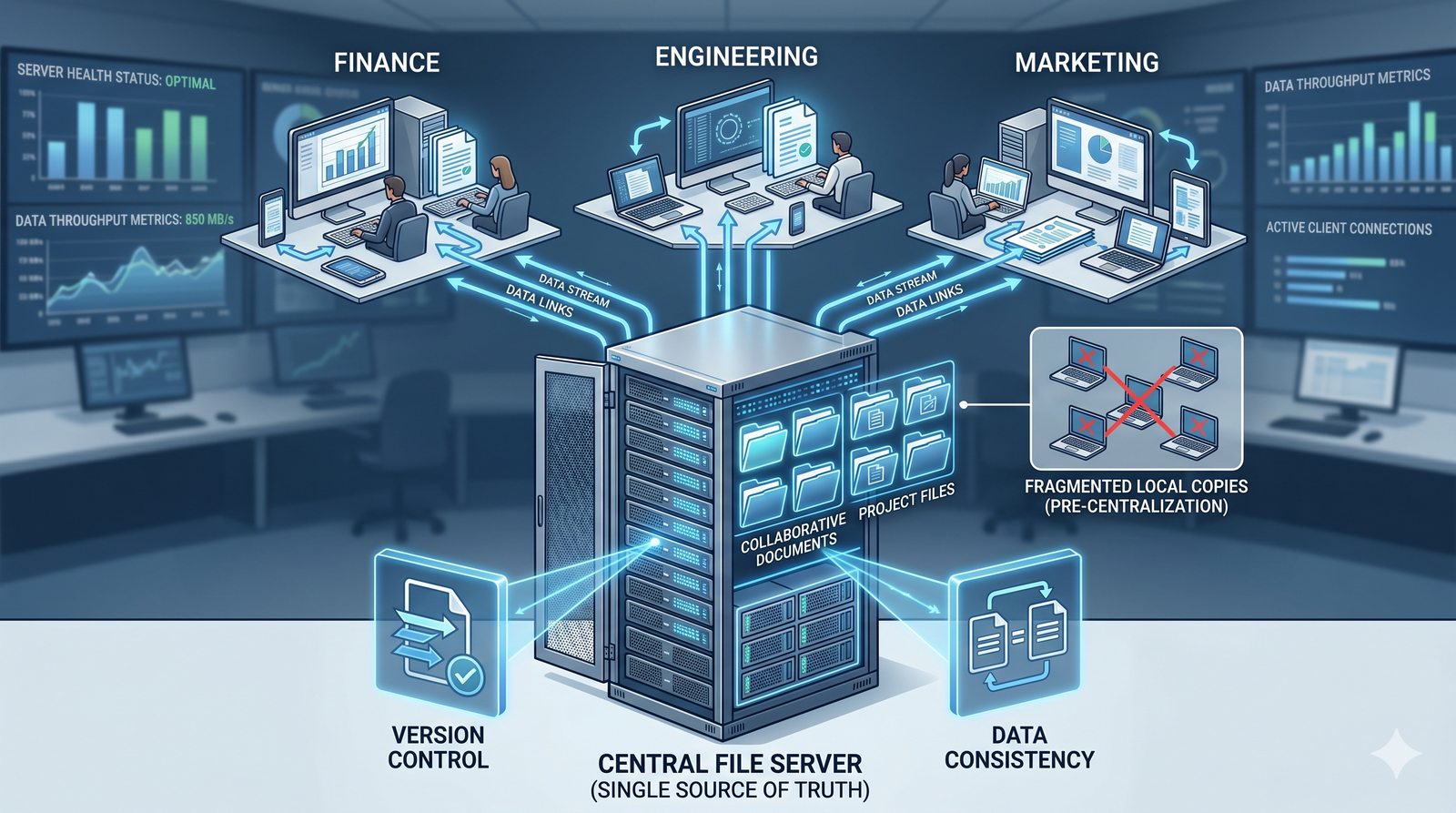
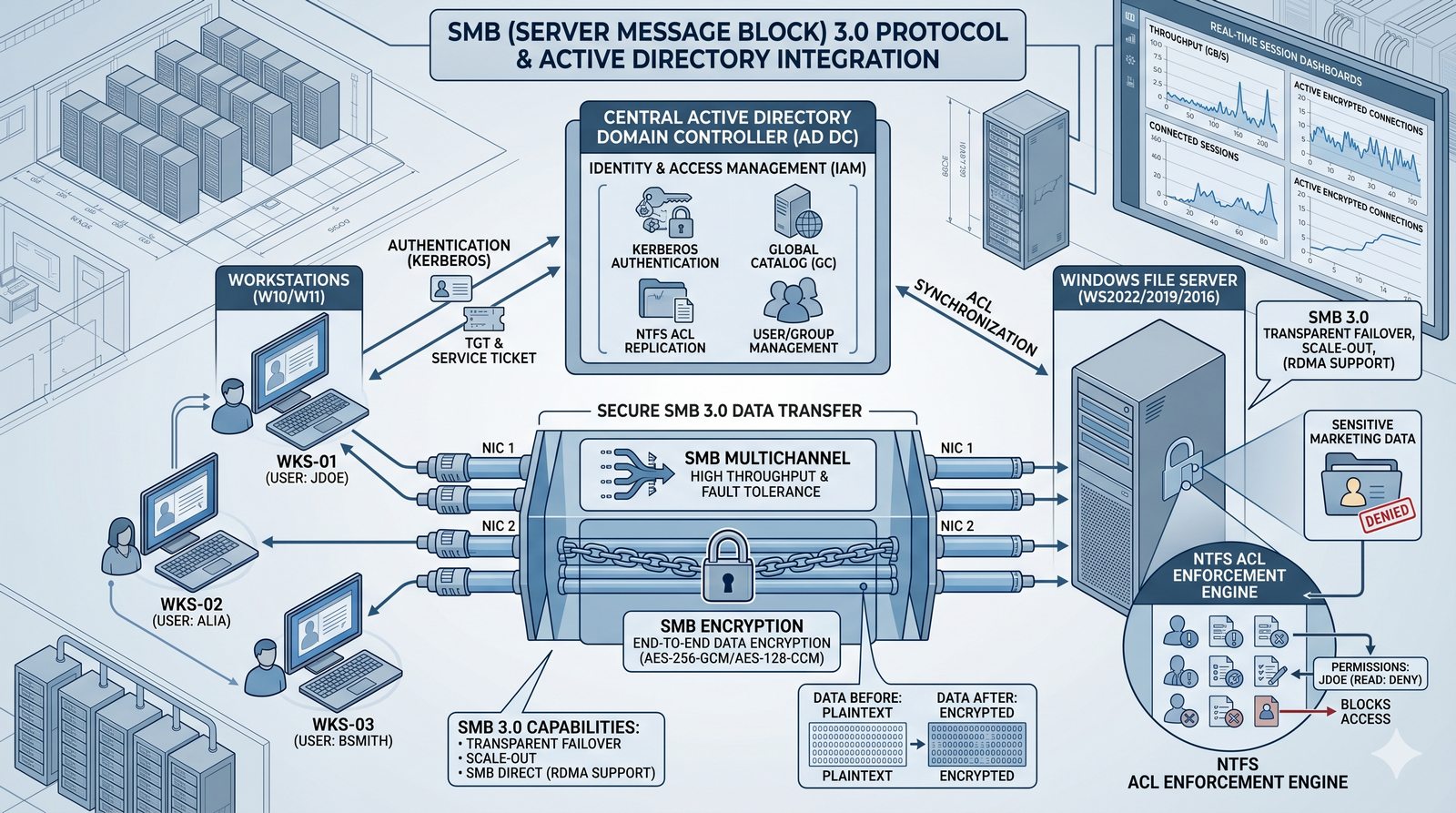
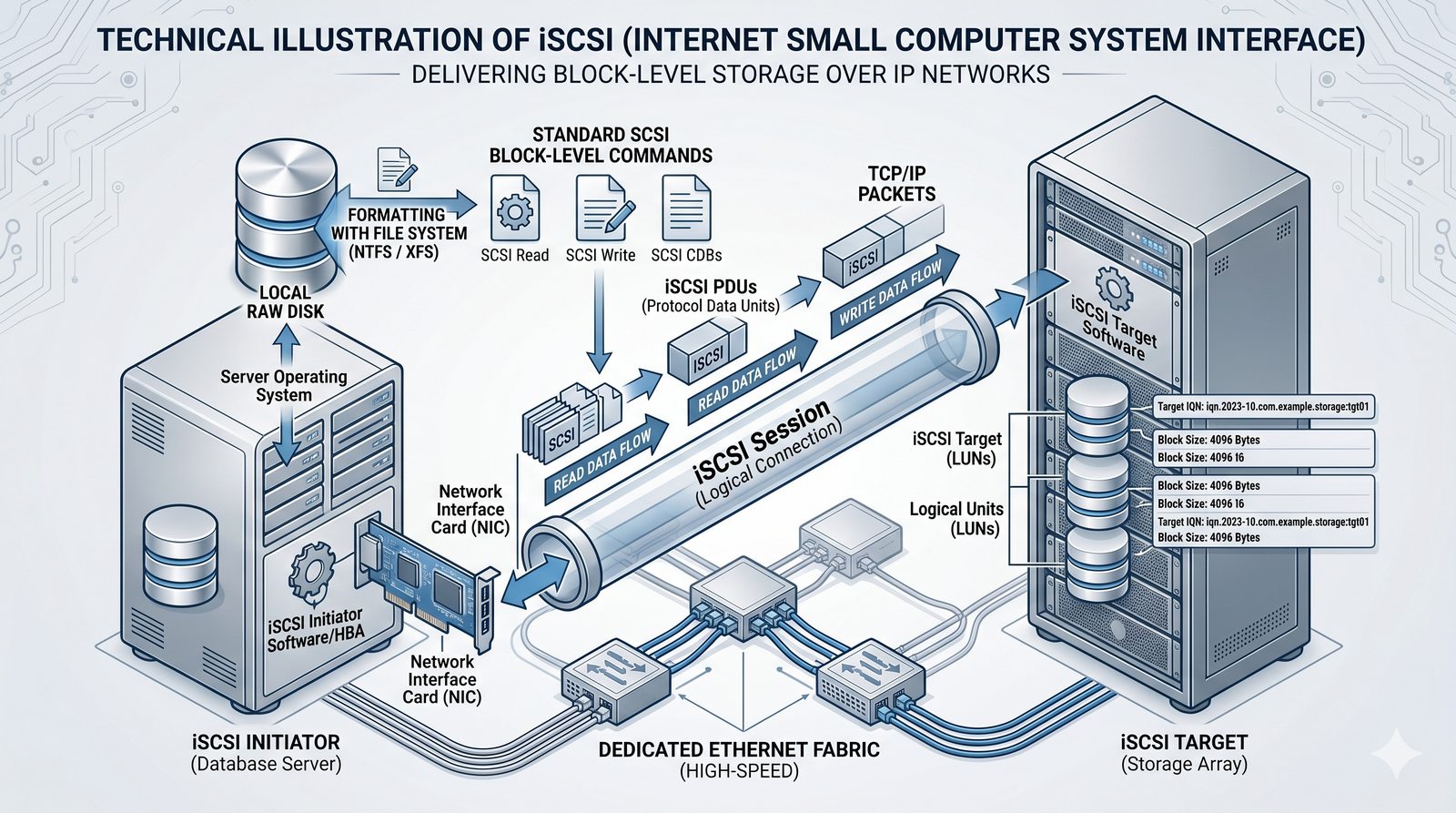
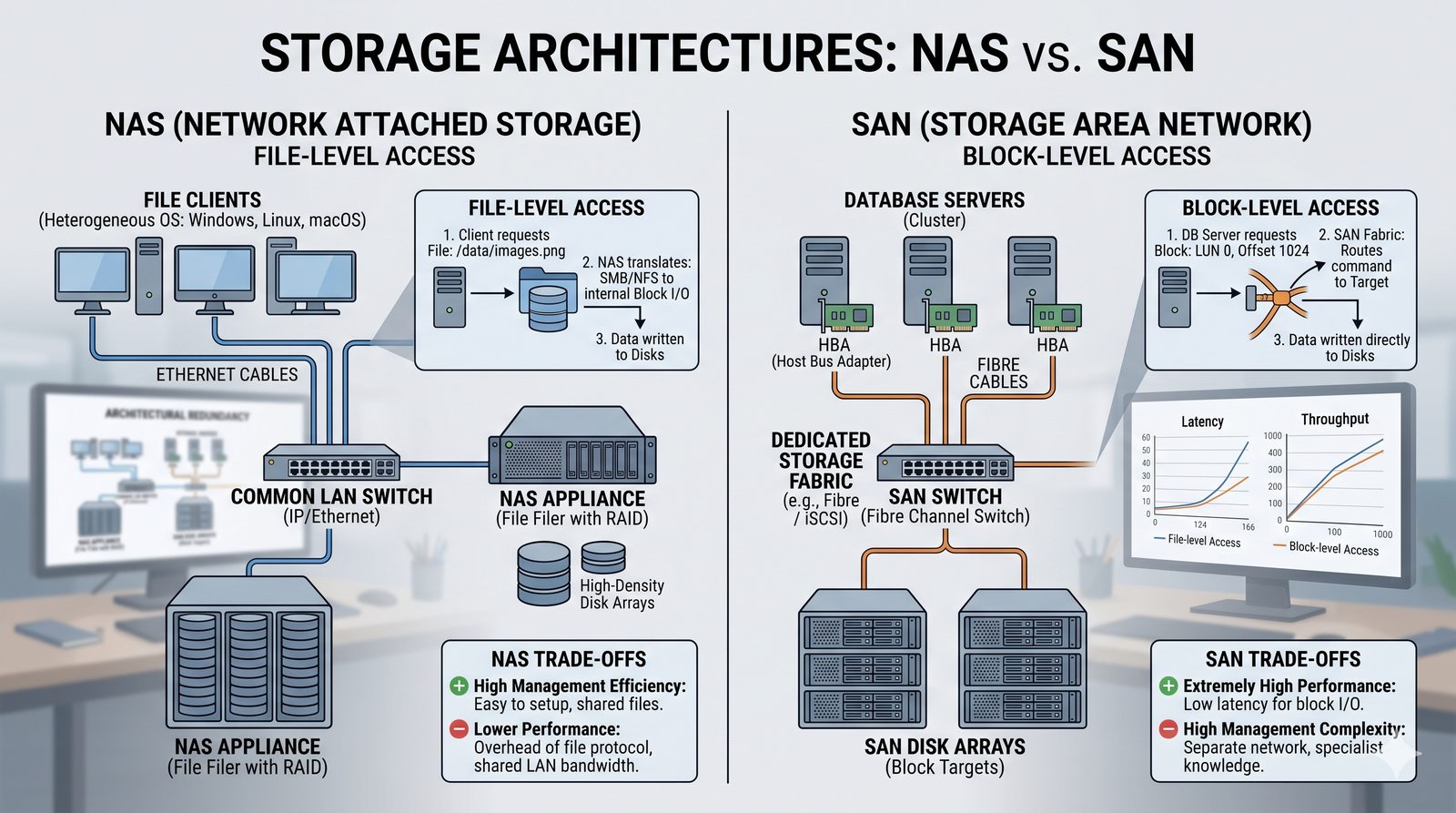
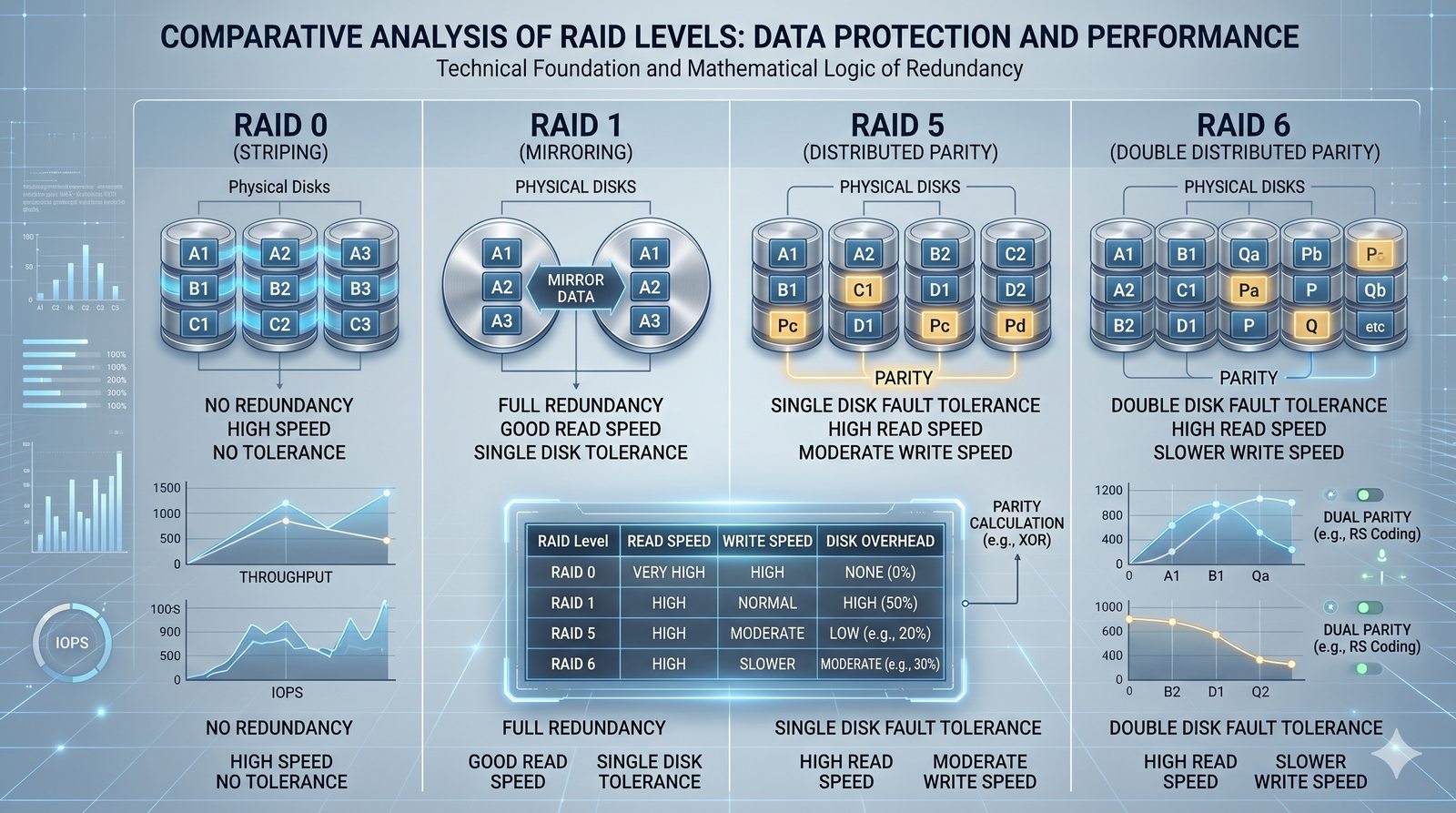
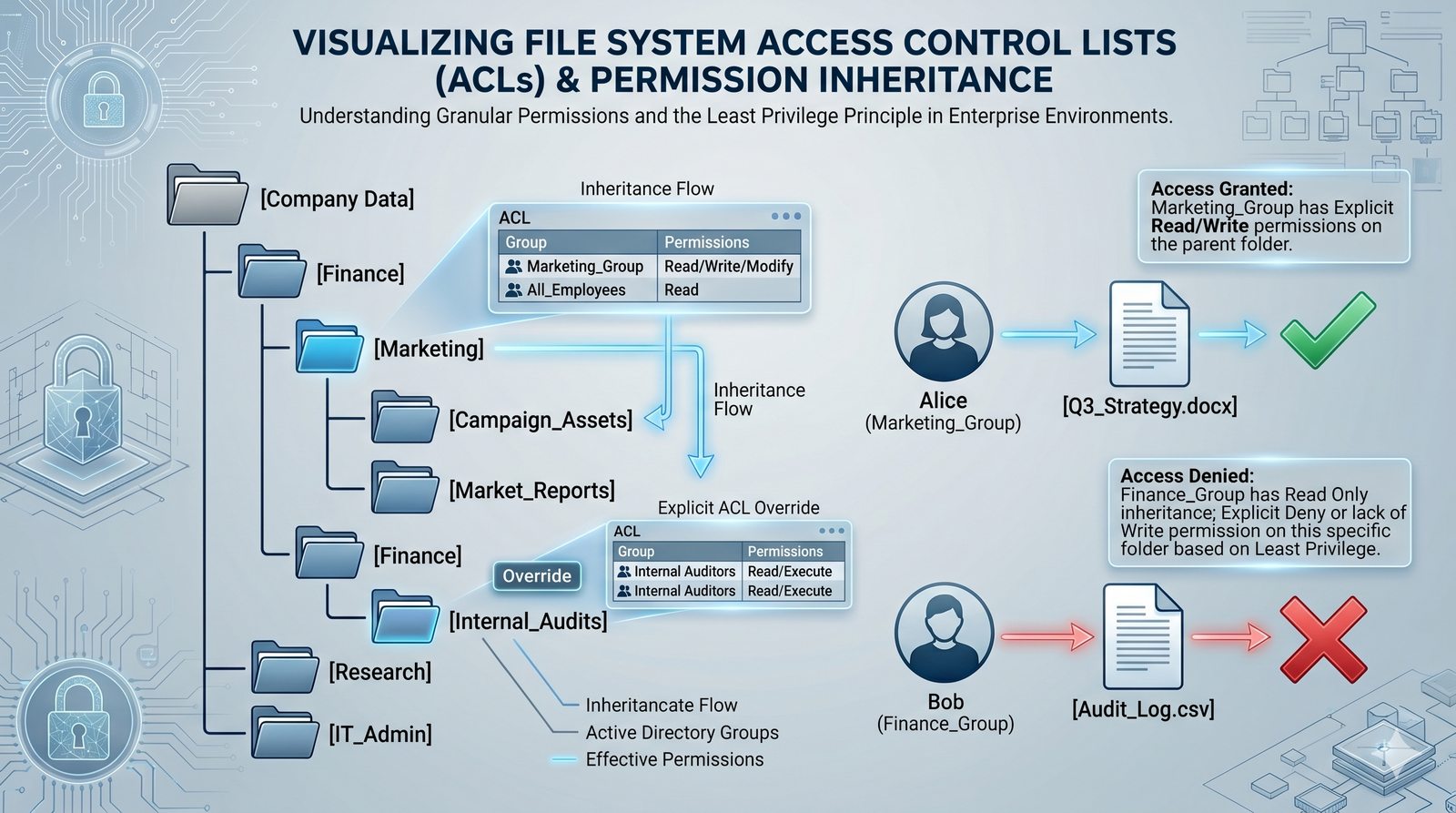
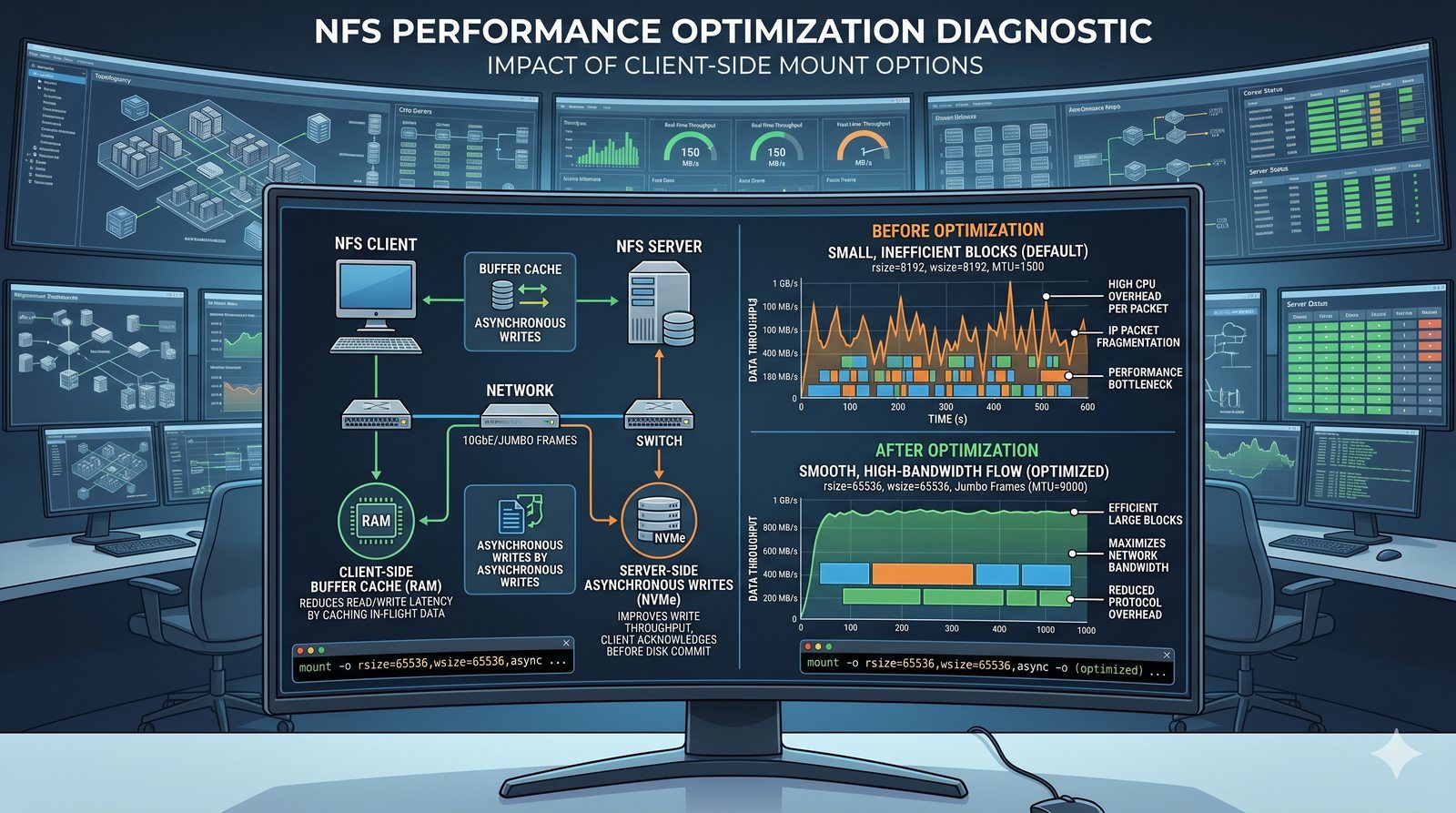
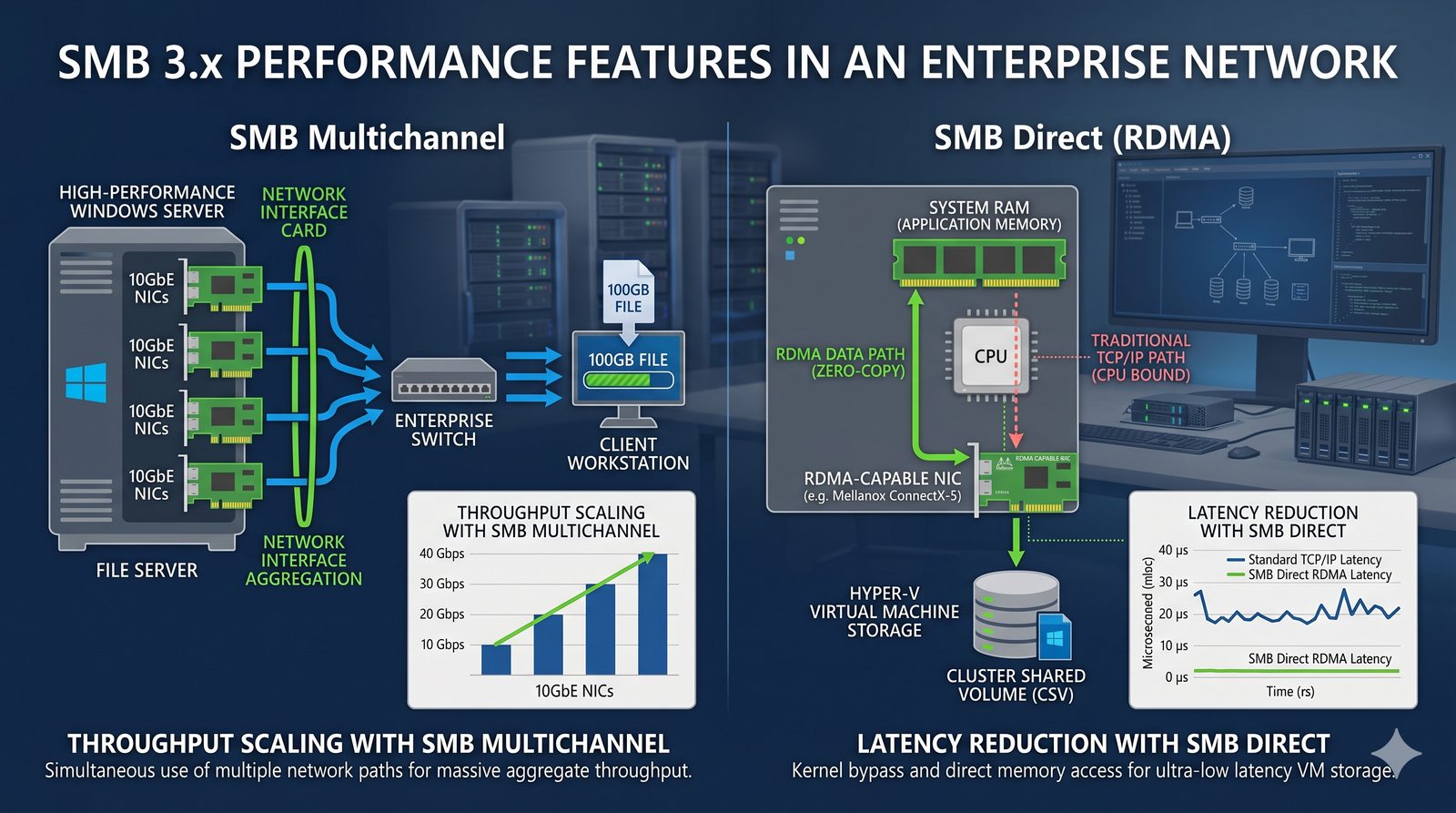
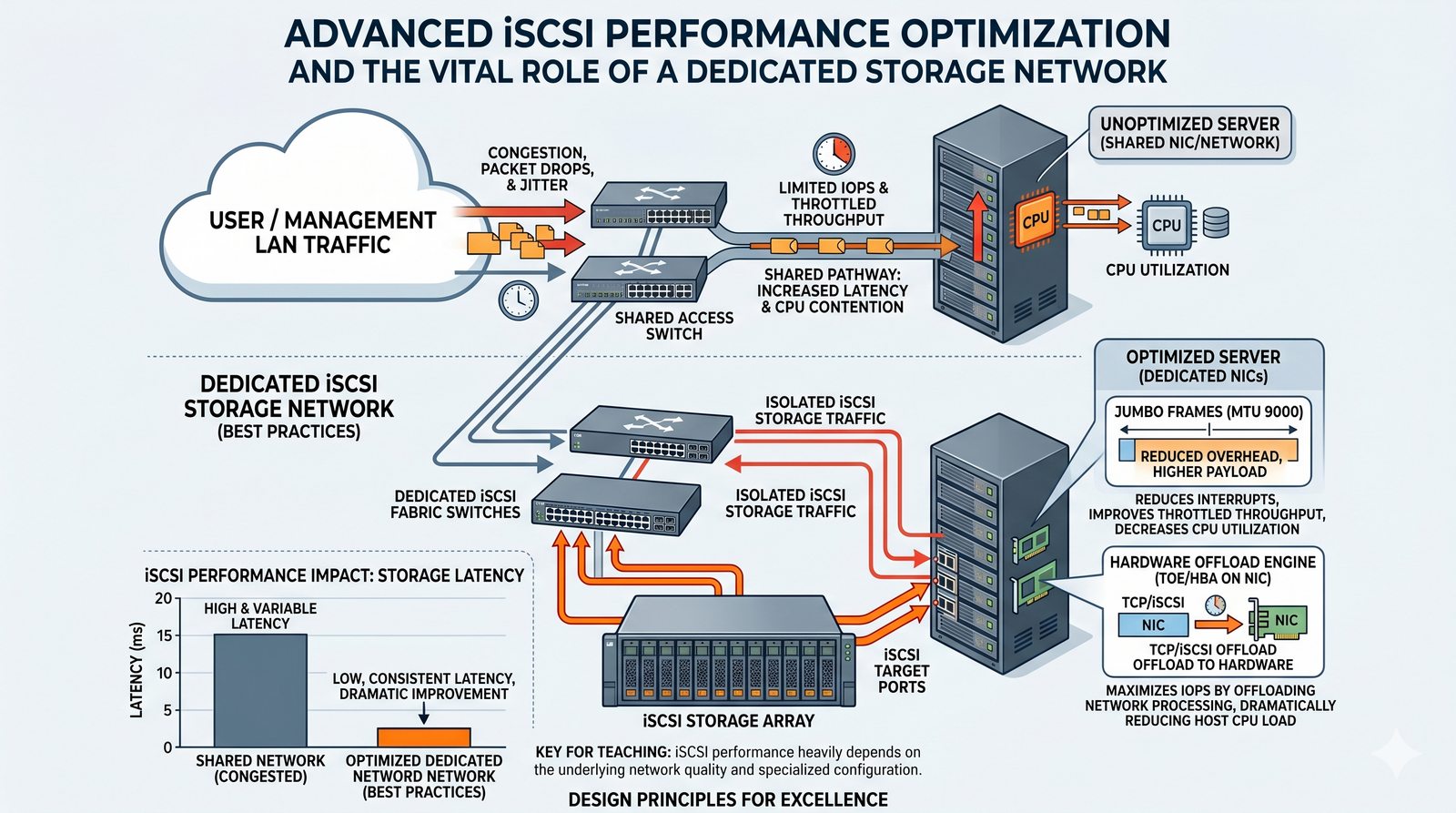
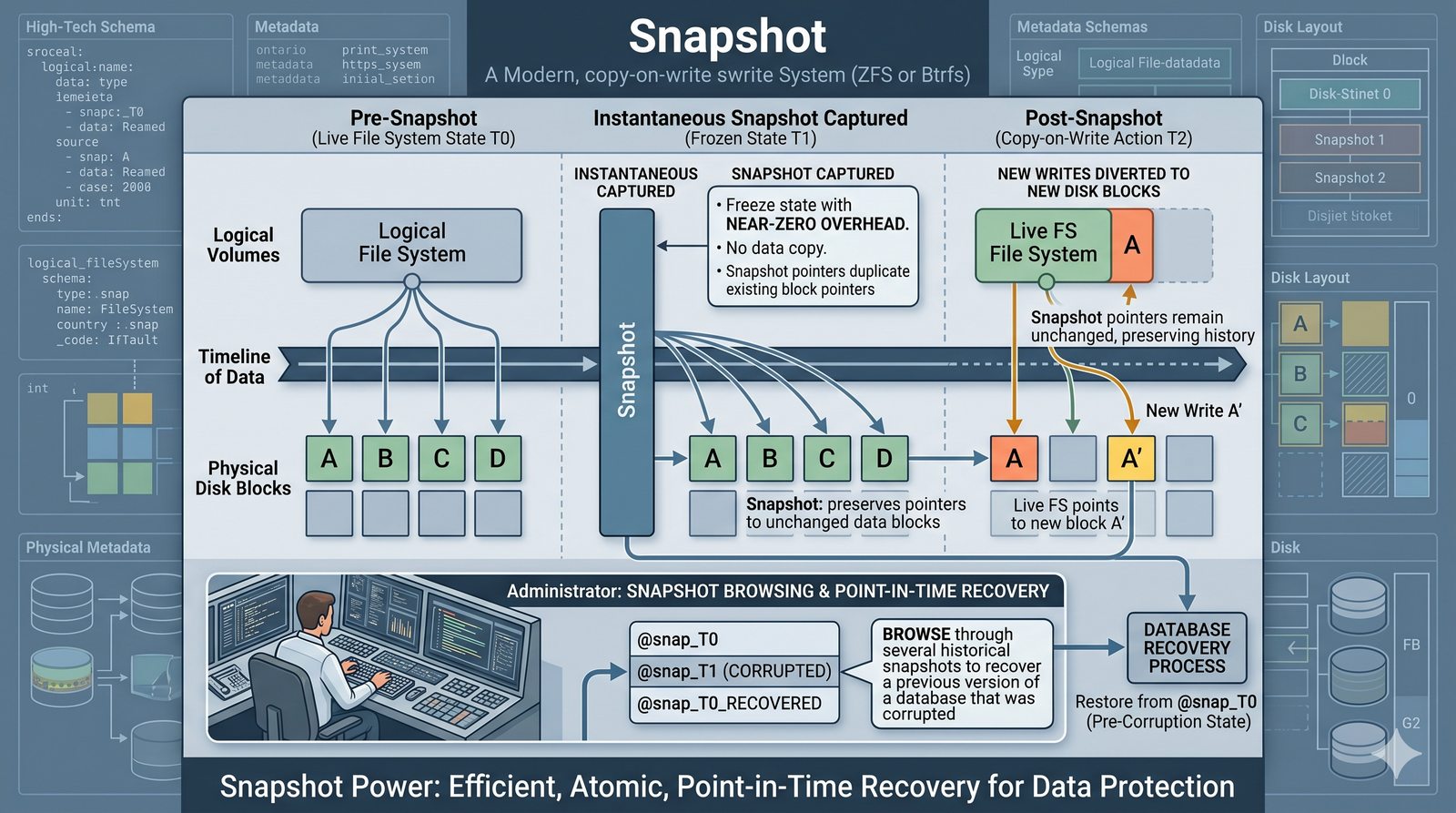
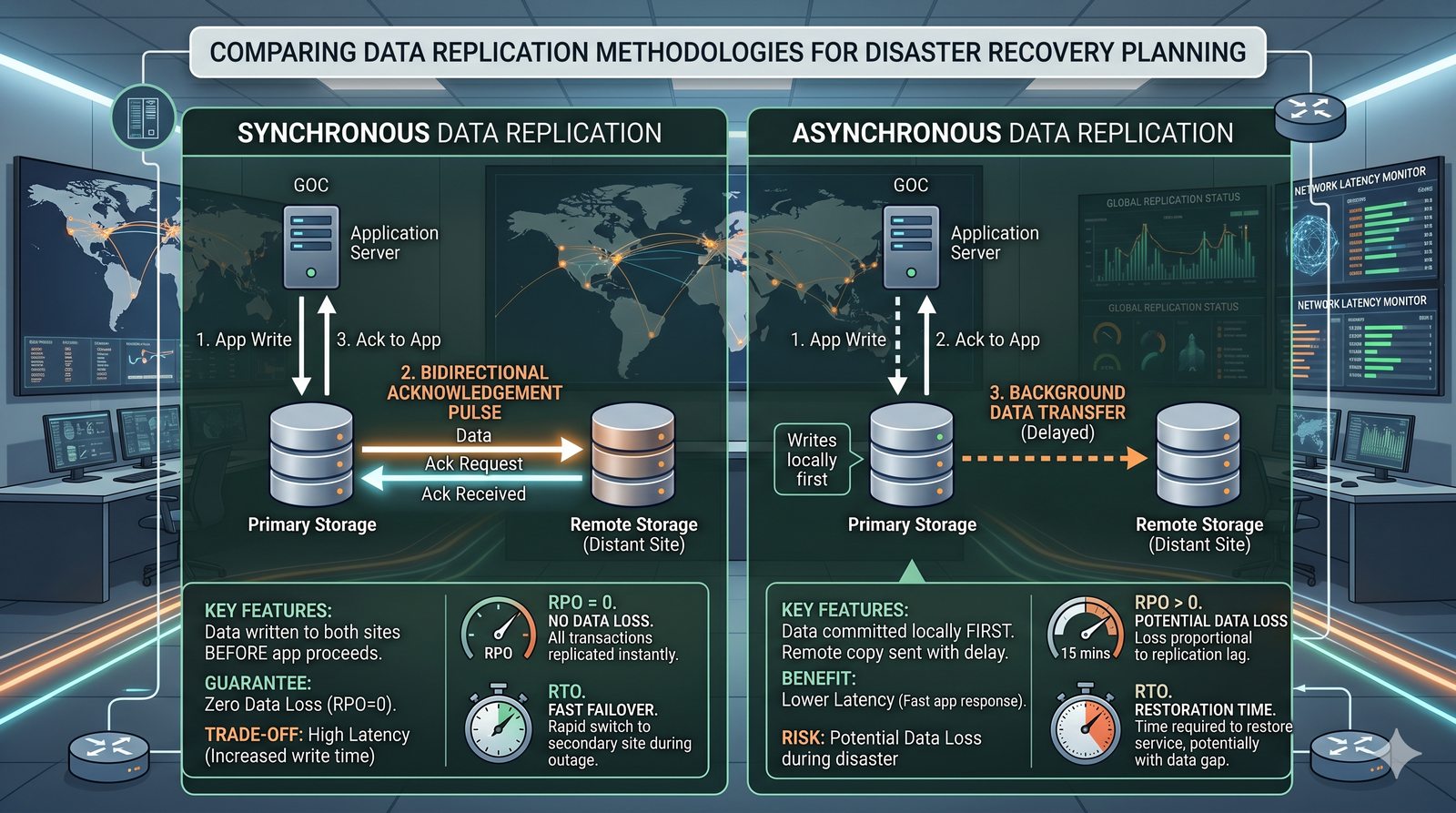
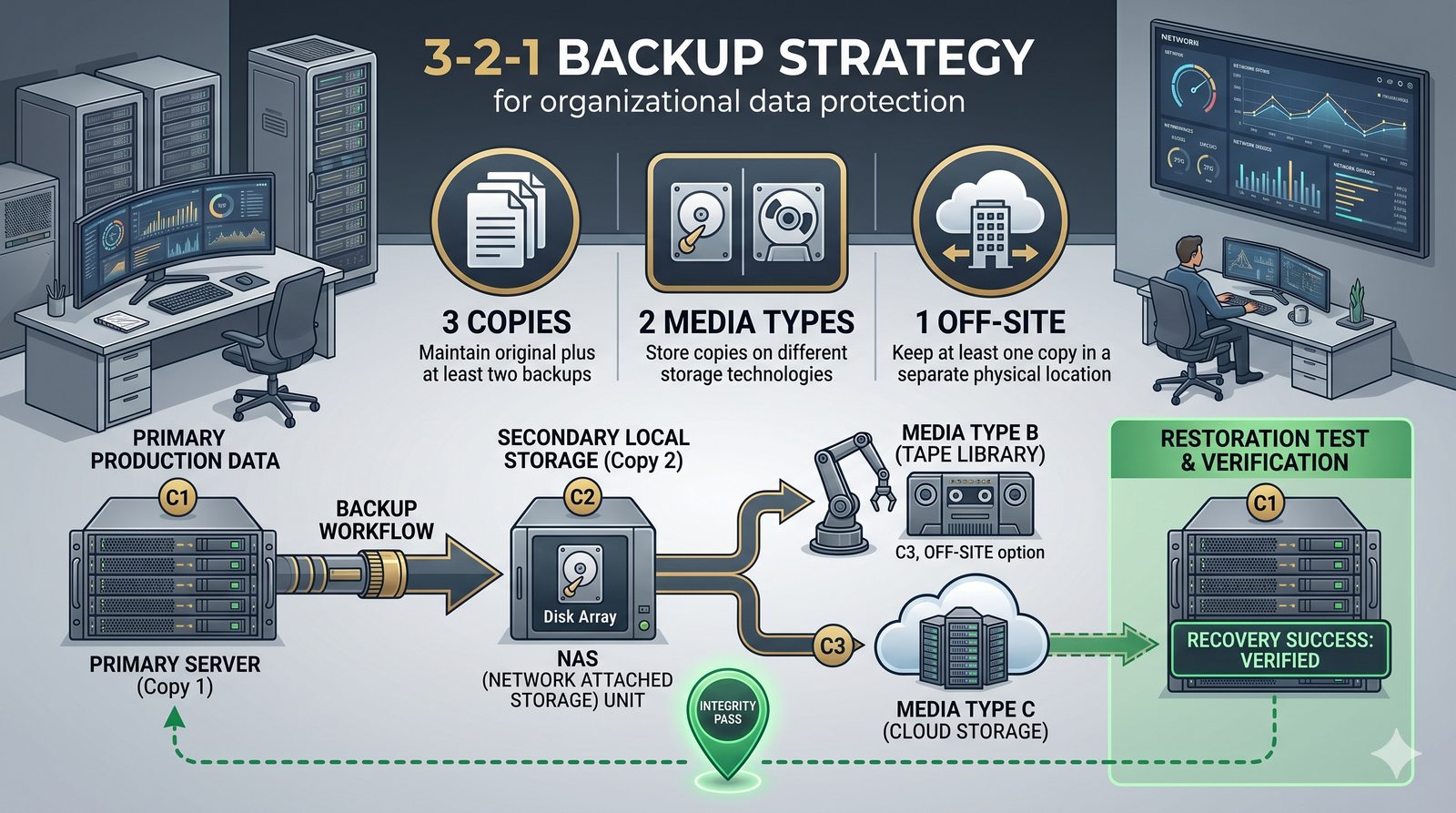
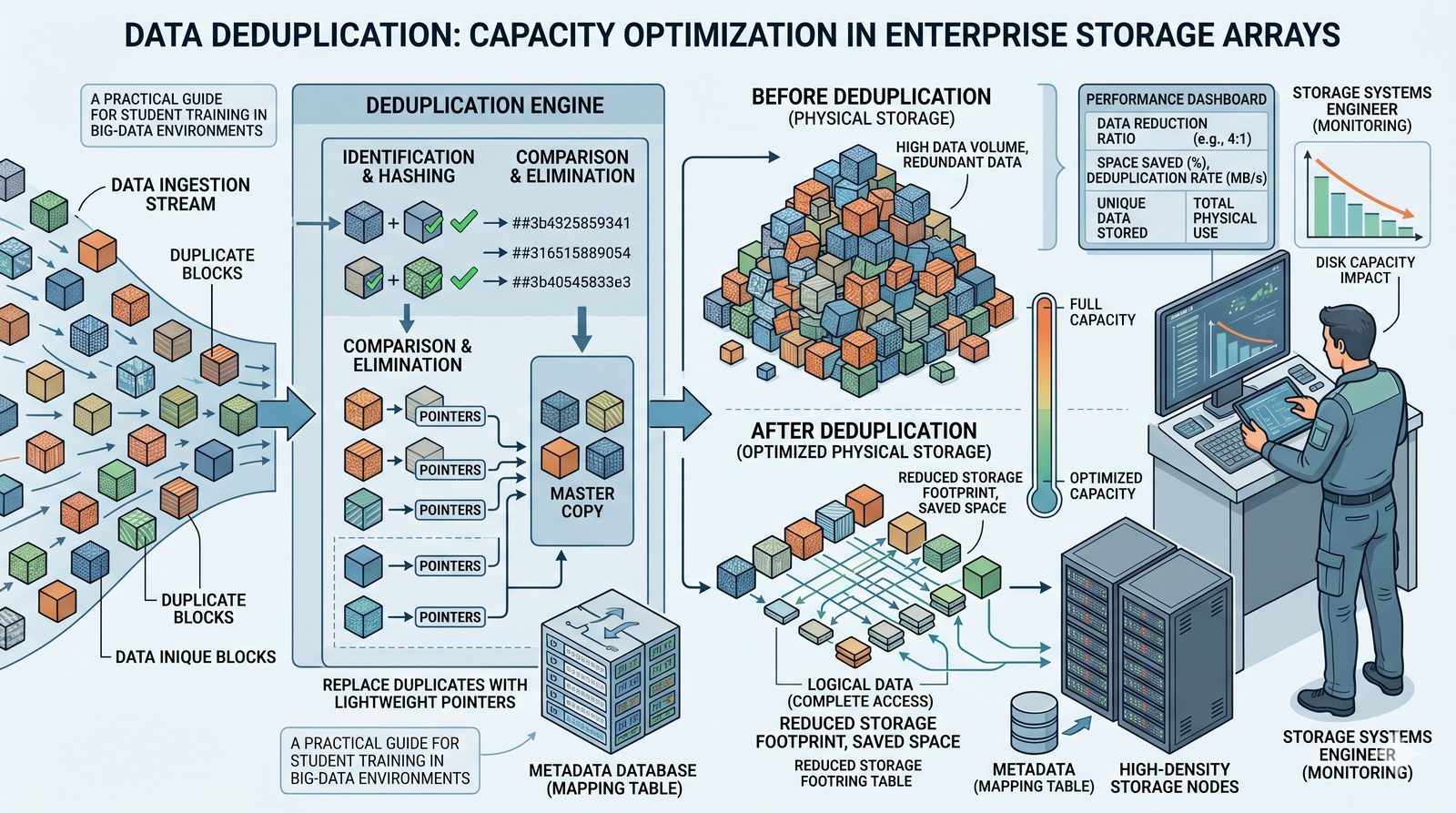
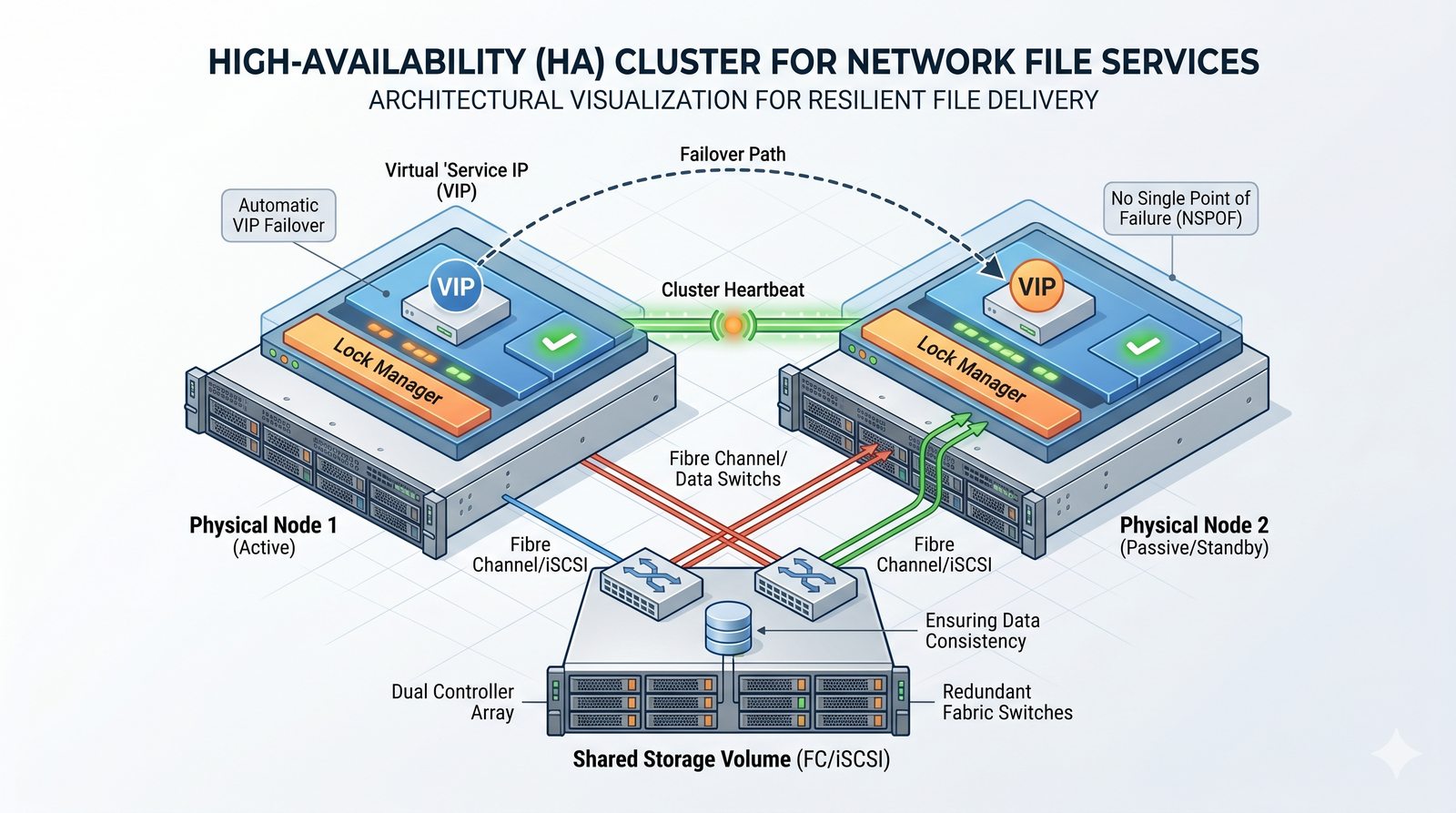
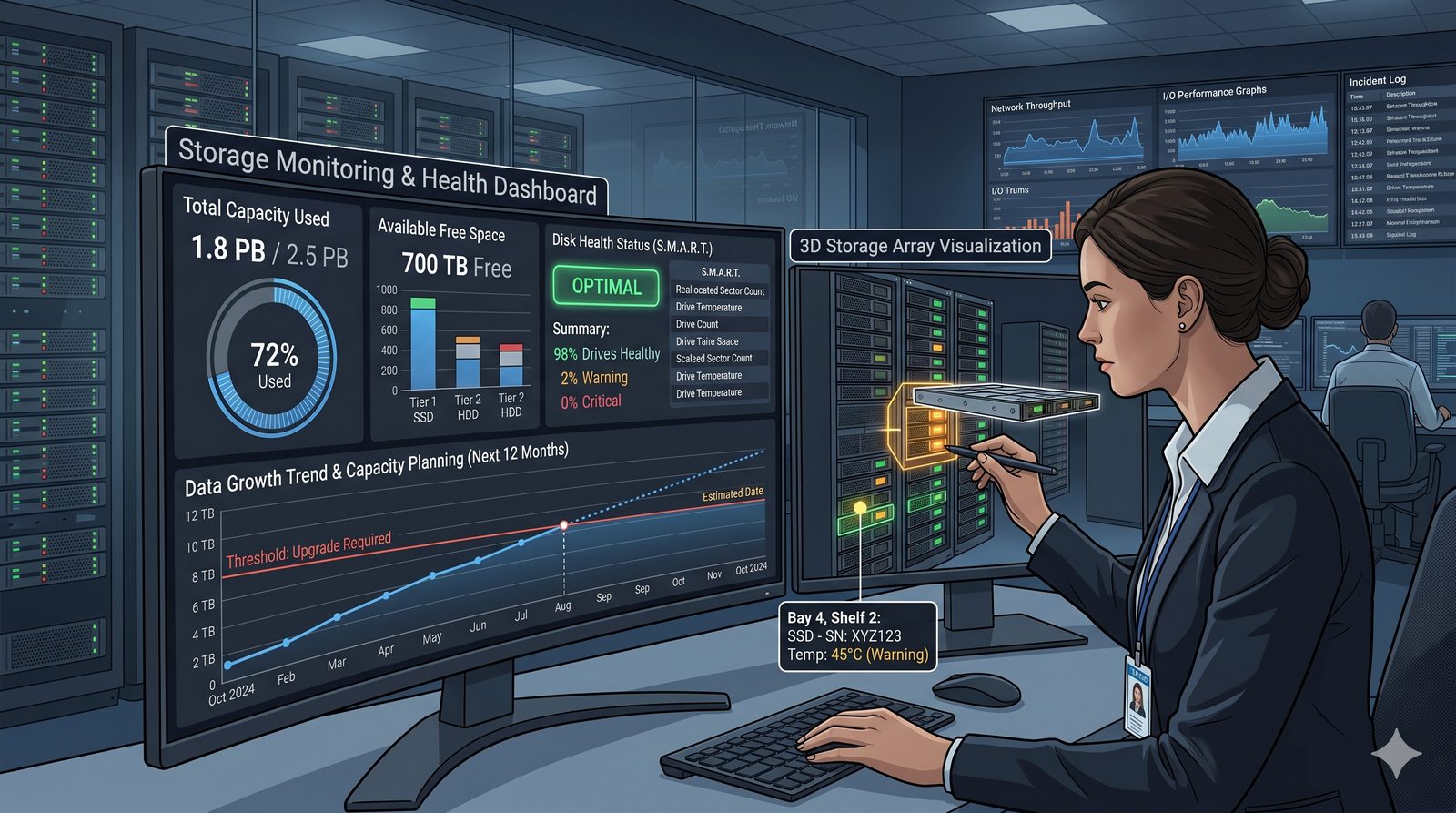
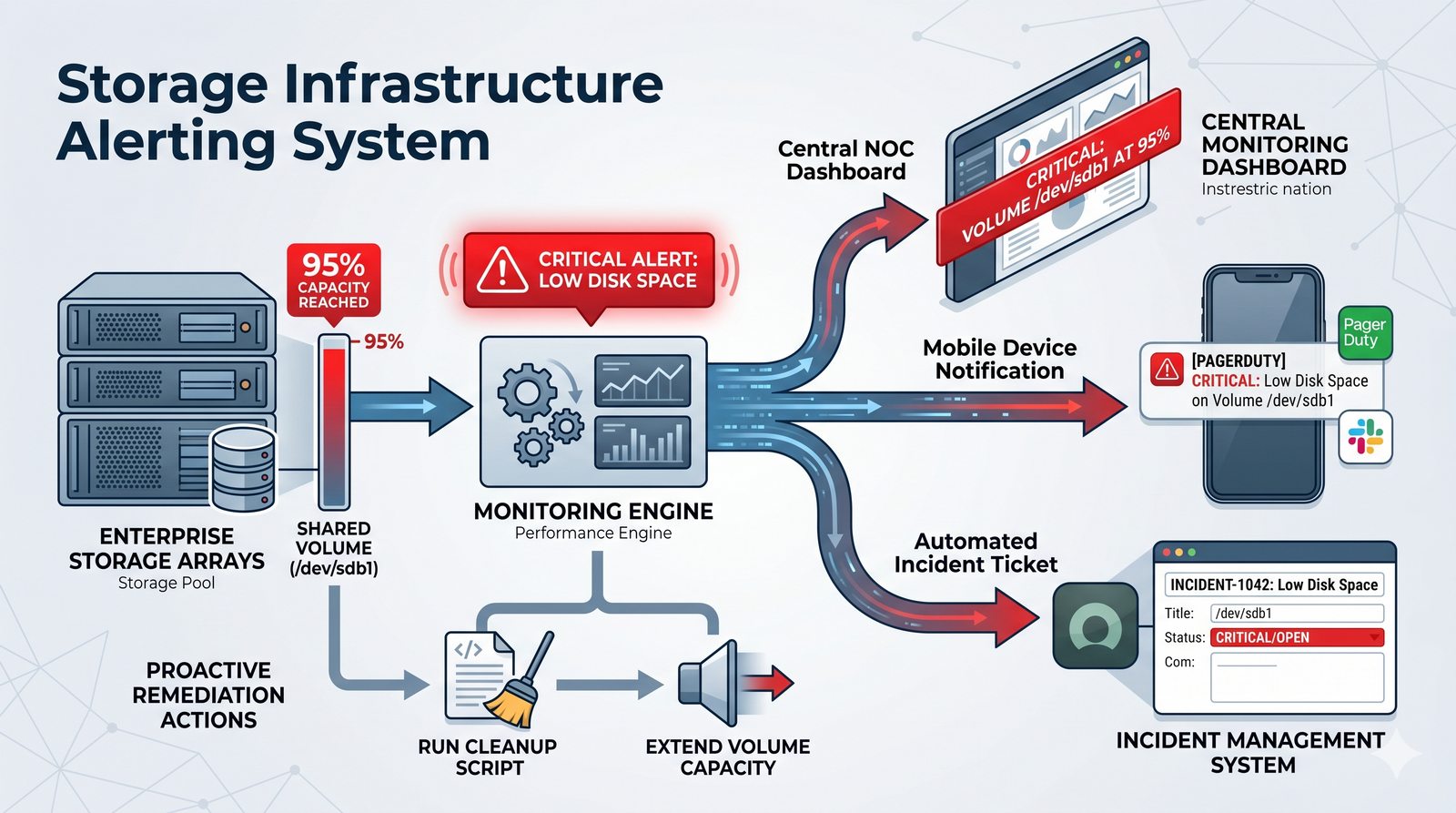
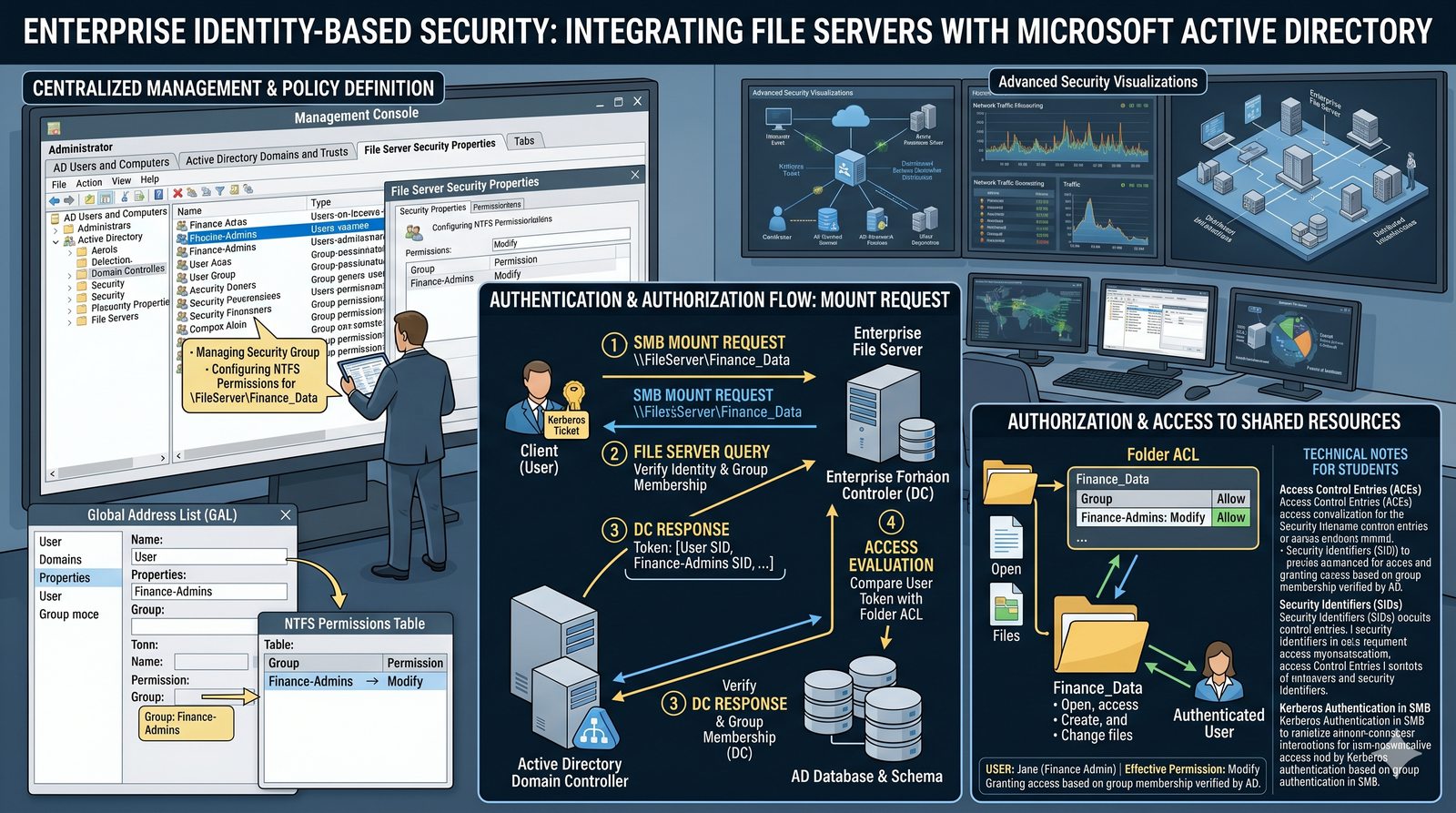
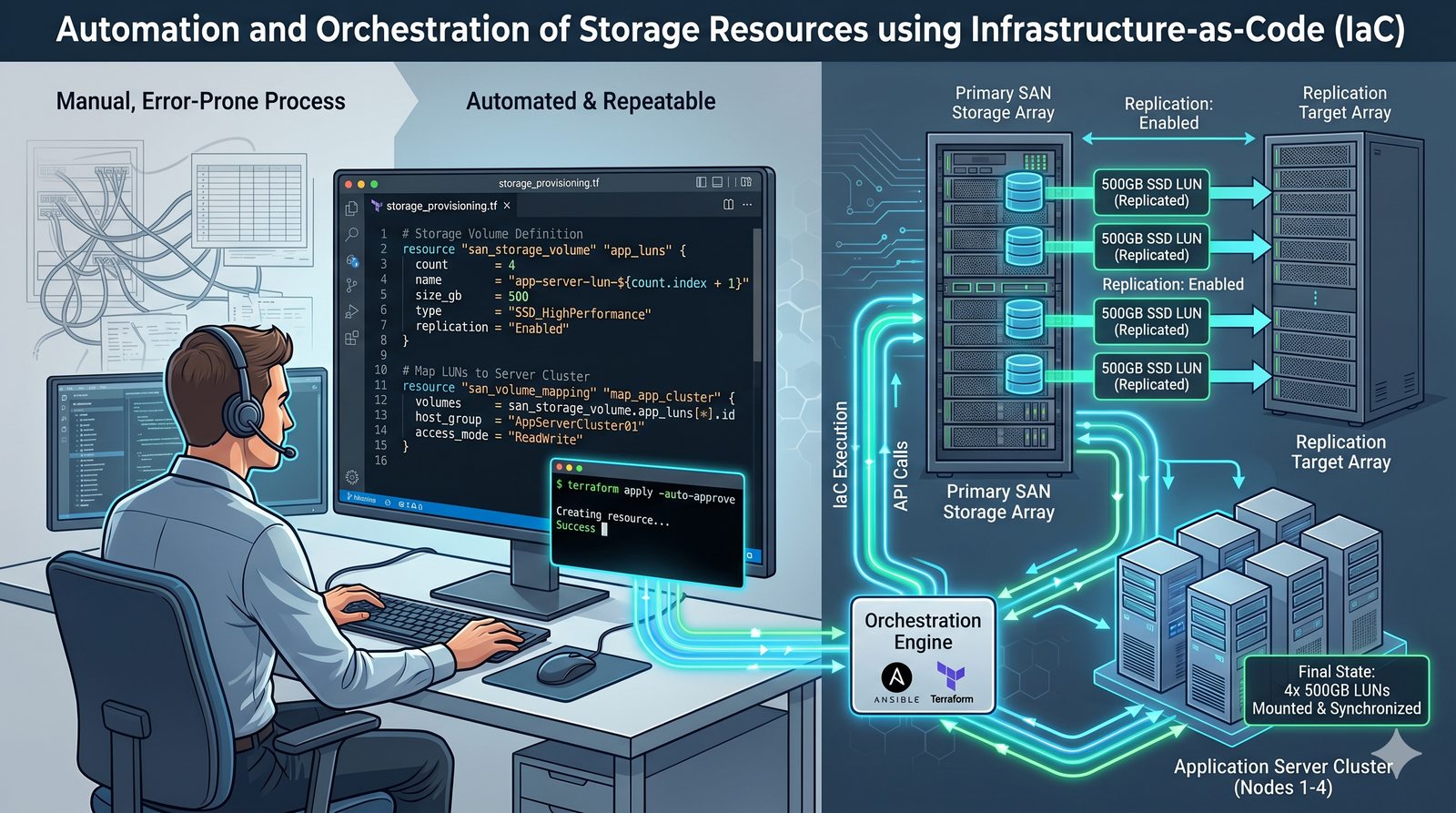
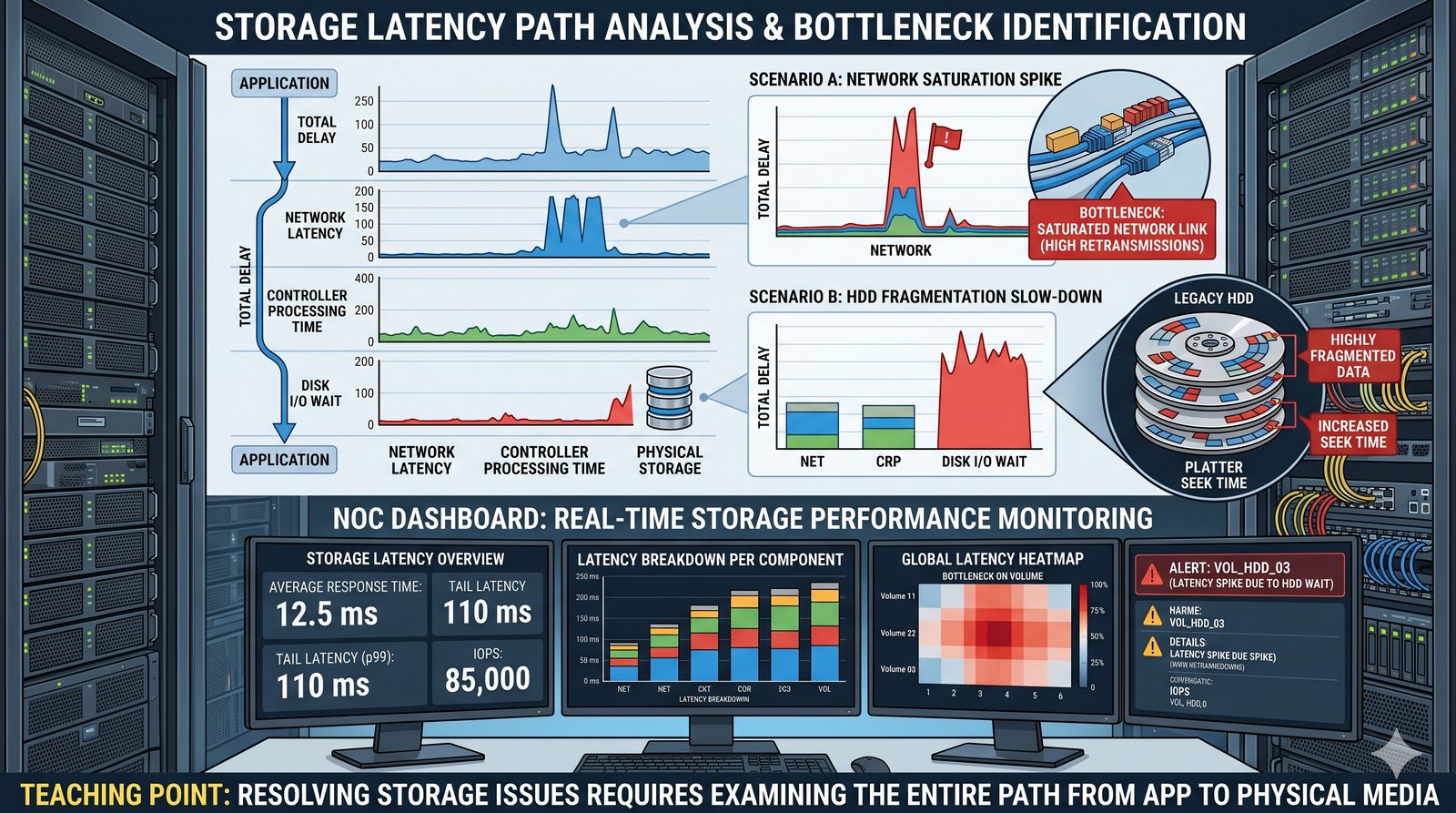
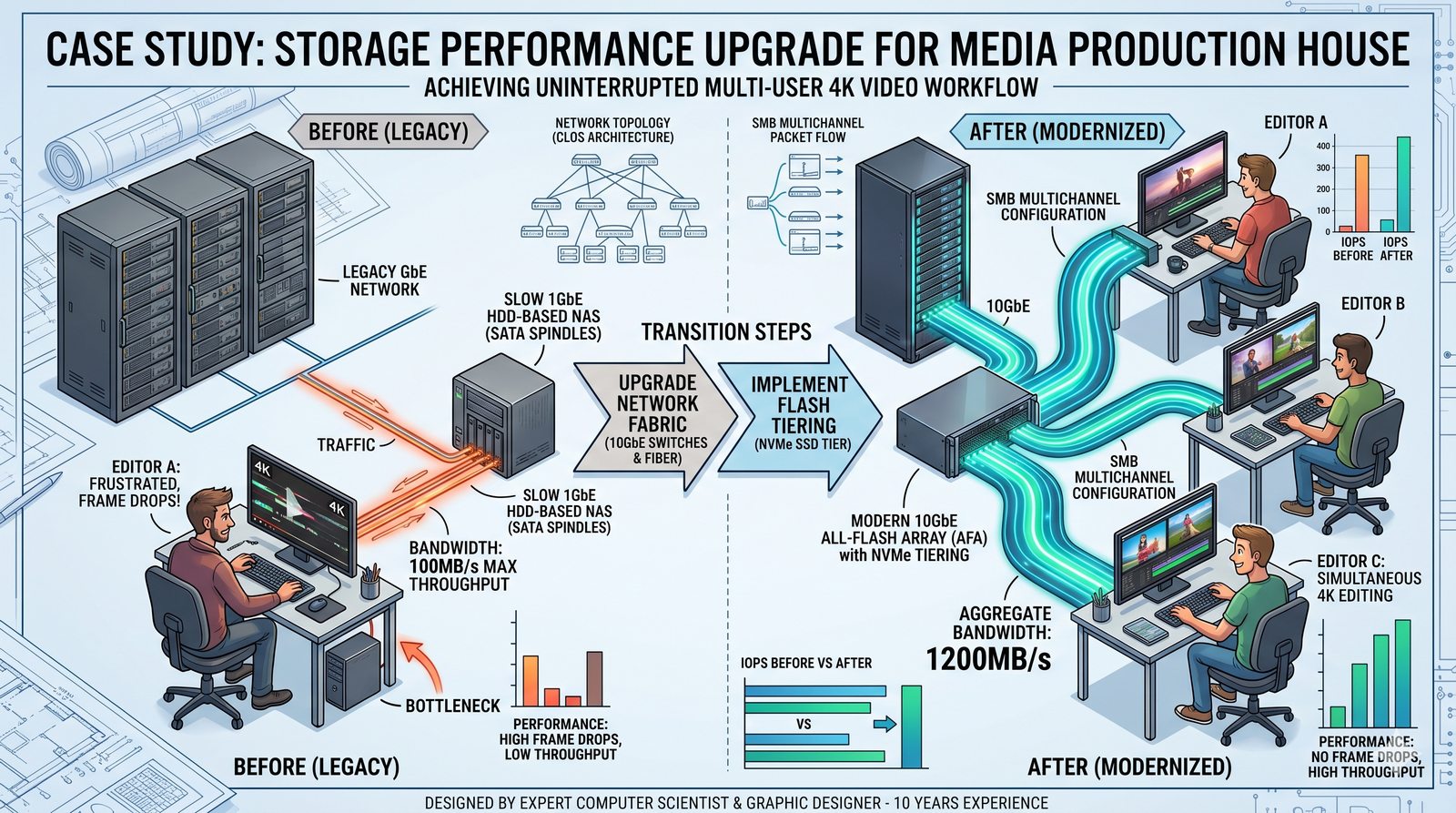
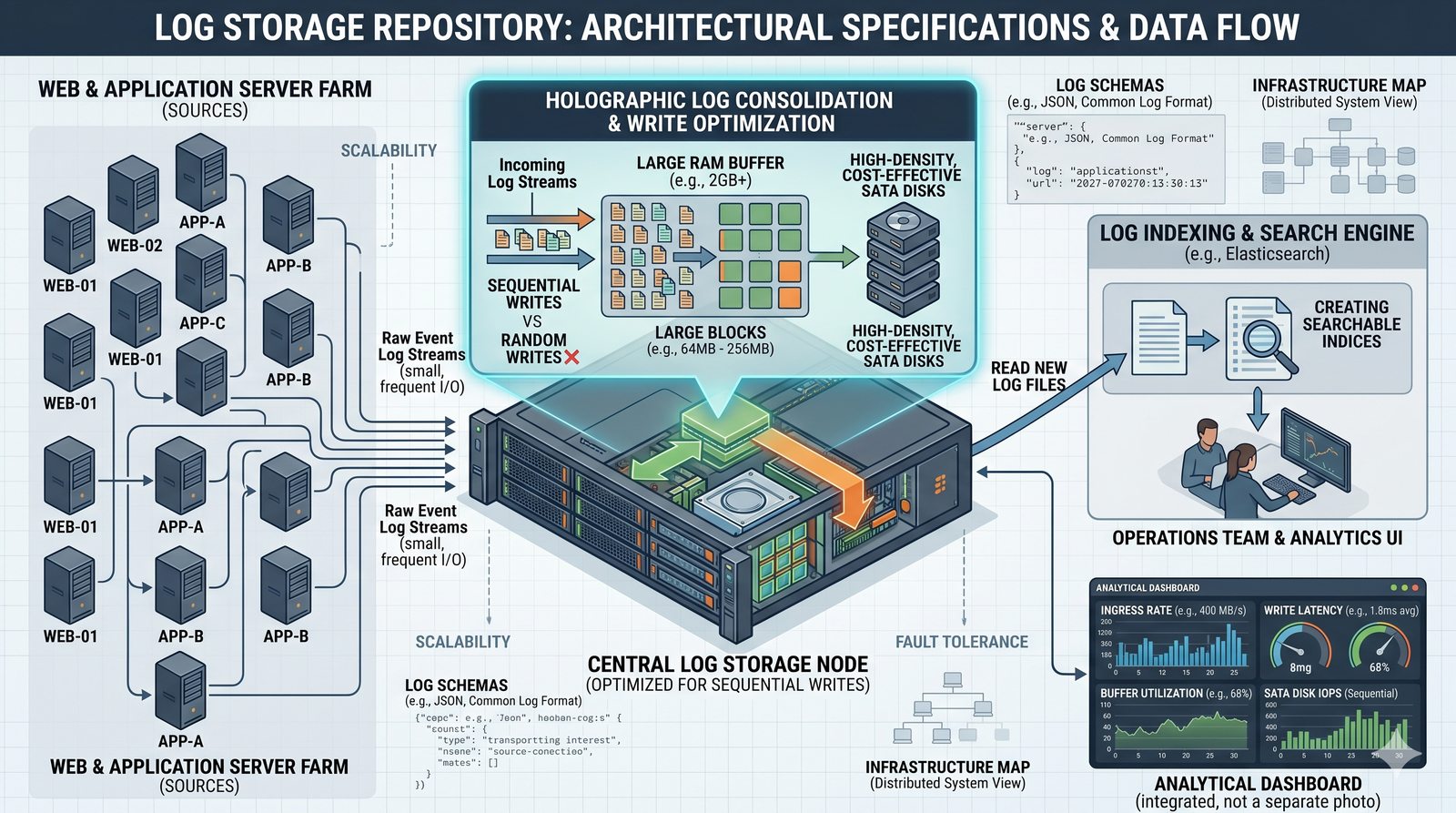
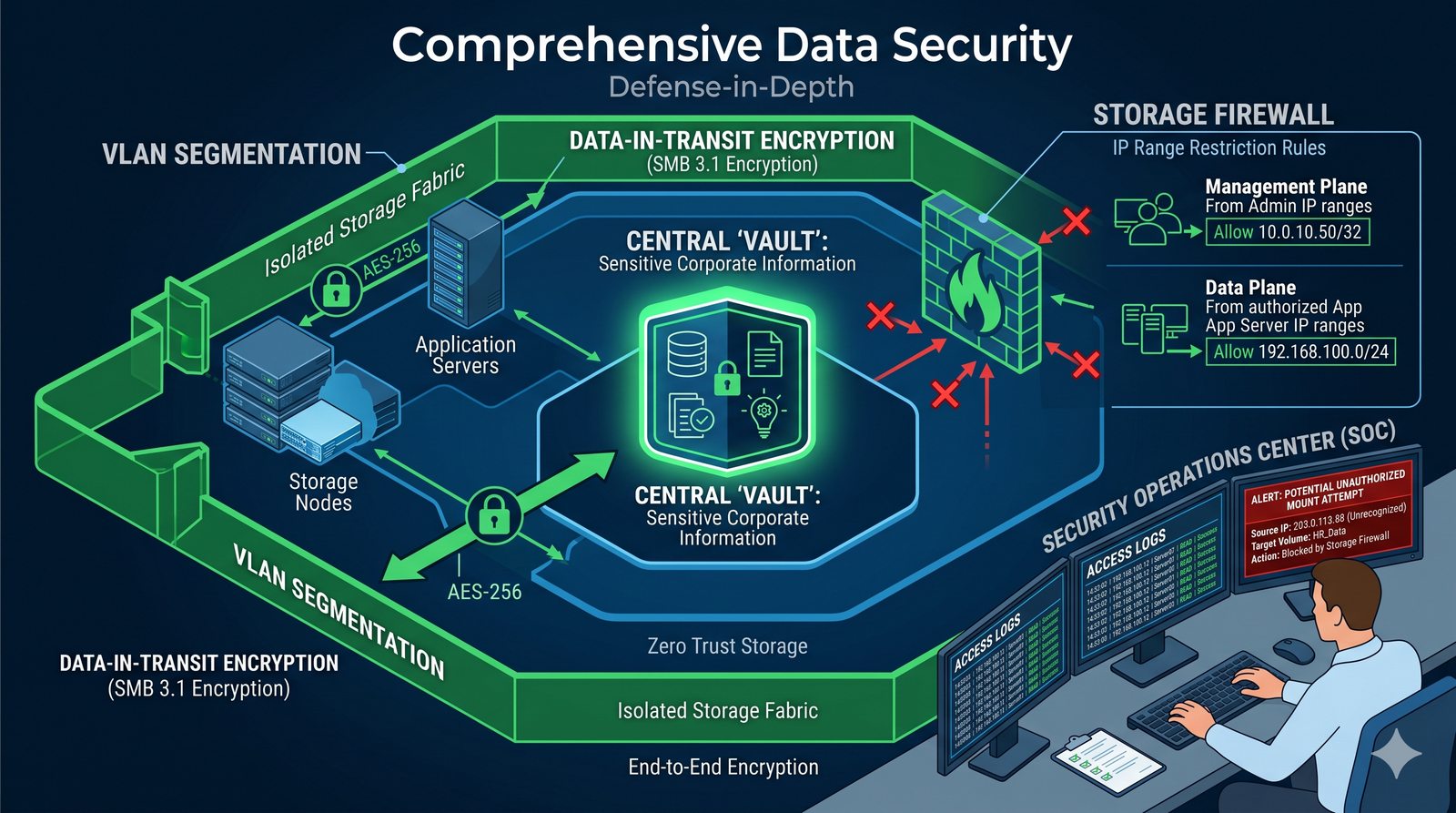
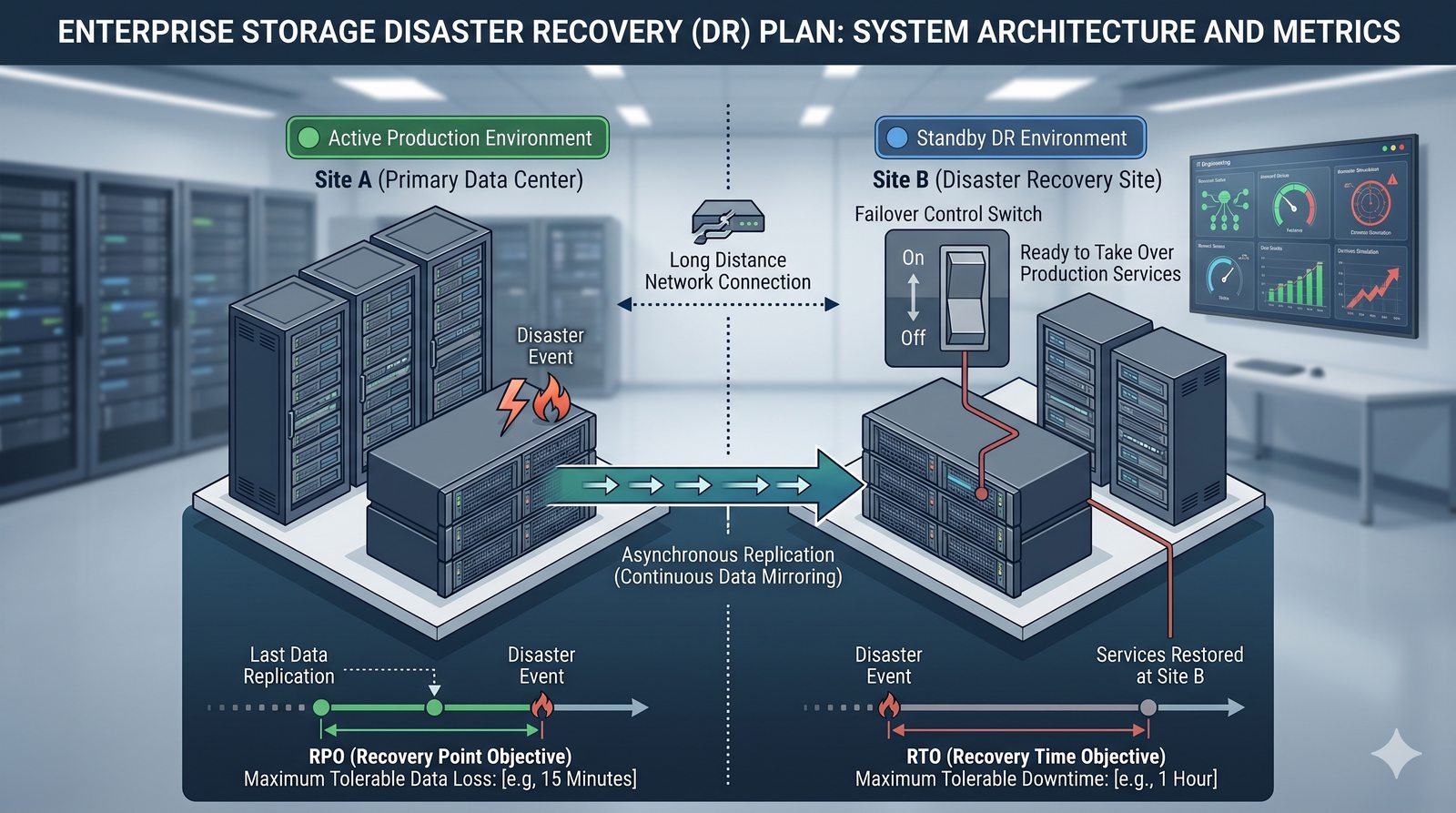
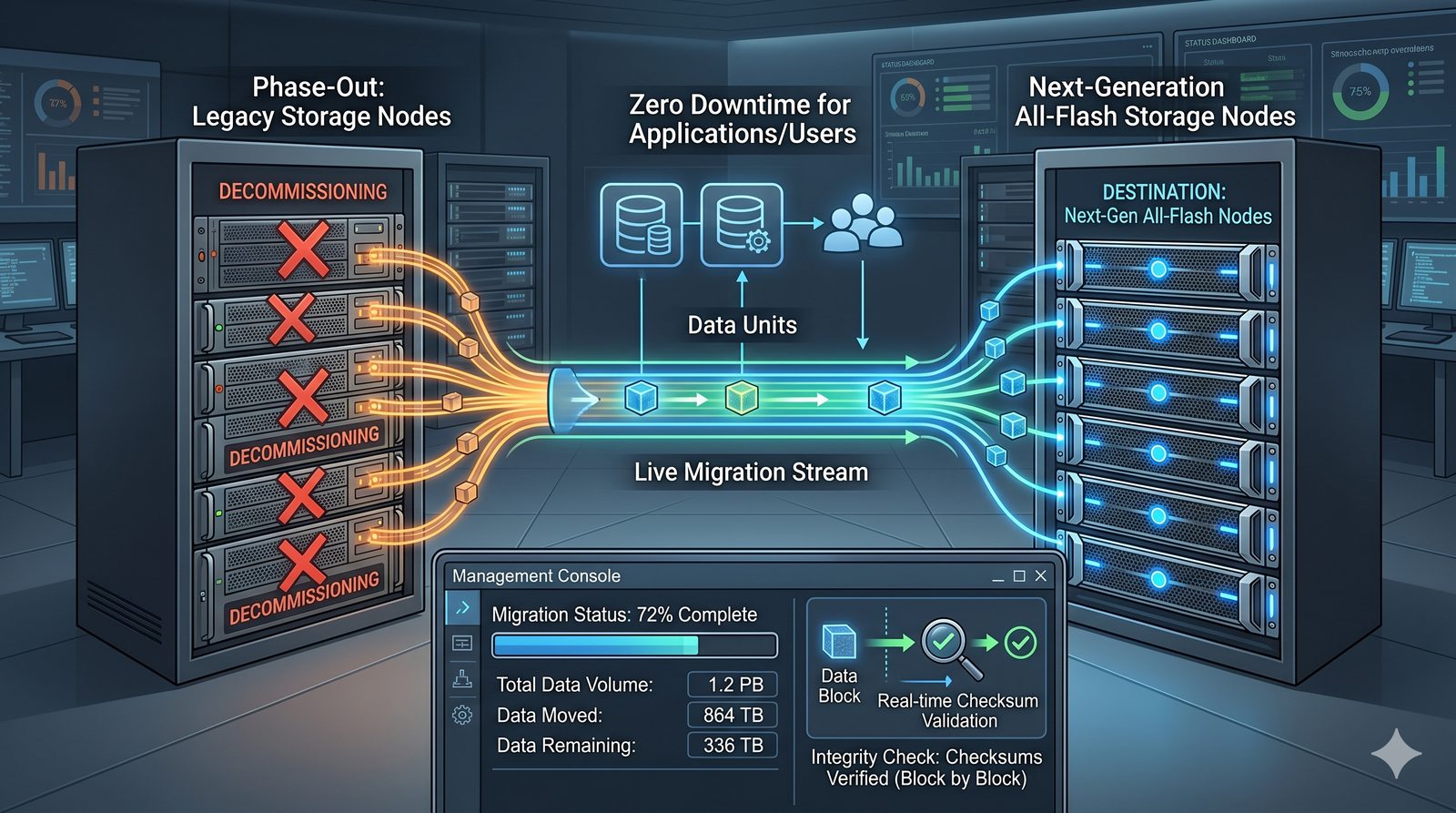
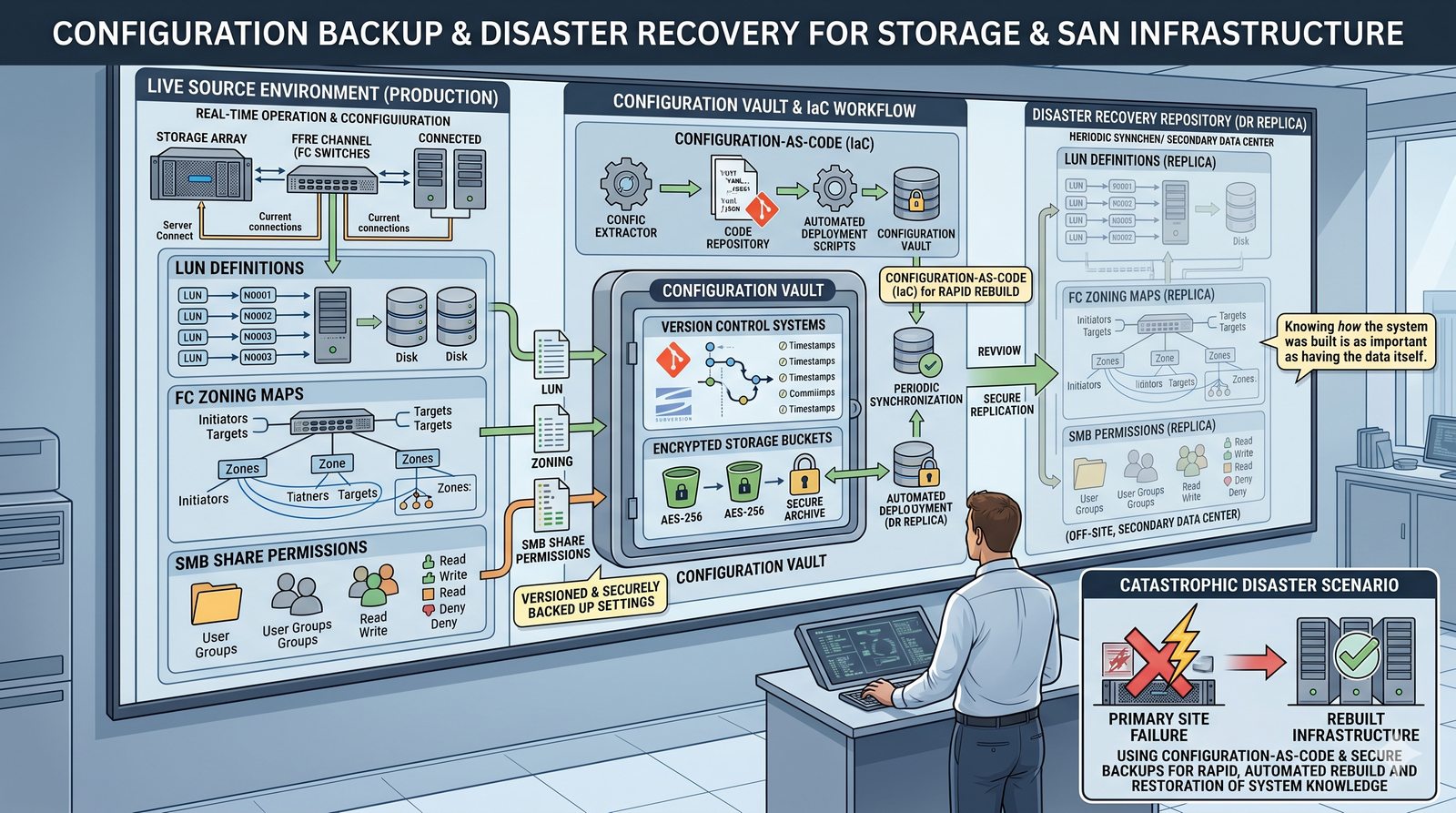
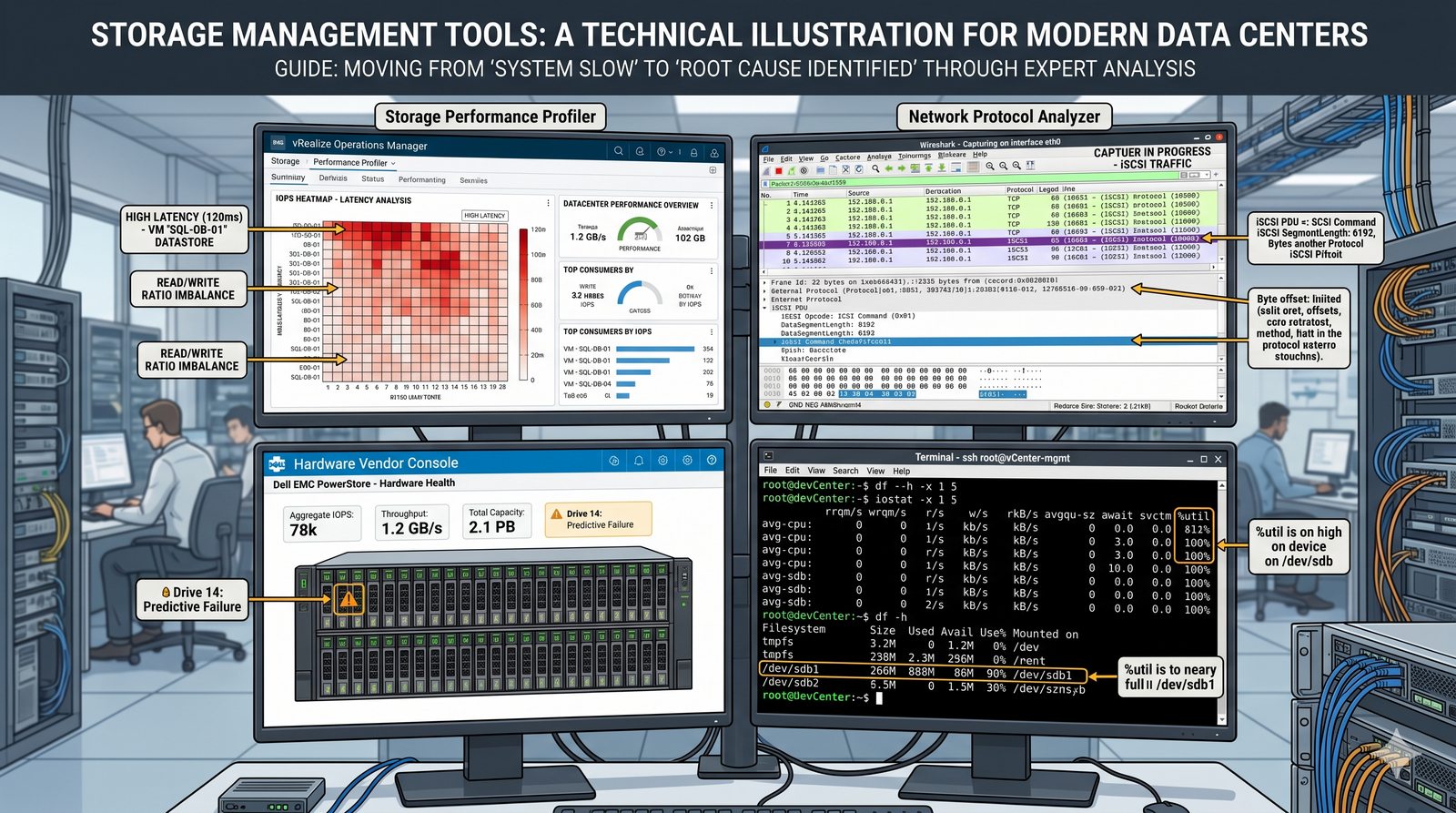
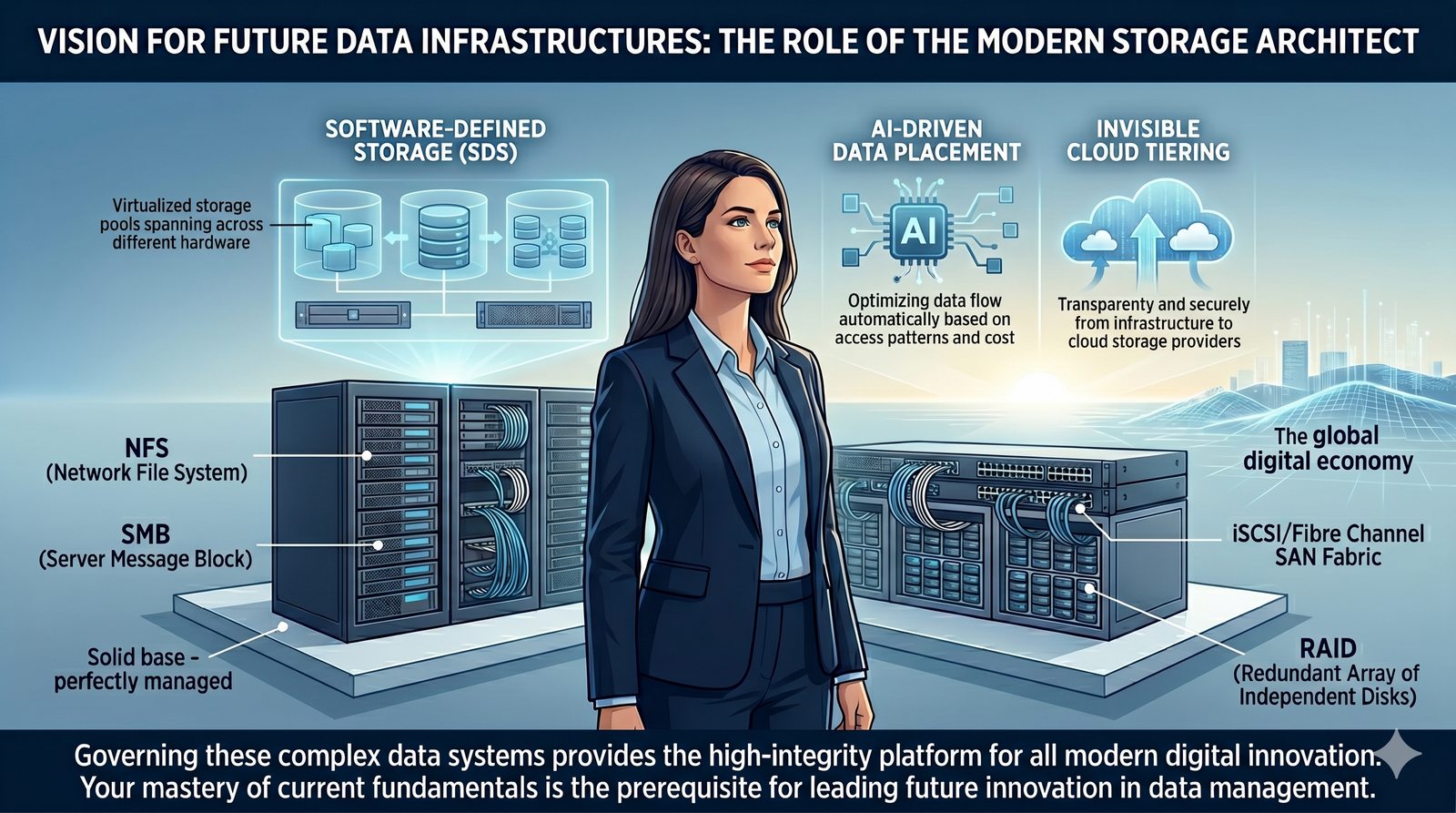
Centralne przechowywanie danych ułatwia również zarządzanie nimi, w tym tworzenie kopii zapasowych, kontrolowanie dostępu i wdrażanie polityk bezpieczeństwa, co jest kluczowe dla każdej organizacji.
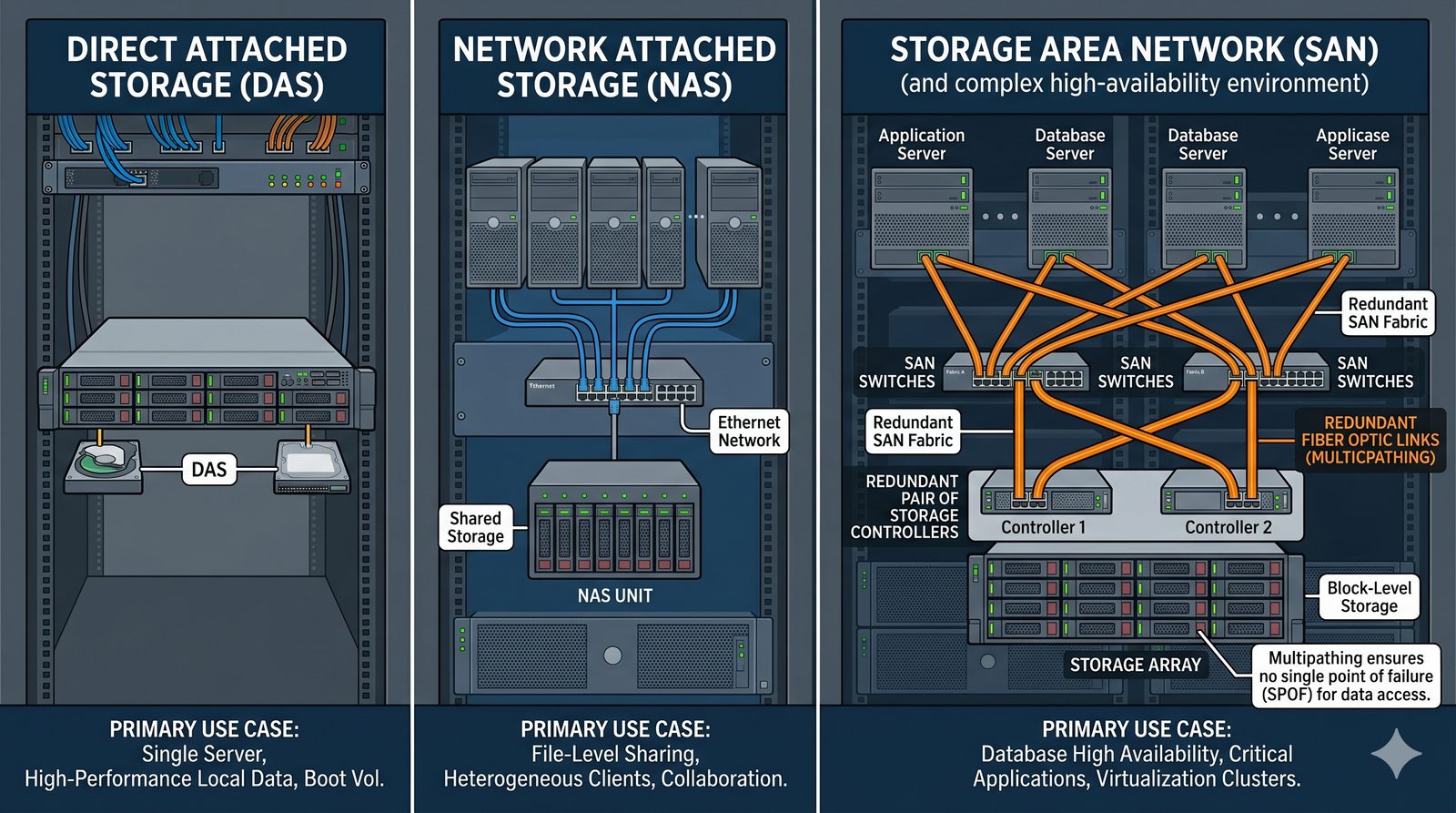
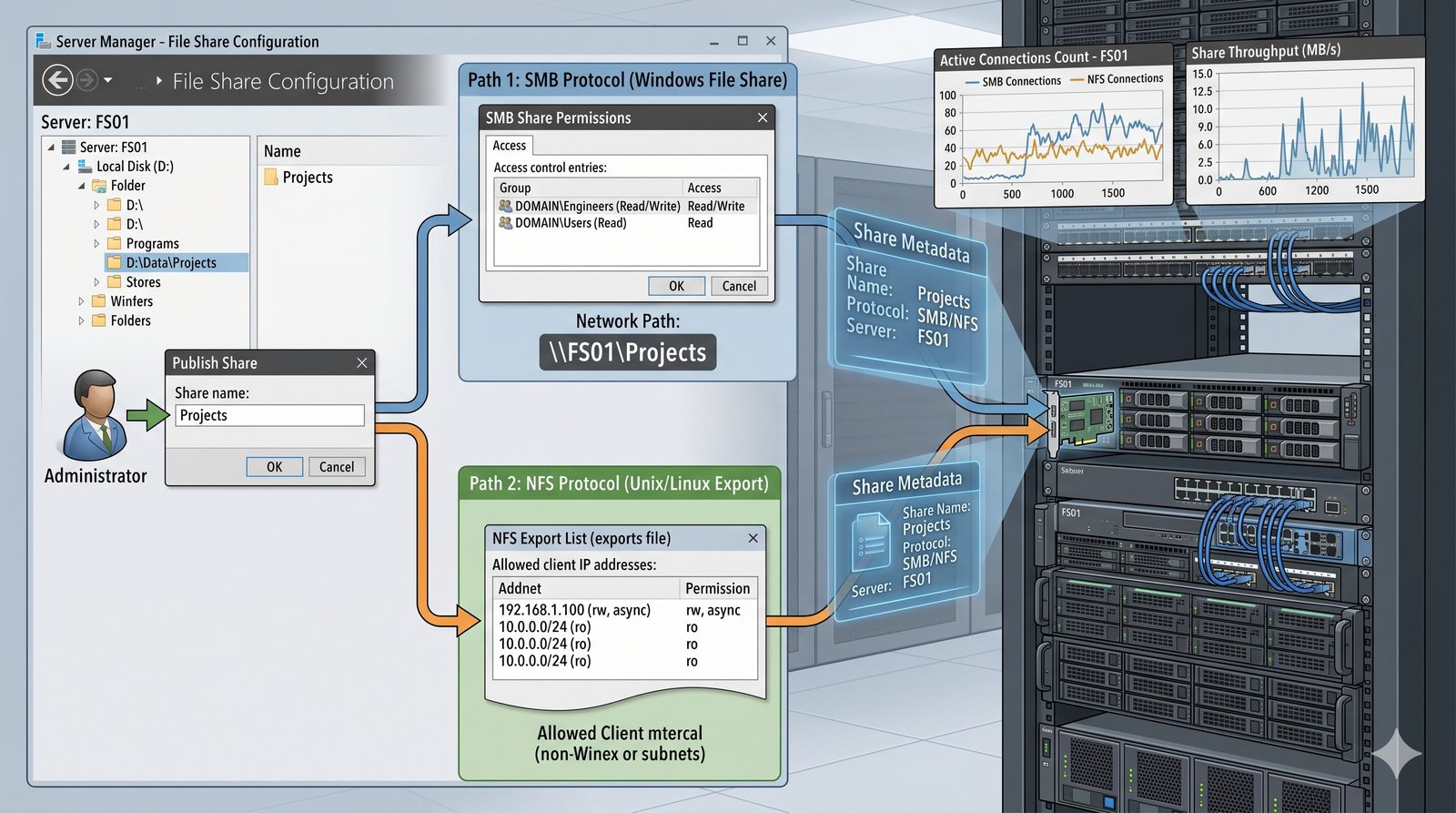
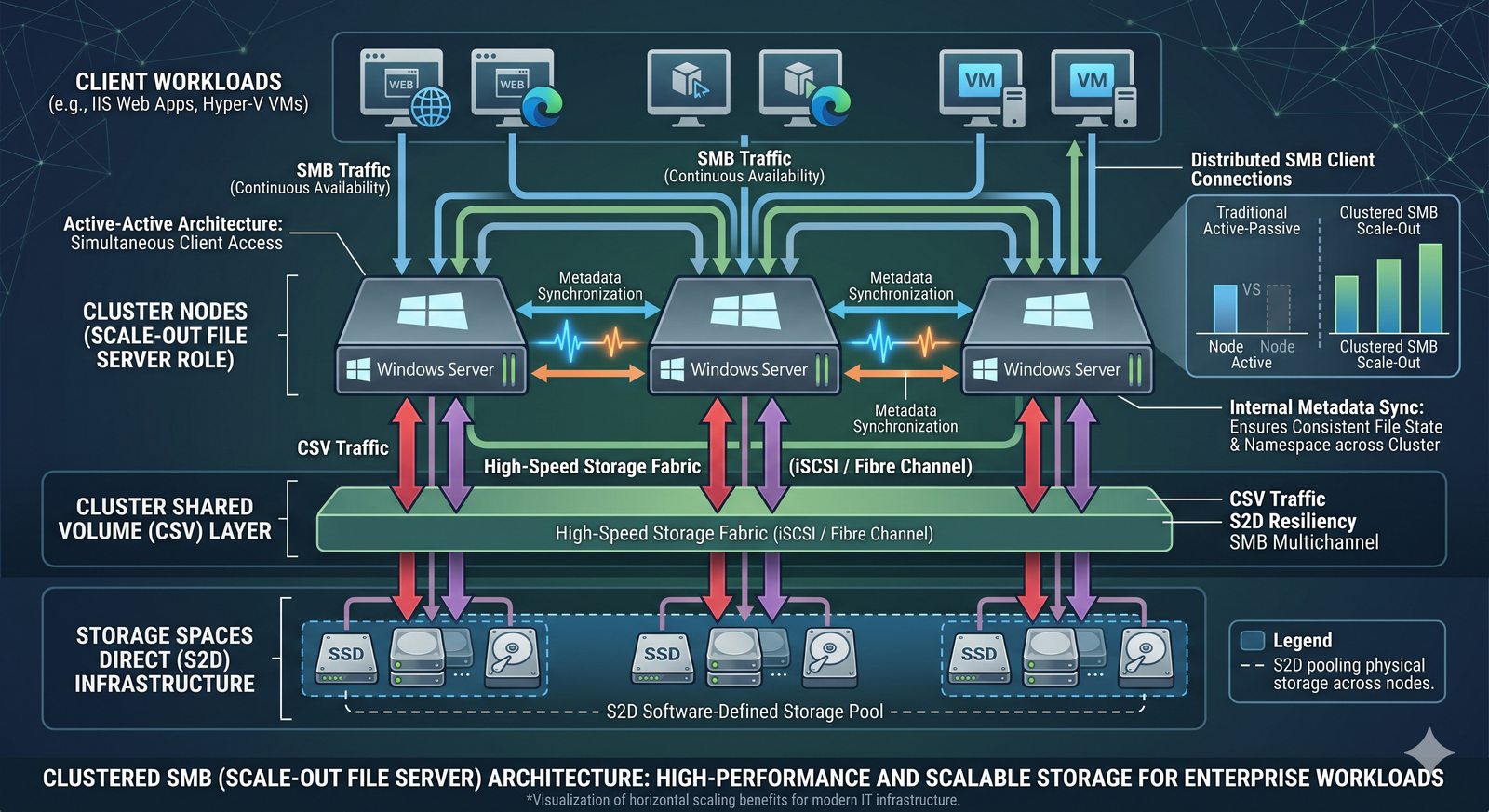
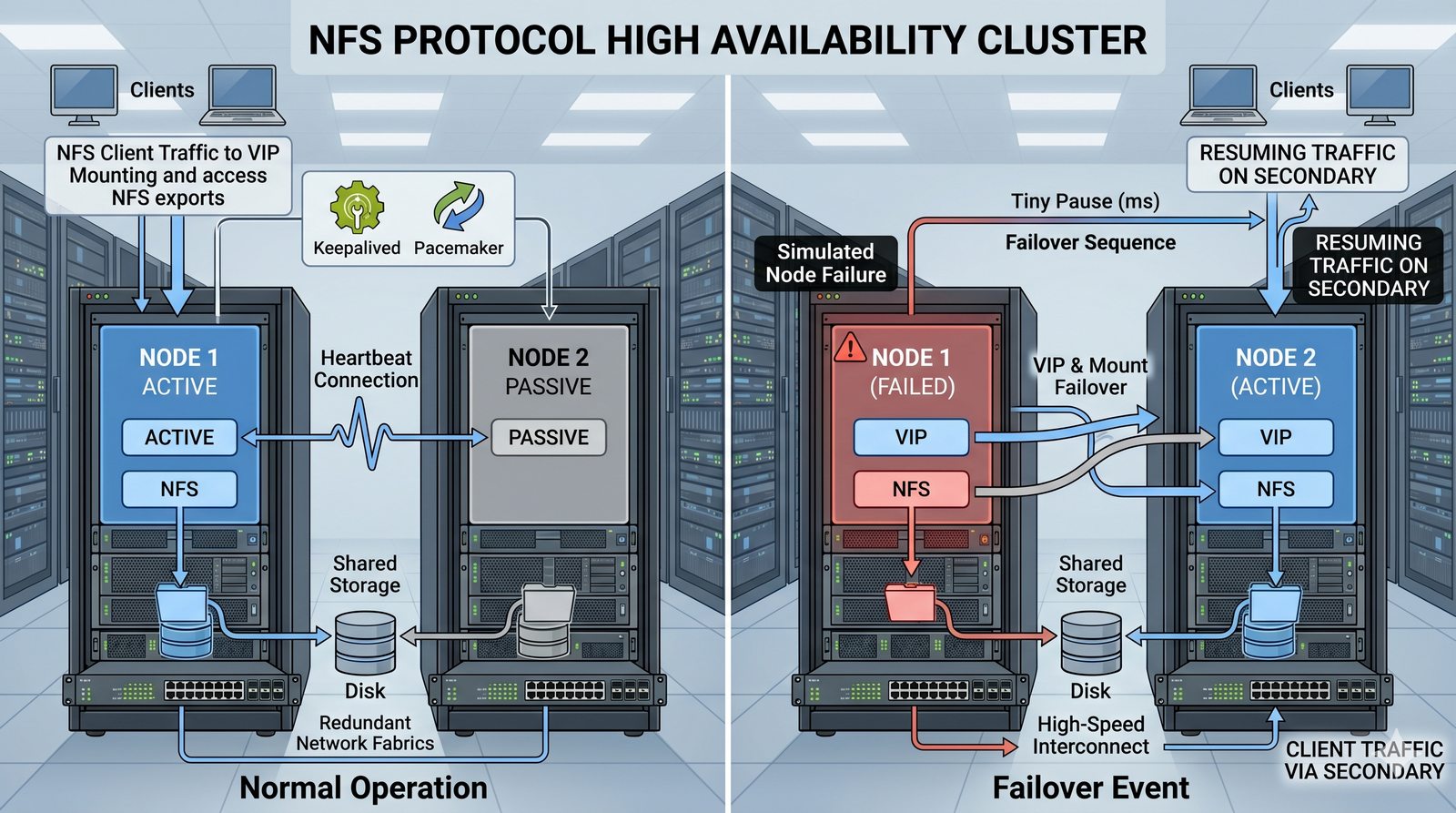
- Usługi plików stanowią kręgosłup centralizacji i współdzielenia danych w środowiskach sieciowych.
- Ich fundamentalną rolą jest umożliwienie wielu użytkownikom i aplikacjom jednoczesnego dostępu do tego samego zbioru plików, tak jakby znajdowały się one na ich lokalnym dysku.
- Eliminuje to potrzebę kopiowania danych między komputerami, co prowadzi do problemów z kontrolą wersji i spójnością.