Projekty muszą zostać zrealizowane w środowisku symulacyjnym (GNS3, EVE-NG) lub na sprzęcie fizycznym.
Objętość dokumentacji ok. 30 stron A4 (font Times New Roman 12 pkt, interlinia 1,5, marginesy 2,5 cm).
Wymagana struktura: strona tytułowa, aktywny spis treści, szczegółowa charakterystyka technologii (standardy, RFC), dokumentacja techniczna (schematy logiczne/fizyczne), listingi konfiguracji z komentarzem, weryfikacja działania (testy failover), polityka bezpieczeństwa i backupu, podsumowanie.
Prace należy wysyłać w formacie PDF oraz ZIP (z plikami projektu). Zachowaj najwyższą staranność techniczną i językową.
Spis treści zadań projektowych
- Cluster High Availability dla usług DHCP i DNS
- Hierarchiczna synchronizacja czasu NTP i resolver DNS Caching
- Utwardzanie dostępu SSH oraz bramy RDP w infrastrukturze IT
- Monitorowanie proaktywne NMS z wykorzystaniem SNMP i Grafany
- Centralna tożsamość Active Directory i integracja Linux (SSO)
- Centralizacja logów i audyt zdarzeń w stosie ELK (Elasticsearch/Kibana)
- Obsługa DHCP Relay w złożonych topologiach Hub-and-Spoke
- Projekt strefy DMZ z Reverse Proxy i DNSSEC
- Disaster Recovery: Strategia backupu i odtwarzania "Bare Metal"
- Obserwowalność usług (Observability) z Prometheus i Exporters
W2 Podstawowe usługi infrastrukturalne, slajdy 10-15.
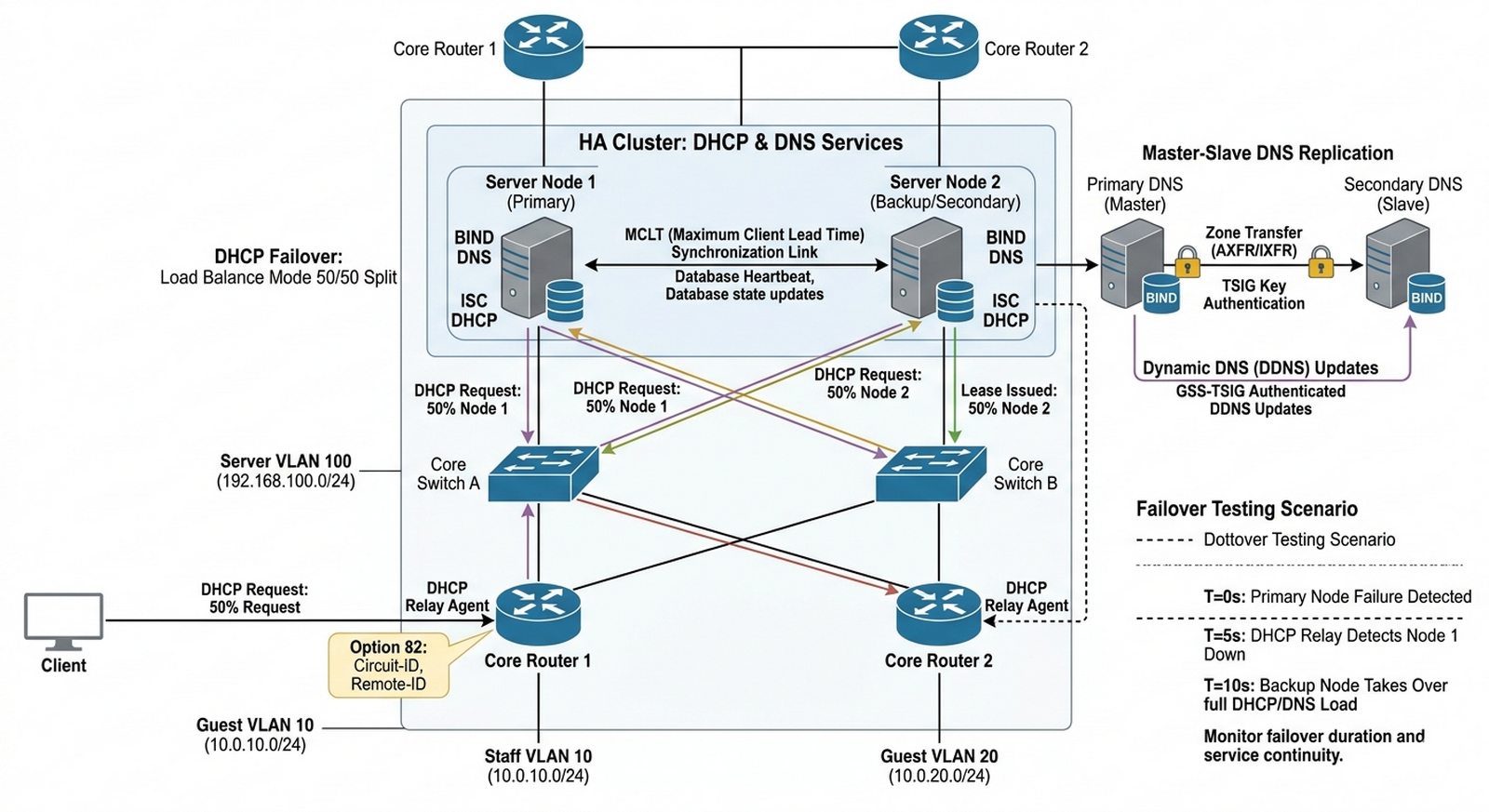
Celem projektu jest zaprojektowanie i wdrożenie nadmiarowej infrastruktury usług DHCP i DNS zapewniającej ciągłość działania w przypadku awarii jednego z węzłów. Projekt obejmuje implementację klastra DHCP w trybie Load Balance lub Hot Standby oraz skonfigurowanie replikacji DNS Master-Slave z wykorzystaniem bezpiecznego transferu stref.
- Konfiguracja klastra DHCP Failover w trybie Load Balance (podział 50/50) lub Hot Standby z automatycznym przejmowaniem ról po awarii serwera głównego.
- Implementacja Master-Slave DNS z szyfrowanym transferem stref (TSIG) oraz automatyczną synchronizacją wpisów Dynamic DNS pochodzących z dzierżawy adresów DHCP.
- Wdrożenie mechanizmu monitorowania stanu klastra i alertowania w przypadku utraty komunikacji między węzłami (MCLT, partner-down).
- Przeprowadzenie symulacji awarii serwera głównego i pomiaru czasu przełączenia usługi (failover test z dokumentacją w logach).
W ramach projektu student realizuje następujące zadania praktyczne:
- Projektowanie topologii redundanckiej — zaprojektować i wdrożyć w środowisku GNS3/EVE-NG fizyczną i logiczną strukturę sieci łączącą dwa węzły serwerowe z routerami centralnymi i przełącznikami, zapewniając co najmniej dwie niezależne ścieżki komunikacyjne między węzłami.
- Konfiguracja BIND jako serwera Master DNS — zainstalować i skonfigurować serwer BIND na węźle primary, tworząc strefy forward (firma.local) i reverse (192.168.x.in-addr.arpa) z odpowiednimi rekordami SOA, NS, A, CNAME, MX i PTR.
- Implementacja Slave DNS z transferem TSIG — skonfigurować drugi węzeł jako serwer Slave DNS, implementując bezpieczny transfer stref z wykorzystaniem symetrycznego klucza TSIG (TSIG key authentication) dla ochrony przed nieautoryzowanym transferem stref.
- Wdrożenie klastra DHCP Failover w trybie Load Balance — skonfigurować dwa serwery DHCP (ISC-DHCP lub Windows Server) w trybie Load Balance z podziałem obciążenia 50/50, definiując wspólne zakresy adresów, exclusions i rezerwacje dla serwerów.
- Konfiguracja mechanizmu MCLT (Maximum Client Lead Time) — zaimplementować i przetestować MCLT jako zabezpieczenie przed utratą synchronizacji między węzłami klastra DHCP w przypadku awarii łącza sieciowego.
- Integracja DHCP z Dynamic DNS (DDNS) — skonfigurować automatyczną aktualizację stref DNS przez serwer DHCP przy każdym przydziale lub odnowieniu dzierżawy adresu IP, z wykorzystaniem zasady nsupdate i uwierzytelniania GSS-TSIG.
- Konfiguracja DHCP Relay z opcjami 82 — wdrożyć relay agent na routerach w segmentach sieci VLAN, konfigurując opcję 82 (Circuit-ID i Remote-ID) umożliwiającą serwerowi DHCP identyfikację źródła zapytania.
- Symulacja awarii i testy failover — przeprowadzić kontrolowane wyłączenie węzła primary, dokumentując w logach systemowych czas przejęcia usług przez węzeł backupowy oraz weryfikując ciągłość działania klientów DHCP i DNS.
- Zbudowanie topologii redundantnej w GNS3/EVE-NG.
- Instalacja systemów bazowych i hardening (wyłączenie zbędnych usług).
- Konfiguracja BIND Master DNS (strefy forward/reverse).
- Implementacja Slave DNS z transferem stref zabezpieczonym TSIG.
- Konfiguracja klastra DHCP Failover (ISC-DHCP lub Windows).
- Wdrożenie DHCP Relay na routerach segmentujących sieć.
- Integracja Dynamic DNS (częsta aktualizacja stref przez DHCP).
- Mitygacja ataków: DHCP Snooping na przełącznikach.
- Symulacja awarii serwera głównego i analiza czasu przełączenia.
- Monitoring stanu klastra przy użyciu logów systemowych.
| Element | Opis wymagań |
|---|---|
| Schemat L3 | Logiczna ścieżka zapytań DHCP/DNS z uwzględnieniem redundancji. |
| Logi Failover | Zrzuty ekranu z momentu przełączenia usług po symulowanej awarii. |
! Krok 1: Włączenie funkcji DHCP i wyłączenie konfliktu adresów
service dhcp
DHCP service enabled
no ip dhcp conflict logging ; Wyłączenie logowania konfliktów (opcjonalne)
Conflict logging disabled
! Krok 2: Utworzenie puli DHCP dla VLAN 100
ip dhcp pool VLAN100_POOL
network 192.168.100.0 255.255.255.0
default-router 192.168.100.1
dns-server 10.0.0.5 10.0.0.6
domain-name firma.local
lease 8 12 ; 8 dni, 12 godzin
DHCP pool created
! Krok 3: Konfiguracja exclusion range (adresy statyczne)
ip dhcp excluded-address 192.168.100.1 192.168.100.50
Excluded addresses: 192.168.100.1 - 192.168.100.50
! Krok 4: Konfiguracja interfejsu VLAN z DHCP Relay
interface GigabitEthernet0/1.100
description VLAN100_DHCP_RELAY
encapsulation dot1Q 100
ip address 192.168.100.1 255.255.255.0
ip helper-address 10.0.0.10 ; Serwer DHCP Primary
ip helper-address 10.0.0.11 ; Serwer DHCP Secondary
no shutdown
Interface GigabitEthernet0/1.100 is up
! Krok 5: Włączenie DHCP Relay Agent Information (Option 82)
ip dhcp relay information option
DHCP Relay Agent Information Option enabled
! Krok 6: Konfiguracja drugiego VLAN (VLAN 200)
interface GigabitEthernet0/1.200
description VLAN200_DHCP_RELAY
encapsulation dot1Q 200
ip address 192.168.200.1 255.255.255.0
ip helper-address 10.0.0.10
no shutdown
Interface GigabitEthernet0/1.200 is up
! Krok 7: Weryfikacja konfiguracji DHCP Relay
show ip interface GigabitEthernet0/1.100 | include helper
Helper addresses: 10.0.0.10, 10.0.0.11
show ip dhcp pool VLAN100_POOL
Pool: VLAN100_POOL Utilization: 45% (115 addresses) Total addresses: 254 Leased: 0 Pending: 0 Available: 254
! Krok 8: Weryfikacja dzierżaw DHCP
show ip dhcp binding
IP address Client-ID/ Hardware address User address 192.168.100.51 0100.1c42.1234.00 001c.4212.3456 - 192.168.100.52 0100.1c42.1235.00 001c.4212.3457 -
! Krok 9: Debug DHCP Relay
debug ip dhcp relay
DHCPD: Relay forward packet from 192.168.100.51 to 10.0.0.10 DHCPD: Option 82 present in relay packet
! Krok 10: Zapis konfiguracji
write memory
Building configuration... [OK]
W2 Usługi infrastrukturalne, slajdy 16-19.
Celem projektu jest zaprojektowanie hierarchicznej struktury NTP zapewniającej synchronizację czasu w warstwie Stratum 2/3 dla wszystkich urządzeń w sieci rozproszonej oraz implementacja lokalnego resolvera DNS redukującego opóźnienia i obciążenie łączy WAN poprzez cache'owanie odpowiedzi.
- Zbudowanie hierarchii NTP: serwery Stratum 2 w centrali synchronizujące się z zewnętrznymi źródłami czasu (np. ptp.ntp.org, GPS), oddziały jako klienci Stratum 3 pobierający czas wyłącznie z serwerów centralnych.
- Wdrożenie uwierzytelniania NTP z wykorzystaniem symetrycznych kluczy (Symmetric Key Authentication) dla ochrony przed atakami man-in-the-middle.
- Konfiguracja lokalnego resolvera DNS (caching-only) w każdym oddziale z ustawieniem odpowiednich TTL oraz ograniczeniem rekursji tylko do sieci lokalnych.
- Optymalizacja cache'owania: konfiguracja minimalnych TTL dla dynamicznych wpisów, preload popularnych domen, statystki hit ratio z wykorzystaniem narzędzi dig/nslookup.
W ramach projektu student realizuje następujące zadania praktyczne:
- Projektowanie hierarchii NTP Stratum — zaprojektować trójpoziomową strukturę synchronizacji czasu, gdzie serwery w centrali (Stratum 2) pobierają czas z zewnętrznych źródeł (ptp.ntp.org, ntp.gum.gov.pl lub lokalnego GPS), a oddziały (Stratum 3) synchronizują się wyłącznie z serwerami centralnymi.
- Konfiguracja serwera NTP w centrali — zainstalować i skonfigurować serwer NTP (ntpd lub chronyd) na serwerach węzłów centralnych, definiując preferowane źródła czasu, parametry poll interval oraz konfigurując wartości stratum dla serwera lokalnego.
- Implementacja uwierzytelniania NTP z kluczami symetrycznymi — wygenerować i wdrożyć symetryczne klucze MD5/SHA1 dla NTP, konfigurując ich użycie na serwerach i klientach w celu zabezpieczenia przed atakami man-in-the-middle i fałszowaniem czasu.
- Konfiguracja ACL dla usług NTP — zaimplementować listy kontroli dostępu na routerach i serwerach, ograniczające które sieci mogą wysyłać zapytania NTP do serwerów centralnych oraz definiujące interfejsy nasłuchu.
- Monitorowanie dryftu zegara i jakości synchronizacji — skonfigurować ciągłe monitorowanie parametrów NTP za pomocą poleceń ntpq -p, ntpdc -p oraz skryptów sprawdzających offset, jitter i delay, dokumentując wyniki w raporcie.
- Instalacja i konfiguracja resolvera DNS caching-only — wdrożyć lokalny resolver DNS (Unbound, BIND caching lub dnsmasq) w każdym oddziale, konfigurując go jako caching-only server bez autorytatywnych stref.
- Optymalizacja cache'owania DNS — dostosować wartości TTL dla różnych typów rekordów, zaimplementować preload popularnych domen firmowych (np. microsoft.com, google.com) oraz skonfigurować aggressive negative caching.
- Ograniczenie rekursji DNS i zabezpieczenia — skonfigurować resolver tak, aby realizował rekursywne zapytania tylko dla sieci lokalnych (oddziałów), blokując zapytania z sieci zewnętrznych w celu zapobiegania atakom DNS amplification.
- Testy wydajności i analiza oszczędności pasma WAN — przeprowadzić pomiary czasu odpowiedzi DNS przed i po wdrożeniu cache'owania, dokumentując hit ratio oraz oszacowanie oszczędności pasma na łączach WAN.
- Zaprojektowanie hierarchii NTP (Stratum 2 w centrali).
- Wdrożenie uwierzytelniania NTP (Symmetric Keys).
- Konfiguracja ACL dla usług czasu na routerach/serwerach.
- Monitorowanie dryftu zegara (ntpq -p).
- Instalacja resolvera DNS (np. Unbound lub BIND).
- Konfiguracja Forwarders do zaufanych serwerów publicznych.
- Ograniczenie rekursji DNS tylko dla sieci lokalnych (ACL).
- Optymalizacja TTL dla wpisów w pamięci podręcznej.
- Testy wydajności zapytań (dig query time).
- Monitoring logów pod kątem prób nadużyć (DNS amplification protection).
# Krok 1: Włączenie klienta NTP
/system ntp client set enabled=yes
enabled: yes
# Krok 2: Dodanie serwerów NTP (preferowany i zapasowy)
/system ntp client servers add address=10.1.1.5 disabled=no
Numbers: 0
/system ntp client servers add address=10.1.1.6 disabled=no
Numbers: 1
# Krok 3: Dodanie zewnętrznych serwerów NTP (stratum 1/2)
/system ntp client servers add address=0.pl.pool.ntp.org
Numbers: 2
/system ntp client servers add address=1.pl.pool.ntp.org
Numbers: 3
# Krok 4: Włączenie trybu multicast (opcjonalne dla lokalnej grupy)
/system ntp client set multicast=yes
multicast: yes
# Krok 5: Konfiguracja strefy czasowej
/system clock set time-zone-name=Europe/Warsaw
time-zone-name: Europe/Warsaw
# Krok 6: Weryfikacja stanu synchronizacji NTP
/system ntp client print
enabled: yes mode: unicast multicast: yes dynamic-servers: 2 poll-size: 600 clock-status: synchronized last-update: 2026-04-26 14:32:15 offset: 0.002345 stratum: 3 primary-server: 10.1.1.5 sync-system: yes
# Krok 7: Lista skonfigurowanych serwerów NTP
/system ntp client servers print
# ADDRESS DISABLED 0 10.1.1.5 no 1 10.1.1.6 no 2 0.pl.pool.ntp.org no 3 1.pl.pool.ntp.org no
# Krok 8: Weryfikacja aktualnego czasu systemowego
/system clock print
date: apr/26/2026 time: 14:32:20 timezone: Europe/Warsaw time-zone-name: Europe/Warsaw gmt-offset: +02:00 dst-active: no
# Krok 9: Konfiguracja serwera NTP (jeśli router ma być serwerem)
/system ntp server set enabled=yes multicast=yes broadcast=yes
enabled: yes
# Krok 10: Monitoring NTP - szczegółowa informacja
/system ntp client get all
clock-status: synchronized last-update: 2026-04-26 14:32:20 offset: 0.002345 ms stratum: 3 primary-server: 10.1.1.5 roundtrip: 5.234 ms selected-server: 10.1.1.5
# Krok 11: Konfiguracja schedulera do synchronizacji ręcznej (backup)
/system scheduler add name=ntp-sync interval=1d on-event="/system ntp client resync" start-time=startup
started: yes
# Krok 12: Zapis konfiguracji
/system backup save name=ntp_config
saved: ntp_config.backup

W7 Bezpieczeństwo usług, slajdy 7-12.
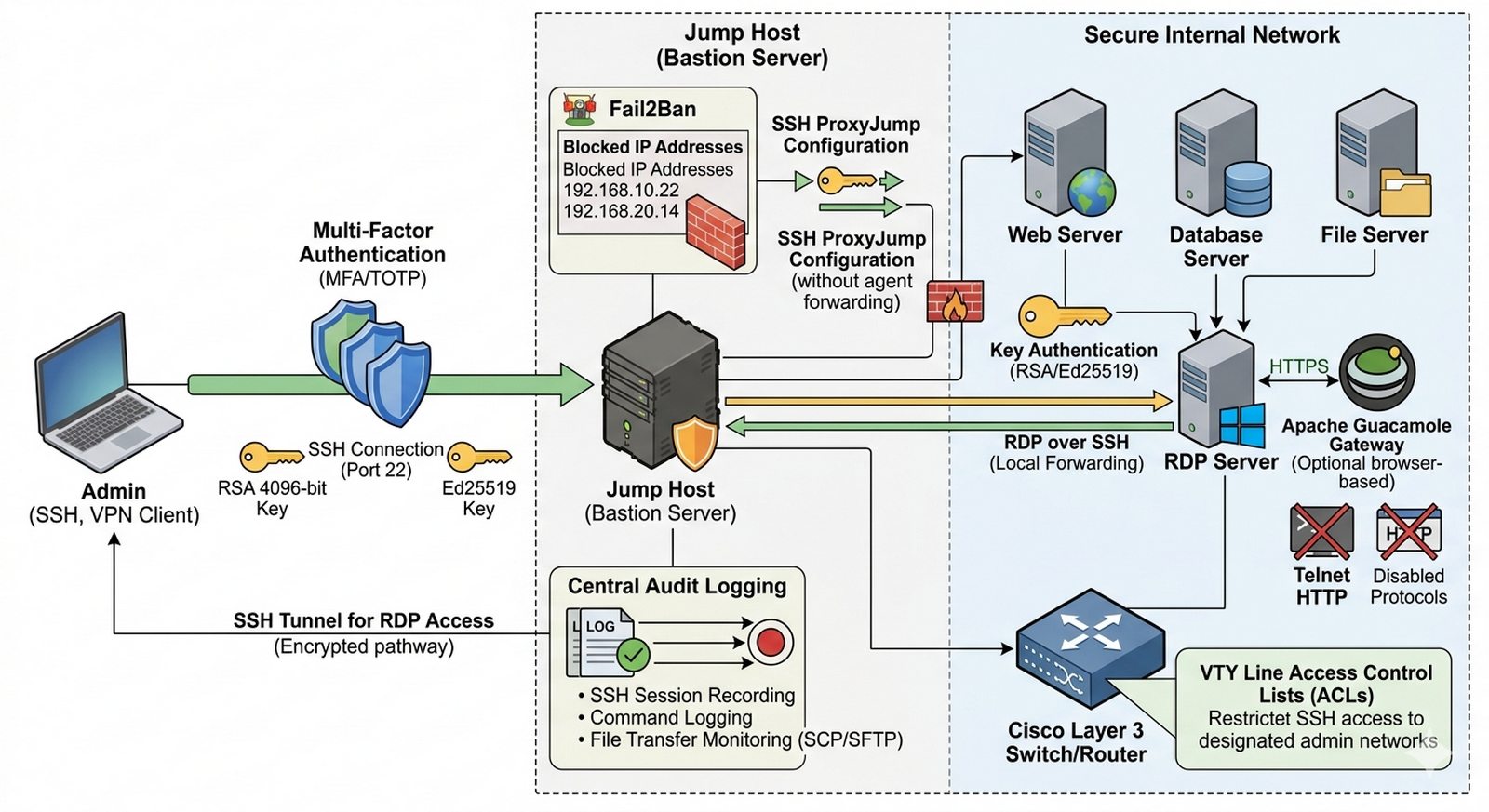
Celem projektu jest wdrożenie bezpiecznej architektury zarządzania zdalnego opartej na jump hostcie (bastion) z uwierzytelnianiem wieloskładnikowym, eliminacja niezaszyfrowanych protokołów (Telnet, HTTP) oraz implementacja tuneli SSH dla dostępu do usług administracyjnych.
- Wdrożenie jump hosta jako jedynego publicznego punktu dostępowego SSH z wymuszeniem kluczy asymetrycznych (RSA 4096/Ed25519) i TOTP MFA.
- Konfiguracja ProxyJump (SSH config) dla bezpiecznego przechodzenia przez bastion do serwerów wewnętrznych bez agent forwarding.
- Implementacja bramy RDP przez tunel SSH lub dedykowanego Gateway (np. Apache Guacamole) z autentykacją certyfikatów i jednorazowych kodów.
- Skonfigurowanie centralnego logowania sesji SSH (audit logs) oraz automatycznej blokady adresów IP po nieudanych próbach logowania (Fail2Ban).
W ramach projektu student realizuje następujące zadania praktyczne:
- Generowanie i dystrybucja kluczy SSH — wygenerować pary kluczy asymetrycznych RSA 4096-bitowych lub Ed25519 dla wszystkich administratorów, skonfigurować klucze publiczne na urządzeniach Cisco i serwerach Linux, wyłączając uwierzytelnianie hasłem.
- Wdrożenie Jump Host (Bastion) — zainstalować i skonfigurować dedykowany serwer bastionowy z ograniczonym dostępem, wdrożyć restricted shell dla użytkowników administracyjnych oraz skonfigurować fail2ban do automatycznego blokowania adresów IP po nieudanych próbach logowania.
- Konfiguracja SSH ProxyJump — skonfigurować plik ~/.ssh/config z definicjami ProxyJump umożliwiającymi bezpieczne przechodzenie przez jump hosta do serwerów wewnętrznych bez konieczności forwardowania agentów.
- Implementacja uwierzytelniania wieloskładnikowego (MFA/TOTP) — skonfigurować na jump hoście drugi składnik uwierzytelniania z wykorzystaniem Google Authenticator, FreeOTP lub dedykowanego serwera RADIUS, wymuszając TOTP dla wszystkich połączeń SSH.
- Utwardzanie SSH na urządzeniach Cisco — skonfigurować SSH w wersji 2 na routerach i przełącznikach, ustawić timeout sesji, wyłączyć SSH v1, skonfigurować silne szyfry (AES-GCM) oraz zdefiniować listy ACL ograniczające dostęp do linii VTY.
- Wdrożenie bramy RDP przez SSH tunneling — skonfigurować tunele SSH dla usług RDP lub wdrożyć Apache Guacamole jako bramę dostępową, implementując uwierzytelnianie certyfikatów klientów i jednorazowych kodów TOTP.
- Centralne logowanie sesji SSH (Audit Logs) — skonfigurować mechanizm rejestrowania wszystkich sesji SSH na jump hoście, włączając protokółiowanie poleceń, transferów plików (SCP/SFTP) i zachowań użytkowników.
- Testy bezpieczeństwa i dokumentacja prób włamania — przeprowadzić kontrolowane próby logowania z zablokowanych adresów IP, testowanie blokad Fail2Ban oraz dokumentację logów wskazujących nieudane próby uwierzytelnienia.
- Wyłączenie Telnet/HTTP na wszystkich urządzeniach.
- Generowanie kluczy asymetrycznych i wdrożenie na urządzenia Cisco/Linux.
- Konfiguracja SSH v2 (timeout, retries, port).
- Implementacja Jump Hosta z ograniczeniami systemowymi (restricted shell).
- Konfiguracja tuneli SSH dla aplikacji administracyjnych.
- Wdrożenie bramy RD Gateway lub odpowiednika open-source.
- Audit log: zbieranie informacji o sesjach SSH w centralnym logu.
- MFA: wdrożenie drugiego składnika (np. Google Authenticator) dla Jump Hosta.
- Testy: próba logowania z zablokowanego adresu IP (ACL).
- Analiza logów pod kątem nieudanych prób logowania (Fail2Ban).
! Krok 1: Konfiguracja hostname i domain-name (wymagane do generowania kluczy)
hostname Router-Core
Router-Core
ip domain-name corp.local
corp.local
! Krok 2: Generowanie klucza RSA 3072-bitowego
crypto key generate rsa modulus 3072
% Generating 3072 bit RSA keys, keys will be non-exportable...[OK]
! Krok 3: Włączenie SSH v2 i wyłączenie SSH v1
ip ssh version 2
SSH v2 enabled
ip ssh rsa keypair-name ssh-key
RSA key pair configured
! Krok 4: Konfiguracja parametrów SSH (timeout, retries, port)
ip ssh time-out 60
SSH timeout set to 60 seconds
ip ssh authentication-retries 3
SSH authentication retries set to 3
ip ssh port 22
SSH port set to 22
! Krok 5: Konfiguracja silnych algorytmów szyfrowania (cipher)
ip ssh cipher aes256-gcm@openssh.com
SSH cipher configured
! Krok 6: Konfiguracja linii VTY z ACL i SSH only
line vty 0 4
access-class 10 in
transport input ssh
transport output ssh
exec-timeout 10 0
logging synchronous
VTY 0-4 configured for SSH only
line vty 5 15
access-class 10 in
transport input ssh
exec-timeout 5 0
VTY 5-15 configured for SSH only
! Krok 7: Definicja ACL dla dozwolonych sieci admin
ip access-list standard 10
permit 10.0.0.0 0.0.0.255
permit 192.168.100.0 0.0.0.255
deny any log
ACL 10 configured
! Krok 8: Konfiguracja AAA dla SSH
aaa new-model
AAA NEW MODEL enabled
aaa authentication login default local
AAA authentication enabled
! Krok 9: Weryfikacja konfiguracji SSH
show ip ssh
SSH Enabled - version 2.0 Auth methods: publickey,password Authentication timeout: 60 secs Authentication retries: 3 Rsa key has been generated Port: 22
show ssh
Connection Version Encryption HMAC State 0 2.0 aes256-gcm hmac-sha2-256 Session Started
! Krok 10: Wyłączenie Telnet na linii console
line console 0
transport output none
exec-timeout 5 0
Console configured - telnet disabled
! Krok 11: Zapis konfiguracji
write memory
Building configuration... [OK]
W6 Monitorowanie i utrzymanie, slajdy 1-7.
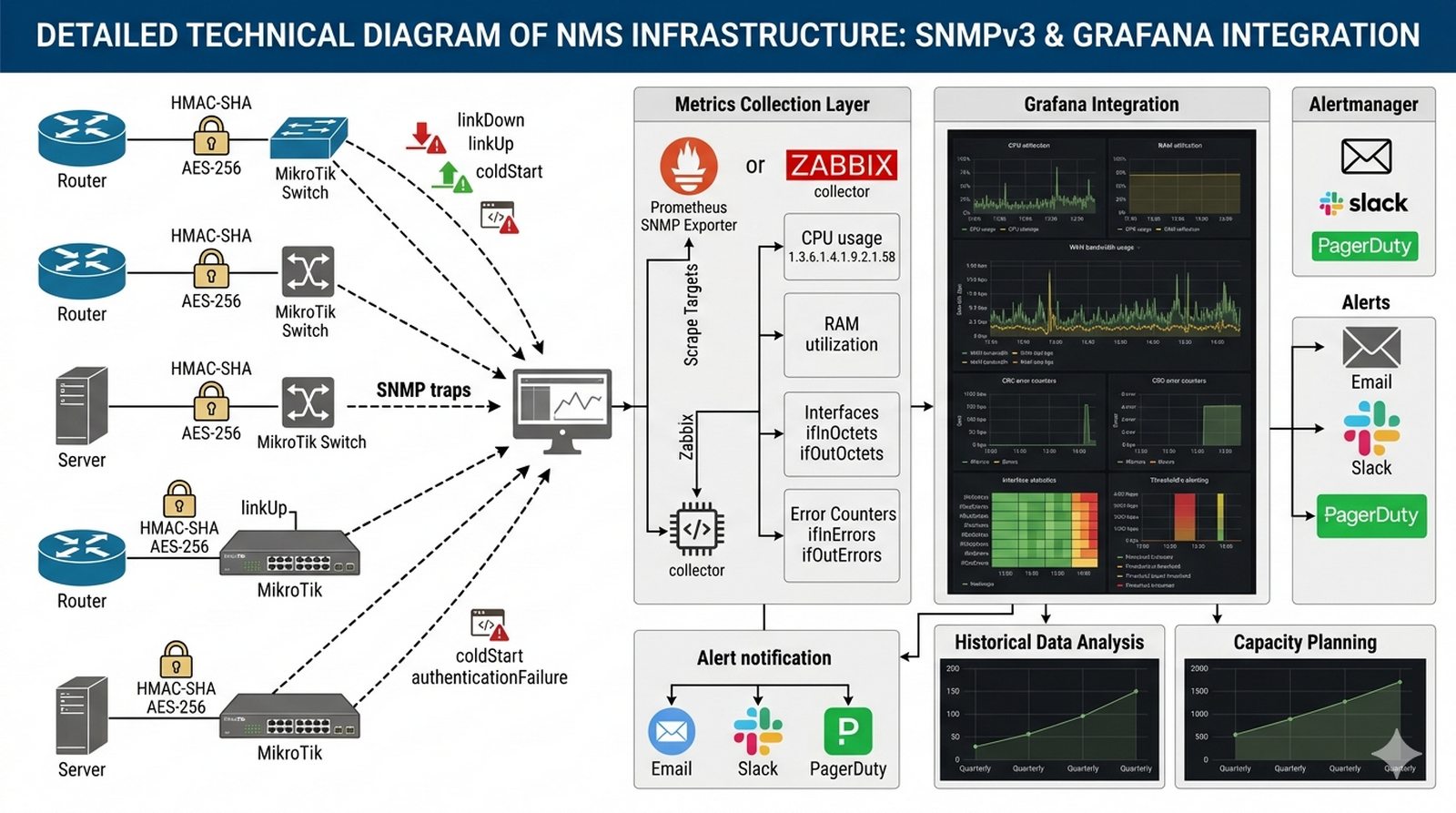
Celem projektu jest zbudowanie centralnego systemu monitorowania sieci (NMS) zapewniającego podgląd w czasie rzeczywistym parametrów wydajnościowych urządzeń sieciowych i serwerów przy użyciu bezpiecznego protokołu SNMPv3 z szyfrowaniem.
- Konfiguracja SNMPv3 z uwierzytelnianiem (HMAC-SHA) i szyfrowaniem (AES-256) dla wszystkich urządzeń sieciowych Cisco/MikroTik i serwerów.
- Inwentaryzacja MIB i wybór kluczowych OID do monitorowania (CPU, RAM, interfejsy sieciowe, błędy CRC, wykorzystanie pasma).
- Wdrożenie kolektora metryk (Prometheus SNMP Exporter lub Zabbix) z konfiguracją przesyłania SNMP Traps do centralnej konsoli alertingowej.
- Integracja z Grafaną: projektowanie interaktywnych dashboardów z alertami progowymi i powiadomieniami (e-mail, Slack/PagerDuty) przy przekroczeniu ustalonego progu.
W ramach projektu student realizuje następujące zadania praktyczne:
- Konfiguracja SNMPv3 z uwierzytelnianiem i szyfrowaniem — skonfigurować SNMPv3 na wszystkich urządzeniach Cisco i MikroTik z wykorzystaniem HMAC-SHA jako protokołu uwierzytelniania oraz AES-256 do szyfrowania przesyłanych danych, definiując odpowiednie grupy i użytkowników.
- Inwentaryzacja MIB i selekcja kluczowych OID — przeprowadzić inwentaryzację dostępnych MIB na urządzeniach sieciowych, wybierając krytyczne OID do monitorowania: 1.3.6.1.4.1.9.2.1.58 (CPU), 1.3.6.1.4.1.9.2.1.56 (RAM), ifInOctets/ifOutOctets dla interfejsów, ifInErrors/ifOutErrors dla błędów.
- Instalacja i konfiguracja kolektora metryk — wdrożyć Prometheus SNMP Exporter lub Zabbix jako kolektor danych, definiując scrape targets dla wszystkich urządzeń sieciowych i serwerów z odpowiednimi interwałami pobierania danych.
- Konfiguracja przesyłania SNMP Traps — skonfigurować urządzenia Cisco do wysyłania SNMP Traps (linkDown, linkUp, coldStart, authenticationFailure) do centralnej konsoli zarządzania, definiując trap filters i severity levels.
- Instalacja i konfiguracja Grafany — zainstalować Grafanę, skonfigurować datasource (Prometheus/Zabbix), zdefiniować organizacje i zespoły użytkowników oraz skonfigurować inicialne ustawienia bezpieczeństwa.
- Projektowanie interaktywnych dashboardów — zaprojektować i wdrożyć dashboardy Grafana wyświetlające czasu rzeczywistego: utylizację CPU i RAM, wykorzystanie pasma na łączach WAN (bps), licznik błędów CRC, statystyki interfejsów oraz heatmapy obciążenia.
- Definiowanie progów alarmowych i powiadomień — skonfigurować Alertmanager z definicjami alertów dla przekroczenia progów (np. CPU > 80% przez 5 min), skonfigurować kanały powiadomień (e-mail, Slack, PagerDuty) z odpowiednimi grupowaniami i eskalacjami.
- Analiza historyczna i Capacity Planning — wykorzystać dane historyczne do analizy trendów wydajnościowych, tworzenia raportów wykorzystania zasobów oraz planowania pojemności (capacity planning) na kolejne kwartały.
- Konfiguracja SNMP v3 (Auth/Priv) na urządzeniach Cisco.
- Wybór i instalacja kolektora (np. Prometheus SNMP Exporter lub Zabbix).
- Inwentaryzacja MIB i wybór OID do monitorowania.
- Konfiguracja przesyłania SNMP Traps do centralnej konsoli.
- Instalacja i konfiguracja Grafany (Data Sources).
- Projektowanie Dashboardów (panele czasu rzeczywistego).
- Definiowanie progów alarmowych (Alertmanager).
- Integracja powiadomień z komunikatorem zewnętrznym.
- Analiza historyczna trendów (Capacity Planning).
- Testy: generowanie sztucznego obciążenia i obserwacja wykresów.
! Krok 1: Wyłączenie SNMP v1/v2c (jeśli nie są potrzebne)
no snmp-server ; Wyłącza SNMP całkowicie - opcjonalne
SNMP disabled
! Krok 2: Konfiguracja lokalizacji i kontaktu SNMP
snmp-server location DataCenter-Rack-A1
Location set
snmp-server contact netadmin@corp.local
Contact set
! Krok 3: Utworzenie grupy SNMPv3 z priv (auth + encryption)
snmp-server group ADMINS v3 priv ; authNoPriv, authPriv
SNMP group created
! Krok 4: Utworzenie użytkownika SNMPv3 z SHA i AES
snmp-server user adminuser ADMINS v3 auth sha StrongPass1 priv aes 128 StrongPriv2
SNMP user created
! Krok 5: Utworzenie drugiego użytkownika (tylko auth - no priv)
snmp-server user monitoruser ADMINS v3 auth sha MonitorPass1
SNMP user (auth only) created
! Krok 6: Konfiguracja widoku (view) dla grupy
snmp-server view isoView iso included
View created
snmp-server group ADMINS v3 priv read isoView write isoView
Group updated with views
! Krok 7: Konfiguracja ACL dla dostępu SNMP
snmp-server community private RW ACL 10 ; Jeśli potrzebne v2c
SNMP community configured
! Krok 8: Włączenie SNMP Traps
snmp-server enable traps
SNMP traps enabled
snmp-server enable traps authentication ; Trap przy nieudanej autoryzacji
Authentication traps enabled
snmp-server enable traps link ; Trap przy zmianie stanu portu
Link traps enabled
! Krok 9: Konfiguracja hosta dla trapów
snmp-server host 10.0.5.50 version 3 priv adminuser
SNMP trap host configured
! Krok 10: Weryfikacja konfiguracji SNMP
show snmp group
groupname: ADMINS security model: v3 contextname: storage-type: nonvolatile status: active groupname: ADMINS security model: v3 security level: priv ...
show snmp user
User name: adminuser Engine ID: 800000090300C2000B4C0000 storage-type: nonvolatile Authentication protocol: SHA Privacy protocol: AES128
! Krok 11: Weryfikacja statusu SNMP
show snmp
Chassis: RTR-CORE-01 Location: DataCenter-Rack-A1 Contact: netadmin@corp.local 184 packets input 0 packets output 0 messages delivered to network
! Krok 12: Test SNMPwalk
! snmpwalk -v3 -u adminuser -l authPriv -a SHA -A StrongPass1 -x AES -X StrongPriv2 10.0.0.1 sysDescr
SNMPWALK: System Description = Cisco IOS Software...
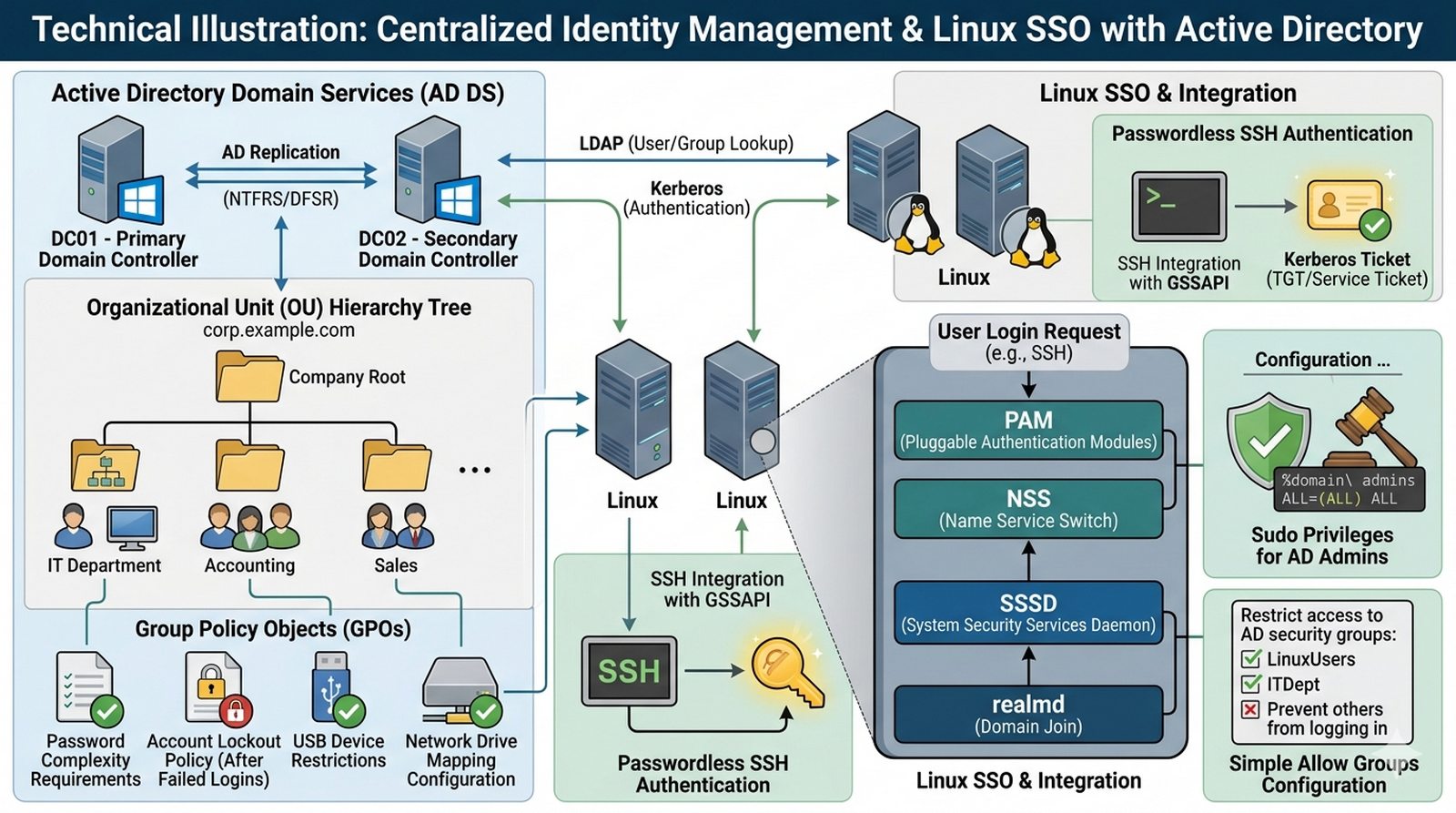
W2 Usługi infrastrukturalne (AD/IAM), slajdy 20-30.
Celem projektu jest wdrożenie scentralizowanego systemu zarządzania tożsamością w środowisku heterogenicznym (Windows/Linux) z wykorzystaniem Active Directory oraz zapewnienie Single Sign-On dla serwerów Linux.
- Instalacja i konfiguracja Domain Controller (AD DS) z replikacją wielowęzłową, projektowanie struktury OU (Organization Units) i grup bezpieczeństwa dla oddziałów.
- Przyłączenie serwerów Linux do domeny przy użyciu realmd/SSSD z konfiguracją PAM i NSS dla uwierzytelniania poświadczeń Windows.
- Wdrożenie polityk GPO (Group Policy Objects) dla wymuszenia złożoności haseł, blokady konta po nieudanych próbach logowania oraz mapowania dysków sieciowych.
- Skonfigurowanie sudo dla grup AD (np. Domain Admins), integracja SSH z kerberos tickets (GSSAPI) oraz ograniczenie logowania do wybranych grup bezpieczeństwa.
W ramach projektu student realizuje następujące zadania praktyczne:
- Instalacja i konfiguracja Domain Controller (AD DS) — zainstalować Windows Server jako Primary Domain Controller, tworząc nowy las i domenę (np. corp.local), konfigurując replikację wielowęzłową z drugim kontrolerem domeny dla zapewnienia wysokiej dostępności.
- Projektowanie struktury OU i grup bezpieczeństwa — zaprojektować hierarchię Organization Units (OU) odpowiadającą struktura organizacyjnej firmy, utworzyć grupy bezpieczeństwa dla poszczególnych działów (IT, Księgowość, Handlowcy) oraz zdefiniować zasady delegacji uprawnień.
- Implementacja polityk GPO (Group Policy Objects) — skonfigurować polityki haseł (długość, złożoność, historia), polityki blokady konta (po 5 nieudanych próbach, czas blokady 30 min), polityki ograniczające użycie nośników USB oraz polityki mapowania dysków sieciowych.
- Przyłączanie serwerów Linux do domeny AD — wykorzystać realmd i SSSD do przyłączenia serwerów Linux (CentOS/RHEL/Ubuntu) do domeny Active Directory, konfigurując PAM (Pluggable Authentication Modules) i NSS (Name Service Switch) do uwierzytelniania poświadczeń Windows.
- Konfiguracja sudo dla grup AD — skonfigurować plik sudoers lub sudoers.d tak, aby członkowie grupy Domain Admins z AD mieli uprawnienia root na serwerach Linux bez konieczności podawania hasła (sudoers: %domain\ admins ALL=(ALL) NOPASSWD: ALL).
- Integracja SSH z Kerberos (GSSAPI) — skonfigurować serwer OpenSSH do uwierzytelniania za pomocą GSSAPI i keytab, umożliwiając logowanie SSH bez hasła dla użytkowników posiadających ważne bilety Kerberos.
- Ograniczenie logowania do wybranych grup AD — skonfigurować Simple Allow Groups w SSSD, ograniczając dostęp do serwerów Linux tylko dla członków określonych grup bezpieczeństwa z AD (np. Linux-Admins, IT-Servers).
- Weryfikacja replikacji i dokumentacja procedur — przeprowadzić testy replikacji między kontrolerami domeny (dcdiag, repadmin), utworzyć dokumentację procedury dodawania nowego użytkownika (User Lifecycle) oraz procedury usuwania kont pracownika.
- Instalacja i konfiguracja Domain Controller (AD DS).
- Projektowanie struktury OU i grup bezpieczeństwa.
- Implementacja polityk GPO (Password Policy, USB lock).
- Wdrożenie mechanizmu SSO (Single Sign-On).
- Przyłączanie serwerów Linux do domeny (SSSD/Realmd).
- Konfiguracja PAM i NSS na Linuxie pod kątem AD.
- Ograniczenie logowania do wybranych grup AD (Simple Allow Groups).
- Automatyczne nadawanie uprawnień sudo dla adminów domeny.
- Testy replikacji między kontrolerami (dcdiag).
- Dokumentacja procedury dodawania nowego użytkownika (User Lifecycle).
# Krok 1: Aktualizacja systemu i instalacja wymaganych pakietów
sudo apt update # lub yum update na CentOS/RHEL
Hit:1 http://security.ubuntu.com/ubuntu focal-security InRelease
sudo apt install realmd sssd adcli krb5-user samba oddjob oddjob-mkhomedir
realmd, sssd installed successfully
# Krok 2: Konfiguracja DNS - dodanie domeny AD
sudo nano /etc/systemd/resolved.conf
[Resolve] DNS=10.0.0.8 Domains=corp.local
sudo systemctl restart systemd-resolved
Service restarted
# Krok 3: Weryfikacja wykrywalności domeny
realm discover corp.local
corp.local type: kerberos realm-name: CORP.LOCAL domain-name: corp.local configured: no server-software: active-directory client-software: sssd required-package: sssd-tools
# Krok 4: Przyłączenie serwera do domeny AD
sudo realm join --user=Administrator corp.local
Successfully enrolled machine in realm
# Krok 5: Weryfikacja przyłączenia do domeny
realm list
corp.local type: active-directory realm-name: CORP.LOCAL domain-name: corp.local configured: kerberos-member server-software: active-directory client-software: sssd login-formats: %U@corp.local default-shell: /bin/bash
# Krok 6: Weryfikacja konta użytkownika AD
id admin@corp.local
uid=10000(admin@corp.local) gid=10000(domain users) groups=10000(domain users),10001(domain admins)
# Krok 7: Konfiguracja automatycznego tworzenia katalogu domowego
sudo pam-auth-update --enable mkhomedir
PAM configuration updated
# Krok 8: Konfiguracja sudo dla grup AD
sudo bash -c 'echo "%domain\ admins ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/domain_admins'
Sudoers file created
# Krok 9: Konfiguracja SSH z GSSAPI (Kerberos SSO)
sudo nano /etc/ssh/sshd_config
GSSAPIAuthentication yes GSSAPICleanupCreds yes AuthorizedKeysCommand /usr/bin/sss_ssh_authorizedkeys AuthorizedKeysCommandUser root
sudo systemctl restart sshd
SSH service restarted
# Krok 10: Ograniczenie logowania do wybranych grup AD (Simple Allow Groups)
sudo nano /etc/sssd/sssd.conf
[domain/corp.local] ... simple_allow_groups = Linux-Admins, IT-Servers simple_allow_users =
sudo systemctl restart sssd
SSSD service restarted
# Krok 11: Test logowania SSH bez hasła (Kerberos)
ssh -v admin@corp.local@server01.corp.local
Authenticated with GSSAPI
# Krok 12: Wylogowanie z domeny (jeśli potrzebne)
sudo realm leave corp.local
Machine left realm
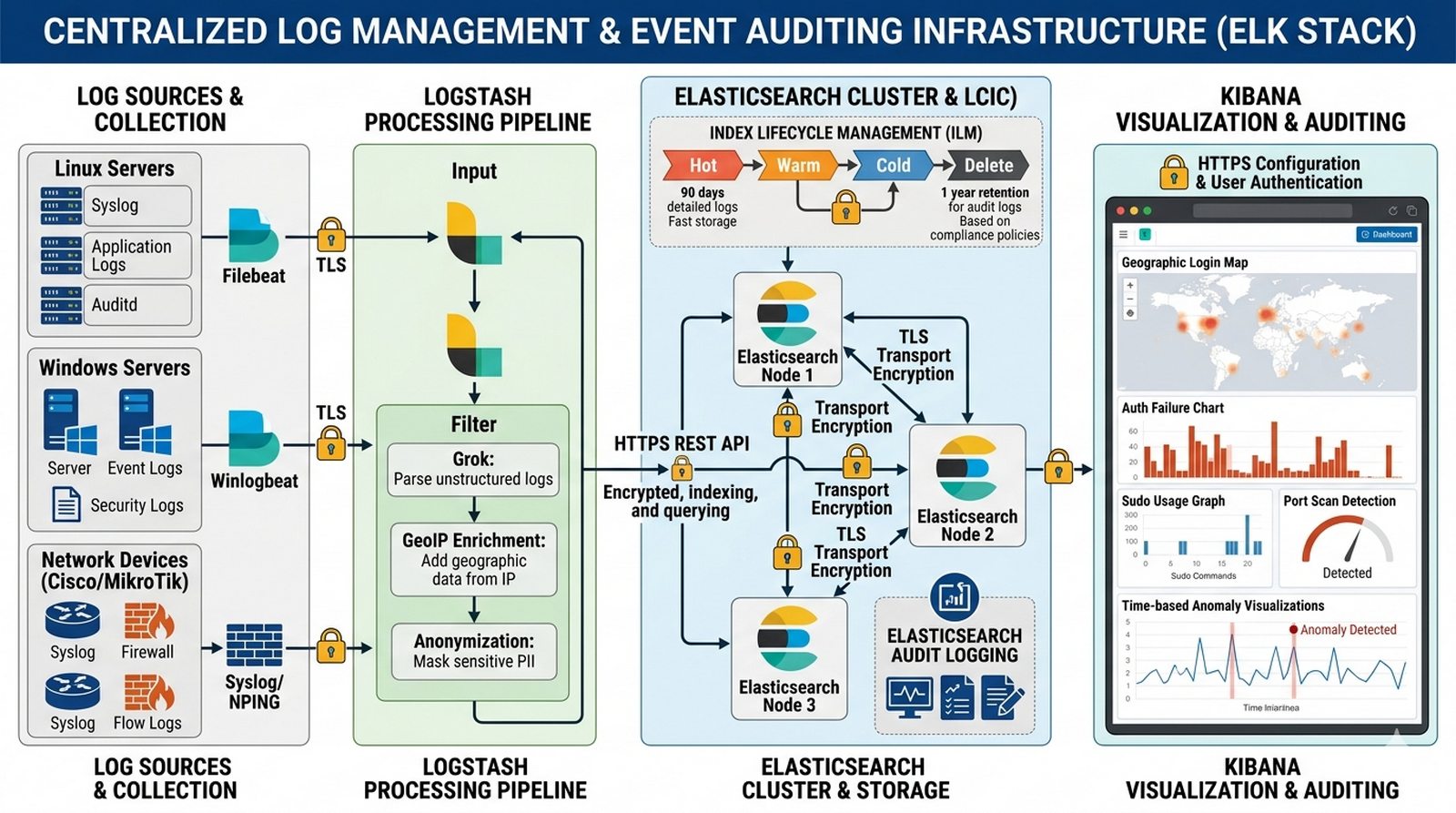
W6 Monitorowanie (Logging), slajdy 8-12.
Celem projektu jest wdrożenie scentralizowanego systemu zarządzania logami (Log Management) opartego na stosie ELK zapewniającego gromadzenie, analizę i wizualizację zdarzeń w czasie rzeczywistym na potrzeby wykrywania anomalii bezpieczeństwa i audytu zgodności.
- Instalacja i konfiguracja klastra Elasticsearch z szyfrowaniem TLS (transport i HTTP), Kibana z HTTPS oraz Logstash z pipeline'ami przetwarzającymi (Grok patterns, geoIP, anonymization).
- Wdrożenie agentów zbierających logi: Filebeat na serwerach Linux, Winlogbeat na Windows Server, Syslog/NPING dla urządzeń sieciowych Cisco/MikroTik.
- Budowa dashboardów bezpieczeństwa w Kibanie: mapa geograficzna logowań, błędy autentykacji, użycie sudo, wykrywanie skanowania portów, anomalie czasowe.
- Implementacja polityki retencji danych (ILM) z automatycznym archiwizowaniem i usuwaniem po okresie zgodności (np. 90 dni) oraz włączenie audit logging w Elasticsearch.
W ramach projektu student realizuje następujące zadania praktyczne:
- Instalacja klastra Elasticsearch z TLS — zainstalować i skonfigurować klaster Elasticsearch (co najmniej 3 węzły) z szyfrowaniem TLS zarówno dla transportu (inter-node communication), jak i HTTP (REST API), generując odpowiednie certyfikaty X.509.
- Konfiguracja Kibana z HTTPS — wdrożyć Kibana z włączonym HTTPS, konfigurując uwierzytelnianie użytkowników (built-in users lub LDAP integration), tworząc indeksy i role dla różnych poziomów dostępu.
- Implementacja Logstash z pipeline'ami przetwarzającymi — skonfigurować Logstash z kompletnym pipeline (Input → Filter → Output), definiując filtry Grok do parsowania logów, filtry geoIP do enrichment danych o lokalizacji geograficznej oraz filtry anonymization do pseudonimizacji danych wrażliwych.
- Wdrożenie agentów Filebeat na serwerach Linux — zainstalować i skonfigurować Filebeat na serwerach Linux do zbierania logów systemowych (/var/log/syslog, /var/log/auth.log), logów aplikacyjnych oraz logów nginx/apache, definiując moduły beats dla poszczególnych typów logów.
- Instalacja Winlogbeat na Windows Server — wdrożyć Winlogbeat na serwerach Windows do zbierania Windows Event Logs (Security, System, Application, PowerShell), konfigurując odpowiednie winlogbeat.event_logs i forwardowanie do Logstash.
- Konfiguracja Syslog dla urządzeń sieciowych — skonfigurować routery Cisco i MikroTik do wysyłania logów Syslog (UDP/TCP 514) do Logstash, definiując odpowiednie poziomy logowania ( Informational, Warning, Error) i kategorie zdarzeń.
- Budowa dashboardów bezpieczeństwa w Kibanie — zaprojektować i wdrożyć interaktywne dashboardy bezpieczeństwa wyświetlające mapę geograficzną logowań (według adresu IP źródłowego), wykresy błędów autentykacji, użycia poleceń sudo, wykrywanie skanowania portów oraz anomalie czasowe (logowania w nietypowych godzinach).
- Implementacja polityki retencji danych (ILM) — skonfigurować Index Lifecycle Management w Elasticsearch z automatycznym archiwizowaniem (cold tier) i usuwaniem danych po okresie zgodności (np. 90 dni dla logów szczegółowych, 1 rok dla logów audit), włączając audit logging w Elasticsearch.
- Instalacja Elasticsearch i Kibana (Docker/VM).
- Konfiguracja Logstash (Input/Filter/Output).
- Uruchomienie przesyłania Syslog z Cisco do Logstash.
- Instalacja Winlogbeat na serwerach Windows.
- Instalacja Filebeat na serwerach aplikacyjnych.
- Parsowanie logów (Grok patterns) w celu wyciągnięcia pól znaczących.
- Tworzenie Index Patterns w Kibanie.
- Budowa Dashboardu bezpieczeństwa (Failed logins, sudo usage).
- Wdrożenie polityki retencji indeksów (ILM).
- Testy: generowanie zdarzeń (np. port scan) i weryfikacja alertów.
! Krok 1: Włączenie trybu synchronizacji logowania
logging synchronous
Logging synchronous enabled
! Krok 2: Konfiguracja hosta Syslog (serwer centralny)
logging host 10.0.5.50
Logging host configured: 10.0.5.50
logging host 10.0.5.51 ; Zapasowy serwer logów
Logging host configured: 10.0.5.51
! Krok 3: Konfiguracja poziomu logowania (trap level)
logging trap notifications ; Informational, warnings, errors
Logging trap level set to notifications (5)
logging trap debugging ; Wszystkie wiadomości (do testów)
Logging trap level set to debugging (7)
! Krok 4: Konfiguracja poziomu monitora console
logging console warnings ; Ostrzeżenia i błędy na console
Console logging level set to warnings
! Krok 5: Konfiguracja bufora logowania
logging buffered 65536 ; Rozmiar bufora w bajtach
Logging buffer size: 65536 bytes
logging buffered informational ; Poziom dla bufora
Buffer logging level set to informational
! Krok 6: Włączenie znacznika czasu w logach
service timestamps debug datetime msec
Debug timestamps enabled with milliseconds
service timestamps log datetime msec
Log timestamps enabled with milliseconds
! Krok 7: Konfiguracja źródła logowania (źródło interfejsu)
logging source-interface Loopback0
Logging source interface set to Loopback0
! Krok 8: ACL dla ochrony Syslog (opcjonalne)
ip access-list extended ACL_SYSLOG
permit udp host 10.0.5.50 host 10.0.0.1 eq syslog
permit udp host 10.0.5.51 host 10.0.0.1 eq syslog
deny udp any any eq syslog log
ACL for Syslog created
! Krok 9: Włączenie logowania do pliku
logging file flash:syslog.txt
Logging to file enabled
logging file flash:syslog.txt size 1048576
Log file size set to 1MB
! Krok 10: Weryfikacja konfiguracji Syslog
show logging
Syslog logging: enabled (0 messages dropped, 2 messages buffered) Facility: local7 Logging to: 10.0.5.50 (UDP port 514) Logging to: 10.0.5.51 (UDP port 514) Console logging: level warnings, 0 messages logged Monitor logging: level debugging, 0 messages logged Buffer logging: level informational, 0 messages logged Exception dump: size 65536 Source Interface: Loopback0
! Krok 11: Weryfikacja aktywnych hostów Syslog
show logging history
Logging history: Size: 1 Level: notifications
! Krok 12: Test wysyłki logu (generowanie testowej wiadomości)
login ; Wywołuje logowanie zdarzenia
%LINEPROTO-5-UPDOWN: Line protocol on Interface...
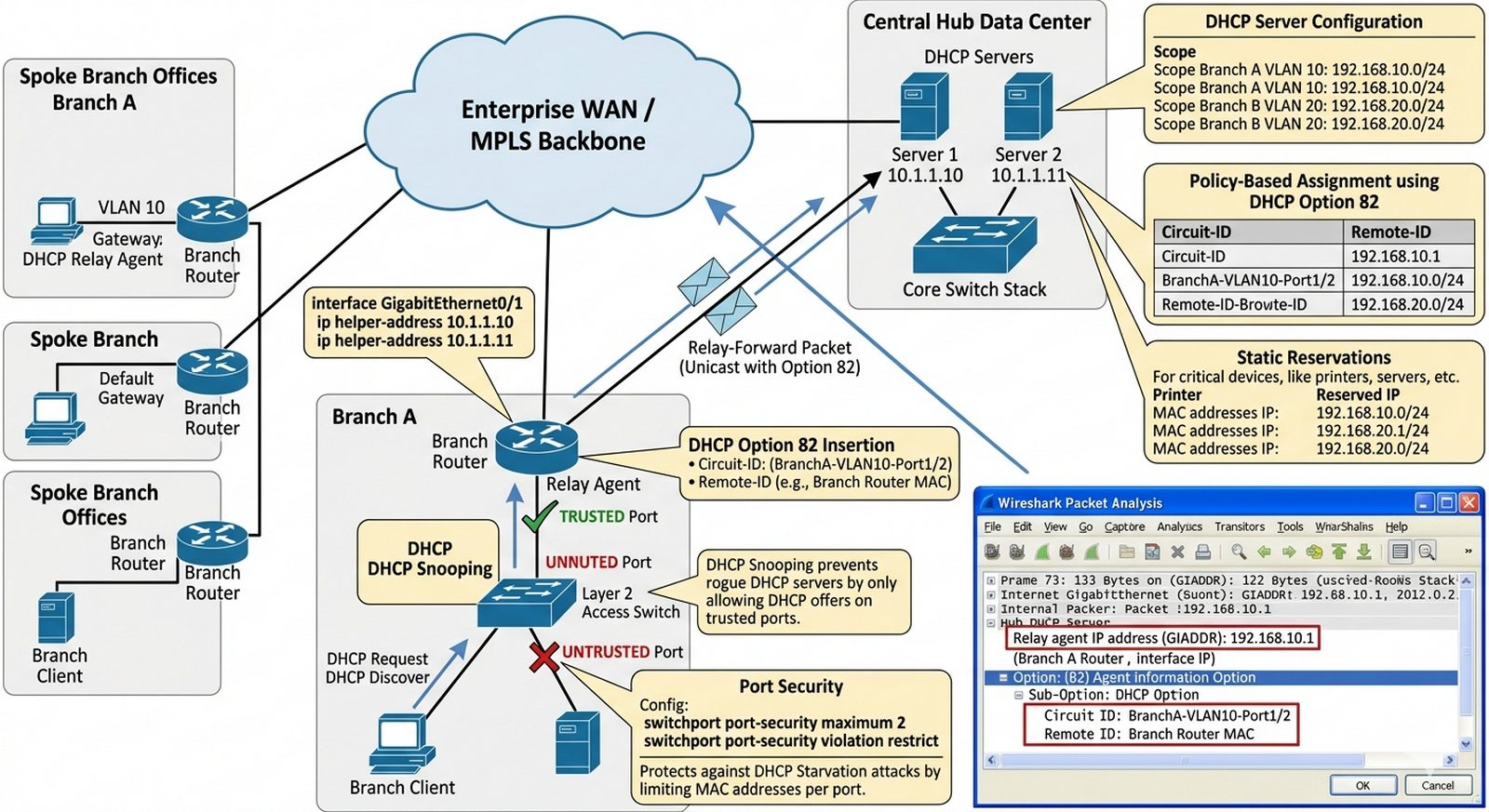
W2 DHCP, slajdy 11-13.
Celem projektu jest implementacja centralnego zarządzania adresacją DHCP w rozległych sieciach Hub-and-Spoke z wykorzystaniem DHCP Relay i opcji 82, zapewniającego prawidłową identyfikację podsieci źródłowej na serwerze centralnym.
- Konfiguracja DHCP Relay (ip helper-address) na routerach oddziałowych w topologii Hub-and-Spoke z przekazywaniem zapytań do serwera DHCP w centrali.
- Wdrożenie DHCP Option 82 (Circuit-ID, Remote-ID) na relay agents dla identyfikacji obwodu i urządzenia źródłowego; konfiguracja klas i wzorców na serwerze DHCP.
- Konfiguracja wielu zakresów (Scopes) na serwerze DHCP z przydziałem adresów na podstawie Option 82 dla różnych VLAN/oddziałów.
- Implementacja zabezpieczeń: DHCP Snooping na przełącznikach (trust/untrust ports), Port Security przeciwko atakom Starvation, rezerwacje adresów dla urządzeń krytycznych.
W ramach projektu student realizuje następujące zadania praktyczne:
- Projektowanie topologii Hub-and-Spoke — zaprojektować i wdrożyć w GNS3/EVE-NG strukturę sieci Hub-and-Spoke z centralą (Hub) i co najmniej trzema oddziałami (Spoke), definiując adresację IP dla każdego oddziału w osobnej podsieci VLAN.
- Konfiguracja DHCP Relay (ip helper-address) — skonfigurować polecenie ip helper-address na routerach w oddziałach, wskazując adresy IP serwera DHCP w centrali oraz opcjonalnie adres zapasowy, zapewniając przekazywanie broadcastów DHCP do serwera w centrali.
- Implementacja DHCP Option 82 — skonfigurować DHCP Relay Agent Information Option (Option 82) na routerach oddziałowych, definiując Circuit-ID (identyfikator VLAN/portu) i Remote-ID (adres MAC routera lub unikalny identyfikator), umożliwiając serwerowi DHCP identyfikację źródła zapytania.
- Konfiguracja wielu zakresów (Scopes) na serwerze DHCP — skonfigurować na serwerze DHCP w centrali osobne zakresy adresów dla każdego oddziału, definiując klasy DHCP (DHCP Class) na podstawie Option 82 do automatycznego przypisywania adresów z odpowiedniej puli.
- Implementacja DHCP Snooping na przełącznikach — skonfigurować DHCP Snooping na przełącznikach L2 w oddziałach, oznaczając porty uplink jako trusted (zaufane) i porty dostępu jako untrusted (nieufne), blokując nieautoryzowane odpowiedzi DHCP.
- Zabezpieczenie przed atakami DHCP Starvation — wdrożyć Port Security na przełącznikach Cisco ograniczającą liczbę dopuszczalnych adresów MAC na porcie oraz implementującą dynamiczne bindingi DHCP Snooping, chroniąc przed atakami wyczerpywania puli DHCP.
- Konfiguracja rezerwacji adresów dla urządzeń krytycznych — zdefiniować rezerwacje adresów IP dla urządzeń krytycznych (serwery, drukarki sieciowe, urządzenia VoIP) na podstawie identyfikatorów klienta (client identifier) lub adresów MAC, zapewniając im stałe adresy IP niezależnie od konfiguracji sieci.
- Testowanie redundancji ścieżek i analiza w Wireshark — przeprowadzić testy failover dla ścieżek do serwera DHCP, przechwycić i przeanalizować pakiety DHCP w Wiresharku, weryfikując poprawne wypełnianie pól GIADDR (Relay Agent IP Address) i Option 82.
- Konfiguracja interfejsów VLAN na routerach oddziałowych.
- Implementacja polecenia ip helper-address.
- Wdrożenie DHCP Option 82 (Circuit-ID).
- Konfiguracja serwera DHCP z wieloma zakresami (Scopes).
- Zabezpieczenie: Trust/Untrust ports na switchach.
- Mitygacja Starvation Attack przy użyciu Port Security.
- Analiza ruchu w Wiresharku (GIADDR field).
- Konfiguracja rezerwacji adresów dla urządzeń statycznych.
- Testowanie redundancji ścieżek do serwera DHCP.
- Monitoring logów serwera pod kątem wyczerpania puli.
# Krok 1: Tworzenie interfejsu VLAN
/interface vlan add name=vlan100 vlan-id=100 interface=ether1 disabled=no
name: vlan100
# Krok 2: Przypisanie adresu IP do interfejsu VLAN
/ip address add address=192.168.100.1/24 interface=vlan100 network=192.168.100.0
address: 192.168.100.1/24
# Krok 3: Włączenie i konfiguracja DHCP Relay
/ip dhcp-relay add name=relay_vlan100 interface=vlan100 dhcp-server=10.0.0.1 disabled=no
Numbers: 0
# Krok 4: Dodanie drugiego serwera DHCP (backup)
/ip dhcp-relay set numbers=0 dhcp-server="10.0.0.1,10.0.0.2"
dhcp-server: 10.0.0.1,10.0.0.2
# Krok 5: Tworzenie drugiego VLAN (VLAN 200)
/interface vlan add name=vlan200 vlan-id=200 interface=ether1 disabled=no
name: vlan200
/ip address add address=192.168.200.1/24 interface=vlan200 network=192.168.200.0
address: 192.168.200.1/24
# Krok 6: Dodanie DHCP Relay dla VLAN 200
/ip dhcp-relay add name=relay_vlan200 interface=vlan200 dhcp-server=10.0.0.1 disabled=no
Numbers: 1
# Krok 7: Włączenie DHCP Relay Option 82
/ip dhcp-relay set numbers=0 relay-info-option=yes
relay-info-option: yes
/ip dhcp-relay set numbers=1 relay-info-option=yes
relay-info-option: yes
# Krok 8: Konfiguracja interfejsu lokalnego (same)
/ip dhcp-relay set numbers=0 local-address=192.168.100.1
local-address: 192.168.100.1
# Krok 9: Weryfikacja konfiguracji DHCP Relay
/ip dhcp-relay print
Flags: X - disabled, I - invalid # NAME INTERFACE DHCP-SERVER LOCAL-ADDRESS 0 relay_vlan100 vlan100 10.0.0.1 192.168.100.1 1 relay_vlan200 vlan200 10.0.0.1 192.168.200.1
# Krok 10: Weryfikacja statystyk DHCP Relay
/ip dhcp-relay monitor numbers=0
interface: vlan100 dhcp-server: 10.0.0.1 local-address: 192.168.100.1 relay-info: enabled packets-received: 234 packets-forwarded: 234 packets-discovered: 234 packets-valid: 234 packets-invalid: 0 packets-bad-relay: 0 packets-local-mac: 234
# Krok 11: Konfiguracja DHCP Client na routerze (opcjonalnie)
/ip dhcp-client add interface=ether1 disabled=no use-peer-dns=yes use-peer-ntp=yes
Numbers: 0
# Krok 12: Zapis konfiguracji
/system backup save name=dhcp_relay_config
saved: dhcp_relay_config.backup
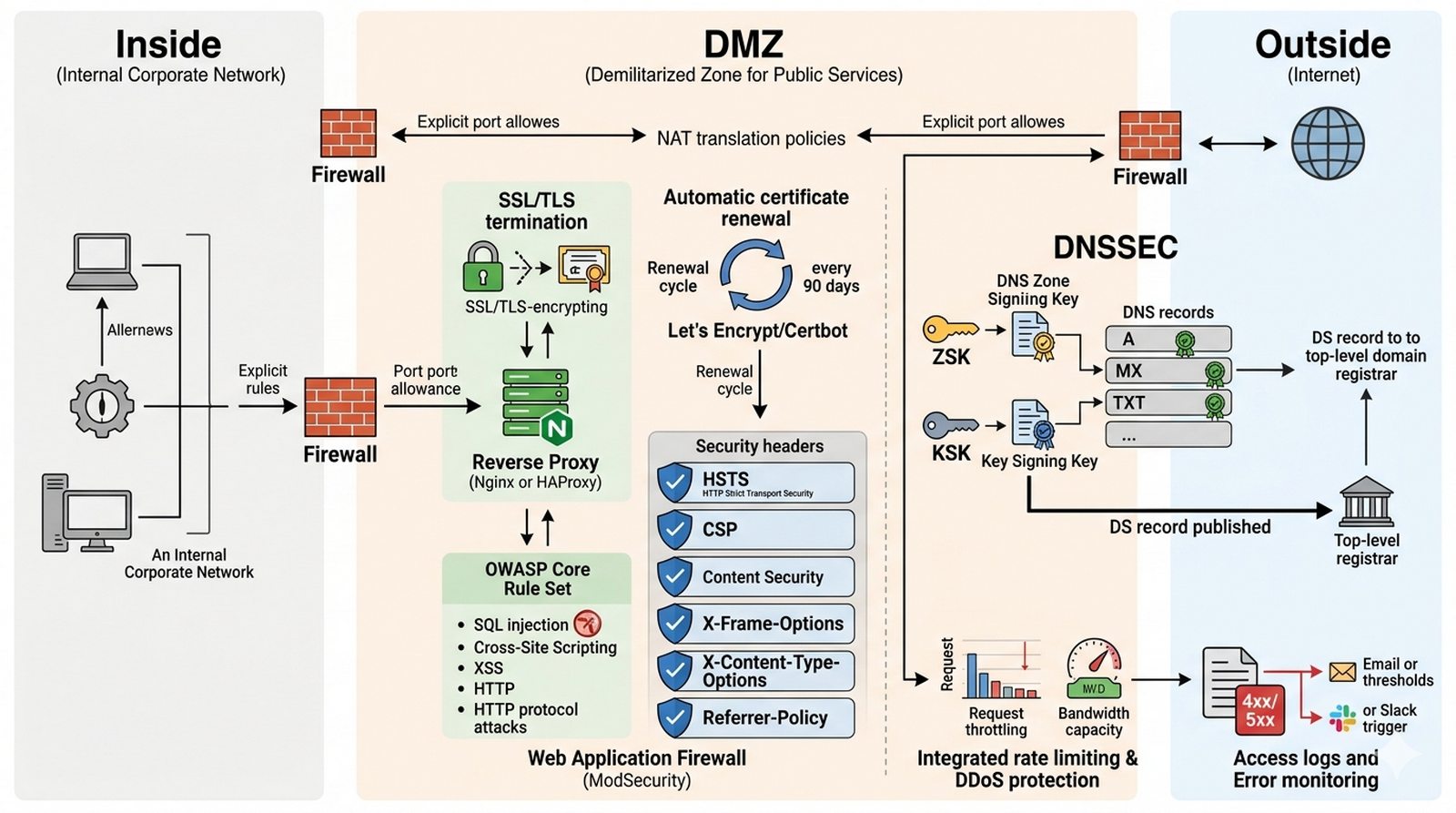
W1 Architektura sieci (DMZ), W7 Bezpieczeństwo usług.
Celem projektu jest zaprojektowanie i wdrożenie strefy DMZ z Reverse Proxy zapewniającego bezpieczne publikowanie usług publicznych (WWW, Mail) oraz implementacja DNSSEC dla ochrony przed manipulacją i fałszowaniem odpowiedzi DNS.
- Konfiguracja firewalla z trzema strefami bezpieczeństwa (Inside, DMZ, Outside) oraz wdrożenie Reverse Proxy (Nginx/HAProxy) z terminacją SSL/TLS i forwardowaniem do serwerów wewnętrznych.
- Implementacja DNSSEC: generowanie par kluczy ZSK/KSK, podpisywanie stref, konfiguracja DNS-over-TLS (DoT) lub DNS-over-HTTPS (DoH), publikacja rekordów DS u rejestratora domeny.
- Skonfigurowanie nagłówków bezpieczeństwa (HSTS, CSP, X-Frame-Options), cipher suites TLS 1.3, automatyczna renovacja certyfikatów (Let's Encrypt/Certbot) oraz rate limiting.
- Wdrożenie WAF (ModSecurity) dla wykrywania ataków SQL injection, XSS, protokołów HTTP, monitoring logów dostępowych i błędów 4xx/5xx z alerowaniem.
W ramach projektu student realizuje następujące zadania praktyczne:
- Projektowanie architektury firewalla z trzema strefami — zaprojektować i wdrożyć infrastrukturę firewall z trzema strefami bezpieczeństwa: Inside (sieć wewnętrzna), DMZ (strefa zdemilitaryzowana dla usług publicznych) i Outside (Internet), definiując reguły translacji NAT i polityki bezpieczeństwa dla każdej strefy.
- Instalacja i konfiguracja Reverse Proxy (Nginx/HAProxy) — zainstalować i skonfigurować Nginx lub HAProxy w strefie DMZ, konfigurując virtual hosts dla usług WWW i Mail, implementując terminację SSL/TLS z oficjalnymi certyfikatami lub self-signed dla testów.
- Konfiguracja automatycznej renovacji certyfikatów (Let's Encrypt/Certbot) — wdrożyć automatyczne odnawianie certyfikatów SSL/TLS z wykorzystaniem Certbot i Let's Encrypt, konfigurując webhooki do reloadu Nginx po odnowieniu certyfikatu oraz mechanizm testowania odnowienia.
- Implementacja nagłówków bezpieczeństwa HTTP — skonfigurować nagłówki bezpieczeństwa na Reverse Proxy: HSTS (HTTP Strict Transport Security), CSP (Content Security Policy), X-Frame-Options (zapobieganie clickjacking), X-Content-Type-Options, Referrer-Policy, definiując odpowiednie dyrektywy dla aplikacji firmowych.
- Konfiguracja DNSSEC — generowanie kluczy ZSK/KSK — wygenerować pary kluczy ZSK (Zone Signing Key) i KSK (Key Signing Key) dla strefy DNS firmowej, konfigurując algorytm RSASHA256 lub ECDSA P-256, definiując okresy życia kluczy i strategie rotacji.
- Podpisywanie stref DNS i publikacja rekordów DS — skonfigurować automatyczne podpisywanie stref DNS (signed zone) z wykorzystaniem BIND lub NSD, wygenerować rekordy DS (Delegation Signer) i opublikować je u rejestratora domeny, weryfikując poprawność łańcucha zaufania DNSSEC.
- Wdrożenie WAF (ModSecurity) dla wykrywania ataków — zainstalować i skonfigurować ModSecurity jako WAF (Web Application Firewall) z zestawem reguł OWASP Core Rule Set, konfigurując wykrywanie ataków SQL injection, XSS (Cross-Site Scripting), ataków na parametry HTTP i żądań typu brute-force.
- Implementacja Rate Limiting i ochrony przed DDoS — skonfigurować mechanizmy ograniczania przepustowości (rate limiting) na Reverse Proxy, definiując limity żądań na adres IP, limity połączeń oraz reguły throttlingu dla zagrożonych ścieżek URL, dokumentując logi błędów 4xx/5xx i alerty przekroczenia limitów.
- Konfiguracja Firewalla z trzema strefami (Inside/Outside/DMZ).
- Instalacja Reverse Proxy (Nginx/HAProxy).
- Automatyzacja certyfikatów SSL (Let's Encrypt/Certbot).
- Konfiguracja hardeningu serwera (header protection, TLS 1.3).
- Implementacja DNSSEC (generowanie kluczy ZSK/KSK).
- Publikacja rekordów DS u rejestratora.
- Ochrona przed DDoS: Rate Limiting na proxy.
- Wykrywanie intruzów: integracja ModSecurity (WAF).
- Testy: skanowanie SSL Labs (Grade A+).
- Monitoring logów dostępowych i błędów 4xx/5xx.
# Krok 1: Instalacja Nginx (Ubuntu/Debian)
sudo apt update
Hit:1 http://security.ubuntu.com/ubuntu focal-security InRelease
sudo apt install nginx
nginx installed
# Krok 2: Tworzenie pliku konfiguracyjnego vhost
sudo nano /etc/nginx/sites-available/reverse-proxy
File created
# Krok 3: Konfiguracja Reverse Proxy z nagłówkami bezpieczeństwa
server {
listen 443 ssl http2;
server_name app.corp.local;
# Certyfikat SSL
ssl_certificate /etc/ssl/certs/corp.crt;
ssl_certificate_key /etc/ssl/private/corp.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers HIGH:!aNULL:!MD5;
# Nagłówki bezpieczeństwa
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always;
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-XSS-Protection "1; mode=block" always;
# Konfiguracja proxy
location / {
proxy_pass http://192.168.10.50:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_connect_timeout 60s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering off;
proxy_request_buffering off;
}
# Rate limiting
limit_req_zone $binary_remote_addr zone=api_limit:10m rate=10r/s;
location /api/ {
limit_req zone=api_limit burst=20 nodelay;
proxy_pass http://192.168.10.50:8080/api/;
}
}
# Krok 4: Włączenie konfiguracji
sudo ln -s /etc/nginx/sites-available/reverse-proxy /etc/nginx/sites-enabled/
Symlink created
# Krok 5: Weryfikacja konfiguracji Nginx
sudo nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok nginx: configuration file /etc/nginx/nginx.conf test is successful
# Krok 6: Przeładowanie Nginx
sudo systemctl reload nginx
Service reloaded
# Krok 7: Dodanie przekierowania HTTP do HTTPS
server {
listen 80;
server_name app.corp.local;
return 301 https://$server_name$request_uri;
}
# Krok 8: Konfiguracja upstream dla load balancing
upstream backend_servers {
server 192.168.10.50:8080 weight=5;
server 192.168.10.51:8080 weight=3;
server 192.168.10.52:8080 backup;
}
# Krok 9: Konfiguracja cache dla statycznych zasobów
proxy_cache_path /var/cache/nginx levels=1:2 keys_zone=app_cache:10m max_size=100m inactive=60m use_temp_path=off;
location /static/ {
proxy_cache app_cache;
proxy_cache_valid 200 60m;
add_header X-Cache-Status $upstream_cache_status;
proxy_pass http://backend_servers;
}
# Krok 10: Monitoring - status strony
location /nginx_status {
stub_status on;
allow 127.0.0.1;
allow 10.0.0.0/24;
deny all;
}
# Krok 11: Test HTTPS
curl -I https://app.corp.local/
HTTP/2 200 Server: nginx Strict-Transport-Security: max-age=31536000 X-Frame-Options: SAMEORIGIN
# Krok 12: Logi dostępu i błędów
tail -f /var/log/nginx/access.log
192.168.1.100 - - [26/Apr/2026:14:32:15 +0200] "GET / HTTP/1.1" 200 1234 "-" "Mozilla/5.0..."
W2 Utrzymanie (Backup), slajdy 31, 45.
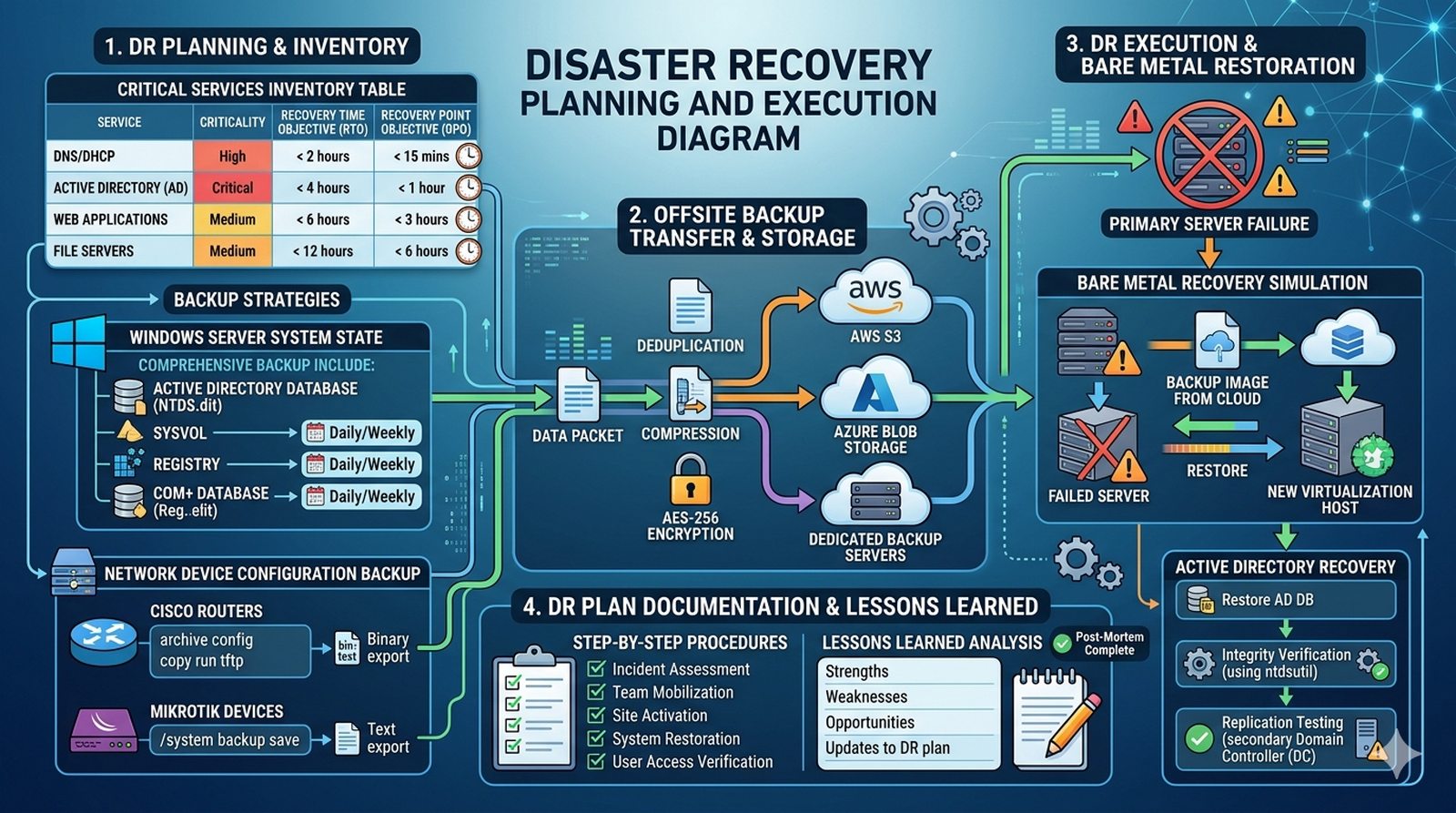
Celem projektu jest opracowanie i przetestowanie strategii Disaster Recovery z określeniem parametrów RTO (Recovery Time Objective) i RPO (Recovery Point Objective), wdrożenie systemu kopii zapasowych oraz weryfikacja zdolności do odtworzenia usług po awarii sprzętowej typu "Bare Metal".
- Przeprowadzenie inwentaryzacji krytycznych danych i usług, określenie RPO/RTO dla każdej usługi (np. DNS/DHCP: RTO < 2h, RPO < 15min) oraz dokumentacja w tabeli priorytetów.
- Konfiguracja backupu "System State" (Windows), eksport konfiguracji binarnej i tekstowej routerów/przełączników (Cisco config, MikroTik export) i transfer do lokalizacji offsite.
- Symulacja awarii "Bare Metal": wyłączenie serwera, odtworzenie maszyny wirtualnej z obrazu backupu na nowym hoście, weryfikacja integralności Active Directory i DNS.
- Opracowanie planu DR (Disaster Recovery Plan) z procedurami krok po kroku, checklistami dla operatorów oraz analiza "Lessons Learned" po testowym odtworzeniu.
W ramach projektu student realizuje następujące zadania praktyczne:
- Inwentaryzacja krytycznych danych i usług — przeprowadzić inwentaryzację wszystkich krytycznych usług infrastrukturalnych (DNS, DHCP, AD, WWW, Mail), określając dla każdej usługi wartości RTO (Recovery Time Objective) i RPO (Recovery Point Objective), dokumentując wyniki w tabeli priorytetów (np. DNS/DHCP: RTO < 2h, RPO < 15min).
- Konfiguracja backupu System State (Windows) — skonfigurować automatyczne kopie zapasowe stanu systemu Windows Server (System State backup) obejmujące Active Directory Database (NTDS.dit), SYSVOL, rejestr i COM+ Database, definiując harmonogram dzienny/tygodniowy i retention policy.
- Eksport konfiguracji urządzeń sieciowych — skonfigurować automatyczny eksport konfiguracji binarnej i tekstowej routerów Cisco (copy run tftp, archive config) i MikroTik (/system backup save), konfigurując transfer do lokalizacji offsite (SFTP/FTPS) z zachowaniem wersji historycznych.
- Wdrożenie systemu backup (Veeam/Bacula) — zainstalować i skonfigurować oprogramowanie do tworzenia kopii zapasowych (Veeam Backup & Replication, Bacula Enterprise lub open-source), definiując zadania backupu dla maszyn wirtualnych, serwerów fizycznych i baz danych.
- Automatyzacja przesyłania kopii do lokalizacji offsite — skonfigurować automatyczne przesyłanie kopii zapasowych do lokalizacji zdalnej (chmurze AWS S3, Azure Blob lub dedykowanego serwera backup), definiując strategie deduplication, kompresji i szyfrowania w tranzicie (AES-256).
- Testy spójności archiwów i weryfikacja backupów — skonfigurować cykliczne testy spójności (integrity checks) archiwów backupowych, przeprowadzając procedury restore verification bez odtwarzania na produkcyjne środowisko, dokumentując wyniki w raportach.
- Symulacja awarii Bare Metal serwera DNS/DHCP — przeprowadzić kontrolowane wyłączenie głównego serwera usług (simulacja awarii sprzętowej), dokumentując czas od awarii do wykrycia (MTTD — Mean Time To Detect), uruchamiając procedurę odtwarzania i mierząc całkowity czas przywrócenia usług.
- Odtwarzanie Active Directory po awarii — przeprowadzić procedurę odtwarzania Active Directory z backupu System State na nowym hoście wirtualizacji, weryfikując integralność bazy NTDS (ntdsutil), replikację z drugim DC oraz poprawność usług DNS i DHCP po odtworzeniu.
- Opracowanie planu DR i analiza Lessons Learned — opracować kompleksowy plan Disaster Recovery (DR Plan) zawierający procedury krok po kroku dla każdej krytycznej usługi, checklisty dla operatorów, dane kontaktowe zespołu ratunkowego oraz sekcję "Lessons Learned" dokumentującą wnioski z przeprowadzonych testów.
- Inwentaryzacja krytycznych danych (RPO/RTO).
- Konfiguracja backupu "System State" (Windows).
- Eksport konfiguracji binarnej i tekstowej routerów.
- Automatyzacja przesyłania kopii do zdalnej lokalizacji (Offsite).
- Testy spójności archiwów.
- Symulacja awarii "Bare Metal" serwera DNS/DHCP.
- Odtwarzanie maszyn na nowym hoście wirtualizacji.
- Weryfikacja integralności AD po odtworzeniu.
- Przygotowanie planu DR (Disaster Recovery Plan).
- Analiza "Lessons Learned" po przetestowaniu procedury.
# Krok 1: Ręczny backup konfiguracji (plik .backup - binarny)
/system backup save name=router_config_$(dateTime) dont-encrypt=no
saved: router_config_Apr26-2026_14-32-15.backup
# Krok 2: Backup bez szyfrowania (dla łatwiejszego odczytu)
/system backup save name=router_config_$(dateTime) dont-encrypt=yes
saved: router_config_Apr26-2026_14-32-15.backup
# Krok 3: Export konfiguracji do pliku tekstowego (.rsc)
/export file=router_export_$(dateTime)
saved: router_export_Apr26-2026_14-32-15.rsc
# Krok 4: Eksport tylko aktywnych komend (bez wartości domyślnych)
/export file=router_compact_$(dateTime) compact
saved: router_compact_Apr26-2026_14-32-15.rsc
# Krok 5: Wysłanie backupu na serwer FTP
/tool fetch address=10.0.0.1 src-path=router_config.backup dst-path=backups/router_config.backup mode=ftp user=ftp-user password=zaq12wsx
status: finished downloaded: 1 file, 124KB in 0.4s
# Krok 6: Wysłanie exportu na serwer SFTP (bezpieczniejsze)
/tool fetch address=10.0.0.1 src-path=router_export.rsc dst-path=backups/router_export.rsc mode=sftp user=backup-user password=secret ssh-host-key="ssh-rsa AAAA..."
status: finished downloaded: 1 file, 45KB in 0.2s
# Krok 7: Tworzenie harmonogramu automatycznego backupu (codziennie o 2:00)
/system scheduler add name=daily_backup start-date=2026/01/01 start-time=02:00:00 interval=1d on-event="/system backup save name=auto_backup\r\n/tool fetch address=10.0.0.1 src-path=auto_backup.backup dst-path=backups/auto_backup.backup mode=ftp user=ftp-user password=zaq12wsx" policy=read,write,test
started: yes
# Krok 8: Lista plików backup w pamięci routera
/file print
# NAME TYPE SIZE CREATION-TIME 0 auto_backup.backup backup 124KB apr/26/2026 14:30:00 1 router_export.rsc script 45KB apr/26/2026 14:28:00 2 router_config.backup backup 124KB apr/26/2026 14:25:00
# Krok 9: Restore z pliku .backup (binarny)
/system backup load name=auto_backup.backup
system will reboot after loading backup
yes ; Potwierdzenie restartu
system will reboot
# Krok 10: Restore z pliku .rsc (skrypt import)
/import file-name=router_export.rsc
Script file loaded and executed successfully
# Krok 11: Wysłanie backupu na serwer HTTP/HTTPS
/tool fetch address=10.0.0.1 src-path=router_config.backup dst-path=/api/backup/upload mode=http method=post http-data="file=@router_config.backup" http-header-field="Authorization: Bearer token123"
status: finished
# Krok 12: Monitorowanie miejsca na dysku i usuwanie starych backupów
/system resource print
uptime: 3w5d2h version: 7.13.5 free-memory: 256MB free-hdd-space: 45.3MiB total-hdd-space: 64MiB
/file remove numbers=0 ; Usunięcie najstarszego pliku
deleted
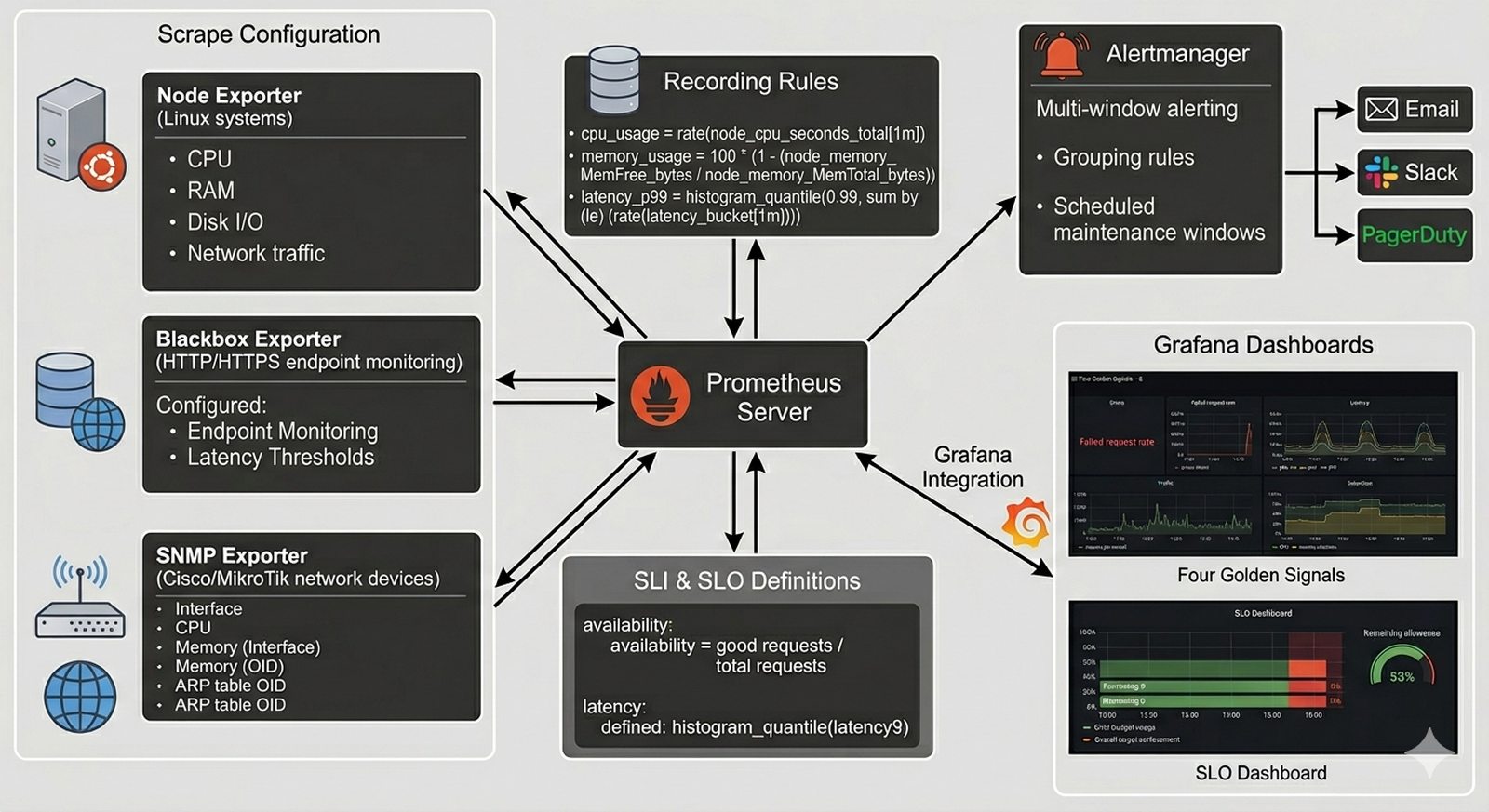
W6 Nowoczesne monitorowanie, slajdy 13-14, 20-22.
Celem projektu jest wdrożenie systemu monitorowania opartego na modelu pull (Prometheus) z wykorzystaniem exporterów do śledzenia parametrów zdrowia aplikacji i infrastruktury w czasie rzeczywistym z definiowaniem SLI/SLO.
- Instalacja i konfiguracja serwera Prometheus z definiowaniem scrape targets, interwałów i retention period; wdrożenie Node Exporter, Blackbox Exporter i SNMP Exporter na urządzeniach docelowych.
- Definiowanie Recording Rules dla często używanych zapytań PromQL (np. cpu_usage, memory_usage, request_latency_p99) oraz budowa zapytań SLI (good total / total requests).
- Wdrożenie Alertmanager z konfiguracją wielookienkowego alertowania (wielookienkowe i wielowskaźnikowe powiadomienia), grupowaniem i wyciszaniem fałszywych alarmów.
- Integracja z Grafaną: budowa dashboardów opartych na "Złotych Sygnałach" (błędy, opóźnienia, ruch, nasycenie), eksport metryk do SLO dashboard z statusem error budget.
W ramach projektu student realizuje następujące zadania praktyczne:
- Instalacja i konfiguracja serwera Prometheus — zainstalować Prometheus z wykorzystaniem kontenerów Docker lub bezpośredniej instalacji binariów, skonfigurować plik prometheus.yml definiując scrape targets dla wszystkich eksporterów, interwały pobierania danych (np. 15s dla metryk systemowych, 60s dla metryk aplikacyjnych) oraz retention period (np. 15 dni dla danych krótkoterminowych).
- Wdrożenie Node Exporter na systemach Linux — zainstalować i skonfigurować Node Exporter na serwerach Linux do zbierania metryk systemowych: CPU, RAM, disk I/O, network traffic, load average, statystyki procesów, definiując odpowiednie collectors i enable/disable dla niepotrzebnych metryk.
- Implementacja Blackbox Exporter dla monitorowania HTTP — wdrożyć Blackbox Exporter do monitorowania dostępności i czasu odpowiedzi usług HTTP/HTTPS, konfigurując moduły probe (HTTP, HTTPS, TCP, DNS), definiując progi czasowe (np. latency < 200ms jako OK, > 1s jako CRITICAL) i walidację treści odpowiedzi.
- Konfiguracja SNMP Exporter dla urządzeń sieciowych — zainstalować i skonfigurować SNMP Exporter do zbierania metryk z routerów Cisco i przełączników, definiując generator snmp.yml z odpowiednimi OID dla interfejsów sieciowych, CPU, pamięci i tabeli ARP, konfigurując walk i get requests.
- Definiowanie Recording Rules w Prometheus — utworzyć Recording Rules dla często używanych zapytań PromQL (np. cpu_usage = 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100), memory_usage = (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100), optymalizując wydajność zapytań.
- Budowa zapytań SLI i definiowanie SLO — zaprojektować i zaimplementować Service Level Indicators (SLI) dla kluczowych usług, definiując wzorce obliczania (np. good_requests / total_requests dla availability, histogram_quantile(0.99, rate(http_request_duration_seconds_bucket[5m])) dla latency), ustanawiając Service Level Objectives (SLO) z określonymi celami (np. 99.9% dostępności).
- Wdrożenie Alertmanager z wielookienkowym alertowaniem — zainstalować i skonfigurować Alertmanager z definiowaniem grupowania alertów (group_by: [alertname, instance]), konfiguracją czasu oczekiwania (group_wait, group_interval), mechanizmami wyciszania (silence) dla zaplanowanych maintenance windows oraz integracją z systemami powiadomień (e-mail, Slack, PagerDuty).
- Integracja z Grafaną i budowa dashboardów SLO — skonfigurować datasource Grafany wskazujący na Prometheus, zaprojektować interaktywne dashboardy oparte na "Złotych Sygnałach" (Golden Signals): Errors (rate of failed requests), Latency (p50, p90, p99), Traffic (requests per second), Saturation (CPU, memory utilization), tworząc dedykowane SLO dashboard z wizualizacją error budget i statusu celu.
- Analiza wydajności zapytań PromQL i optymalizacja — przeprowadzić analizę wydajności zapytań PromQL z wykorzystaniem narzędzi explain() i profile(), identyfikując bottlenecki w złożonych zapytaniach, optymalizując poprzez użycie Recording Rules, zmniejszając cardinality metryk i dostosowując interwały scrape.
- Instalacja serwera Prometheus.
- Konfiguracja Node Exporter na systemach docelowych.
- Wdrożenie Blackbox Exportera do monitorowania dostępności HTTP.
- Konfiguracja SNMP Exporter dla routerów nieobsługujących agentów.
- Definiowanie reguł agregacji danych.
- Wdrożenie Alertmanager i wyciszanie fałszywych alarmów (Silencing).
- Budowa Dashboardów koncentrujących się na "Złotych Sygnałach" (Errors, Latency, Traffic, Saturation).
- Integracja z Grafaną.
- Analiza wydajności zapytań PromQL.
- Raport końcowy z analizą trendów wydajnościowych.
# Krok 1: Podstawowa konfiguracja globalna
global:
scrape_interval: 15s ; Interwał scrape (domyślny)
evaluation_interval: 15s ; Interwał ewaluacji reguł
external_labels:
cluster: 'prod-usi'
env: 'production'
Global config loaded
# Krok 2: Konfiguracja alertów
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093'
Alert manager configured
# Krok 3: Ścieżka do plików reguł
rule_files:
- '/etc/prometheus/rules/*.yml'
- '/etc/prometheus/rules/alerts/*.yml'
Rule files loaded
# Krok 4: Scrape config dla Node Exporter (Linux)
scrape_configs:
- job_name: 'node_exporter'
static_configs:
- targets: ['10.0.1.10:9100', '10.0.1.11:9100', '10.0.1.12:9100']
labels:
service: 'linux'
Node exporter targets: 3
# Krok 5: Scrape config dla Blackbox Exporter (HTTP monitoring)
- job_name: 'blackbox_http'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets: ['https://app.corp.local', 'https://mail.corp.local']
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 'localhost:9115'
Blackbox exporter configured
# Krok 6: Scrape config dla SNMP Exporter
- job_name: 'snmp_exporter'
static_configs:
- targets:
- 192.168.1.1 ; Router Cisco
- 192.168.1.2 ; Switch Cisco
- 192.168.53.108 ; MikroTik
params:
snmp:
- ifindex64 ; Moduł z generatora snmp.yml
scrape_interval: 60s
SNMP targets: 3
# Krok 7: Scrape config z autentykacją (basic auth)
- job_name: 'custom_app'
static_configs:
- targets: ['10.0.2.50:8080']
basic_auth:
username: 'prometheus'
password: 'secure_password'
Custom app configured with basic auth
# Krok 8: DNS discovery (automatyczne wykrywanie celów)
- job_name: 'consul_service'
consul_sd_configs:
- server: 'consul.service.consul:8500'
datacenter: 'dc1'
Consul service discovery configured
# Krok 9: Konfiguracja file_sd (plik JSON/YAML)
- job_name: 'file_sd_targets'
file_sd_configs:
- files:
- '/etc/prometheus/targets/*.json'; Format: [{"targets": ["host:port"]}]
refresh_interval: 30s
File service discovery configured
# Krok 10: Weryfikacja konfiguracji (test)
promtool check config /etc/prometheus/prometheus.yml
SUCCESS: The configuration file is valid.
# Krok 11: Przeładowanie Prometheus bez restartu
curl -X POST http://localhost:9090/-/reload
HTTP 200 OK
# Krok 12: Sprawdzenie endpointów scrape
curl http://localhost:9090/api/v1/targets | jq
{ "data": { "activeTargets": [ {"job": "node_exporter", "health": "up", "labels": {"instance": "10.0.1.10:9100"}}, {"job": "blackbox_http", "health": "up", "labels": {"instance": "https://app.corp.local"}} ] } }