Spis tematów projektowych
- Architektura nowoczesnych usług sieciowych — od monolitu do mikroserwisów
- Rola usług infrastrukturalnych (DNS, DHCP, NTP) w stabilności sieci
- Utrzymanie i bezpieczeństwo serwerów WWW w środowisku korporacyjnym
- Projektowanie bezpiecznego systemu poczty elektronicznej i pracy grupowej
- Przechowywanie danych w sieci — analiza technologii NAS i SAN
- Systemy monitorowania i obserwowalności jako fundament utrzymania usług
- Zarządzanie bezpieczeństwem i ryzykiem w usługach sieciowych
- Automatyzacja i orkiestracja infrastruktury — podejście Infrastructure as Code
- Metodyka diagnozowania awarii i utrzymania ciągłości działania usług
- Projektowanie systemów wysokiej dostępności i mechanizmy skalowania
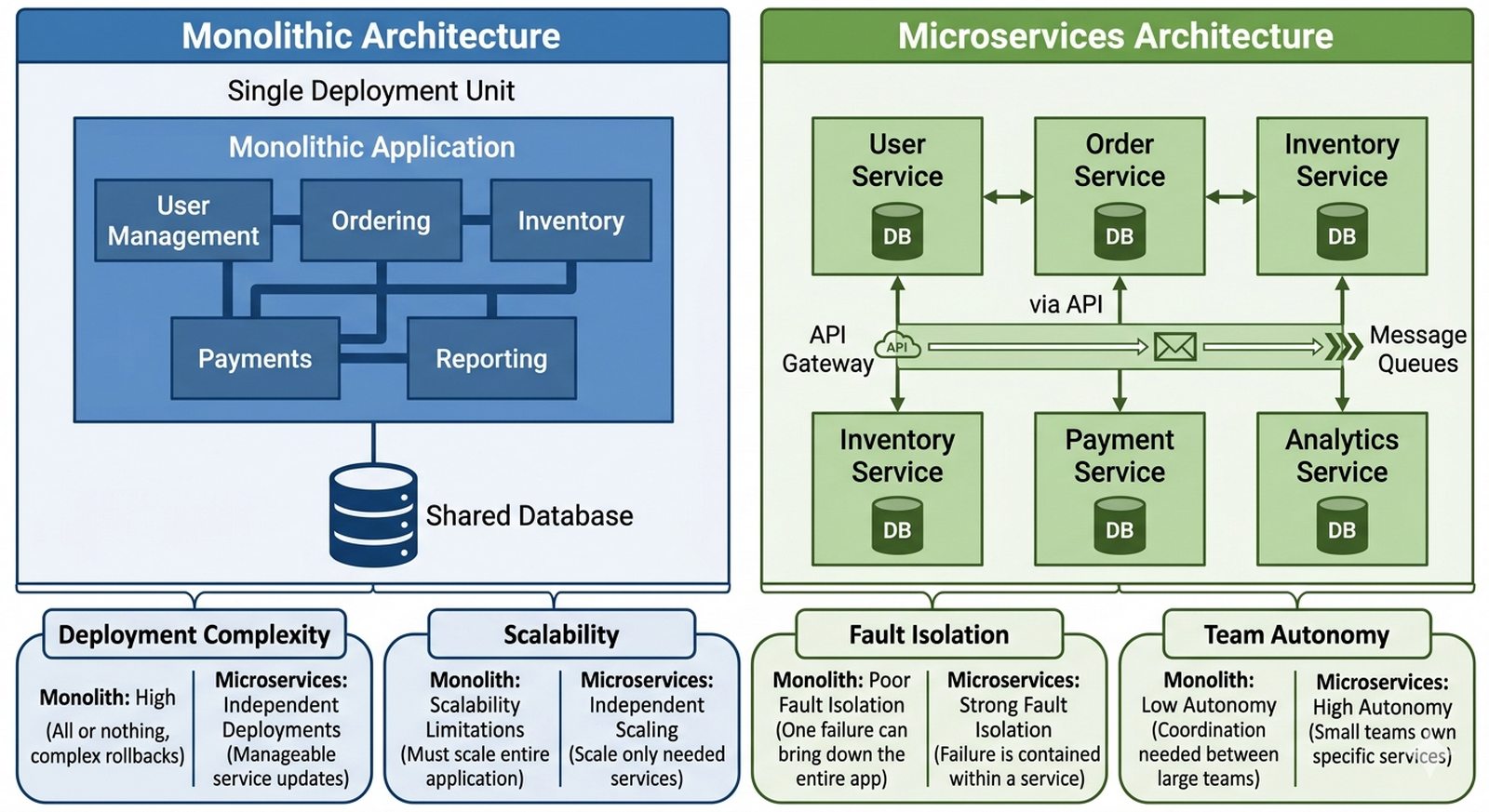
W1 Definicja usług, modele warstwowe, architektura klient-serwer, monolity vs mikroserwisy, SOA.
Celem projektu jest opisanie ewolucji architektur systemów informatycznych, ze szczególnym uwzględnieniem przejścia od tradycyjnych aplikacji monolitycznych do rozproszonych systemów mikroserwisowych. Student powinien wyjaśnić fundamentalne różnice między modelem monolitycznym opartym na ścisłej integracji wszystkich komponentów w jednej jednostce wdrożeniowej a architekturą mikroserwisową, w której każda usługa stanowi niezależny, autonomiczny moduł możliwy do samodzielnego rozwoju i skalowania. Projekt ma na celu wskazanie zalet i wad obu podejść w kontekście utrzymania usług sieciowych, ze szczególnym uwzględnieniem wpływu architektury na ciągłość działania, łatwość aktualizacji oraz złożoność zarządzania rozproszonego systemu.
Przedsiębiorstwo "TechCorp" planuje modernizację swojego głównego systemu sprzedażowego, który obecnie funkcjonuje jako monolityczna aplikacja o nazwie "Wielka Kula Błota", charakteryzująca się ścisłym powiązaniem wszystkich modułów biznesowych w jednym wdrożeniu. Zarząd potrzebuje opracowania, które wyjaśni, dlaczego przejście na architekturę mikroserwisową może (ale nie musi) pomóc w stabilności i skalowalności systemu. Kluczowym problemem do rozstrzygnięcia jest to, czy firma posiada wystarczająco duże zespoły developerów (minimum 5-6 niezależnych teamów), aby uzasadnić koszty operacyjne rozproszonego systemu. Należy wziąć pod uwagę, że w 2026 roku według raportu CNCF około 42% organizacji, które wcześniej wdrożyły mikroserwisy, wraca do modelu modularnego monolitu ze względu na złożoność zarządzania rozproszonym systemem. Projekt powinien wskazać konkretne kryteria decyzyjne: czy zespół jest w stanie operować niezależnie, czy istnieją wyraźne domeny biznesowe (płatności, użytkownicy, magazyn), czy potrzeba niezależnego skalowania poszczególnych komponentów, oraz czy firma może pozwolić sobie na 2-3x wyższe koszty infrastruktury i operacyjne.
- Wstęp — czym jest usługa sieciowa w XXI wieku
- Architektura monolityczna — charakterystyka i ograniczenia
- Paradygmat mikroserwisów — dekompozycja funkcji i niezależność
- Komunikacja w systemach rozproszonych (REST, kolejki komunikatów)
- Wyzwania związane z utrzymaniem wielu małych usług
- Porównanie kosztów i skomplikowania obu modeli
- Podsumowanie — który model wybrać dla średniej firmy?
- Przygotuj schemat porównawczy w formie diagramu blokowego, który wizualnie przedstawi różnice w architekturze monolitu (jeden duży kwadrat z wszystkimi modułami wewnątrz) versus mikroserwisy (wiele małych, niezależnych kwadratów połączonych szynami komunikacyjnymi).
- Utwórz tabelę porównawczą minimum 3x5 komórek zestawiającą oba modele pod względem: trudności wdrożenia, łatwości debugowania, skalowalności, odporności na awarie pojedynczego komponentu oraz kosztów infrastruktury.
- Omów w projekcie konkretne kryteria decyzyjne przydatne przy wyborze architektury: liczba zespołów developerskich (minimum 5-6 niezależnych teamów uzasadnia mikroserwisy), wyraźne domeny biznesowe (płatności, użytkownicy, magazyn), potrzeba niezależnego skalowania komponentów.
- Wyjaśnij wady modelu mikroserwisowego: znacznie wyższe koszty infrastruktury i operacyjne (2-3x w porównaniu z monolitem), złożoność zarządzania rozproszonym systemem, konieczność śledzenia żądań przez wiele usług (distributed tracing).
- Opisz mechanizmy komunikacji między mikroserwisami: synchroniczny REST API oraz asynchroniczne kolejki komunikatów (RabbitMQ, Apache Kafka), wraz z omówieniem kiedy każde z podejść jest preferowane.
- Uwzględnij w projekcie dane statystyczne z raportu CNCF wskazujące, że około 42% organizacji wraca do modelu modularnego monolitu ze względu na złożoność zarządzania rozproszonym systemem.
- Przygotuj przykładowy scenariusz decyzyjny dla firmy TechCorp ze scenariusza: oceń czy firma posiada wystarczające zasoby ludzkie i finansowe do migracji na mikroserwisy.
- Zdefiniuj pojęcie moduł monolityczny jako alternatywę: wyjaśnij, że nowoczesne monolity mogą być modularne (wydzielone domeny wewnątrz jednego wdrożenia), co często jest kompromisem między prostotą monolitu a elastycznością mikroserwisów.
- Omów praktyczne aspekty wdrożeniowe: potrzebę narzędzi service mesh (Istio, Linkerd) do zarządzania ruchem między usługami, monitoring distributed tracing (Jaeger, Zipkin) oraz centralizowanego logowania (ELK Stack).
- Sformułuj wnioski dotyczące rekomendacji dla średniej firmy — kiedy mikroserwisy mają sens (duża skala, wiele niezależnych domen biznesowych), a kiedy pozostać przy monolicie (mały zespół, proste wymagania).
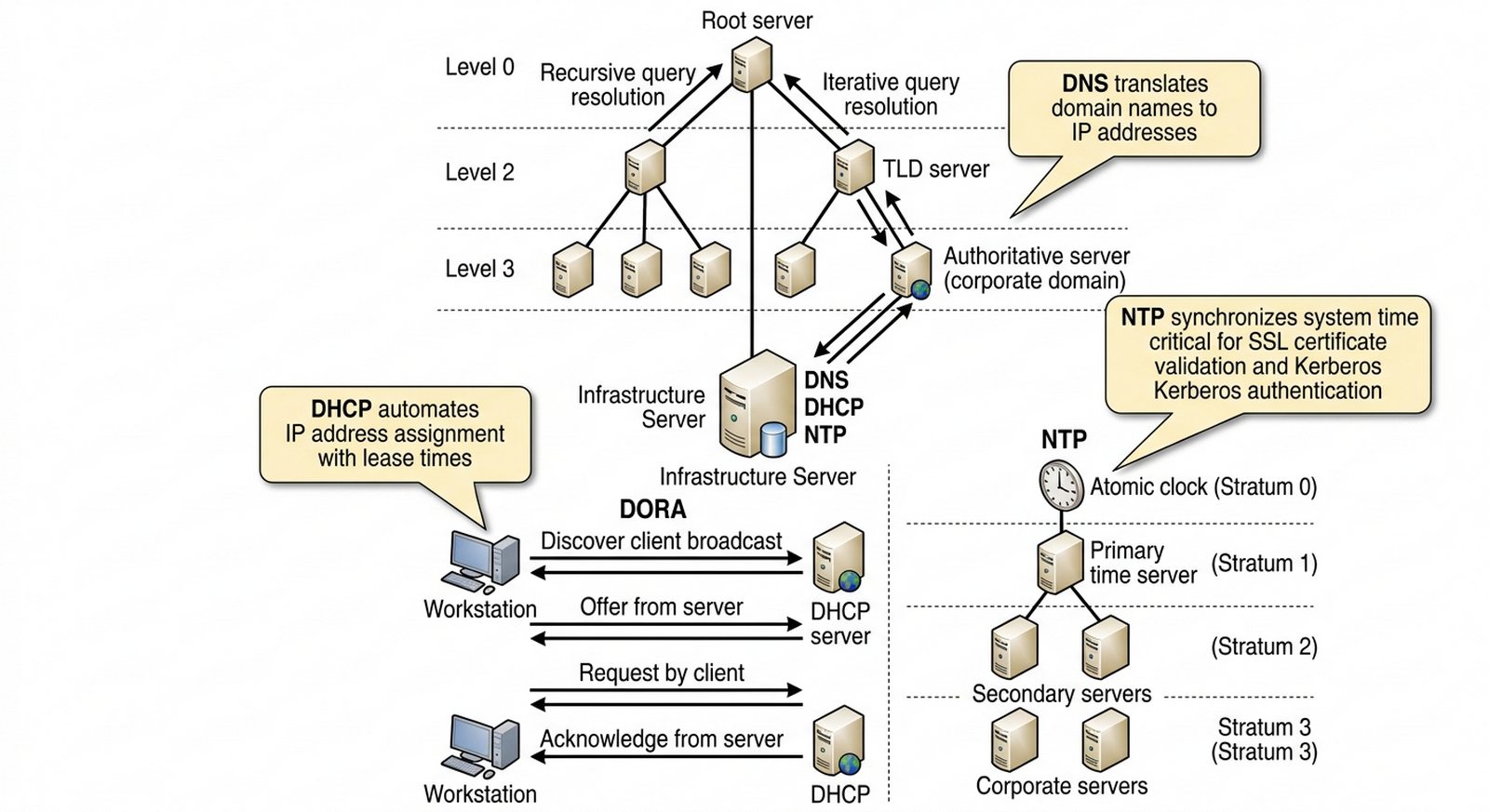
W2 Protokół DNS (hierarchia, rekordy), DHCP (proces DORA), NTP (synchronizacja czasu), Directory Services.
Celem projektu jest szczegółowe przedstawienie roli fundamentalnych usług infrastrukturalnych w sieciach LAN i WAN, ze szczególnym uwzględnieniem mechanizmów działania protokołów DNS, DHCP oraz NTP. Student powinien wyjaśnić, w jaki sposób system nazw domenowych umożliwia translację symbolicznym adresów na numeryczne adresy IP, jak protokół DHCP automatyzuje proces przydzielania adresacji IP oraz konfiguracji sieciowych, a także dlaczego precyzyjna synchronizacja czasu za pomocą NTP jest krytyczna dla prawidłowego funkcjonowania logów systemowych, mechanizmów uwierzytelniania i ważności certyfikatów SSL/TLS. Projekt koncentruje się na technicznych aspektach konfiguracji i wzajemnych interakcjach tych usług oraz ich wpływie na spójność i stabilność całej infrastruktury IT przedsiębiorstwa.
W nowo otwartym oddziale firmy dochodzi do częstych problemów z logowaniem do systemów korporacyjnych i dostępem do zasobów WWW, co powoduje przestoje w pracy operacyjnej pracowników. Administratorzy sieciowi zauważają, że stacje robocze otrzymują adresy IP z różnych zakresów, a uwierzytelnianie w Active Directory kończy się niepowodzeniem w losowych momentach. Twoim zadaniem jest przygotowanie opracowania opisującego, jak poprawnie skonfigurować fundamenty sieci (DNS, DHCP i NTP), aby uniknąć problemów z uwierzytelnianiem i dostępnością usług. Kluczowym aspektem jest wyjaśnienie, dlaczego niewłaściwie skonfigurowany serwer NTP powoduje problemy z ważnością certyfikatów SSL/TLS (czas wystawienia certyfikatu musi być wcześniejszy niż czas systemowy), co skutkuje błędami "certyfikat nie jest zaufany" w przeglądarkach. Należy opisać hierarchię serwerów NTP (stratum) oraz proces DORA (Discover, Offer, Request, Acknowledge) realizowany przez protokół DHCP, wraz z mechanizmem rezerwacji adresów MAC dla serwerów krytycznych, aby zapewnić im stałe adresy IP niezbędne do poprawnego działania usług infrastrukturalnych.
- Wstęp — usługi niewidzialne, ale krytyczne
- System nazw domenowych (DNS) — od zapytania rekurencyjnego do odpowiedzi
- Automatyzacja adresacji (DHCP) — mechanizm DORA i rezerwacje
- Synchronizacja czasu (NTP) — dlaczego milisekundy mają znaczenie dla logów i certyfikatów
- Usługi katalogowe (Active Directory/LDAP) jako centrum zarządzania
- Interakcje między tymi usługami
- Podsumowanie
- Przygotuj diagram sekwencji procesu DORA (Discover, Offer, Request, Acknowledge) w formie schematu przebiegu czasowego pokazującego wymianę komunikatów między klientem DHCP a serwerem — od wysłania DISCOVER przez klienta, przez OFERTĘ od serwera, REQUEST klienta, po potwierdzenie ACK.
- Utwórz uproszczony graf hierarchii rekordów DNS dla przykładowej domeny firmowej obejmujący rekordy: SOA (Start of Authority dla domeny), NS (serwery nazw), A (adres IPv4), AAAA (adres IPv6), CNAME (alias), MX (serwer pocztowy) oraz PTR (reverse DNS).
- Wyjaśnij w projekcie mechanizm rezerwacji adresów DHCP na podstawie adresu MAC — dlaczego jest to kluczowe dla serwerów krytycznych (DC, DNS, DHCP same) i jak skonfigurować stałe adresy IP w Windows Server lub Linux DHCP (dhcpd.conf).
- Opisz hierarchię serwerów NTP (stratum 0-3): stratum 0 to wzorce atomowe/GPS, stratum 1 to serwery bezpośrednio połączone ze wzorcami, stratum 2 to serwery synchronizujące się ze stratum 1, i tak dalej — zawsze synchronizuj się z stratum 2 lub 3 w LAN.
- Omów krytyczne znaczenie synchronizacji czasu dla certyfikatów SSL/TLS — wyjaśnij, że certyfikat musi mieć czas ważności (notBefore) wcześniejszy od czasu systemowego, inaczej przeglądarka wyświetla błąd "certyfikat nie jest zaufany".
- Opisz wzajemne interakcje między usługami: jak DNS zależy od DHCP (auto-registration), jak Active Directory wymaga poprawnego czasu NTP (Kerberos toleruje max 5 minut różnicy), jak DHCP dostarcza adresy IP wraz z opcją Option 006 (serwery DNS).
- Przygotuj tabelę konfiguracyjną z podstawowymi parametrami dla każdej usługi: zakresy adresów DHCP, serwery DNS ( lokalny + publiczny), serwer NTP, czas dzierżawy (typowo 24-72 godziny dla stacji roboczych).
- Wyjaśnij bezpieczeństwo usług infrastrukturalnych: DNS — zabezpieczenie przed cache poisoning (DNSSEC), DHCP — izolacja VLAN, NTP — ograniczenie do autoryzowanych klientów w LAN (restrict kod 6).
- Opisz typowe problemy diagnostyczne i ich przyczyny: "zębaty czas" (NTP wskazuje na inne strefy czasowe), losowe logowanie do AD (DNS zwraca różne IP dla tego samego hosta — split brain DNS), adresy z różnych zakresów (wielu serwerów DHCP w tej samej sieci VLAN).
- Sformułuj procedurę postępowania przy problemach z uwierzytelnianiem w Active Directory: 1) sprawdź czas systemowy (NTP), 2) sprawdź rozwiązywanie DNS (nslookup dc01.domena.local), 3) sprawdź łączność DC (ping), 4) analizuj logi dhcpcd.msc lub /var/log/dhcpd.log.
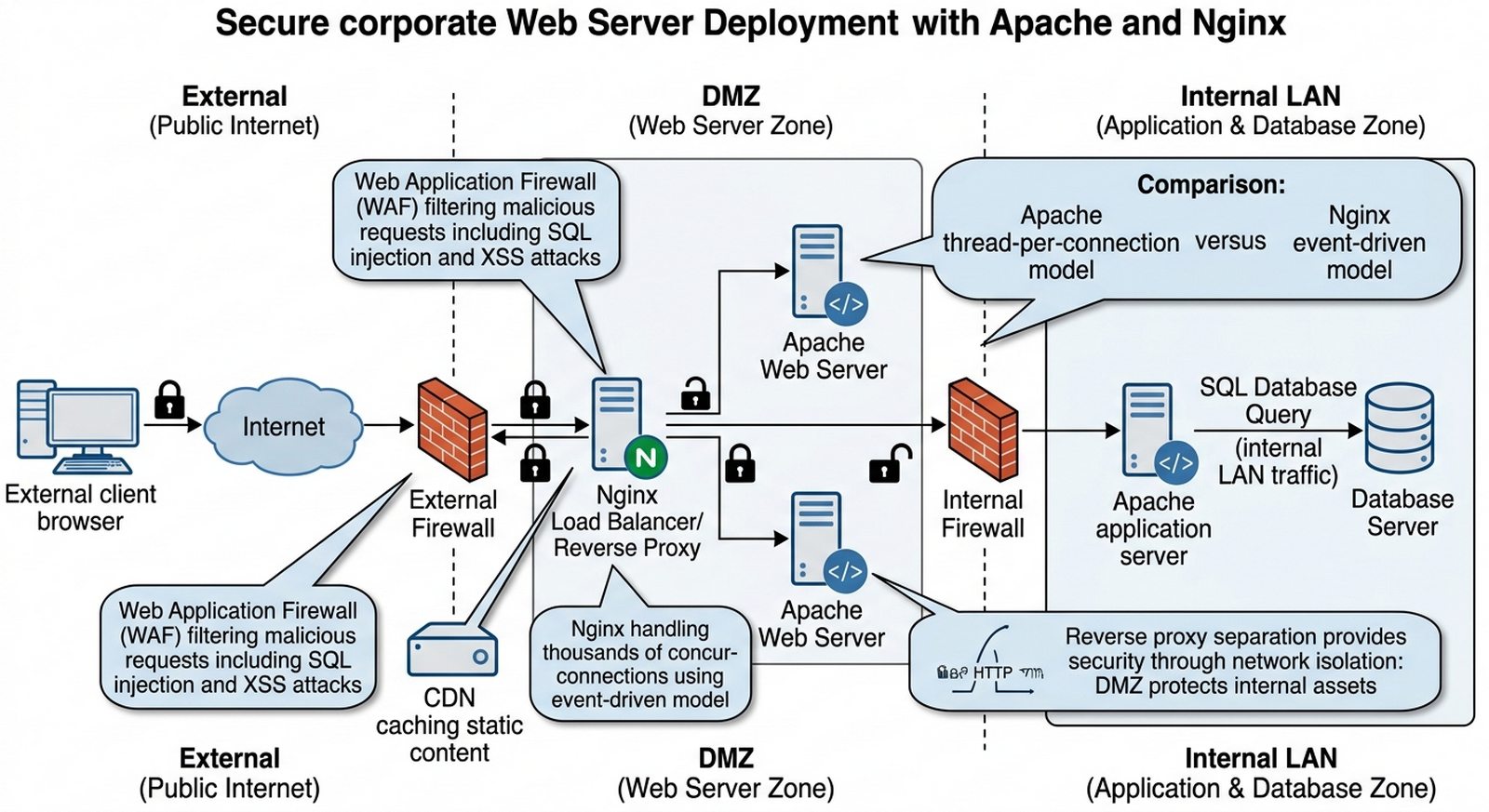
W3 Serwery Apache/Nginx, protokół HTTP/HTTPS, certyfikaty SSL/TLS, Reverse Proxy, WAF.
Celem projektu jest szczegółowa analiza technologii serwowania treści WWW w środowisku korporacyjnym, ze szczególnym uwzględnieniem różnic architektonicznych między serwerem Apache a Nginx oraz mechanizmów zapewniających bezpieczeństwo i wydajność publikacji internetowej. Student powinien opisać rolę serwera WWW jako frontu obsługującego żądania HTTP/HTTPS od klientów, wyjaśnić funkcję odwrotnego proxy w odciążaniu serwerów aplikacyjnych oraz omówić zasady działania mechanizmów szyfrowania SSL/TLS i zapory aplikacyjnej (WAF) chroniącego przed atakami typu SQL Injection, XSS i innymi zagrożeniami warstwy aplikacji. Projekt ma na celu przedstawienie kompletnej architektury bezpiecznego portalu WWW z punktu widzenia utrzymania usługi w środowisku korporacyjnym.
Twoja firma chce wystawić publiczny portal e-commerce dla klientów z możliwością składania zamówień online. Jako konsultant IT masz opisać bezpieczną architekturę publikacji treści WWW, uwzględniającą terminację SSL/TLS na reverse proxy (np. Nginx lub HAProxy) oddzielającą ruch zewnętrzny od serwerów aplikacyjnych, co ukrywa wewnętrzną strukturę sieci przed atakującymi. Kluczowym elementem jest wyjaśnienie, w jaki sposób Web Application Firewall (WAF) chroni przed atakami warstwy aplikacji, takimi jak SQL Injection (wstrzyknięcie kodu SQL przez formularze), XSS (Cross-Site Scripting — wstrzyknięcie skryptów JavaScript), czy CSRF (Cross-Site Request Forgery). Należy opisać różnice między Apache HTTP Server a Nginx pod kątem modelu przetwarzania żądań (threaded vs event-driven), co wpływa na wydajność przy dużym obciążeniu. Projekt powinien zawierać wyjaśnienie, dlaczego Nginx często pełni rolę reverse proxy przed Apache jako backend, oraz omówienie mechanizmów cache'owania treści statycznych (CDN, Varnish) redukujących obciążenie serwerów źródłowych.
- Wstęp — ewolucja serwerów WWW
- Apache vs Nginx — charakterystyka i różnice w architekturze
- Szyfrowanie SSL/TLS — droga od HTTP do bezpiecznego HTTPS
- Rola Reverse Proxy w odciążaniu serwerów aplikacji
- Zabezpieczanie warstwy aplikacji (WAF)
- Optymalizacja dostarczania treści — mechanizmy cache
- Podsumowanie
- Przygotuj schemat blokowy przepływu żądania od przeglądarki klienta przez zewnętrzny firewall, Load Balancer/Reverse Proxy (Nginx/HAProxy), serwer Apache jako backend, po bazę danych — pokaż miejsca terminacji SSL, cache'owania i filtrowania.
- Utwórz tabelę porównującą Apache HTTP Server i Nginx pod kątem: modelu przetwarzania (threaded worker vs event-driven), wydajności przy połączeniach statycznych/wielu równoległych, zużycia pamięci, łatwości konfiguracji, dostępności modułów (mod_php vs PHP-FPM).
- Wyjaśnij w projekcie różnicę między serwerem front-endowym (Reverse Proxy) a back-endowym — dlaczego Nginx często pracuje przed Apache jako Terminator SSL i Load Balancer, oddzielając ruch zewnętrzny od serwerów aplikacyjnych i ukrywając wewnętrzną strukturę sieci.
- Opisz mechanizmy szyfrowania SSL/TLS: protokol HTTPS (HTTP over TLS), certyfikaty X.509, urzędy certyfikacji (CA), chain of trust — wyjaśnij, że certyfikat serwera musi być podpisany przez zaufany CA, inaczej przeglądarka wyświetla ostrzeżenie.
- Omów Web Application Firewall (WAF) jako warstwę ochrony przed atakami warstwy aplikacji: SQL Injection (wstrzyknięcie kodu SQL przez formularze), XSS (Cross-Site Scripting — wstrzyknięcie JavaScript), CSRF (Cross-Site Request Forgery), oraz jak WAF je wykrywa i blokuje.
- Zdefiniuj terminologię bezpieczeństwa WWW: terminacja SSL (rozszyfrowanie ruchu na reverse proxy), offload SSL (przekazanie nieszyfrowanego ruchu wewnątrz LAN), perfect forward secrecy (PFS) — wyjaśnij, dlaczego PFS jest wymagany dla bezpiecznej komunikacji.
- Przygotuj sekcję o cache'owaniu treści: CDN (Content Delivery Network — Cloudflare, Akamai) dla treści statycznych, Varnish jako cache warstwa przed serwerem źródłowym, Cache-Control headers (max-age, s-maxage), różnice między cache przeglądarki a serwerowego.
- Opisz różnice między Apache i Nginx w kontekście wymagań projektu: Nginx lepiej radzi sobie z tysiącami połączeń (model event-driven), Apache lepiej integruje się z .htaccess i mod_php — dla e-commerce z dużym ruchem rozważ Nginx jako front-end.
- Omów konfigurację reverse proxy w Nginx: proxy_pass http://backend, proxy_set_header X-Real-IP, X-Forwarded-For, X-Forwarded-Proto — zachowanie informacji o oryginalnym kliencie przy przekazywaniu żądań.
- Sformułuj wnioski dla bezpiecznego portalu e-commerce: wymagaj TLS 1.2+ (TLS 1.3 preferowany), HSTS (HTTP Strict Transport Security), certyfikaty od zaufanych CA (Let's Encrypt, DigiCert), redirect HTTP→HTTPS, CSP (Content Security Policy) oraz regularne audyty bezpieczeństwa.
W4 SMTP, IMAP, POP3, mechanizmy SPF, DKIM, DMARC, systemy antyspamowe.
Celem projektu jest wyjaśnienie zasad działania profesjonalnego systemu poczty elektronicznej w infrastrukturze sieciowej przedsiębiorstwa, ze szczególnym uwzględnieniem protokołów przesyłania (SMTP), odbierania (IMAP, POP3) oraz mechanizmów uwierzytelniania i zabezpieczenia komunikacji. Student powinien opisać strukturę współczesnego systemu pocztowego składającą się z serwera pocztowego (MTA), agenta dostarczania (MDA) oraz klienta pocztowego (MUA), a także wyjaśnić nowoczesne mechanizmy ochrony przed spamem i phishingem, takie jak rekordy SPF weryfikujące autoryzowane serwery wysyłające dla domeny, DKIM podpisujący cyfrowo wiadomości oraz DMARC definiujący politykę postępowania z wiadomościami niezweryfikowanymi. Projekt ma na celu przedstawienie kompletnej architektury bezpiecznego systemu pocztowego od punktu widzenia utrzymania usługi w sieci korporacyjnej LAN.
Dyrektor operacyjny narzeka na dużą ilość spamu i phishingu obierającego pracowników, a także obawia się o bezpieczeństwo korespondencji biznesowej, która może zawierać poufne dane finansowe i kontrakty. Przygotuj opracowanie opisujące, jak nowoczesne standardy uwierzytelniania domeny (SPF, DKIM i DMARC) chronią wizerunek firmy przed podszywaniem się, oraz jakie elementy musi posiadać profesjonalny system pocztowy w środowisku korporacyjnym. Kluczowym aspektem jest wyjaśnienie, że rekord SPF definiuje listę serwerów upoważnionych do wysyłania wiadomości w imieniu domeny, DKIM używa kryptografii asymetrycznej do podpisywania nagłówków i treści wiadomości, a DMARC definiuje politykę postępowania z wiadomościami, które nie przechodzą weryfikacji. Należy opisać architekturę systemu pocztowego składającą się z serwera MTA (Mail Transfer Agent, np. Postfix lub Exim), agenta dostarczania MDA (np. Dovecot), oraz interfejsu webmail, a także omówić różnice między protokołami IMAP (synchronizacja folderów między urządzeniami) a POP3 (pobieranie i usuwanie).
- Wstęp — poczta e-mail jako narzędzie biznesowe
- Architektura systemu pocztowego (MTA, MDA, MUA)
- Protokoły pocztowe — SMTP vs IMAP/POP3
- Mechanizmy obronne: Filtry Antyspamowe i Antywirusowe
- Uwierzytelnianie domeny — SPF, DKIM i DMARC
- Prywatne serwery pocztowe vs usługi chmurowe (Exchange Online)
- Podsumowanie
- Przygotuj schemat drogi wiadomości e-mail od nadawcy do odbiorcy obejmujący: MUA (klient pocztowy Thunderbird/Outlook), MTA (serwer Postfix/Exim na porcie 25), przesyłanie między domenami przez MX, skrzynkę odbiorczą (Dovecot LDA), MUA odbiorcy — pokaż rolę każdego komponentu.
- Utwórz opisową tabelę wyjaśniającą rolę rekordów DNS w zabezpieczeniu poczty: SOA (Start of Authority), NS (serwery nazw domeny), MX (Mail Exchanger — priorytet i host), TXT (wpisy SPF), klucze DKIM (_domainkey), DMARC policy — każdy z wyjaśnieniem funkcji.
- Wyjaśnij mechanizmy uwierzytelniania domeny wysyłającej: SPF (Sender Policy Framework) — definuje IP serwerów upoważnionych do wysyłania w domenie przez rekord TXT z include:_spf.domena, DKIM (DomainKeys Identified Mail) — podpis kryptograficzny nagłówków i treści kluczem prywatnym, weryfikacja kluczem publicznym w DNS.
- Opisz DMARC (Domain-based Message Authentication, Reporting and Conformance) — polityka postępowania z wiadomościami niezweryfikowanymi: none (brak działania), quarantine (spam), reject (odrzucenie), oraz raportowanie (agregowane XML, forensic/RAF) — dlaczego warto zacząć od "none" i stopniowo zaostrzać.
- Omów architekturę systemu pocztowego w środowisku korporacyjnym: Postfix/Exim jako MTA (przesyłanie), Dovecot jako MDA (dostarczanie IMAP/POP3) i MRA (Mail Retrieval Agent), Roundcube jako webmail — dlaczego ta separacja jest popularna w Linuksie.
- Porównaj protokoły odbierania: IMAP (synchronizacja folderów między urządzeniami, zalecany dla wielu urządzeń) vs POP3 (pobieranie i opcjonalne usuwanie, dla pojedynczego komputera) — wyjaśnij typowe porty: SMTP 25/587, IMAP 143/993 (TLS), POP3 110/995 (TLS).
- Opisz mechanizmy ochrony przed spamem: filtry treści (SpamAssassin z punktacji Bayesa), blacklists RBL (Realtime Blackhole Lists — spamhaus.org), greylisting (chwilowe odrzucenie nieznanych nadawców), DMARC raportowanie (feedback od odbiorców o próbach podszywania się).
- Zdefiniuj różnice między prywatnym serwerem pocztowym a usługami chmurowymi: Exchange Online (Microsoft 365), Google Workspace — koszty, zarządzanie, SLA vs pełna kontrola i koszty CAPEX/OPEX lokalnego rozwiązania — kiedy każde jest lepsze.
- Omów bezpieczeństwo warstwy transportowej: STARTTLS (opportunistyczne szyfrowanie połączenia SMTP), wymuszanie szyfrowania (smtp_tls_security_level = encrypt), certyfikaty TLS dla serwerów pocztowych — wyjaśnij różnicę między szyfrowaniem poczty a uwierzytelnianiem domeny.
- Sformułuj wnioski dla bezpiecznego systemu pocztowego firmy: skonfiguruj SPF (wylistuj serwery wysyłające), DKIM ( podpis cyfrowy), DMARC (policy reject), włącz STARTTLS, monitoruj raporty DMARC — kroki od podstawowych do zaawansowanych.
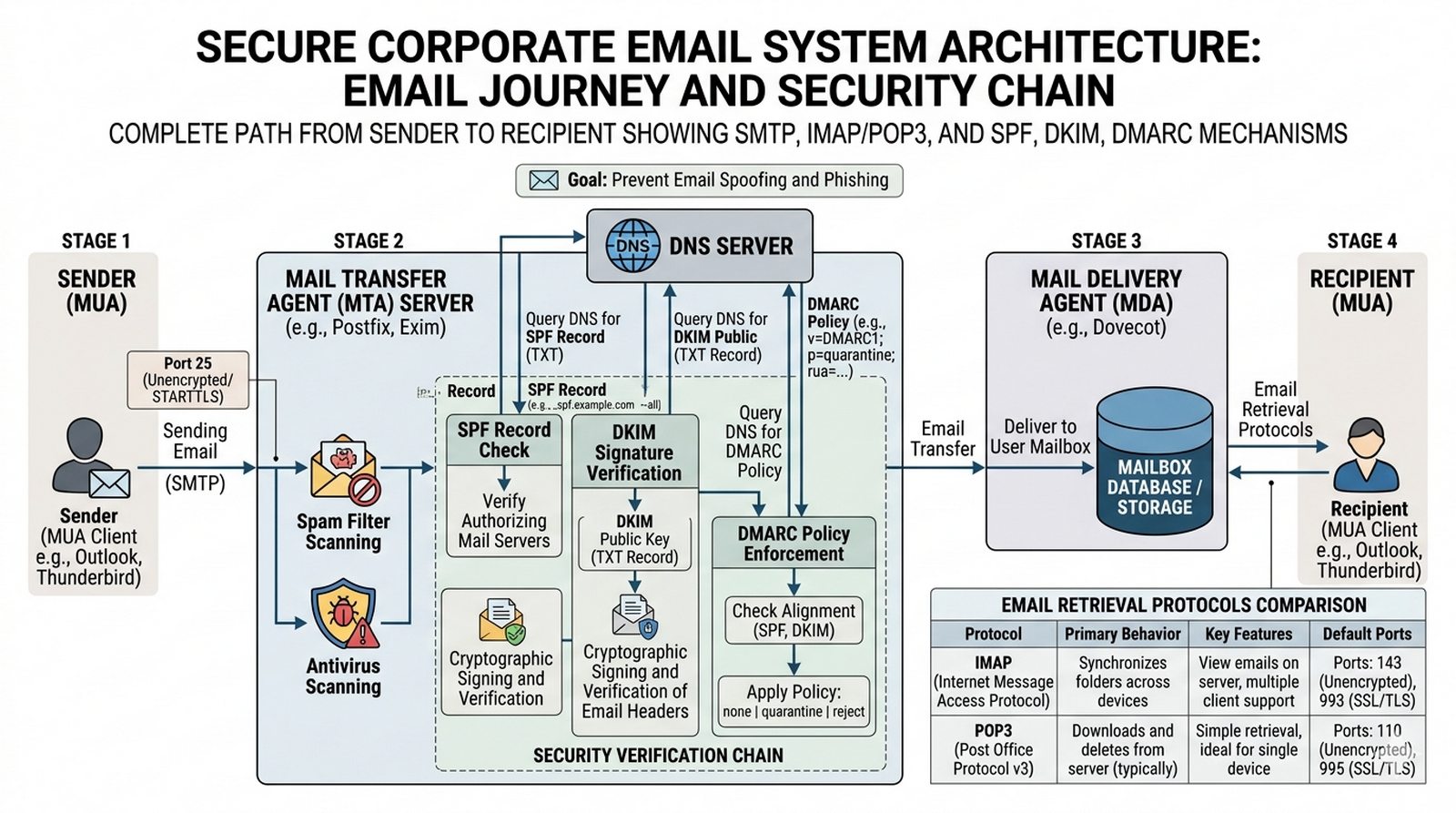
W5 Systemy plików (NFS, SMB/CIFS), iSCSI, Fibre Channel, macierze dyskowe, RAID, kopie zapasowe.
Celem projektu jest szczegółowe przedstawienie technologii przechowywania danych w sieciach lokalnych i rozległych, ze szczególnym uwzględnieniem różnic między dostępem plikowym a blokowym do zasobów dyskowych. Student powinien wyjaśnić zasady działania systemów NAS (Network Attached Storage) wykorzystujących protokoły SMB/CIFS i NFS do udostępniania plików w sieci LAN oraz technologii SAN (Storage Area Network) bazującej na protokołach iSCSI i Fibre Channel umożliwiającej bezpośredni dostęp blokowy do macierzy dyskowych. Projekt ma na celu omówienie zasad ochrony danych przed utratą poprzez zastosowanie poziomów macierzowych RAID oraz mechanizmy backupu i replikacji, a także wskazanie kryteriów wyboru odpowiedniej technologii składowania w zależności od wymagań przedsiębiorstwa dotyczących wydajności, pojemności i ciągłości działania usługi.
Firma projektowa generuje terabajty danych rocznie (rysunki CAD, symulacje CFD, materiały wideo z budowy), co powoduje, że lokalne dyski serwerów szybko się zapełniają, a kopie zapasowe na taśmach magnetofonowych wymagają manualnej obsługi. Potrzebuje centralnego systemu składowania danych z szybkim dostępem przez sieć LAN. Opisz dla nich, kiedy lepszym wyborem będzie serwer NAS (Network Attached Storage) działający na protokołach SMB/CIFS (Windows) lub NFS (Linux/Unix), oferujący prostą integrację jako kolejny dysk sieciowy w systemie plików, a kiedy powinni zainwestować w sieć SAN (Storage Area Network) z macierzą iSCSI lub Fibre Channel zapewniającą dostęp blokowy (block-level) o wydajności porównywalnej z lokalnym dyskiem SATA/SAS. Kluczowym kryterium wyboru jest to, czy aplikacje wymagają szybkiego, random I/O (bazy danych = SAN), czy tylko przechowywania plików (archiwa = NAS). Należy omówić poziomy macierzowe RAID: RAID 5/6 (parzystość, oszczędność pojemności), RAID 10 (lustrzane kopie, wysoka wydajność i odporność na awarie), oraz wyjaśnić różnicę między backupem (odtwarzanie pojedynczych plików) a replikacją (ciągłe kopiowanie na lokację zapasową w celu Disaster Recovery).
- Wstęp — dlaczego dane to najważniejszy zasób firmy
- Network Attached Storage (NAS) — wygoda i protokoły SMB/NFS
- Storage Area Network (SAN) — wydajność blokowa i iSCSI/FC
- Poziomy RAID — balans między wydajnością a bezpieczeństwem
- Backup vs Replikacja danych — kluczowe różnice
- Software Defined Storage — przyszłość składowania danych
- Podsumowanie
- Utwórz tabelę porównawczą NAS i SAN obejmującą minimum 6 kryteriów: protokoły (SMB/NFS vs iSCSI/FC), model dostępu (file-level vs block-level), wydajność IOPS/throughput, złożoność wdrożenia, koszt za TB, typowe zastosowania — zilustruj kiedy każde rozwiązanie jest lepsze.
- Przygotuj schemat ideowy macierzy dyskowej z różnymi typami RAID: RAID 0 (brak redundancji, striping), RAID 1 (lustrzane kopie), RAID 5 (parzystość pojedyncza, min 3 dyski), RAID 6 (podwójna parzystość), RAID 10 (lustrzane pary w stripingu) — pokaż rozkład danych i parzystości.
- Wyjaśnij kluczowe kryterium wyboru technologii: czy aplikacje wymagają szybkiego, random I/O (bazy danych = SAN) czy tylko przechowywania plików (archiwa, backup, media = NAS) — podaj przykłady z opisu: CAD/CFD = NFS/SAN, wideo z budowy = NAS.
- Opisz protokoły NAS: SMB/CIFS (Server Message Block — Windows, Samba w Linuksie, port 445), NFS (Network File System — Linux/Unix, wersje 3/4.1, port 2049) — wyjaśnij różnice w obsłudze uprawnień i blokad plików.
- Omów protokoły SAN: iSCSI (SCSI over IP —SCSI komendy w TCP/IP, port 3260, CHAP authentication) oraz Fibre Channel (FC — wyspecjalizowana warstwa, 8/16/32 Gbps, WWN addressing) — wyjaśnij, dlaczego iSCSI jest tańszą alternatywą dla FC.
- Zdefiniuj poziomy macierzowe RAID pod kątem praktycznym: RAID 5 (1 dysk parzystości — min 3 dyski, nie nadaje się do dużych pojemności ze względu na ryzyko URE podec odbudowy), RAID 6 (2 dyski parzystości — bezpieczniejszy), RAID 10 (wysoka wydajność + odporność na awarie, ale 50% pojemności).
- Wyjaśnij różnicę między backupem a replikacją: backup (odtwarzanie pojedynczych plików/DB z punktu w czasie, kopie pełne/inkrementalne/differencyjne) vs replikacja (ciągłe kopiowanie synchroniczne/asynchroniczne na lokację zapasową dla Disaster Recovery) — RPO/RTO.
- Omów architekturę macierzy: kontroler (cache NVMe/Li-Ion, snapshots), JBOD (Just a Bunch Of Disks — seria bez intelligencji), all-flash vs hybrid (SSD cache + HDD) — dlaczego all-flash jest standardem dla baz danych.
- Opisz praktyczne wdrożenie NAS w firmie projektowej z opisu: podłącz serwer NAS do switch'y LAN 10GbE, skonfiguruj exporty NFS (/projekty/cad, /projekty/wideo) lub Samba shares, ustaw user quotas, skonfiguruj rsync/backup do taśm LTO.
- Sformułuj wniosek decyzyjny dla firmy projektowej: jeśli dane to głównie pliki (CAD, wideo) — NAS wystarczy; jeśli bazy danych aplikacji produkcyjnych (Oracle, SQL Server) — rozważ SAN + backup; w praktyce hybrydowe rozwiązania (NAS na front, SAN na back).
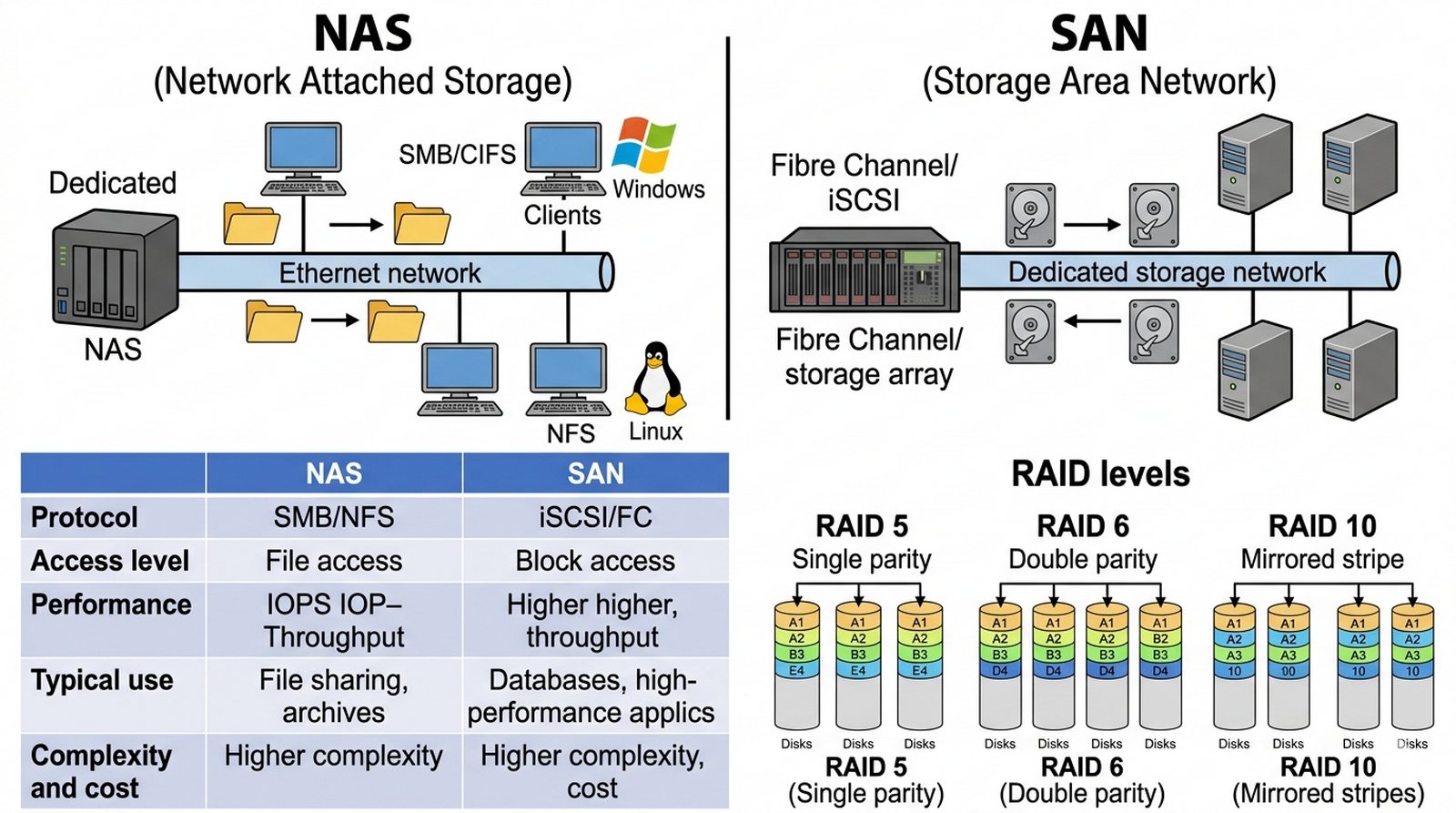
W6 SNMP, Syslog, NetFlow, Prometheus, Grafana, logowanie zdarzeń, KPI usług.
Celem projektu jest wyjaśnienie roli systemów monitorowania i obserwowalności w utrzymaniu ciągłości działania usług sieciowych, ze szczególnym uwzględnieniem metody zbierania informacji o stanie infrastruktury IT. Student powinien opisać fundamentalne techniki monitorowania obejmujące pasywne nasłuchiwanie zdarzeń za pomocą protokołów Syslog i SNMP oraz aktywne sprawdzanie dostępności usług przez periodyczne testy HTTP i pingi, a także koncepcję trzech filarów obserwowalności, czyli metryk numerycznych mierzących wydajność, logów tekstowych dokumentujących zdarzenia oraz śladów (traces) śledzących przepływ żądań przez rozproszony system. Projekt ma na celu przedstawienie architektury nowoczesnego systemu monitoringu opartego na narzędziach takich jak Prometheus do zbierania metryk i Grafana do wizualizacji danych, wraz z mechanizmami alertowania umożliwiającymi proaktywne reagowanie na incydenty przed ich eskalacją do poziomu krytycznego.
Systemy firmy działają "w czarnej skrzynce" — nikt nie widzi przeciążeń infrastruktury ani nietypowych wzorców ruchu, dopóki serwer nie padnie i klienci nie zaczną dzwonić z reklamacjami. Zespół IT dowiaduje się o awariach post factum, a próby włączenia monitoringu kończą się chaotycznym zbieraniem logów bezcentralizowanej agregacji. Opracuj plan wdrożenia systemu monitoringu i obserwowalności, który pozwoli proaktywnie reagować na incydenty, zanim eskalują do poziomu krytycznego. Kluczowym elementem jest opis trzech filarów obserwowalności: metryki (Prometheus, InfluxDB — wartości numeryczne jak CPU, RAM, licznik zapytań HTTP), logi (Syslog, ELK Stack — zdarzenia tekstowe z timestampami do analizy przyczyn awarii) oraz tracing rozproszony (Jaeger, Zipkin — ścieżka żądania przez wszystkie mikrousługi przy debugowaniu). Należy wyjaśnić różnicę między modelem push (Zabbix, Nagios — agent wysyła dane do serwera) a modelem pull (Prometheus — serwer okresowo pobiera metryki z endpoint /metrics), oraz omówić konfigurację progów alertów (warning/critical) w Grafana dla wskaźników KPI usług (SLA, czas odpowiedzi, dostępność).
- Wstęp — nie możesz zarządzać tym, czego nie mierzysz
- Monitoring pasywny (Syslog, SNMP) vs aktywny (checki HTTP)
- Trzy filary obserwowalności: Metryki, Logi, Tracing
- Systemy oparte na pull (Prometheus) i push (Zabbix)
- Wizualizacja danych — rola pulpitów menedżerskich (Grafana)
- Systemy ostrzegania (Alerting) i progi alarmowe
- Podsumowanie
- Przygotuj schemat architektury systemu monitoringu w formie blokowej: źródła danych (agenty, SNMP, exportery) → kolektor (Prometheus/Zabbix/OpenTSDB) → baza szeregów czasowych → wizualizacja (Grafana) → alertowanie (Alertmanager/PagerDuty) — pokaż przepływ danych.
- Utwórz przykładową tabelę z KPI dla serwera WWW obejmującą metryki: dostępność (up/down), czas odpowiedzi (p95, p99), throughput (req/s), zużycie CPU, zużycie RAM, liczba błędów 5xx, rozmiar logów — z progiem warning/critical dla każdej.
- Wyjaśnij trzy filary obserwowalności: metryki (numeryczne wartości — CPU, RAM, IOPS, collected przez Prometheus z /metrics), logi (tekstowe zdarzenia z timestampami — syslog, journald, stored w ELK), tracing (ścieżki żądań przez usługi — Jaeger/Zipkin).
- Opisz różnicę między modelem push a pull: model push (Nagios, Zabbix — agent aktywnie wysyła dane do serwera, firewall wyjściowy) vs model pull (Prometheus — serwer okresowo pobiera metryki z endpoint /metrics, firewall przychodzący) — wyjaśnij zalety każdego.
- Omów konfigurację alertów w Grafana: zdefiniuj zapytania PromQL (np. rate(http_requests_total[5m]) > 100), ustaw progi warning (>100) i critical (>500), skonfiguruj kanały powiadomień (e-mail, Slack, PagerDuty), dodaj eskalację (po 5 min bez ACK eskaluj).
- Zdefiniuj SLO (Service Level Objective) i SLA (Service Level Agreement): SLO wewnętrzny cel zespołu (np. 99,9% dostępności), SLA umowa z klientem (konsekwencje finansowe), SLI (Service Level Indicator) — metryka mierząca SLO (uptime %).
- Opisz narzędzia do wizualizacji: Grafana dashboardy z wykresami liniowymi (trendy), heatmapami (obciążenie), stat panelami (aktualne wartości) — pokaż praktyczny przykład dashboardu dla SLA serwera WWW.
- Wyjaśnij sens posiadania centralizowanego logowania: ELK Stack (Elasticsearch — baza, Logstash/Fluentd — collector, Kibana — wizualizacja), agregacja logów z wszystkich serwerów, korelacja zdarzeń przy incydentach, Retention (7/30/90 dni).
- Omów praktyczne wdrożenie monitoringu z opisu: wdrażaj stopniowo — najpierw podstawowe metryki (CPU/RAM/Disk), potem application metrics (HTTP response times), na końcu tracing distributed (Jaeger) — "nie mierz wszystkiego naraz".
- Sformułuj wniosek projektowy: monitoring to koszt, ale inwestycja — bez niego "systemy działają w czarnej skrzynce", incydenty eskalują do krytycznych zanim ktoś je zauważy; dobry system monitoringu pozwala na proaktywne reagowanie.
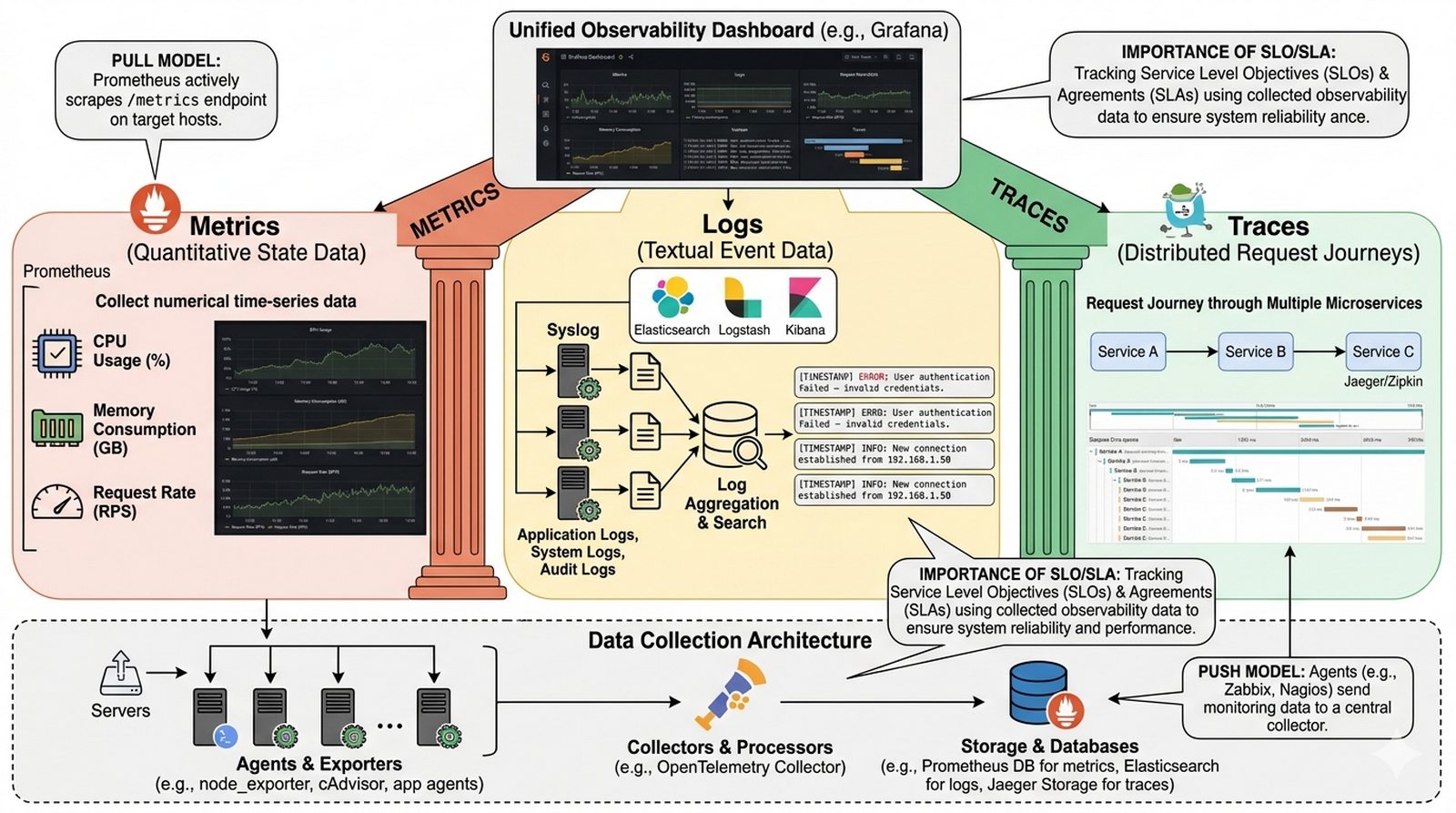
W7 Triada CIA, zarządzanie tożsamością (IAM), VPN, segmentacja sieci, analiza ryzyka, aktualizacje (Patch Management).
Celem projektu jest szczegółowa analiza zagrożeń bezpieczeństwa usług sieciowych oraz metod ich ochrony w środowisku LAN przedsiębiorstwa, ze szczególnym uwzględnieniem podejścia wielowarstwowego (defense in depth). Student powinien wyjaśnić fundamentalne zasady triady CIA obejmujące poufność ( Confidentiality ), integralność ( Integrity ) i dostępność ( Availability ) danych oraz omówić mechanizmy ich egzekwowania poprzez zarządzanie tożsamością i dostępem (IAM), wieloskładnikowe uwierzytelnianie (MFA), virtualne sieci prywatne (VPN) i segmentację sieci na strefy o różnym poziomie zaufania. Projekt ma na celu przedstawienie procesu zarządzania ryzykiem w usługach sieciowych, obejmującego identyfikację podatności, ocenę zagrożeń, wdrożenie środków zaradczych oraz zarządzanie aktualizacjami bezpieczeństwa (Patch Management), co umożliwia utrzymanie usług w stanie akceptowalnego ryzyka dla organizacji.
W audycie bezpieczeństwa przeprowadzonym przez zewnętrzną firmę wykazano poważne braki: brak kontroli nad tym, kto i skąd łączy się z zasobami firmy (brak logowania połączeń VPN), pracownicy używają tych samych haseł do wielu systemów (brak MFA), a segmentacja sieci jest płaska — dział finansów i produkcja są w tej samej sieci LAN bez firewalla między nimi. Opisz system bezpiecznego dostępu zdalnego opartego na VPN z uwierzytelnianiem wieloskładnikowym (MFA) oraz zasady segmentacji sieci na strefy o różnym poziomie zaufania zgodnie z modelem Zero Trust. Wyjaśnij, dlaczego tradycyjny model "castle and moat" (zaufaj wszystkiemu wewnątrz sieci korporacyjnej) jest przestarzały — atakujący, który raz przedostanie się przez firewall, ma dostęp do wszystkiego. Opisz implementację sieci DMZ (Demilitarized Zone) wydzielonej jako strefy pośredniej między Internetem a LAN, zawierającej serwery WWW dostępne publicznie, ale odizolowane od wewnętrznych baz danych. Omów zasady triady CIA ( Poufność, Integralność, Dostępność ) oraz proces zarządzania poprawkami bezpieczeństwa (Patch Management) — dlaczego aktualizacje systemów produkcyjnych muszą być testowane przed wdrożeniem, ale opóźnienia powyżej 30 dni od wydania poprawki krytycznej znacząco zwiększają ryzyko ataku.
- Wstęp — bezpieczeństwo jako proces, a nie produkt
- Model CIA (Poufność, Integralność, Dostępność)
- Zarządzanie tożsamością i uprawnieniami (RBAC, MFA)
- Bezpieczeństwo połączeń zdalnych (VPN, Zero Trust)
- Segmentacja sieci i firewalle aplikacyjne
- Zarządzanie poprawkami (Patching) — walka z czasem
- Podsumowanie
- Przygotuj diagram segmentacji sieci obejmujący trzy strefy: Internet → DMZ (publicznie dostępne serwery WWW, odizolowane od wewnętrznych serwisów) → LAN (wewnętrzne bazy danych, kontrolery domeny) → Management (stacja administratora, izolowana od zwykłego ruchu) — pokaż firewalle między strefami.
- Utwórz tabelę analizy ryzyka dla wybranych dwóch usług sieciowych (np. serwer WWW i baza danych) z kolumnami: zagrożenie (np. DDoS, SQL Injection, nieautoryzowany dostęp), podatność (luki w oprogramowaniu, słabe hasła), prawdopodobieństwo (wysokie/średnie/niskie), wpływ (krytyczny/znaczący/niski), środek zaradczy wagi (niska/średnia/wysoka).
- Wyjaśnij triadę CIA w kontekście projektu: Poufność (Confidentiality — tylko uprawnieni widzą dane: szyfrowanie, ACL, MFA), Integralność (Integrity — dane niezmienione: checksum, signing, wersjonowanie), Dostępność (Availability — usługi działają: HA, backup, monitoring) — dla każdego przykład chroniących mechanizmów.
- Opisz model Zero Trust w opozycji do "castle and moat": zamiast "zaufaj wszystkiemu w LAN", weryfikuj każde żądanie (tożsamość, urządzenie, kontekst), minimalizuj uprawnienia (least privilege), mikrosegmentacja — wyjaśnij, dlaczego tradycyjny model jest przestarzały (atakujący przez firewall = dostęp do wszystkiego).
- Omów implementację VPN z MFA: protokoły VPN (IPsec, OpenVPN, WireGuard), uwierzytelnianie wieloskładnikowe (coś co wiesz — hasło, coś co masz — token/smartphone, coś czym jesteś — biometria), NPS (Network Policy Server) jako RADIUS, dwie separacyjne sieci VPN (dla pracowników i partnerów).
- Zdefiniuj zasady segmentacji: DMZ = serwery WWW dostępne publicznie (porty 80/443), ale NIE mające połączenia do wewnętrznych baz danych (tylko przez API z autentykacją); LAN = pracownicy (pełny dostęp do zasobów z autentykacją AD); zarządzanie = tylko z dedykowanych stacji (jump server/bastion).
- Opisz proces Patch Management: monitoruj CVEs (Common Vulnerabilities and Exposures), priorytetyzuj krytyczne (RCE, Privilege Escalation), testuj w środowisku testowym (48h), wdrażaj w oknach maintenance (off-hours), retention (max 30 dni od wydania dla krytycznych), rollback plan — wyjaśnij, dlaczego opóźnienia >30 dni znacząco zwiększają ryzyko.
- Wyjaśnij różnicę między RBAC (Role-Based Access Control — role: admin, developer, user) a ABAC (Attribute-Based — atrybuty: dział, lokalizacja, czas, urządzenie) — kiedy stosować każdy model.
- Omów bezpieczeństwo fizyczne i warstwa: serwerownia (kontrola dostępu, CCTV, klimatyzacja), KVM over IP (Virtual Network Computing przez dedykowany VLAN), BIOS/UEFI (wyłącz boot z sieci/USB), TPM ( trusted platform module — szyfrowanie dysków).
- Sformułuj wniosek dla audytu bezpieczeństwa z opisu: brak MFA + płaska sieć + brak VPN = krytyczne ryzyko; wdrożenie Zero Trust wymaga etapów: inwentaryzacja zasobów, segmentacja, MFA everywhere, monitoring, ciągła weryfikacja.
W8 Narzędzia IaC (Ansible, Terraform), orkiestracja (Kubernetes), potoki CI/CD, konteneryzacja (Docker).
Celem projektu jest przedstawienie metodyki Infrastructure as Code (IaC) jako fundamentalnej zmiany paradygmatu zarządzania infrastrukturą sieciową, odechodzącej od ręcznej konfiguracji serwerów poprzez interfejsy graficzne na rzecz zdeklaratywnego opisu infrastruktury w plikach tekstowych wersjonowanych w systemie kontroli wersji. Student powinien wyjaśnić różnicę między narzędziami do konfiguracji systemów operacyjnych (takimi jak Ansible) a narzędziami do provisionowania infrastruktury chmurowej (takimi jak Terraform), omówić koncepcję konteneryzacji za pomocą Dockera jako nowoczesnego standardu pakowania i dystrybucji usług oraz wprowadzić podstawy orkiestracji kontenerów w Kubernetes. Projekt ma na celu wyjaśnienie korzyści płynących z automatyzacji powtarzalnych zadań administratora, w tym powtarzalności wdrożeń, łatwości odtwarzania środowisk, możliwości śledzenia zmian w historii repozytorium oraz implementacji potoków CI/CD automatyzujących proces od commitu kodu do wdrożenia produkcyjnego.
Dział IT poświęca 70% swojego czasu na proste, powtarzalne zadania konfiguracyjne: ręczne stawianie nowych serwerów według checklist w Wordzie, instalowanie aplikacji przez RDP na każdą maszynę z osobna, oraz reagowanie na "a czemu nie działa?" po nieudanych zmianach konfiguracji. Każda zmiana infrastruktury wymaga ręcznej edycji kilkunastu plików konfiguracyjnych, a dokumentacja opisowa jest nieaktualna od momentu napisania. Zaproponuj zmianę podejścia — opisz, jak narzędzia takie jak Ansible czy Terraform mogą zautomatyzować stawianie nowych serwerów i ich konfigurację w sposób powtarzalny i udokumentowany w kodzie. Wyjaśnij różnicę między podejściem imperatywnym (Ansible — opisuj "jak" wykonać kroki: apt install nginx, service nginx start) a deklaratywnym (Terraform — opisuj "jaki" ma być stan końcowy: resource "aws_instance" "web" { ami = "..." }, a narzędzie samo wylicza różnice). Omów, jak Docker konteneryzuje aplikacje ze wszystkimi zależnościami (OS, biblioteki, kod), umożliwiając uruchomienie na dowolnym Linuxie bez "to u mnie działa" problemów. Należy opisać przepływ CI/CD (Continuous Integration/Continuous Deployment): od commitu developera przez automatyczne testy, build obrazu Docker, do wdrożenia na produkcji — w pełni automatycznie i z możliwością natychmiastowego roll-back w przypadku błędów.
- Wstęp — zmierzch ery "ręcznej" administracji
- Idea Infrastructure as Code (IaC) — infrastruktura w plikach tekstowych
- Konfiguracja systemów (Ansible) vs provisionowanie (Terraform)
- Konteneryzacja jako nowy standard pakowania usług (Docker)
- Wprowadzenie do orkiestracji (Kubernetes)
- Automatyzacja wdrożeń (CI/CD) — opis koncepcji
- Podsumowanie
- Przygotuj diagram pokazujący cykl życia zmiany od wysłania kodu do repozytorium (git push) przez automatyczne testy (CI), budowanie obrazu (Docker build), wdrożenie na staging (docker-compose), testy integracyjne, do wdrożenia na produkcji (CD) — pokaż etapy potoku CI/CD.
- Utwórz tabelę porównującą tradycyjne maszyny wirtualne z kontenerami Dockera pod kątem: izolacji (VM pełna, kontener namespace/cgroups), rozmiaru (GB vs MB), czasu startu (minuty vs sekundy), zarządzania (hypervisor vs dockerd), sieciowania (virtual bridge vs overlay), typowe use case (legacy apps vs mikrousługi).
- Wyjaśnij różnicę między podejściem imperatywnym a deklaratywnym: Ansible = imperatywny (opisujesz kroki: apt install nginx, service nginx start), Terraform = deklaratywny (opisujesz stan końcowy: resource "aws_instance" "web" { ami = "..." }, narzędzie samo wylicza różnicę).
- Opisz strukturę pliku Dockerfile: FROM (obraz bazowy), RUN (polecenia w build), COPY (pliki z kontekstu), ENV (zmienne), EXPOSE (porty), CMD/ENTRYPOINT (polecenie startowe) — pokaż przykładowy Dockerfile dla prostej aplikacji Node.js.
- Omów orkiestrację kontenerów w Kubernetes: Pod (minimalna jednostka — jeden lub więcej kontenerów), Deployment (Zarządzanie replikami Pod), Service (stabilny IP/name), Ingress (HTTP routing), ConfigMap/Secret (konfiguracja), StatefulSet (dla baz danych z persystentnym storage).
- Zdefiniuj Infrastructure as Code w praktyce: trzymaj konfigurację w plikach tekstowych (YAML, HCL), wersjonuj w Git (commit, branch, PR), code review przed zmianami (pull request), automatyczne testy (terratest), idempotentność (ten sam kod daje ten sam stan).
- Wyjaśnij korzyści IaC: powtarzalność (ten sam kod = ten sam stan na każdym środowisku), śledzenie zmian (git log, bisect), odtwarzalność (destroy + apply = nowe środowisko), audyt (kto, kiedy, co zmienił), współpraca (merge requesty z review).
- Opisz potok CI/CD w kontekście projektu: developer commituje kod → GitLab/GitHub CI uruchamia testy jednostkowe → buduje obraz Docker → skanuje podatności (Trivy/Snyk) → pushuje do registry → deploy na staging (Docker Compose/Kubernetes) → testy integracyjne → deploy na produkcję (rolling update).
- Omów narzędzia IaC dla administratora: Ansible (konfiguracja systemów — serwery, bazy danych, aplikacje), Terraform (provisioning infrastruktury — chmura, sieci, DNS), Packer (obrazy VM), Vault (sekrety), GitLab CI/GitHub Actions (CI/CD) — kiedy każde narzędzie.
- Sformułuj wniosek dla firmy z opisu: ręczna konfiguracja = niepowtarzalność, błędy, brak audytu; przejście na IaC wymaga zmiany kultury (koduj konfigurację, nie rób exception), inwestycji (nauka Terraform/Ansible), alezwraca się w ciągu miesięcy (powtarzalne wdrożenia, mniej "a czemu nie działa").
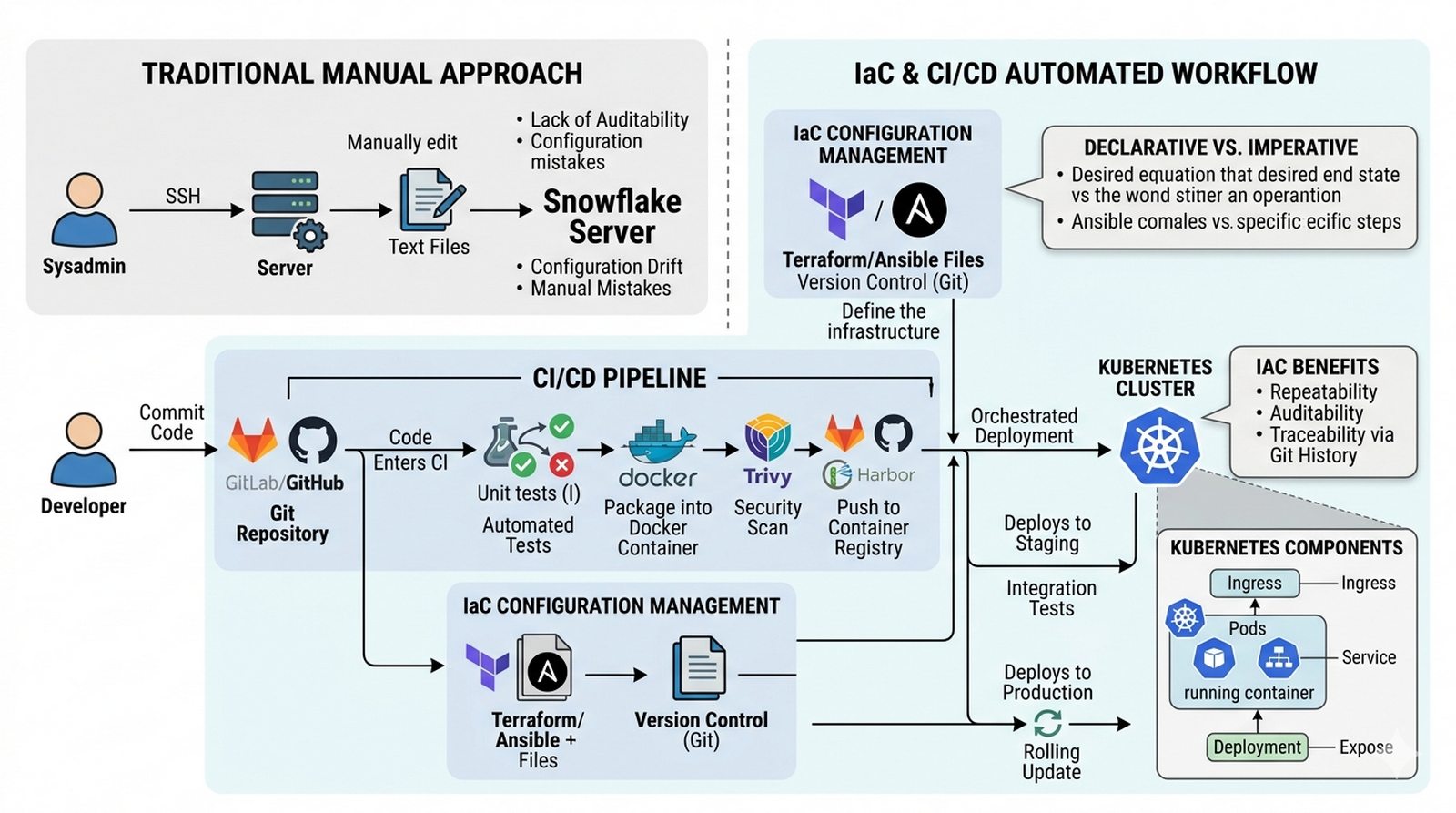
W9 Logi systemowe, narzędzia diagnostyczne (MTR, Wireshark), procesy ITIL, zarządzanie incydentem i problemem.
Celem projektu jest szczegółowe opisanie metodyki diagnozowania awarii i procesu utrzymania ciągłości działania usług sieciowych w środowisku korporacyjnym, ze szczególnym uwzględnieniem systematycznego podejścia do rozwiązywania problemów. Student powinien wyjaśnić hierarchiczny model rozwiązywania problemów rozpoczynający się od weryfikacji warstwy fizycznej (kable, przełączniki), przez warstwę sieciową (łączność IP, routing), warstwę transportową (porty TCP/UDP) aż po warstwę aplikacyjną (usługi i procesy), a także przedstawić warsztat administratora obejmujący analizę logów systemowych i aplikacyjnych, narzędzia diagnostyczne (ping, traceroute, MTR, nslookup) oraz techniki zaawansowanej analizy ruchu sieciowego w Wiresharku. Projekt ma na celu wyjaśnienie procesu Root Cause Analysis (RCA) służącego do identyfikacji fundamentalnej przyczyny incydentu oraz przedstawienie zasad dokumentowania awarii i tworzenia procedur zapobiegających ich ponownemu wystąpieniu.
W firmie wystąpiła awaria krytycznej bazy danych Oracle/PostgreSQL — systemy sprzedażowe stanęły, kasjerzy nie mogą obsłużyć klientów, a menedżerowie dzwiąą z pytaniami "kiedy będzie działać?". Przygotuj procedurę opisową dla młodszych administratorów: jak systematycznie zbierać dowody (evidencję), gdzie szukać logów (systemowe /var/log, aplikacyjne, bazy danych), i jakich narasieciowych narzędzi użyć, by zlokalizować warstwę, na której leży problem. Wyjaśnij hierarchiczny model diagnozowania rozpoczynający od warstwy fizycznej (kable sieciowe, diody na przełącznikach — czy link jest UP?), przez warstwę IP (ping, traceroute — czy路由owanie działa?), warstwę transportową (telnet/nc na port TCP 1433 — czy firewall blokuje?), aż po warstwę aplikacyjną (logi bazy danych, czy serwer nasłuchuje na wskazanym adresie IP). Omów narzędzia diagnostyczne: ping (łączność ICMP), traceroute/MTR (śledzenie hopów), dig/nslookup (rozwiązywanie DNS), netstat/ss (aktywne połączenia i nasłuchiwanie na portach), oraz Wireshark jako ostateczność przy trudnych do powtórzenia problemach z transmisją danych. Należy opisać proces Root Cause Analysis (RCA) — pytanie "dlaczego" powtarzane 5 razy (metoda 5 dlaczegoch), które prowadzi do fundamentalnej przyczyny, a nie tylko objawu awarii, oraz dlaczego dokumentowanie incydentów w systemie zarządzania problemami (ITIL) jest kluczowe dla zapobieżenia nawrotom.
- Wstęp — psychologia awarii i znaczenie zimnej krwi
- Hierarchiczny model rozwiązywania problemów (od warstwy fizycznej w górę)
- Analiza logów systemowych i aplikacyjnych
- Diagnostyka sieciowa: ping, traceroute, mtr, nslookup
- Zaawansowana analiza ruchu — kiedy sięgnąć po Wiresharka?
- Dokumentowanie awarii i Root Cause Analysis (RCA)
- Podsumowanie
- Przygotuj schemat algorytmu decyzyjnego podczas awarii (drzewo decyzji administratora) w formie flowchartu: 1) Czy serwer odpowiada na ping? (NIE → warstwa fizyczna/przełącznik, TAK → 2) Czy aplikacja nasłuchuje na porcie? (NIE → usługa nieaktywna, TAK → 3) Czy logi pokazują błąd? (TAK → analyzuj, NIE → 4) Czy inni użytkownicy mają problem? (NIE → problem clienta, TAK → 5) Skontaktuj zespół/eskaluj.
- Utwórz tabelę z opisem 5 kluczowych narzędzi diagnostyki sieciowej obejmującą: ping (ICMP echo — test łączności, straty pakietów, RTT), traceroute/MTR (śledzenie hopów — gdzie są opóźnienia), dig/nslookup (rozwiązywanie DNS — MX, A, PTR), netstat/ss (aktywne połączenia, nasłuchiwanie na portach, stan TIME_WAIT), Wireshark (analiza protokołów — captures, filtry, follow TCP stream).
- Opisz hierarchiczny model diagnozowania awarii: zacznij od warstwy 1 (fizyczna — kable, diody na switchu: Link/Activity, Speed), warstwa 2 (Ethernet — MAC, VLAN, spanning tree), warstwa 3 (IP — routing, ping bramy), warstwa 4 (TCP/UDP — netstat -an, firewall), warstwa aplikacji (logi, services) — idź zawsze od dołu!
- Wyjaśnij proces Root Cause Analysis (RCA) metodą 5 dlaczegoch: 1) Dlaczego baza nie działa? — nie odpowiada; 2) Dlaczego? — za dużo połączeń; 3) Dlaczego? — wyciek pamięci w aplikacji; 4) Dlaczego? — brak limitów połączeń w konfiguracji; 5) Dlaczego? — nie wdrożono limitów w deployment — zastosuj środek zaradczy (max_connections = 100).
- Omów lokalizację logów systemowych i aplikacyjnych: Linux (/var/log/syslog, /var/log/auth.log, /var/log/nginx/error.log, /var/log/mysql/error.log), Windows (Event Viewer — System, Application, Security), bazy danych (Oracle: diag/.../alert.log, PostgreSQL: pg_log/, MySQL: error.log) — gdzie szukać pierwszych śladów.
- Zdefiniuj narzędzia zaawansowanej diagnostyki: Wireshark — filtry (tcp.port == 443, http.request.uri contains /api), tcpdump — capture na CLI (tcpdump -i eth0 host 192.168.1.1), strace/ltrace (śledzenie syscalli procesu), iostat/vmstat (obciążenie I/O, pamięci) — kiedy użyć każdego.
- Opisz ITIL w kontekście zarządzania incydentem: incident (przerwa/obniżona jakość usługi → przywróć działanie ASAP), problem (przyczyna incidents), change (zmiana w środowisku z approval), Known Error Database (KEDB — dokumentacja recurrent problems z workaroundami) — dlaczego dokumentowanie jest kluczowe.
- Wyjaśnij czas eskalacji i RTO (Recovery Time Objective): ile czasu na przywrócenie usługi krytycznej (np. 15 min), kto ma uprawnienia do eskalacji (2nd level, manager), komunikacja z biznesem (status updates), post-mortem (po awarii — co, dlaczego, jak zapobiec) — proces po incydencie.
- Omów praktyczne przygotowanie do awarii: dokumentacja aktualna (IP, contacty, hasła w sejfie), runbooki (krok-po-kroku procedures dla common failures), alternatywne serwery (hot spare — w standby), backup konfiguracji (configs w Git), testy Disaster Recovery (co pół roku) — lepiej zapobiegać niż leczyć.
- Sformułuj wniosek dla scenariusza z opisu: baza danych nie działa → nie panikuj → zbieraj dowody → stosuj model warstwowy → szukaj w logach → RCA → dokumentuj → zapobiegaj nawrotowi; klucz to systematyczność, nie strzały w ciemność.
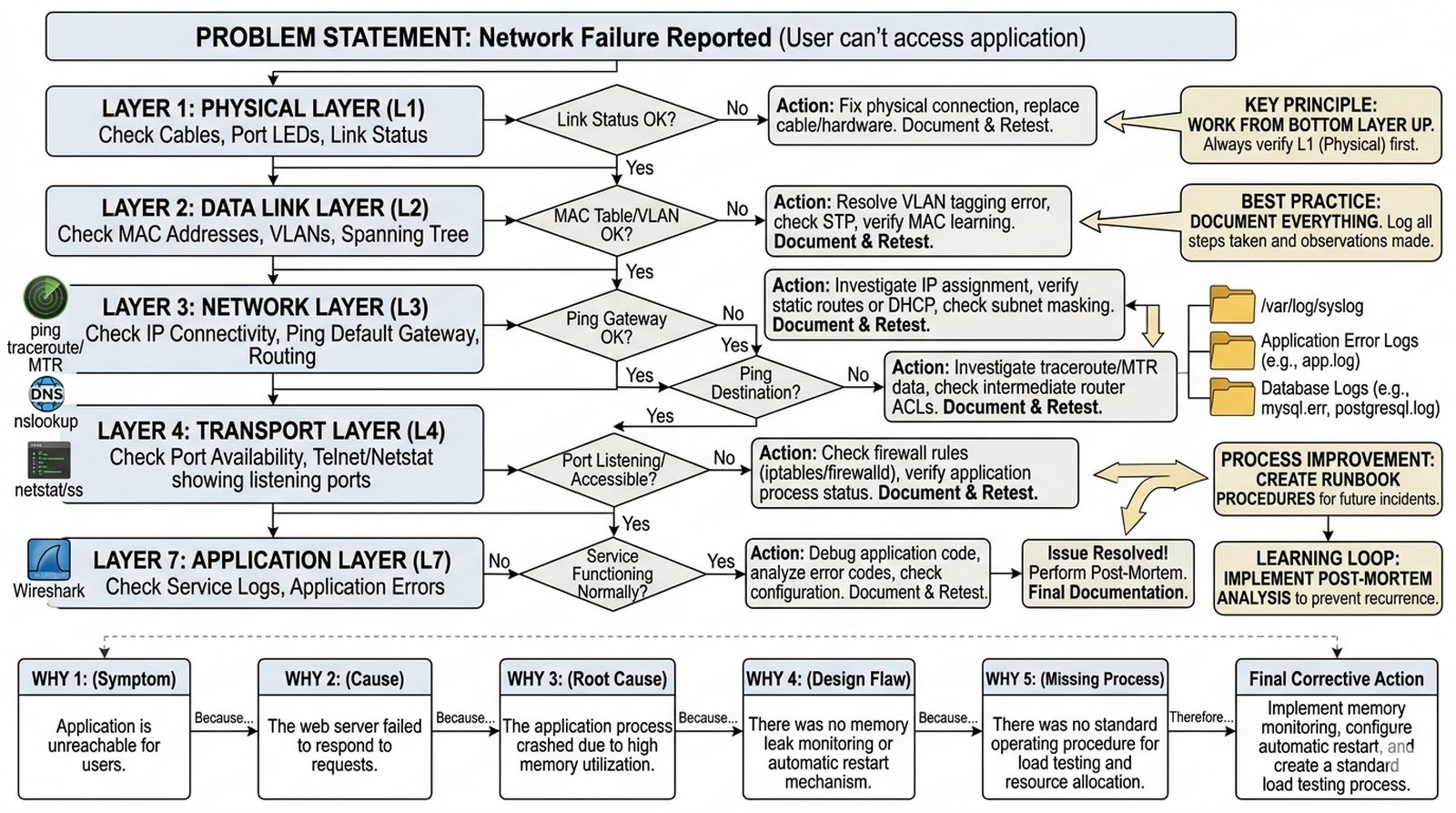
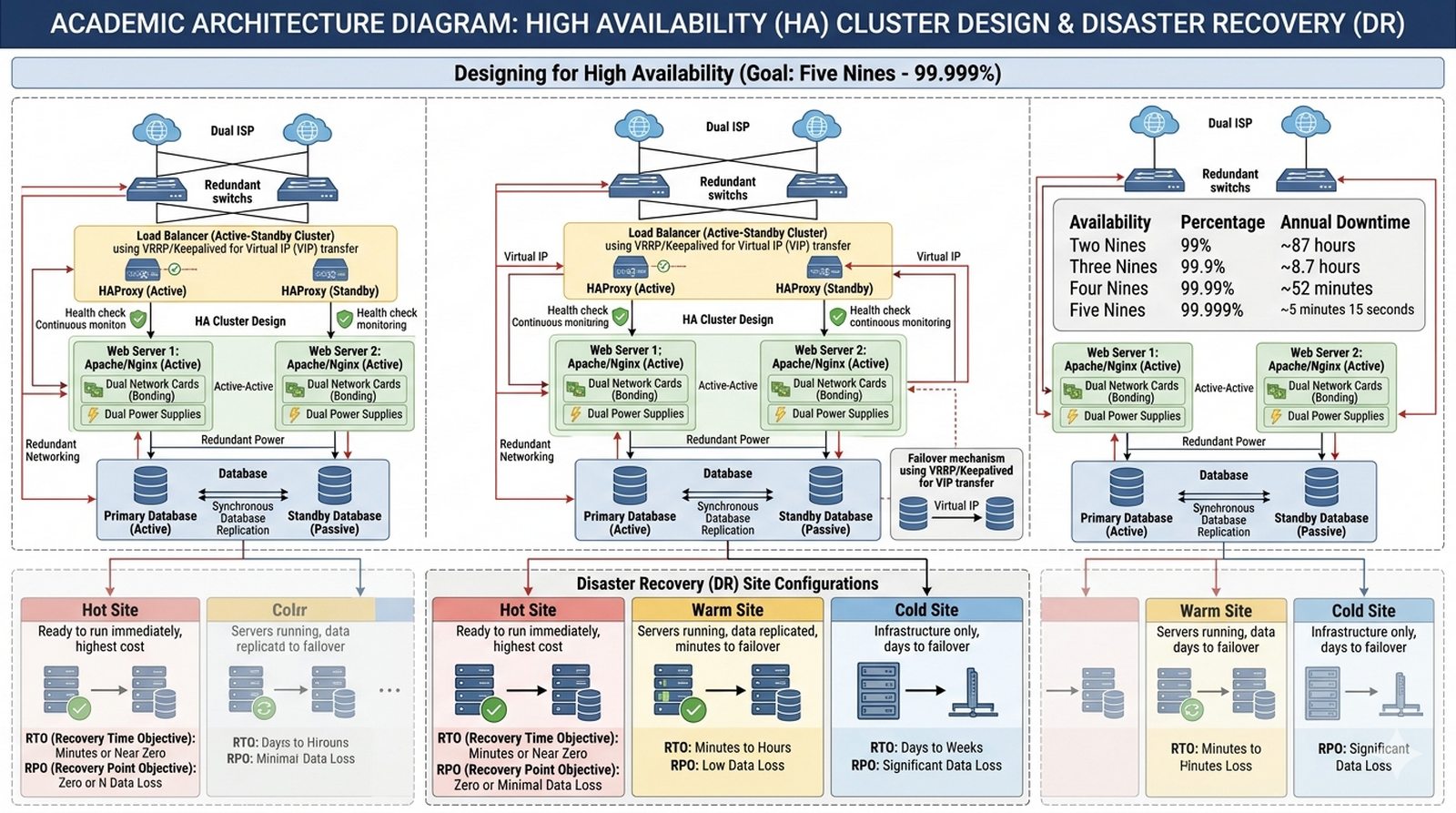
W10 Failover, Cluster, Load Balancing, replikacja baz danych, odzyskiwanie po awarii (Disaster Recovery).
Celem projektu jest szczegółowe przedstawienie architektury systemów wysokiej dostępności (High Availability, HA) i mechanizmów skalowania usług sieciowych w środowisku korporacyjnym, ze szczególnym uwzględnieniem eliminacji pojedynczych punktów awarii (SPOF). Student powinien wyjaśnić koncepcję wskaźnika dostępności wyrażanego w liczbie dziewiątek (np. 99,999% oznacza maksymalnie 5 minut i 15 sekund przestoju rocznie), omówić mechanizmy równoważenia obciążenia (Load Balancing) działające na warstwie 4 (TCP) i warstwie 7 (HTTP) protokołu OSI, przedstawić tryby pracy klastrów serwerowych Active-Active i Active-Passive oraz wyjaśnić zasady replikacji baz danych jako metody ochrony stanu aplikacji. Projekt ma na celu przedstawienie strategii Disaster Recovery obejmującej utrzymywanie zapasowego centrum danych (DR Site) zdolnego do przejęcia funkcji produkcyjnych w przypadku awarii głównej serwerowni, co zapewnia ciągłość działania usług krytycznych dla funkcjonowania przedsiębiorstwa.
Firma świadczy usługi ciągłe 24/7/365 (np. sklep internetowy, system bankowy, platforma gier online) i każda minuta przestoju kosztuje setki tysięcy złotych strat w przychodach oraz utratę zaufania klientów. Masz opracować koncepcję klastra wysokiej dostępności (High Availability, HA) dla serwera WWW i bazy danych, uwzględniając mechanizmy automatycznego przełączania awaryjnego (failover) w przypadku awarii jednego węzła. Kluczowym aspektem jest wskaźnik dostępności wyrażany w liczbie dziewiątek (SLA): 99% (2 x 365 = 17,5h przestoju rocznie), 99,9% ("trzy dziewiątki" = 8,7h), 99,99% ("cztery dziewiątki" = 52 minuty), 99,999% ("pięć dziewiątek" = 5 minut 15 sekund) — każda dziewiątka to 10x wyższy koszt infrastruktury. Omów różnicę między trybem Active-Active (oba węzła obsługują ruch równolegle, przy awarii jeden przejmuje 100% bez przerwywania sesji) a Active-Passive (drugi węzeł czuwa w standby, przełączenie trwa kilka-kilknaście sekund), oraz zasadę eliminacji SPOF (Single Point of Failure) — każdy element infrastruktury musi mieć rezerwę: dwie karty sieciowe (bonding/team), dwa zasilacze (redundancja PSU), dwa łącza ISP (dwa dostawcy). Należy opisać mechanizm Load Balancer (L4 TCP/Haproxy vs L7 HTTP/Nginx) rozkładającego ruch między węzłami, replication bazy danych (synchronous — gwarancja spójności, asynchroniczna — wydajność), oraz Disaster Recovery Site jako oddzielną lokację geograficzną z repliką danych zdolną do przejęcia funkcji produkcyjnych w ciągu RTO (Recovery Time Objective) i RPO (Recovery Point Objective) zdefiniowanych w umowie SLA.
- Wstęp — co oznacza "pięć dziewiątek" (99.999%) dostępności
- Eliminacja pojedynczych punktów awarii (SPOF)
- Równoważenie obciążenia (Load Balancing) — L4 vs L7
- Klastrowanie serwerów — tryb Active-Active vs Active-Passive
- Replikacja baz danych jako metoda ochrony stanu aplikacji
- Disaster Recovery — planowanie na wypadek całkowitej utraty serwerowni
- Podsumowanie
- Przygotuj schemat klastra HA z dwoma serwerami WWW, Load Balancerem (HAProxy/Nginx) pośrodku, shared storage (NAS/SAN) dla sesji i plików statycznych, oraz bazą danych replikowaną — pokaż przepływ żądań i failover w przypadku awarii jednego węzła.
- Utwórz tabelę z wyliczonymi czasami dopuszczalnych przestojów dla różnych poziomów SLA: 99% (2 x 365 = 17,5h/rok = 28 min/tydzień), 99,9% ("trzy dziewiątki" = 8,7h/rok = 10 min/tydzień), 99,99% ("cztery dziewiątki" = 52 min/rok = 1 min/tydzień), 99,999% ("pięć dziewiątek" = 5 min 15 s/rok = 6 s/tydzień) — pokaż koszt Infrastructure.
- Wyjaśnij wskaźniki SLA w kontekście projektu: RTO (Recovery Time Objective — max czas przywrócenia), RPO (Recovery Point Objective — max utrata danych w czasie), MTTR (Mean Time To Recovery), MTBF (Mean Time Between Failures) — pokaż jak definiować cele dla biznesu.
- Opisz tryb Active-Active vs Active-Passive: Active-Active (oba węzły obsługują ruch, failover natychmiastowy bez przerwania sesji, wyższe koszty, load balancing), Active-Passive (drugi węzeł czuwa w standbyHot=ciepły, warm=bez danych, cold=wyłączony, failover ręczny/automatyczny po kilka-kilknaście sekund, niższe koszty).
- Omów mechanizmy Load Balancingu: L4 TCP (HAProxy — routing na podstawie IP:port, stateless), L7 HTTP (Nginx — routing na podstawie URL, cookies, headers), health checks (HTTP GET /health, TCP connect), algorytmy (round robin, least connections, IP hash) — wyjaśnij kiedy każdy.
- Zdefiniuj eliminację SPOF (Single Point of Failure): każdy element infrastruktury musi mieć rezerwę — dwie karty sieciowe (bonding/team), dwa zasilacze (redundancja PSU), dwa łącza ISP (dwa dostawcy), dwa switche (spanning tree), dwa kontrolery macierzy, rezerwowy generator — wyjaśnij dlaczego "n-redundancja" = 1 fizyczny.
- Opisz replikację baz danych: synchroniczna (gwarancja spójności — oba commit przed potwierdzeniem, wyższe opóźnienie, bez utraty danych), asynchroniczna (wysoka wydajność, ryzyko utraty ostatnich transakcji), primary-standby (PGSQL streaming replication, MySQL GTID), multi-primary (rozwiązywanie konfliktów zapisu) — RPO/RTO.
- Omów Disaster Recovery Site: oddzielna lokacja geograficzna (inna serwerownia, min 50+ km), replikacja danych (synch/asynch), ciągła gotowość (hot site — gotowe serwery, RTO min), gotowość (warm site — serwery uruchamiane na żądanie, RTO godziny), mobilizacja (cold site — infrastructure, dni) — wybór według budżetu.
- Wyjaśnij praktyczną implementację klastra HA dla WWW i bazy danych: dwa serwery Apache/Nginx + HAProxy L4/7, VRRP/Keepalived dla wirtualnego IP, shared storage przez NFS/iSCSI, Postgres/MySQL z replikacją, monitoring (Prometheus/Grafana), alerty (pagerduty), testy failover (co miesiąc) — end-to-end.
- Sformułuj wniosek decyzyjny: "pięć dziewiątek" (99,999%) kosztuje 10x więcej niż "cztery dziewiątki" (99,99%); wybierz SLA odpowiednie do krytyczności usługi i budżetu; błędy (2-3x wyższy koszt) gorszego SLA w dłuższej perspektywie (utrata klientów, koszty odtworzenia) — inwestycja w HA zwraca się w ciągu miesięcy.