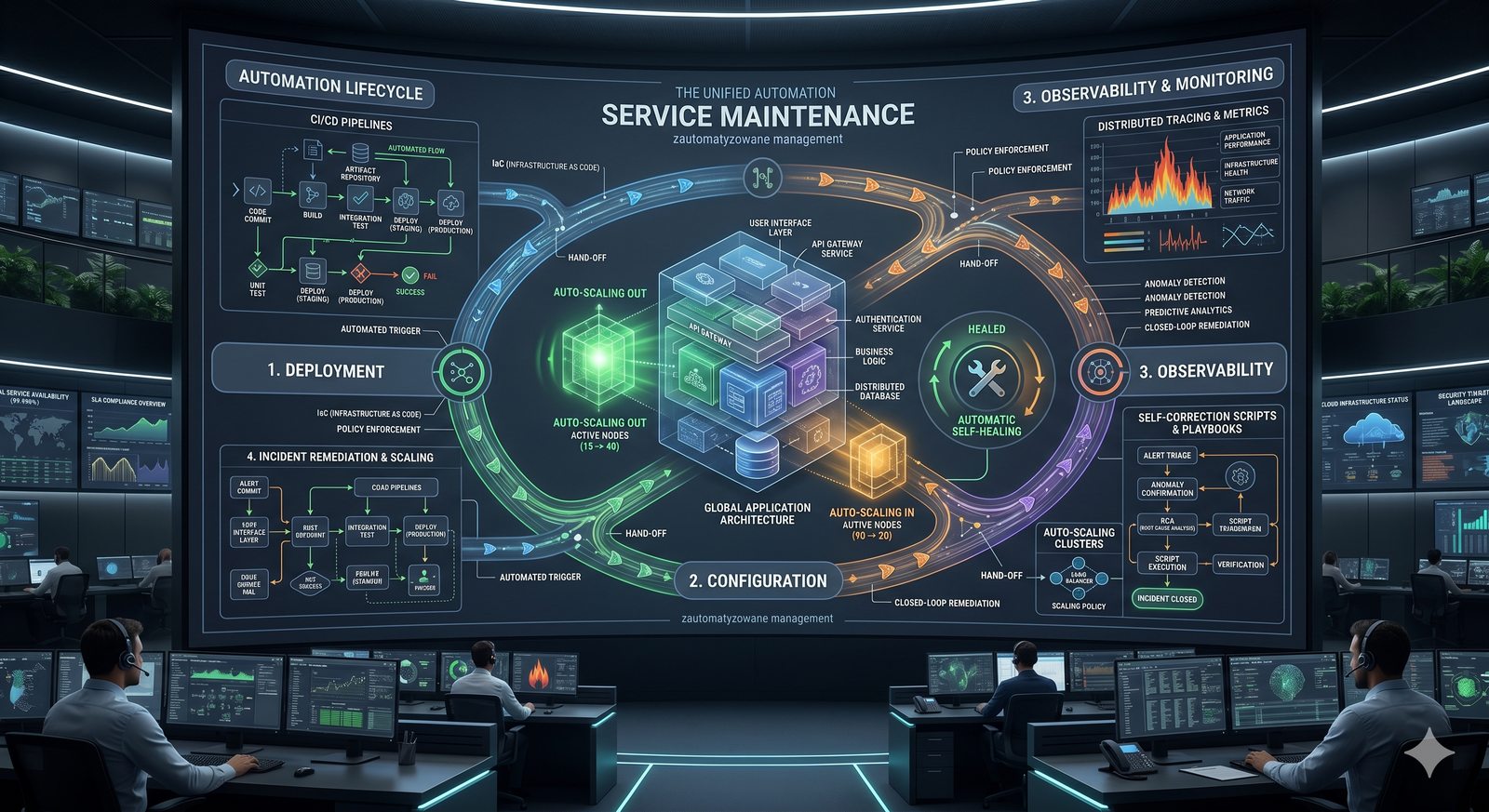
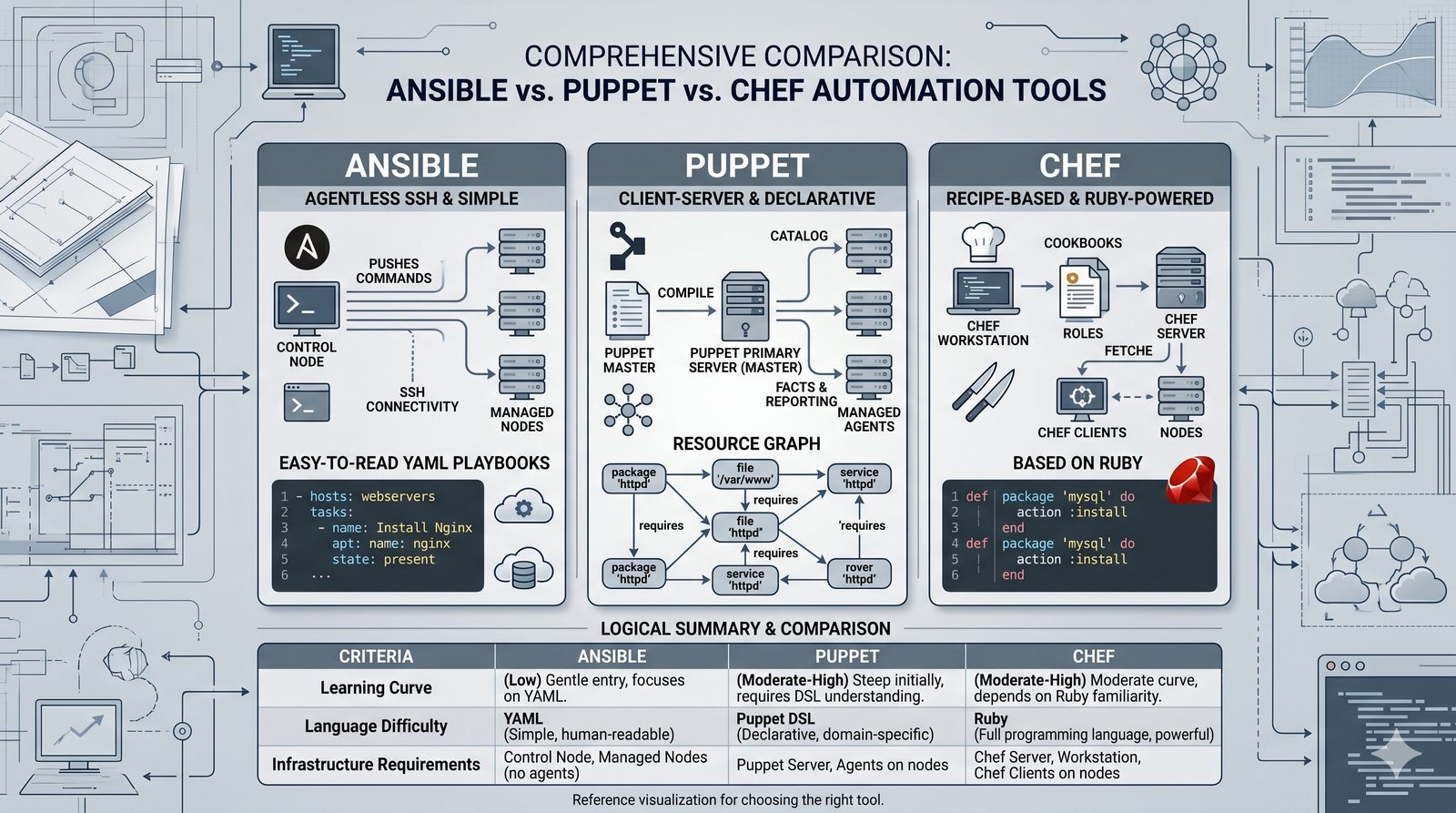
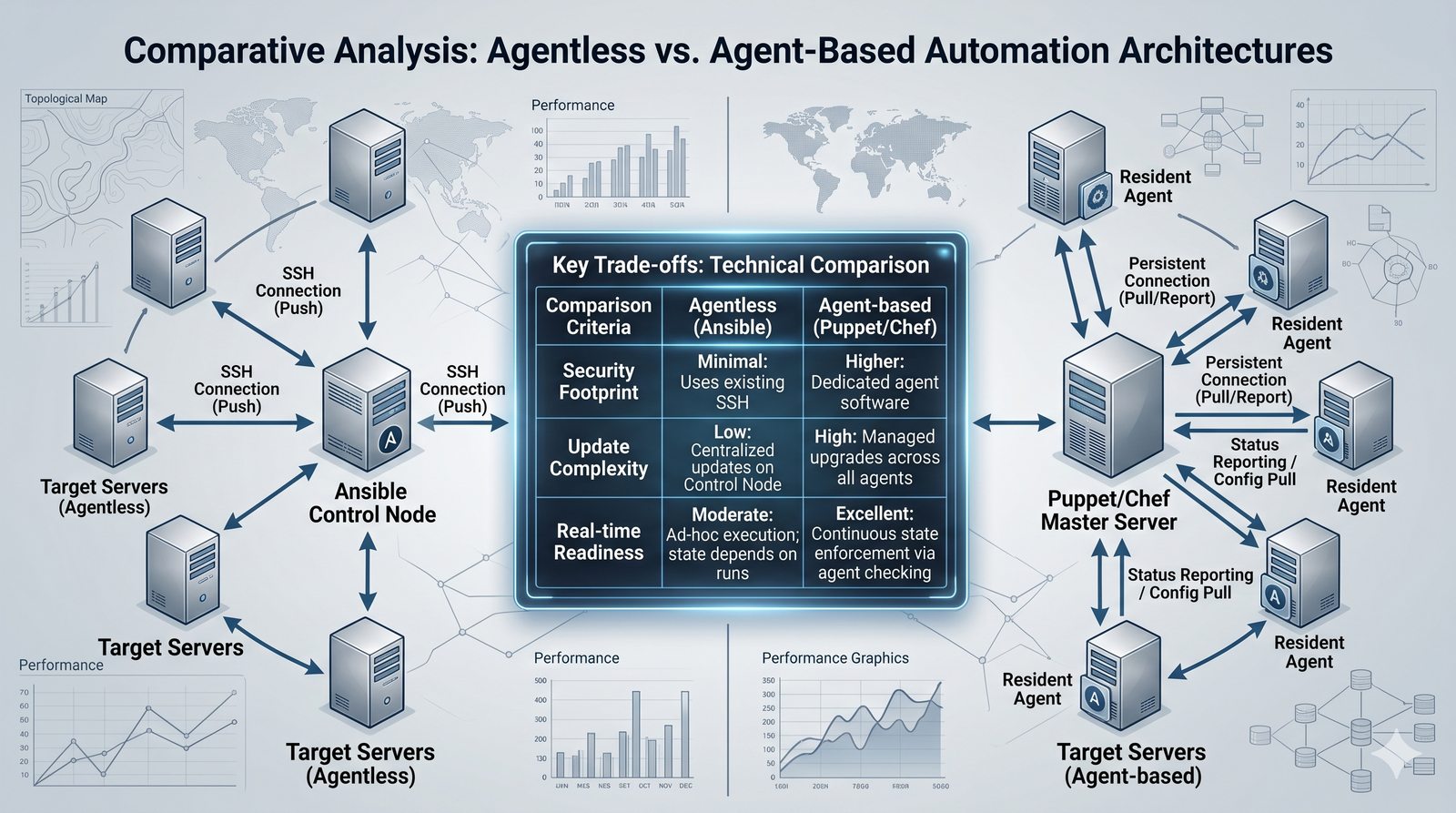
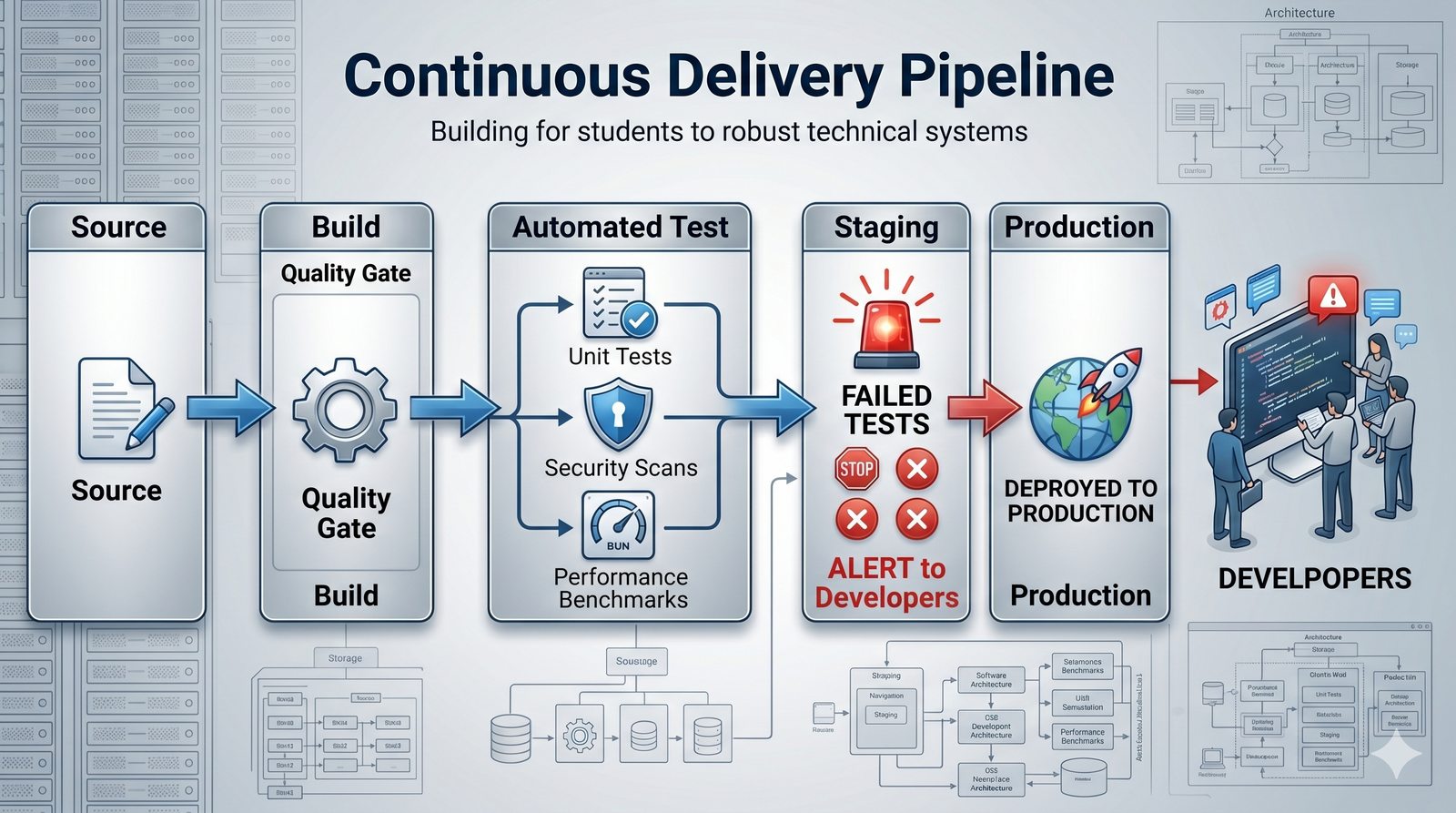
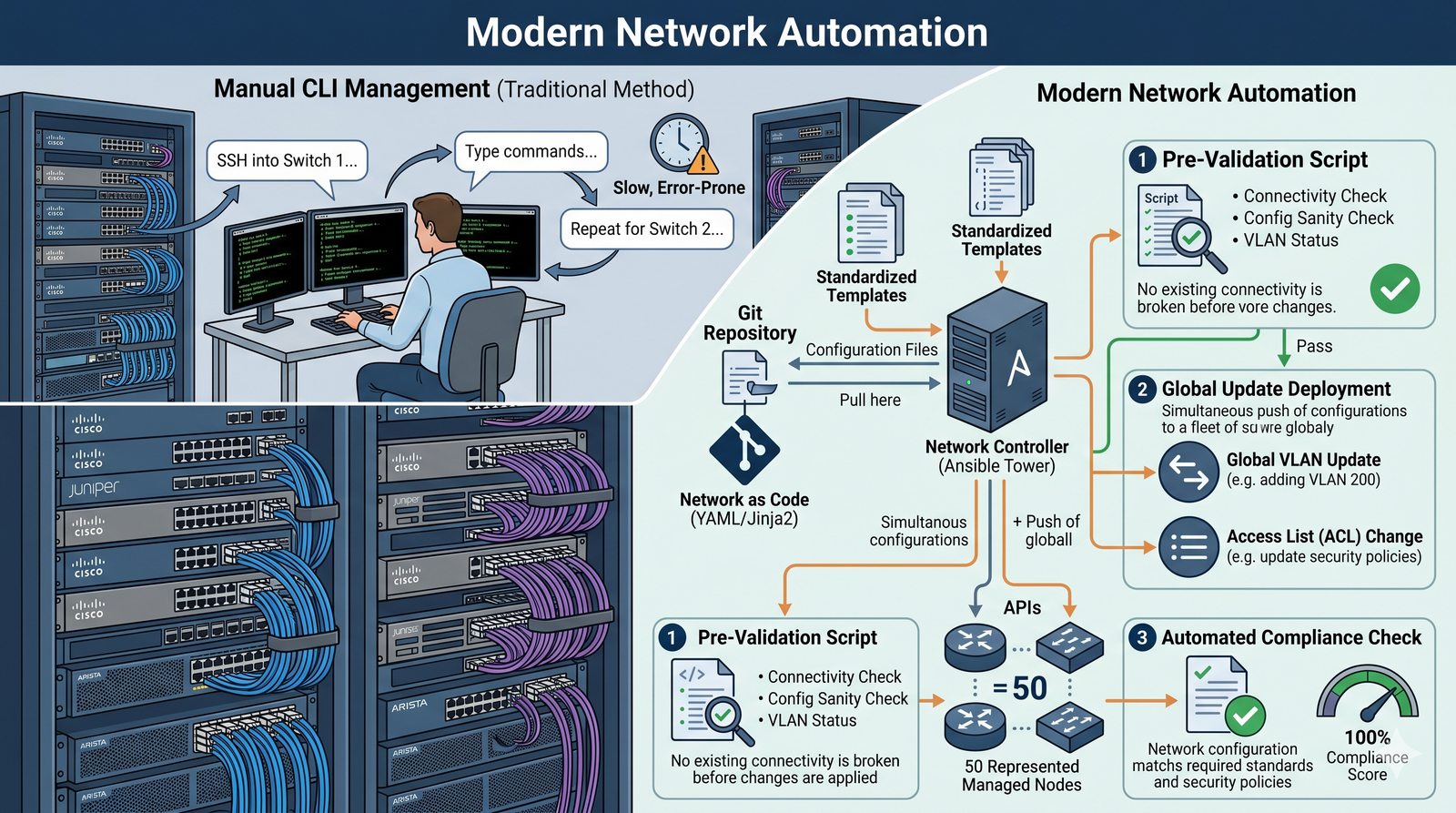
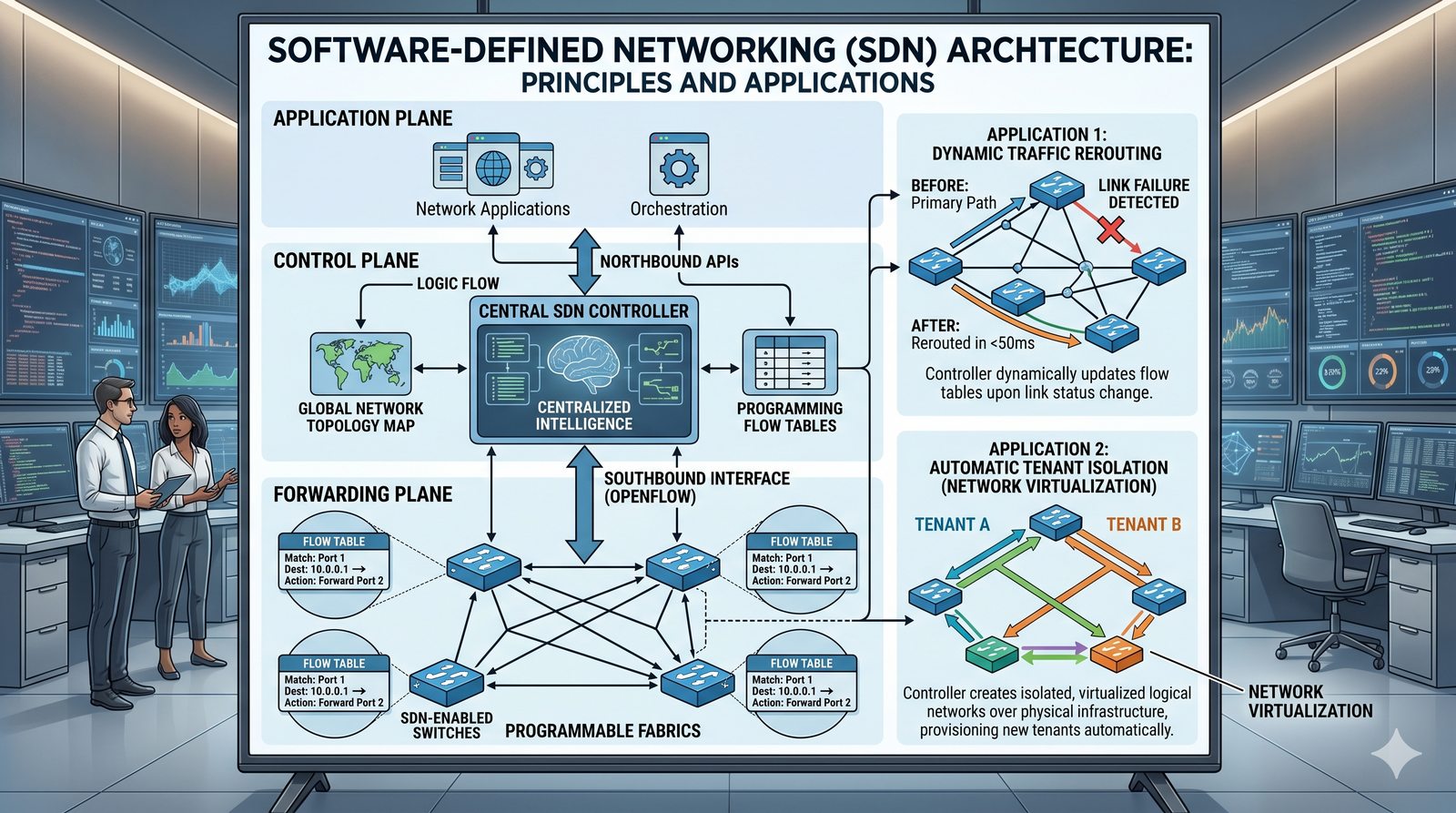
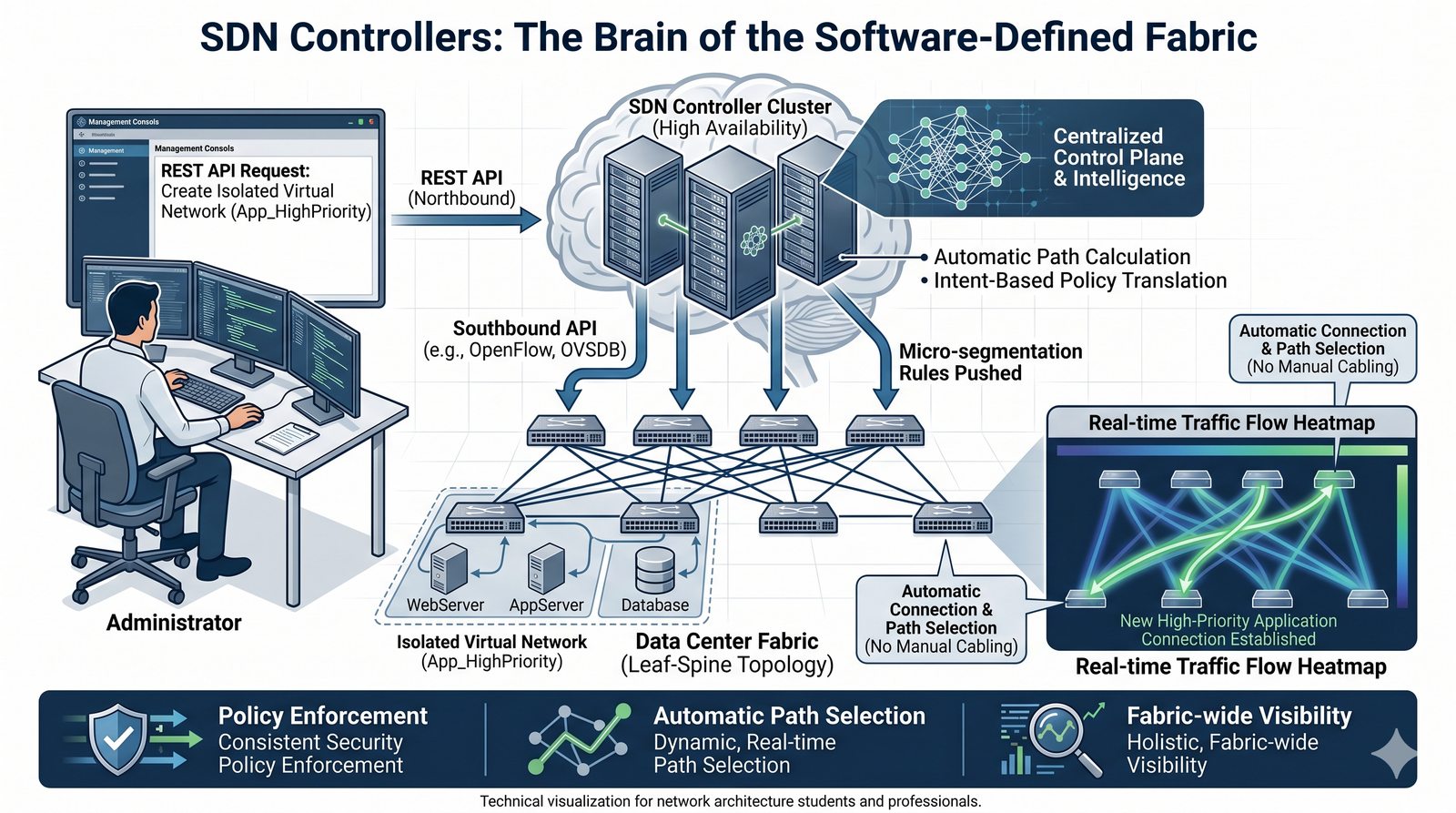
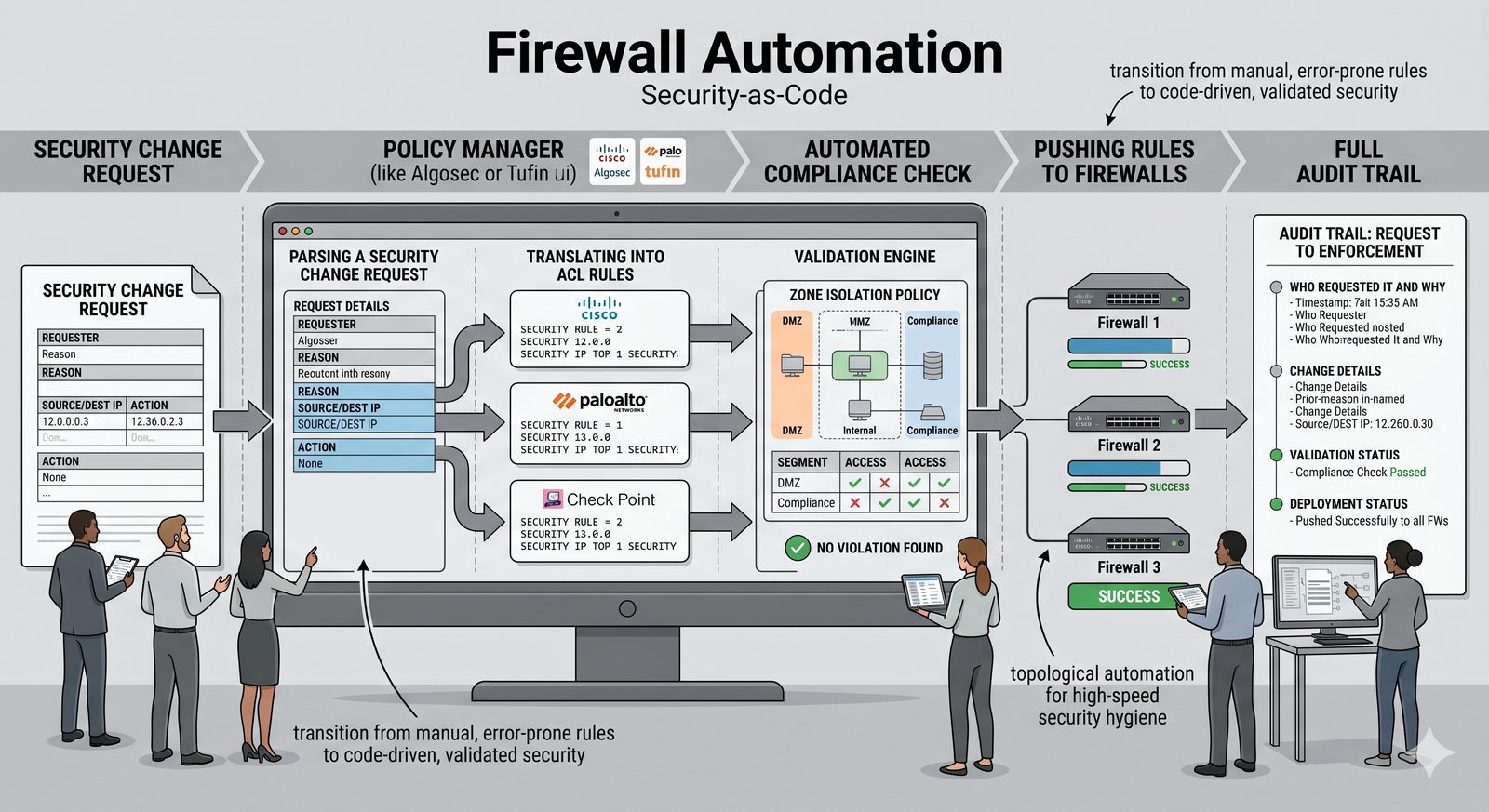
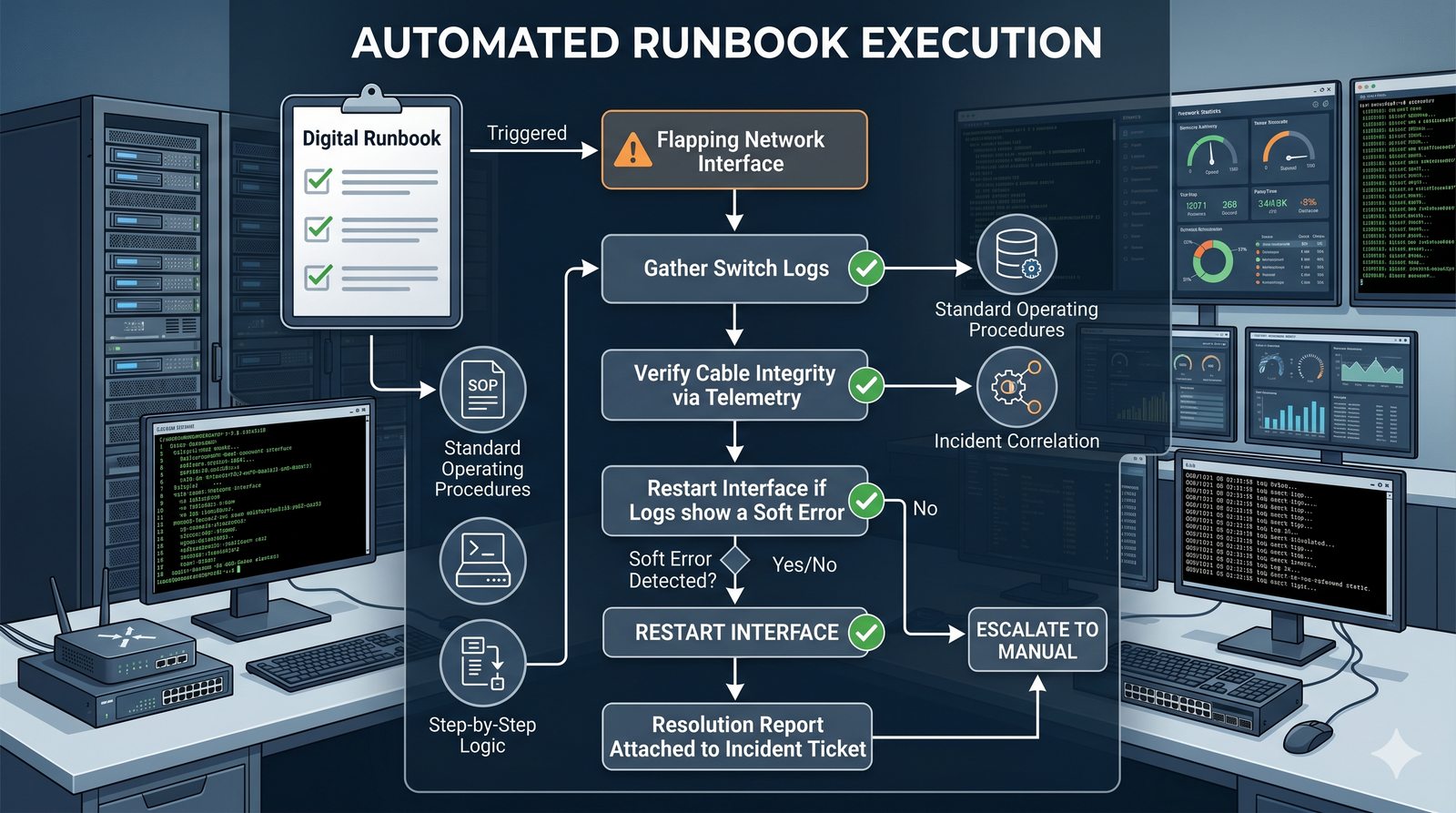
Podejście imperatywne w automatyzacji skupia się na sekwencji kroków, które należy wykonać, aby osiągnąć cel. Przykładem imperatywności jest tradycyjny skrypt bash, który krok po kroku instaluje pakiety i konfiguruje usługi. Główną wadą tego podejścia jest brak idempotentności, co oznacza, że wielokrotne uruchomienie tego samego skryptu może dać różne rezultaty.
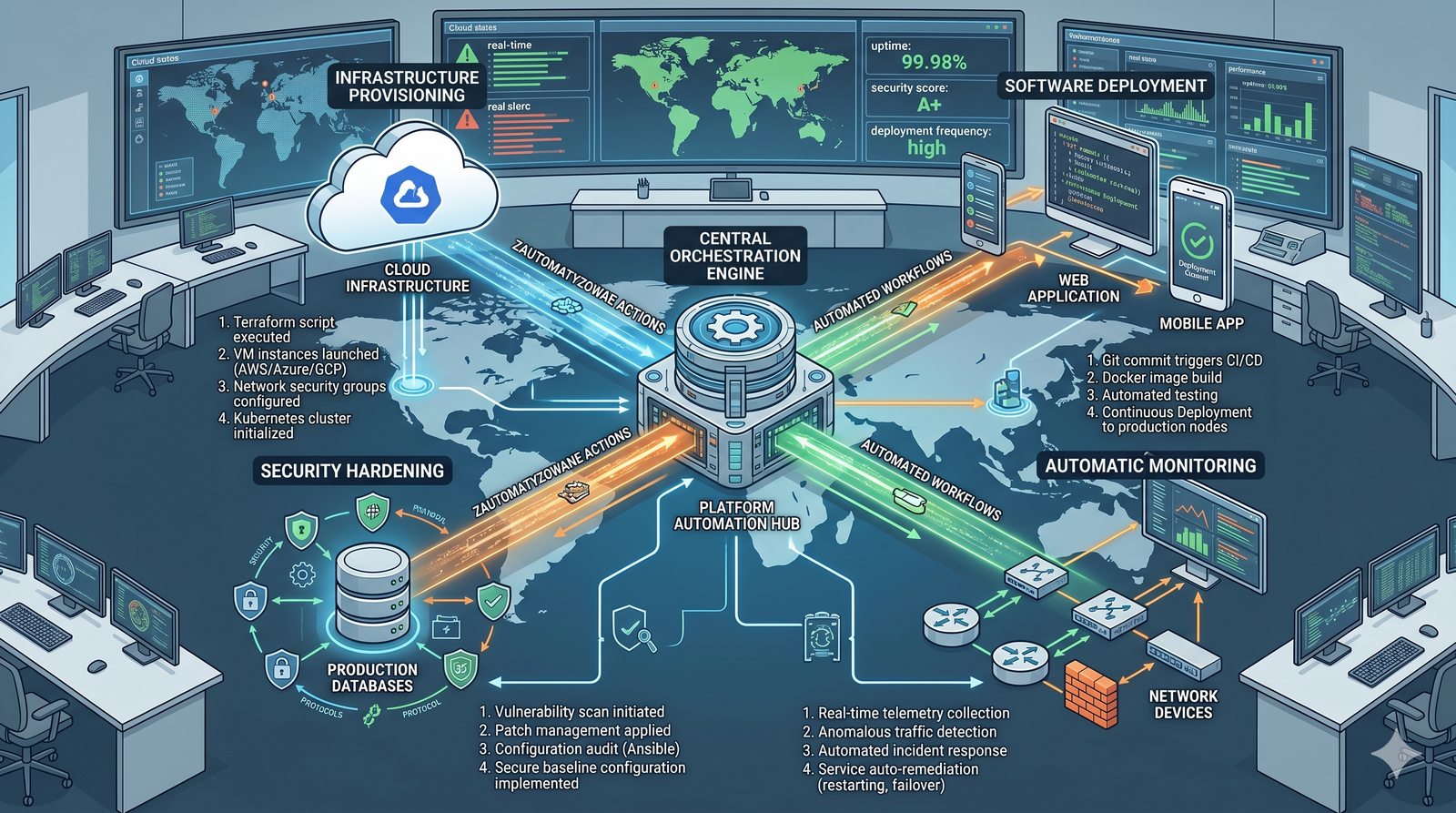
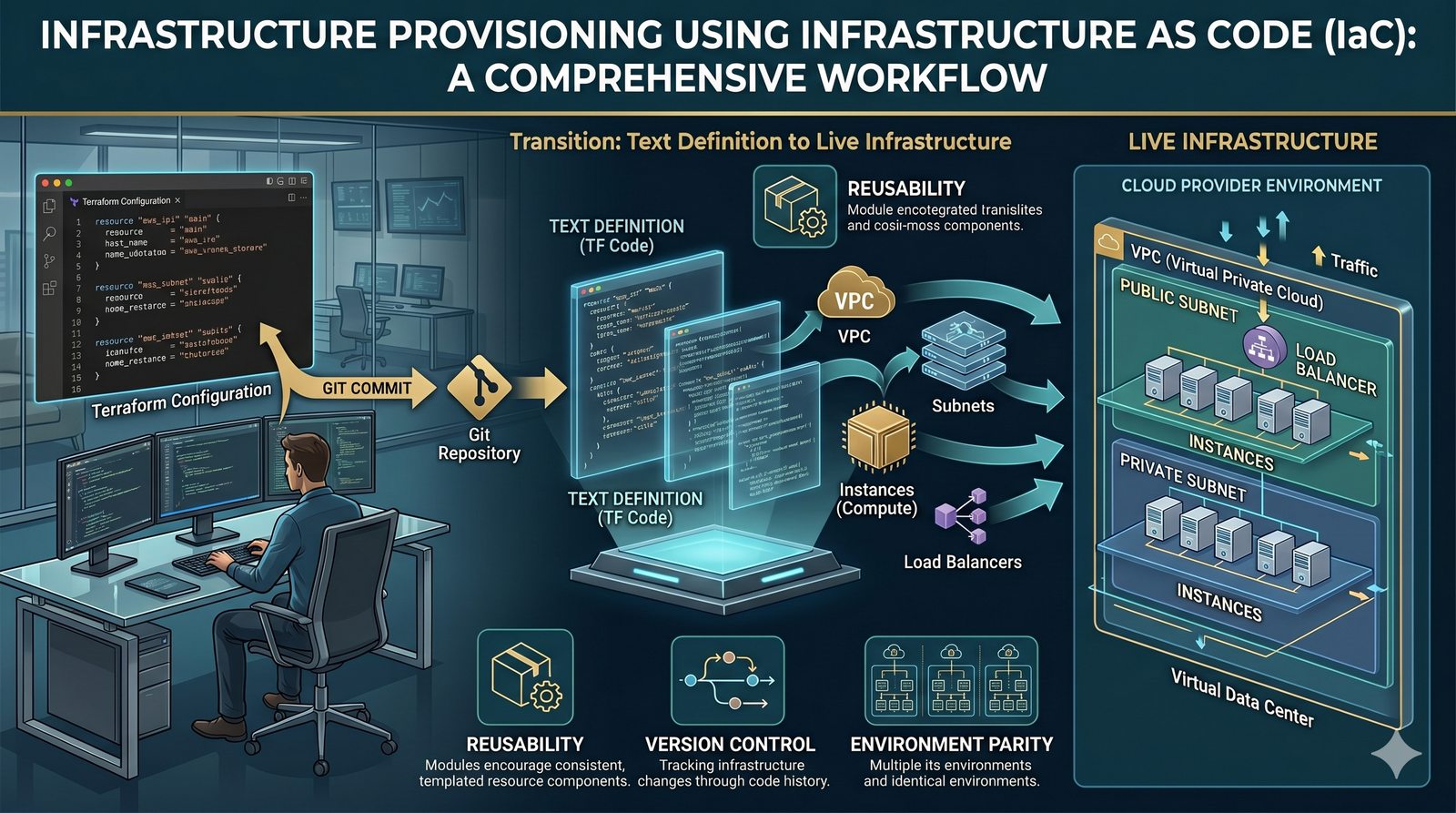
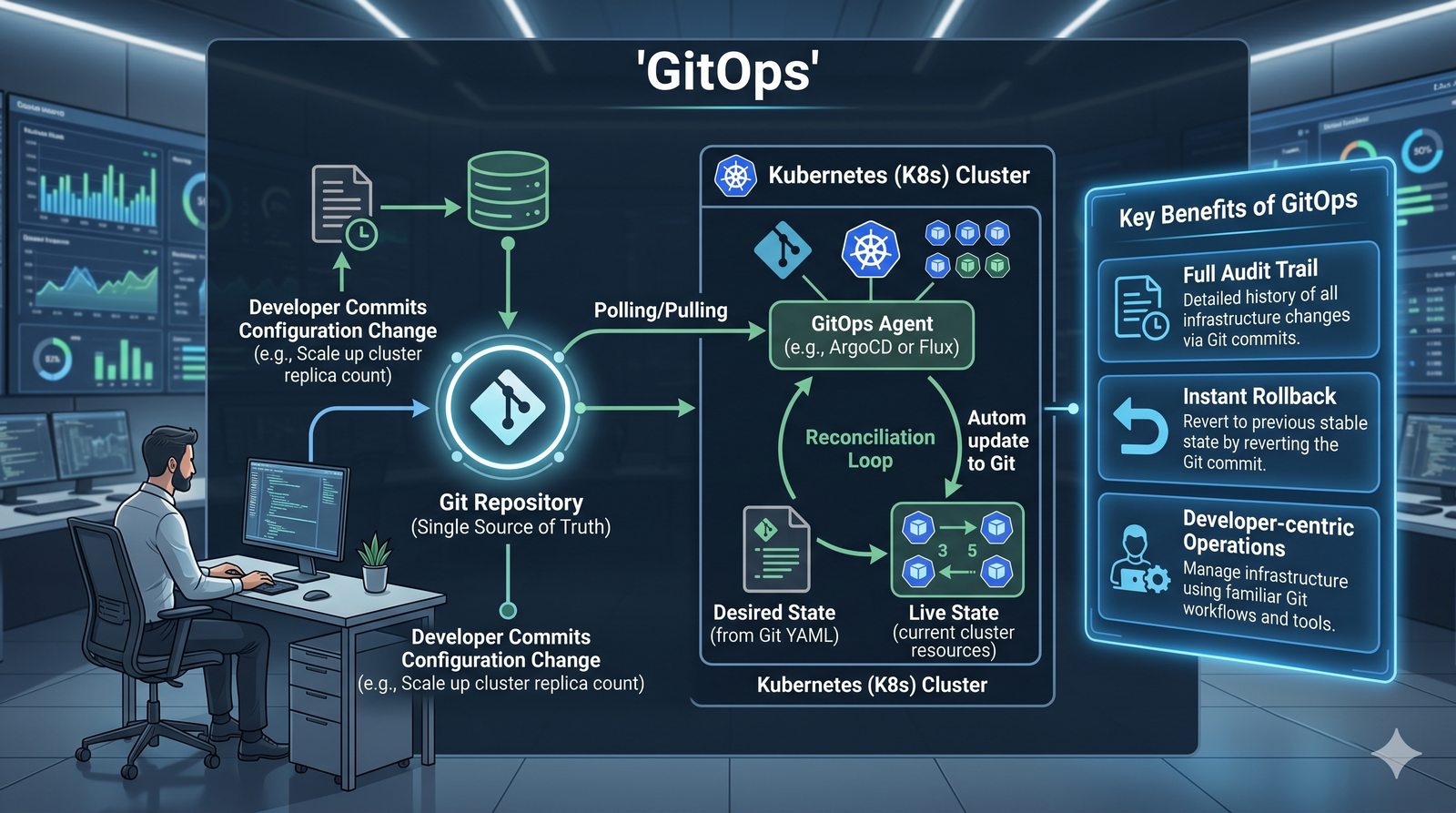
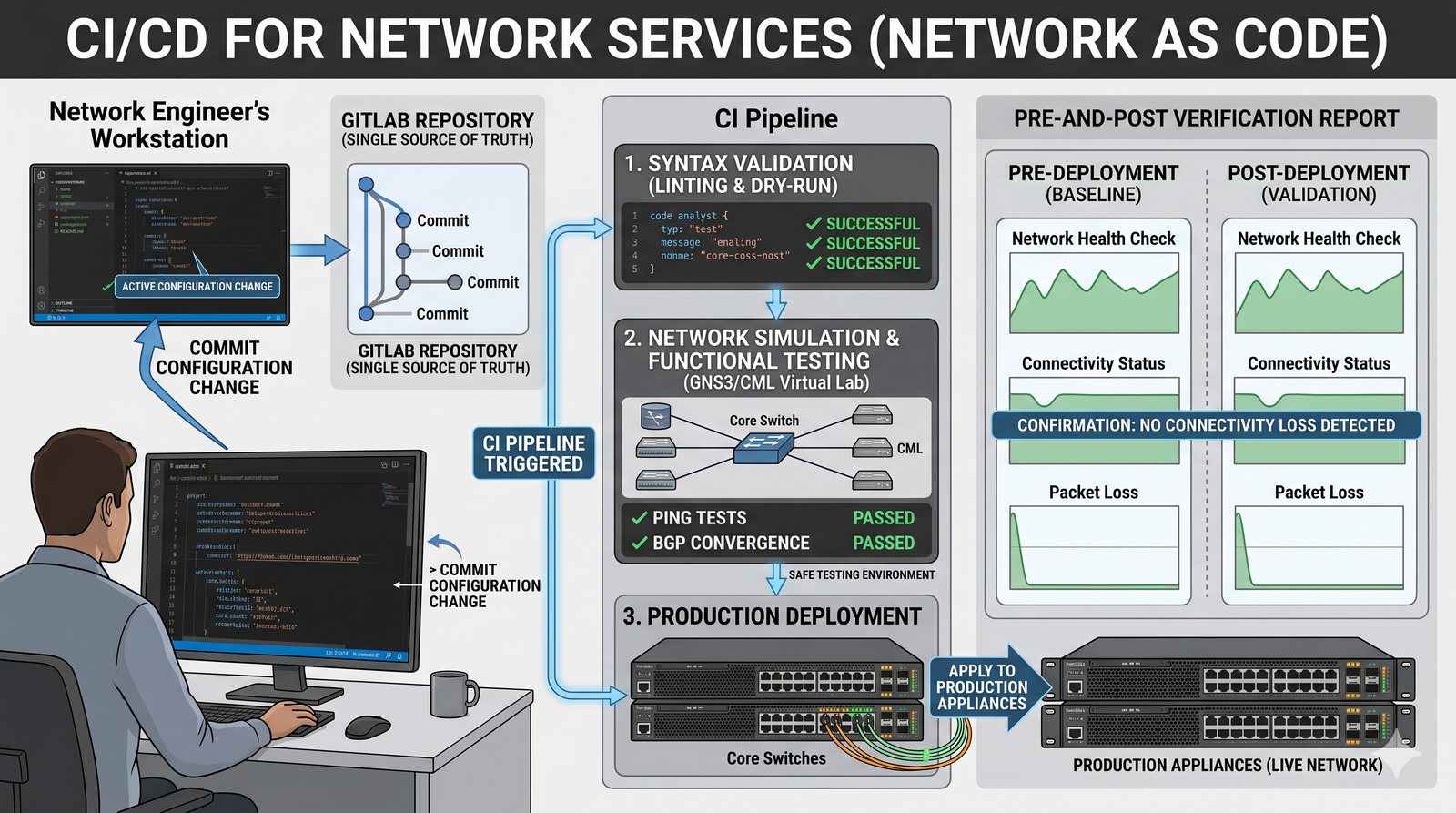
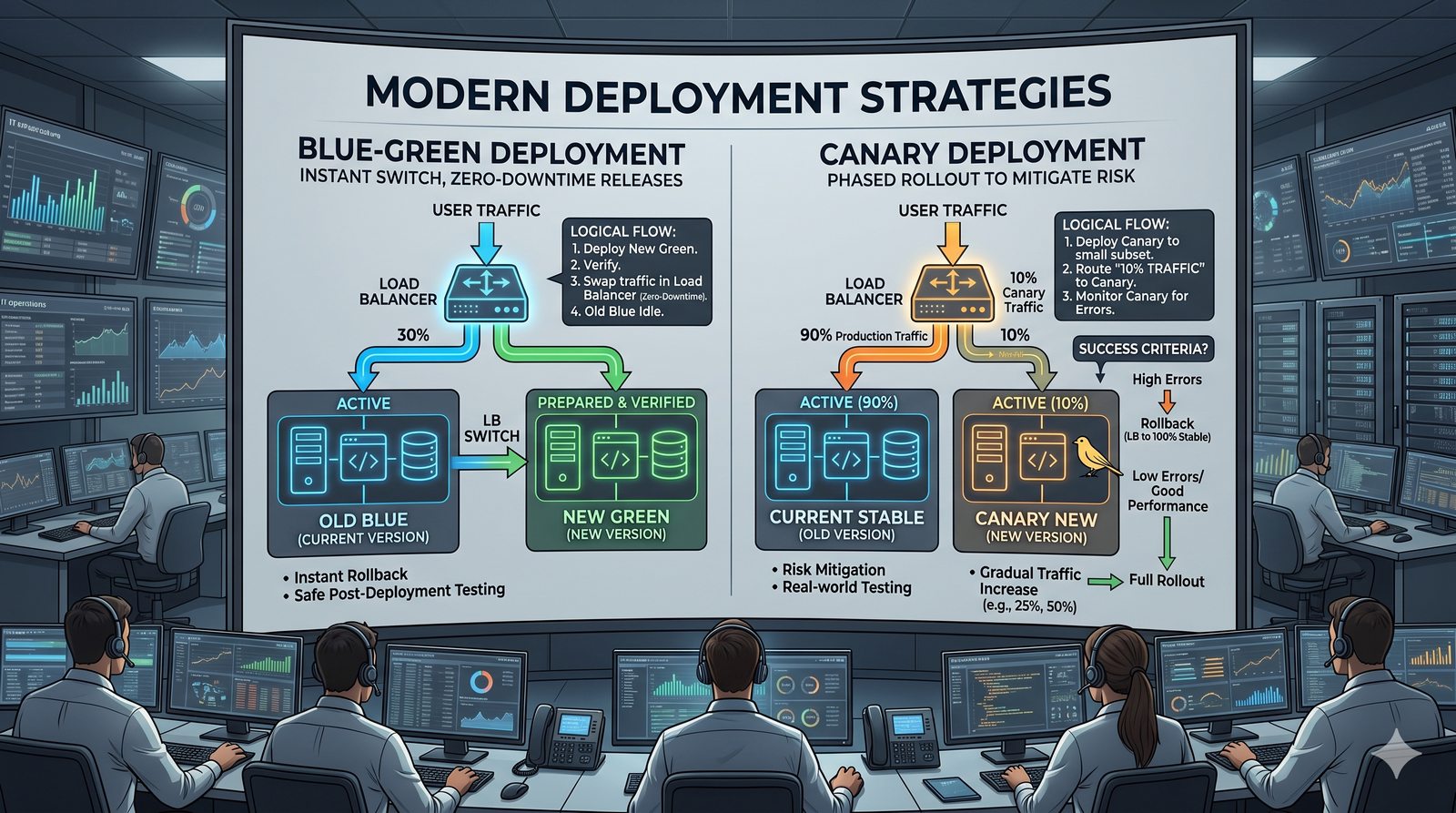
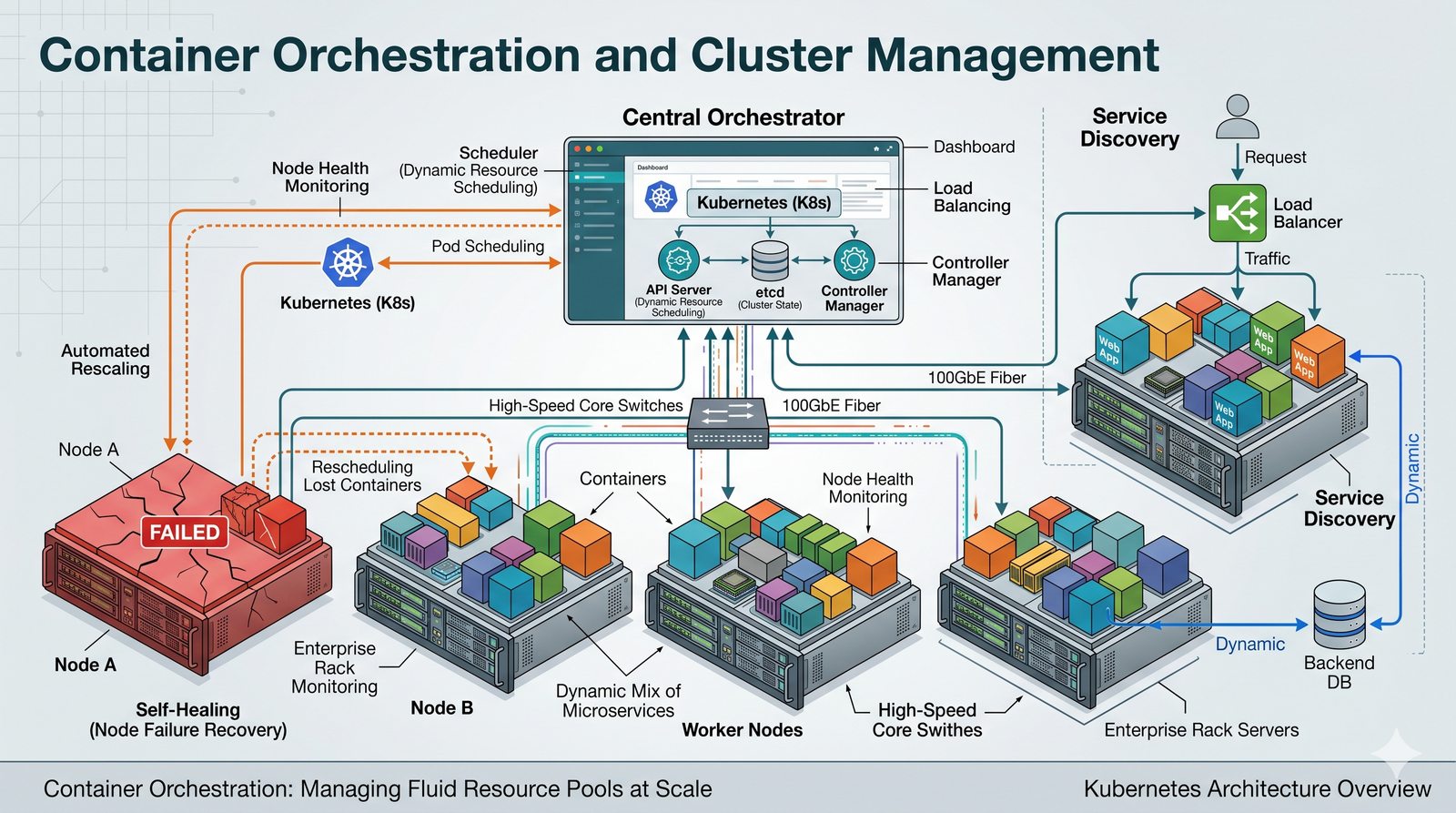
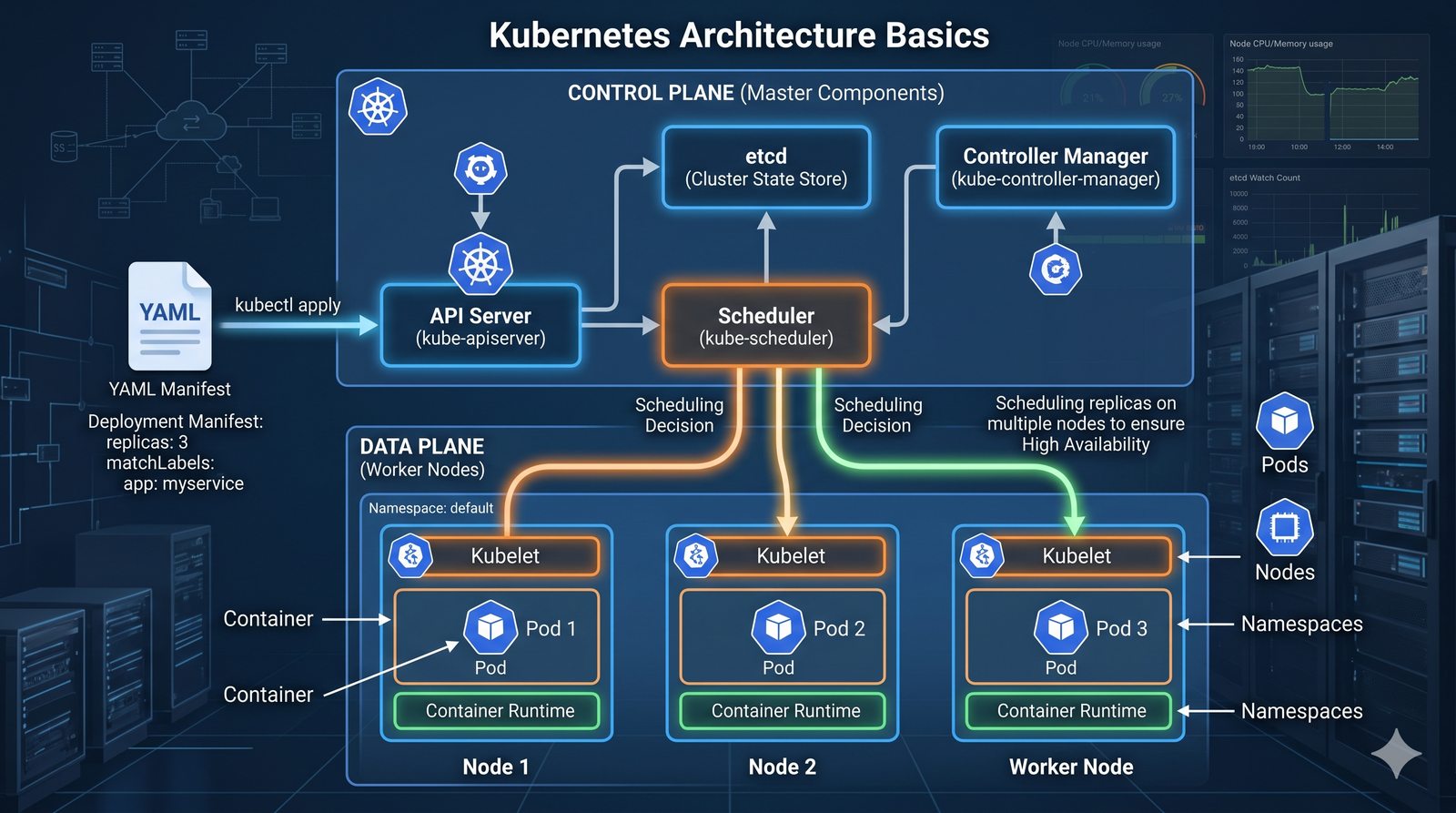
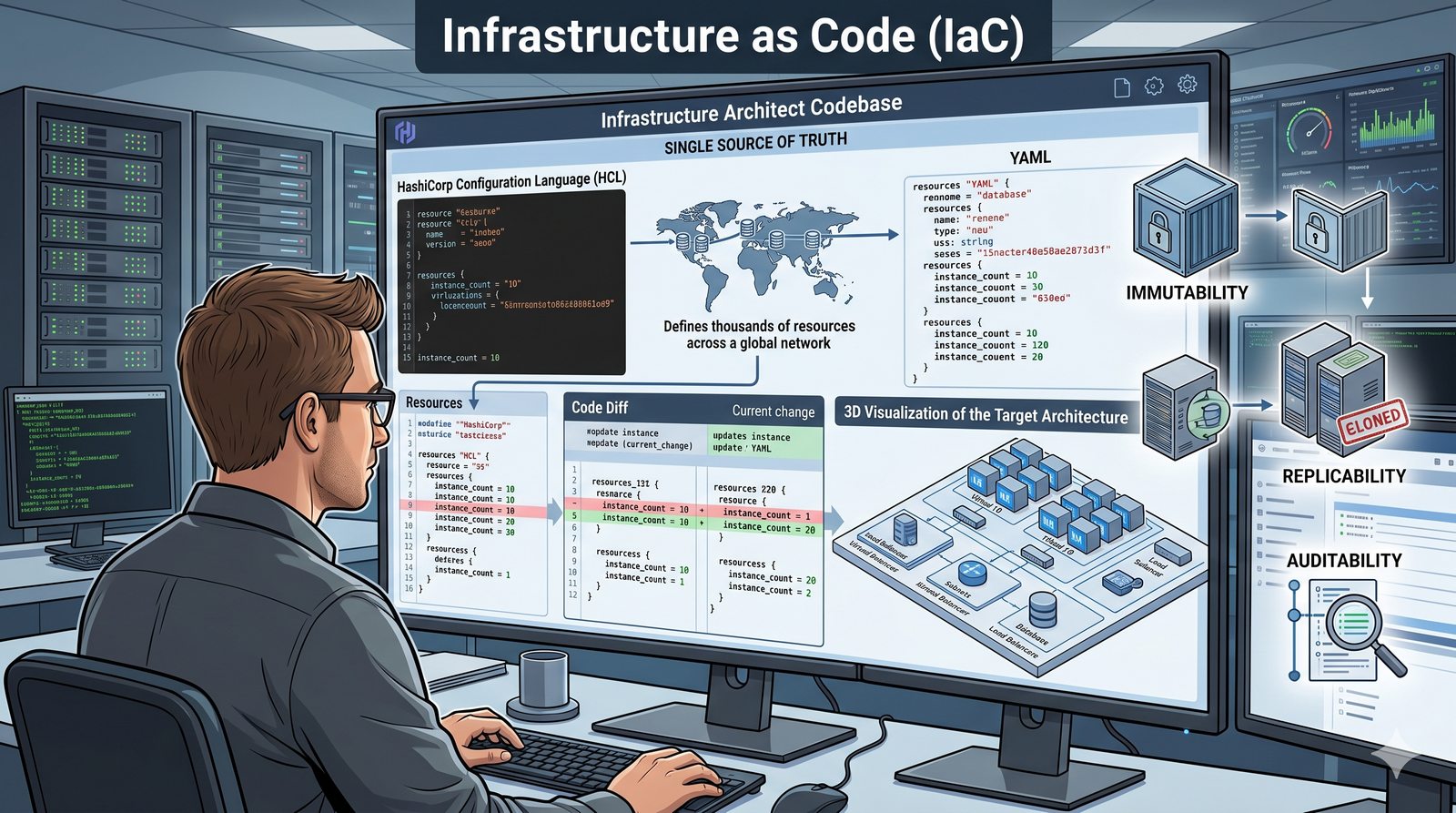
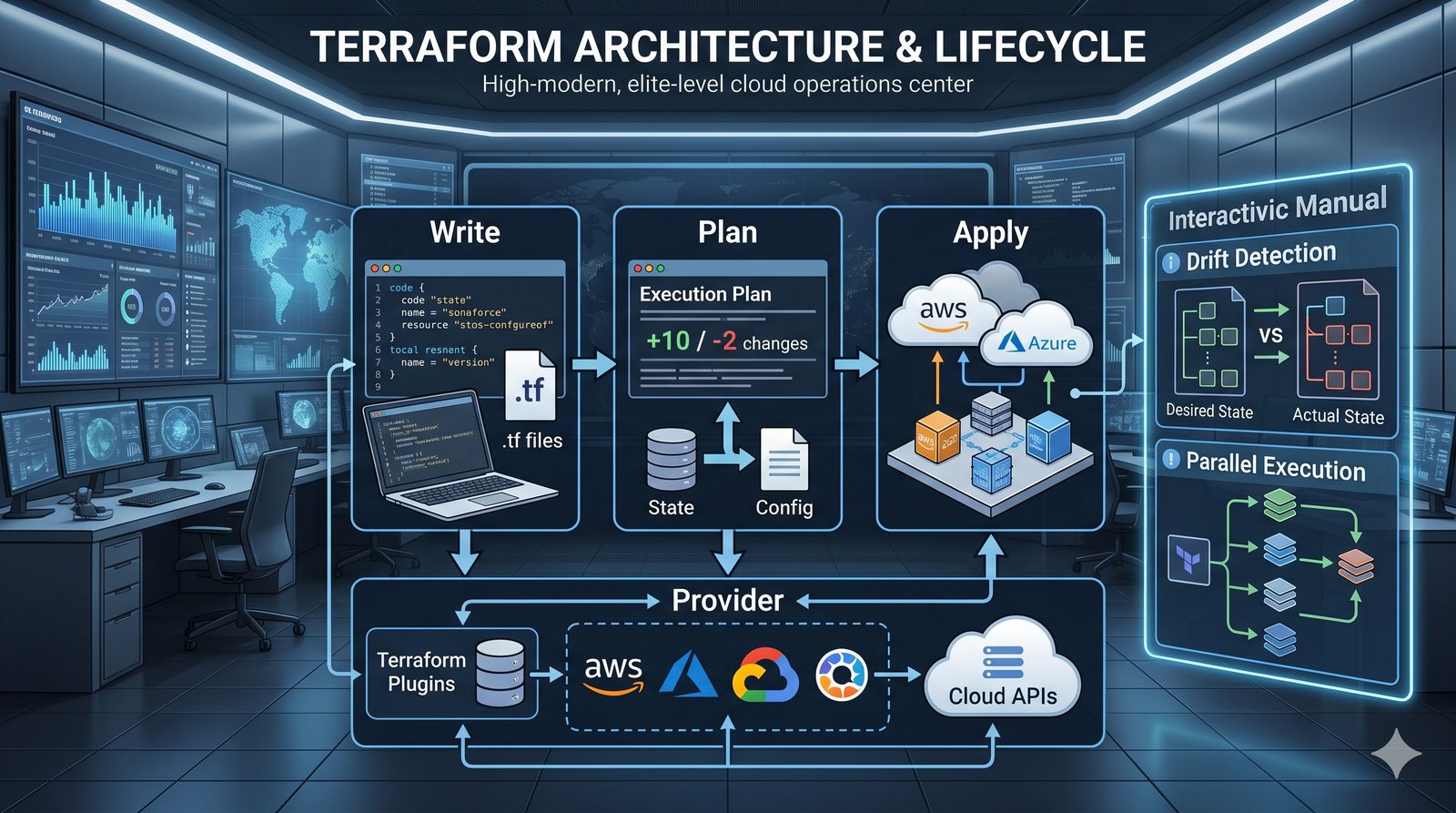
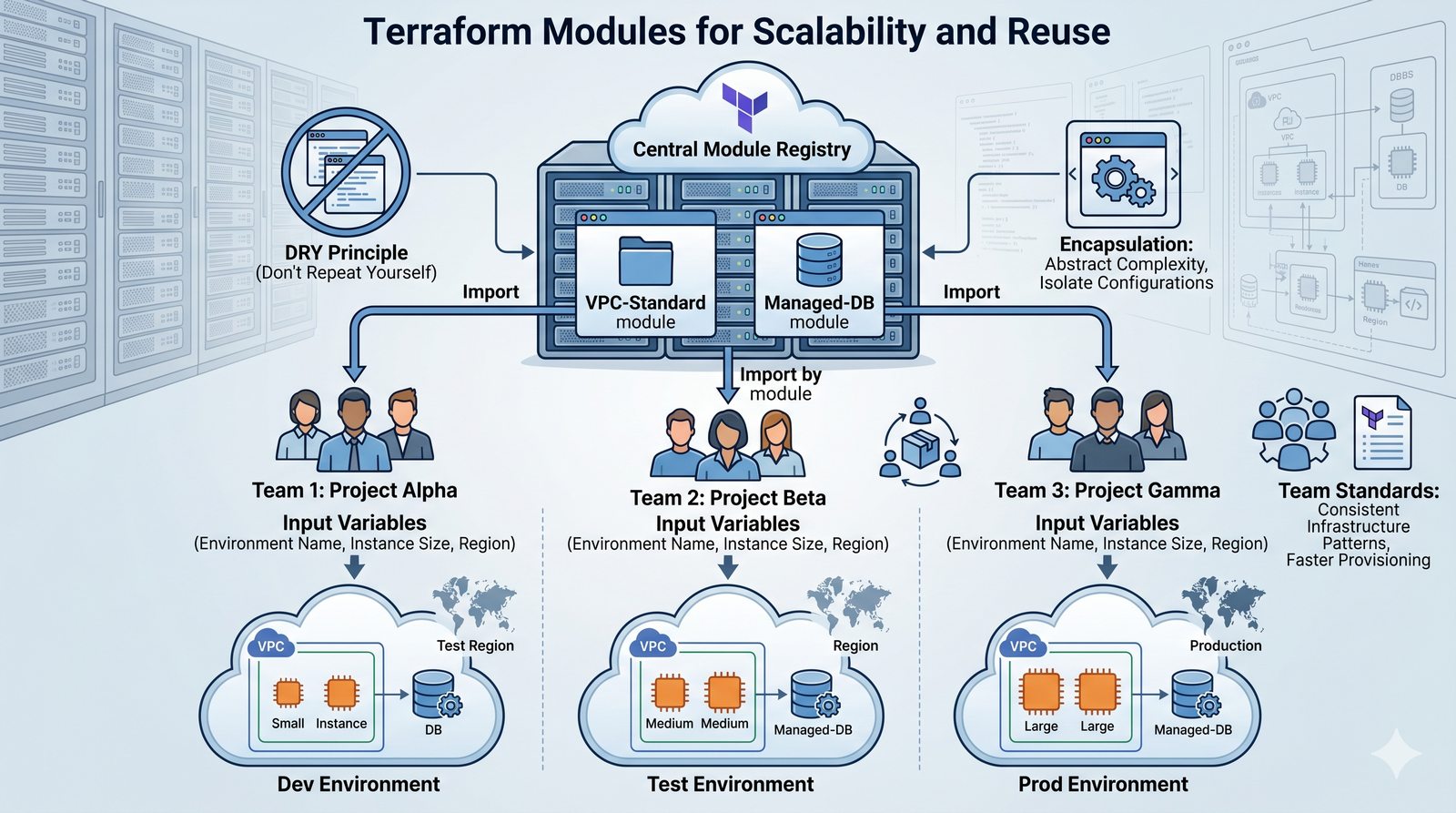
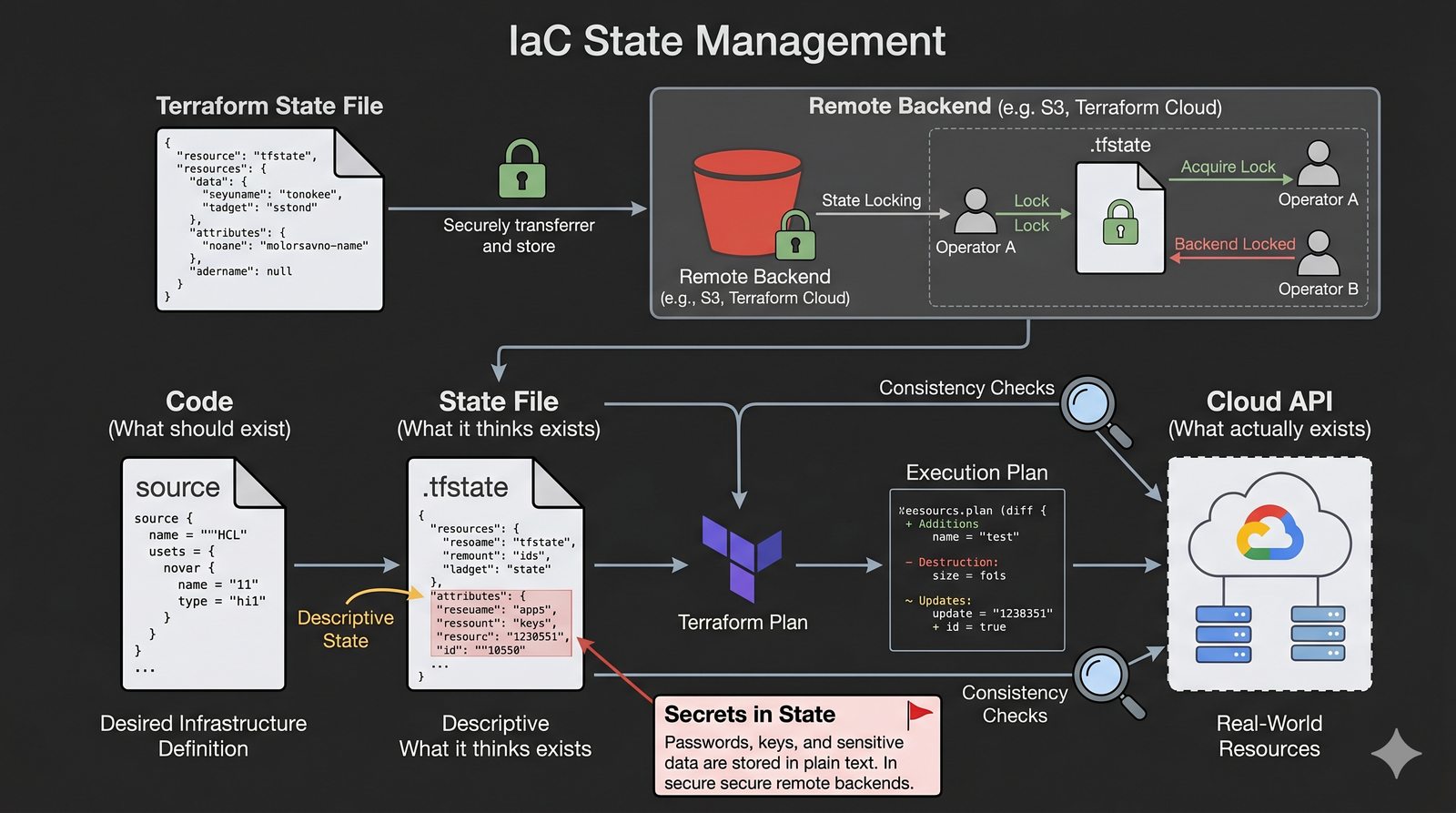
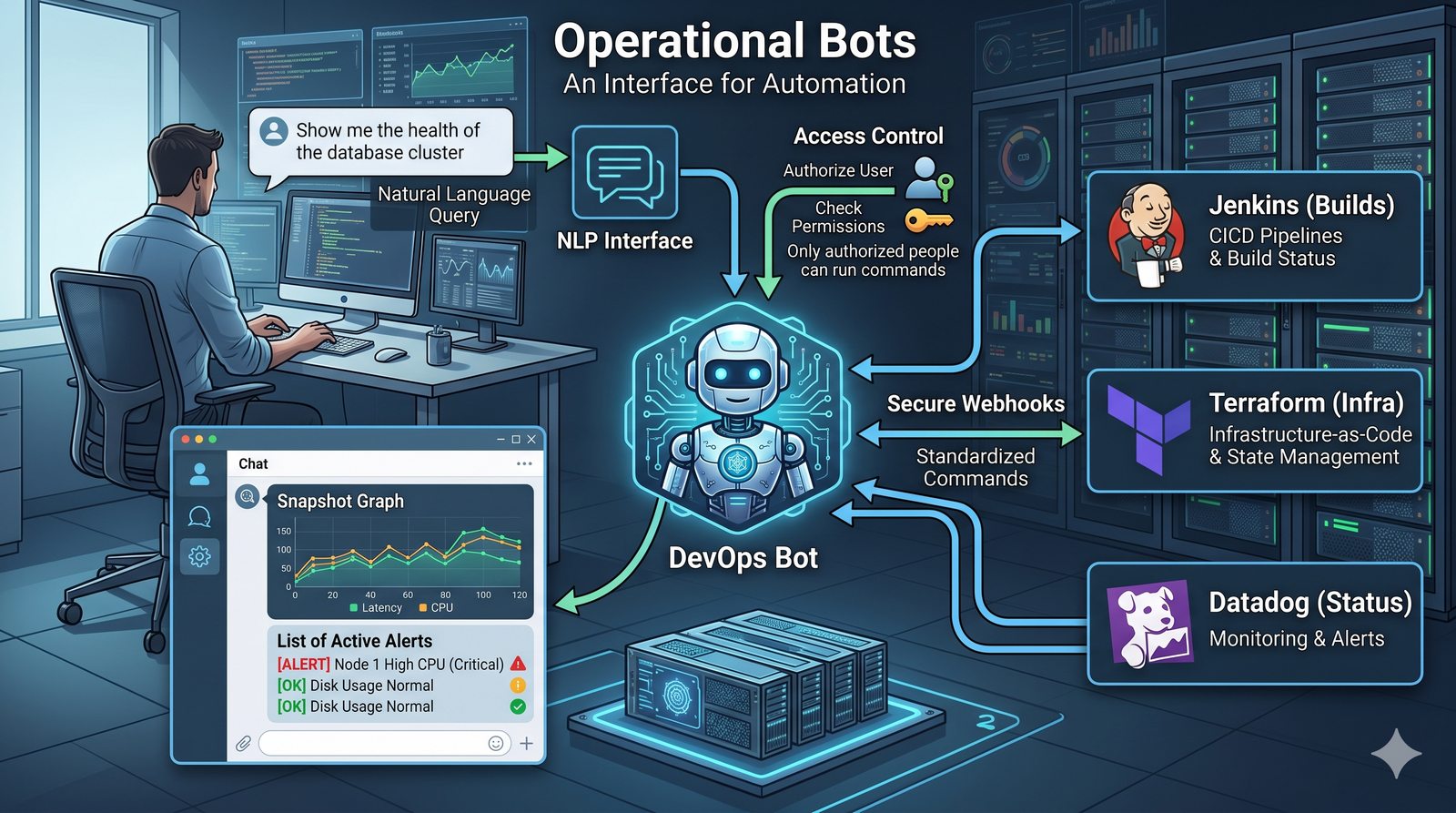
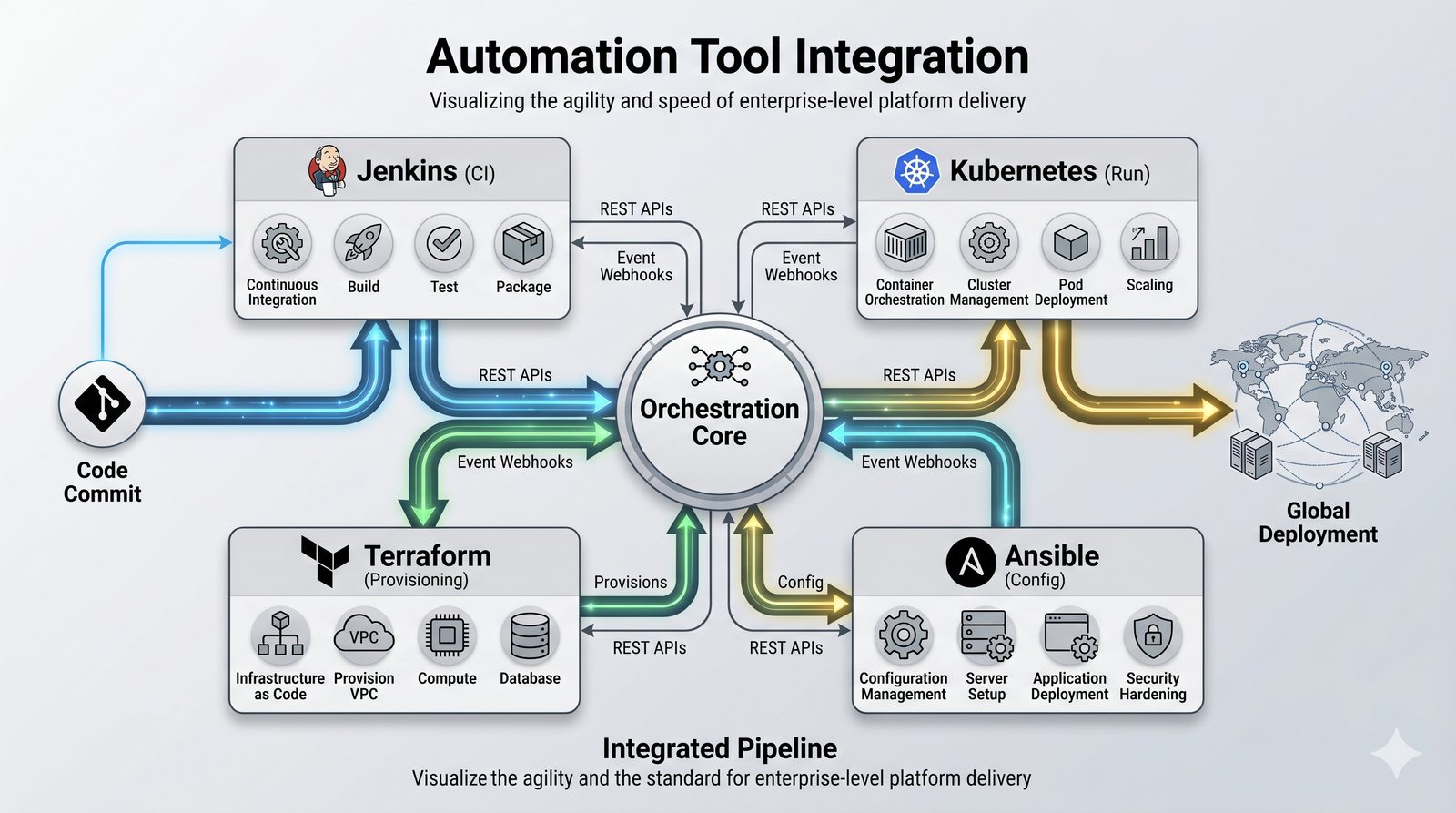
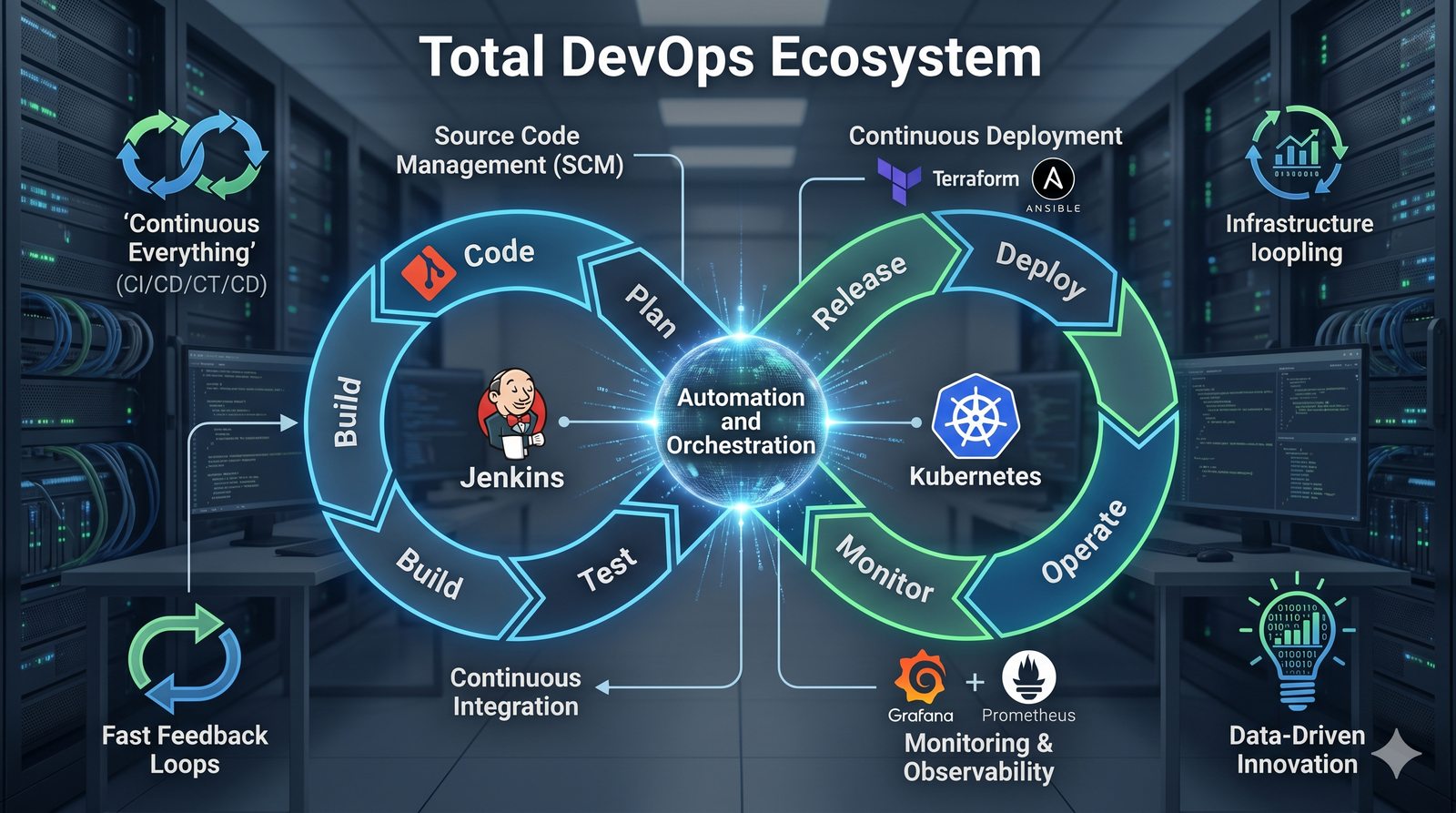
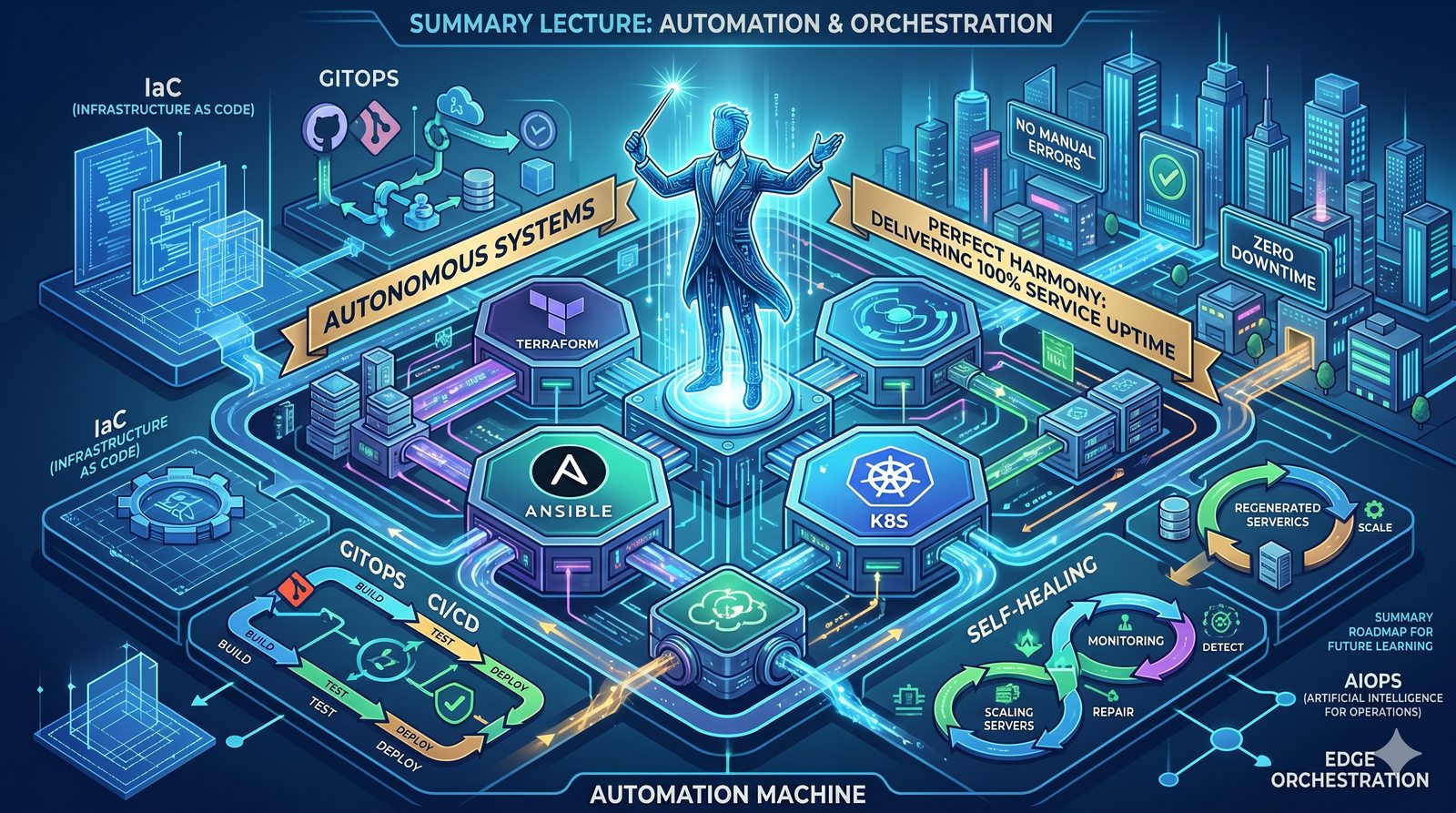
Podejście deklaratywne przyjmuje natomiast, że użytkownik opisuje stan końcowy systemu, a narzędzie samo decyduje, jakie czynności są niezbędne. W przypadku Terraforma użytkownik deklaruje, że ma istnieć maszyna wirtualna o określonych parametrach, a narzędzie oblicza różnicę między stanem obecnym a pożądanym. Automatycznie tworzy, modyfikuje lub usuwa zasoby, aby osiągnąć zgodność z deklaracją.
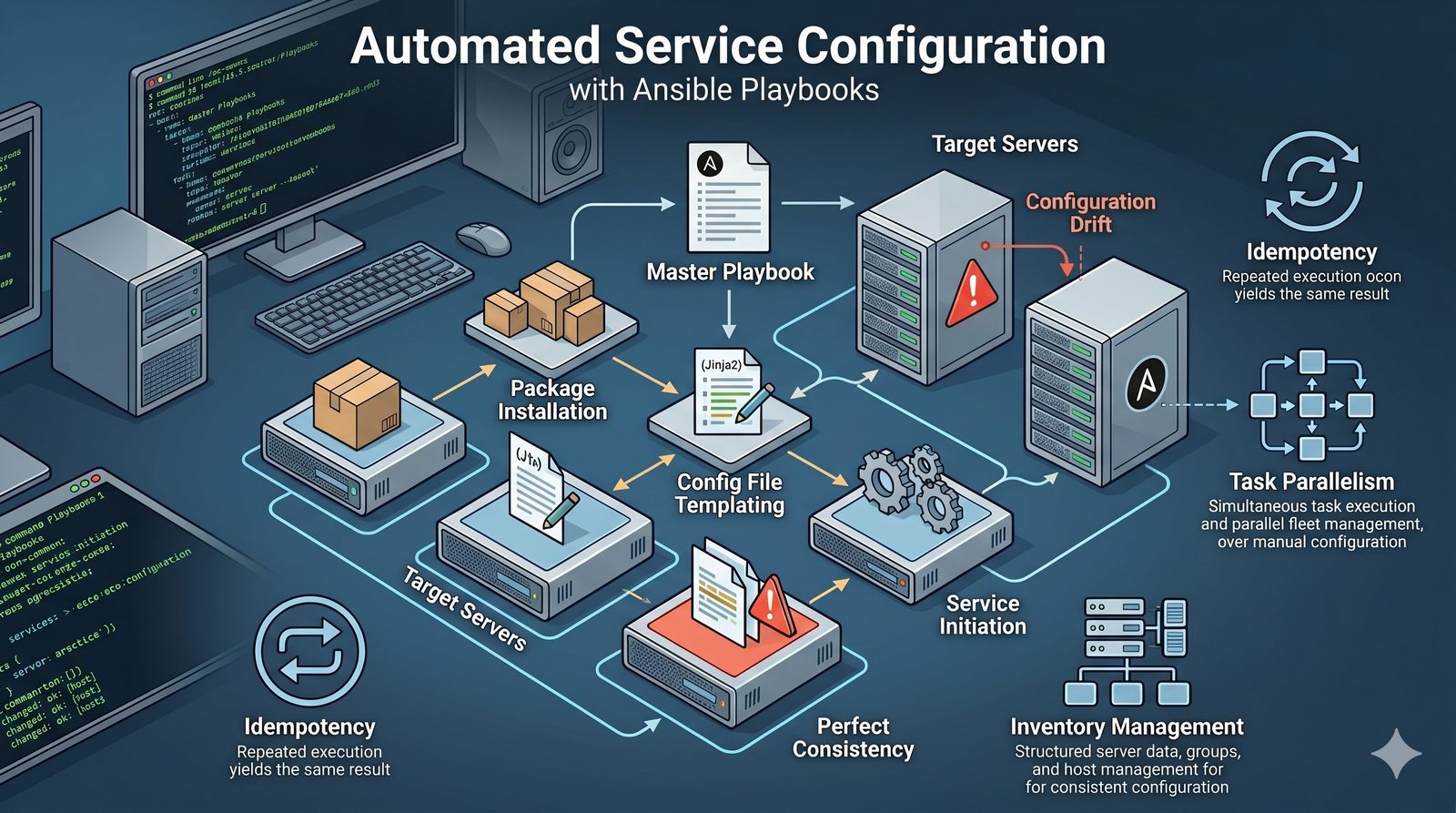
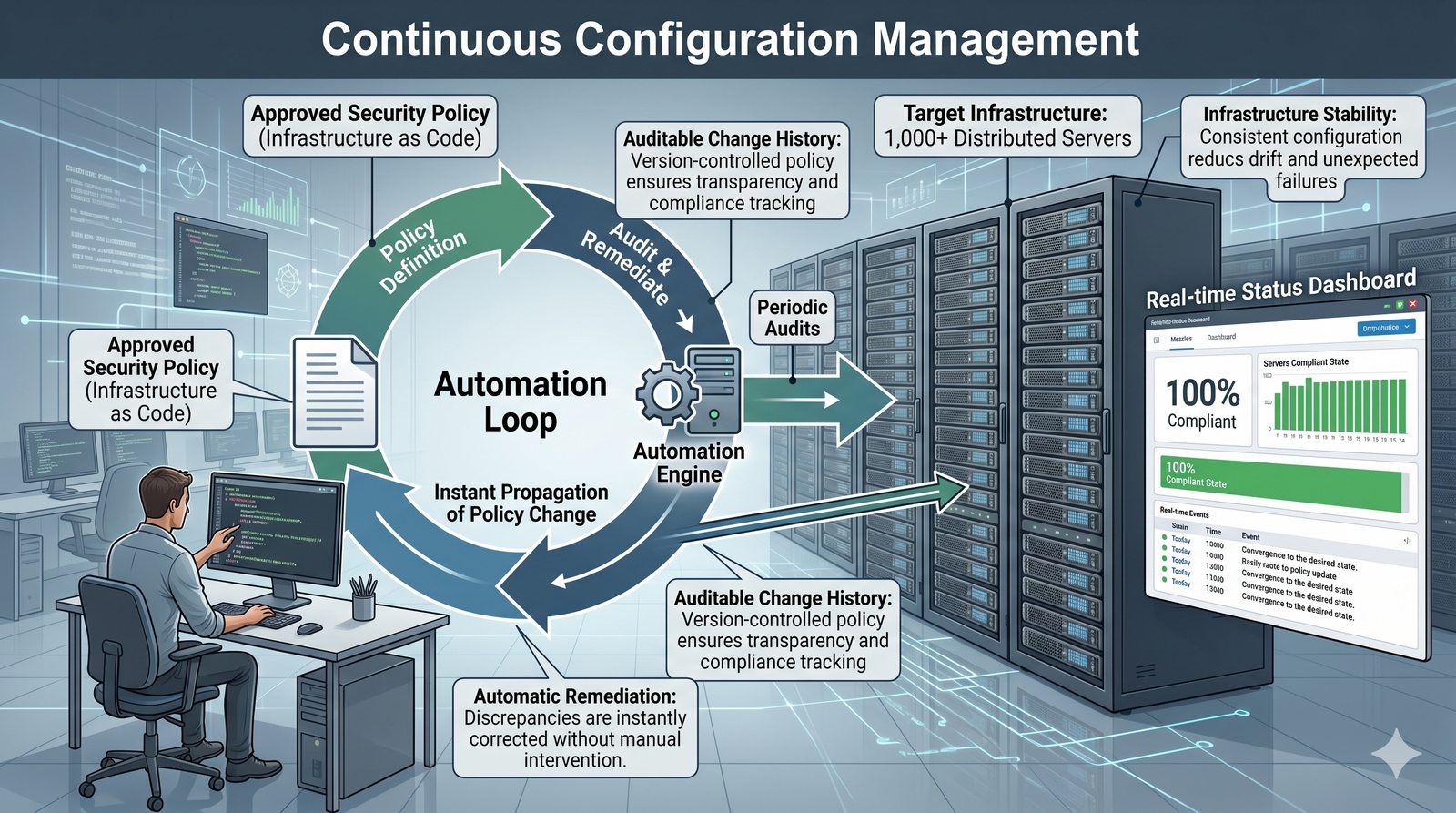
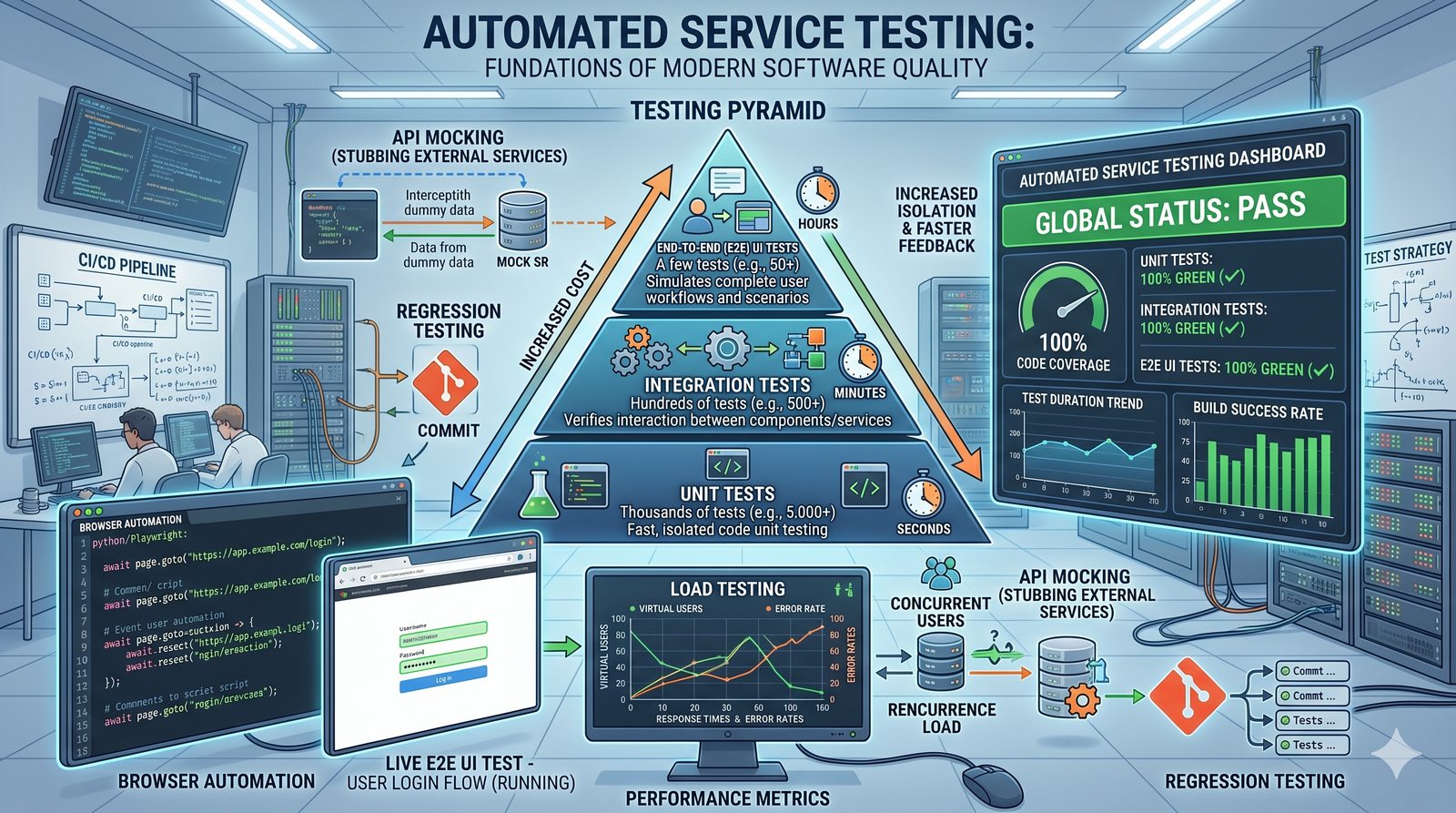
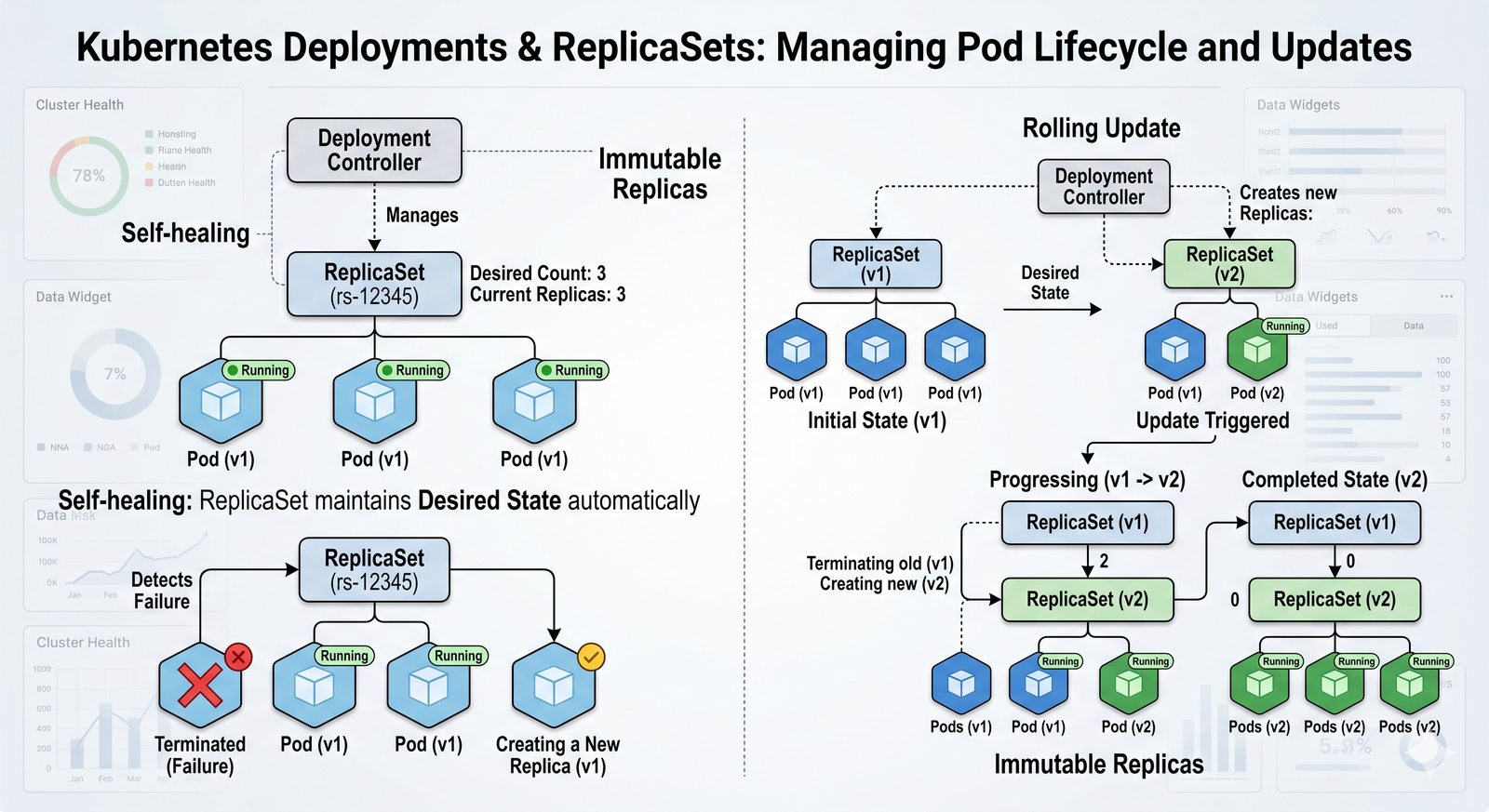
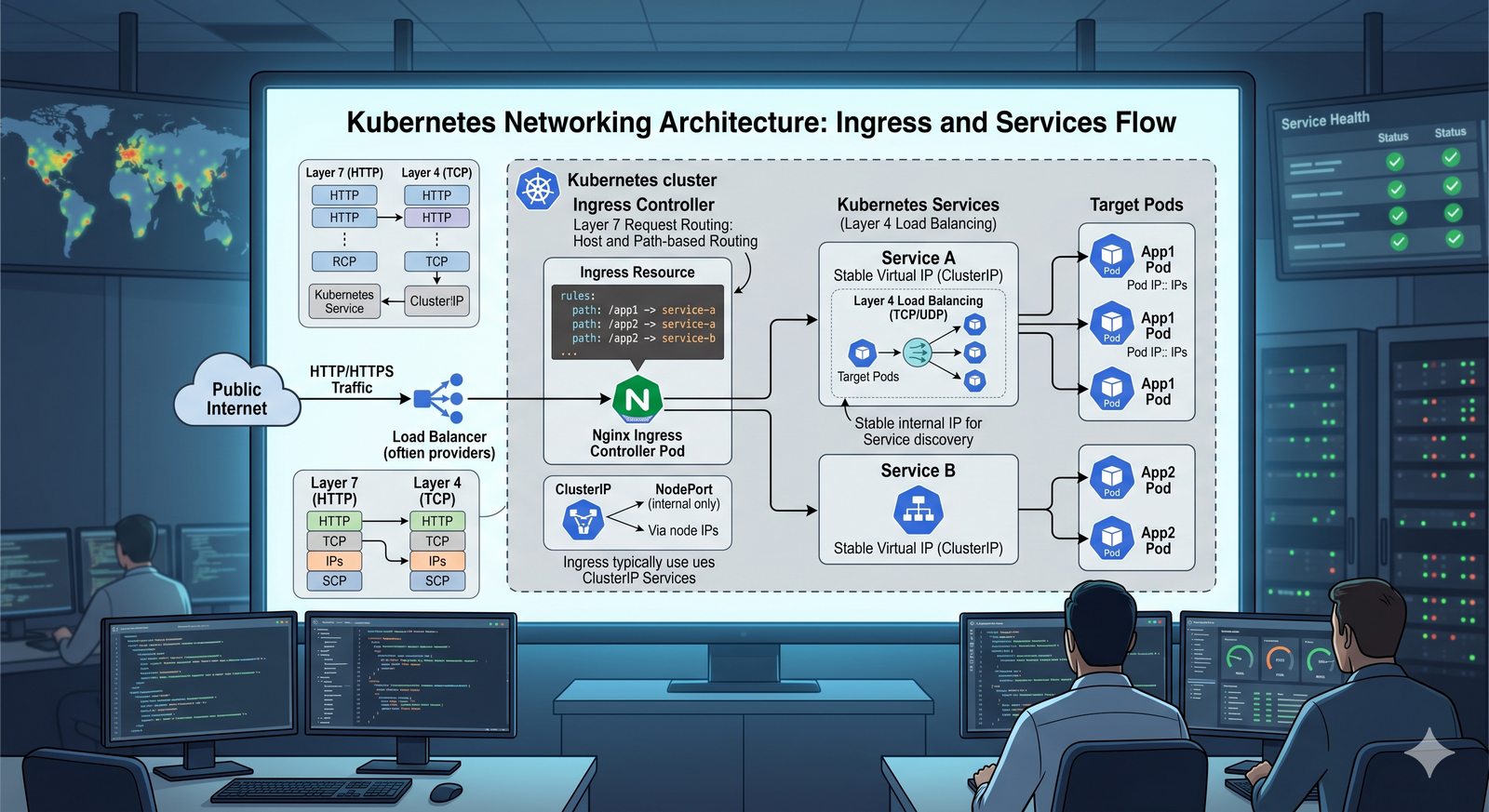
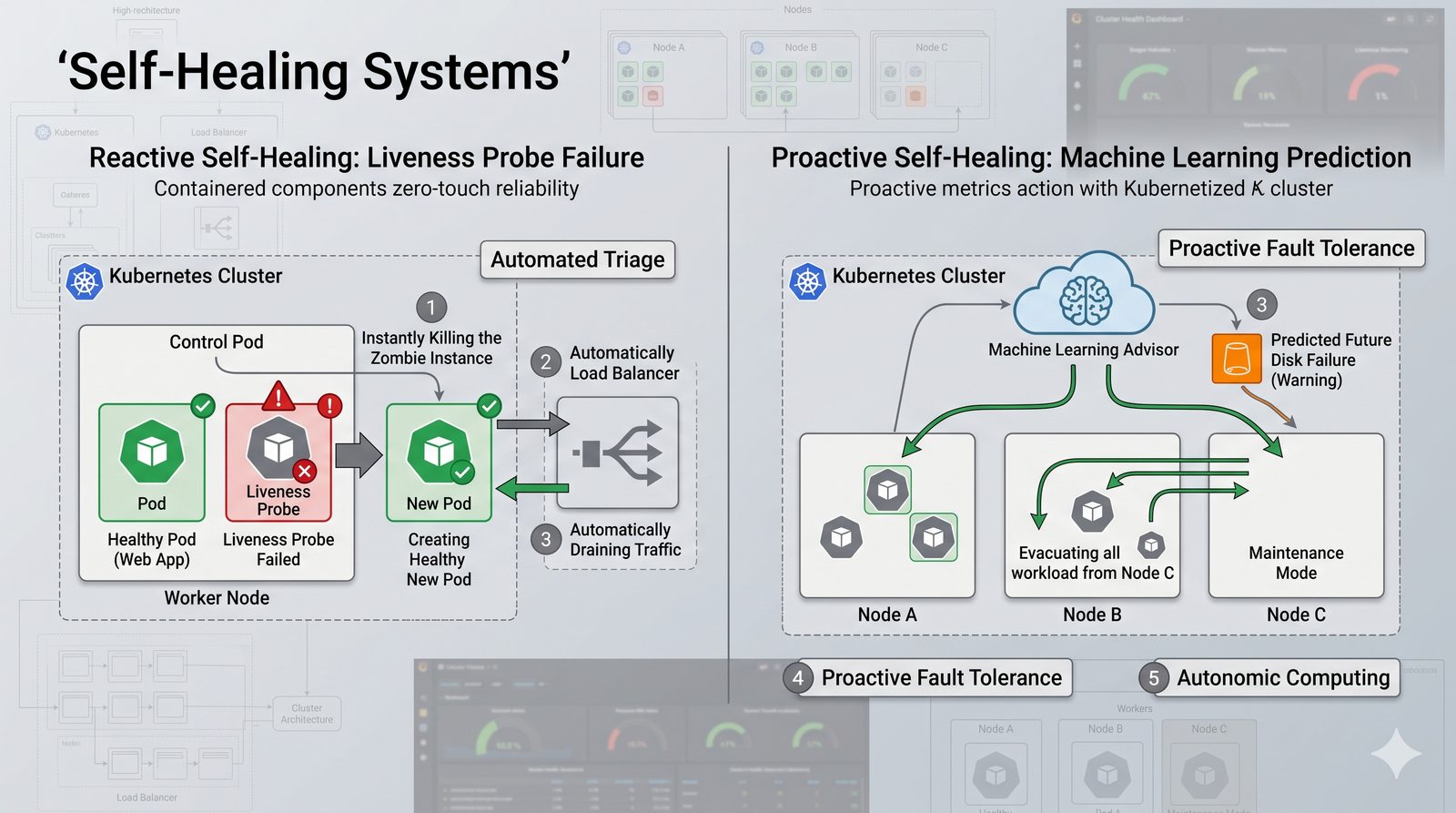
Idempotentność jest naturalną cechą podejścia deklaratywnego, co czyni je bezpieczniejszym w użyciu. W praktyce wiele narzędzi łączy oba podejścia, pozwalając na imperatywne kroki w ramach deklaratywnych przepływów. Ansible, choć głównie imperatywny, wspiera idempotentność modułów, a Terraform i Kubernetes są w pełni deklaratywne.