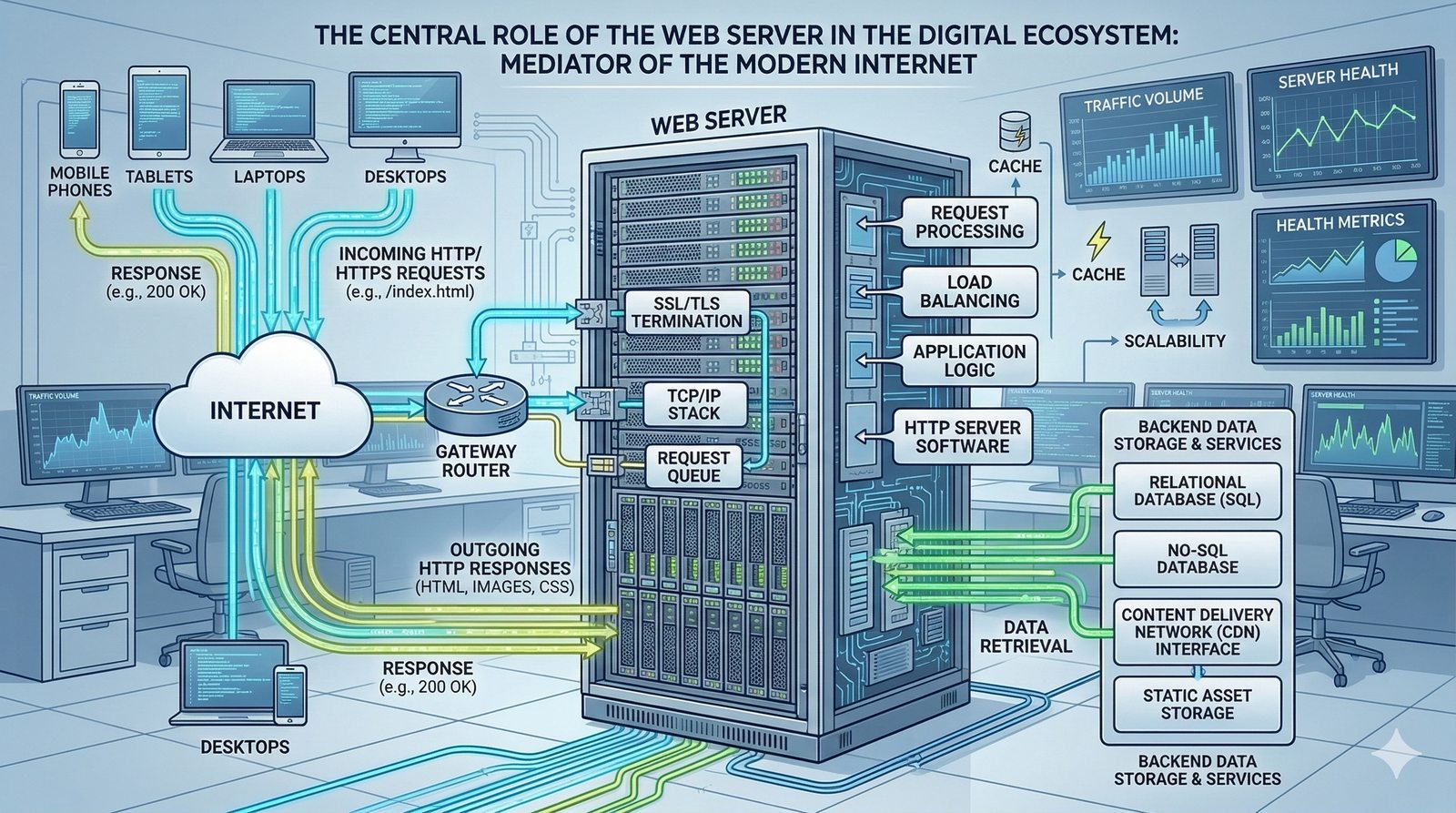
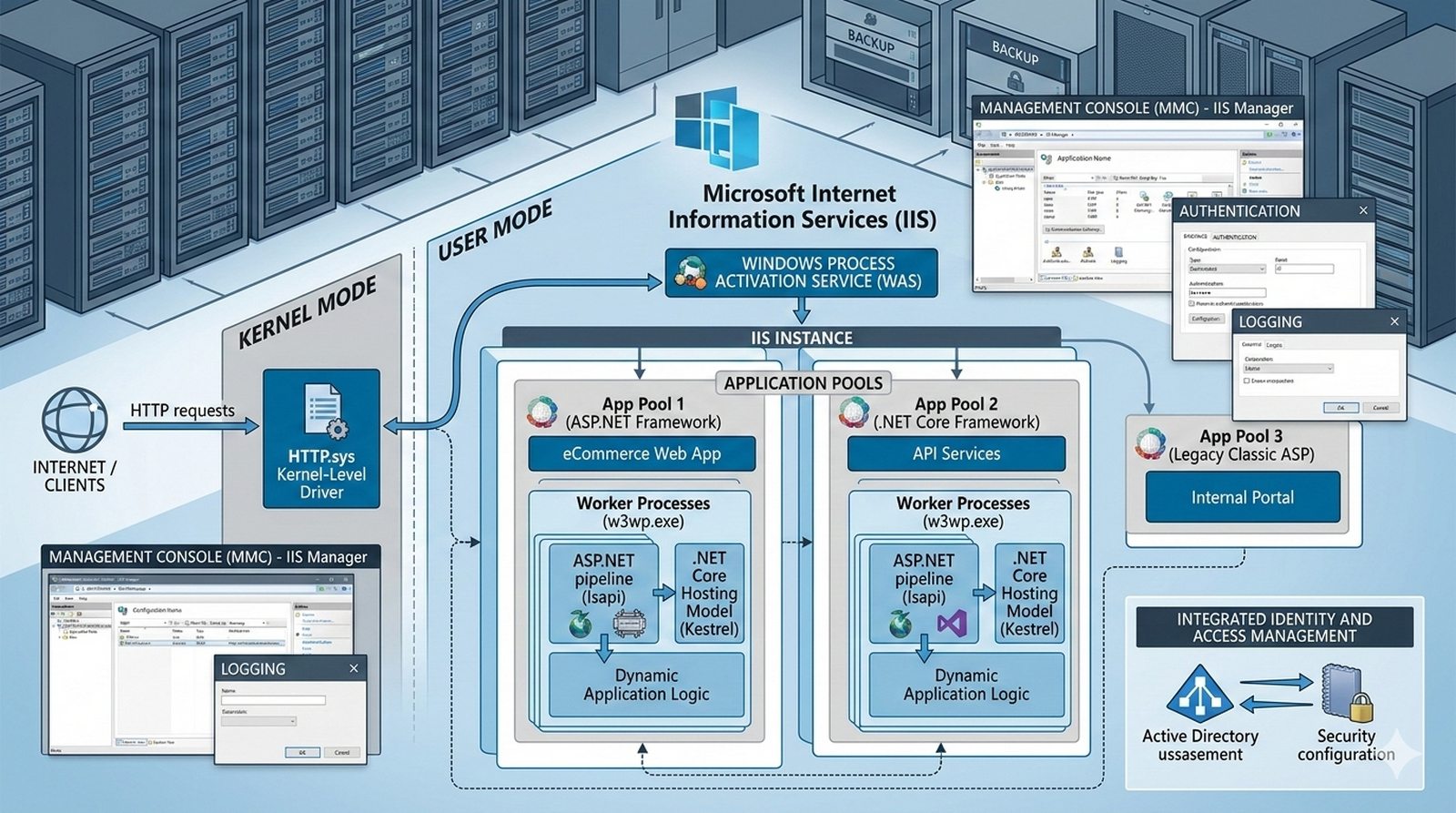
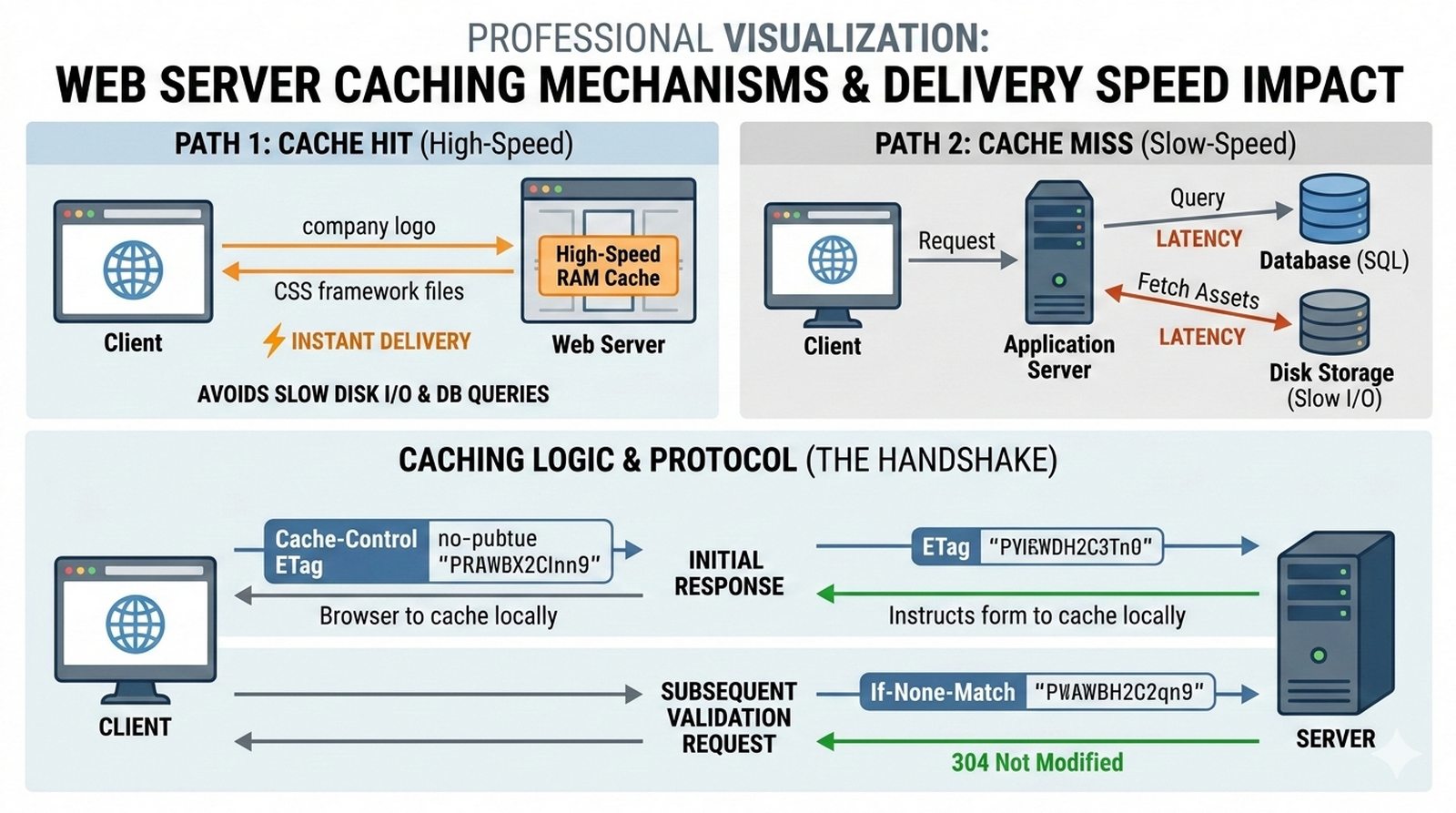
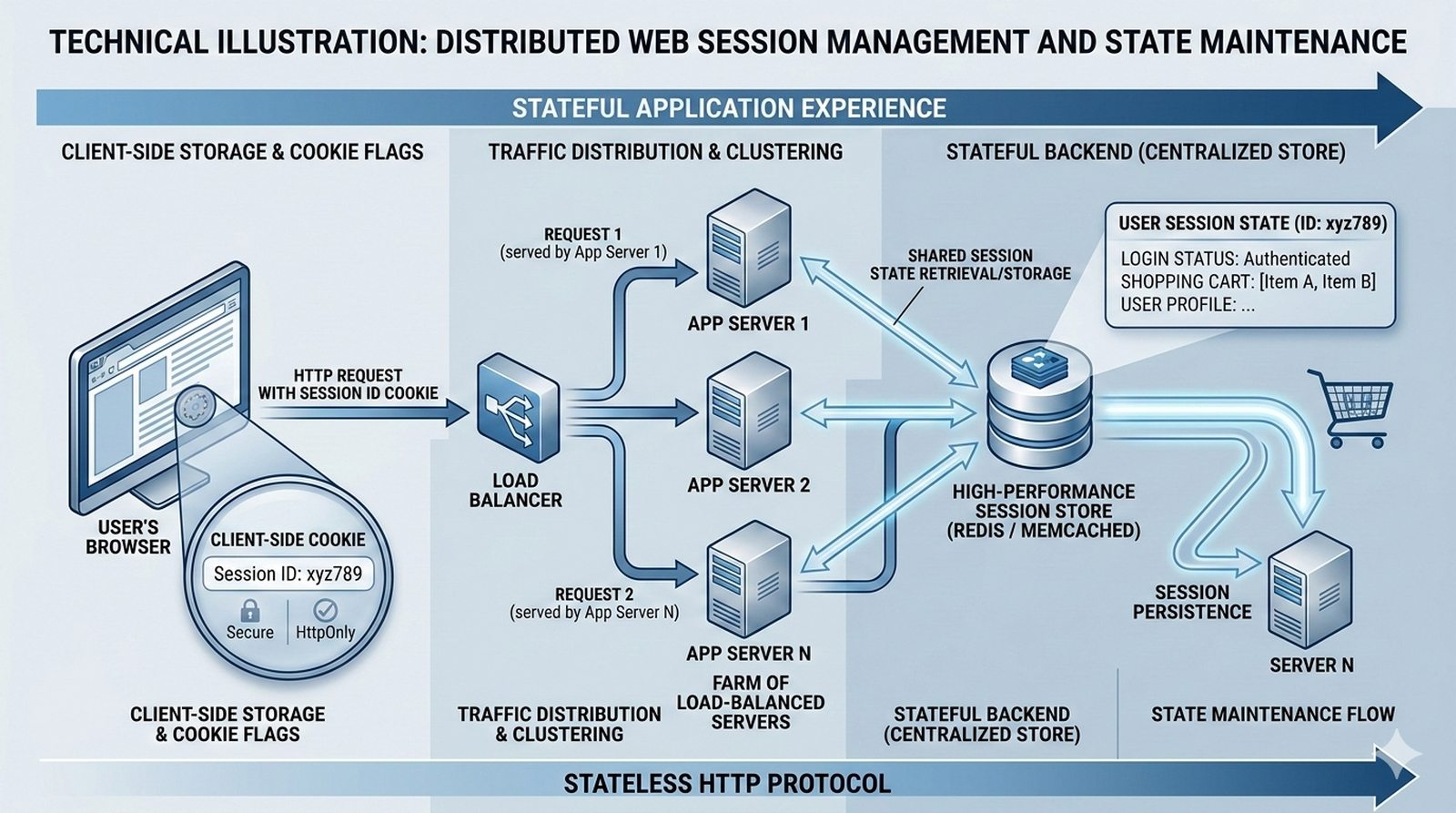
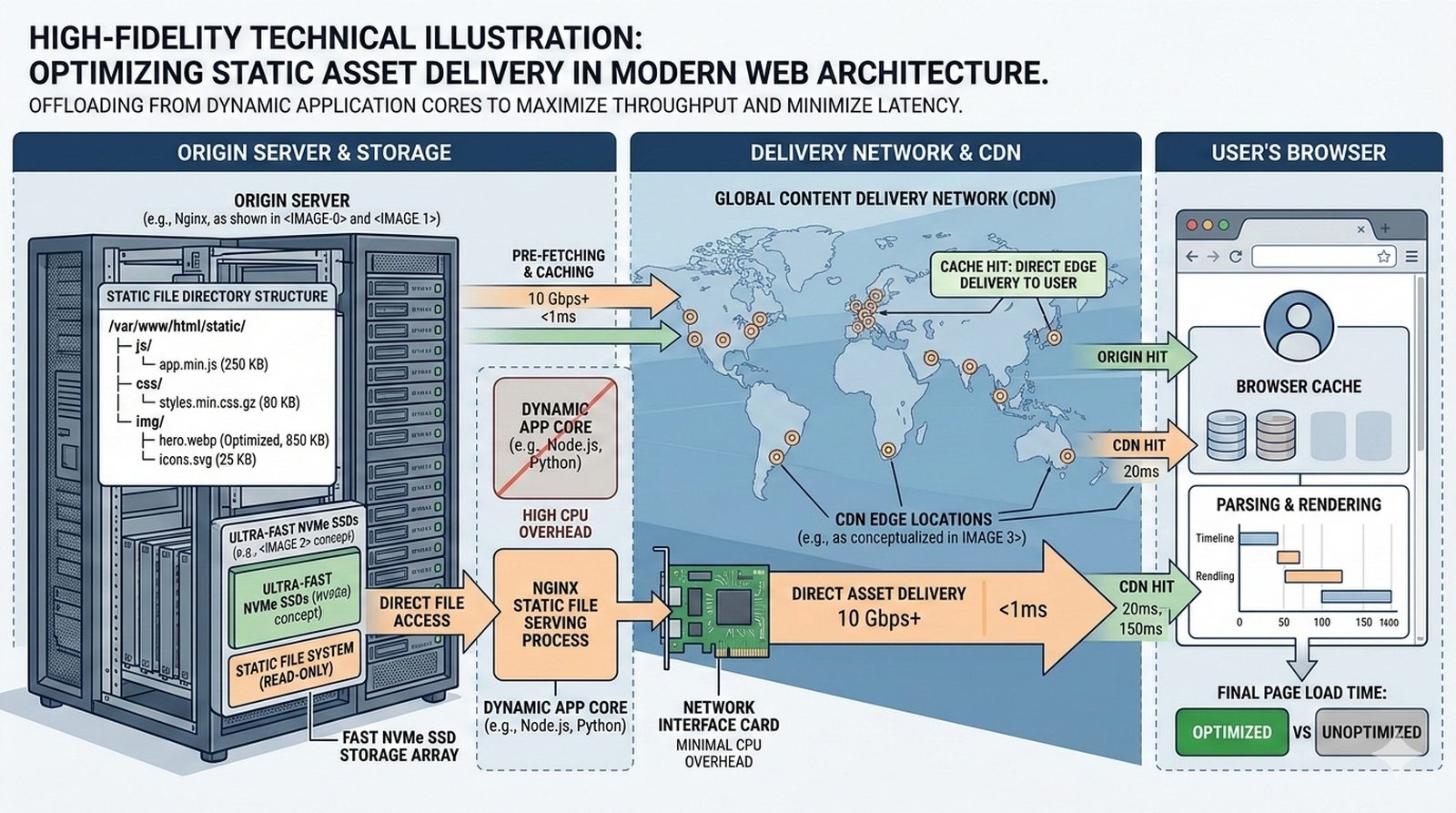
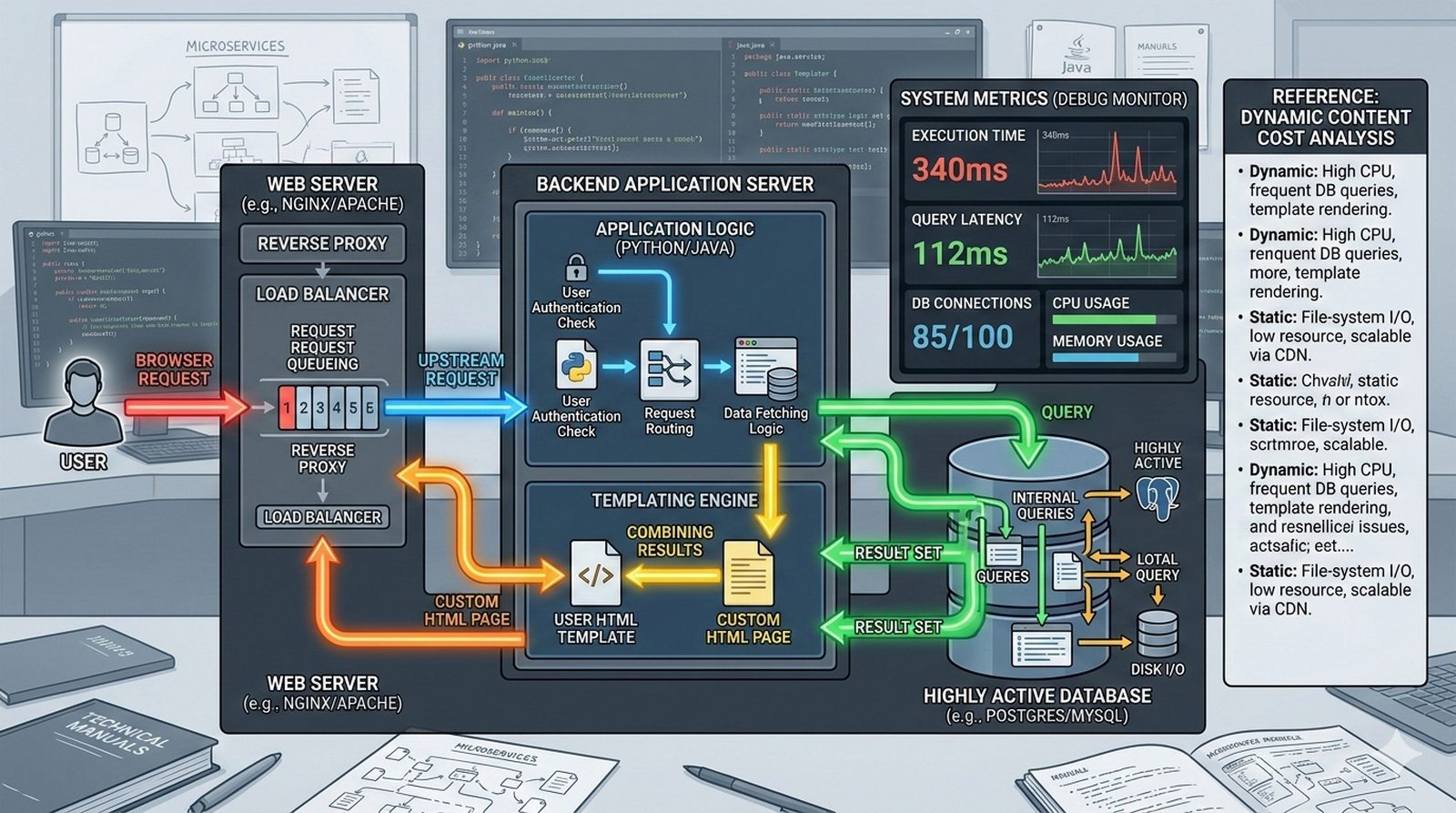
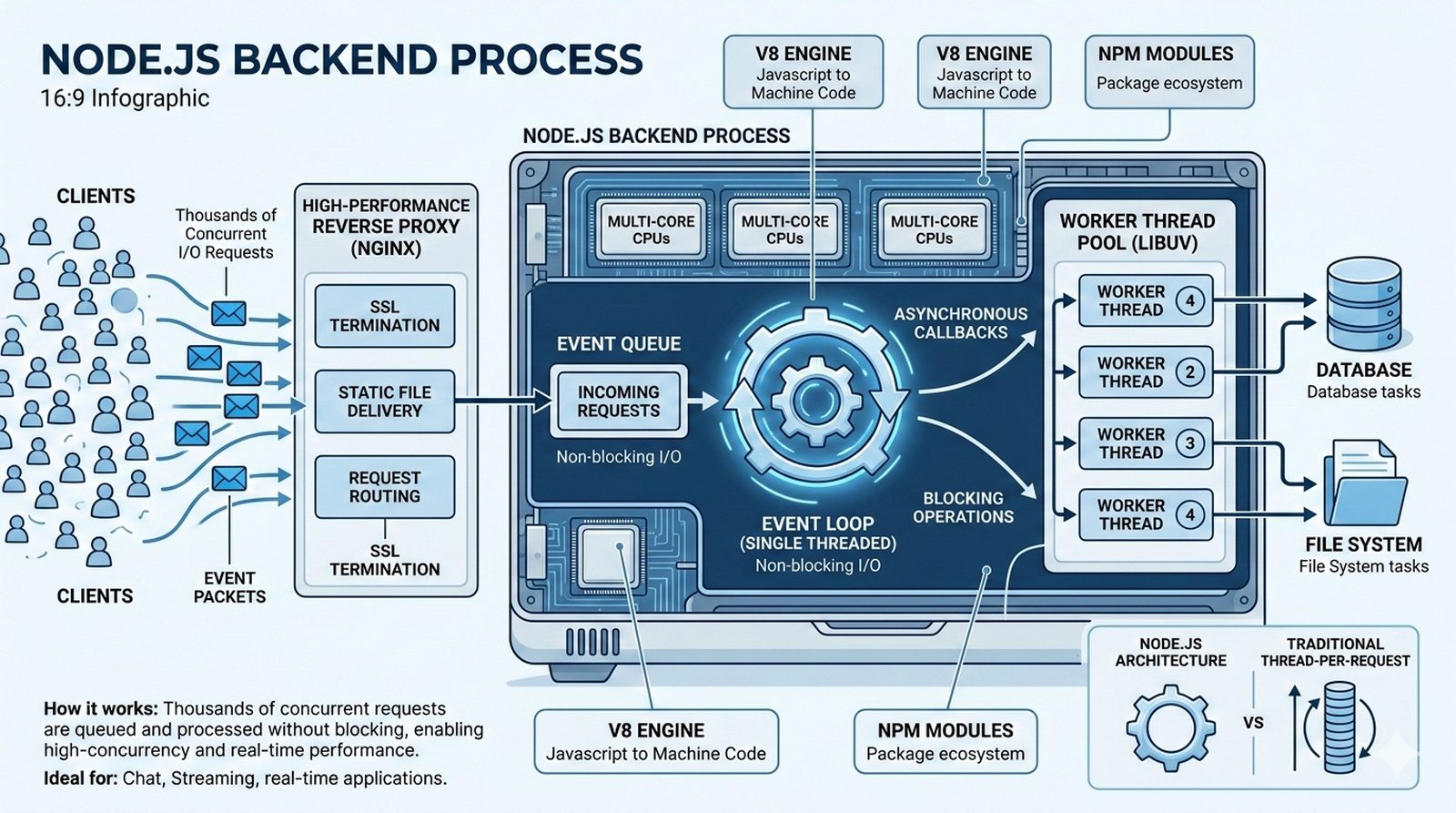
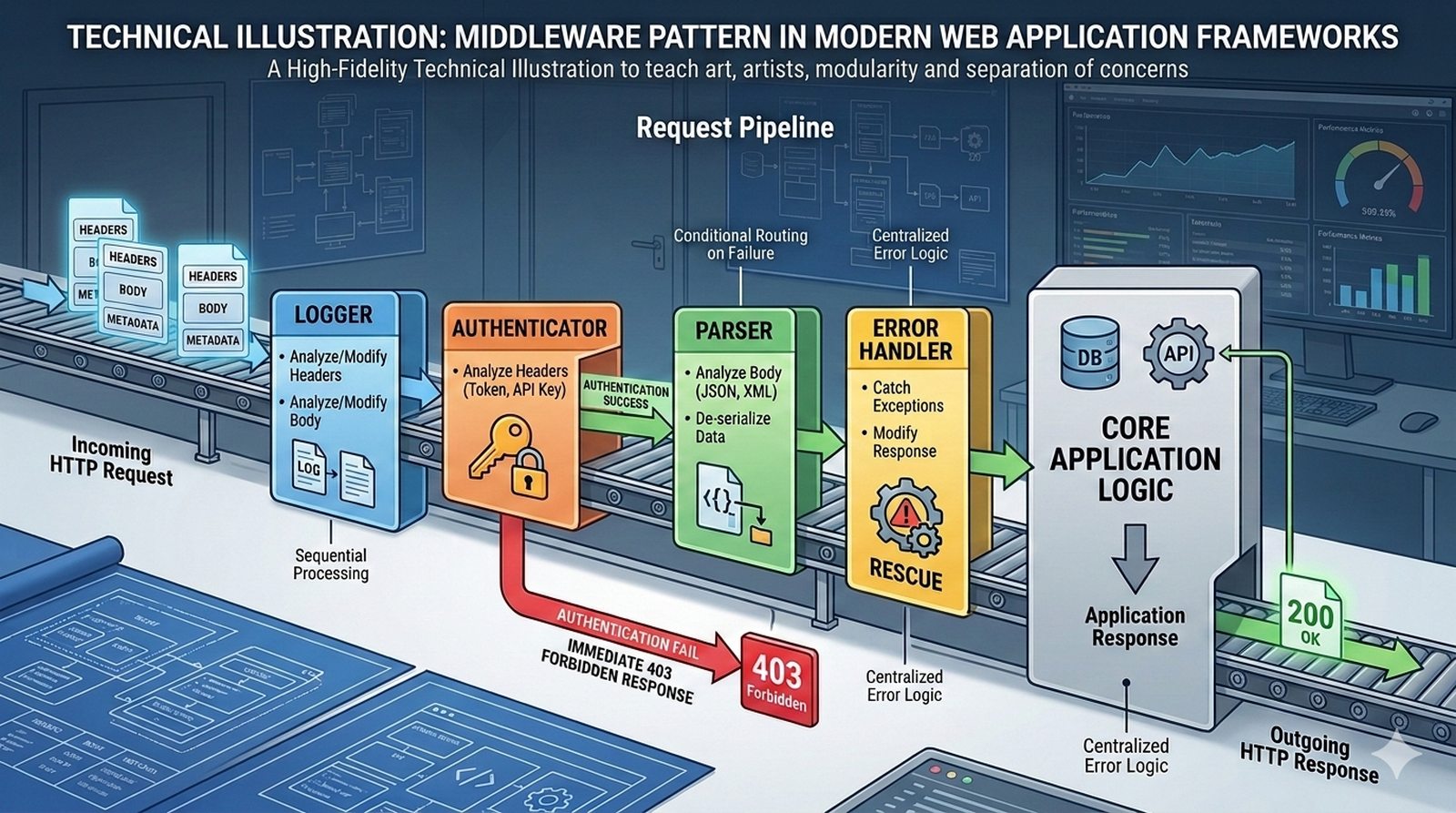
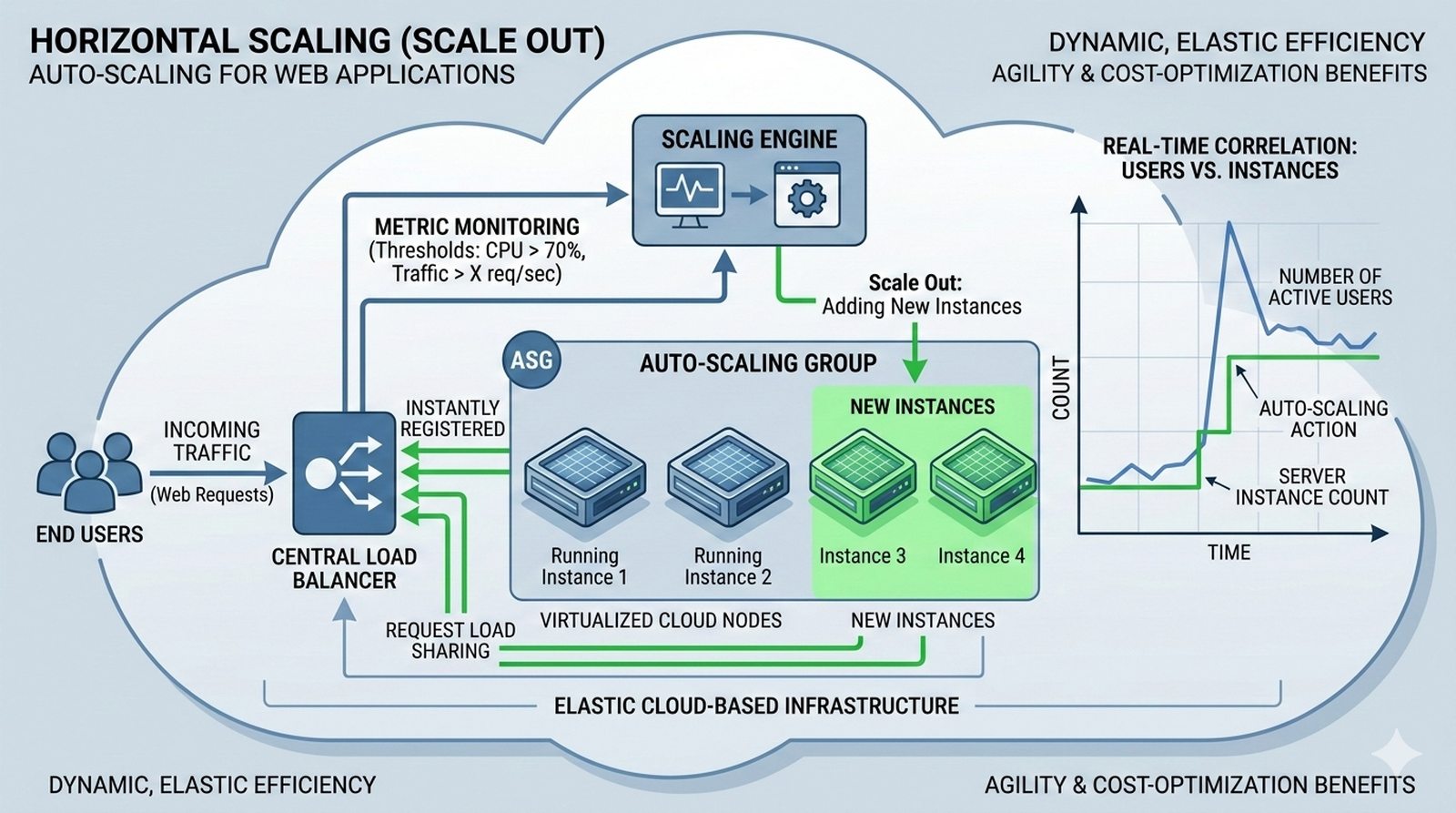
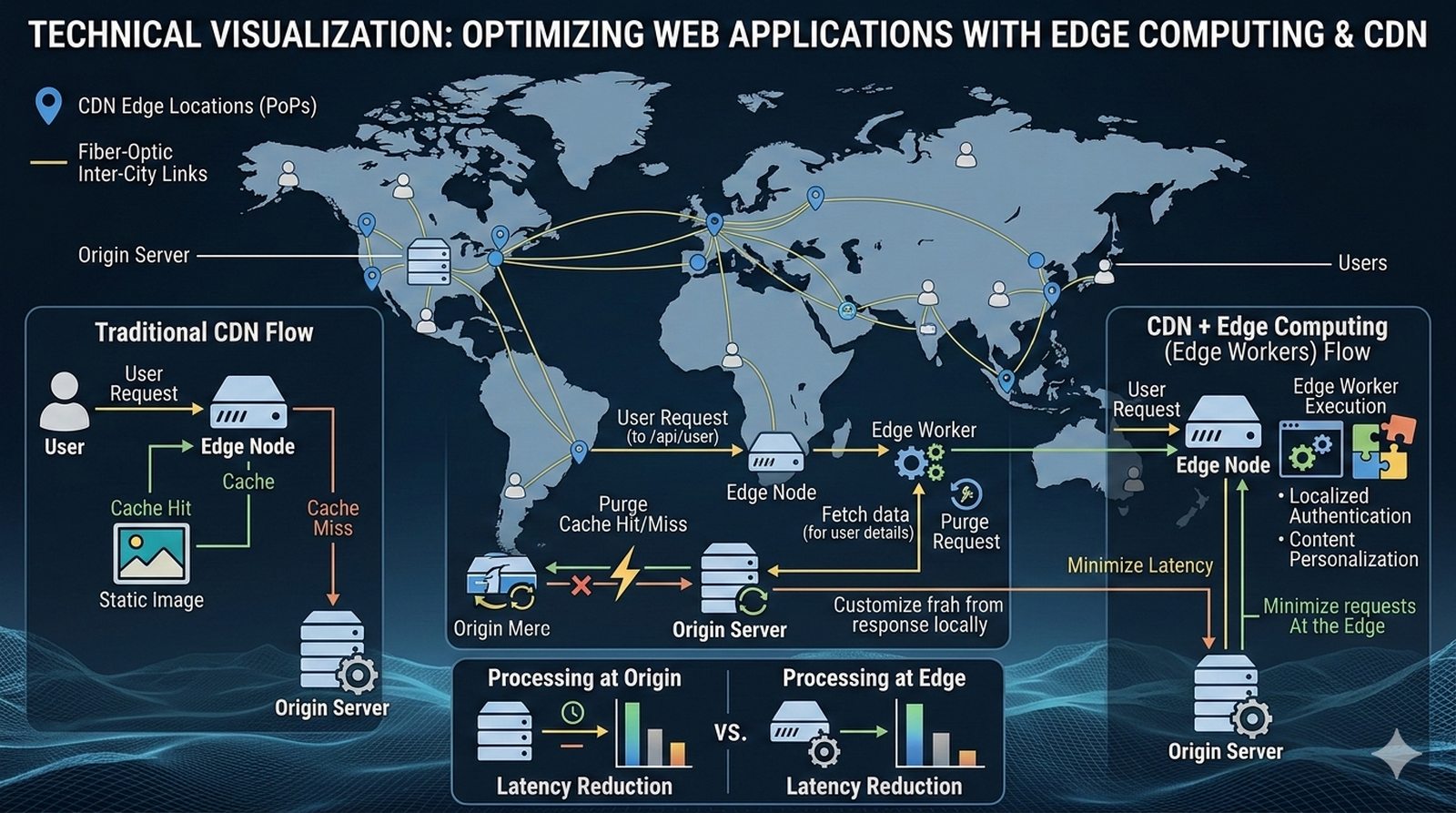
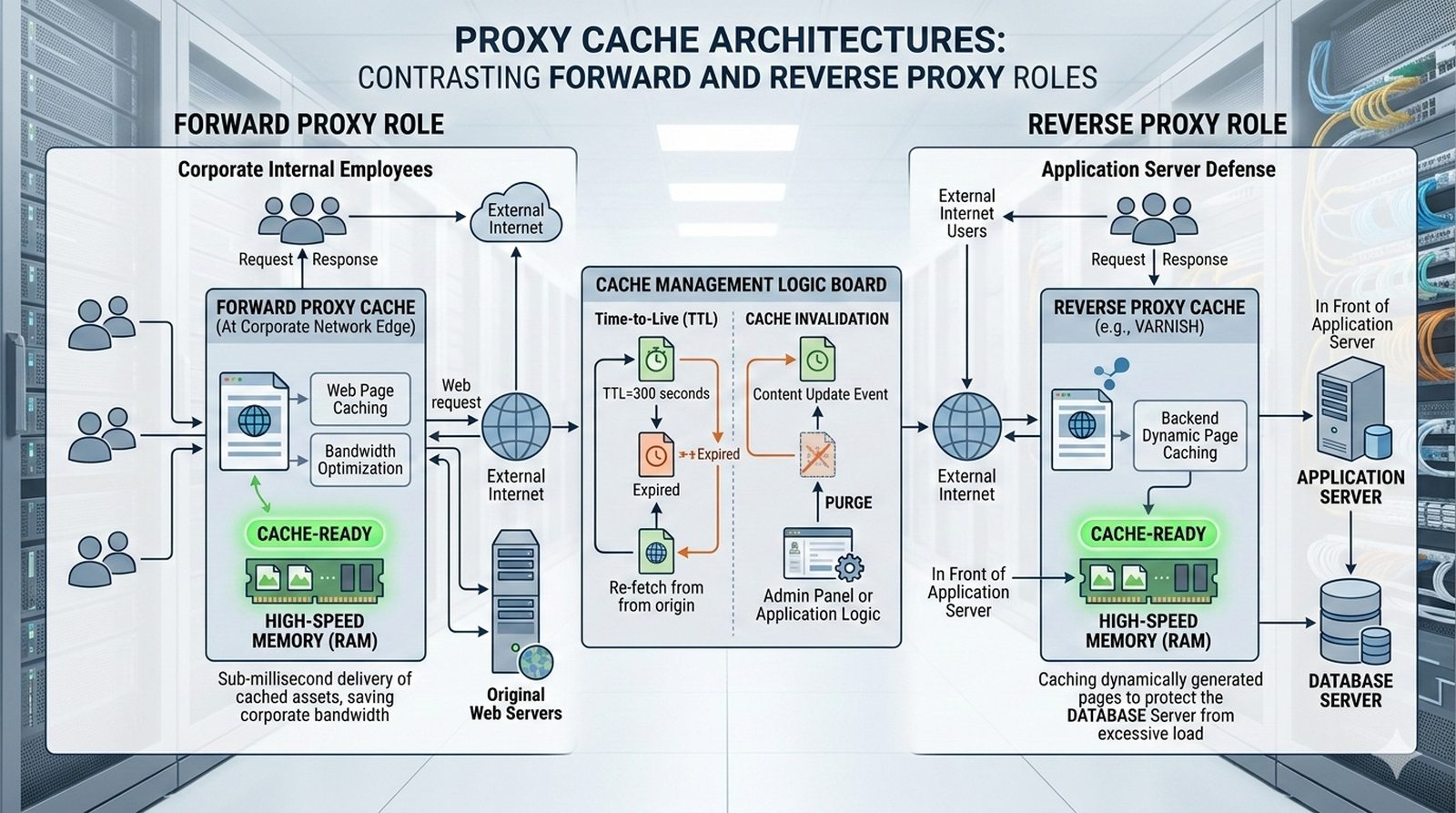
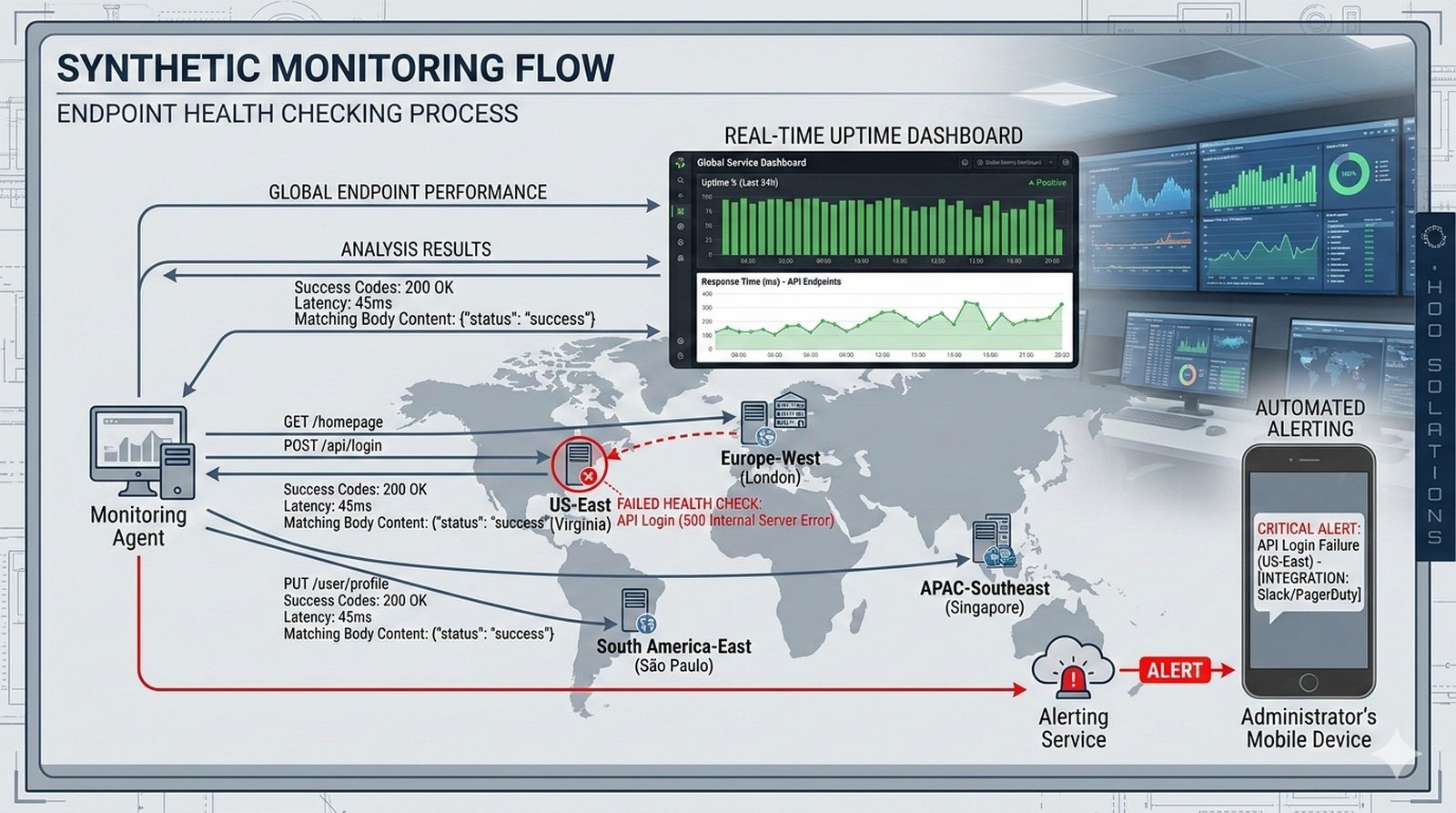
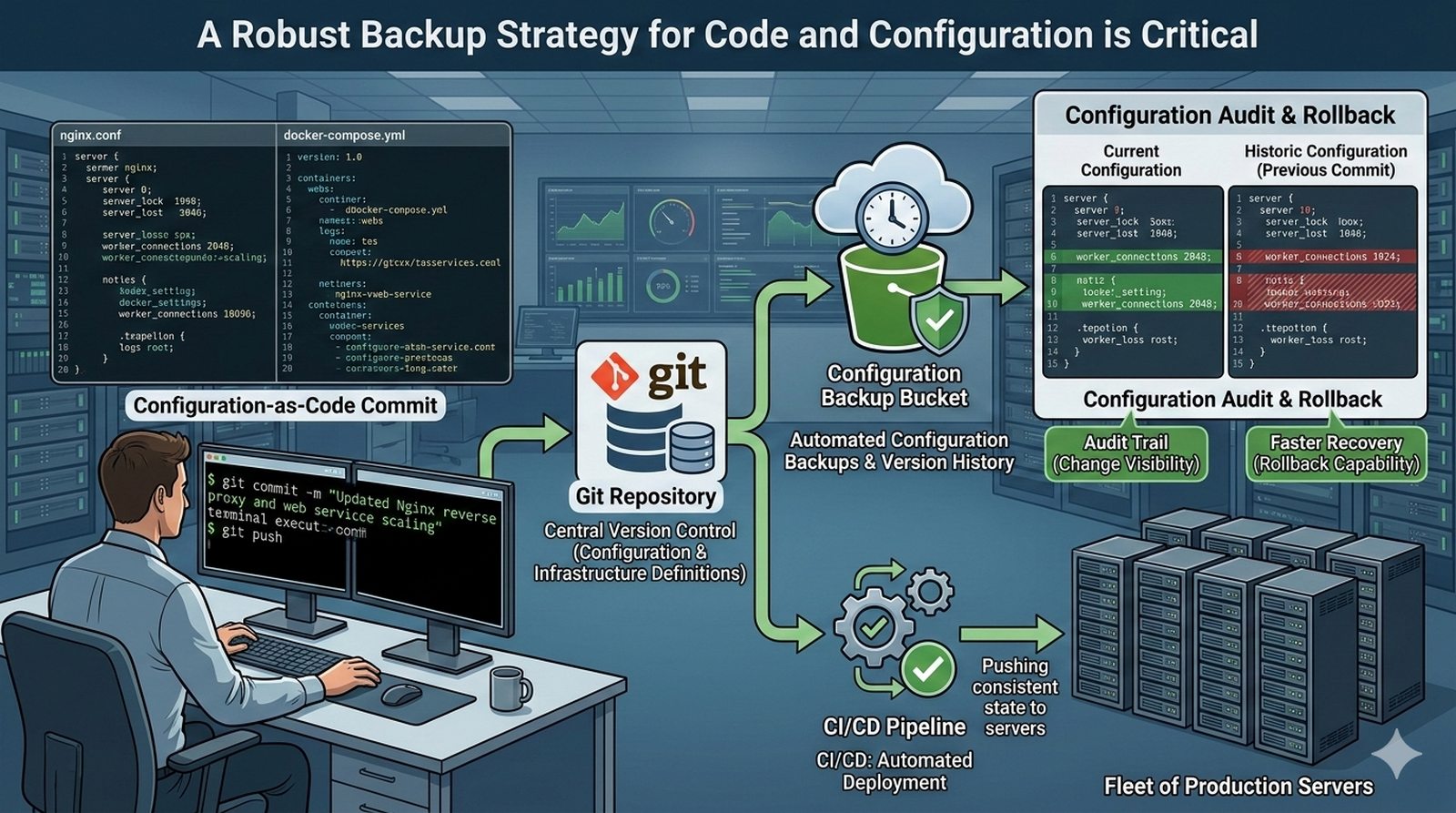
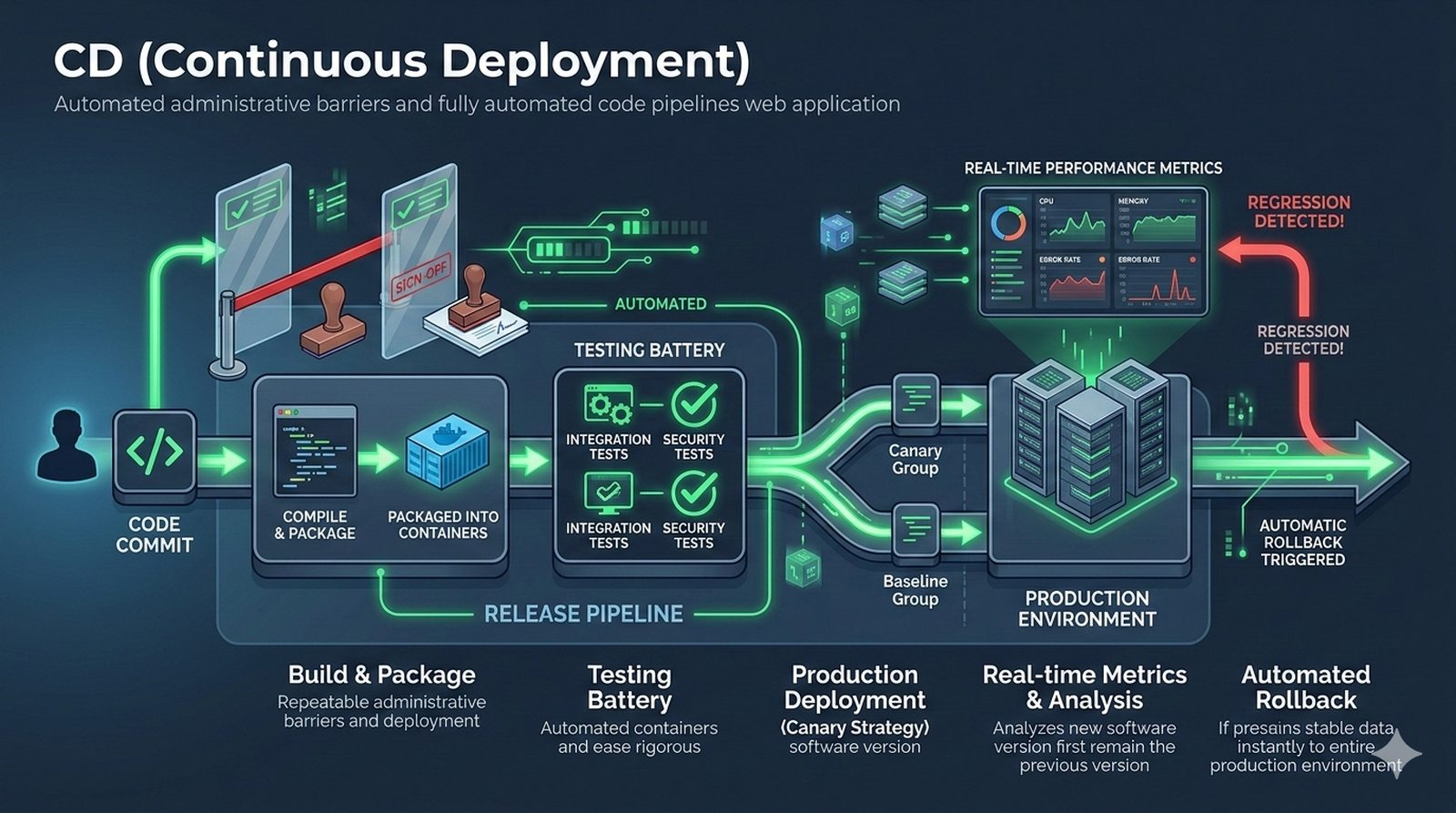
Potok CI/CD dzieli sie na kilka etapow: checkout kodu ze zrodla (najczesciej Git), instalacja zaleznosci (npm install, composer install, pip install), wykonanie testow (jednostkowych, integracyjnych, end-to-end), budowanie artefaktow (webpack, vite, gulp), tworzenie obrazu Docker (docker build) i wdrozenie na srodowisko docelowe. Kazdy etap powinien byc izolowany i niezalezny, co ulatwia identyfikacje miejsca wystapienia bledu.
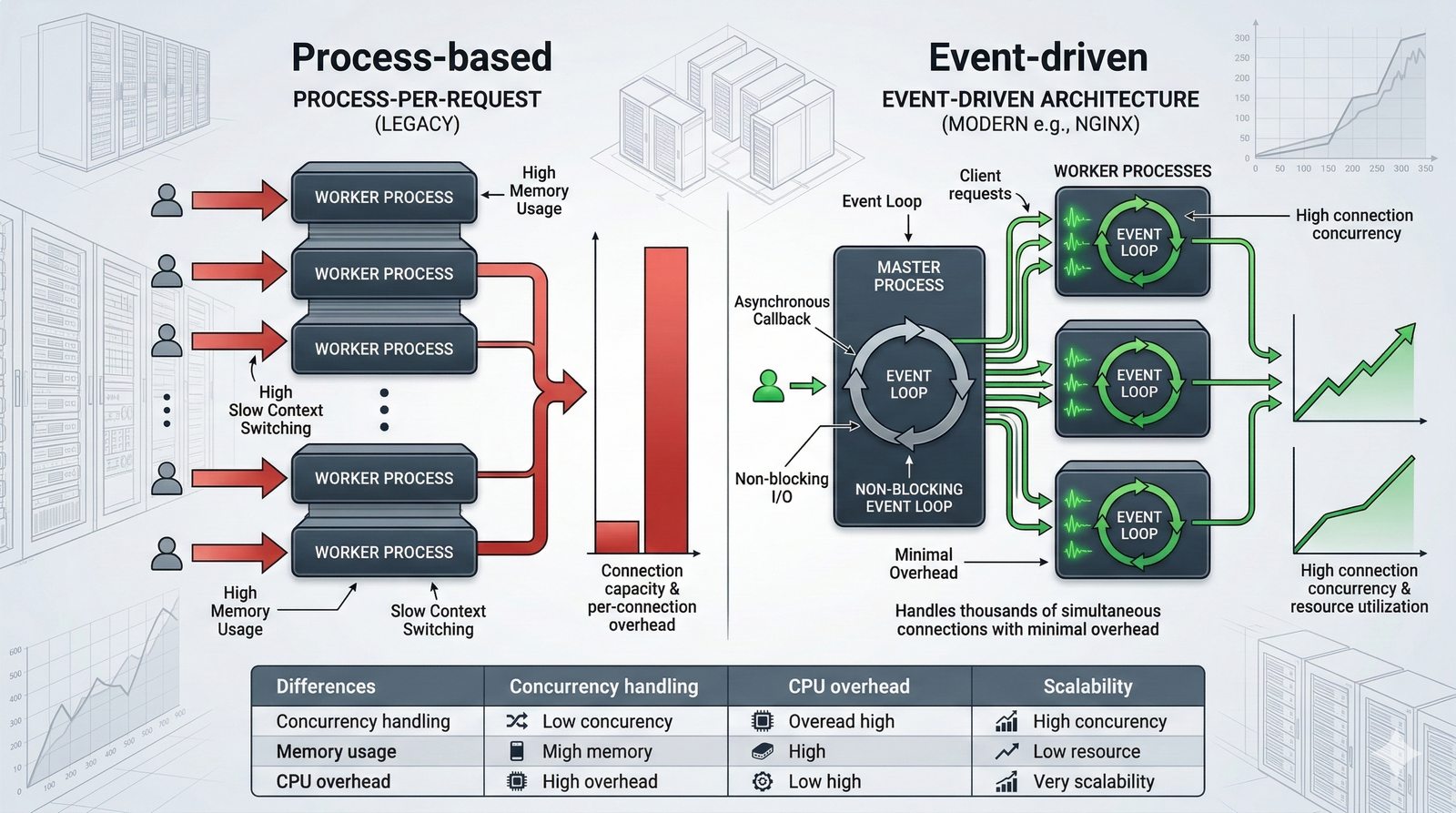
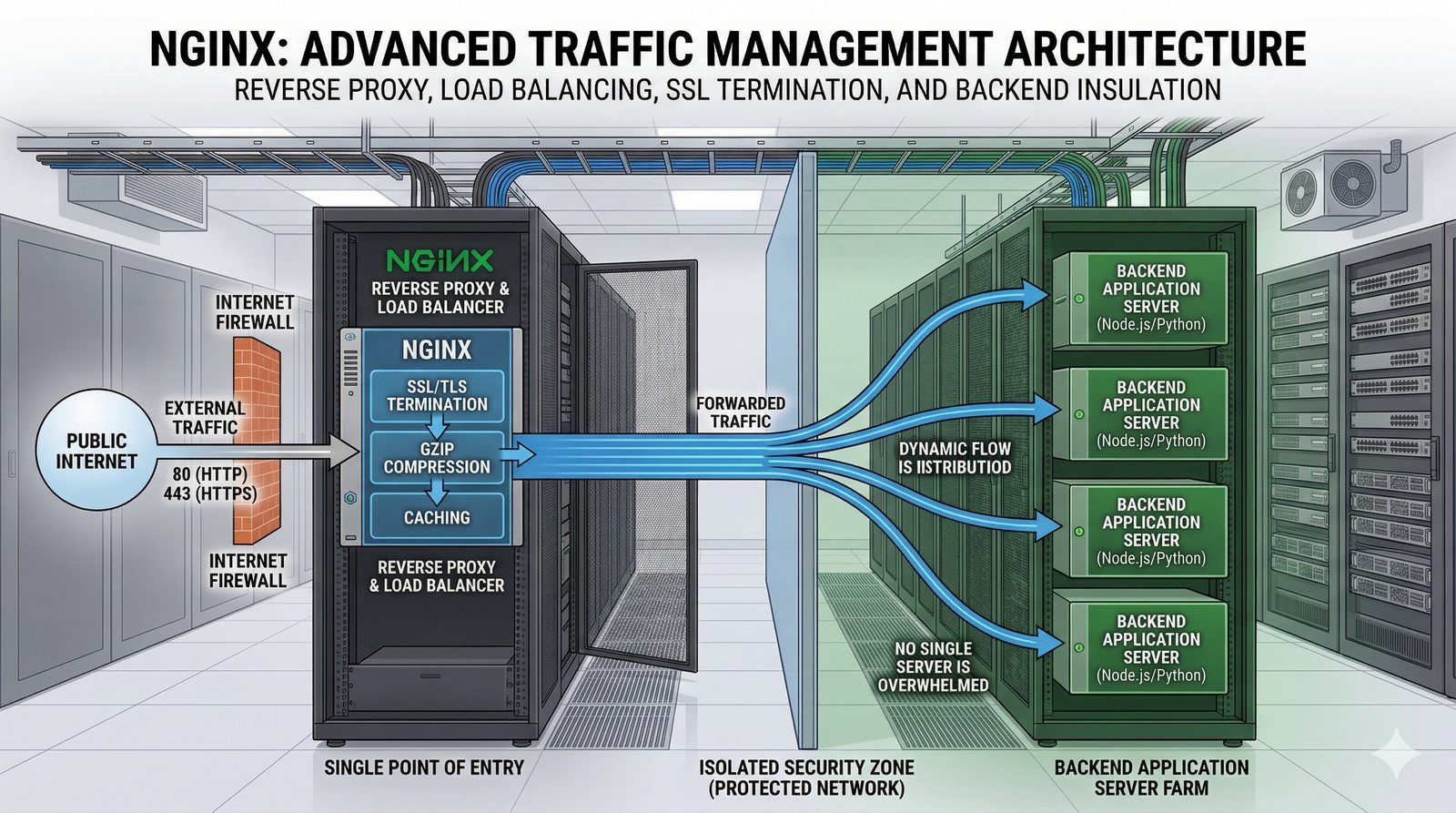
Narzedzia CI/CD takie jak GitHub Actions, GitLab CI, Jenkins, CircleCI i Bitbucket Pipelines roznia sie sposobem konfiguracji (YAML, DSL, GUI) i modelem hostingowym (cloud, self-hosted). GitHub Actions oferuje bogata biblioteke gotowych akcji, ktore mozna laczyc w workflow. GitLab CI charakteryzuje sie wbudowanym rejestrem kontenerow (Container Registry) i zaawansowanym zarzadzaniem srodowiskami.
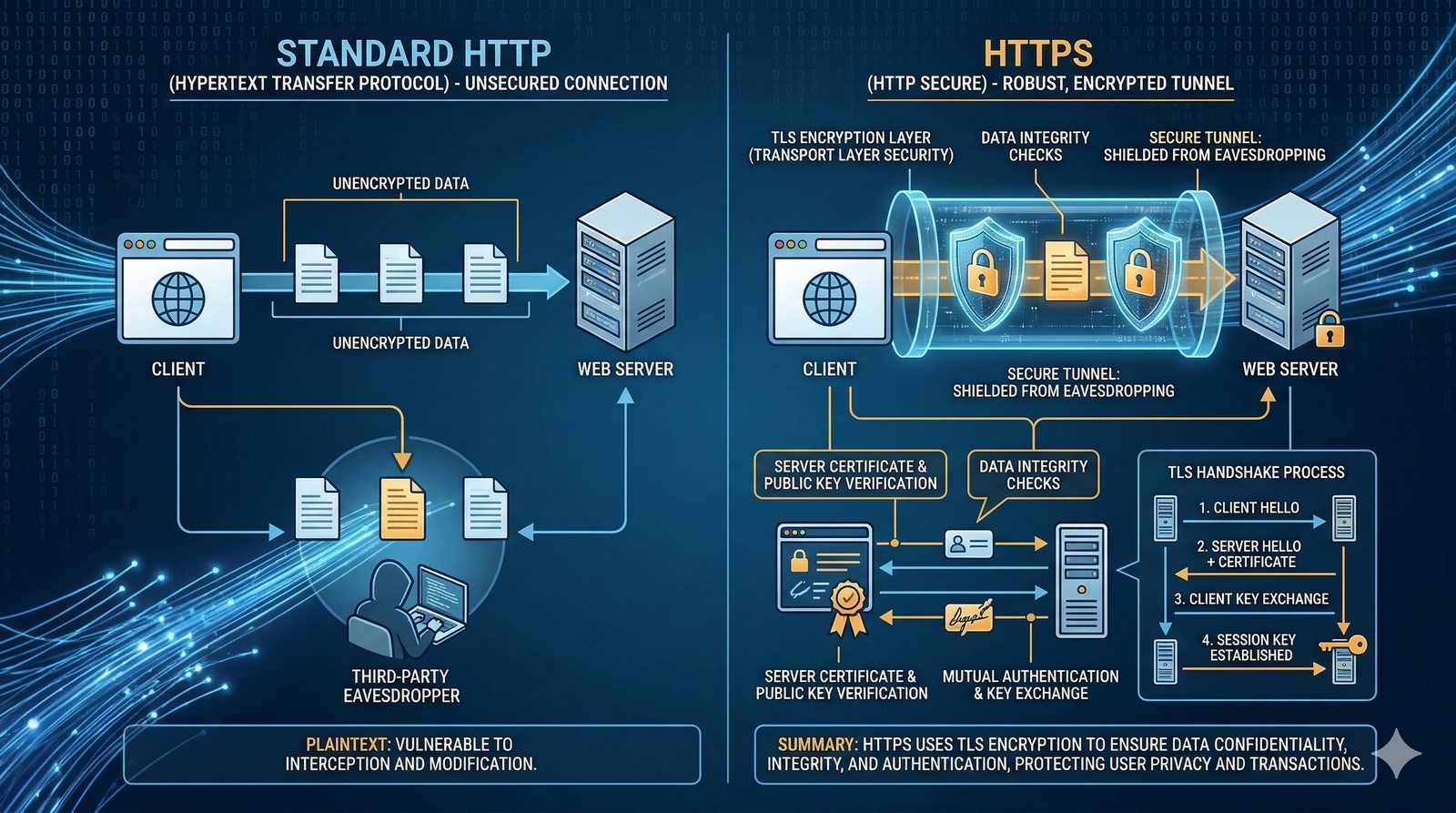
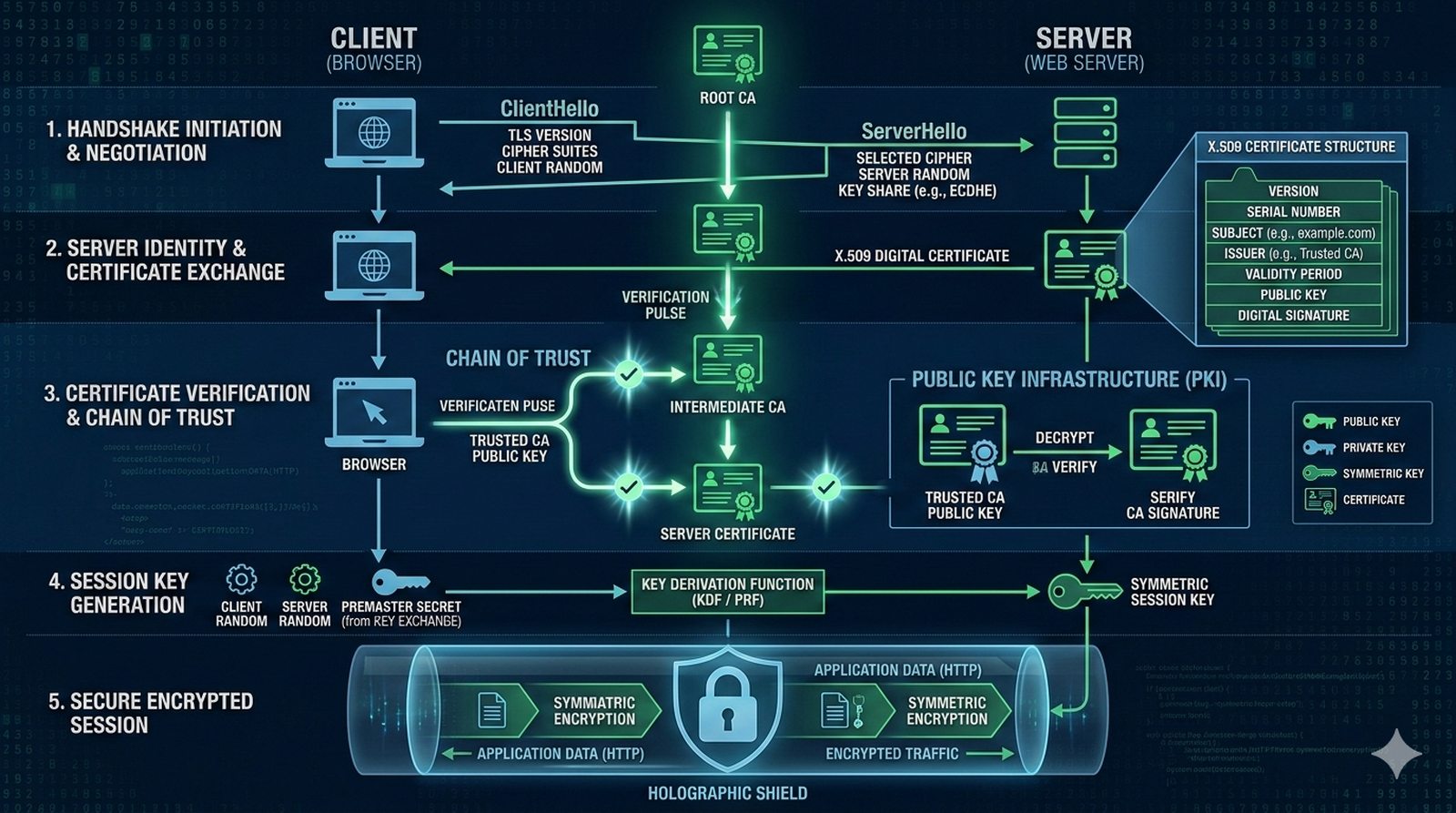
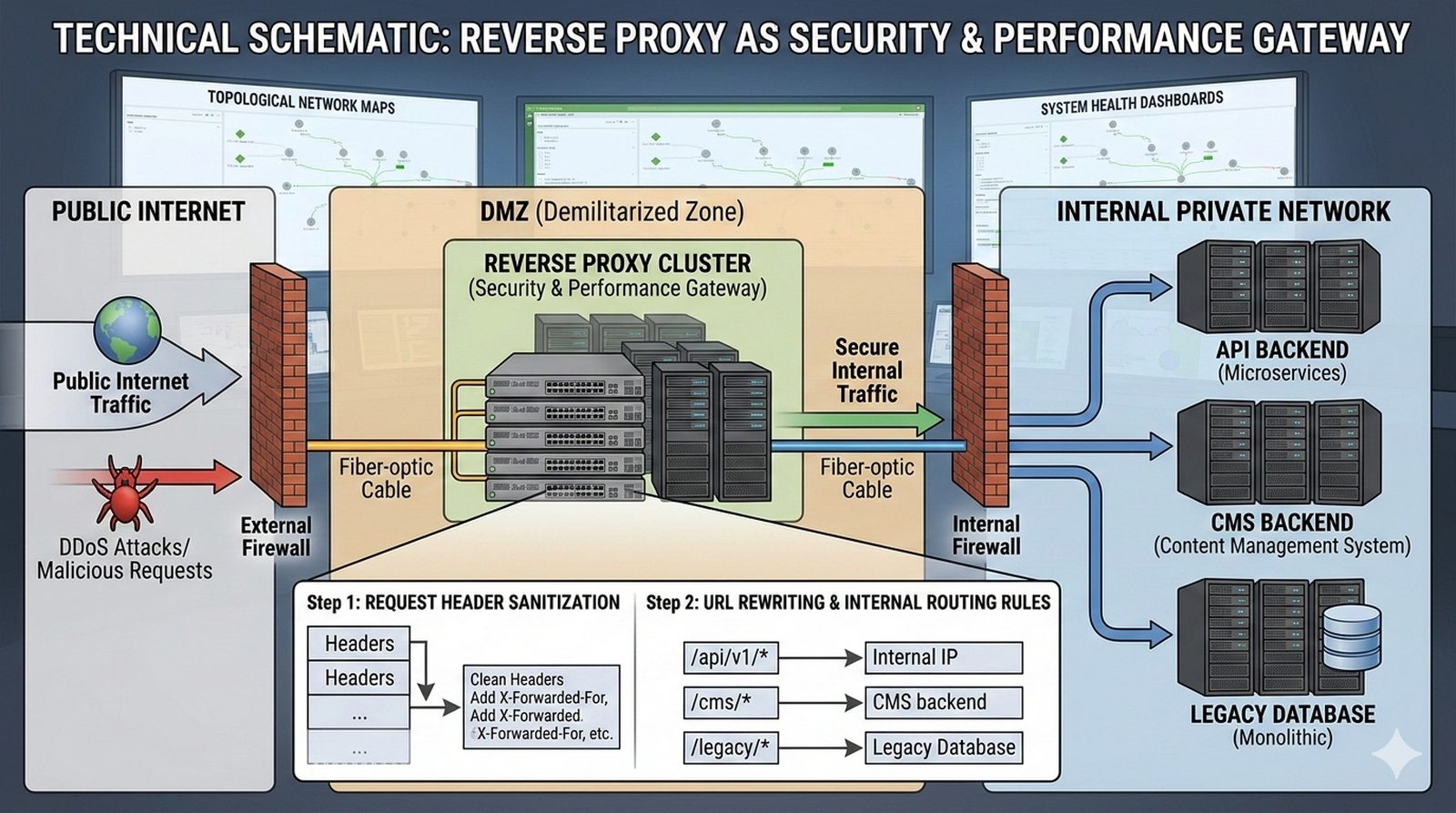
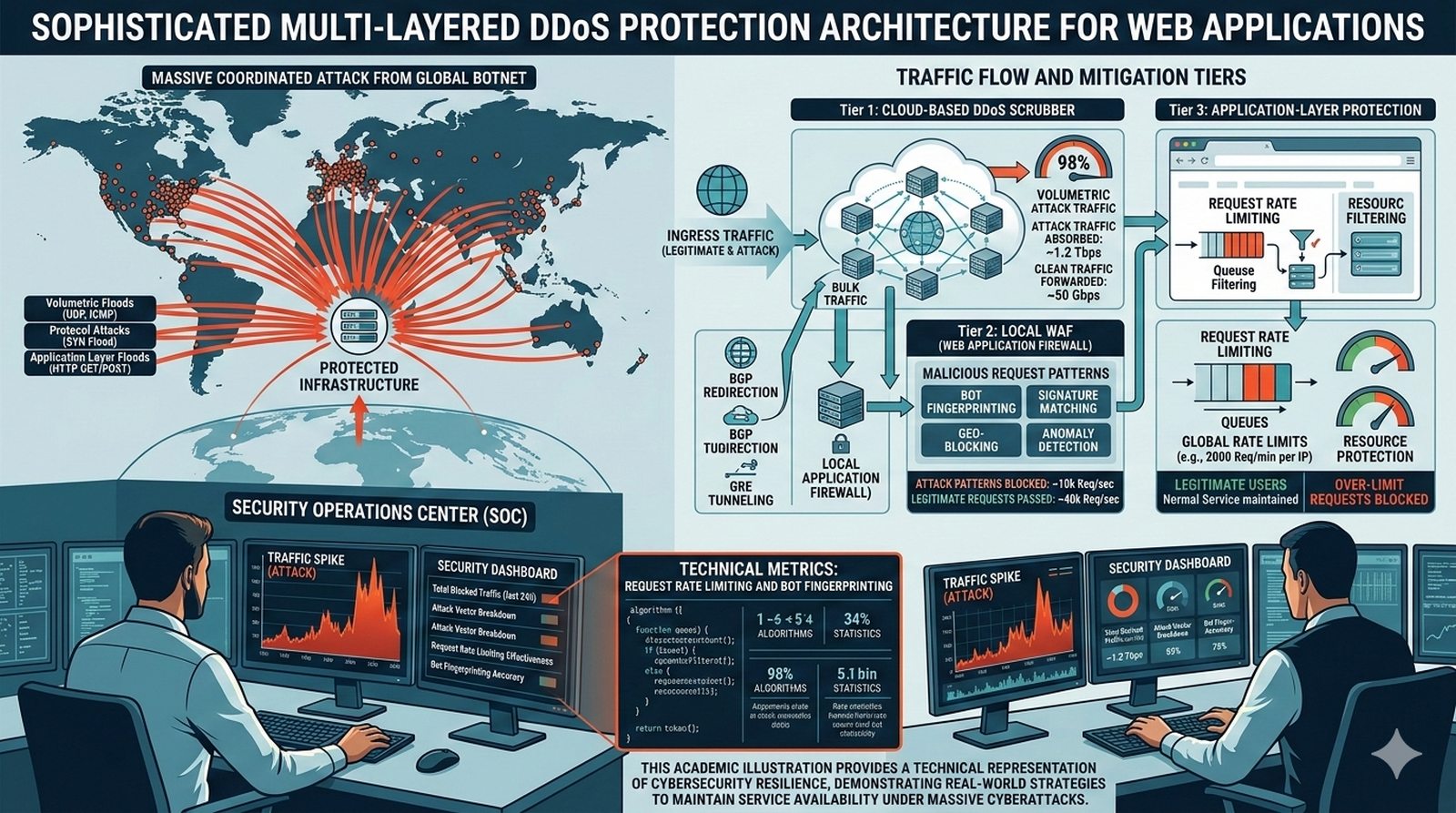
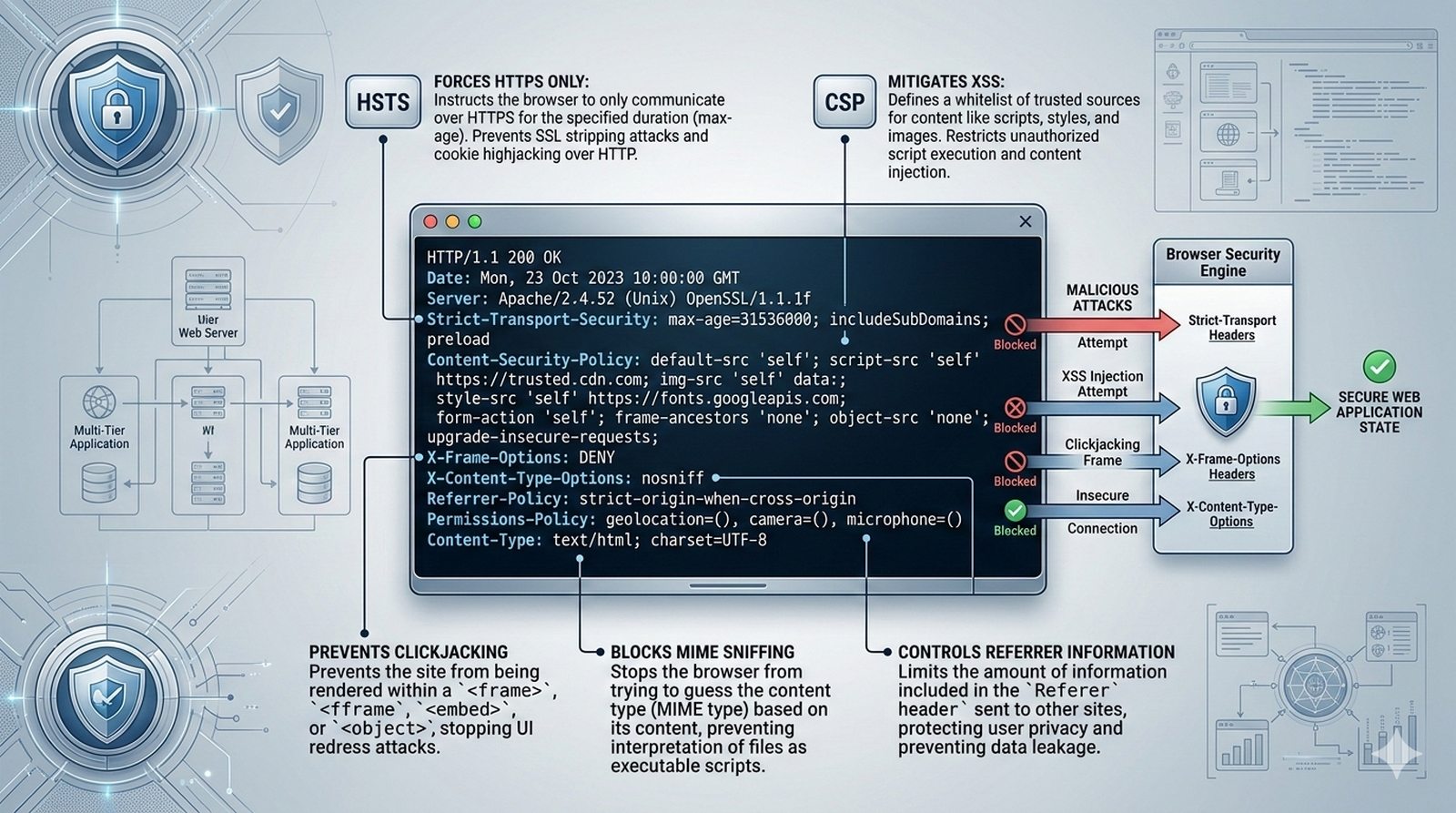
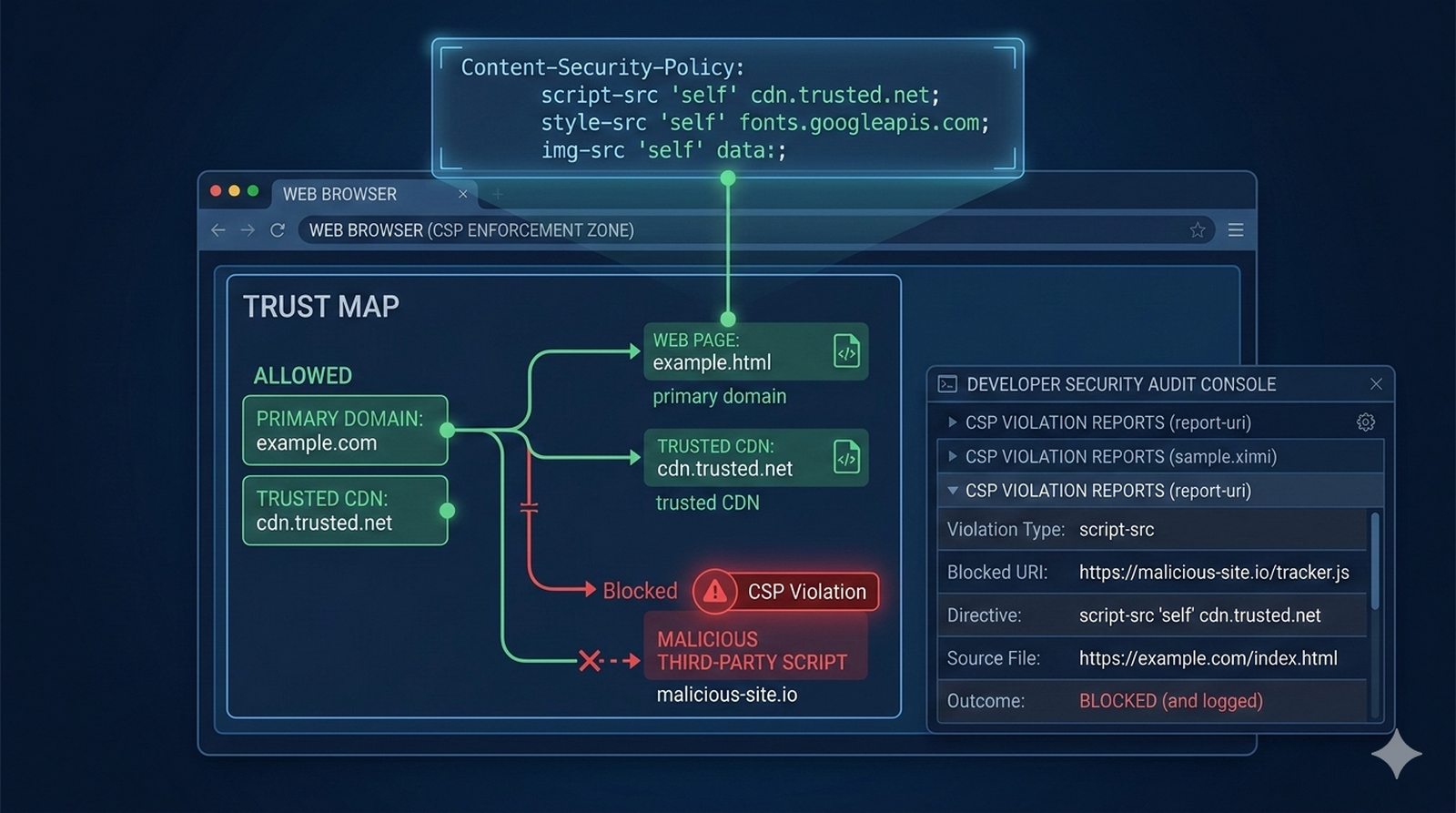
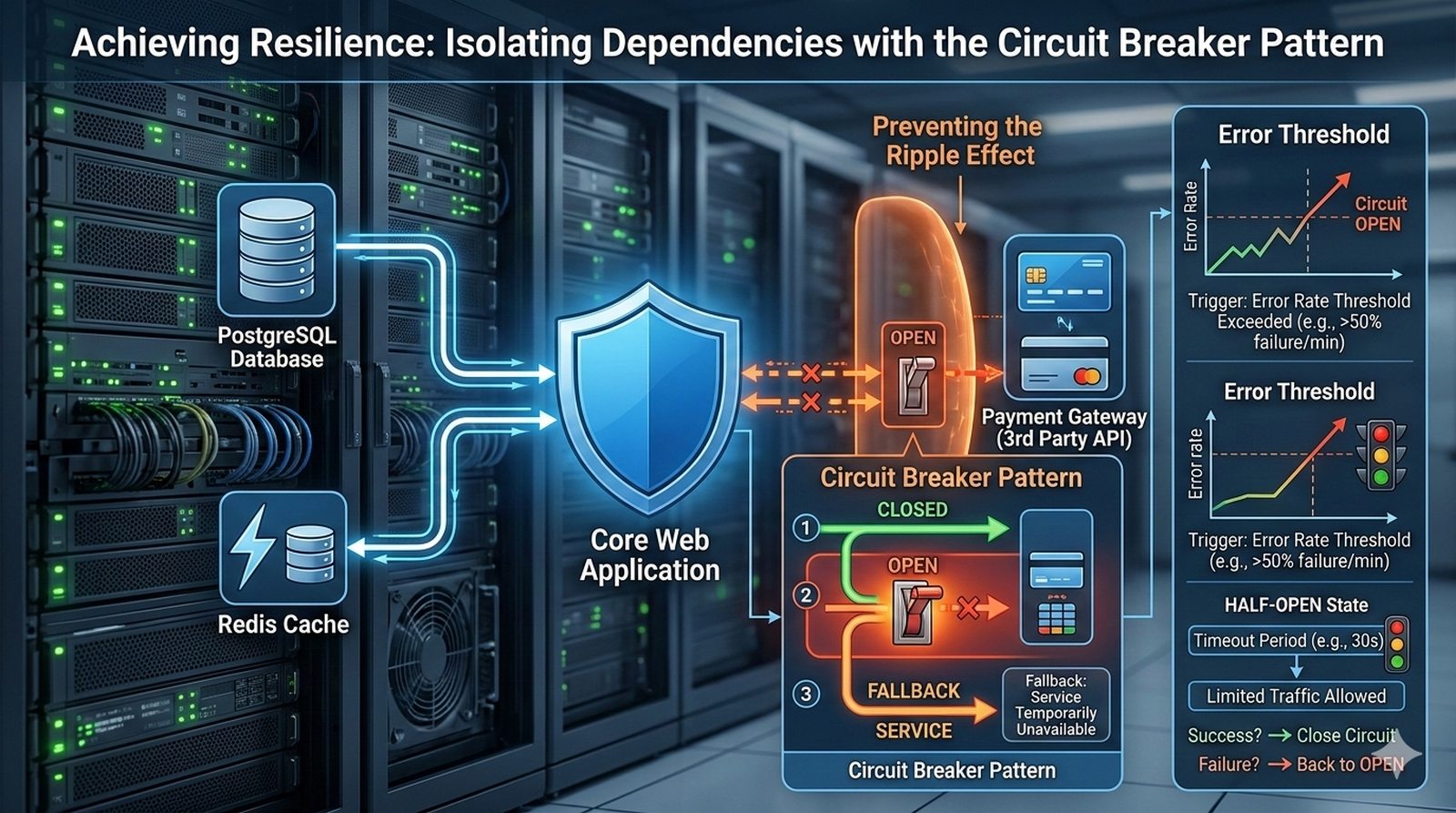
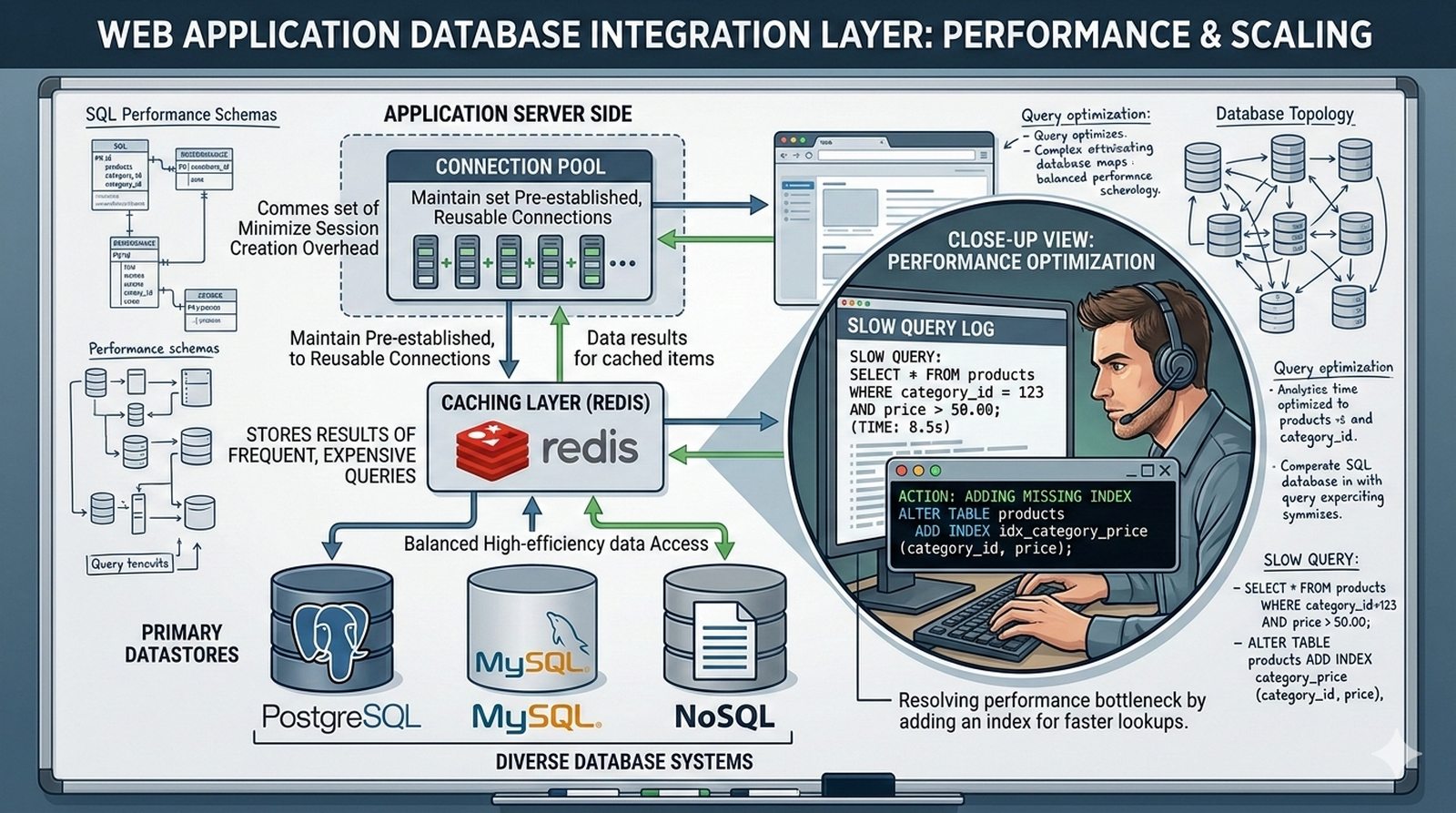
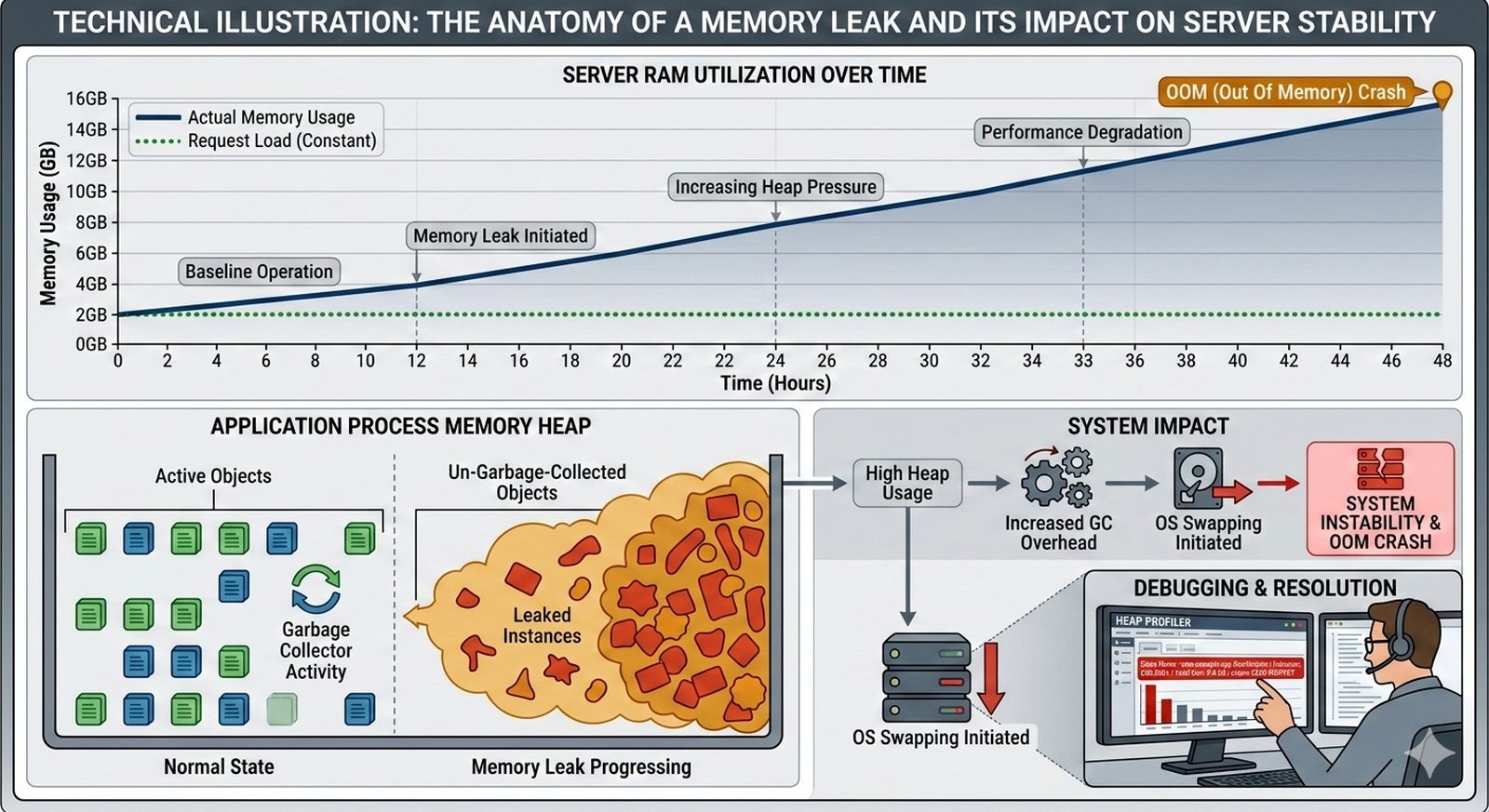
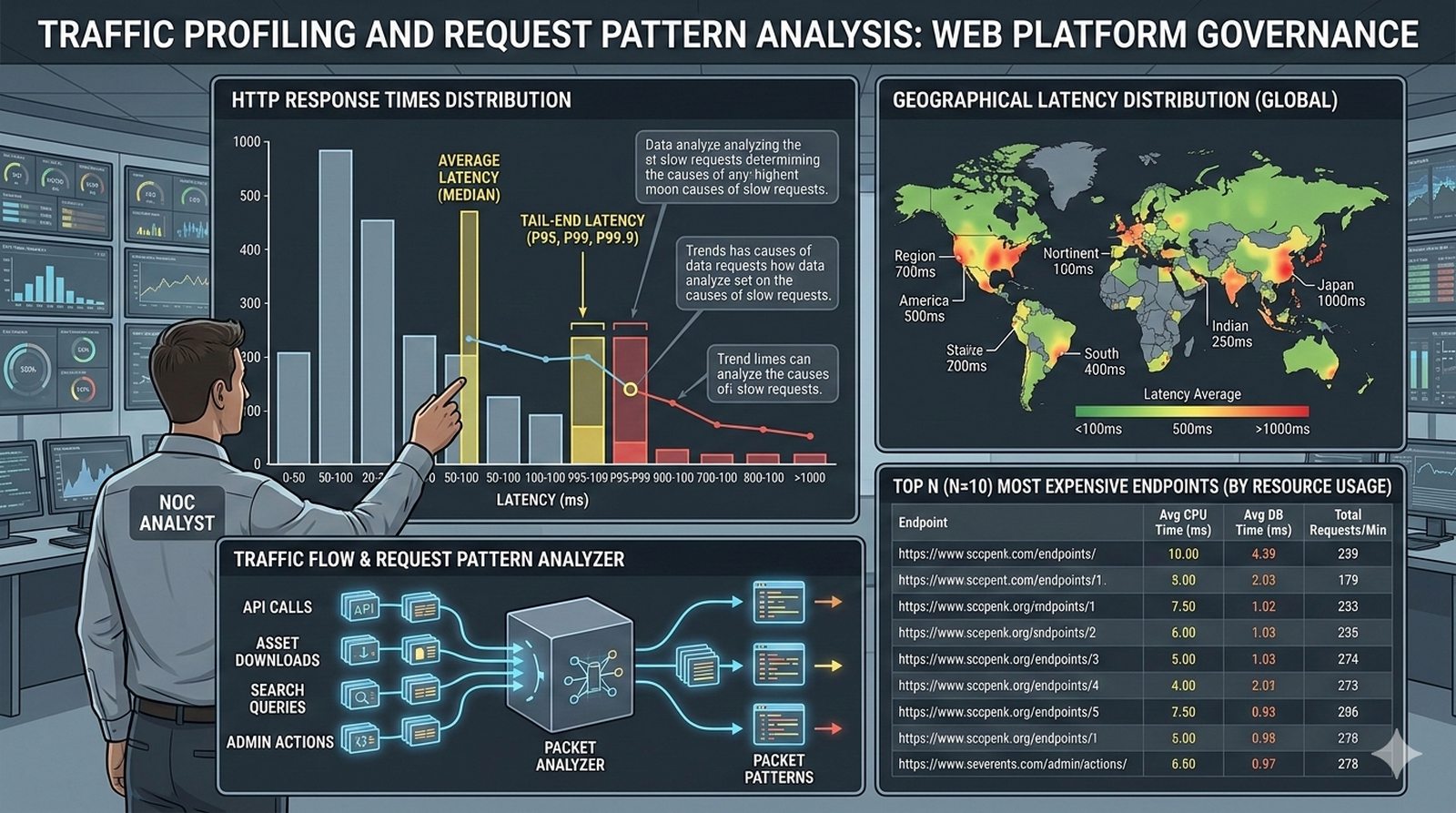
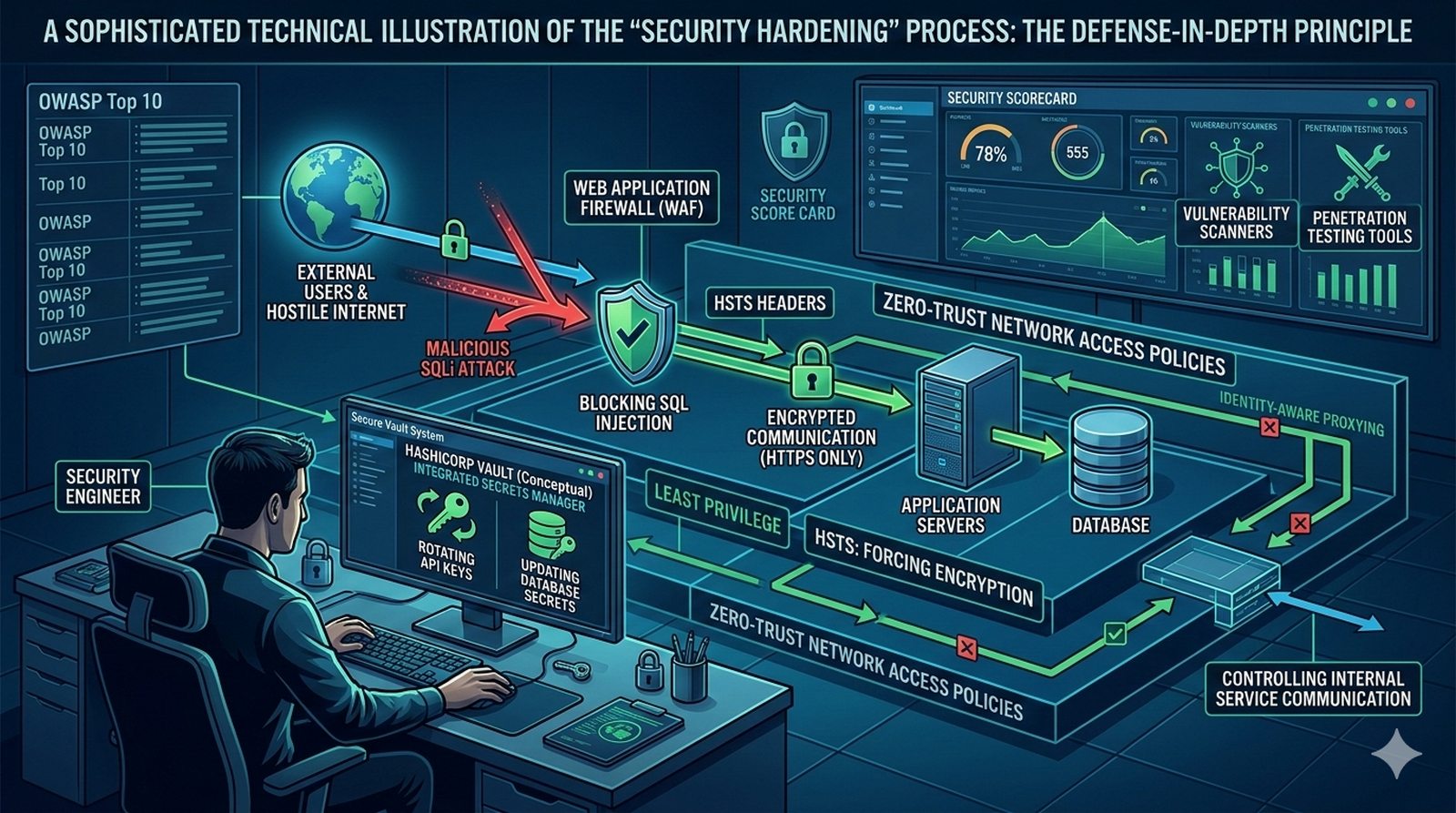
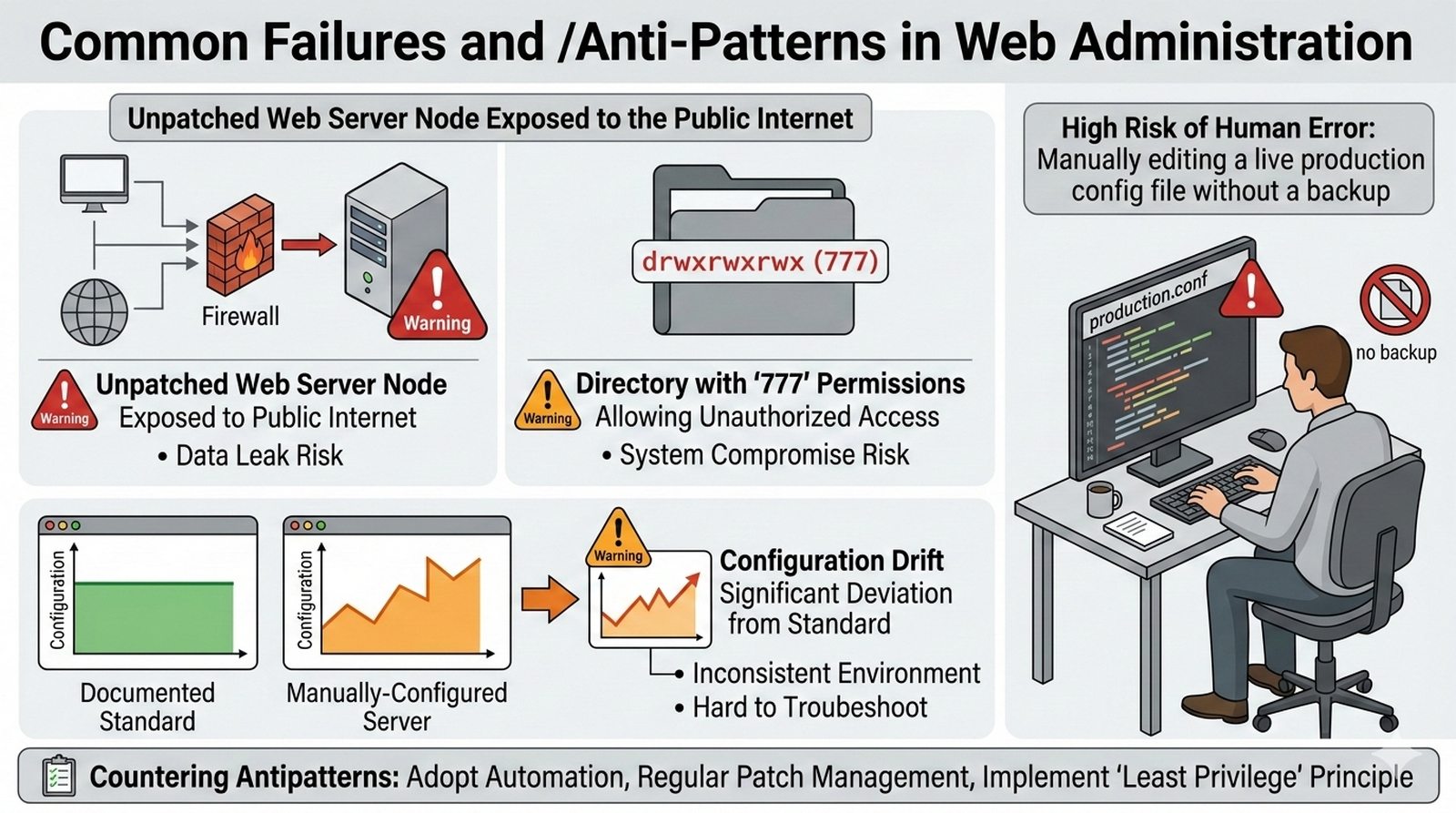
W kontekscie bezpieczenstwa potok CI/CD powinien zawierac skanowanie zaleznosci (npm audit, OWASP Dependency-Check), skanowanie kodu SAST (Static Application Security Testing) z uzyciem narzedzi takich jak SonarQube lub Semgrep oraz sprawdzanie zgodnosci licencji. Sekrety takie jak hasla i klucze API powinny byc przechowywane w dedykowanych magazynach i wstrzykiwane do potoku jako zmienne srodowiskowe.