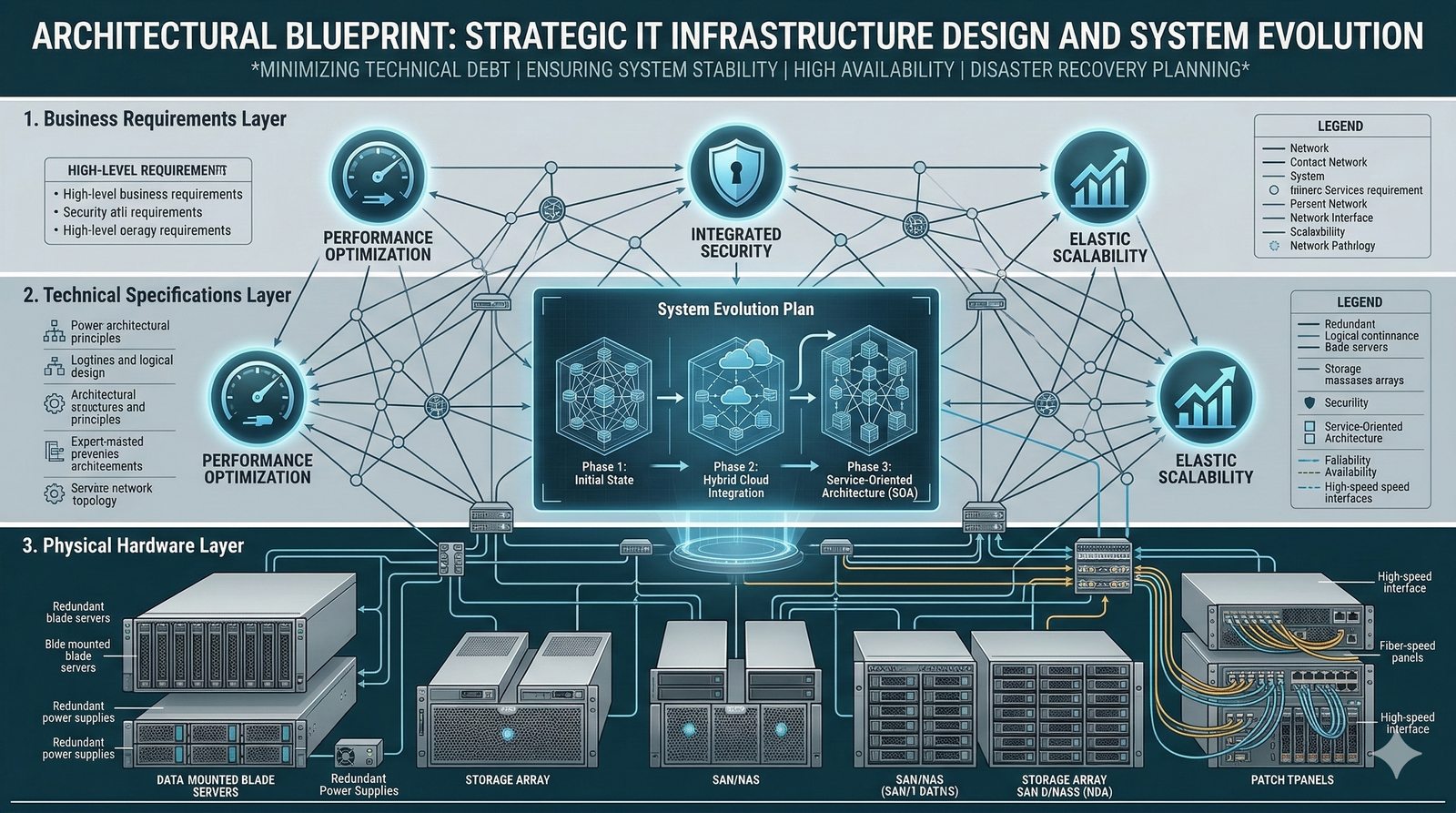
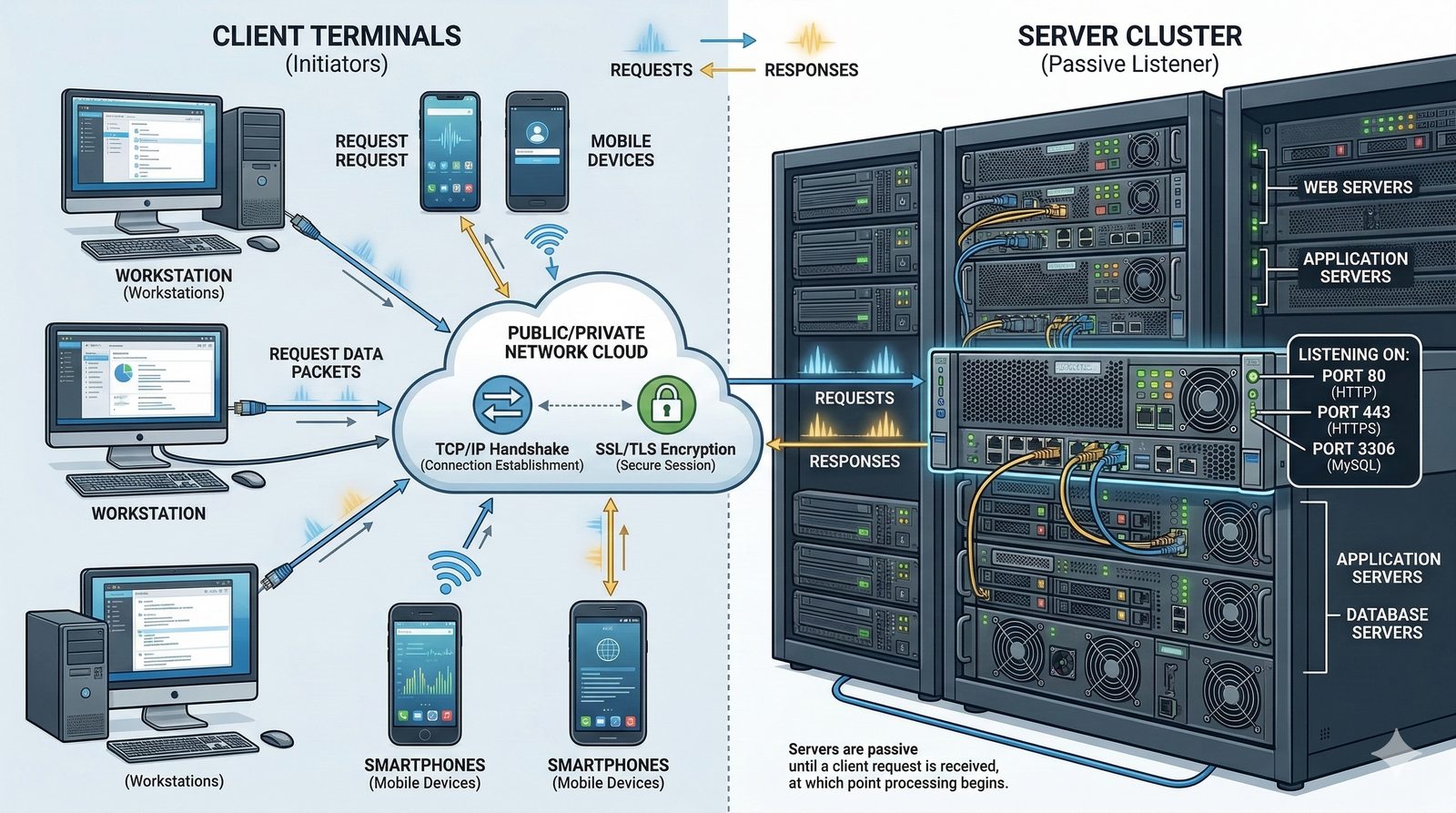
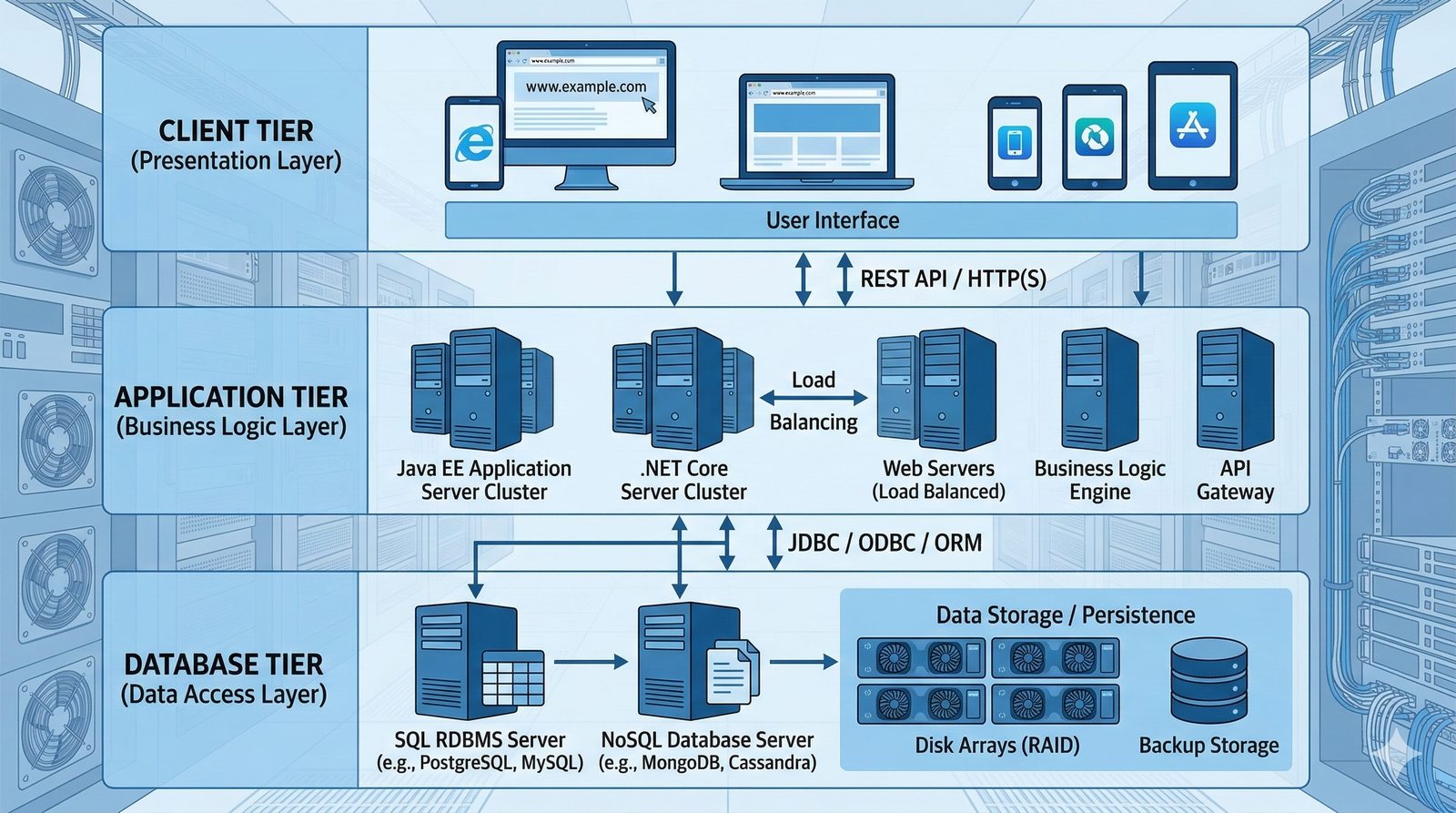
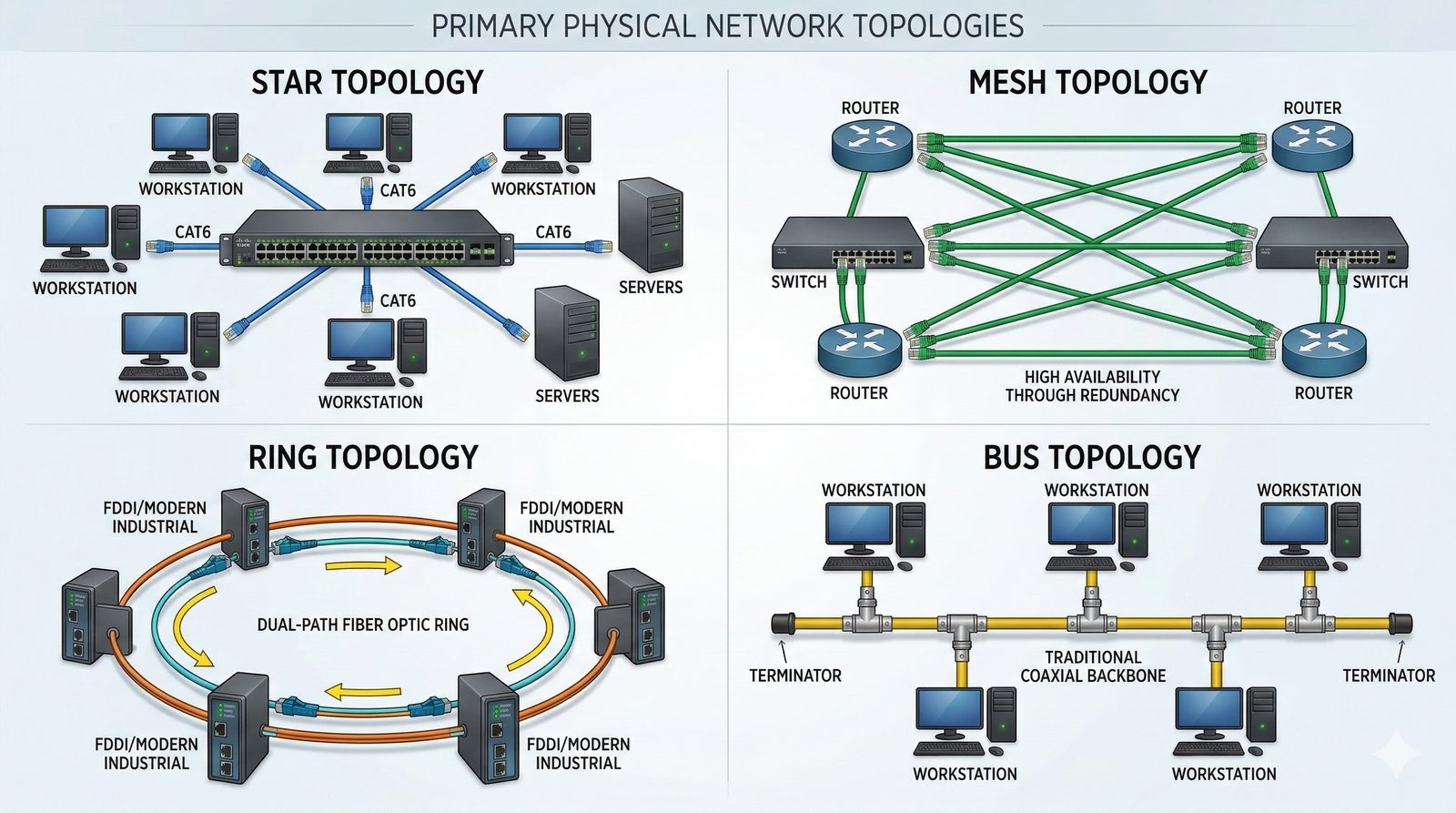
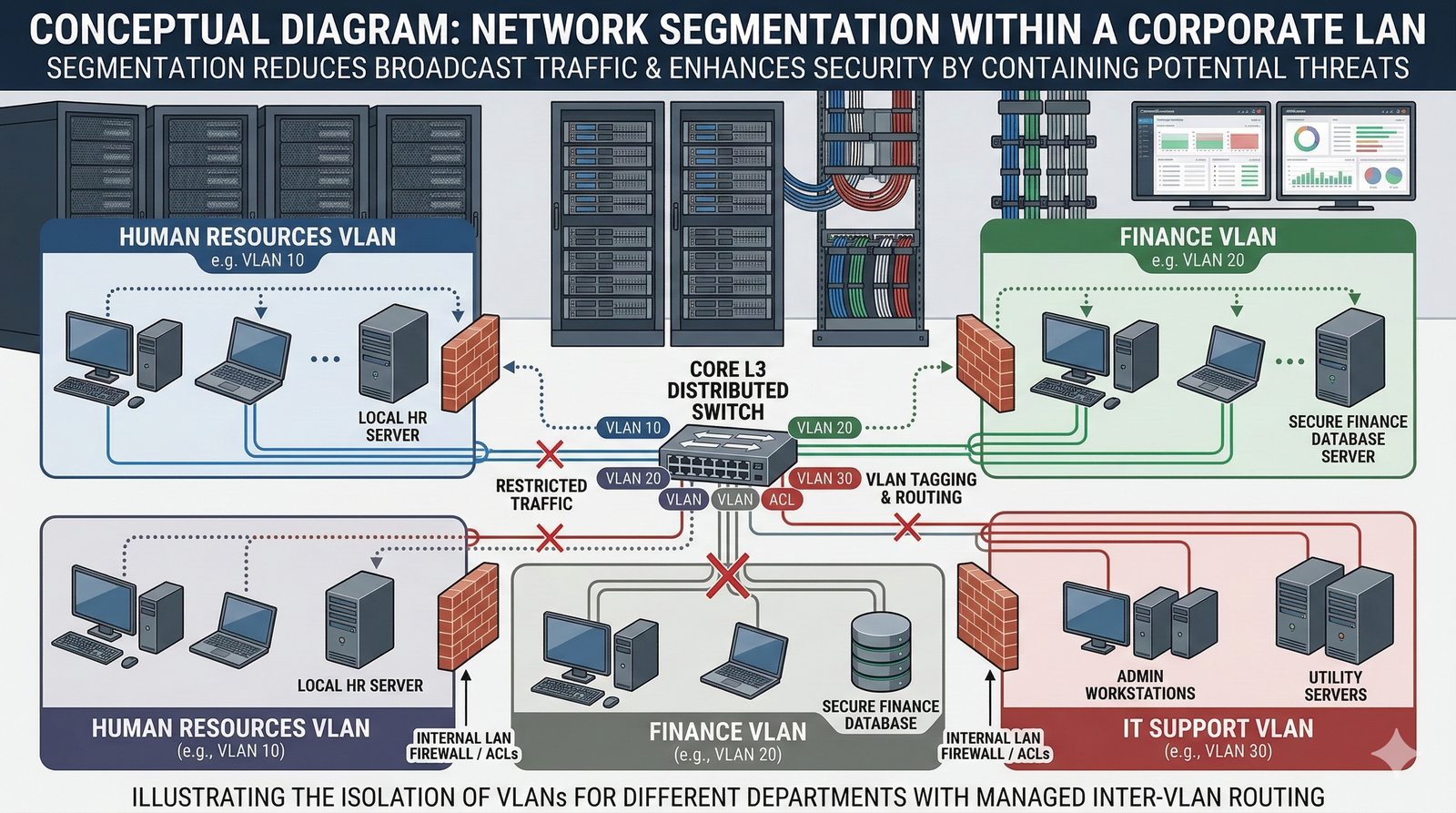
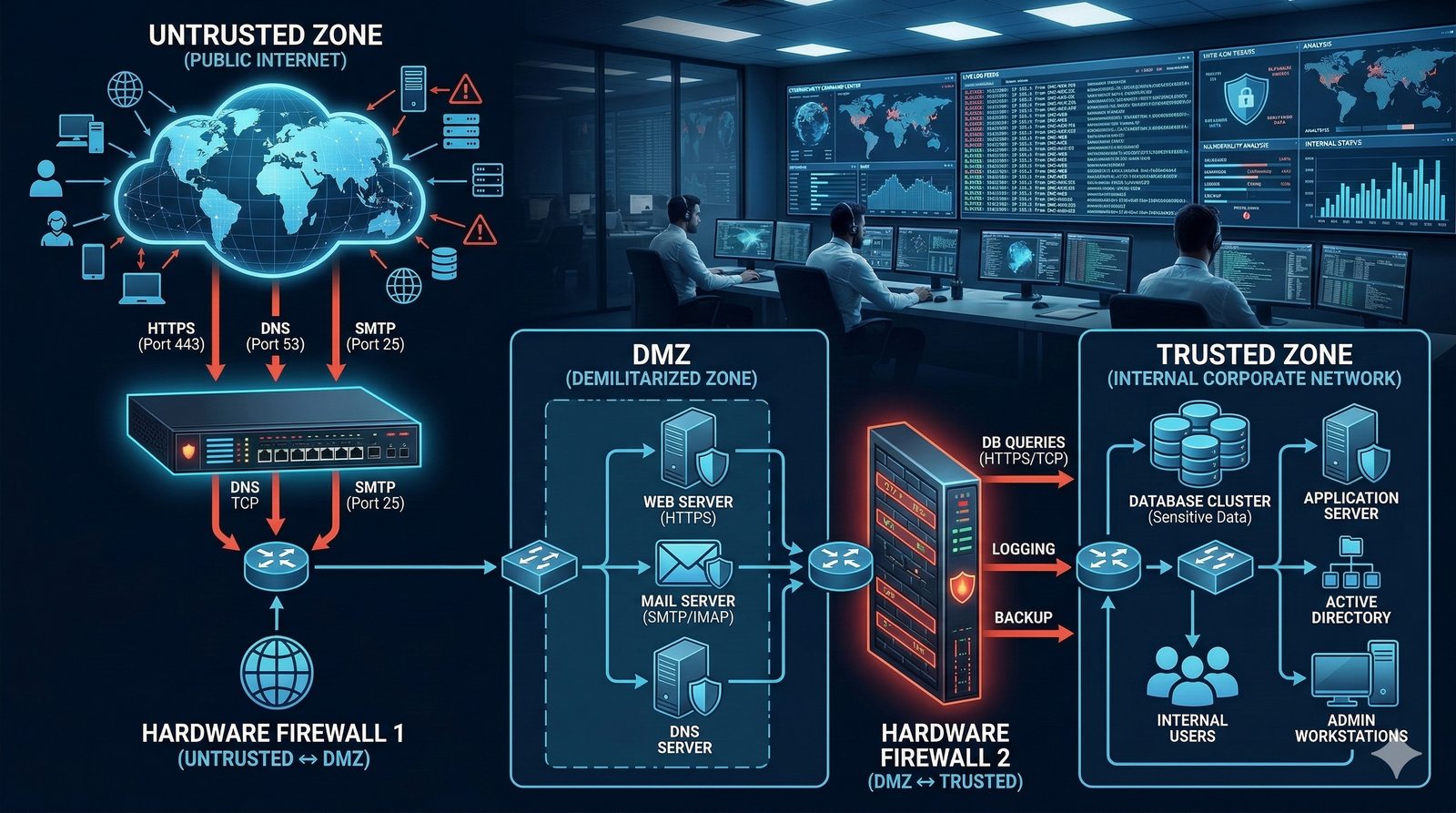
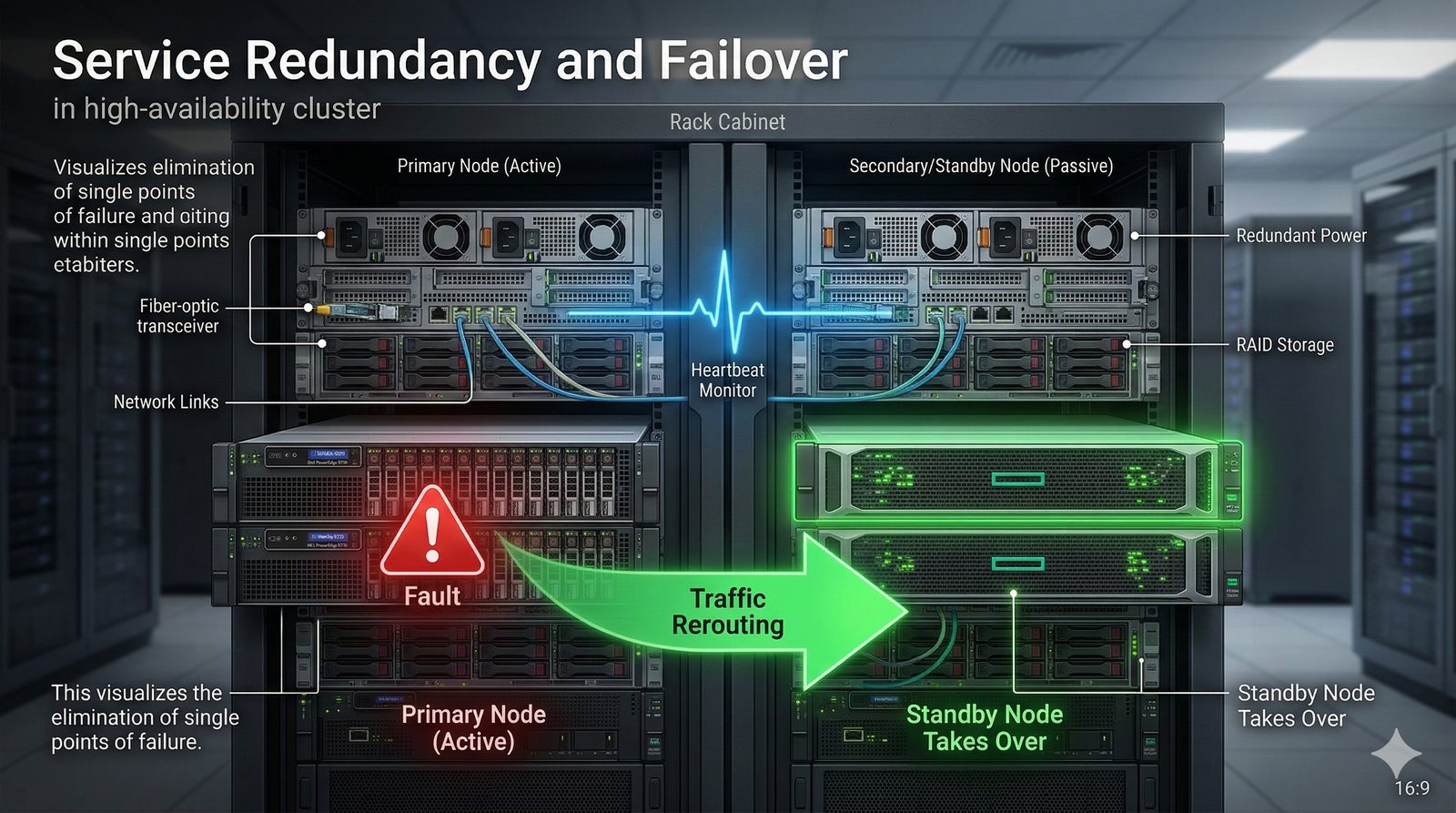
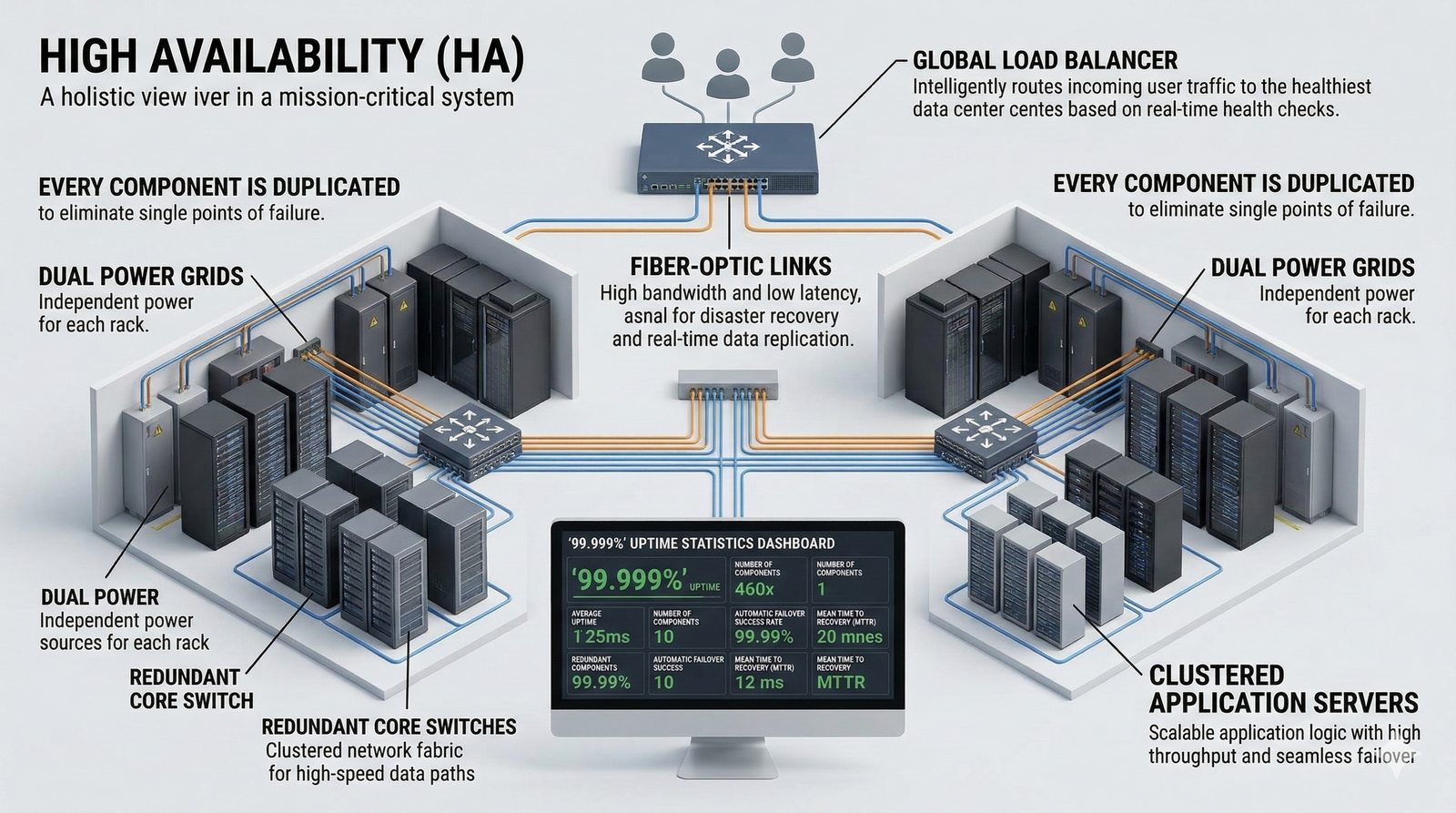
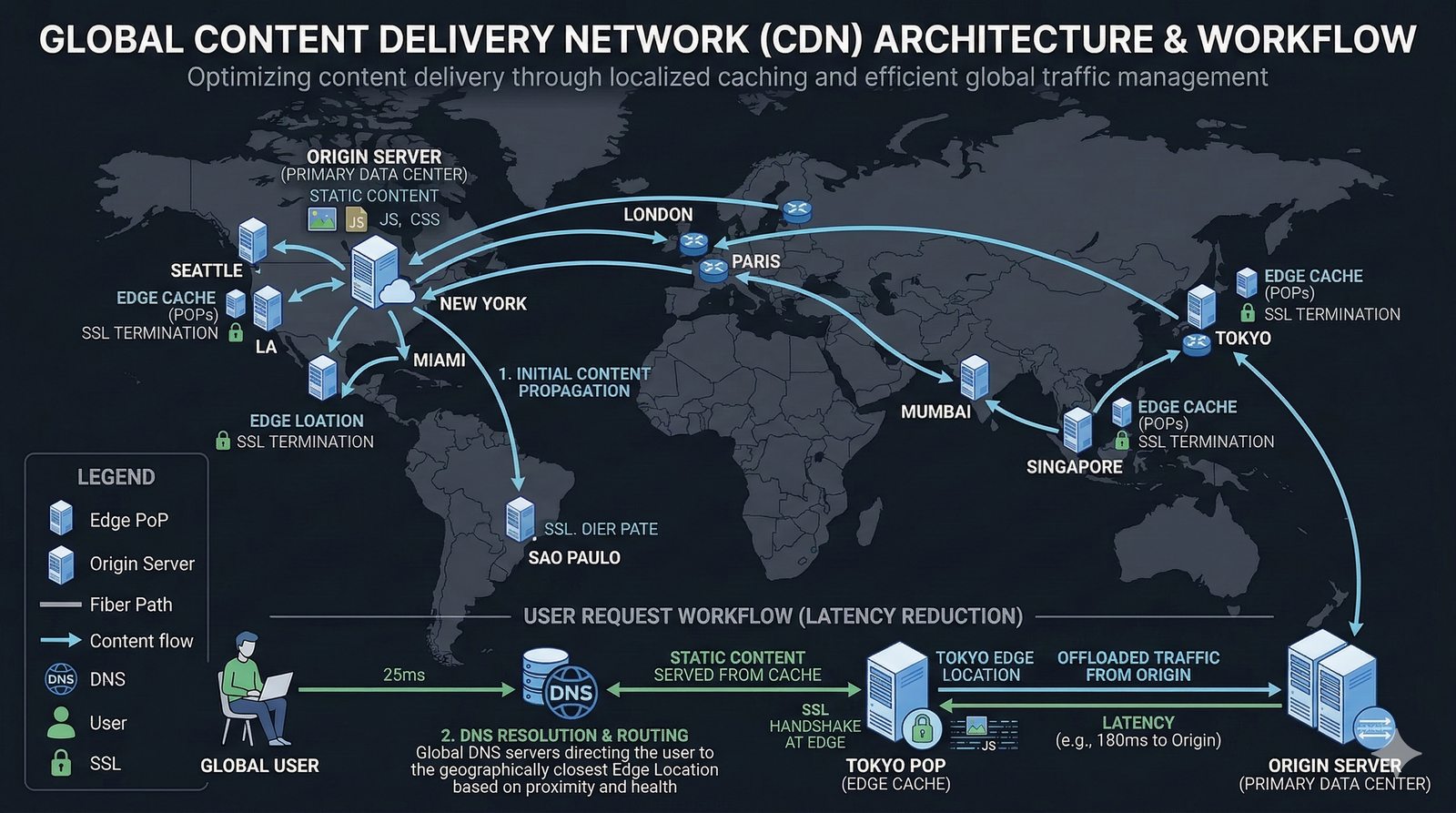
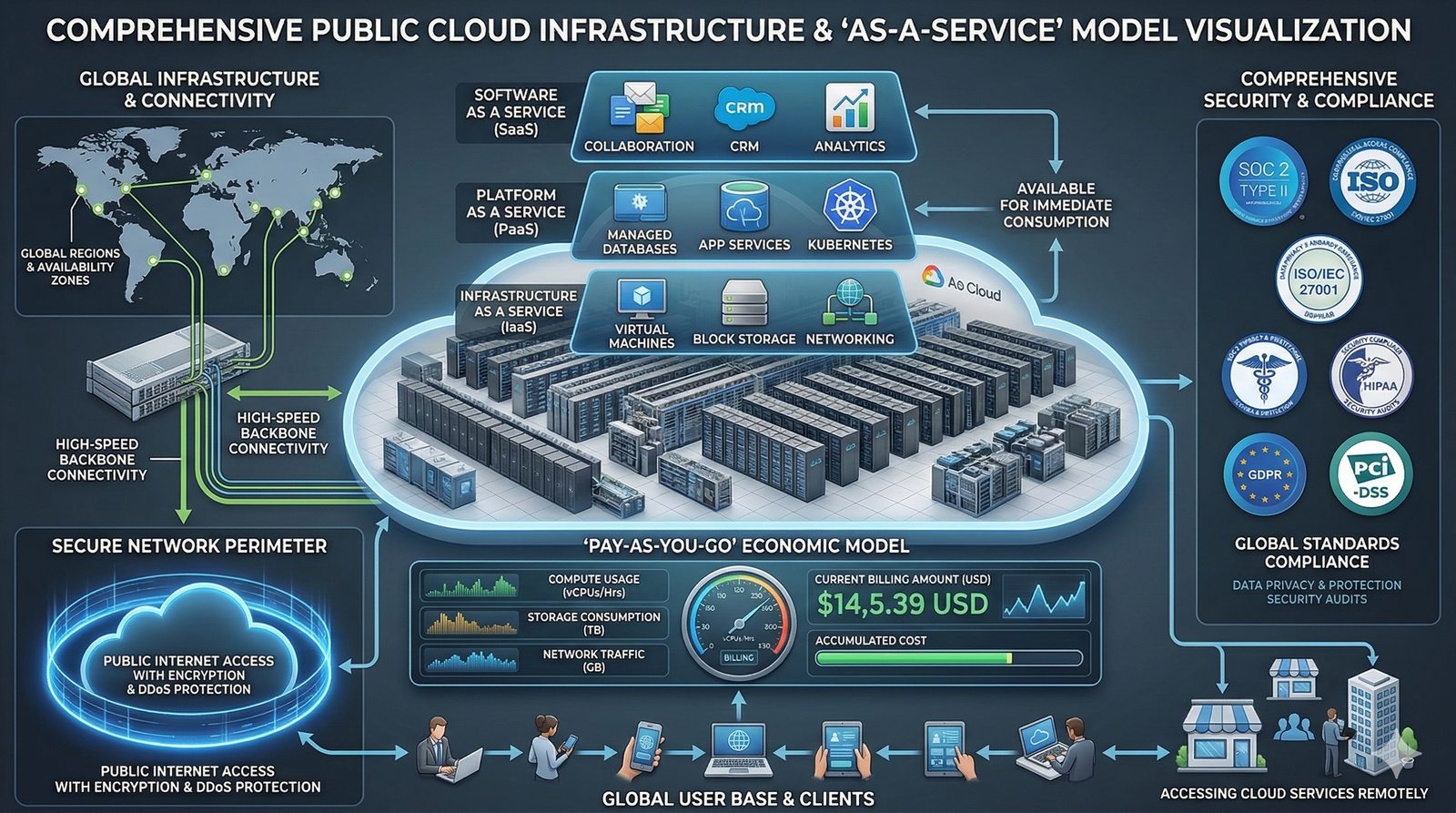
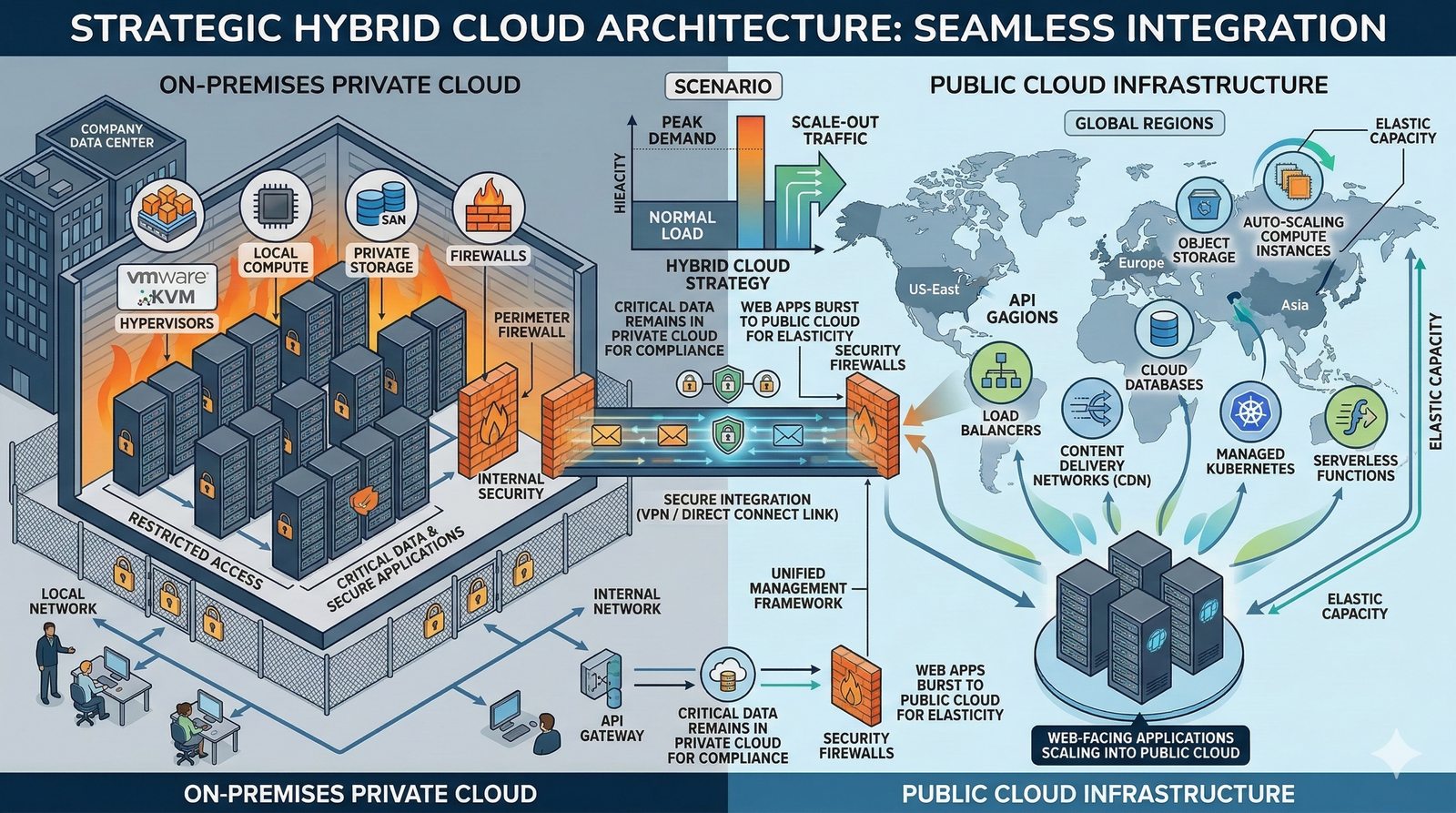
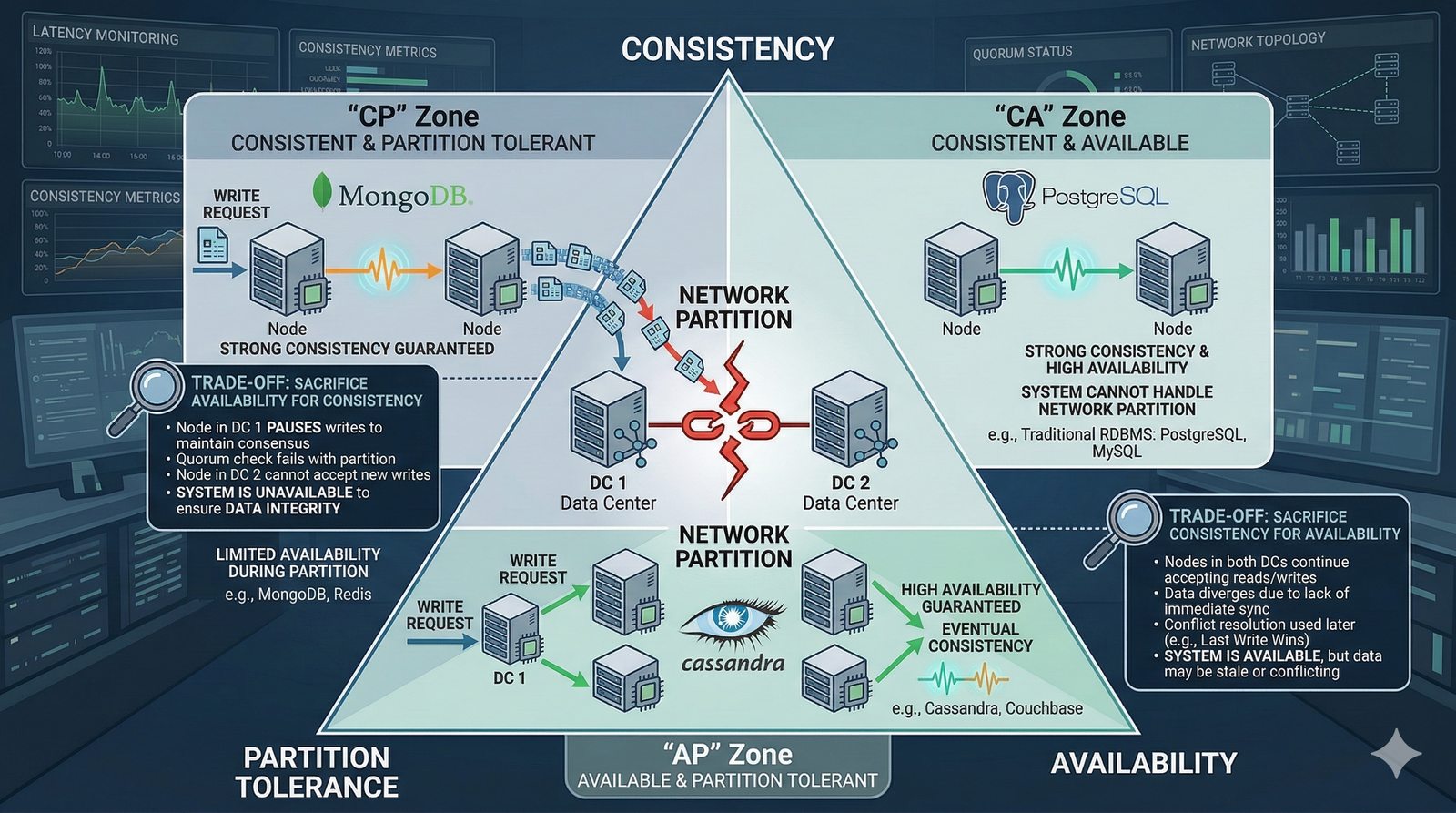
Projektowanie dla dostępności rozpoczyna się od analizy wymagań biznesowych i określenia docelowego poziomu SLA, który musi spełniać system. Na tej podstawie definiuje się architekturę referencyjną, która uwzględnia redundancję na każdym poziomie: geograficznym (wiele regionów), dostępowym (wielu dostawców usług internetowych), sieciowym (redundantne przełączniki i routery), obliczeniowym (klastry serwerów) i danych (repliki baz danych). Każdy z tych poziomów musi być zaprojektowany w taki sposób, aby awaria pojedynczego elementu nie wpływała na ogólną dostępność systemu.
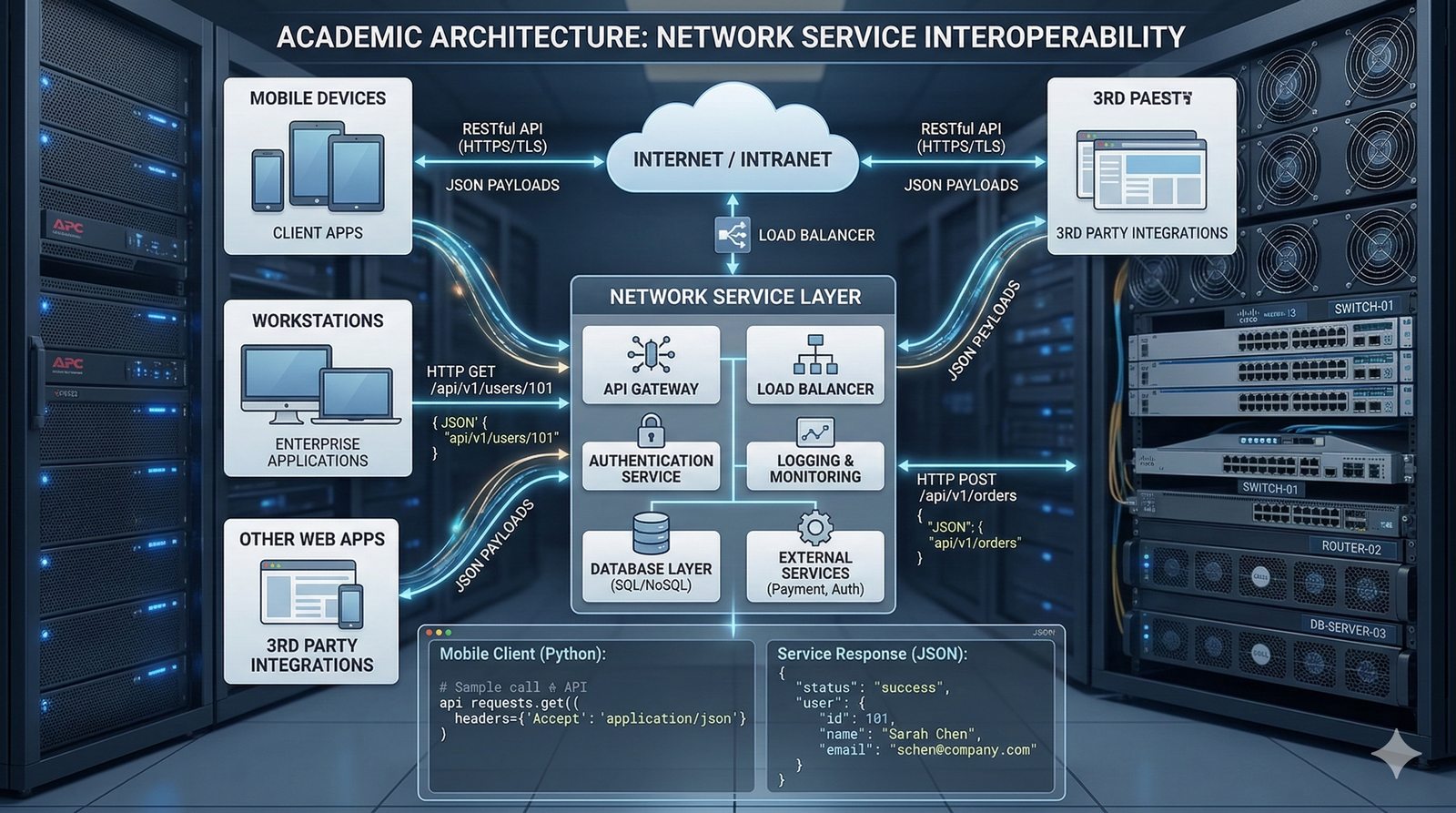
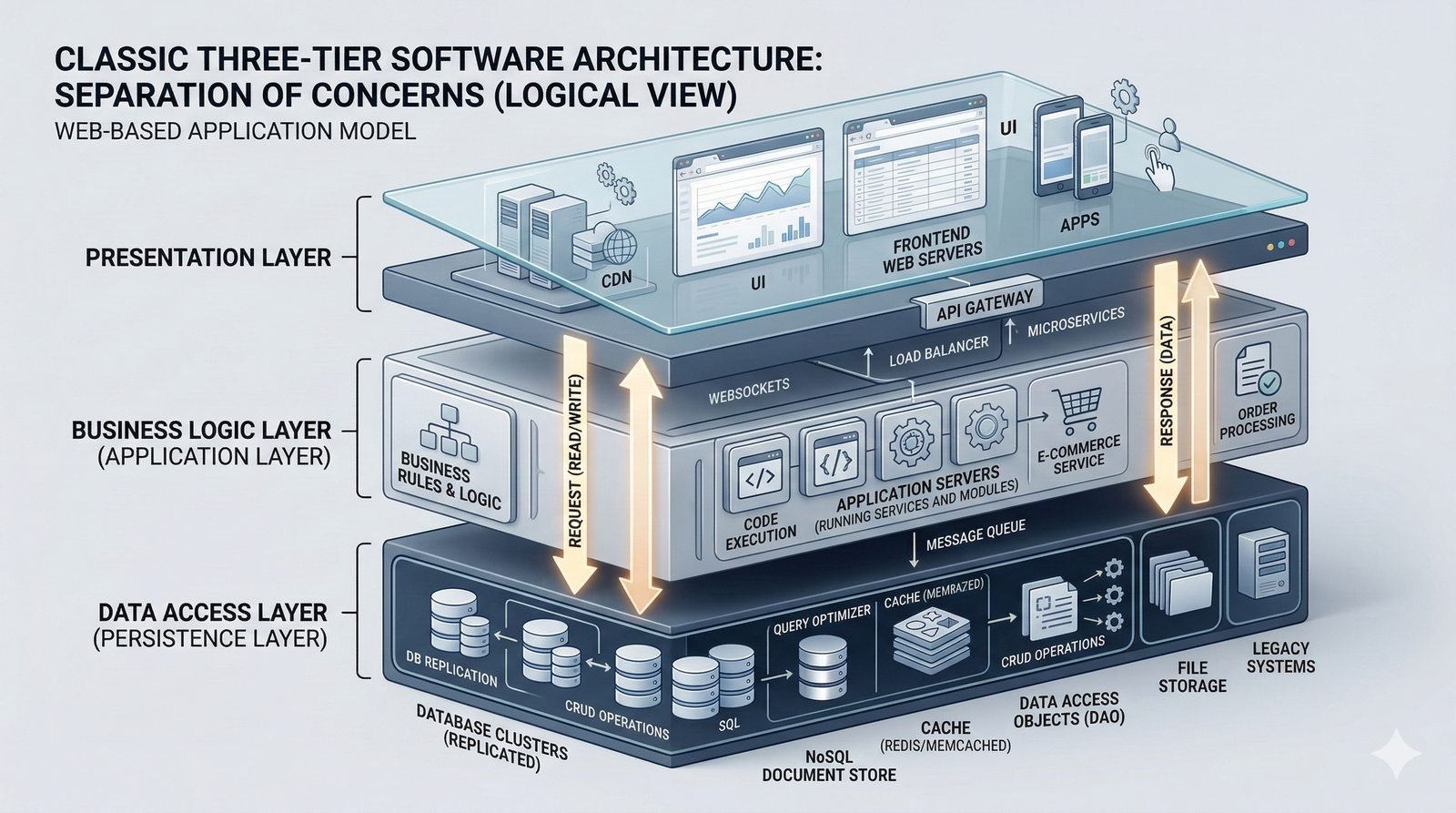
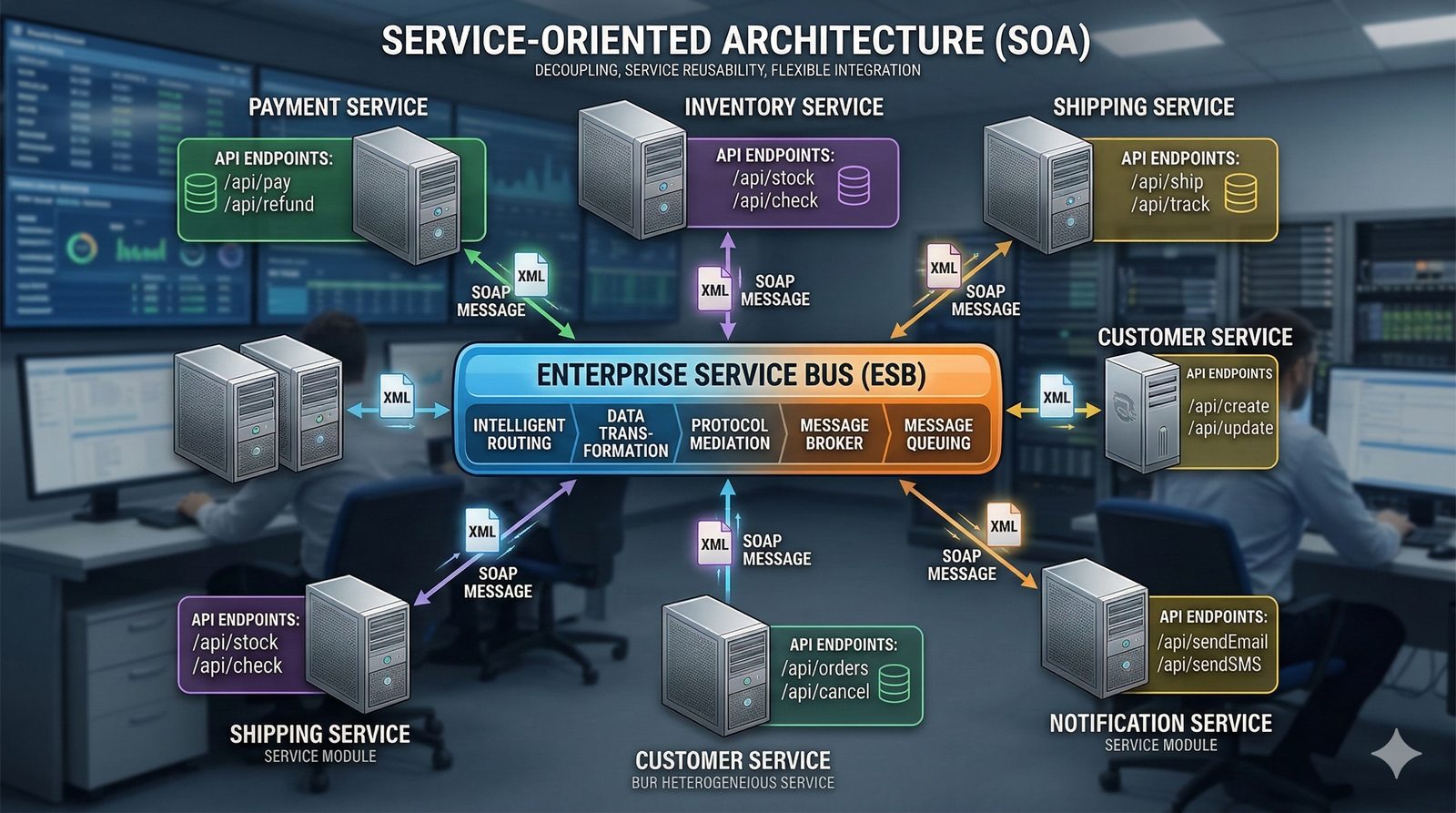
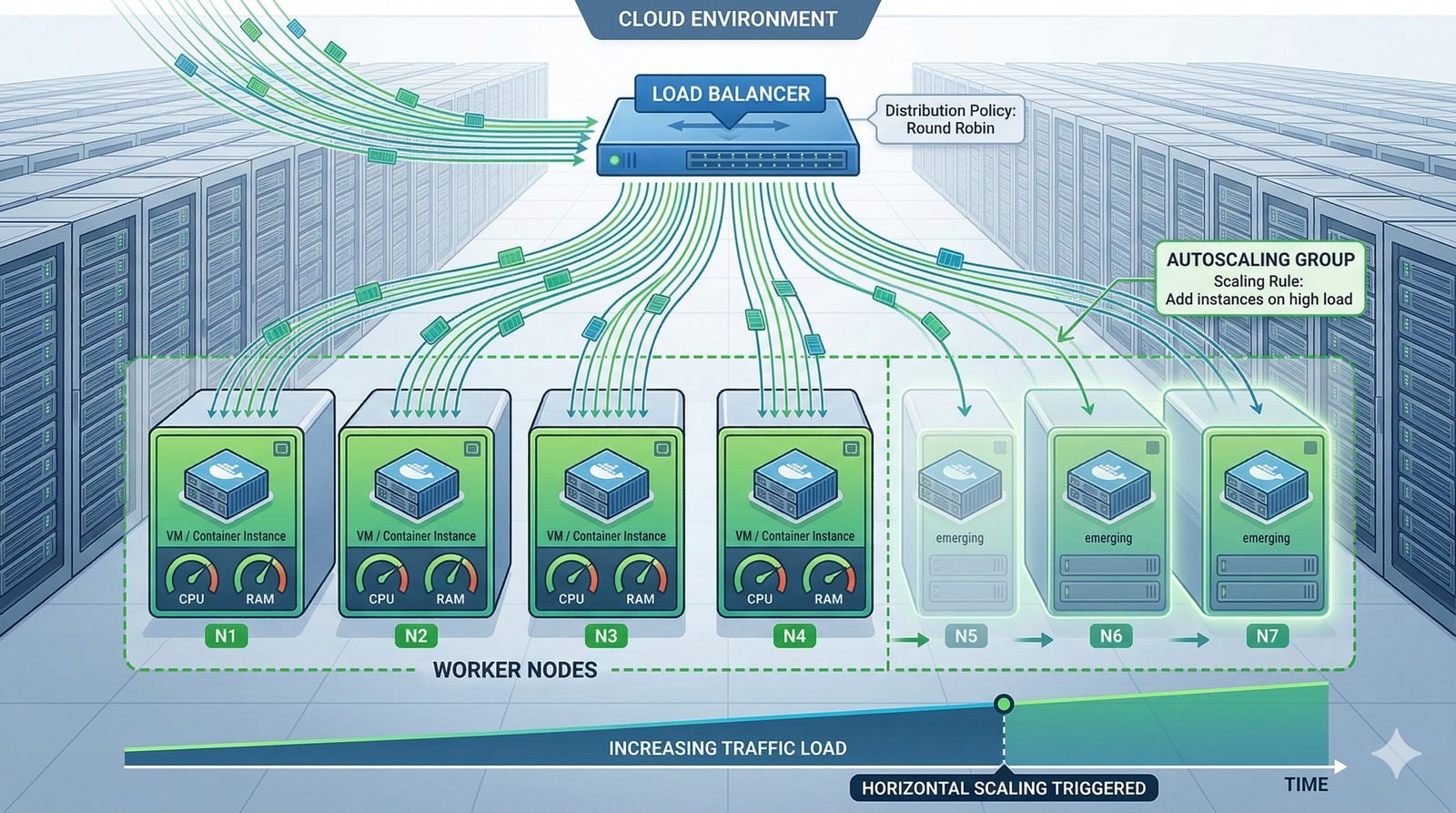
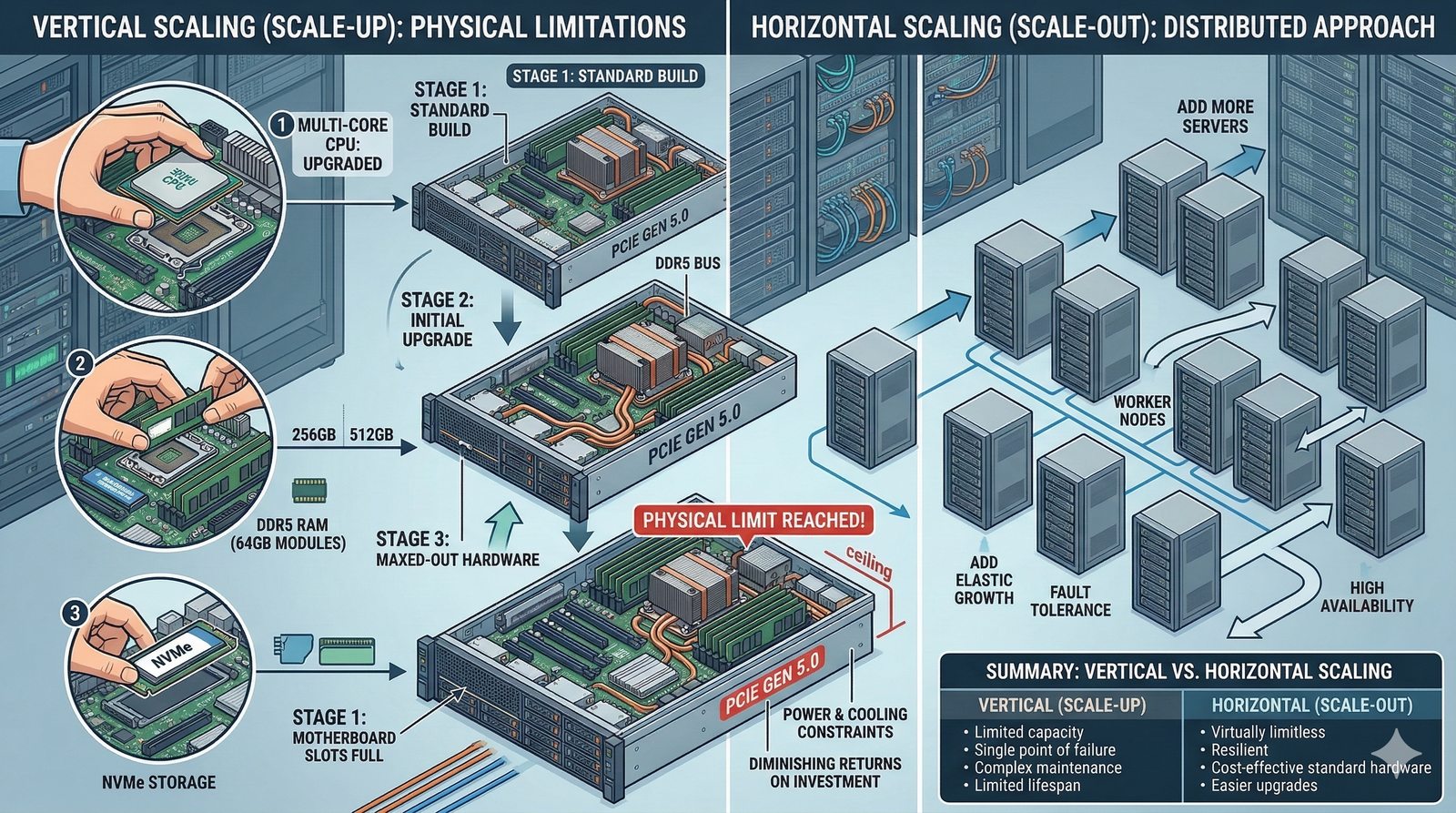
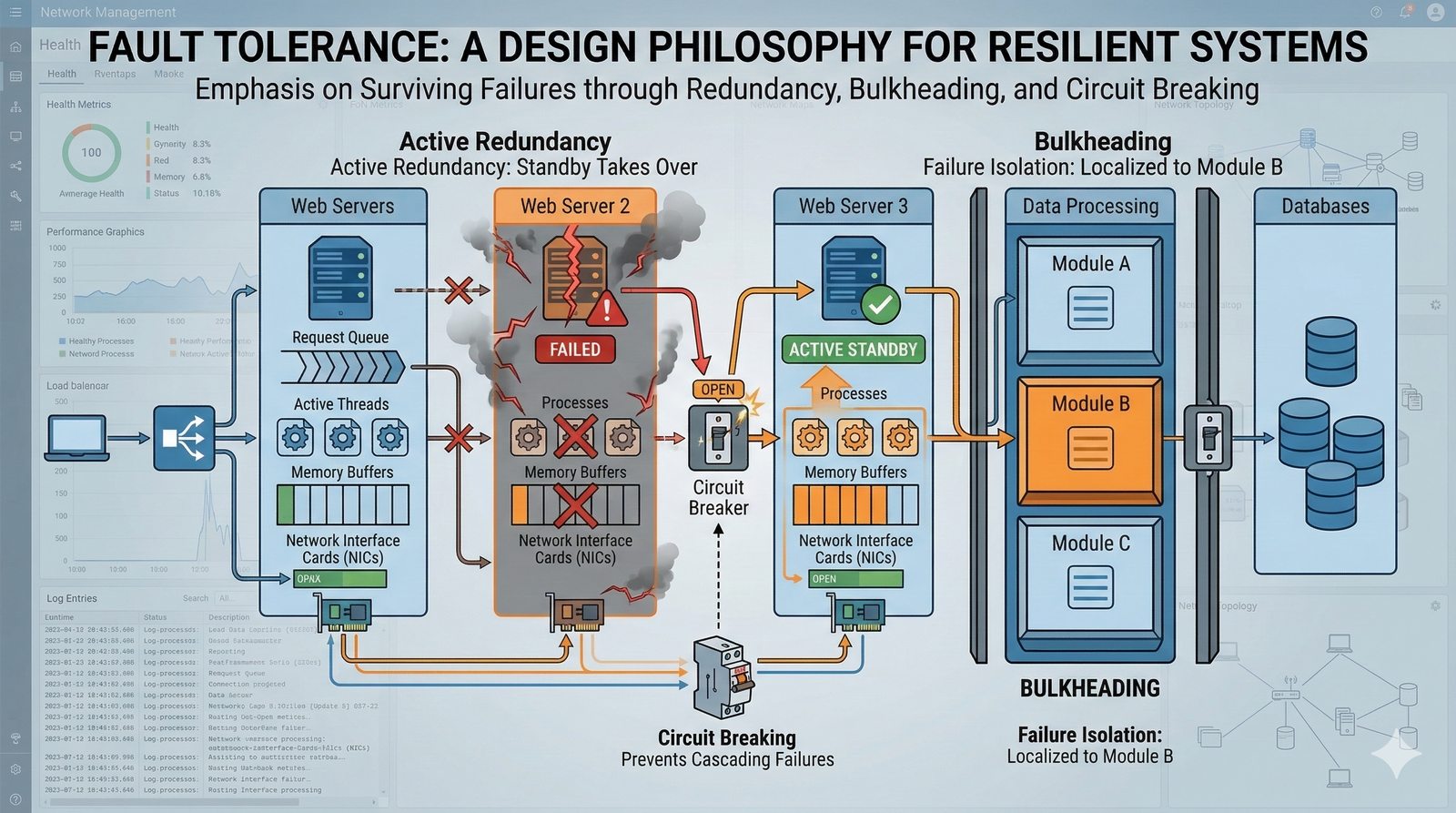
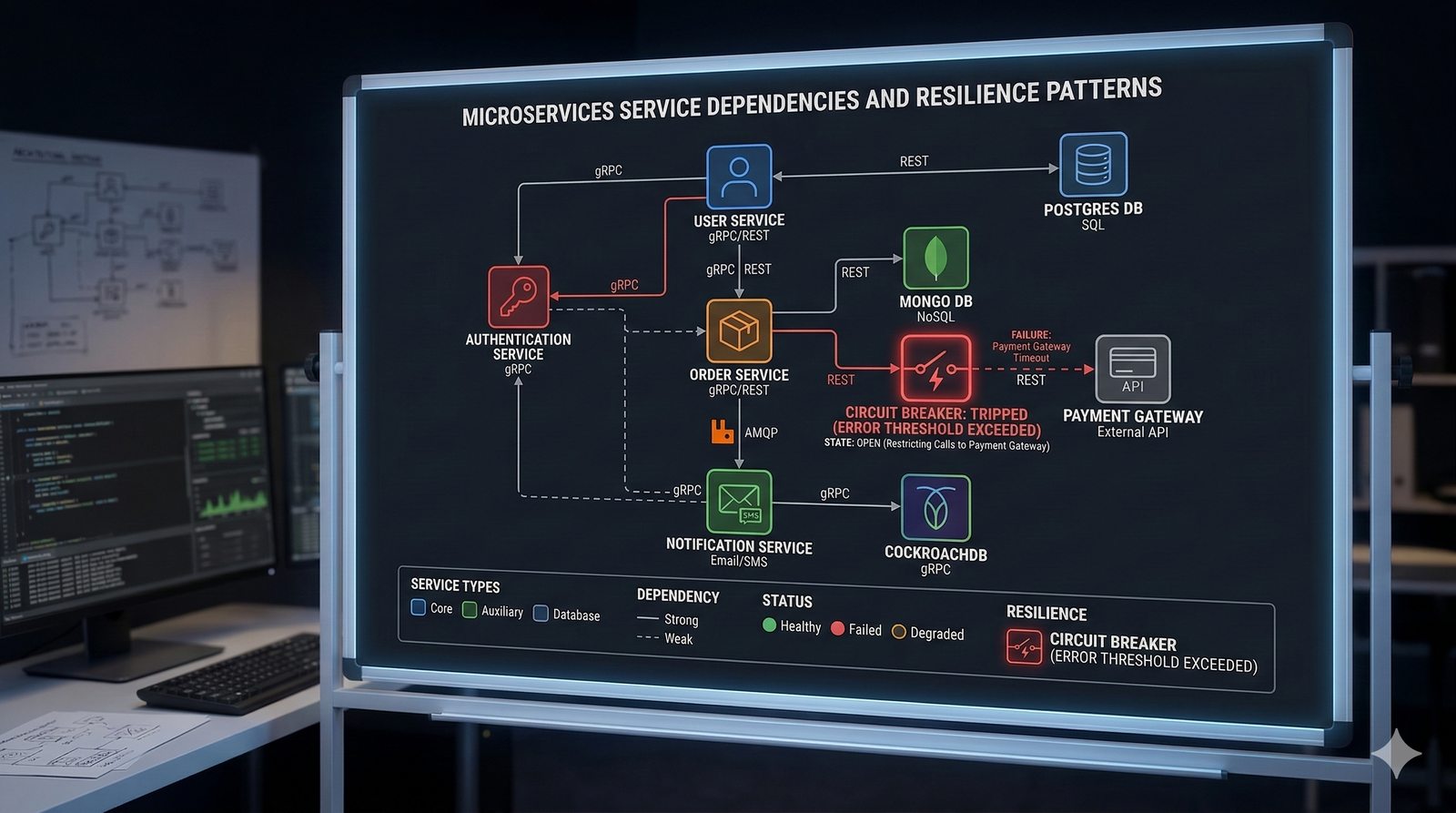
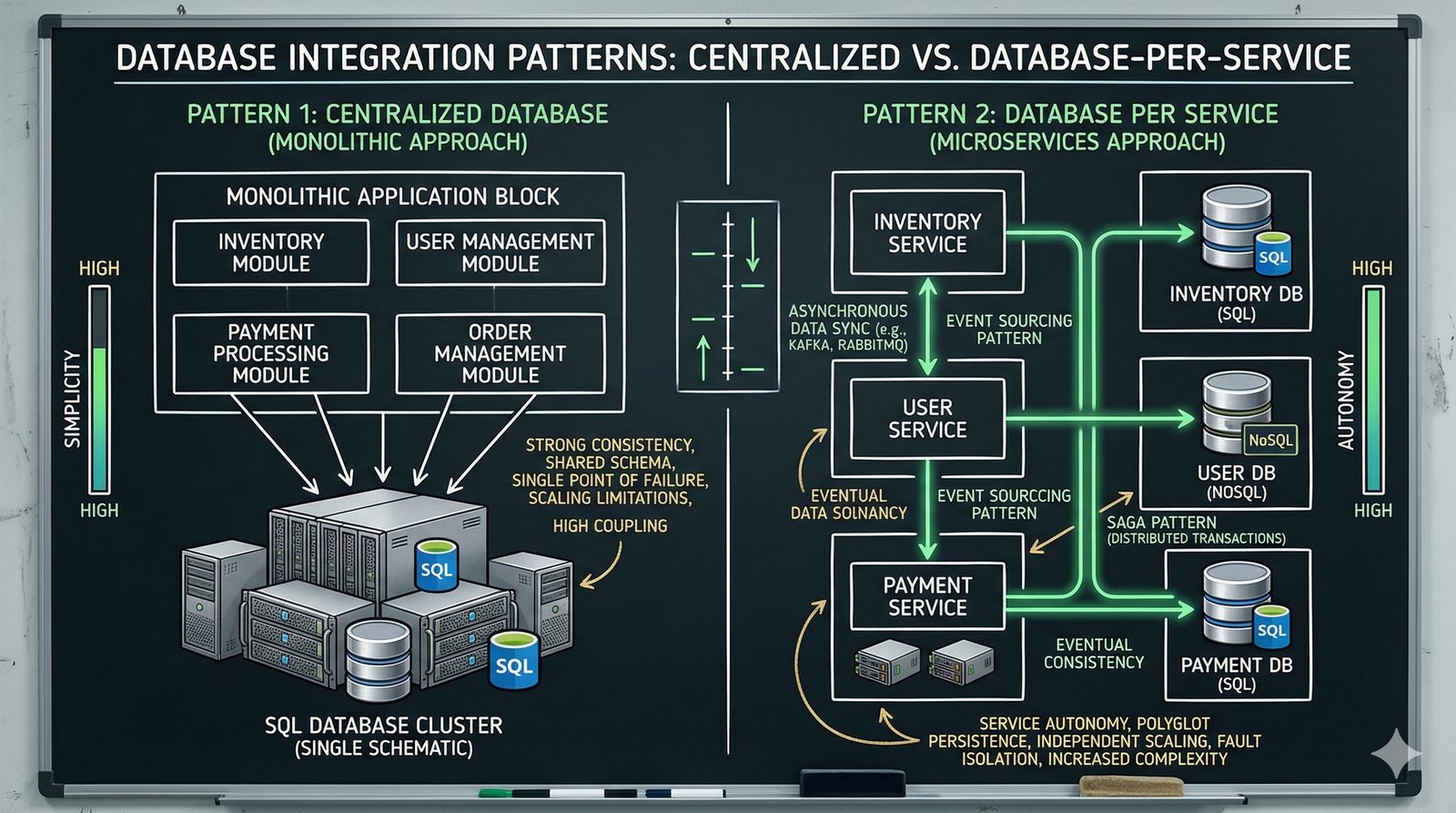
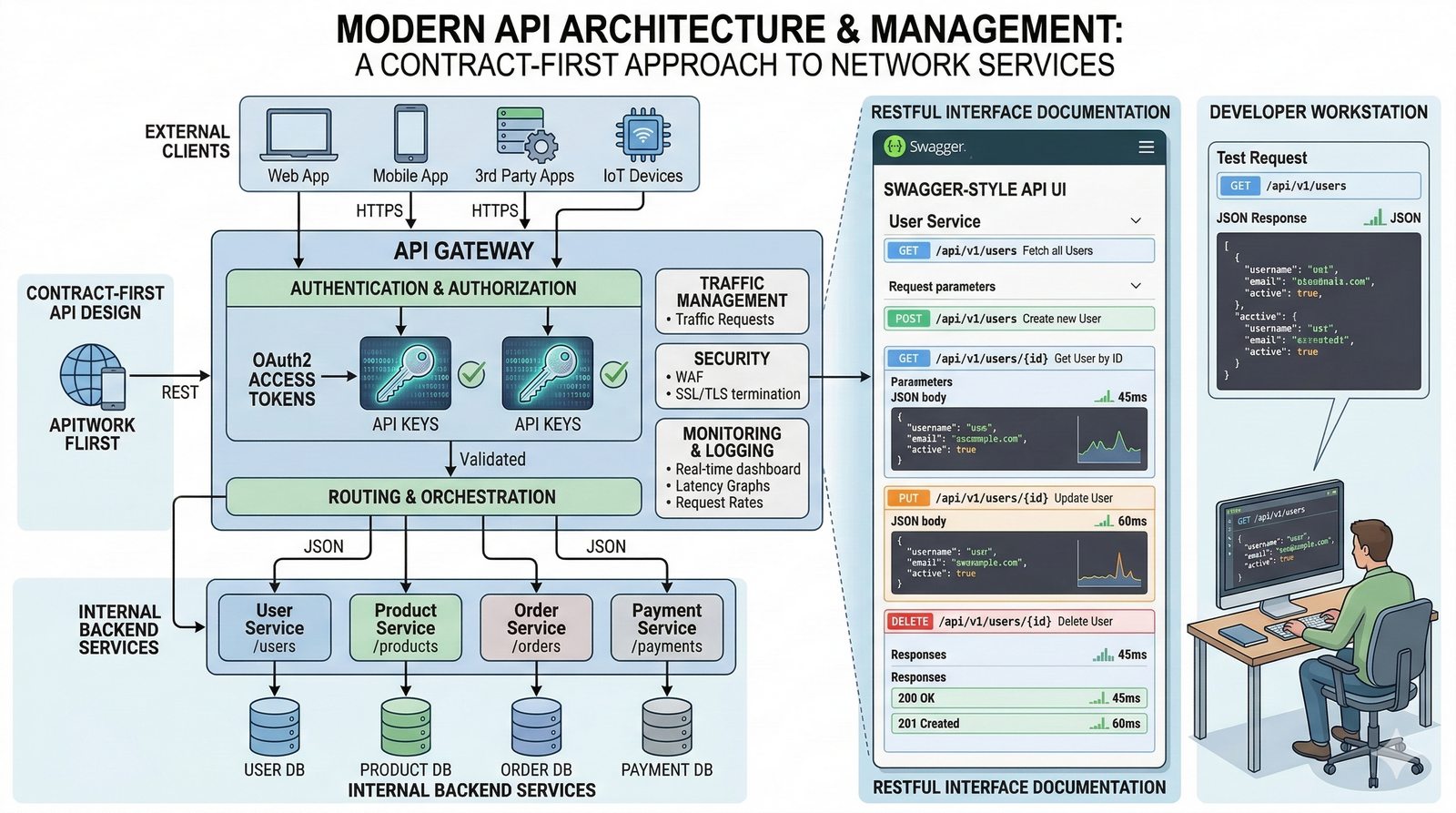
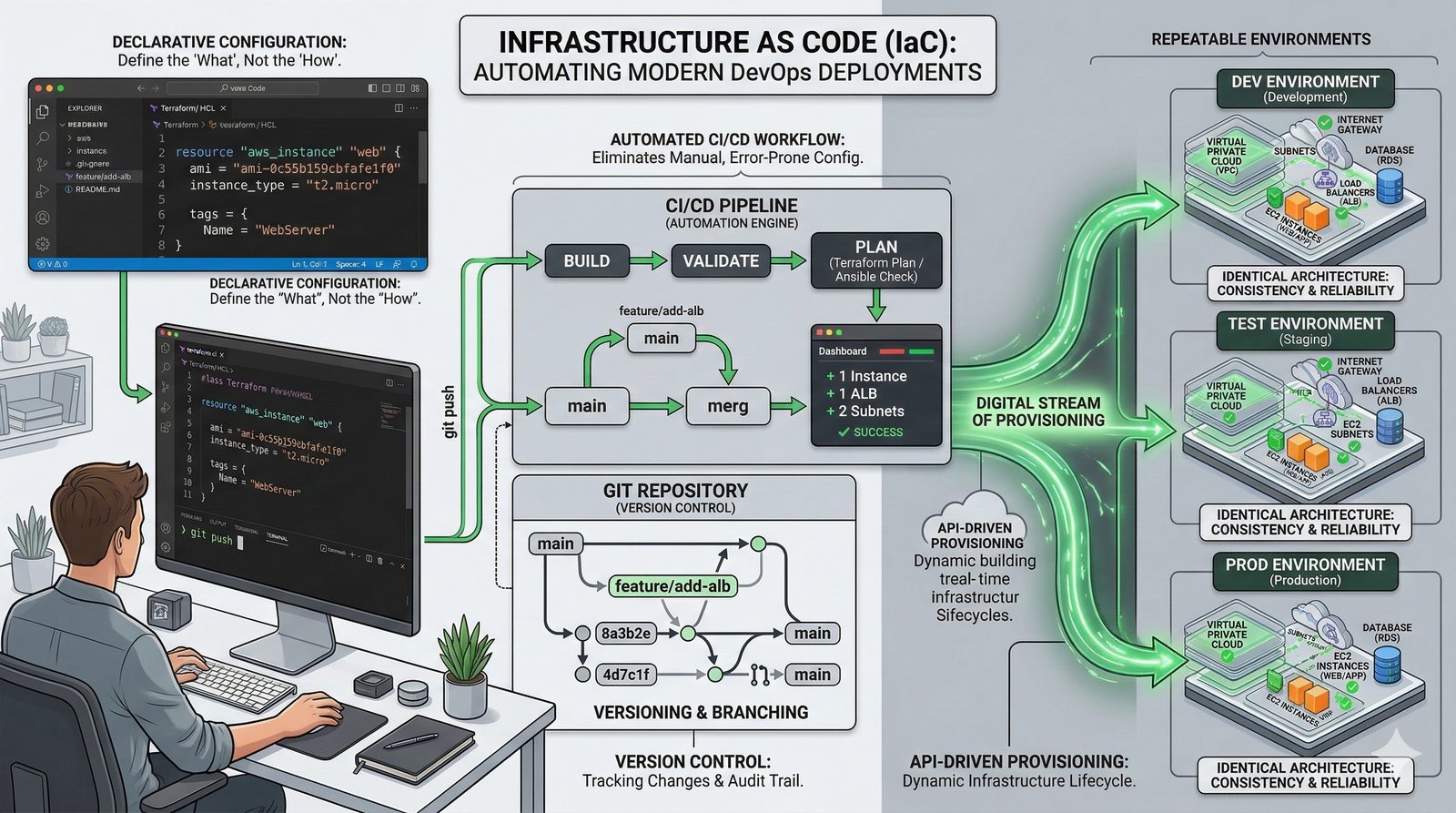
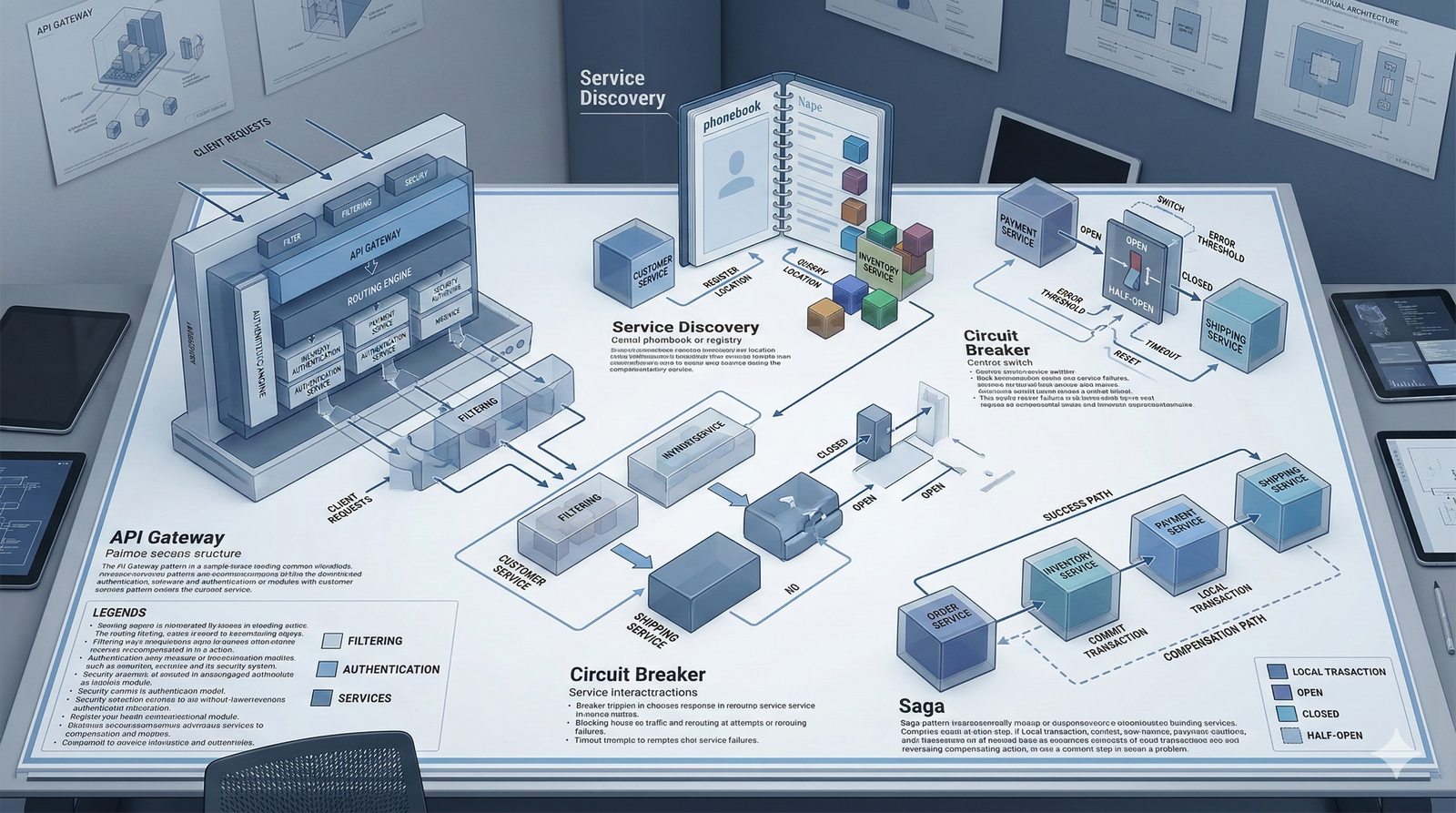
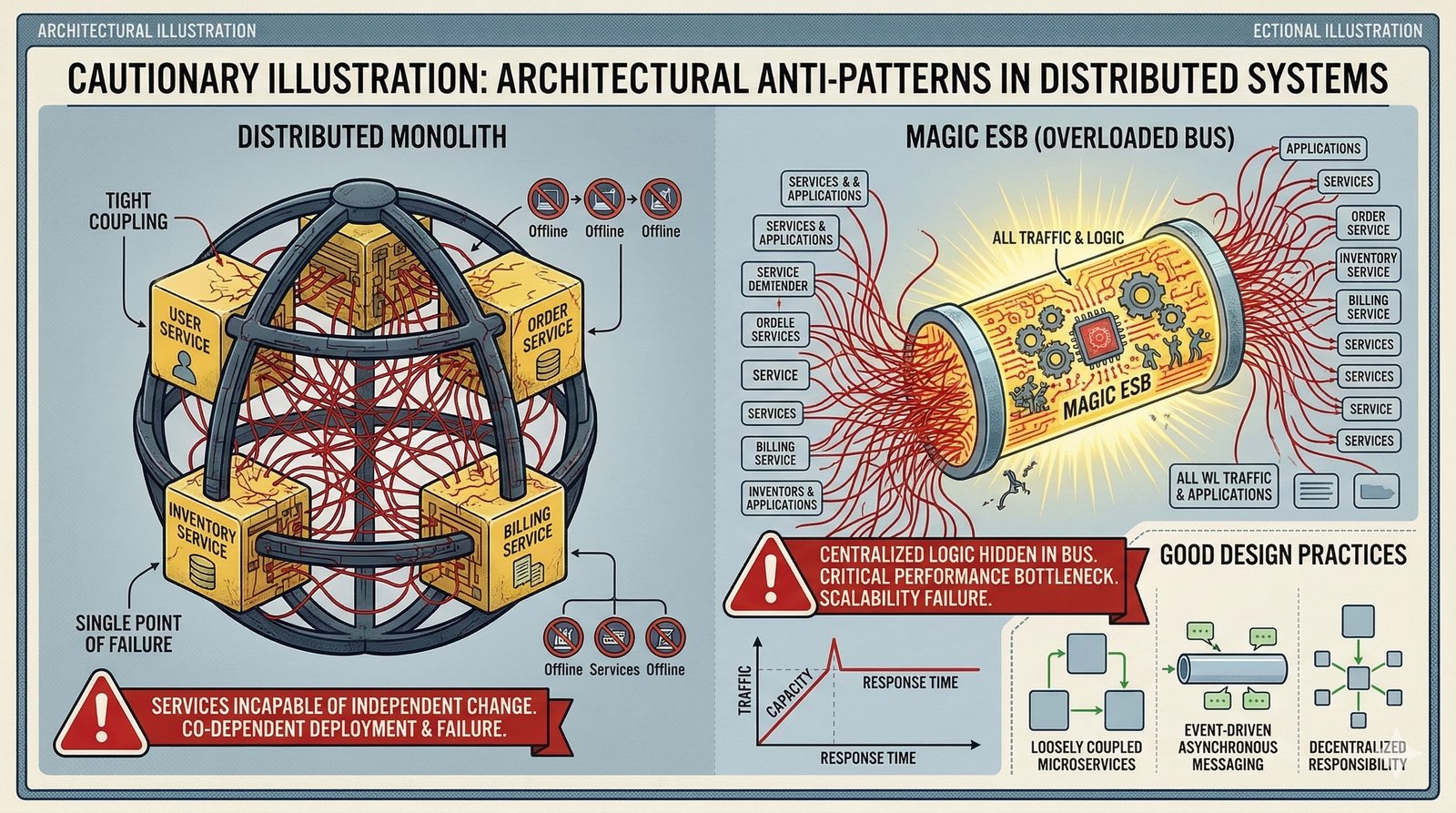
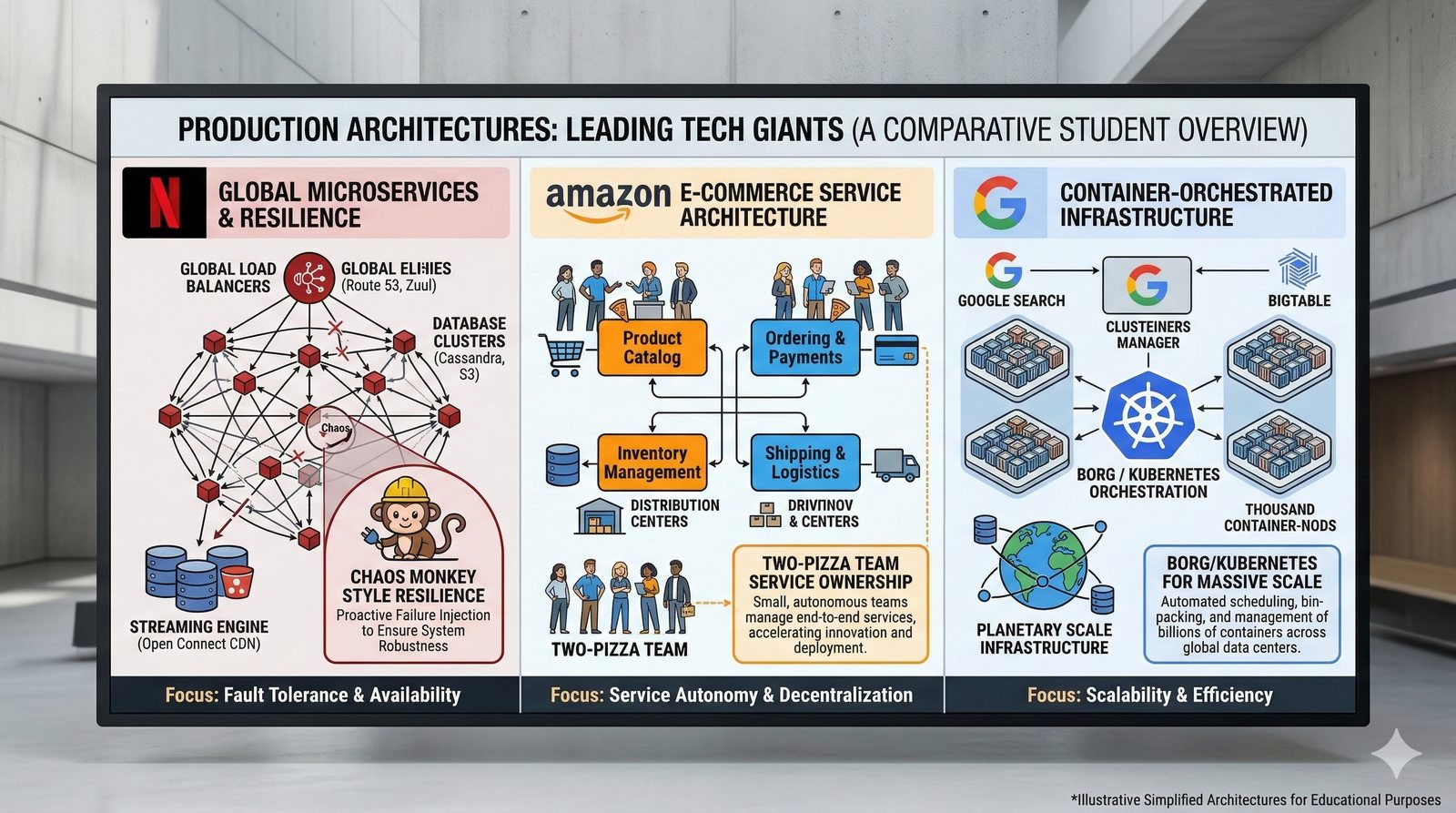
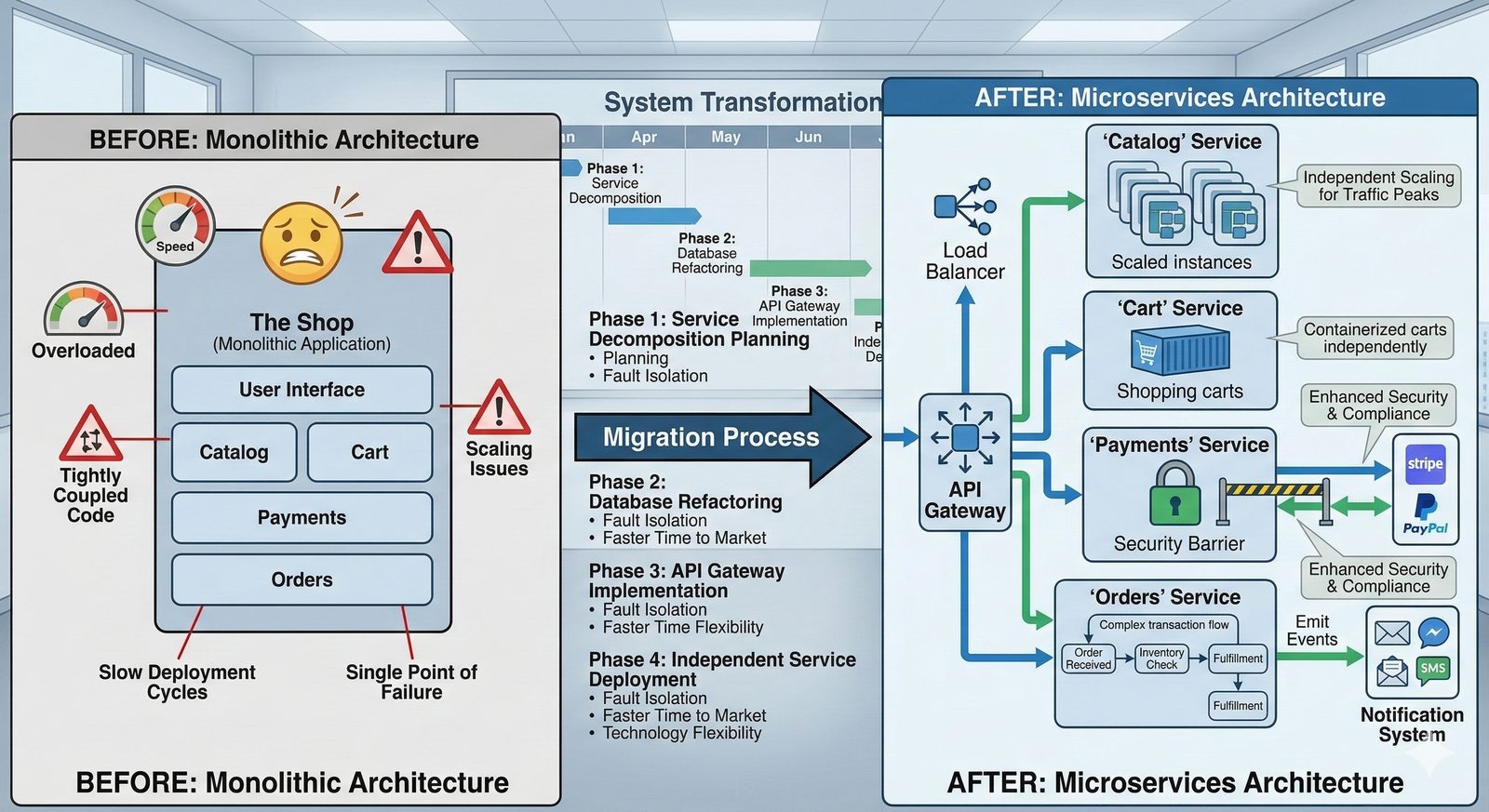
W nowoczesnych systemach kluczowym aspektem projektowania dla dostępności jest wykorzystanie architektury mikroserwisowej z dekompozycją na małe, niezależne jednostki, które mogą być wdrażane i skalowane oddzielnie. Należy unikać wspólnych zasobów, takich jak centralne bazy danych czy monolityczne kolejki, które stają się wąskimi gardłami i pojedynczymi punktami awarii. Zamiast tego stosuje się podejście database-per-service, asynchroniczną komunikację przez kolejki zdarzeń i sagi do zarządzania transakcjami rozproszonymi, co zapewnia izolację awarii i autonomię poszczególnych usług.
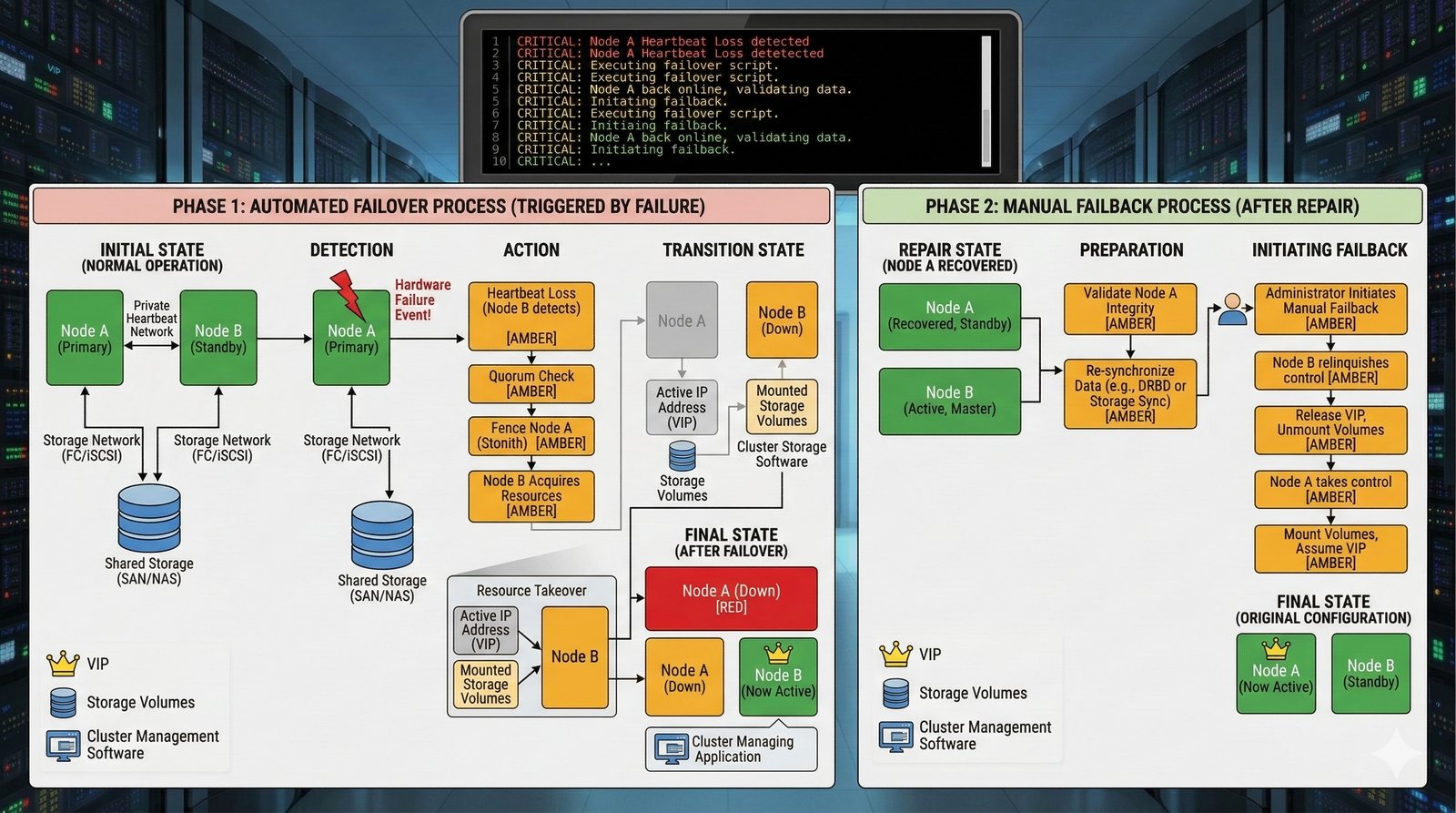
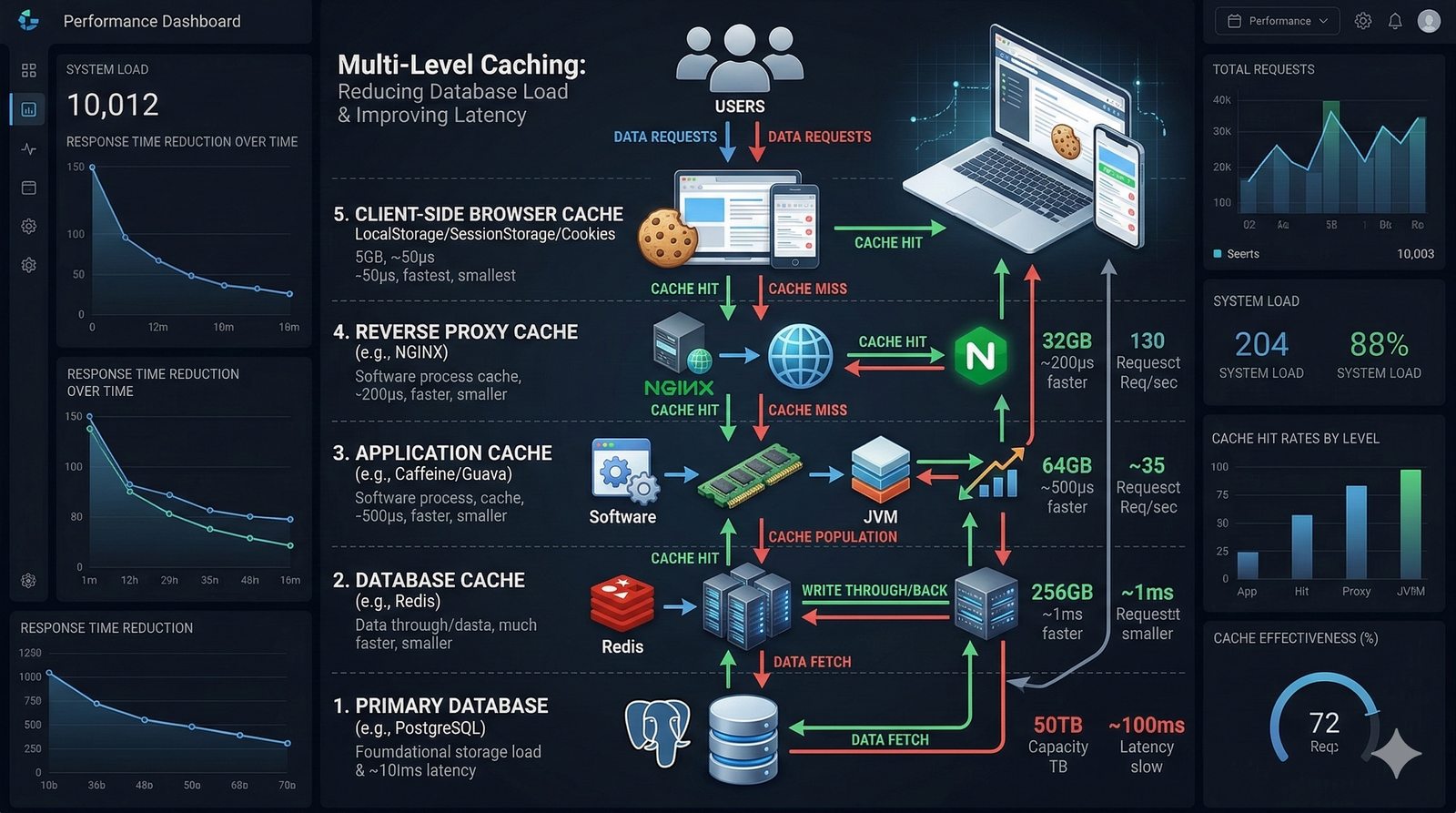
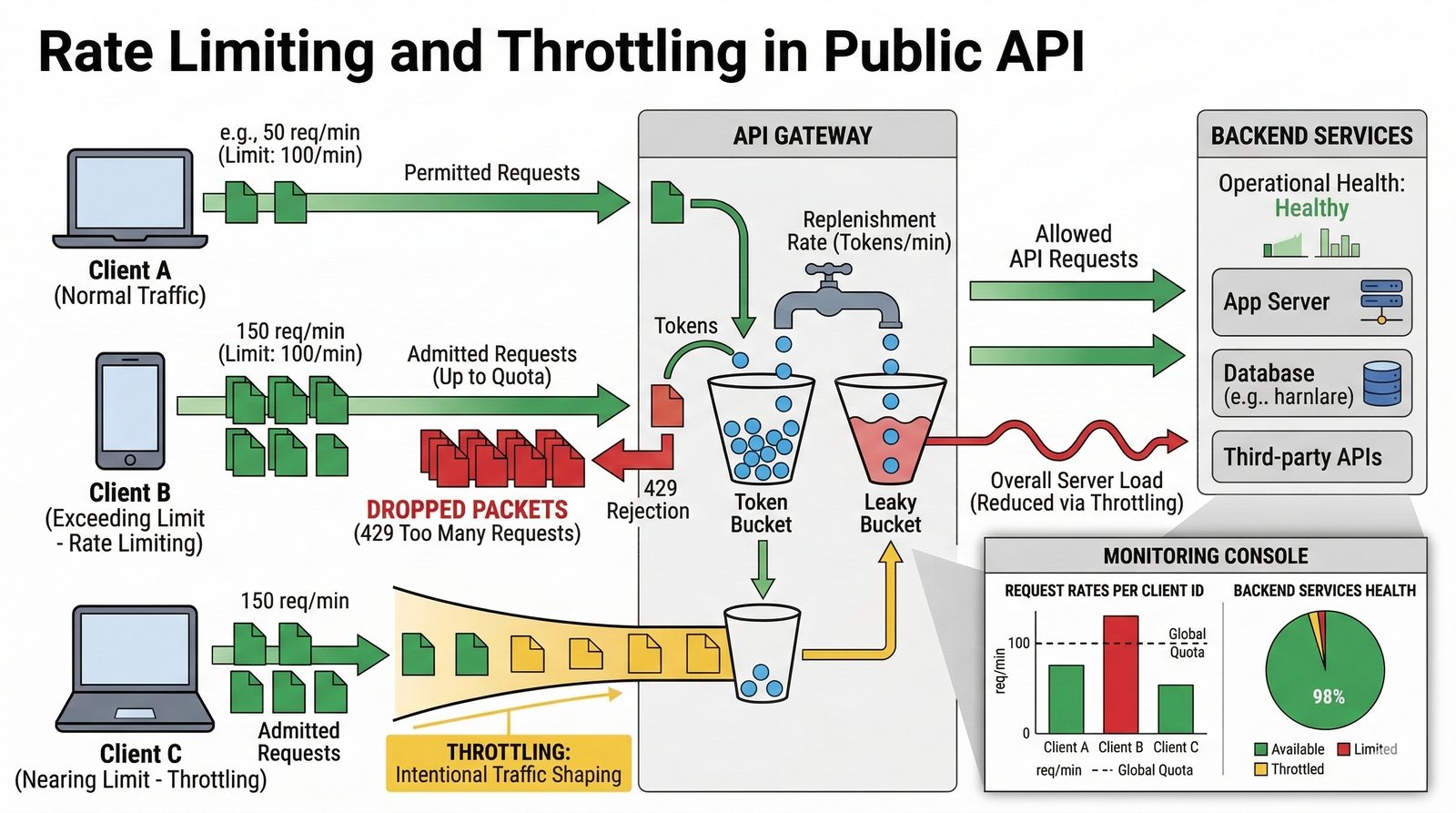
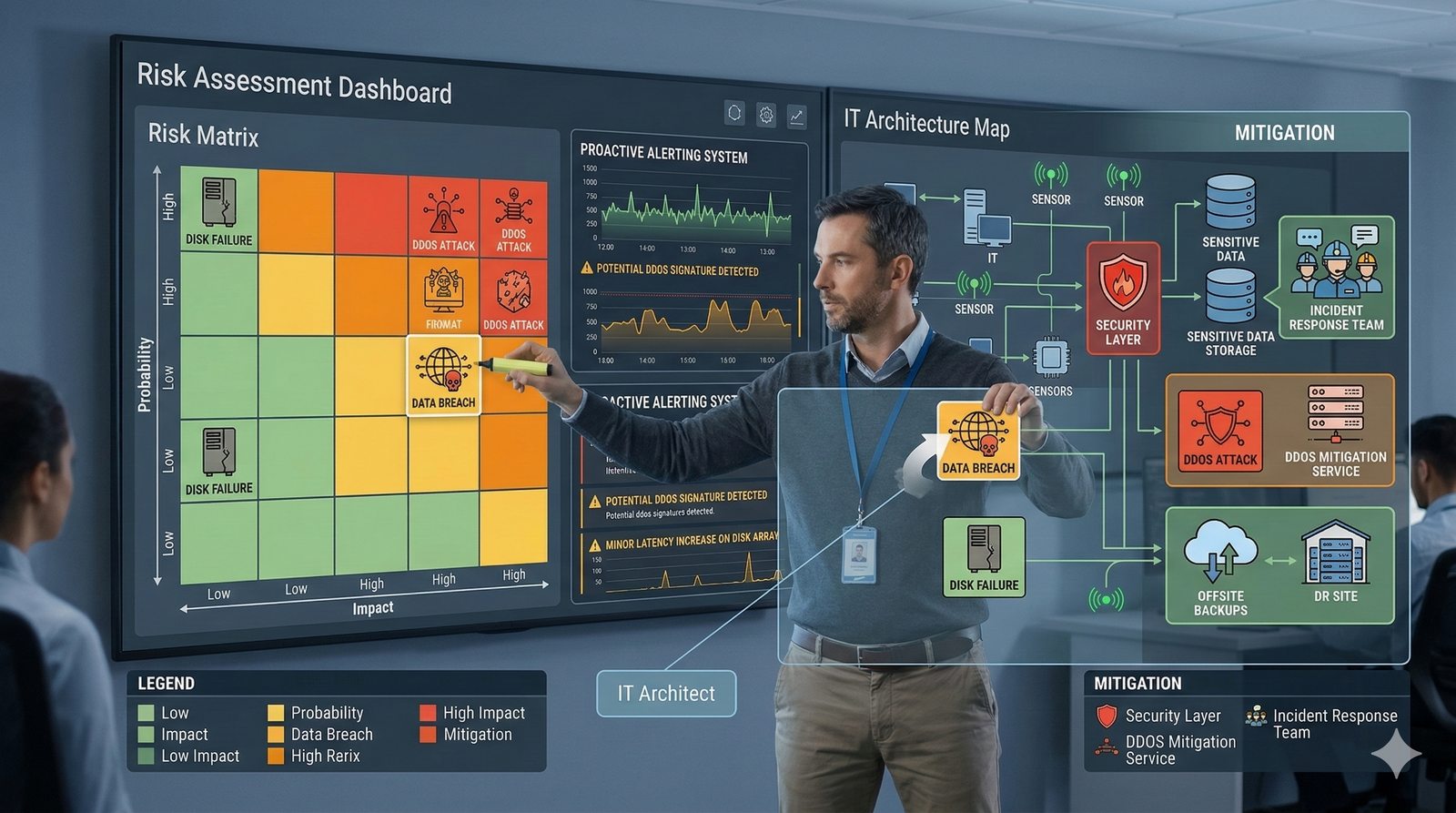
Nieodzownym elementem projektowania dla dostępności jest wdrożenie kompleksowego systemu monitoringu i alertowania, który obejmuje zarówno metryki infrastrukturalne (CPU, pamięć, dysk, sieć), jak i metryki aplikacyjne (czas odpowiedzi, liczba błędów, przepustowość). Narzędzia takie jak Prometheus, Grafana, ELK Stack czy Datadog umożliwiają wizualizację trendów i szybkie wykrywanie anomalii. Dodatkowo wdrożenie mechanizmów self-healing, które automatycznie restartują uszkodzone procesy lub instancje, pozwala na minimalizację czasu przestoju bez konieczności interwencji człowieka.