux.
- Sprawdzenie poprawności zapytania DNS przy użyciu polecenia 'nslookup' lub 'dig'.
- Udokumentowanie logów DHCP podczas procesu DORA.
- Konfiguracja rezerwacji adresu IP (Static Lease) dla konkretnego adresu MAC.
1. Przed rozpoczęciem konfiguracji upewnij się, że interfejs ether2 ma przypisany adres IP z odpowiednią maską (/24) i jest aktywny — status interfejsu w Winbox powinien być zielony.
2. W GNS3 uruchom klienta VPCS lub Docker Container z systemem Linux i połącz go z interfejsem ether2 routera — domyślnie klient powinien automatycznie otrzymać adres z procesu DORA.
3. Podczas konfiguracji puli DHCP (/ip pool) zdefiniuj zakres adresów zarezerwowanych dla urządzeń statycznych, np. serwery — aby uniknąć konfliktów adresacji.
4. Po skonfigurowaniu serwera DHCP sprawdź zakładkę "Leases" — adresy przypisane klientom pojawią się tam z etykietą "bound". Czerwony status serwera oznacza konflikt adresów lub brak adresu na interfejsie.
5. Serwer DNS skonfiguruj z dwoma zewnętrznymi serwerami rozwiązywania nazw (np. 8.8.8.8 i 1.1.1.1) jako zapasowymi — zwiększa to odporność na awarie.
6. Włącz opcję "Allow Remote Requests" w DNS tylko wtedy, gdy router pełni rolę serwera DNS dla sieci LAN — nigdy nie włączaj jej na interfejsie WAN.
7. Statyczne wpisy DNS dodawaj po zakończeniu konfiguracji usług, aby uniknąć problemów z propagacją ustawień.
8. Przed włączeniem firewalla na porcie 53/UDP od strony WAN przetestuj działanie DNS z sieci LAN — aby upewnić się, że reguła drop nie blokuje prawidłowego ruchu.
9. Do weryfikacji DNS używaj poleceń:
nslookup router.local (Windows) lub dig router.local (Linux) — zweryfikują one, czy lokalny wpis DNS jest rozpoznawany.10. Rezerwację adresu IP (Static Lease) skonfiguruj dla hosta, którego adres MAC poznasz z tabeli leases — pozwoli to przypisać stały adres do urządzenia bez ingerencji w konfigurację klienta.
11. Dokumentuj proces DORA w logach: uruchom Terminal w Winbox i użyj polecenia
/log print where topics~"dhcp" — zobaczysz komunikaty Discover, Offer, Request i Acknowledge.12. Po zakończeniu zadania wykonaj test łączności: ping z klienta do routera, ping do adresu zewnętrznego (np. 8.8.8.8) oraz weryfikację rozpoznawania nazw domen (np.
nslookup google.com).
Podczas realizacji zadania skonfigurowano podstawowe usługi sieciowe DHCP i DNS w systemie MikroTik RouterOS, które stanowią fundament sprawnego funkcjonowania sieci lokalnej. Poprawnie skonfigurowany serwer DHCP zapewnia automatyczną konfigurację stacji roboczych, eliminując problem błędnie wpisanych adresów IP i bram przez użytkowników końcowych. Rezerwacje adresów (Static Lease) pozwalają na przypisanie stałych adresów do urządzeń wymagających niezmiennej adresacji, takich jak serwery czy drukarki sieciowe. Serwer DNS pełniący funkcję cache znacząco przyspiesza rozwiązywanie nazw domenowych przez przechowywanie wyników zapytań lokalnie, co redukuje opóźnienia i obciążenie zewnętrznych serwerów DNS. Statyczne wpisy DNS umożliwiają definiowanie własnych nazw dla lokalnych usług, co ułatwia dostęp do zasobów firmowych bez konieczności pamiętania ich adresów IP. Zabezpieczenie serwera DNS przed dostępem z sieci WAN jest kluczowe dla bezpieczeństwa infrastruktury, ponieważ otwarty serwer DNS może być wykorzystany do ataków typu DNS amplification. Podsumowując, usługi DHCP i DNS są niezbędne do prawidłowego działania sieci, a ich poprawna konfiguracja i zabezpieczenie stanowią podstawę profesjonalnej administracji siecią.
Wykład 1 Znaczenie czasu systemowego w logowaniu zdarzeń, certyfikatach i bezpieczeństwie usług sieciowych.
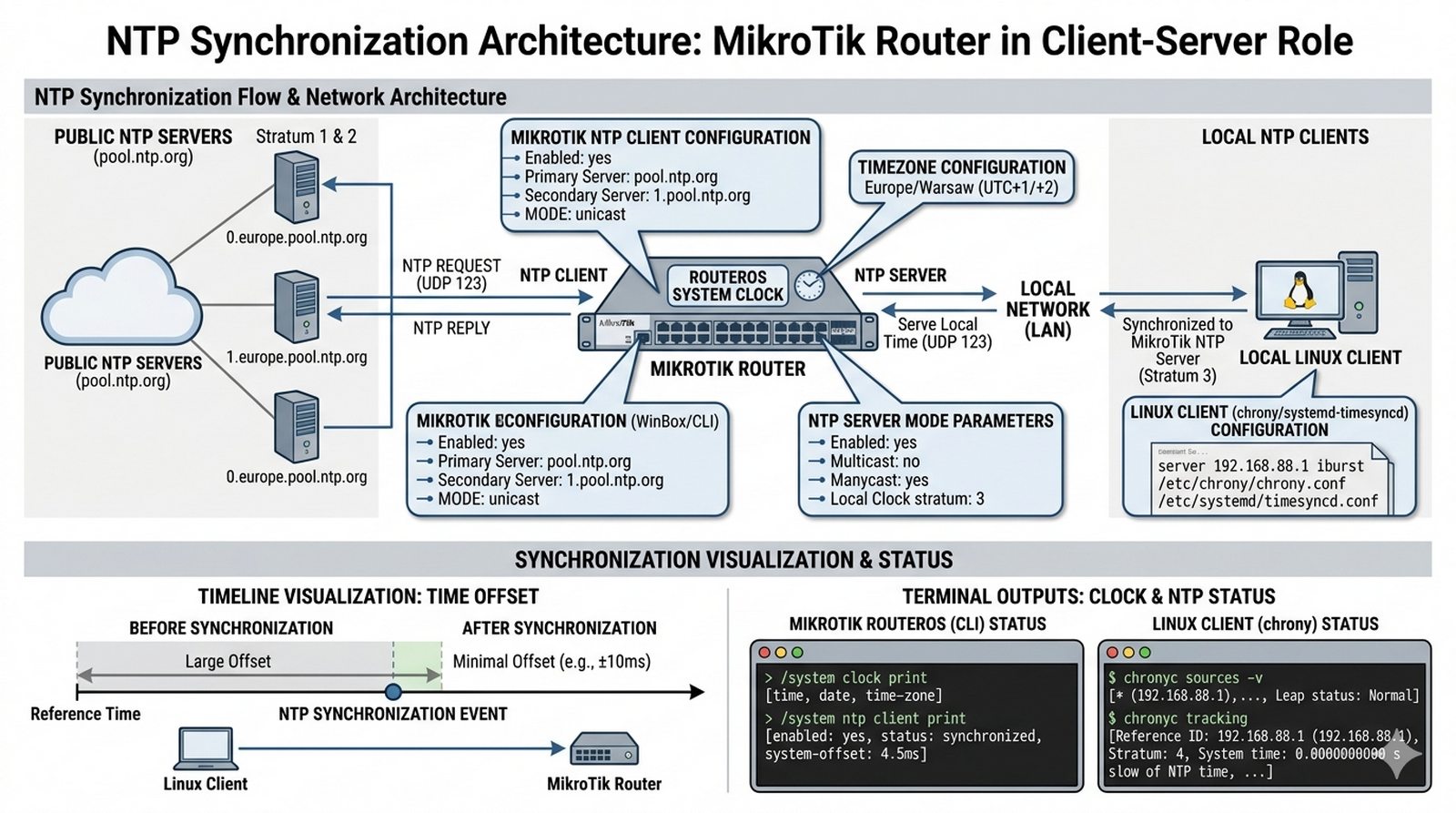
Prawidłowy czas systemowy na wszystkich urządzeniach sieciowych jest kluczowy dla bezpieczeństwa i diagnostyki — bez synchronizacji logi z różnych urządzeń nie dają się skorelować, a certyfikaty SSL/TLS mogą być odrzucane jako nieważne z powodu błędnych dat. Administrator musi skonfigurować router MikroTik jako klienta NTP synchronizującego się z publicznymi serwerami czasu (pool.ntp.org), a następnie uruchomić serwer NTP na tym routerze dla pozostałych urządzeń w sieci, takich jak serwery Linux czy przełączniki. Twoim zadaniem jest skonfigurować strefę czasową Europe/Warsaw, włączyć klienta i serwera NTP, a następnie zweryfikować poprawność synchronizacji na kliencie Linux oraz udokumentować offset czasu przed i po synchronizacji.
- Poprawna konfiguracja strefy czasowej (Timezone) dla Polski.
- Instalacja i aktywacja pakietu 'ntp' (jeśli wymagany w danej wersji ROS).
- Konfiguracja klienta SNTP z użyciem serwerów z puli pool.ntp.org.
- Weryfikacja statusu synchronizacji zegara (system clock print).
- Uruchomienie serwera NTP na routerze dla sieci lokalnej.
- Konfiguracja klienta NTP na systemie Linux (np. chrony lub systemd-timesyncd) wskazującego na router.
- Weryfikacja offsetu czasu na kliencie.
- Zabezpieczenie serwera NTP przed zapytaniami z zewnątrz.
- Analiza wpływu braku synchronizacji na logi systemowe (Timestamp).
- Ustawienie cyklicznej weryfikacji statusu serwerów nadrzędnych.
1. W RouterOS v7 funkcjonalność NTP znajduje się w menu
/system ntp — w starszych wersjach pakiet ntp wymaga osobnej instalacji.2. Przed konfiguracją klienta NTP upewnij się, że DNS działa poprawnie — nazwy hostów serwerów z puli pool.ntp.org muszą być rozpoznawalne.
3. Poprawna strefa czasowa dla Polski to
Europe/Warsaw — ustaw ją poleceniem /system clock set time-zone-name=Europe/Warsaw przed aktywacją NTP.4. Dodaj minimum dwa serwery NTP z puli polskiej (np. pl.pool.ntp.org) — zwiększa to niezawodność synchronizacji w przypadku awarii jednego serwera.
5. Po włączeniu klienta NTP odczekaj kilka minut przed weryfikacją — synchronizacja może potrwać od kilku sekund do kilku minut, zależnie od stratyfikacji czasu.
6. Weryfikuj synchronizację poleceniem
/system clock print — pole time pokazuje aktualny czas, a synchronized wskazuje status synchronizacji (yes/no).7. Serwer NTP włączaj tylko dla interfejsów LAN — nie udostępniaj NTP na zewnątrz, aby uniknąć ataków typu NTP amplification.
8. Na kliencie Linux używaj demonów
chrony lub systemd-timesyncd — skonfiguruj je tak, aby wskazywały na adres IP routera MikroTik jako serwer NTP.9. Offset czasu sprawdzaj na kliencie poleceniem
chronyc tracking (dla chrony) lub timedatectl (dla systemd-timesyncd) — wartość offsetu nie powinna przekraczać kilku sekund.10. W logach systemowych MikroTik (
/log print) możesz śledzić komunikaty dotyczące synchronizacji NTP — filtruj logi poleceniem /log print where topics~"ntp".11. Testuj brak synchronizacji celowo: wyłącz interfejs WAN lub zablokuj ruch NTP firewallem i obserwuj, jak system się zachowuje po utracie źródła czasu.
12. Dokumentuj różnicę czasu (offset) przed i po synchronizacji — zanotuj, jak duże było początkowe opóźnienie i ile czasu zajęło jego skorygowanie.
Synchronizacja czasu jest krytycznym elementem administracji siecią, mającym bezpośredni wpływ na bezpieczeństwo i możliwość analizy incydentów. Prawidłowy czas systemowy jest niezbędny do poprawnego działania protokołów SSL/TLS, gdzie ważność certyfikatów jest weryfikowana na podstawie daty wydania i wygaśnięcia. W przypadku niesynchronizowanego czasu połączenia szyfrowane mogą być odrzucane jako nieprawidłowe, co skutkuje niemożnością nawiązania bezpiecznej komunikacji. Mechanizm NTP w RouterOS pozwala routerowi pełnić rolę serwera czasu dla urządzeń w sieci lokalnej, co centralizuje zarządzanie czasem i zapewnia spójność zegarów wszystkich urządzeń. Wybór odpowiedniej strefy czasowej (Europe/Warsaw) jest kluczowy dla poprawnej interpretacji zdarzeń w logach systemowych, zwłaszcza przy korelacji zdarzeń między różnymi urządzeniami. Włączenie serwera NTP tylko dla interfejsów LAN zapobiega potencjalnym atakom typu NTP amplification z sieci WAN. Dokumentowanie offsetu czasu przed i po synchronizacji pozwala ocenić dokładność synchronizacji i czas potrzebny na ustabilizowanie zegara. Podsumowując, centralizacja zarządzania czasem poprzez NTP jest fundamentem profesjonalnej administracji siecią i bezpieczeństwa IT.
Wykład 2 i Wykład 7 Bezpieczeństwo usług zarządzania, hardening systemowy, minimalizacja powierzchni ataku.
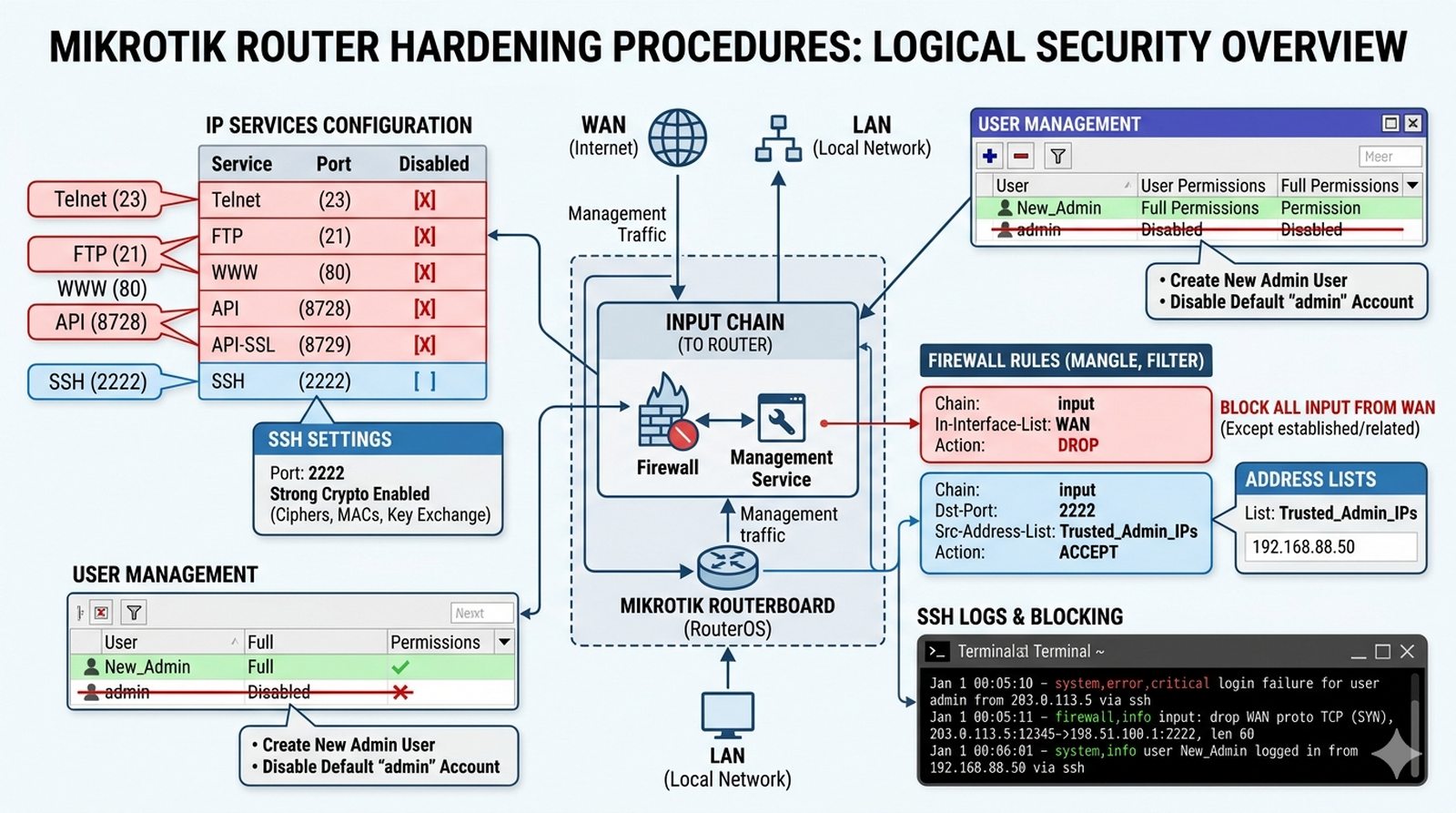
Routery wystawione bezpośrednio do Internetu są nieustannie skanowane przez automatyczne boty szukające słabych punktów wejścia — domyślne usługi takie jak Telnet, HTTP czy FTP stanowią poważne zagrożenie bezpieczeństwa. Zadaniem administratora jest przeprowadzenie procedury utwardzania (hardening) routera MikroTik, obejmującej wyłączenie zbędnych usług, zmianę domyślnego portu SSH na niestandardowy, ograniczenie dostępu SSH do zaufanych adresów IP oraz konfigurację reguł firewalla blokujących cały ruch przychodzący z WAN. Musisz również wyłączyć domyślne konto administratora i utworzyć nowe konto z uprawnieniami pełnymi, a następnie przetestować dostęp z nieautoryzowanych adresów, aby upewnić się, że zabezpieczenia działają poprawnie.
- Wyłączenie usług: telnet, ftp, www, api, api-ssl.
- Zmiana portu SSH na niestandardowy (np. 2222).
- Włączenie silnej kryptografii dla SSH (strong-crypto).
- Ograniczenie dostępu do SSH (address list) wyłącznie do IP administratora.
- Wyłączenie Neighbors Discovery na interfejsie WAN.
- Utworzenie nowego użytkownika o uprawnieniach 'full' i usunięcie/wyłączenie konta 'admin'.
- Konfiguracja Firewall: drop wszystkich połączeń na input z WAN (poza niezbędnymi).
- Weryfikacja braku odpowiedzi na 'ping' z sieci zewnętrznej (ICMP drop).
- Test połączenia SSH z konsoli Linux z użyciem kluczy RSA/ED25519 (opcjonalnie).
- Analiza logów po nieudanej próbie logowania.
1. Przed wyłączeniem jakichkolwiek usług stwórz nowego użytkownika z pełnymi uprawnieniami i przetestuj logowanie nim — domyślne konto admin wyłącz dopiero po potwierdzeniu działania nowego użytkownika.
2. W GNS3 przed rozpoczęciem procedury hardeningu sprawdź, czy masz aktywne połączenie przez Winbox (port 8291) — upewnij się, że nie stracisz dostępu do urządzenia.
3. Usługi telnet, ftp, www, api i api-ssl wyłączaj etapami: najpierw zmień port SSH na niestandardowy i przetestuj połączenie, a dopiero potem wyłączaj pozostałe usługi.
4. Przy zmianie portu SSH na niestandardowy (np. 2222) używaj polecenia
/ip service set ssh port=2222 — po zmianie połączenia testuj z konsoli Linux poleceniem ssh -p 2222 uzytkownik@adres_ip.5. Listę dostępową (address list) dla SSH utwórz z adresów IP, które będą używane do zarządzania — dodaj regułę allow dla tych adresów PRZED regułą drop dla wszystkich innych.
6. Włączenie silnej kryptografii SSH (
strong-crypto=yes) wykluczy połączenia ze starszymi klientami SSH — upewnij się, że wszyscy administratorzy używają nowoczesnych klientów SSH.7. Wyłączenie Neighbors Discovery na interfejsie WAN wykonaj poleceniem
/ip neighbor discovery-settings set discover-interface-list=none dla interfejsu WAN — zapobiega to wykryciu routera przez nieautoryzowanych użytkowników.8. Firewallowe reguły input drop konfiguruj z ostrożnością — pamiętaj, że reguły są przetwarzane sekwencyjnie, więc kolejność ma znaczenie dla bezpieczeństwa.
9. Testuj połączenie SSH po każdej zmianie firewalla — jeśli połączenie SSH przestanie działać, sprawdź logi (
/log print where topics~"ssh") i ostatnią wprowadzoną regułę.10. Używaj kluczy RSA/ED25519 zamiast haseł — generuj klucz poleceniem
ssh-keygen -t ed25519 na kliencie Linux i dodawaj klucz publiczny do użytkownika w RouterOS.11. ICMP drop (blokowanie pingów) jest częstą praktyką hardeningu, ale pamiętaj, że utrudnia to diagnostykę — możesz zamiast tego ograniczyć ICMP tylko do zaufanej podsieci.
12. Po zakończeniu hardeningu przetestuj dostęp z nieautoryzowanego IP — upewnij się, że połączenie SSH z nieprawidłowego adresu jest blokowane zgodnie z konfiguracją address list.
Procedura utwardzania (hardening) routera jest fundamentem bezpieczeństwa sieci i powinna być przeprowadzona przed podłączeniem urządzenia do sieci produkcyjnej. Wyłączenie zbędnych usług (telnet, ftp, www, api, api-ssl) znacząco redukuje powierzchnię ataku i eliminuje potencjalne wektory ataku. Ograniczenie dostępu SSH do zaufanych adresów IP poprzez address list zapobiega atakom siłowym i próbom zgadywania haseł z nieautoryzowanych lokalizacji. Zmiana domyślnego portu SSH na niestandardowy utrudnia automatyczne skanowanie i próby automatycznego logowania przez boty. Włączenie silnej kryptografii (strong-crypto) zapewnia użycie bezpiecznych algorytmów szyfrujących, eliminując podatności związane ze starszymi protokołami. Utworzenie dedykowanego konta administratora i wyłączenie konta domyślnego "admin" chroni przed atakami dedykowanymi do domyślnych poświadczeń MikroTik. Reguły firewalla blokujące cały ruch przychodzący z WAN tworzą skuteczną barierę przed nieautoryzowanymi próbami połączenia. Dokumentowanie wszystkich zmian konfiguracyjnych i zachowanie procedury rollback jest kluczowe dla bezpieczeństwa operacyjnego. Podsumowując, hardening routera to proces ciągły, a nie jednorazowe działanie, wymagający regularnego przeglądu i aktualizacji zabezpieczeń.
Wykład 2 Bezpieczeństwo przesyłu danych przez publiczne sieci, kryptografia symetryczna i asymetryczna, standard IPsec.
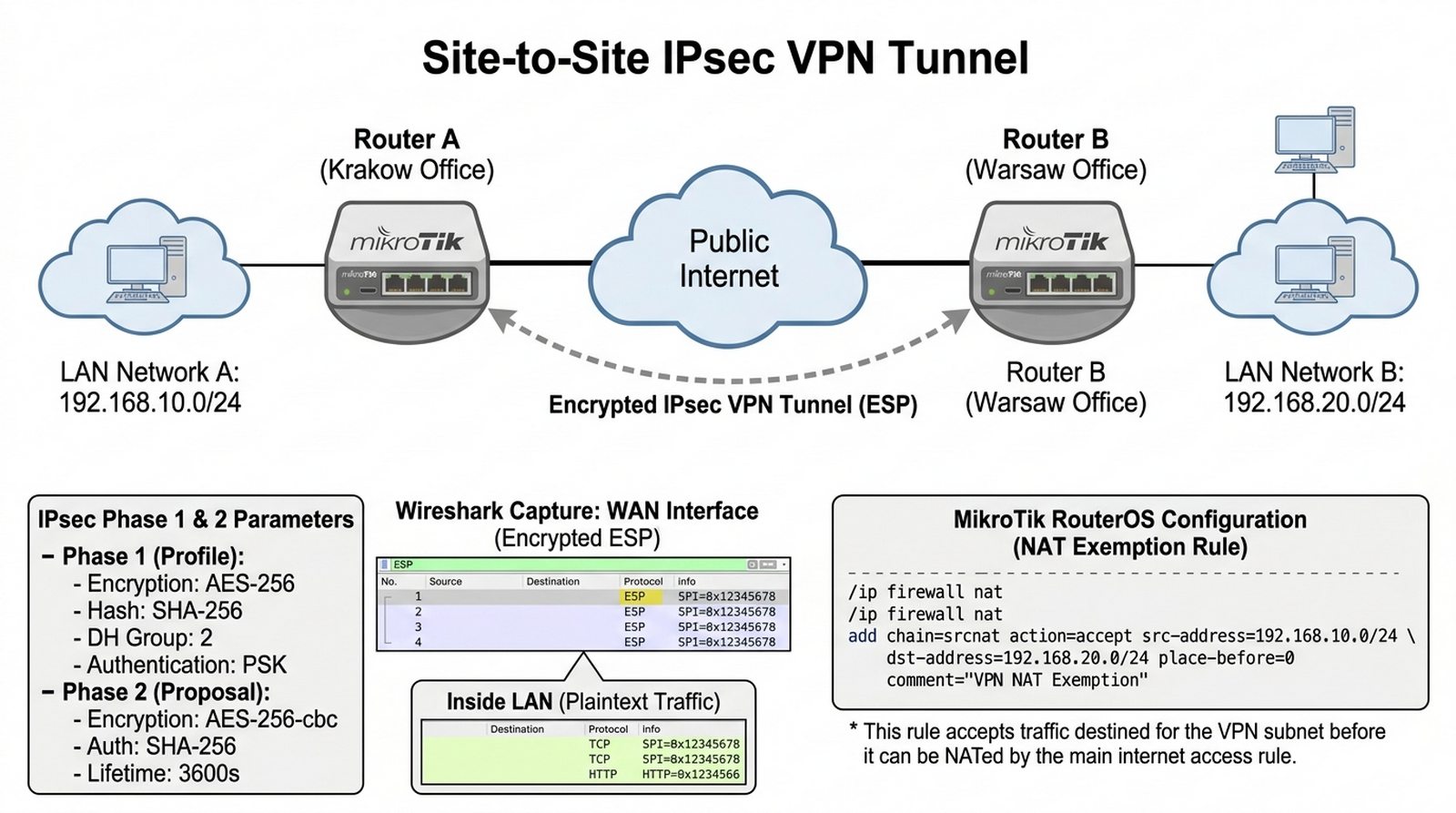
Firma posiada dwa biura w różnych miastach (Kraków i Warszawa), które muszą bezpiecznie wymieniać poufne dane przez publiczną sieć Internet. Plaintext ruch sieciowy jest podatny na podsłuch i modyfikację przez osoby trzecie, dlatego administrator zdecydował o utworzeniu tunelu VPN Site-to-Site IPsec między routerami MikroTik. Twoim zadaniem jest skonfigurować profile Phase 1 (AES-256, SHA-256), proposal Phase 2, peer oraz polityki IPsec dla ruchu między sieciami 192.168.10.0/24 i 192.168.20.0/24, skonfigurować NAT Exemption, a następnie zweryfikować działanie tunelu za pomocą pingów i Wiresharkem sprawdzić, czy ruch jest faktycznie szyfrowany.
- Konfiguracja Profile (Phase 1): AES-256, SHA-256, Diffie-Hellman Group 2.
- Ustawienie Peer: adres IP zdalnej bramy i klucz Pre-shared Key (PSK).
- Konfiguracja Proposal (Phase 2): AES-256-cbc, SHA-256, lifetime 1h.
- Stworzenie IPsec Policy (ruch z 192.168.10.0/24 do 192.168.20.0/24).
- Konfiguracja NAT Exemption (No-NAT) dla ruchu między biurami.
- Weryfikacja statusu negocjacji IKEv2 (Installed SAs).
- Test łączności (ping) między hostami w różnych oddziałach.
- Udokumentowanie wzrostu liczby pakietów zaszyfrowanych (encapsulated).
- Sprawdzenie braku możliwości podsłuchania ruchu za pomocą Wiresharka na styku WAN.
- Konfiguracja mechanizmu Dead Peer Detection (DPD).
1. Przed konfiguracją IPsec upewnij się, że routery "widzą się" nawzajem — przetestuj łączność ping między interfejsami WAN obu routerów, aby wykluczyć problemy z routingiem.
2. Parametry Phase 1 (Profile) i Phase 2 (Proposal) muszą być IDENTYCZNE po obu stronach tunelu — różnice w algorytmach szyfrowania lub grupach DH powodują brak negocjacji SA.
3. W RouterOS v7 struktura IPsec została zmieniona — profile są teraz oddzielne od peer, a proposal od policy. Upewnij się, że używasz odpowiedniej składni dla swojej wersji RouterOS.
4. Najczęstszym błędem jest brak reguły NAT exemption — przed regułą masquerade na NAT musi znaleźć się reguła accept dla ruchu IPsec:
/ip firewall nat add chain=srcnat action=accept src-address=192.168.10.0/24 dst-address=192.168.20.0/24 place-before=0.5. Pre-shared Key (PSK) powinien być wystarczająco silny — użyj co najmniej 16 znaków losowych, ponieważ słabe PSK jest podatne na ataki brute-force.
6. Po skonfigurowaniu tunelu sprawdź status w zakładce IP > IPsec > Installed SAs — jeśli jest pusta, oznacza to, że negocjacja Phase 2 nie powiodła się.
7. Dead Peer Detection (DPD) skonfiguruj na obu routerach — pozwala to na automatyczne wykrywanie i ponowne ustanawianie zerwanych tuneli.
8. Weryfikuj ruch zaszyfrowany w Wiresharku na interfejsie WAN — pomiędzy routerami powinieneś widzieć tylko pakiety ESP (protokół 50), a nie plaintext.
9. Pamiętaj, że NAT Exemption tworzy się w NAT, ale oznaczenie "ipsec" w action srcnat nie działa w RouterOS v7 — używaj jawnego src-address/dst-address.
10. Dokumentuj całą konfigurację po obu stronach — zanotuj adresy WAN, używane algorytmy szyfrowania, grupy DH, lifetime i PSK (ten ostatni oczywiście bezpiecznie).
11. Przetestuj trwałość tunelu: po ustanowieniu połączenia zrestartuj jeden z routerów — obserwuj, jak szybko tunel zostanie ponownie nawiązany.
12. Przeprowadź test "capture" w Wiresharku podczas handshake IPsec — zaobserwuj komunikaty ISAKMP (IKE) Phase 1 i Phase 2, aby zrozumieć proces negocjacji.
Tunel VPN IPsec Site-to-Site zapewnia bezpieczną komunikację między oddziałami firmy przez publiczną sieć Internet, szyfrując cały ruch i chroniąc poufne dane przed podsłuchem. Poprawna konfiguracja Phase 1 (Profile) i Phase 2 (Proposal) z identycznymi parametrami po obu stronach jest kluczowa dla ustanowienia połączenia — różnice w algorytmach szyfrowania lub grupach Diffie-Hellman powodują brak negocjacji Security Associations. Użycie silnych algorytmów (AES-256, SHA-256) oraz odpowiedniej grupy DH (modp1024 lub wyższej) zapewnia ochronę przed współczesnymi atakami kryptograficznymi. Mechanizm NAT Exemption jest niezbędny do prawidłowego działania tunelu — reguła NAT musi być umieszczona przed regułą masquerade, aby ruch między oddziałami nie był translacji adresów. Dead Peer Detection (DPD) automatycznie wykrywa przerwę w połączeniu i inicjuje ponowne ustanowienie tunelu, co minimalizuje przestój. Pre-shared Key (PSK) powinien być wystarczająco silny i przechowywany w bezpieczny sposób — słabe PSK jest podatne na ataki brute-force. Wireshark pozwala zweryfikować, czy ruch jest faktycznie szyfrowany (pakiety ESP) i czy nie ma przecieków plaintext. Dokumentowanie konfiguracji po obu stronach jest kluczowe dla późniejszego rozwiązywania problemów. Podsumowując, IPsec jest dojrzałym i bezpiecznym rozwiązaniem do łączenia oddziałów, wymagającym jednak precyzyjnej konfiguracji i testowania.
Wykład 3 Systemy monitorowania NMS, protokół SNMP (v2c/v3), parametry OID i MIB.
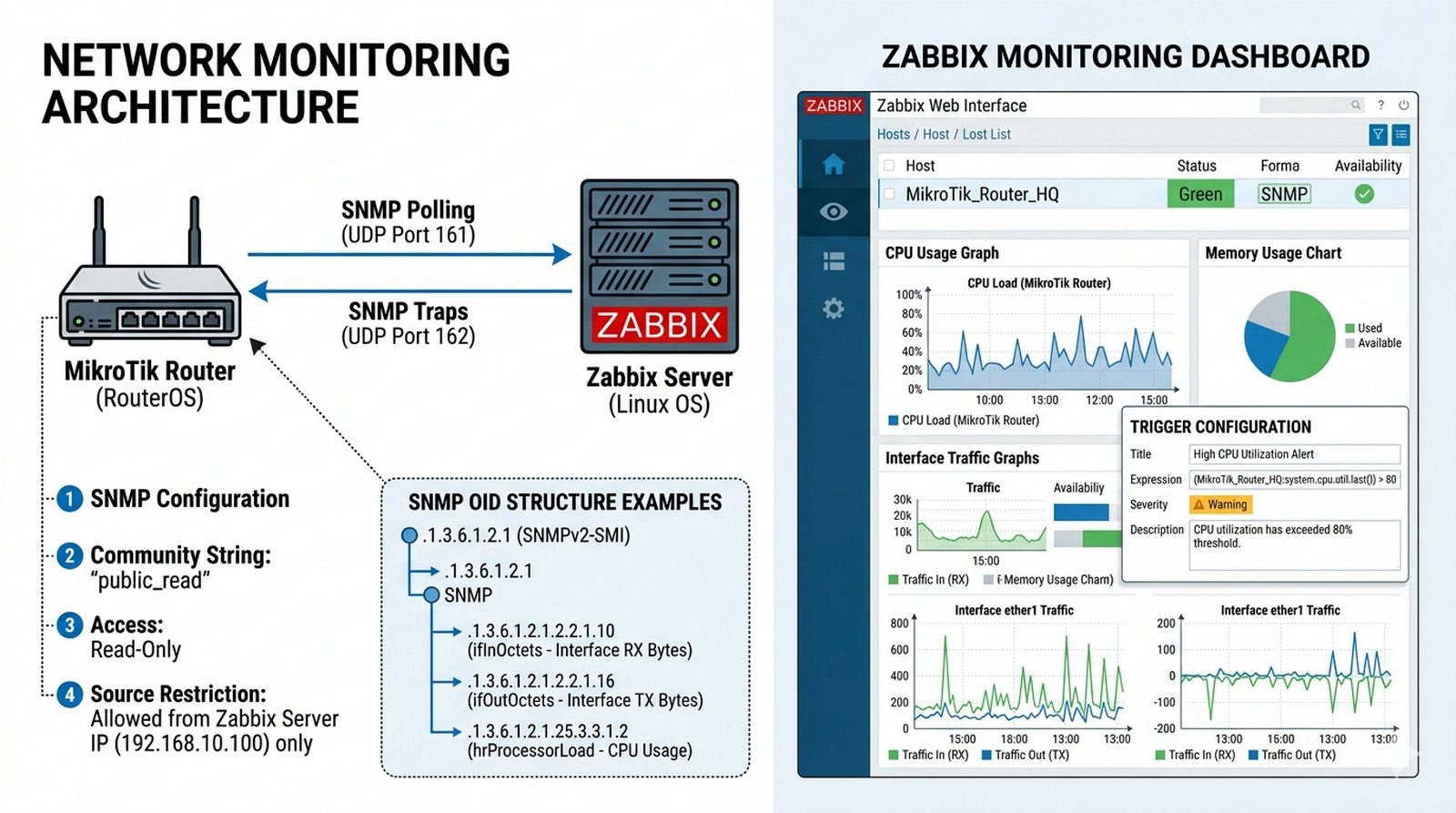
Aby uniknąć niespodziewanych przerw w działaniu usług sieciowych, administrator potrzebuje proaktywnego monitoringu infrastruktury — wiedzieć o problemach zanim zadzwonią użytkownicy. Wymagane jest monitorowanie obciążenia CPU, pamięci RAM i ruchu na interfejsach wszystkich routerów MikroTik. Administrator zdecydował o wdrożeniu serwera Zabbix na Linux, który będzie zbierał dane przez protokół SNMP. Twoim zadaniem jest włączyć i skonfigurować SNMP na routerze MikroTik (community string, ograniczenie do IP serwera Zabbix), zainstalować i skonfigurować Zabbix, dodać host z szablonem dla MikroTik, a następnie zweryfikować czy dane są zbierane i wyświetlane na wykresach.
- Włączenie usługi SNMP na RouterOS.
- Konfiguracja 'Community string' (np. public_read) z dostępem tylko do odczytu.
- Ograniczenie zapytań SNMP wyłącznie do adresu IP serwera Zabbix.
- Instalacja serwera Zabbix na maszynie Linux (lub użycie gotowego obrazu).
- Dodanie 'Host' w Zabbix z adresem IP routera.
- Zastosowanie szablonu (Template) dedykowanego dla MikroTik.
- Weryfikacja dostępności SNMP (zielona ikona w Zabbix).
- Stworzenie wykresu (Graph) obciążenia pasma na interfejsie WAN.
- Konfiguracja prostego triggera (np. wysokie użycie CPU > 80%).
- Udokumentowanie struktury OID za pomocą narzędzia 'snmpwalk'.
1. SNMP na RouterOS włącz poleceniem
/snmp set enabled=yes — domyślnie usługa jest wyłączona ze względów bezpieczeństwa.2. Community string (np. public_read) skonfiguruj z opcją addresses=192.168.10.50/32 — ogranicz dostęp SNMP tylko do serwera Zabbix, aby uniknąć nieautoryzowanych zapytań.
3. Przed konfiguracją Zabbixa sprawdź firewall routera — port 161/UDP (SNMP) musi być dozwolony dla ruchu przychodzącego od serwera monitoringu.
4. Na serwerze Linux zainstaluj Zabbix korzystając z oficjalnego repozytorium — wersja pakietu powinna odpowiadać wersji agenta na routerze MikroTik.
5. Podczas dodawania hosta w Zabbixie używaj szablonu dedykowanego dla MikroTik (np. Template Net Mikrotik SNMPv2) — zawiera on predefiniowane pozycje i wykresy.
6. Po dodaniu hosta odczekaj kilka minut przed weryfikacją — Zabbix potrzebuje czasu na pierwsze zebranie danych (discovery).
7. Zielona ikona dostępności SNMP oznacza poprawne działanie — ikona szara lub czerwona wskazuje na problem z komunikacją lub błędny community string.
8. Narzędzie
snmpwalk służy do weryfikacji dostępności OID: snmpwalk -v 2c -c public_read 192.168.10.1 — zwróci ono listę wszystkich dostępnych parametrów SNMP.9. Wybrane OID do monitoringu MikroTik: .1.3.6.1.2.1.2.2.1.10 (interfejs RX bytes), .1.3.6.1.2.1.1.3 (uptime), .1.3.6.1.2.1.2.2.1.16 (interfejs TX bytes).
10. Triggery konfiguruj z odpowiednim opóźnieniem (np. 5m) — zbyt agresywne progi mogą generować fałszywe alarmy podczas normalnego obciążenia.
11. SNMP v2c nie zapewnia szyfrowania ani uwierzytelniania — w środowisku produkcyjnym rozważ migrację do SNMP v3 z uwierzytelnianiem MD5/SHA i szyfrowaniem DES/AES.
12. Regularnie przeglądaj wykresy w Zabbixie — pozwalają one wychwycić anomalie, takie jak nagłe skoki ruchu czy degradacja wydajności interfejsów.
System monitoringu SNMP z Zabbix stanowi kluczowy element zarządzania siecią, umożliwiając proaktywne wykrywanie problemów przed ich eskalacją do poziomu krytycznego. Poprawna konfiguracja community string z ograniczeniem do adresu IP serwera Zabbix jest fundamentalna dla bezpieczeństwa — nieuprzywilejowany dostęp do SNMP może ujawnić wrażliwe informacje o konfiguracji sieci. Protokół SNMP v2c mimo braku szyfrowania jest wystarczający w środowisku laboratoryjnym, ale w produkcji należy rozważyć migrację do v3 z uwierzytelnianiem i szyfrowaniem. Trigger'y konfigurowane z odpowiednim opóźnieniem zapobiegają fałszywym alarmom generowanym przez chwilowe skoki obciążenia. Analiza wykresów historycznych pozwala na identyfikację trendów i planowanie pojemności — np. stopniowy wzrost wykorzystania pasma może sygnalizować potrzebę rozbudowy łącza. Szablony dla MikroTik dostarczają predefiniowanych pozycji i wykresów, co przyspiesza wdrożenie monitoringu. Narzędzie snmpwalk jest nieocenione przy debuggingu i weryfikacji dostępności konkretnych OID. Podsumowując, monitoring sieci jest inwestycją w ciągłość działania usług i umożliwia szybką reakcję na incydenty.
Wykład 3 i Wykład 9 Architektura logowania, retencja danych, analiza incydentów i diagnostyka błędów.
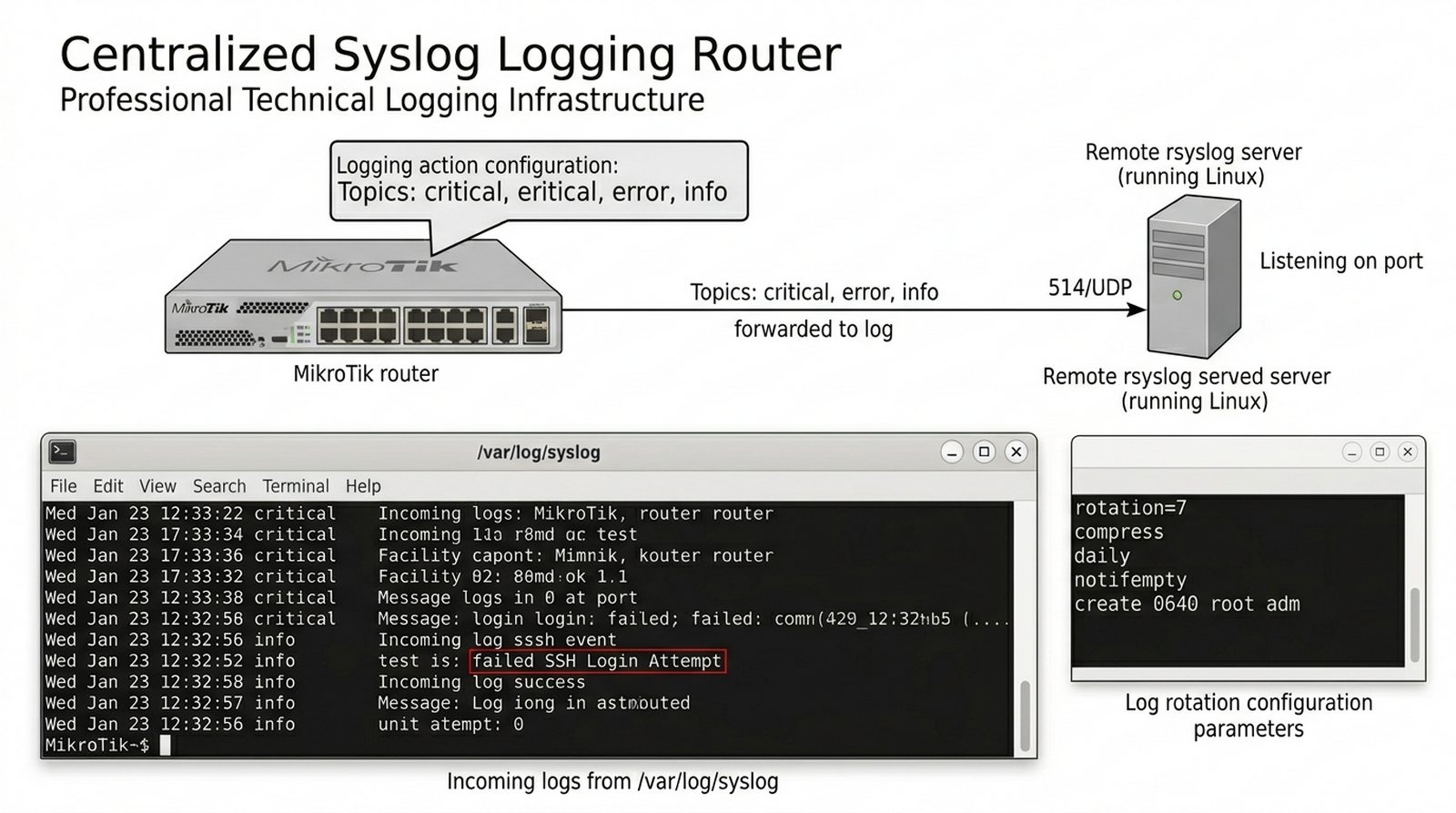
Logi na routerze MikroTik przechowują tylko ostatnie zdarzenia — po awarii lub ataku hackerów wszystkie dowody mogą zostać nadpisane. Administrator potrzebuje scentralizowanego systemu logowania, aby w przypadku incydentu móc przeanalizować wszystkie zdarzenia z różnych urządzeń w jednym miejscu i ustalić co dokładnie się wydarzyło. Twoim zadaniem jest zainstalować i skonfigurować serwer rsyslog na Linux (nasłuch na porcie 514/UDP), skonfigurować RouterOS do wysyłania logów (topics: critical, error, info) na ten serwer, otworzyć port w firewallu, a następnie wygenerować testowe zdarzenie (np. nieudane logowanie SSH) i zweryfikować czy pojawiło się w pliku /var/log/syslog na serwerze Linux.
- Konfiguracja usługi rsyslog na Linux do nasłuchu na porcie 514/udp.
- Otwarcie portu 514/udp w firewallu Linuxa (ufw/iptables).
- Konfiguracja RouterOS 'Logging Action' typu 'remote' z adresem serwera.
- Przekierowanie logów 'critical', 'error' i 'info' do zdalnej lokalizacji.
- Weryfikacja napływania logów w pliku /var/log/syslog lub dedykowanym katalogu.
- Konfiguracja 'Log rotation' na Linuxie, aby uniknąć przepełnienia dysku.
- Wygenerowanie testowego zdarzenia (np. nieudane logowanie) i sprawdzenie go na serwerze.
- Ustawienie formatu logów (BSD vs RFC5424).
- Analiza logów pod kątem wzorców błędów.
- Zabezpieczenie transmisji logów (opcjonalnie Syslog over TLS).
1. Na serwerze Linux instaluj rsyslog poleceniem
sudo apt install rsyslog — w większości dystrybucji jest już zainstalowany, ale sprawdź jego status poleceniem systemctl status rsyslog.2. W pliku /etc/rsyslog.conf dodaj na początku sekcji modułów:
module(load="imudp") i input(type="imudp" port="514") — te dwie linie są niezbędne do odbierania logów przez UDP.3. Firewall na serwerze Linux otwórz dla portu 514/UDP:
sudo ufw allow 514/udp (dla UFW) lub dodaj regułę iptables: sudo iptables -A INPUT -p udp --dport 514 -j ACCEPT.4. W RouterOS skonfiguruj akcję logowania typu remote:
/system logging action add name=remote_syslog remote=192.168.10.50 target=remote — adres IP to adres serwera Linux z rsyslog.5. Tematy logów (topics) wybieraj selektywnie — w RouterOS możesz logować różne kategorie:
critical, error, warning, info, debug.6. Logi zobaczysz w /var/log/syslog (Ubuntu/Debian) lub w katalogu /var/log/ z osobnymi plikami (np. /var/log/mikrotik.log) — zależy to od konfiguracji filtrów w rsyslog.conf.
7. Konfiguracja rotacji logów jest kluczowa — plik /etc/logrotate.d/rsyslog określa, jak długo przechowywać logi i kiedy je kompresować. Typowa rotacja: tygodniowa z retencją 4 tygodni.
8. Testuj przesyłanie logów generując zdarzenie na routerze — wykonaj nieudane logowanie SSH lub zmień konfigurację i obserwuj, czy log pojawi się na serwerze.
9. Format logów (BSD vs RFC5424) ustaw w /etc/rsyslog.conf — RFC5424 jest nowoczesnym standardem z lepszą strukturą, ale BSD jest bardziej kompatybilny ze starszymi parserami.
10. Analiza wzorców błędów: używaj poleceń
grep i awk do filtrowania logów — np. grep "error" /var/log/syslog | tail -50 wyświetli 50 ostatnich błędów.11. Opcjonalnie skonfiguruj Syslog over TLS dla bezpiecznej transmisji — wymaga to dodania certyfikatów i konfiguracji modułu imptpc w rsyslog.
12. Dokumentuj strukturę logów i ich znaczenie — stwórz tabelę z najważniejszymi typami logów (np. auth, firewall, system) i przypisz im priorytetyważność dla procesu analizy incydentów.
Centralizacja logów systemowych jest fundamentem bezpieczeństwa i umożliwia korelację zdarzeń między różnymi urządzeniami w sieci. W przypadku incydentu bezpieczeństwa lub awarii, logi z wielu źródeł pozwalają na rekonstrukcję przebiegu zdarzeń i identyfikację przyczyny źródłowej. Konfiguracja rsyslog na Linux do nasłuchu na porcie 514/UDP jest standardem przemysłowym, zapewniającym kompatybilność z urządzeniami różnych producentów. Selektywne logowanie kategorii (critical, error, info) pozwala zarządzać wolumenem logów i skupić się na najważniejszych zdarzeniach. Log rotation jest krytyczna dla zapobiegania przepełnieniu dysku — automatyczna kompresja i usuwanie starych logów zapewnia ciągłość działania. Syslog over TLS (opcjonalnie) szyfruje transmisję logów, chroniąc przed podsłuchem w sieci. Analiza logów przy użyciu narzędzi takich jak grep i awk pozwala na szybkie filtrowanie i znajdowanie wzorców błędów. Dokumentowanie znaczenia różnych typów logów ułatwia późniejszą analizę i szkolenie personelu. Podsumowując, centralny syslog jest niezbędnym elementem infrastruktury bezpieczeństwa i powinien być wdrożony w każdym profesjonalnym środowisku sieciowym.
Wykład 4 Architektura systemów pocztowych, protokoły SMTP, IMAP, POP3, agenci MTA, MDA i MUA.
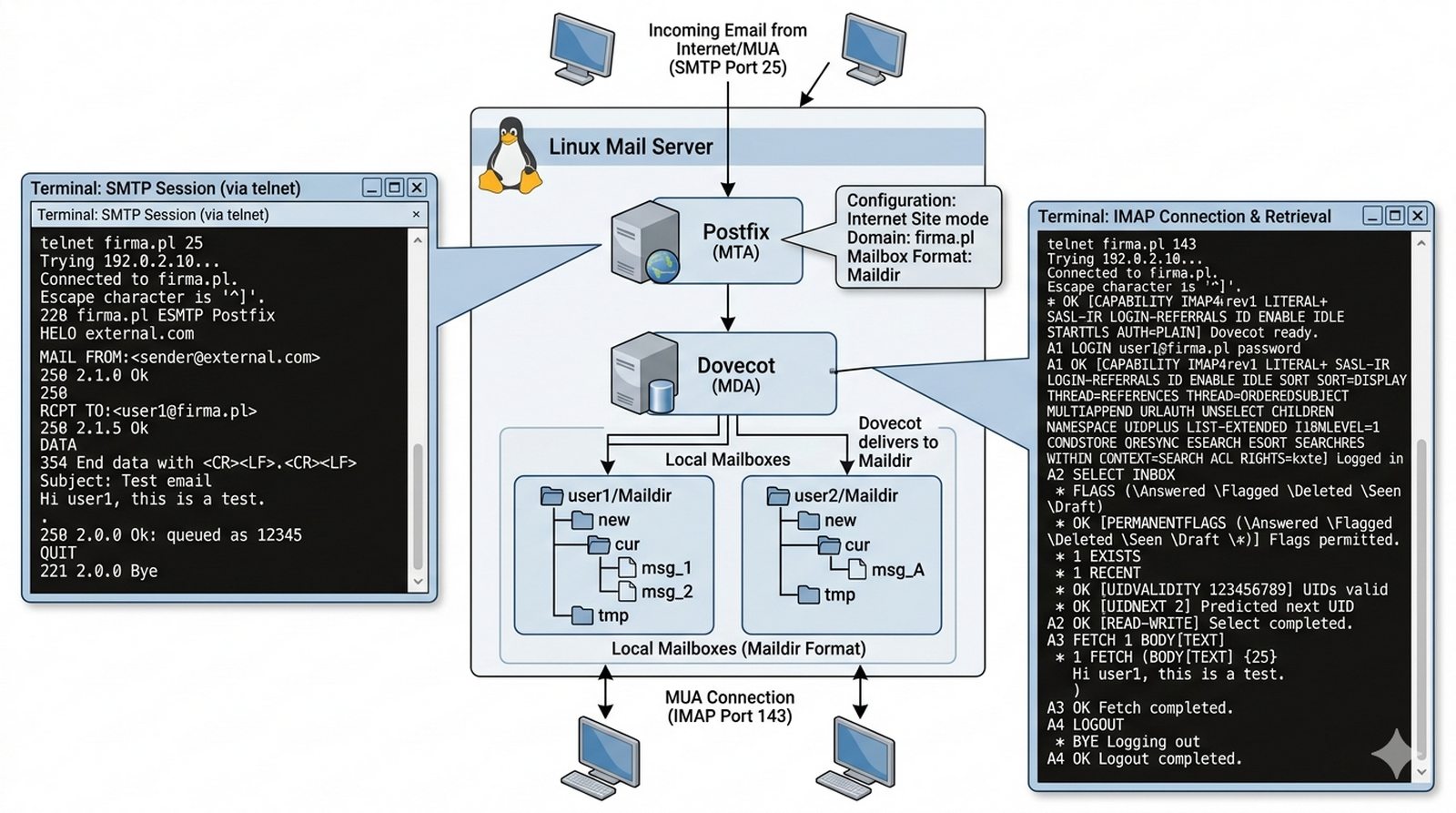
Firma potrzebuje własnej, niezależnej infrastruktury pocztowej do komunikacji wewnętrznej — poleganie na zewnętrznych dostawcach Gmail czy Office 365 nie jest akceptowalne ze względu na poufność danych firmowych. Administrator musi uruchomić na Linux serwer SMTP (Postfix) do wysyłania wiadomości oraz serwer IMAP (Dovecot) do odbierania i przechowywania poczty. Twoim zadaniem jest zainstalować oba pakiety, skonfigurować Postfix w trybie Internet Site z domeną firma.pl, skonfigurować format Maildir, utworzyć konta użytkowników (user1, user2), a następnie przetestować wysyłkę i odbiór poczty za pomocą telnet na port 25 lub klienta Thunderbird, aby upewnić się, że serwer działa poprawnie.
- Instalacja pakietów postfix i dovecot-imapd na systemie Linux.
- Konfiguracja Postfix w trybie 'Internet Site' z domeną firmową (np. firma.pl).
- Ustawienie formatu skrzynek na 'Maildir' (zamiast przestarzałego mbox).
- Konfiguracja Dovecot do obsługi protokołu IMAP na porcie 143.
- Stworzenie dwóch użytkowników systemowych (user1, user2) z hasłami.
- Otwarcie portów 25 i 143 w firewallu Linuxa.
- Weryfikacja wysyłki maila za pomocą polecenia 'telnet' lub 'swaks' na port 25.
- Podłączenie klienta MUA i sprawdzenie odbioru wiadomości.
- Analiza logów pocztowych w pliku /var/log/mail.log.
- Konfiguracja limitu wielkości załączników (message_size_limit).
1. Podczas instalacji Postfix wybierz typ konfiguracji "Internet Site" — opcja ta jest najbardziej odpowiednia dla samodzielnego serwera pocztowego z pełną kontrolą nad wysyłką i odbiorem.
2. Nazwa hosta (
myhostname) musi być w pełni kwalifikowaną nazwą domeny (FQDN), np. mail.firma.pl — serwer pocztowy bez poprawnego FQDN będzie traktowany jako podejrzany przez inne serwery.3. Format Maildir zamiast mbox ustawiasz poleceniem
postconf -e "home_mailbox = Maildir/" — Maildir jest nowoczesnym formatem, gdzie każda wiadomość to osobny plik, co ułatwia backup i synchronizację.4. Przed utworzeniem użytkowników sprawdź, czy istnieją w systemie — poleceniem
sudo useradd -m user1 tworzysz użytkownika z katalogiem domowym.5. Katalog Maildir w katalogu domowym użytkownika tworzy się automatycznie przy pierwszym dostarczeniu wiadomości — ale możesz też utworzyć go ręcznie poleceniem
sudo maildirmake /home/user1/Maildir.6. Firewall otwórz dla portów: 25 (SMTP), 143 (IMAP), 993 (IMAPS) — port 25 tylko dla lokalnej sieci lub z odpowiednim zabezpieczeniem, aby uniknąć otwartego relayu.
7. Test SMTP za pomocą telnet wykonaj dokładnie zgodnie ze składnią: po
HELO domena.pl następuje MAIL FROM: (FROM z dwukropkiem), a nie "from:".8. Po konfiguracji Dovecot sprawdź plik /var/log/mail.log — logi pokazują, czy połączenie IMAP zostało nawiązane i czy użytkownik się uwierzytelnił.
9. Limity wielkości załączników ustaw w Postfix przez
postconf -e "message_size_limit = 10240000" — domyślnie limit to ok. 10 MB.10. Konfiguracja uwierzytelniania SMTP (SMTP AUTH) jest wymagana, jeśli serwer ma wysyłać pocztę przez zewnętrznego providera — Postfix wymaga włączenia szyfrowania TLS i odpowiedniej konfiguracji sasl_auth.
11. Do testów możesz użyć narzędzia
swaks (Swiss Army Knife for SMTP): swaks --to user2@firma.pl --server localhost — jest to wygodniejsze niż ręczne telnetowanie.12. Przetestuj pobieranie poczty z klienta Thunderbird lub Evolution — wskaż adres serwera IMAP jako adres IP serwera Linux, a nie jako localhost, aby symulować rzeczywiste połączenie.
Serwer pocztowy Postfix/Dovecot stanowi podstawę komunikacji e-mail w infrastrukturze firmowej, zapewniając pełną kontrolę nad przepływem wiadomości. Konfiguracja Postfix w trybie Internet Site z właściwą domeną FQDN jest niezbędna dla poprawnego działania i reputacji serwera — serwery pocztowe odbiorców weryfikują nazwę hosta nadawcy. Format Maildir zamiast przestarzałego mbox oferuje lepszą niezawodność i ułatwia backup, ponieważ każda wiadomość jest osobnym plikiem. Protokół IMAP (Dovecot) umożliwia synchronizację skrzynek między wieloma urządzeniami, co jest kluczowe dla nowoczesnych pracowników mobilnych. Uwierzytelnianie SMTP (SMTP AUTH) jest wymagane do wysyłania poczty przez zewnętrznych providerów i zapobiega open relay — serwer bez uwierzytelniania może być wykorzystany do rozsiewania spamu. Limity wielkości załączników chronią przed przeciążeniem serwera i nadużyciami. Analiza logów w /var/log/mail.log pozwala na debugging problemów i monitorowanie działania. Podsumowując, własny serwer pocztowy daje pełną kontrolę nad komunikacją, ale wymaga odpowiedzialnej administracji i dbałości o bezpieczeństwo.
Wykład 4 i Wykład 7 Zagrożenia w komunikacji e-mail (spoofing, phishing), mechanizmy uwierzytelniania nadawcy.
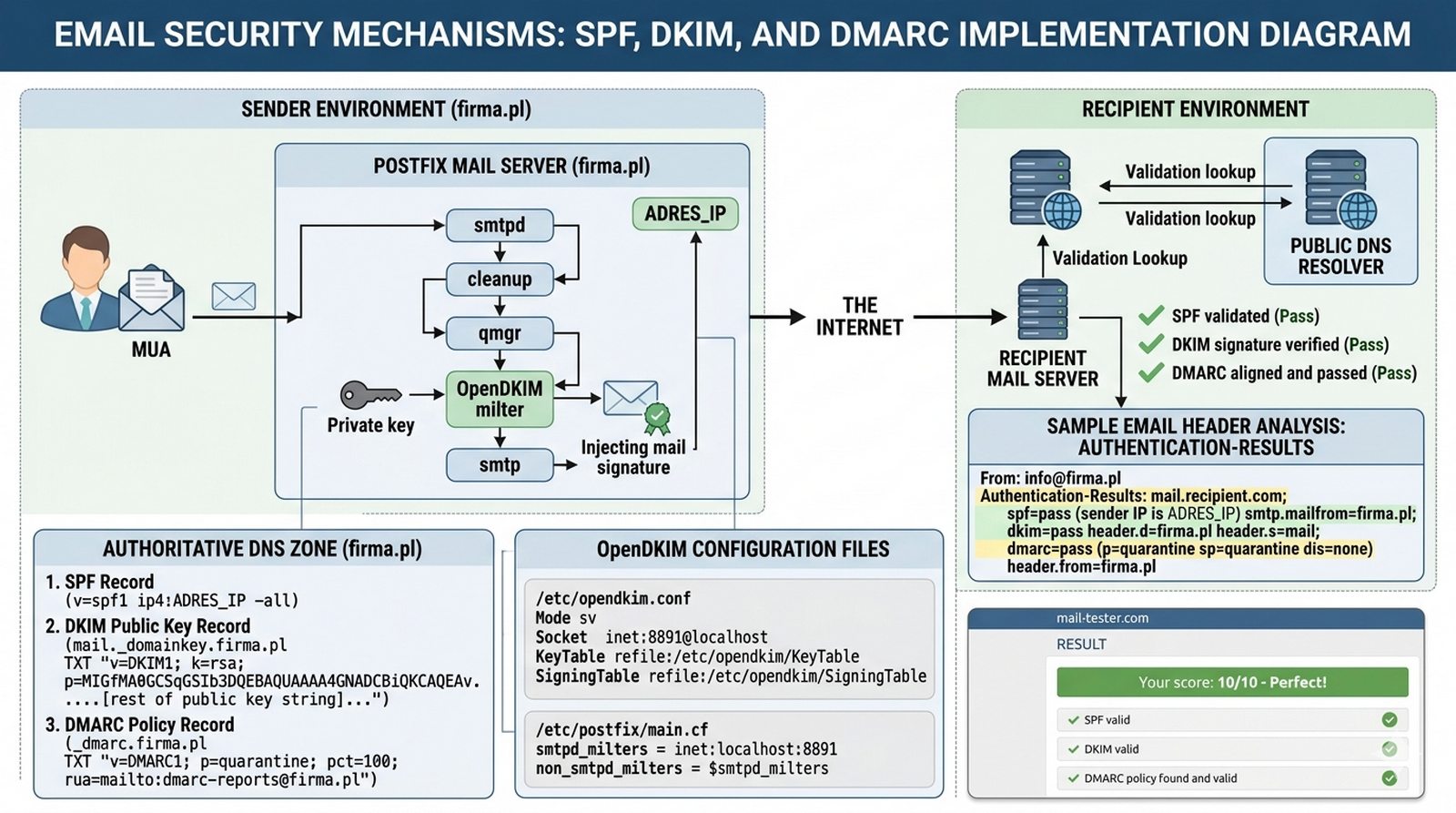
Własny serwer pocztowy bez zabezpieczeń jest podatny na podszywanie się pod domenę firmy — atakujący mogą wysyłać maile rzekomo od kierownictwa z fałszywymi linkami phishingowymi. Serwery odbiorców (Gmail, Outlook) nie mają jak zweryfikować autentyczności wiadomości bez dodatkowych mechanizmów, co powoduje, że nasze maile trafiają do spamu lub są odrzucane. Administrator musi wdrożyć trzy warstwy bezpieczeństwa: SPF (określa autoryzowane serwery wysyłające), DKIM (podpis cyfrowy wiadomości) i DMARC (polityka postępowania z nieautoryzowanymi wiadomościami). Twoim zadaniem jest dodać rekord TXT SPF w DNS routera MikroTik, zainstalować i skonfigurować OpenDKIM z Postfixem, dodać rekord DKIM do DNS oraz skonfigurować politykę DMARC, a następnie zweryfikować konfigurację narzędziem mail-tester.com.
- Dodanie rekordu TXT (SPF) w serwerze DNS MikroTik: "v=spf1 ip4:ADRES_IP -all".
- Instalacja i konfiguracja OpenDKIM na serwerze pocztowym.
- Wygenerowanie pary kluczy (prywatny/publiczny) dla domeny firma.pl.
- Dodanie rekordu TXT (DKIM) z kluczem publicznym do DNS.
- Konfiguracja Postfixa do współpracy z OpenDKIM (milter).
- Dodanie rekordu TXT (DMARC) z polityką 'quarantine' lub 'reject'.
- Weryfikacja nagłówka otrzymanej wiadomości (Authentication-Results).
- Użycie narzędzi online (np. mail-tester) or CLI tool 'opendkim-testkey' do walidacji.
- Analiza logów OpenDKIM pod kątem błędów podpisywania.
- Udokumentowanie znaczenia selektora w DKIM.
1. Rejestr SPF dodajesz w DNS jako rekord TXT:
v=spf1 ip4:ADRES_IP_SERWERA -all — "-all" oznacza, że wiadomości z innych adresów powinny być odrzucane (hard fail).2. Przed konfiguracją DKIM zainstaluj OpenDKIM:
sudo apt install opendkim opendkim-tools — następnie skonfiguruj plik /etc/opendkim.conf z parametrami domeny.3. Klucze DKIM generuj poleceniem
opendkim-genkey -s mail -d firma.pl — utworzy to dwa pliki: mail.private (klucz prywatny) i mail.txt (rekord DNS z kluczem publicznym).4. Klucz prywatny przechowuj bezpiecznie w /etc/opendkim/keys/ z uprawnieniami 600 — klucz publiczny trafia do DNS jako rekord TXT o nazwie mail._domainkey.firma.pl.
5. W Postfix skonfiguruj milter (Mail Filter) dla OpenDKIM — w /etc/postfix/main.cf dodaj:
smtpd_milters = inet:localhost:8891 i non_smtpd_milters = inet:localhost:8891.6. DMARC to trzecia warstwa — rekord TXT _dmarc.firma.pl z polityką:
v=DMARC1; p=quarantine; rua=mailto:raporty@firma.pl — "p=quarantine" kwarantannuje nieautoryzowane wiadomości.7. Waliduj konfigurację narzędziem mail-tester.com — wyślij testową wiadomość na wskazany adres i otrzymasz raport ze szczegółową oceną konfiguracji SPF/DKIM/DMARC.
8. Nagłówek Authentication-Results w wiadomości email pokazuje, czy uwierzytelnianie przeszło — możesz go zobaczyć w opcjach wyświetlania nagłówków klienta pocztowego.
9. Selektor w DKIM (np. "mail" w mail._domainkey) pozwala na wiele kluczy dla jednej domeny — używaj różnych selektorów dla różnych usług lub kluczy.
10. Długie klucze DKIM (2048 bitów) mogą być problematyczne w niektórych serwerach DNS — jeśli serwer DNS ma limit długości TXT, użyj 1024 bitów.
11. Logi OpenDKIM analizuj w /var/log/mail.log — szukaj wpisów "DKIM verification" i "DKIM signature" aby sprawdzić, czy wiadomości są podpisywane poprawnie.
12. Pamiętaj, że w środowisku laboratoryjnym GNS3 serwery pocztowe innych firm nie będą weryfikować Twoich rekordów — walidacja działa tylko dla rzeczywistych serwerów DNS w Internecie.
Mechanizmy bezpieczeństwa poczty e-mail (SPF, DKIM, DMARC) są kluczowe dla ochrony domeny firmowej przed spoofingiem i phishingem. Rekord SPF definiuje, które serwery są autoryzowane do wysyłania wiadomości w imieniu domeny, co pozwala odbiorcom na odrzucenie wiadomości pochodzących z nieautoryzowanych źródeł. Podpisy DKIM zapewniają integralność wiadomości — każda wiadomość jest podpisywana kluczem prywatnym, a odbiorca weryfikuje podpis kluczem publicznym z DNS. Polityka DMARC definiuje, co odbiorca ma robić z wiadomościami nieprzechodzącymi uwierzytelniania — od kwarantanny po całkowite odrzucenie. Wdrożenie wszystkich trzech mechanizmów znacząco redukuje ryzyko, że wiadomości z domeny będą klasyfikowane jako spam. Selektor w DKIM pozwala na wiele kluczy dla różnych usług lub rotacji kluczy bez przestoju. Walidacja narzędziem mail-tester.com jest niezbędna przed wdrożeniem produkcyjnym. Podsumowując, SPF/DKIM/DMARC to współczesny standard bezpieczeństwa e-mail, który powinien być wdrożony na każdym profesjonalnym serwerze pocztowym.
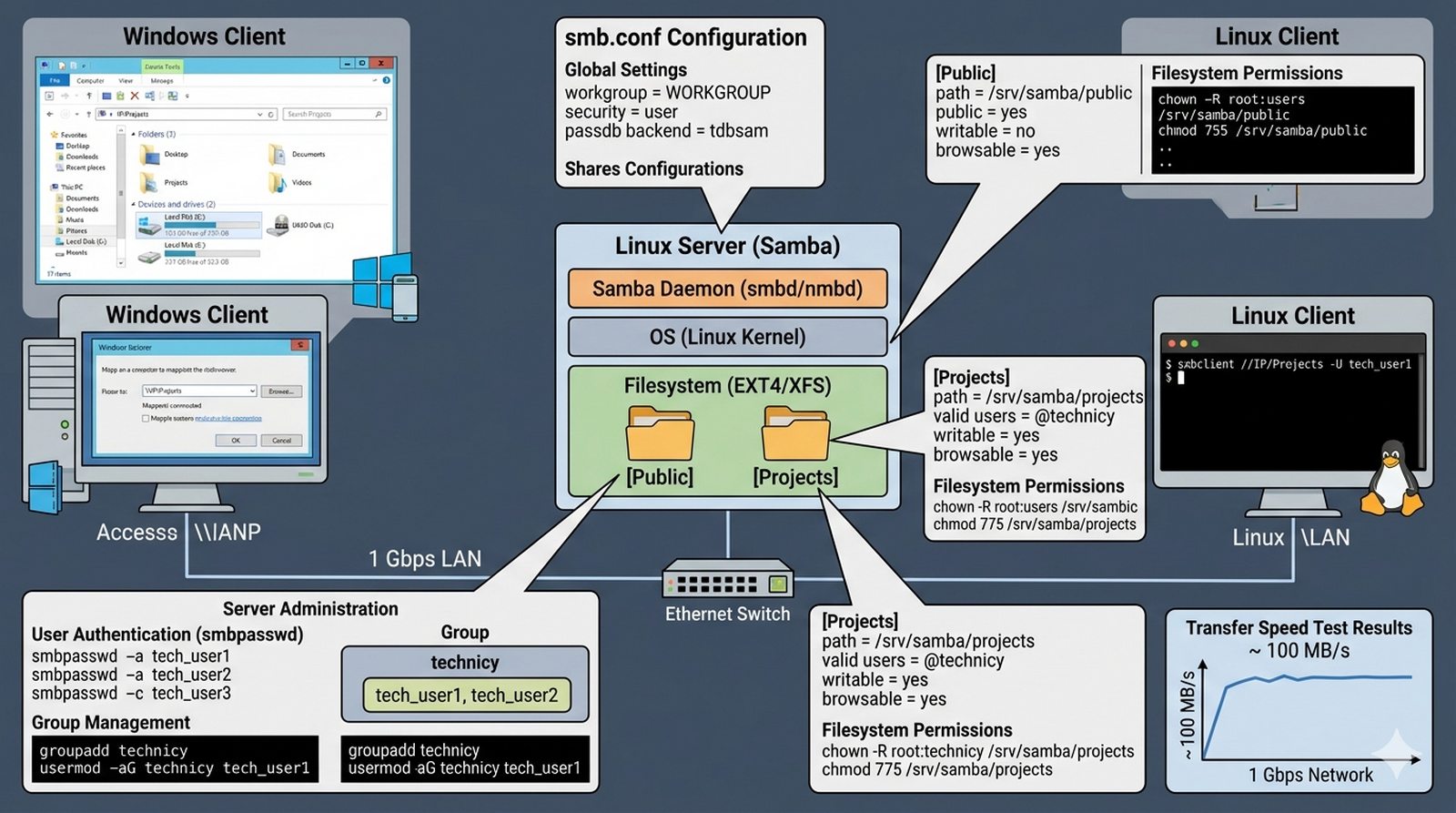
Wykład 5 Usługi plikowe SMB/CIFS, zarządzanie uprawnieniami (ACL), protokół uwierzytelniania Kerberos.
Pracownicy biura potrzebują wspólnej przestrzeni dyskowej do przechowywania projektów i plików roboczych — wymiana przez email jest nieefektywna, a udostępnianie przez USB stwarza ryzyko bezpieczeństwa i utraty kontroli wersji. Serwer plików musi umożliwiać dostęp z różnych systemów operacyjnych (Windows, Linux) oraz zapewniać kontrolę dostępu na poziomie użytkowników i grup z oddzielnymi uprawnieniami do odczytu i zapisu. Twoim zadaniem jest zainstalować serwer Samba na Linux, skonfigurować zasób [Public] tylko do odczytu dla wszystkich oraz zasób [Projects] z prawami zapisu dla grupy technicy, utworzyć użytkowników i grupy, skonfigurować uprawnienia na poziomie systemu plików, a następnie przetestować dostęp z klienta Windows i Linux oraz zmierzyć wydajność transferu danych.
- Instalacja pakietu samba na systemie Linux.
- Konfiguracja zasobu [Public] dostępnego tylko do odczytu dla wszystkich.
- Konfiguracja zasobu [Projects] z prawami zapisu dla grupy 'technicy'.
- Utworzenie bazy użytkowników Samby (smbpasswd).
- Zastosowanie uprawnień na poziomie systemu plików (chmod/chown/ACL).
- Otwarcie portów 139 i 445 w firewallu.
- Weryfikacja dostępu z klienta Windows/Linux (smbclient).
- Konfiguracja opcji 'browsing' i 'guest ok'.
- Analiza wydajności przesyłu danych (dd/pv).
- Udokumentowanie struktury pliku smb.conf.
1. Przed instalacją Samby sprawdź, czy nie ma już zainstalowanych konfliktujących pakietów:
dpkg -l | grep samba — w niektórych systemach domyślnie instalowany jest tylko Samb4.2. Twórz katalogi współdzielone PRZED edycją pliku smb.conf — np.
sudo mkdir -p /srv/samba/projects z odpowiednimi uprawnieniami: sudo chown root:technicy /srv/samba/projects.3. Baza haseł Samby (smbpasswd) jest oddzielna od haseł systemowych — każdy użytkownik Samby musi najpierw istnieć w systemie:
sudo useradd -M -s /sbin/nologin user1.4. Dodawanie użytkownika do Samby:
sudo smbpasswd -a user1 — system poprosi o hasło, które będzie używane do uwierzytelniania w Windows/Linux.5. W pliku smb.conf używaj poprawnej składni sekcji: nazwy w nawiasach kwadratowych [Public], [Projects] — każda sekcja definiuje osobny zasób współdzielony.
6. Parametr "valid users = @technicy" oznacza grupę systemową — utwórz ją poleceniem
sudo groupadd technicy i dodaj użytkowników: sudo usermod -aG technicy user1.7. Uprawnienia systemu plików (chmod/chown) mają pierwszeństwo przed Sambą — jeśli użytkownik ma dostęp w smb.conf, ale nie ma praw do plików w systemie, dostęp zostanie zablokowany.
8. Porty 139 (NetBIOS) i 445 (SMB directly over TCP/IP) otwórz w firewallu — nowoczesne systemy Windows używają portu 445.
9. Testuj z Windows poleceniem
net use * \\\\ADRES_IP\\Projects — w Windows 10/11 domyślnie SMBv1 jest wyłączony, więc upewnij się, że używasz SMBv2/v3.10. Testuj z Linuxa narzędziem smbclient:
smbclient -L //ADRES_IP -U user1 — lista zasobów powinna pokazać wszystkie skonfigurowane udziały.11. Wydajność przesyłu danych testuj poleceniami
dd if=/dev/zero of=/mnt/sambatest bs=1M count=100 i mierz czas — typowa sieć 1 Gbps powinna osiągać ~100 MB/s.12. Integracja z Active Directory (dla przyszłych zadań) wymaga instalacji Samba w trybie "ads" i konfiguracji Kerberos — na razie przygotuj strukturę smb.conf z opcjami "security = user" i "domain logons = yes".
Serwer plików Samba jest standardem udostępniania zasobów w środowiskach heterogenicznych, umożliwiając współdzielenie plików między systemami Linux i Windows bez dodatkowego oprogramowania po stronie klienta. Poprawna konfiguracja uprawnień na poziomie systemu plików (chmod/chown/ACL) ma pierwszeństwo przed ustawieniami Samby — bezpieczeństwo plików zaczyna się od systemu operacyjnego. Baza haseł Samby (smbpasswd) jest oddzielna od haseł systemowych, co wymaga zarządzania dwoma zestawami poświadczeń, ale zwiększa elastyczność. Format uprawnień z użyciem grup systemowych (@technicy) pozwala na łatwe zarządzanie dostępem dla wielu użytkowników jednocześnie. Protokoły SMBv2/v3 zapewniają lepsze bezpieczeństwo i wydajność niż starszy SMBv1, który jest domyślnie wyłączony w nowszych systemach Windows. Wydajność sieci 1 Gbps pozwala na transfery rzędu 100 MB/s, co jest wystarczające dla większości zastosowań biurowych. Przygotowanie struktury do integracji z Active Directory ułatwia przyszłą migrację do pełnego kontrolera domeny. Podsumowując, Samba jest dojrzałym rozwiązaniem do współdzielenia plików, oferującym kompatybilność z ekosystemem Windows.
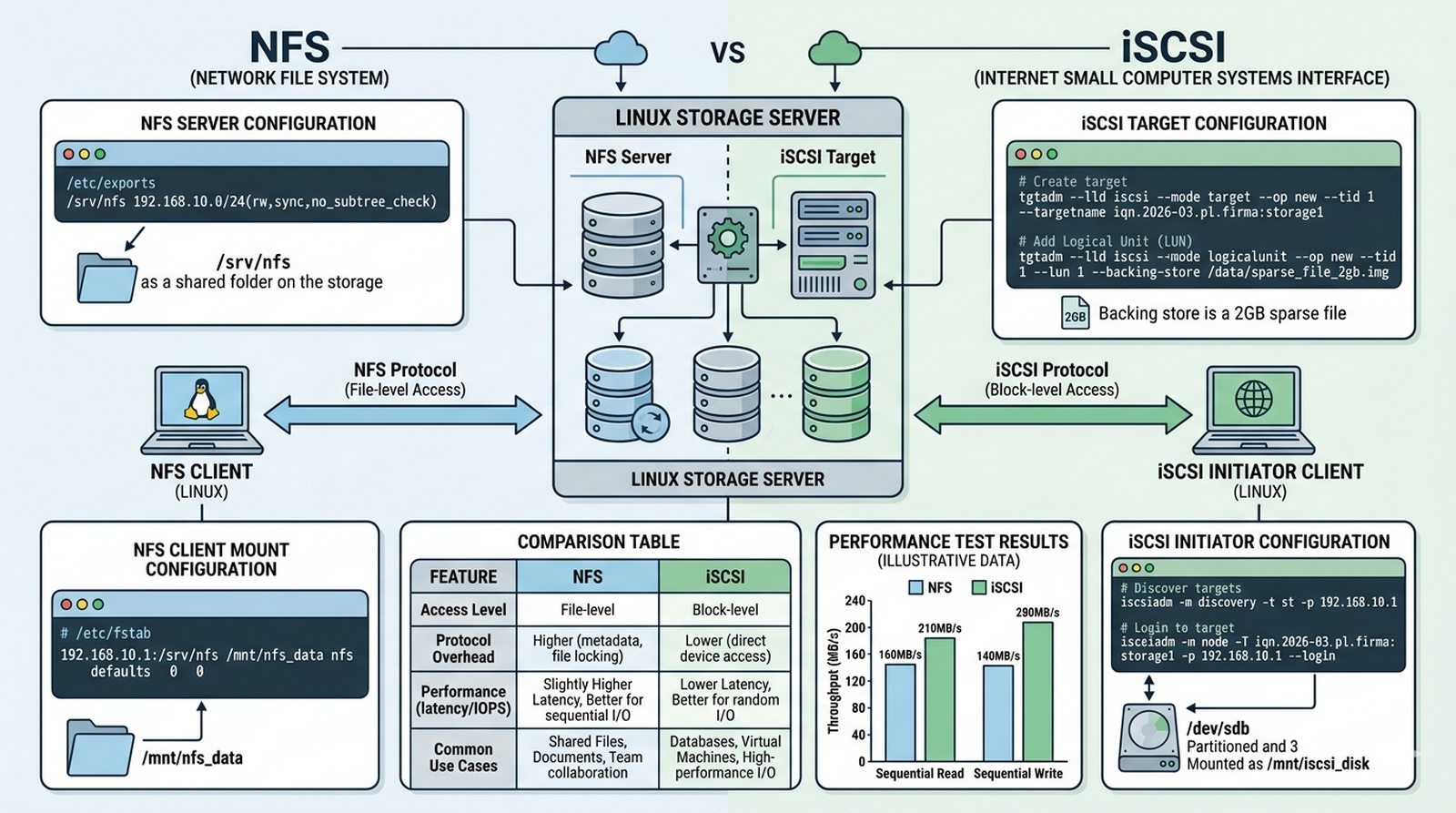
Wykład 5 Sieciowe systemy plików (NFS), pamięci masowe w sieciach SAN/NAS, protokół blokowy iSCSI.
W środowisku serwerowym Linux wymagane jest współdzielenie plików konfiguracyjnych i danych aplikacyjnych w sposób wydajny i przeźroczysty dla systemu — NFS zapewnia dostęp plikowy, gdzie zdalny katalog widoczny jest jak lokalny. Dodatkowo maszyny wirtualne potrzebują dedykowanych dysków, ale fizyczne serwery mają ograniczoną liczbę slotów — iSCSI pozwala udostępnić surowy dysk (LUN) przez sieć, który VM widzi jako lokalny dysk. Twoim zadaniem jest zainstalować i skonfigurować serwer NFS (eksport /srv/nfs), skonfigurować klienta NFS z wpisem w /etc/fstab, zainstalować iSCSI Target (tgt), utworzyć plik-obraz 2GB jako LUN i udostępnić go klientowi iSCSI, a następnie porównać wydajność NFS i iSCSI oraz udokumentować różnice między dostępem plikowym a blokowym.
- Instalacja pakietu nfs-kernel-server na Linuxie.
- Eksport katalogu /srv/nfs dla podsieci LAN z uprawnieniami rw i sync.
- Konfiguracja montowania zasobu NFS na kliencie Linux z wpisem w /etc/fstab.
- Instalacja pakietu tgt (lub open-iscsi) do obsługi iSCSI Target.
- Utworzenie pliku-obrazu (sparse file) o rozmiarze 2GB jako dysku iSCSI.
- Konfiguracja 'Target' iSCSI z ACL ograniczonym do IQN klienta.
- Weryfikacja widoczności dysku sieciowego na kliencie przy użyciu lsblk.
- Formatowanie i montowanie dysku iSCSI.
- Analiza wydajności przesyłu danych między NFS a iSCSI.
- Dokumentacja różnic między dostępem plikowym (NFS) a blokowym (iSCSI).
1. Pakiet nfs-kernel-server instaluj poleceniem
sudo apt install nfs-kernel-server nfs-common — nfs-common zawiera klienta NFS.2. Eksporty NFS definiuj w pliku /etc/exports — każda linia to osobny eksport z formatem:
/srv/nfs 192.168.10.0/24(rw,sync,no_subtree_check,no_root_squash).3. Opcja
no_root_squash pozwala rootowi klienta na dostęp jako root na serwerze — używaj jej ostrożnie, najlepiej tylko w środowisku lab. Zwykle stosuje się root_squash.4. Po modyfikacji /etc/exports uruchom
sudo exportfs -ra — polecenie to aktualizuje listę eksportów bez restartu usługi.5. Montowanie NFS w /etc/fstab:
serwer:/srv/nfs /mnt/nfs nfs defaults 0 0 — montowanie przy starcie systemu.6. UID/GID użytkowników muszą być identyczne po obu stronach — problemy z uprawnieniami NFS wynikają głównie z niezgodności ID użytkowników między serwerem a klientem.
7. iSCSI Target wymaga pakietu tgt:
sudo apt install tgt — w nowszych dystrybucjach możesz też użyć targetcli (LIO).8. Plik-obraz dla iSCSI twórz jako sparse file:
sudo truncate -s 2G /srv/iscsi_disks/disk1.img — sparse file alokuje miejsce tylko w miarę potrzeby.9. IQN (iSCSI Qualified Name) klienta (Initiator) znajdziesz poleceniem
cat /etc/iscsi/initiatorname.iscsi — skopiuj go do konfiguracji Target ACL.10. Na kliencie iSCSI zainstaluj open-iscsi:
sudo apt install open-iscsi — usługa iscsid łączy się z Target i udostępnia dysk lokalnie.11. Po wykryciu dysku iSCSI (np. /dev/sdb) sformatuj go:
sudo mkfs.ext4 /dev/sdb i zamontuj: sudo mount /dev/sdb /mnt/iscsi.12. Wydajność testuj poleceniami
dd if=/dev/zero | nc serwer PORT dla NFS i porównuj z zapisem na dysku iSCSI — iSCSI powinien oferować mniejsze opóźnienia, NFS większą przepustowość dla małych plików.
NFS i iSCSI to dwa fundamentalnie różne podejścia do udostępniania zasobów dyskowych w sieci, każde z własnymi zastosowaniami. NFS (Network File System) to protokół plikowy, który udostępnia całe systemy plików — użytkownik widzi zdalny katalog jak lokalny, uprawnienia są mapowane przez UID/GID. iSCSI to protokół blokowy, który udostępnia surowy dysk (LUN), który system operacyjny widzi jako lokalne urządzenie blokowe i sam zarządza systemem plików. NFS jest prostszy w konfiguracji i idealny do współdzielenia plików konfiguracyjnych, kodów źródłowych i danych w trybie read-heavy. iSCSI oferuje mniejsze opóźnienia i lepszą wydajność dla obciążeń transactionalnych, takich jak bazy danych czy maszyny wirtualne. Sparse files są wydajnym sposobem alokacji miejsca dla dysków iSCSI — miejsce jest alokowane tylko w miarę zapisu danych. Synchronizacja UID/GID między serwerem a klientem NFS jest kluczowa dla spójności uprawnień. Podsumowując, wybór między NFS a iSCSI zależy od charakterystyki obciążenia i wymagań wydajnościowych.
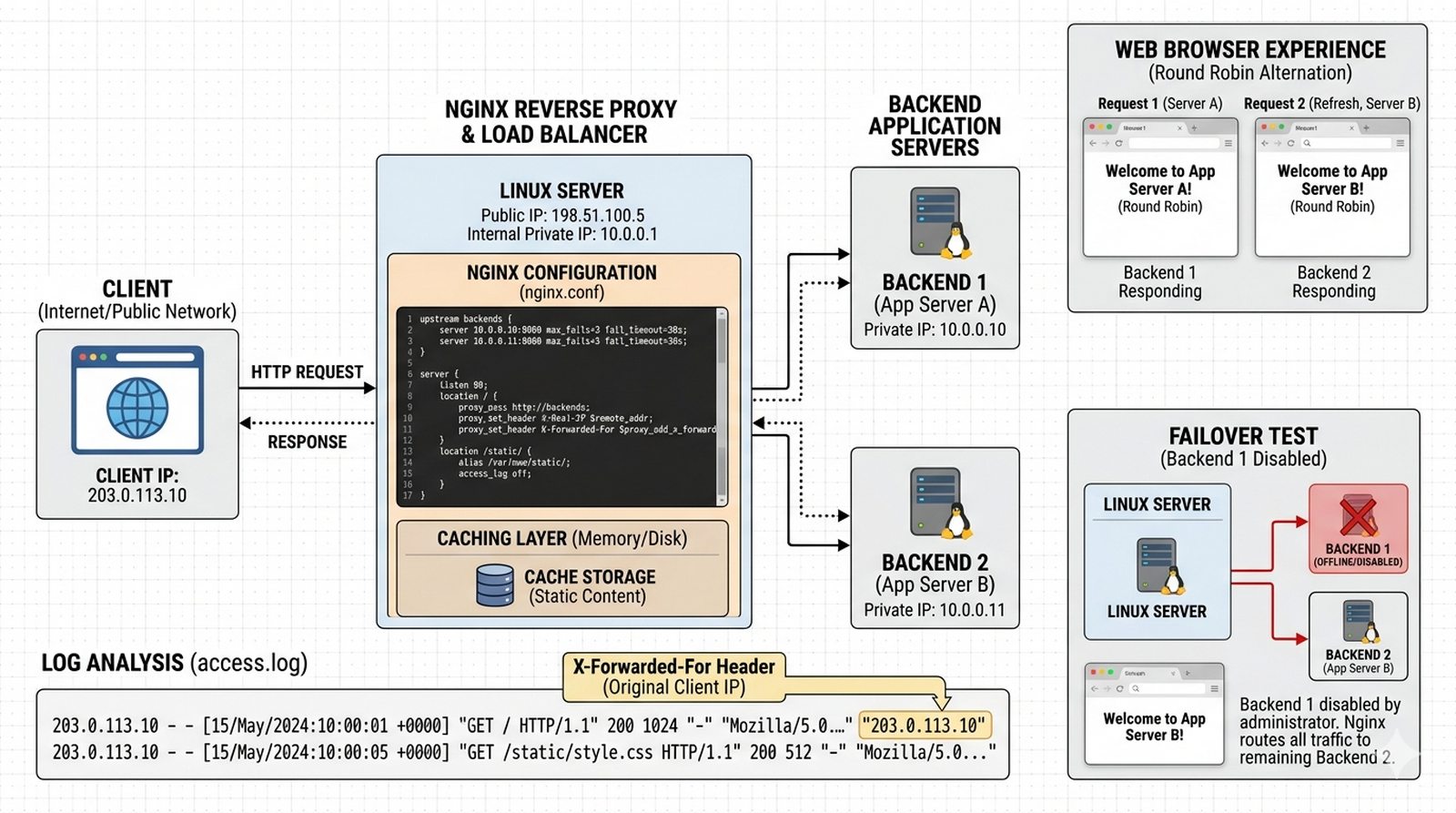
Wykład 6 Utrzymanie wysokiej dostępności usług HTTP, równoważenie obciążenia (Load Balancing), terminacja SSL/TLS.
Serwis WWW firmy cieszy się rosnącą popularnością i pojedynczy serwer nie jest w stanie obsłużyć całego ruchu, co powoduje wolne ładowanie strony i utratę klientów. Administrator zdecydował o wdrożeniu warstwy pośredniczącej (Reverse Proxy) opartej na Nginx, która będzie rozkładać zapytania użytkowników na dwa serwery aplikacyjne (Backend) oraz cache'ować.pliki statyczne. Dodatkowo Nginx ukrywa strukturę wewnętrznej sieci przed użytkownikami zewnętrznymi. Twoim zadaniem jest zainstalować Nginx na trzech maszynach (1x Proxy, 2x Backend), skonfigurować upstream z dwoma backendami i metodą Round Robin, skonfigurować proxy_pass z nagłówkami X-Forwarded-For, skonfigurować health check i cache statycznych plików, a następnie przetestować działanie load balancingu i failover przy wyłączeniu jednego backendu.
- Instalacja nginx na trzech maszynach (1x Proxy, 2x Backend).
- Konfiguracja bloku 'upstream' w Nginx Proxy zawierającego adresy backendów.
- Implementacja metody równoważenia ruchu (np. Round Robin lub Least Conn).
- Konfiguracja 'proxy_pass' przekierowującego ruch HTTP.
- Dodanie nagłówków X-Forwarded-For w celu przekazania oryginalnego IP klienta.
- Weryfikacja działania poprzez odświeżanie strony (zmiana treści z różnych backendów).
- Konfiguracja 'Health check' dla serwerów backendowych.
- Implementacja prostego cache'u dla plików statycznych.
- Analiza logów access.log na proxy i serwerach końcowych.
- Dokumentacja korzyści płynących z użycia Reverse Proxy (bezpieczeństwo, skalowalność).
1. Architektura: 3 maszyny Linux — jedna z Nginx jako Proxy, dwie z Apache/Nginx jako Backend — połącz je w GNS3 w osobnej podsieci (np. 192.168.20.0/24).
2. Na backendach wyłącz default site i skonfiguruj prostą stronę testową:
echo "Serwer 1" | sudo tee /var/www/html/index.html — na drugim serwerze "Serwer 2".3. Konfiguracja upstream w pliku /etc/nginx/sites-available/reverse_proxy — definicja dwóch backendów:
server 192.168.20.101; i server 192.168.20.102;.4. Nagłówki X-Forwarded-For dodawaj ZAWSZE w konfiguracji proxy:
proxy_set_header X-Forwarded-For $remote_addr; — backend musi widzieć oryginalny IP klienta.5. Metoda równoważenia Round Robin jest domyślna w Nginx — Least Connections ustawiasz przez
least_conn; w bloku upstream.6. Health check w Nginx realizuj przez parametry:
server 192.168.20.101 max_fails=3 fail_timeout=30s; — serwer zostanie tymczasowo wyłączony po 3 niepowodzeniach.7. Cache dla plików statycznych konfiguruj w bloku location:
proxy_cache_valid 200 1h; — cache'uje odpowiedzi 200 na godzinę.8. Logi access.log analizuj poleceniem
tail -f /var/log/nginx/access.log — obserwuj, jak żądania są rozkładane między backendy.9. Aby przetestować automatyczne przekierowanie przy awarii backendu: wyłącz jeden serwer poleceniem
sudo systemctl stop apache2 i obserwuj, czy Nginx kieruje cały ruch na drugi.10. Nagłówek X-Real-IP dodawaj dla kompatybilności z niektórymi aplikacjami:
proxy_set_header X-Real-IP $remote_addr; — niektóre aplikacje używają tego nagłówka do logowania.11. Weryfikuj łączność z backendami z poziomu serwera proxy:
curl -I http://192.168.20.101 i curl -I http://192.168.20.102 — oba powinny zwracać HTTP 200.12. Dokumentuj w sprawozdaniu diagram architektury z zaznaczeniem przepływu żądań — pokazuj, jak żądanie klienta przechodzi przez Proxy do Backend i z powrotem.
Reverse Proxy Nginx z Load Balancerem jest kluczowym elementem architektury wysokiej dostępności, rozkładającym ruch między wiele serwerów backendowych. Round Robin jako domyślna metoda równoważenia zapewnia równomierne rozłożenie requestów, podczas gdy Least Connections kieruje ruch do serwera z najmniejszą liczbą aktywnych połączeń. Nagłówki X-Forwarded-For i X-Real-IP są niezbędne do przekazania oryginalnego IP klienta do backendów — bez nich aplikacja widzi tylko adres proxy. Health check (max_fails, fail_timeout) automatycznie wyłącza niedziałające serwery, kierując ruch wyłącznie na zdrowe instancje. Cache'owanie plików statycznych znacząco redukuje obciążenie serwerów backendowych i czas odpowiedzi. Logi access.log na proxy i backendach pozwalają na analizę rozkładu ruchu i debugging problemów. Automatyczny failover przy awarii backendu zapewnia ciągłość działania aplikacji nawet przy częściowej awarii infrastruktury. Podsumowując, Reverse Proxy Nginx to praktyczne i wydajne rozwiązanie do budowy odpornej architekturyWWW.
Wykład 8 Paradygmat Infrastructure as Code (IaC), narzędzia automatyzacji (Ansible, Terraform), idempotentność konfiguracji.
Zarządzanie wieloma routerami i serwerami ręcznie jest czasochłonne i obarczone ryzykiem błędu ludzkiego — zmiana hasła czy reguły firewalla na 10 routerach oznacza 10 ręcznych połączeń, gdzie jedno przeoczenie może spowodować lukę bezpieczeństwa. Firma przechodzi na model Infrastructure as Code (IaC), gdzie konfiguracja definiowana jest w plikach tekstowych, a narzędzie automatycznie wprowadza zmiany na wszystkich urządzeniach. Twoim zadaniem jest zainstalować Ansible na Linux (Control Node), przygotować plik inventory z adresami routerów, skonfigurować SSH kluczami, zainstalować kolekcję community.routeros, napisać playbook konfigurujący MOTD Banner i reguły firewalla, a następnie uruchomić playbook i zweryfikować idempotentność (uruchomić dwukrotnie i porównać wyniki).
- Instalacja ansible na maszynie Linux Control Node.
- Przygotowanie pliku 'inventory' z adresami routerów i serwerów.
- Konfiguracja uwierzytelniania SSH za pomocą kluczy (passwordless).
- Stworzenie Playbooka YAML do konfiguracji systemowej MikroTika (moduł routeros).
- Stworzenie Playbooka do aktualizacji pakietów na serwerach Linux.
- Weryfikacja idempotentności (uruchomienie playbooka dwa razy).
- Użycie zmiennych (Variables) dla różnych środowisk.
- Udostępnienie wyników działania (Ansible facts).
- Konfiguracja powiadomień po udanym wdrożeniu.
- Udokumentowanie struktury katalogów projektu Ansible.
1. Ansible instalowany jest na maszynie Linux (Control Node):
sudo apt update && sudo apt install ansible — sprawdź wersję poleceniem ansible --version.2. Struktura katalogów Ansible:
~/ansible/ z podkatalogami: inventory/hosts, playbooks/, roles/, group_vars/ — organizacja jest kluczowa dla skalowalności.3. Plik inventory (hosts) definiujesz w formacie INI:
[mikrotiks] i pod spodem adresy IP lub nazwy hostów — np. router1 ansible_host=192.168.10.1 ansible_user=admin.4. SSH bez hasła konfiguruj przez wygenerowanie klucza:
ssh-keygen -t ed25519 i skopiowanie klucza publicznego na routery: ssh-copy-id -i ~/.ssh/id_ed25519.pub admin@192.168.10.1.5. Kolekcję community.routeros zainstaluj:
ansible-galaxy collection install community.routeros — zawiera ona moduł community.routeros.command do wykonywania poleceń.6. Playbook ma strukturę YAML:
- hosts: mikrotiks, tasks: i lista zadań — każde zadanie wykonuje moduł z określonymi parametrami.7. Idempotentność testujesz uruchamiając playbook DWA RAZY — jeśli przy drugim uruchomieniu nie ma zmian (changed=0), konfiguracja jest idempotentna.
8. Zmienne (variables) w Ansible definiujesz w pliku
group_vars/mikrotiks.yml: ntp_servers: i lista serwerów — playbook może ich używać zamiast hardkodowanych wartości.9. Ansible facts to dane automatycznie zbierane z hostów:
ansible_facts['net_model'], ansible_facts['net_version'] — wyświetl je poleceniem ansible all -m setup.10. Moduł firewalla w RouterOS:
community.routeros.api pozwala na bezpośrednie modyfikacje reguł — ale community.routeros.command z wywołaniami CLI jest prostszy na początek.11. Powiadomienia po wdrożeniu skonfiguruj przez dodanie
notify: Send Slack message w playbooku i odpowiedniego handlera — mogą wysyłać informacje o statusie wdrożenia.12. Dokumentuj strukturę katalogów i rolę każdego pliku — sprawozdanie powinno zawierać diagram pokazujący przepływ wykonywania playbooka od Control Node do zarządzanych hostów.
Ansible jako narzędzie Infrastructure as Code (IaC) rewolucjonizuje zarządzanie infrastrukturą, pozwalając na deklaratywne definesowanie pożądanego stanu systemów. Idempotentność — kluczowa właściwość playbooków — oznacza, że wielokrotne uruchomienie tego samego playbooka nie powoduje zmian, jeśli system jest już w pożądanym stanie. Kolekcja community.routeros rozszerza Ansible o moduły do zarządzania urządzeniami MikroTik, umożliwiając konfigurację przez API lub CLI. Struktura katalogów Ansible (inventory, playbooks, roles, group_vars) zapewnia organizację i możliwość wielokrotnego użycia kodu. Uwierzytelnianie SSH kluczami (passwordless) eliminuje potrzebę ręcznego wprowadzania haseł i umożliwia automatyzację. Zmienne (variables) pozwalają na sparametryzowanie playbooków dla różnych środowisk bez modyfikacji kodu. Ansible facts dostarczają automatycznie zbierane informacje o hostach, które mogą być używane w warunkach i konfiguracjach. Podsumowując, Ansible znacząco redukuje czas i ryzyko błędu przy zarządzaniu dużą infrastrukturą, umożliwiając ciągłą automatyzację zmian.
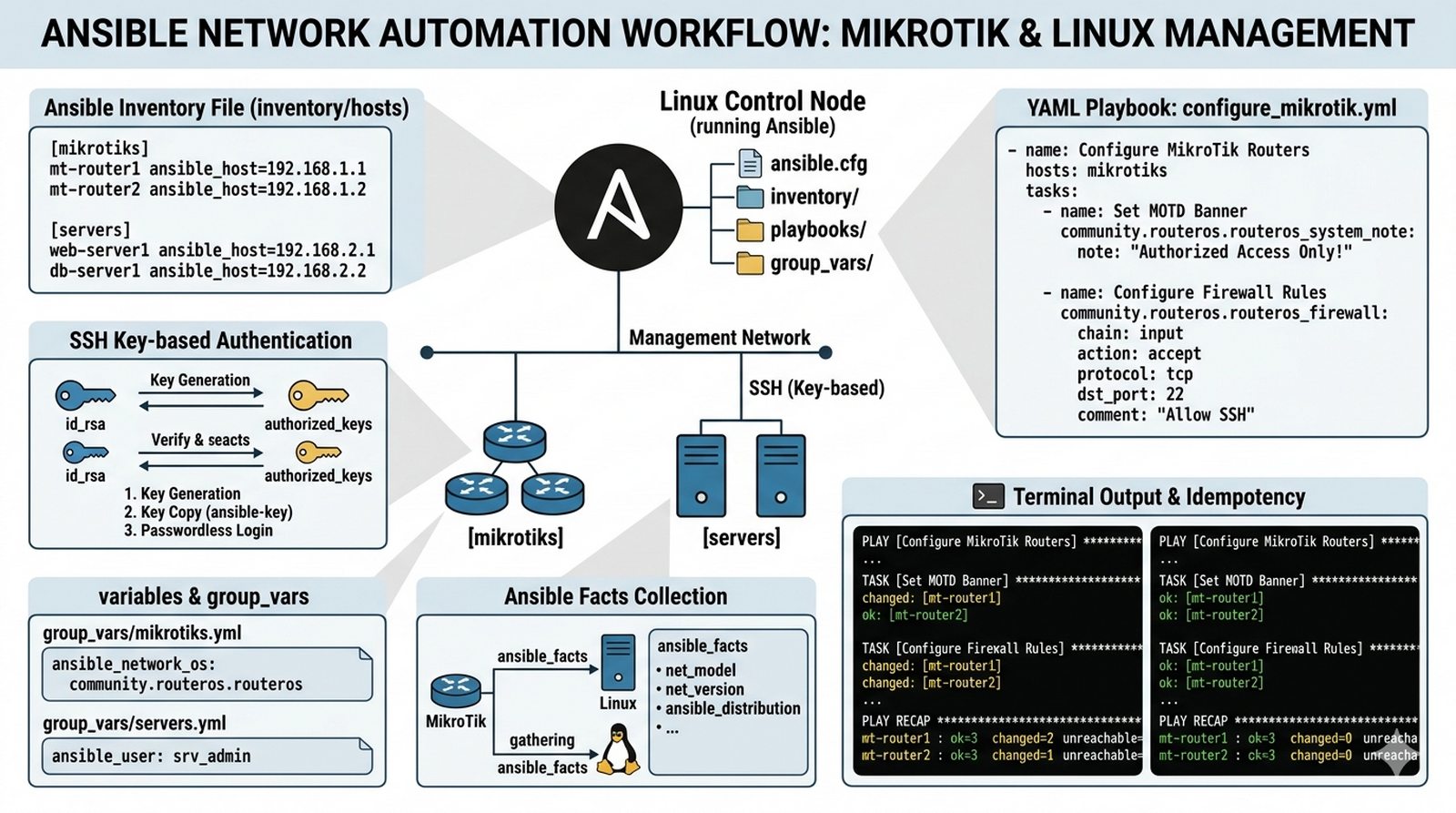
Wykład 8 Mikrousługi, konteneryzacja (Docker), orkiestracja kontenerów, architektura Kubernetes.
Firma migruje swoje aplikacje z maszyn wirtualnych do kontenerów (Docker/Kubernetes), aby ułatwić skalowanie, szybsze wdrażanie poprawek i zmniejszenie kosztów infrastruktury. Tradycyjne VM są ciężkie i wolne, podczas gdy kontenery startują w sekundach, a Kubernetes automatycznie zarządza replikami i przywraca awaryjne instancje (self-healing). Administrator musi przygotować lekkie środowisko K3s na Linux w labie GNS3. Twoim zadaniem jest zainstalować K3s na węźle Master, opcjonalnie dodać Worker, utworzyć Deployment nginx z 3 replikami, stworzyć Service NodePort, zweryfikować czy pody działają i są dostępne z przeglądarki, przetestować self-healing usuwając jeden pod i obserwując jego automatyczne odtworzenie, a następnie udokumentować różnice między VM a kontenerami.
- Instalacja K3s na węźle Master przy użyciu skryptu instalacyjnego.
- Pobranie pliku konfiguracyjnego 'kubeconfig' i weryfikacja statusu węzłów (kubectl get nodes).
- Przygotowanie pliku YAML z definicją 'Deployment' (np. nginx z 3 replikami).
- Przygotowanie pliku YAML z definicją 'Service' typu NodePort.
- Weryfikacja uruchomienia podów (kubectl get pods) na klastrze.
- Test dostępności aplikacji z przeglądarki/konsoli Linuxa zewnętrznego.
- Symulacja awarii jednego poda i obserwacja mechanizmu 'self-healing'.
- Przegląd logów kontenera (kubectl logs).
- Analiza zużycia zasobów przez pody (kubectl top).
- Dokumentacja różnic w zarządzaniu między tradycyjnym VM a kontenerem.
1. K3s instaluje się jednym poleceniem:
curl -sfL https://get.k3s.io | sh - — instalator automatycznie konfiguruje kubeconfig w /etc/rancher/k3s/k3s.yaml.2. Token do dołączenia węzłów Worker znajdziesz w:
cat /var/lib/rancher/k3s/server/node-token — token jest wymagany przy instalacji workerów.3. Plik kubeconfig skopiuj na klienta:
mkdir -p ~/.kube && sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config — następnie ustaw uprawnienia: sudo chown $(id -u):$(id -g) ~/.kube/config.4. Polecenie kubectl jest dostępne po zainstalowaniu K3s — sprawdź status klastra:
kubectl get nodes — powinien pokazać węzeł Master w stanie Ready.5. Deployment tworzysz plikiem YAML:
kubectl create deployment nginx --image=nginx --replicas=3 --dry-run=client -o yaml > nginx-deployment.yaml — opcja --dry-run pozwala wygenerować szablon bez tworzenia obiektu.6. Serwis NodePort eksponuje aplikację na porcie (30000-32767) — poeksperymentuj:
kubectl get svc aby zobaczyć przypisany port.7. Self-healing testujesz usuwając pod:
kubectl delete pod nazwa-poda — Kubernetes automatycznie utworzy nowy pod do zastąpienia usuniętego.8. Logi kontenera przeglądaj:
kubectl logs nazwa-poda — polecenie to pokazuje stdout kontenera, przydatne do debugowania.9. Zużycie zasobów:
kubectl top nodes i kubectl top pods — wymaga zainstalowania Metrics Server: kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml.10. Pody mogą utknąć w stanie Pending z powodu braku zasobów — w GNS3 przydziel minimum 1 vCPU i 1GB RAM do maszyny z K3s, w przeciwnym razie scheduler nie będzie mógł ich zaplanować.
11. Ingress Controller nie jest wymagany w tym zadaniu, ale warto wiedzieć, że K3s instaluje traefik jako domyślny — umożliwia to bardziej zaawansowane routingowanie żądań.
12. Dokumentuj różnice: VM to pełna wirtualizacja (osobne jądro, izolowane zasoby), kontener to współdzielenie jądra hosta z mniejszą izolacją, ale większą wydajnością i szybszym startem.
K3s to lekka dystrybucja Kubernetes idealna do środowisk laboratoryjnych i edge computing, oferująca pełną funkcjonalność orkiestracji kontenerów przy minimalnym zużyciu zasobów. Self-healing — kluczowa funkcja Kubernetes — automatycznie rekonstruuje pody po awarii, co zapewnia wysoką dostępność aplikacji bez interwencji administratora. Deployment z wieloma replikami zapewnia skalowanie horyzontalne i redundancję — równoważenie obciążenia dystrybuuje ruch między replikami. Service typu NodePort eksponuje aplikację na porcie dostępnym z zewnątrz, umożliwiając testowanie i dostęp z przeglądarki. Metrics Server dostarcza danych o zużyciu zasobów, niezbędnych do planowania pojemności i optymalizacji. Plik kubeconfig jest kluczowy do zarządzania klastrem — jego bezpieczne przechowywanie i transport jest fundamentem bezpieczeństwa. K3s instaluje Traefik jako domyślny Ingress Controller, umożliwiając zaawansowane routingowanie żądań HTTP. Podsumowując, konteneryzacja z Kubernetes/K3s jest przyszłością wdrażania aplikacji, oferującą skalowalność, odporność i portability.
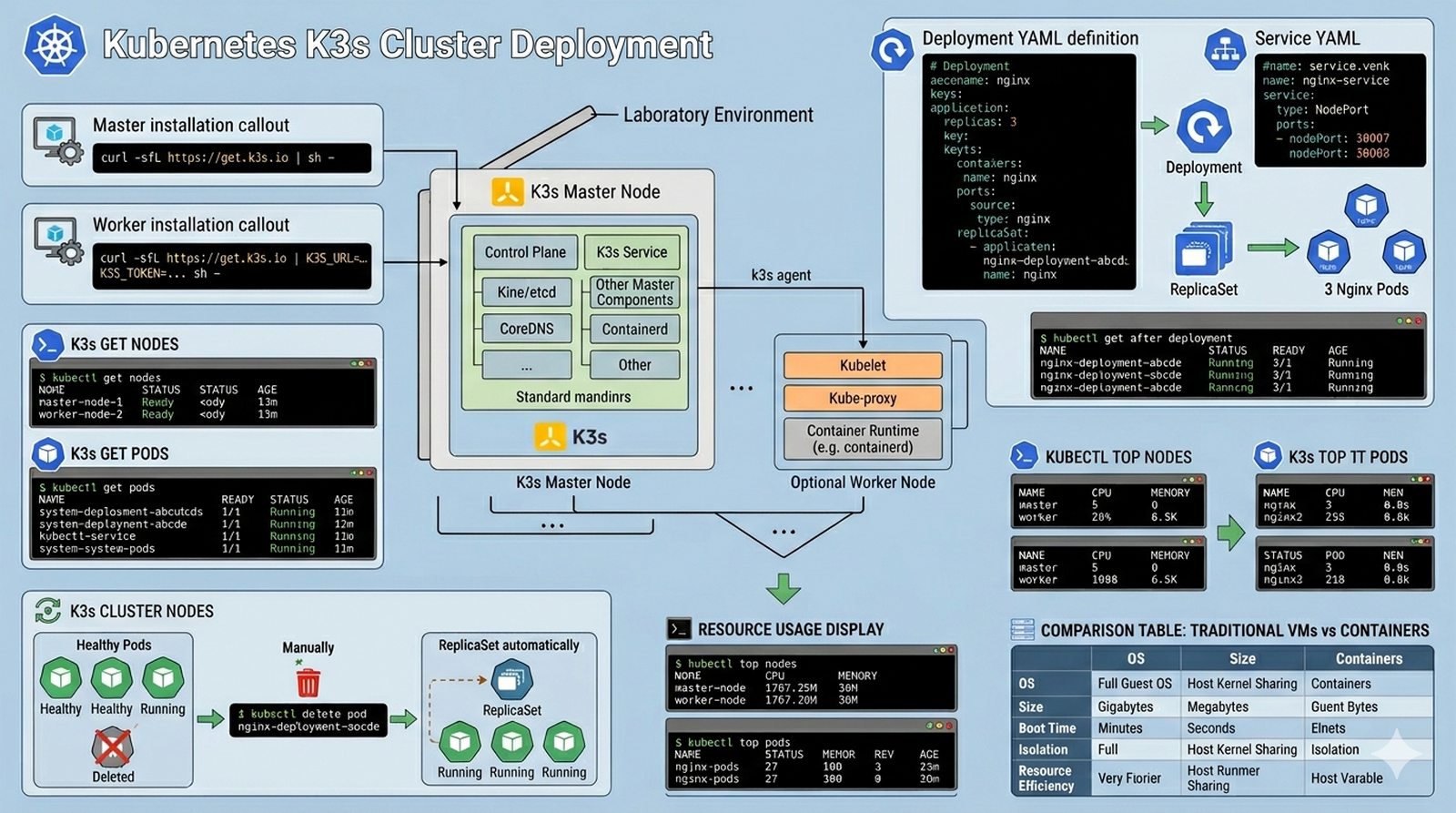
Wykład 9 Metodyka troubleshootingu sieciowego, narzędzia diagnostyczne, skanowanie podatności i analiza pakietów.
Po wdrożeniu wszystkich usług administrator musi upewnić się, że sieć jest bezpieczna i nie zawiera luk konfiguracyjnych — otwarty port Telnet czy nieszyfrowane hasła to poważne zagrożenia, które atakujący mogą wykorzystać. Audyt bezpieczeństwa to proces systematycznego badania sieci przy użyciu narzędzi, które mają też atakujący. Twoim zadaniem jest przeprowadzić audyt bezpieczeństwa: wykonać Syn Scan Nmap na całą podsieć, zidentyfikować wersje usług (-sV), użyć skryptów NSE do wykrycia słabych haseł, uruchomić Wireshark i przechwycić ruch HTTP/Telnet aby sprawdzić czy hasła przesyłane są plaintext, zweryfikować czy firewallowe porty są stealth (nieodpowiadające na skanowanie), a następnie stworzyć raport z listą podatności i rekomendacjami mitygacyjnymi.
- Przeprowadzenie skanowania typu 'Syn Scan' (-sS) na całą podsieć LAN.
- Identyfikacja wersji systemów i usług (-sV, -O).
- Wykrycie słabych haseł przy użyciu skryptów Nmap Scripting Engine (NSE).
- Przechwycenie ruchu HTTP/Telnet w Wiresharku i odczytanie danych logowania.
- Weryfikacja poprawnego działania firewalla MikroTik (czy porty 'stealth' są niewidoczne).
- Analiza przebiegu traceroute pod kątem filtracji ICMP.
- Stworzenie raportu z listą znalezionych podatności i rekomendacjami.
- Udokumentowanie '3-way handshake' przechwyconego w Wiresharku.
- Analiza flag TCP (SYN, ACK, RST) w nieudanych próbach połączenia.
- Użycie filtrów w Wiresharku do odfiltrowania zbędnego ruchu (np. ip.addr == ...).
1. Syn Scan (-sS) wymaga uprawnień root/sudo — w GNS3 uruchom skanowanie z konta root:
sudo nmap -sS -sV 192.168.10.0/24.2. OID wersji systemu (-O) w routerach MikroTik może nie działać precyzyjnie — skup się na wersji RouterOS:
nmap -sV --script=fingerprint-finger 192.168.10.1.3. Skrypty NSE (Nmap Scripting Engine) pozwalają na wykrywanie podatności:
nmap --script vuln 192.168.10.0/24 — uruchom to z ostrożnością w środowisku produkcyjnym.4. Słabe hasła wykrywaj skryptami:
nmap --script ftp-anon,smtp-enum-users,ssh-brute 192.168.10.0/24 — w środowisku lab używaj słabych haseł celowo do testów.5. Wireshark w GNS3 "podłączysz" do połączenia klikając prawym przyciskiem na link i wybierając "Start Capture" — ruch będzie przechwytywany w czasie rzeczywistym.
6. Podczas capture Wiresharka wyślij testowy login HTTP (np. przez telnet) — w filtrze wpisz
http.request.method == "POST" aby zobaczyć dane w plaintext.7. Firewallowe porty stealth weryfikujesz przez skanowanie z zewnątrz — port stealth nie pokazuje się w wyniku skanowania, ale ICMP może nadal działać.
8. 3-way handshake w Wiresharku: obserwuj sekwencję SYN → SYN-ACK → ACK — pierwsze trzy pakiety tworzą połączenie TCP, ich brak oznacza problem z firewallem.
9. Flagi TCP analizuj w Wiresharku: FIN oznacza normalne zamknięcie, RST (Reset) oznacza odmowę, SYN to żądanie połączenia, ACK potwierdza otrzymanie danych.
10. Filtry w Wiresharku:
ip.addr == 192.168.10.1 (ruch z/do IP), tcp.port == 80 (ruch HTTP), tcp.flags.reset == 1 (pakiety RST).11. Traceroute w Windows (
tracert) używa ICMP, w Linux (traceroute) domyślnie UDP — oba pokazują hops, ale filtracja ICMP może ukryć część ścieżki.12. Raport z audytu powinien zawierać: listę otwartych portów i usług, ocenę podatności (krytyczna/wysoka/średnia/niska), rekomendacje mitygacyjne — np. wyłączenie Telnetu czy zmiana domyślnych haseł.
Audyt bezpieczeństwa przy użyciu Nmap i Wireshark jest fundamentalnym elementem procesu zabezpieczania infrastruktury sieciowej. Syn Scan (-sS) wymaga uprawnień root, ale dostarcza dokładnych informacji o stanach portów bez pełnego nawiązania połączenia. Wireshark pozwala na głęboką analizę ruchu sieciowego, w tym przechwytywanie plaintext credentials w nieszyfrowanych protokołach (HTTP, Telnet, FTP). 3-way handshake TCP jest podstawą diagnostyki problemów z połączeniami — brak którejkolwiek z flag (SYN, SYN-ACK, ACK) wskazuje na problem z firewall lub routing. Porty stealth, które nie odpowiadają na skanowanie, są pożądanym stanem dla usług niewidocznych zewnętrznie. Skrypty NSE pozwalają na automatyczne wykrywanie podatności, ale powinny być używane ostrożnie — niektóre mogą zakłócać działanie usług. Raport z audytu powinien zawierać listę otwartych portów, ocenę ryzyka i konkretne rekomendacje mitygacyjne z priorytetami. Filtracja ICMP może utrudniać diagnostykę traceroute, ale jest powszechną praktyką bezpieczeństwa. Podsumowując, regularne audyty bezpieczeństwa są niezbędne do utrzymania bezpiecznej infrastruktury.
Wykład 10 i Wykład 5 Projektowanie sieci odpornych na awarie, redundancja bram domyślnych, protokół VRRP.
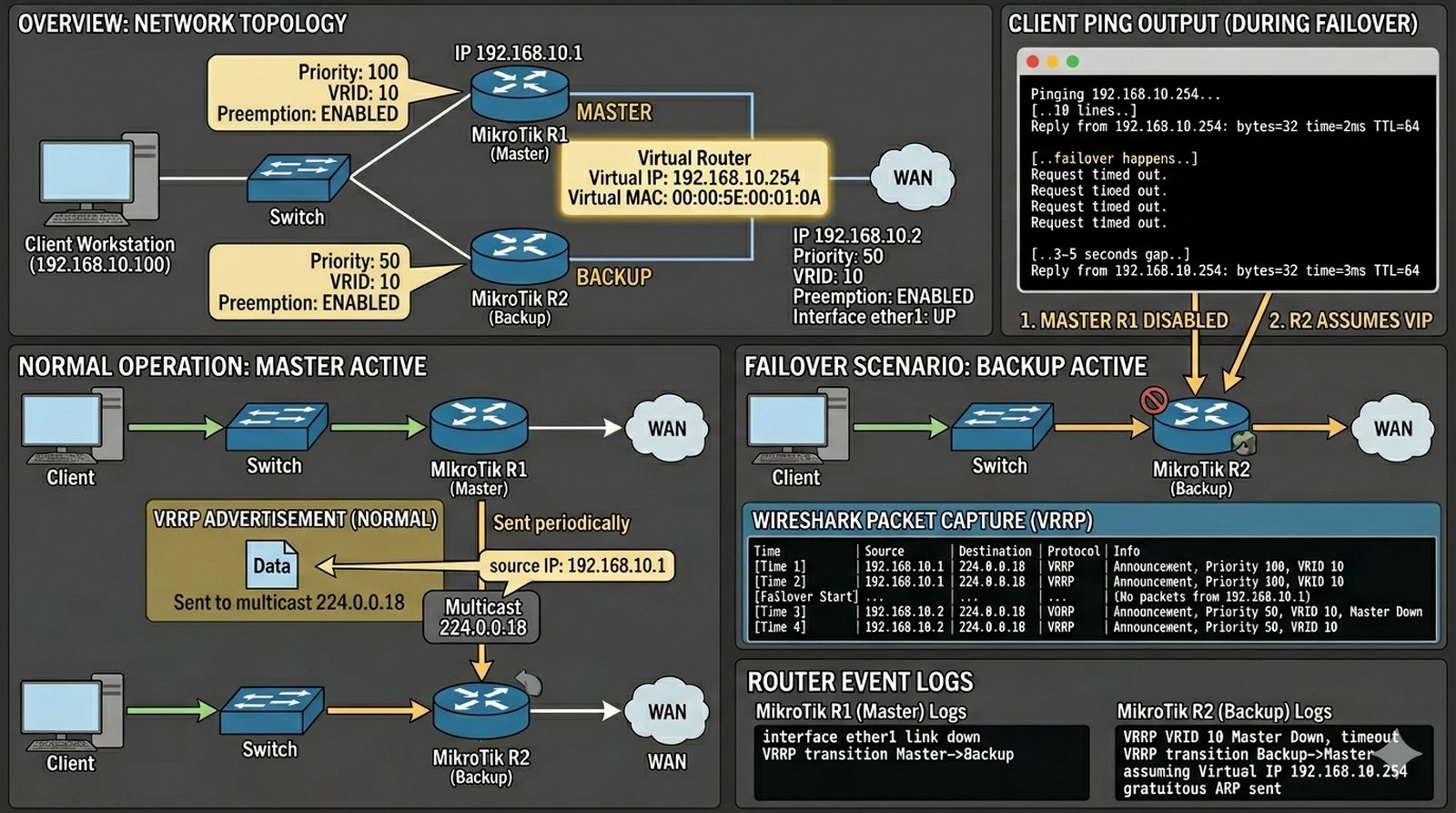
Router brzegowy jest pojedynczym punktem awarii (SPOF) dla całej firmy — jeśli ulegnie awarii, wszyscy tracą dostęp do Internetu i usług, a administrator dostaje telefon od rozgniewanych pracowników. Aby zapewnić ciągłość działania, administrator zdecydował o wdrożeniu drugiego routera MikroTik i skonfigurowaniu protokołu VRRP (Virtual Router Redundancy Protocol), gdzie oba routery współdzielą jeden wirtualny adres IP (np. 192.168.10.254) jako bramę domyślną dla stacji roboczych. Drugi router (Backup) automatycznie przejmuje rolę, gdy główny (Master) przestaje działać. Twoim zadaniem jest dodać drugi router do topologii, skonfigurować VRRP z vrid=10 i priorytetami (Master: 100, Backup: 50), skonfigurować wirtualny adres IP, przetestować failover (wyłączyć Master i obserwować pingi klienta), zmierzyć czas przełączenia i liczbę zgubionych pakietów, a następnie udokumentować mechanizm działania VRRP i wirtualnego adresu MAC.
- Dodanie drugiego routera MikroTik do topologii LAN.
- Konfiguracja interfejsu VRRP na obu routerach z tym samym ID (vrid).
- Ustawienie wirtualnego adresu IP (np. 192.168.10.254/24).
- Konfiguracja priorytetów (Master: 100, Backup: 50).
- Ustawienie mechanizmu 'preemption' (powrót roli po naprawie).
- Weryfikacja statusu VRRP (show vrrp).
- Test 'failover' poprzez wyłączenie interfejsu lub całego routera Master.
- Monitorowanie pingu od strony klienta podczas przełączenia (liczba zgubionych pakietów).
- Udokumentowanie pakietów ogłoszeń VRRP (advertisements) w Wiresharku.
- Konfiguracja skryptów 'on-master' i 'on-backup' na ruterze (opcjonalnie).
1. Dodaj drugi router MikroTik do topologii GNS3 — oba routery powinny być w tej samej podsieci na ether2 (np. 192.168.10.0/24), połączone przez przełącznik (Cloud lub Switch).
2. VRRP wymaga identycznego VRID po obu stronach — użyj dowolnej wartości (np. 10), która będzie taka sama na obu routerach.
3. Wirtualny adres IP (192.168.10.254) przypisz do interfejsu VRRP, NIE do fizycznego interfejsu ether2 — stacje robocze używają tego VIP jako bramy domyślnej.
4. Router z wyższym priorytetem (Master, np. 100) automatycznie "przejmuje" wirtualny adres — Backup (50) aktywuje się, gdy Master przestanie wysyłać advertisements.
5. Preemption pozwala Masterowi na powrót po naprawie — jeśli wyłączysz preemption, router Backup pozostanie Masterem do końca sesji, nawet po naprawieniu oryginalnego Mastera.
6. Test failover: na Masterze wyłącz interfejs ether2 (
/interface set ether2 disabled=yes) lub cały router — obserwuj w logach Backup: /log print where topics~"vrrp".7. Stacja kliencka podczas failover powinna zauważyć przerwę — przy dobrze skonfigurowanym VRRP (< 5s) przerwa wynosi ok. 3-4 sekundy, co jest akceptowalne dla większości aplikacji.
8. Wireshark podczas failover pokazuje pakiety advertisements VRRP (multicast 224.0.0.18) — Master wysyła je co 1 sekundę, Backup nasłuchuje i po 3 nieodebranych advertisements przejmuje rolę.
9. Multicast 224.0.0.18 wymaga, aby przełącznik między routerami prawidłowo obsługiwał multicast — w GNS3 Cloud/Switch obsługuje to domyślnie, ale w realnym sprzęcie może wymagać konfiguracji.
10. Skrypty on-master i on-backup (opcjonalne) pozwalają na automatyczne akcje przy zmianie roli — np. wysłanie emaila administratorowi o awarii.
11. Wirtualny adres MAC VRRP (00:00:5E:00:01:VRID w hex) jest kluczowy — stacje robocze "widzą" jeden stały adres MAC bramy, więc nie muszą zmieniać tablicy ARP po failover.
12. Dokumentuj w sprawozdaniu tabelę stanów: kto jest Masterem, jaki jest VIP, ile pakietów zostało zgubionych przy failover — zmierz czas przełączenia (mierz pingi klienta podczas wyłączenia Mastera).
VRRP (Virtual Router Redundancy Protocol) jest standardem przemysłowym do zapewnienia redundancji bramy domyślnej, eliminując pojedynczy punkt awarii (SPOF) w infrastrukturze sieciowej. Wybór routera Master opiera się na priorytecie — router z wyższym priorytetem (domyślnie 100) automatycznie staje się aktywny. Wirtualny adres MAC (00:00:5E:00:01:XX) jest kluczowy dla przezroczystości przełączania — stacje robocze nie muszą zmieniać tablicy ARP, ponieważ odpowiedź na ARP zawiera stały adres MAC. Preemption pozwala oryginalnemu Masterowi na powrót po naprawie, ale może powodować krótkotrwałe zakłócenia podczas przełączenia. Czas przełączenia (3-5 sekund) jest akceptowalny dla większości aplikacji biznesowych, ale aplikacje wrażliwe na opóźnienia mogą wymagać szybszych mechanizmów. Pakiety VRRP advertisements wysyłane są multicastem (224.0.0.18) co 1 sekundę — brak 3 kolejnych pakietów inicjuje failover na Backup. Wireshark pozwala na przechwycenie i analizę pakietów VRRP, co jest pomocne przy debuggingu problemów. Podsumowując, VRRP zapewnia wysoką dostępność bramy domyślnej przy minimalnym nakładzie konfiguracji i jest rekomendowany dla każdego środowiska produkcyjnego.