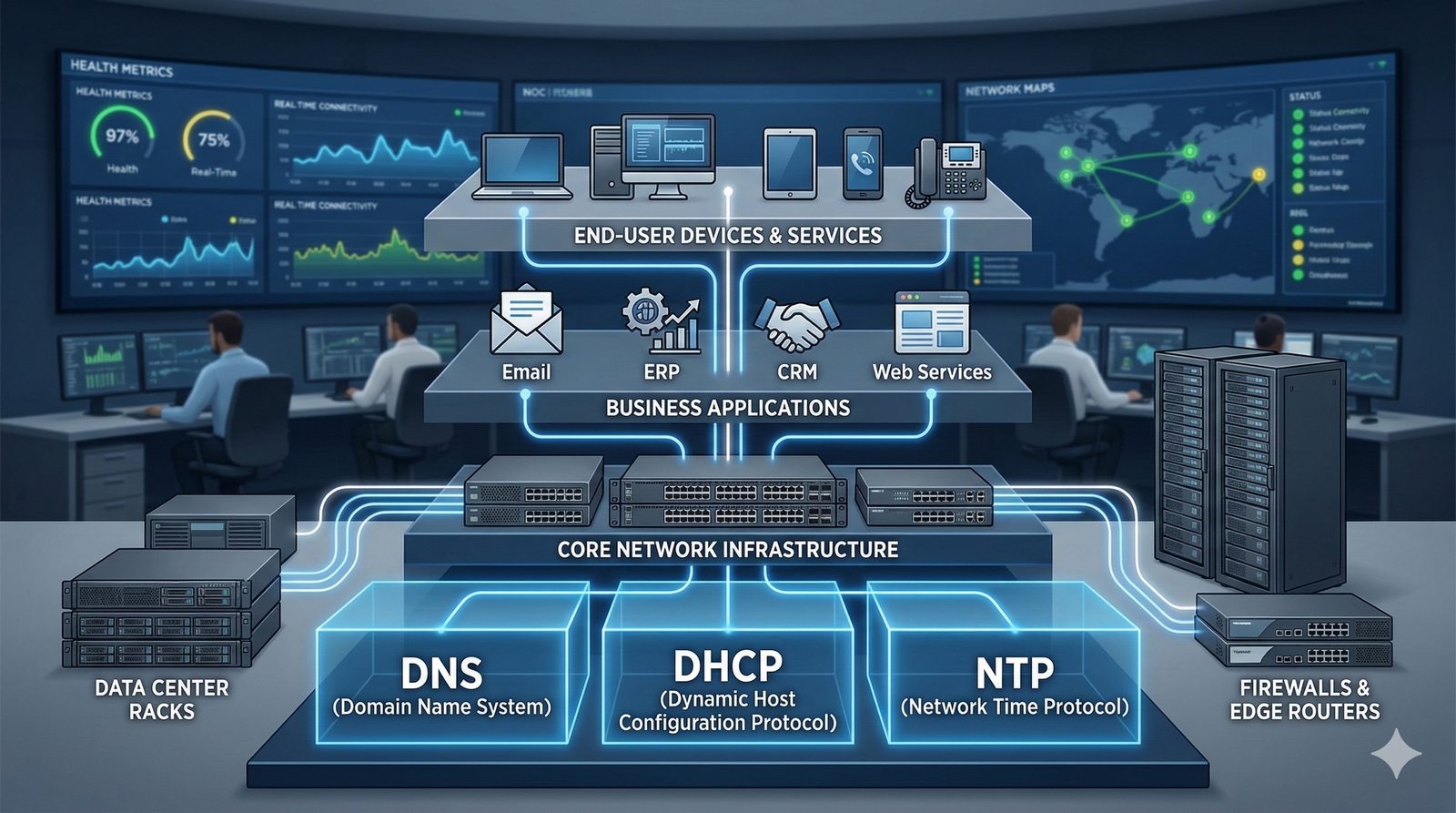
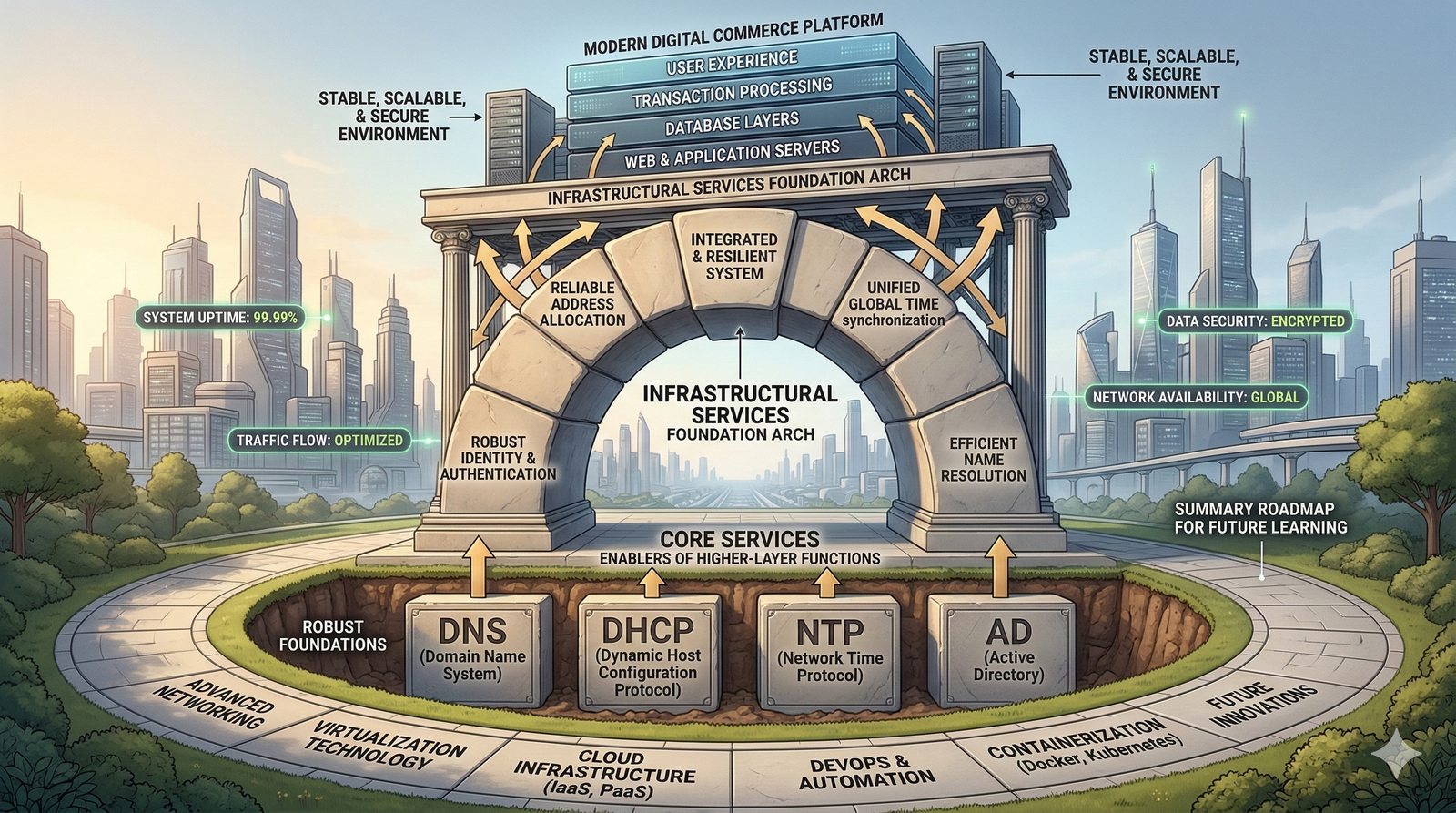
System ten jest fundamentem niemal każdej transakcji internetowej, od przeglądania stron WWW, przez wysyłanie e-maili, po działanie aplikacji mobilnych.
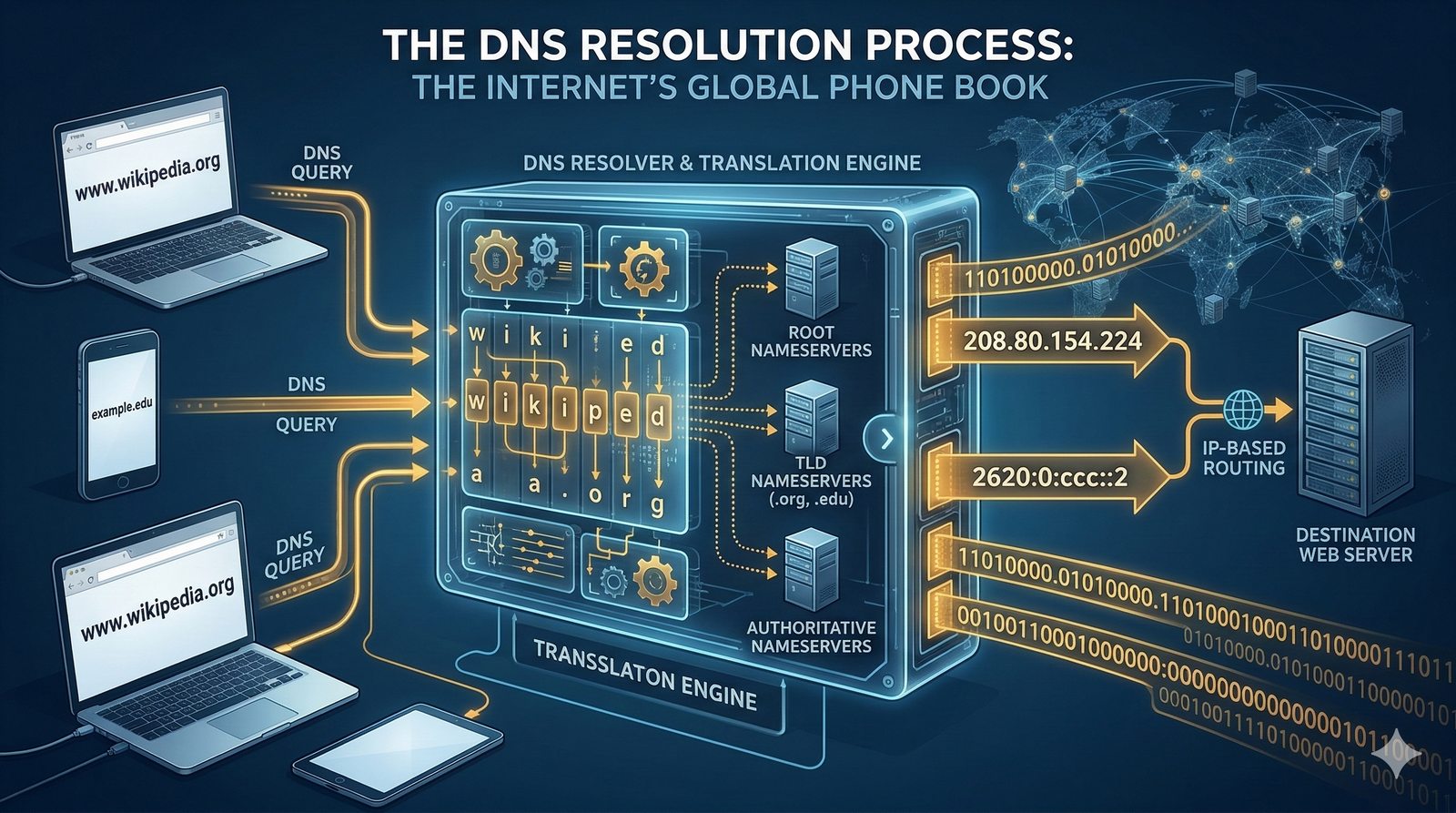
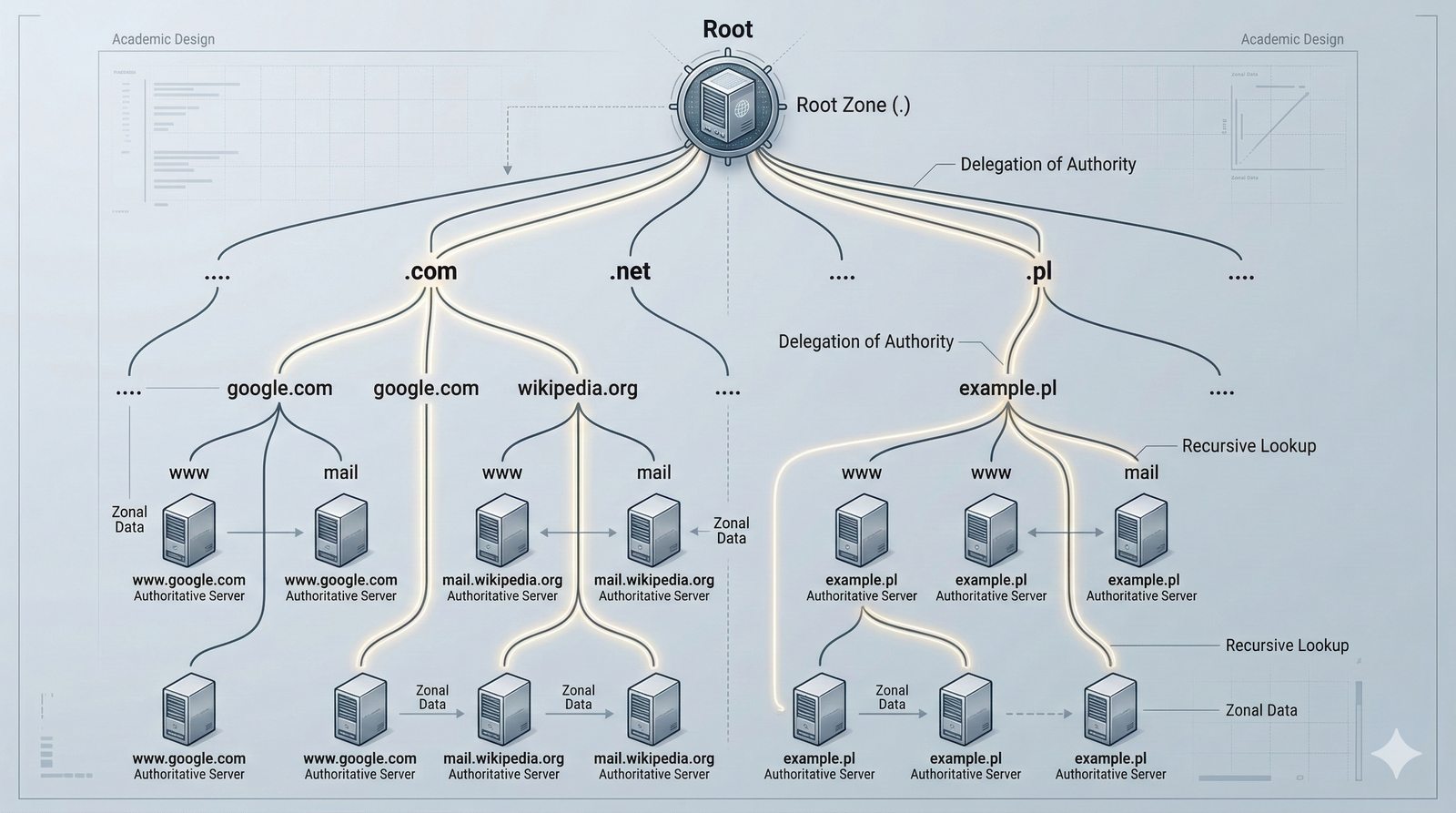
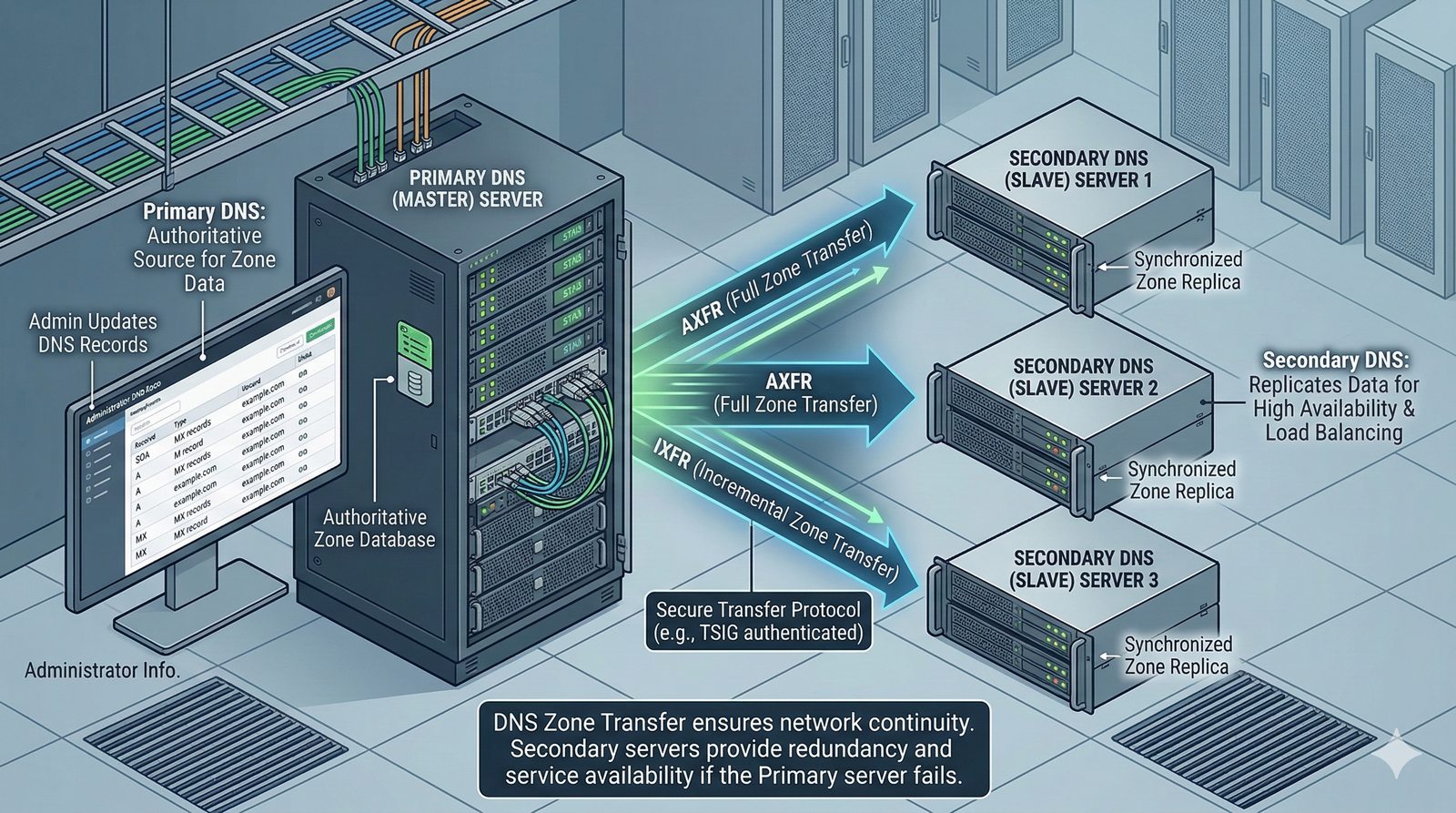
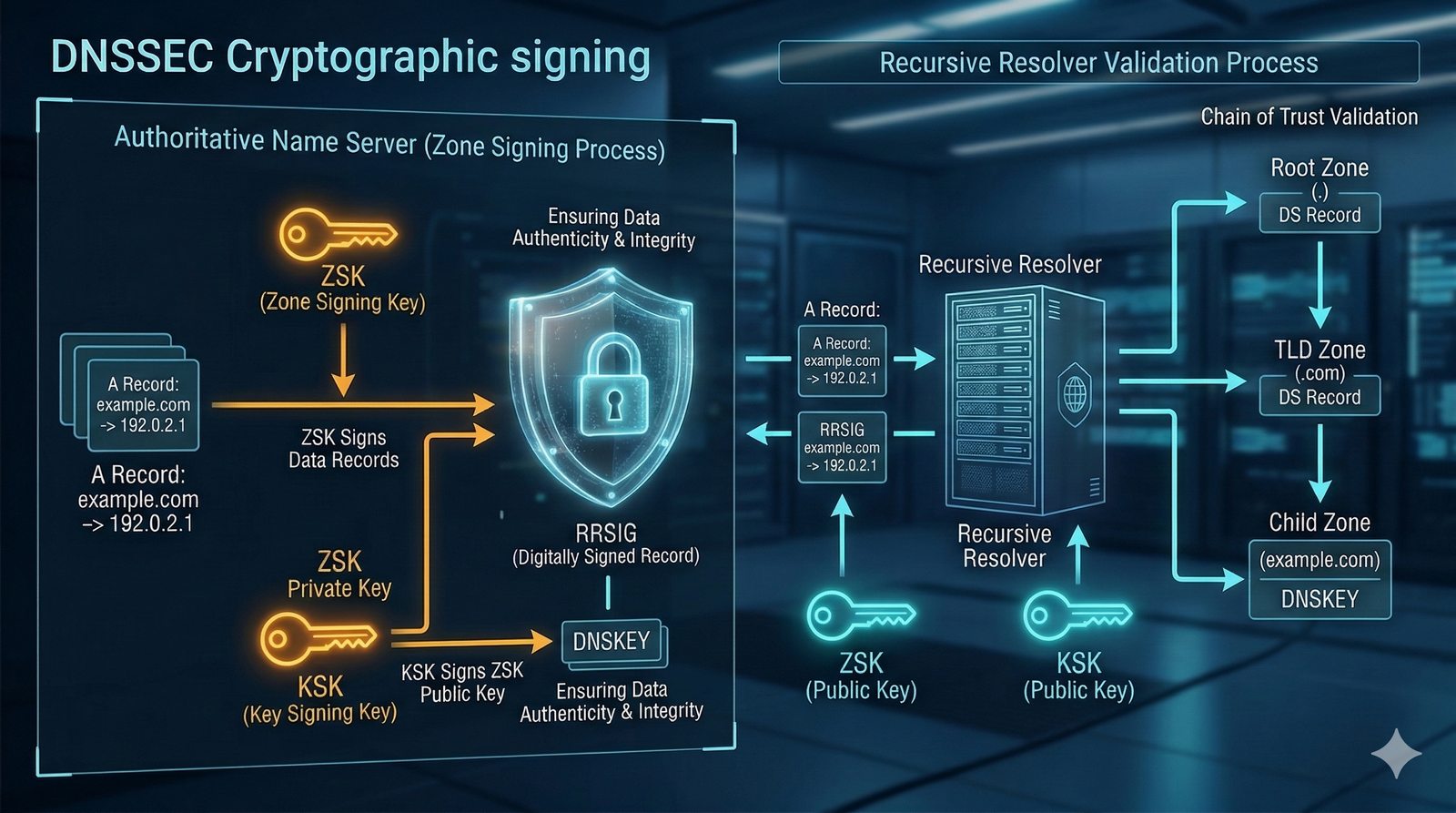
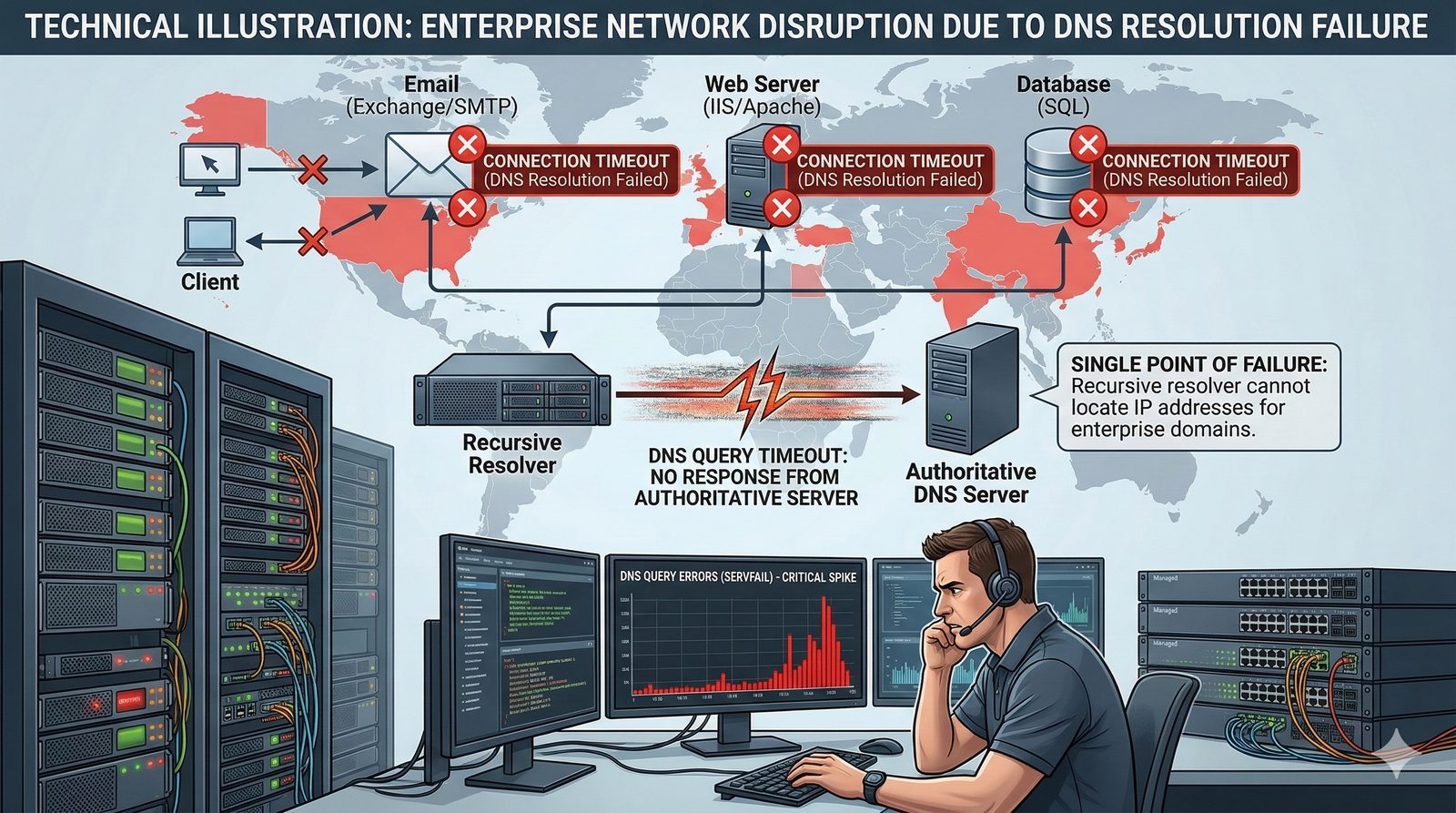
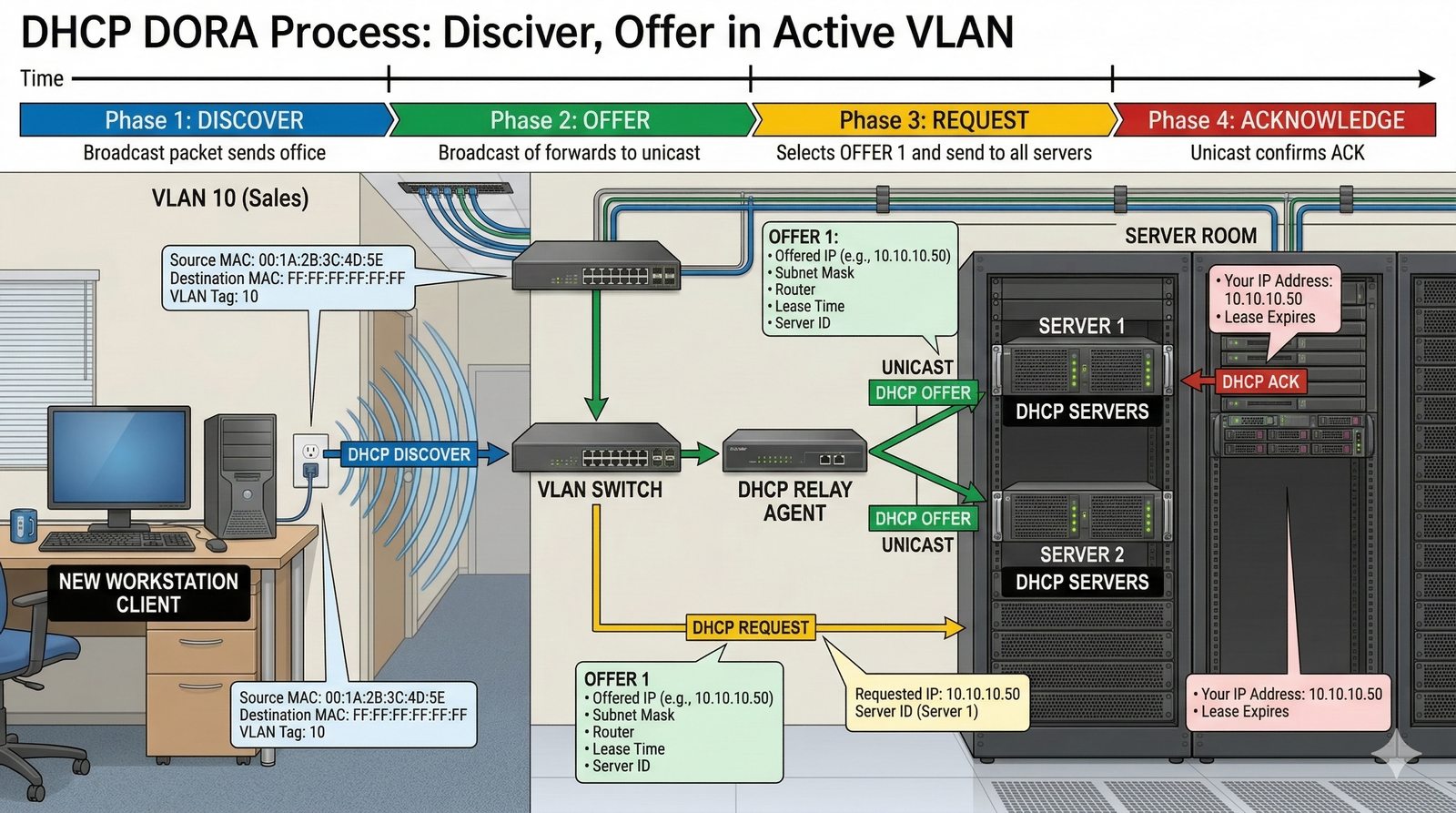
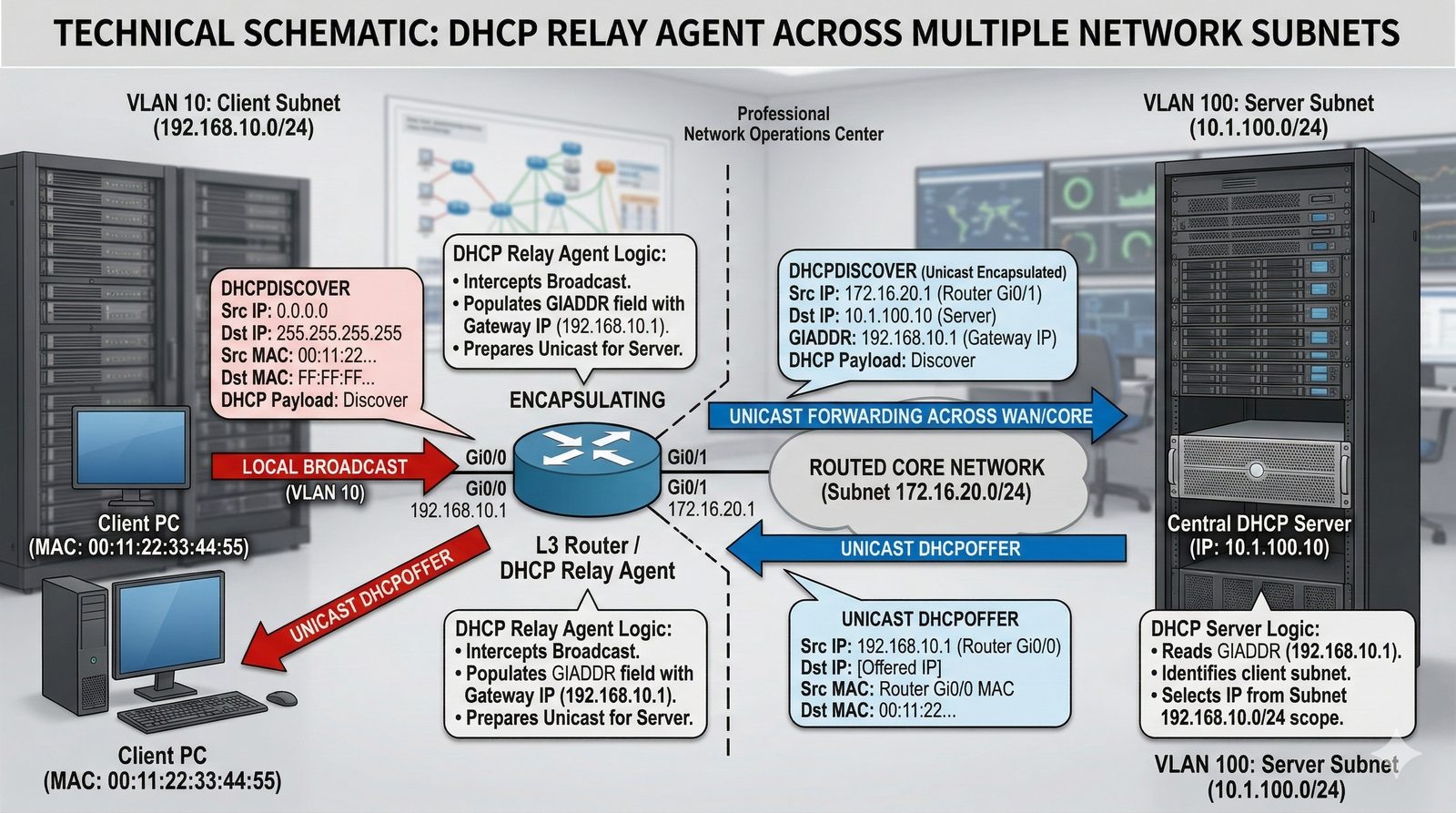
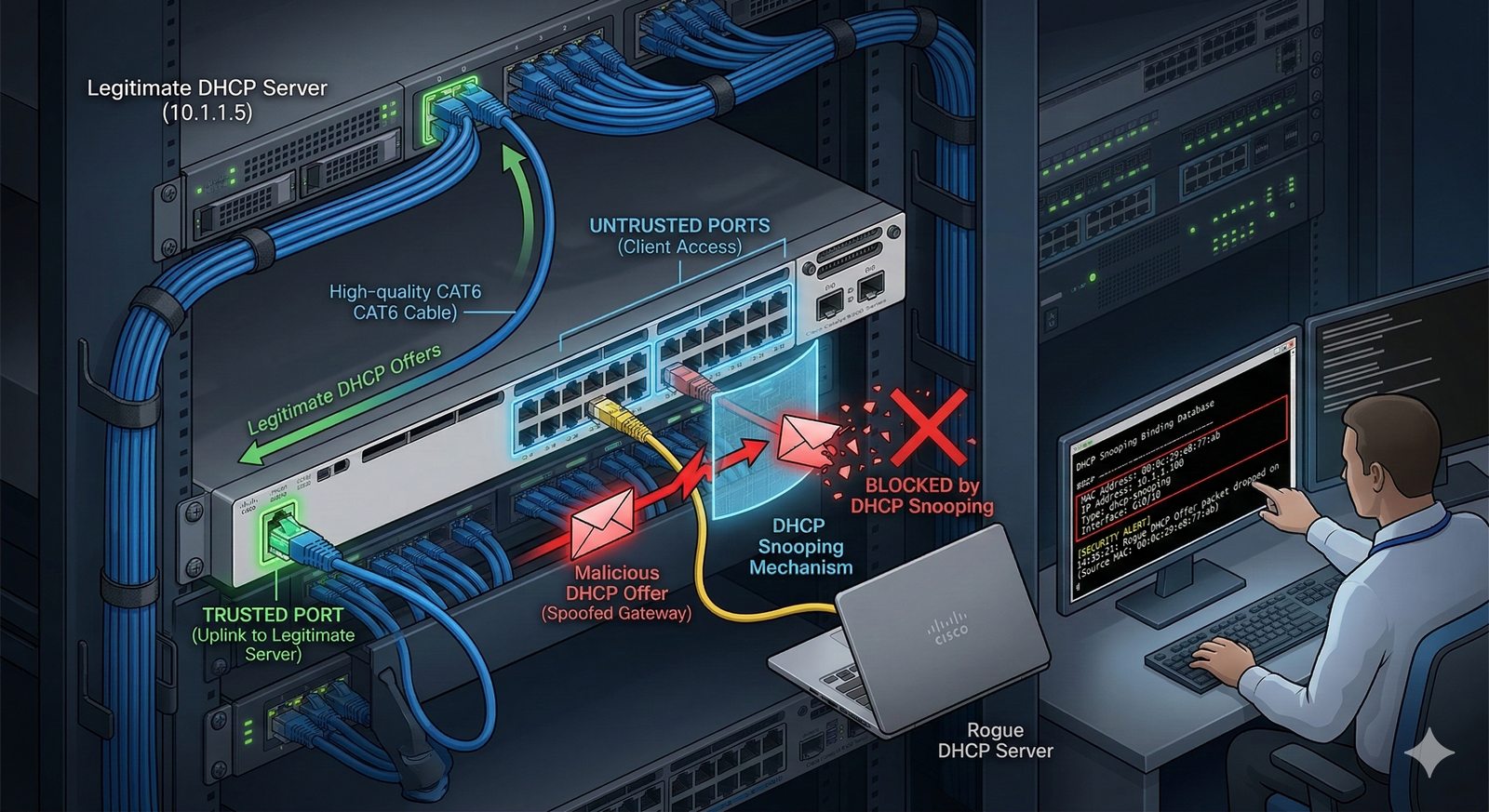
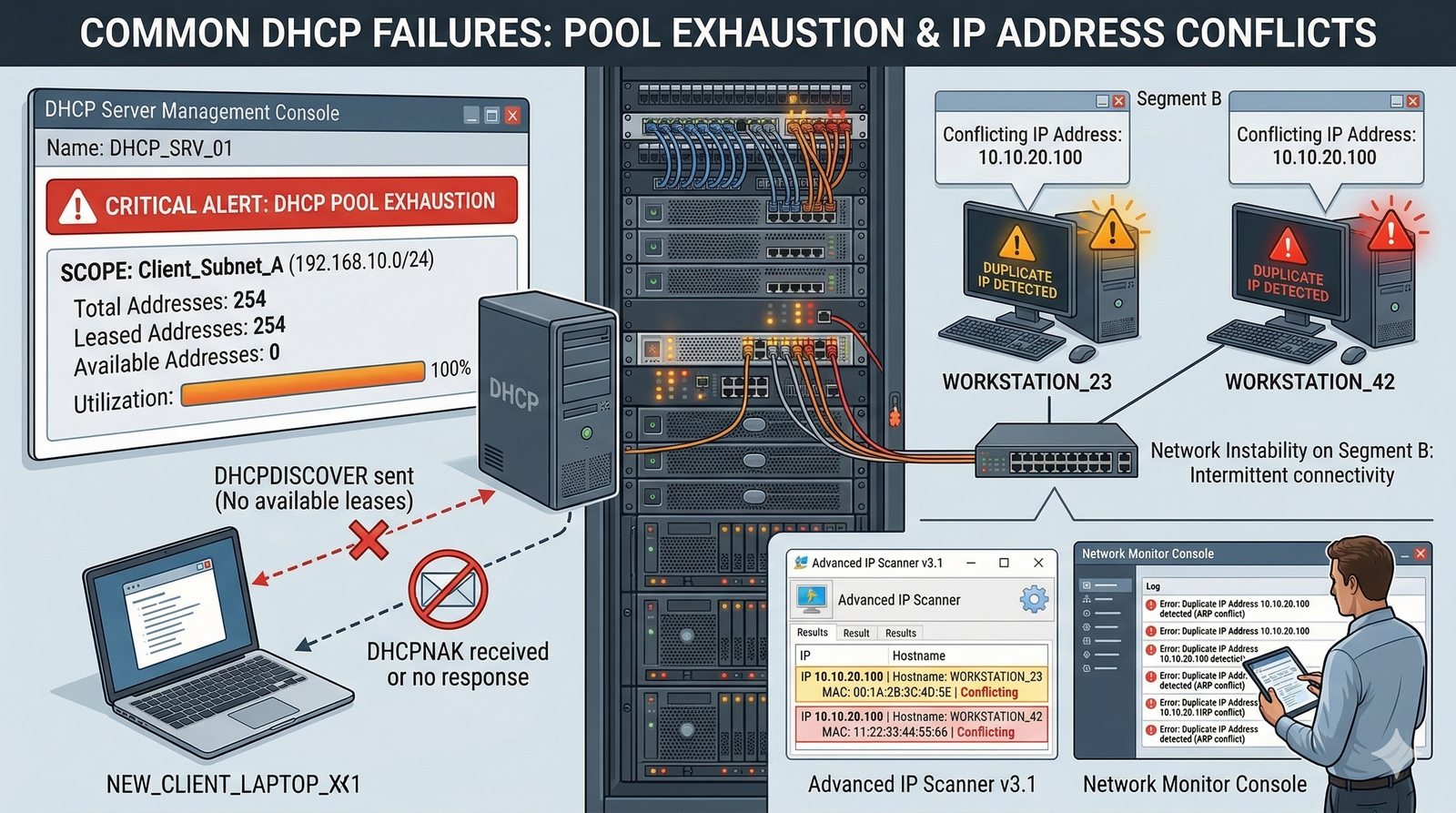
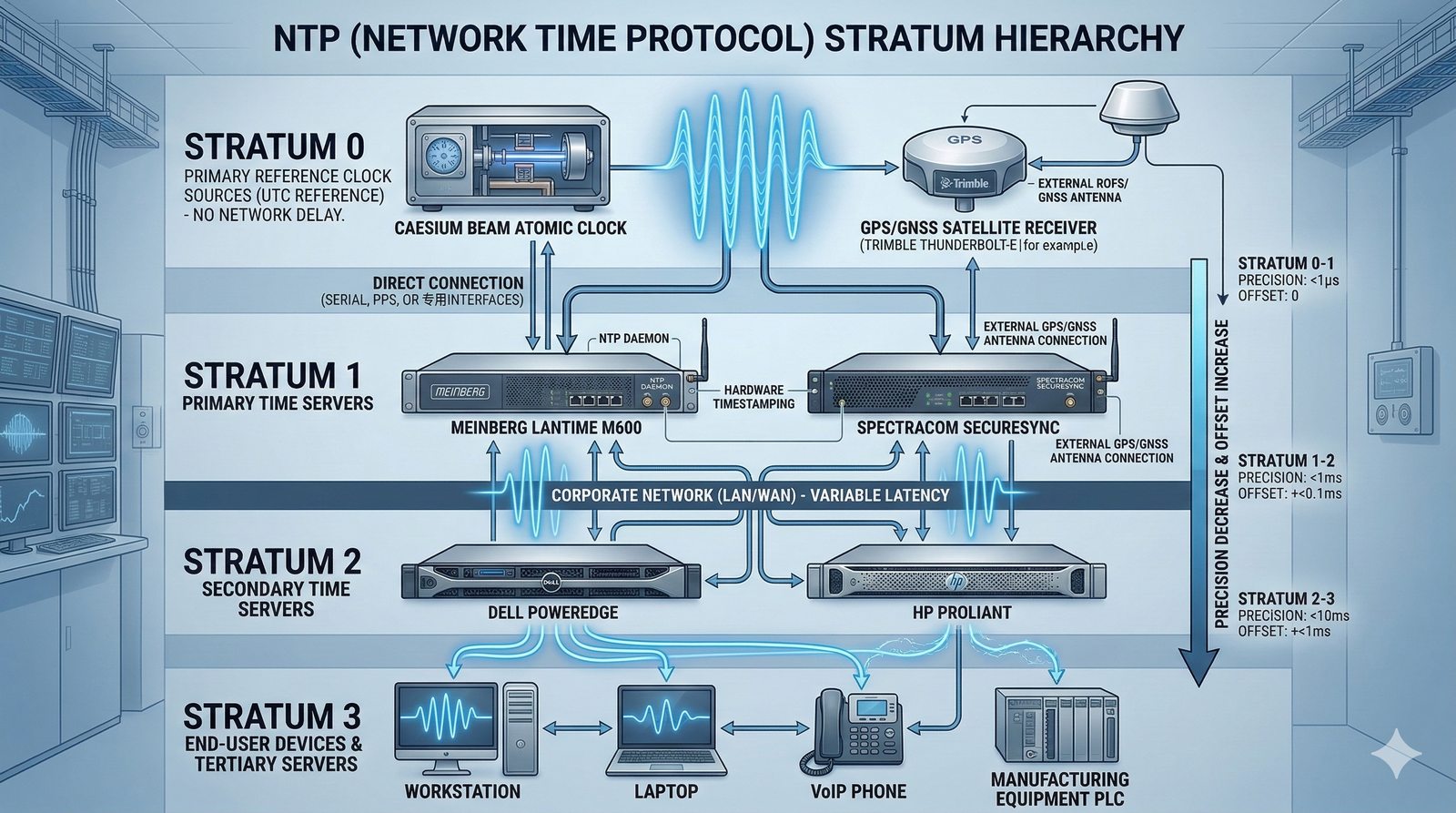
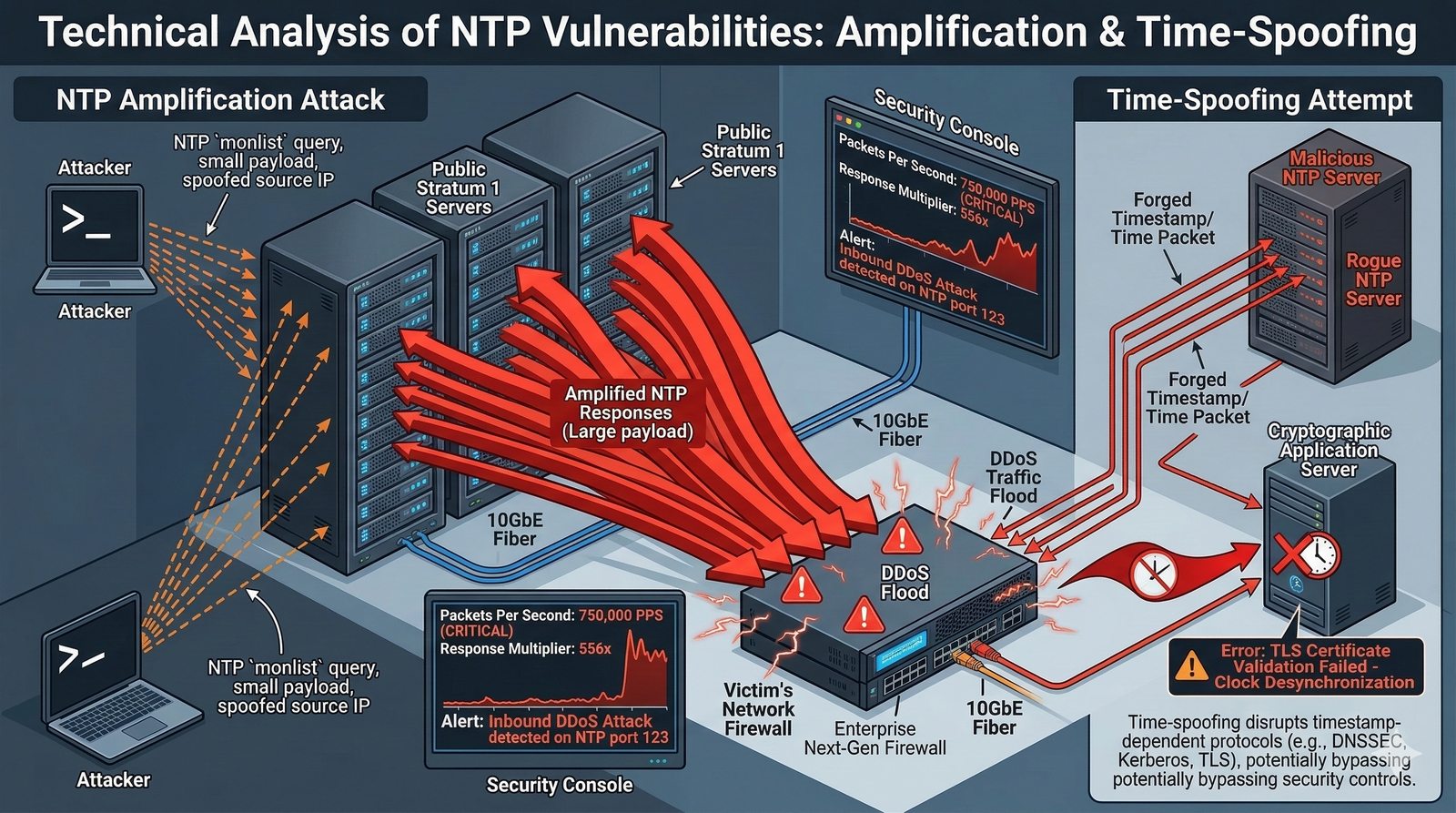
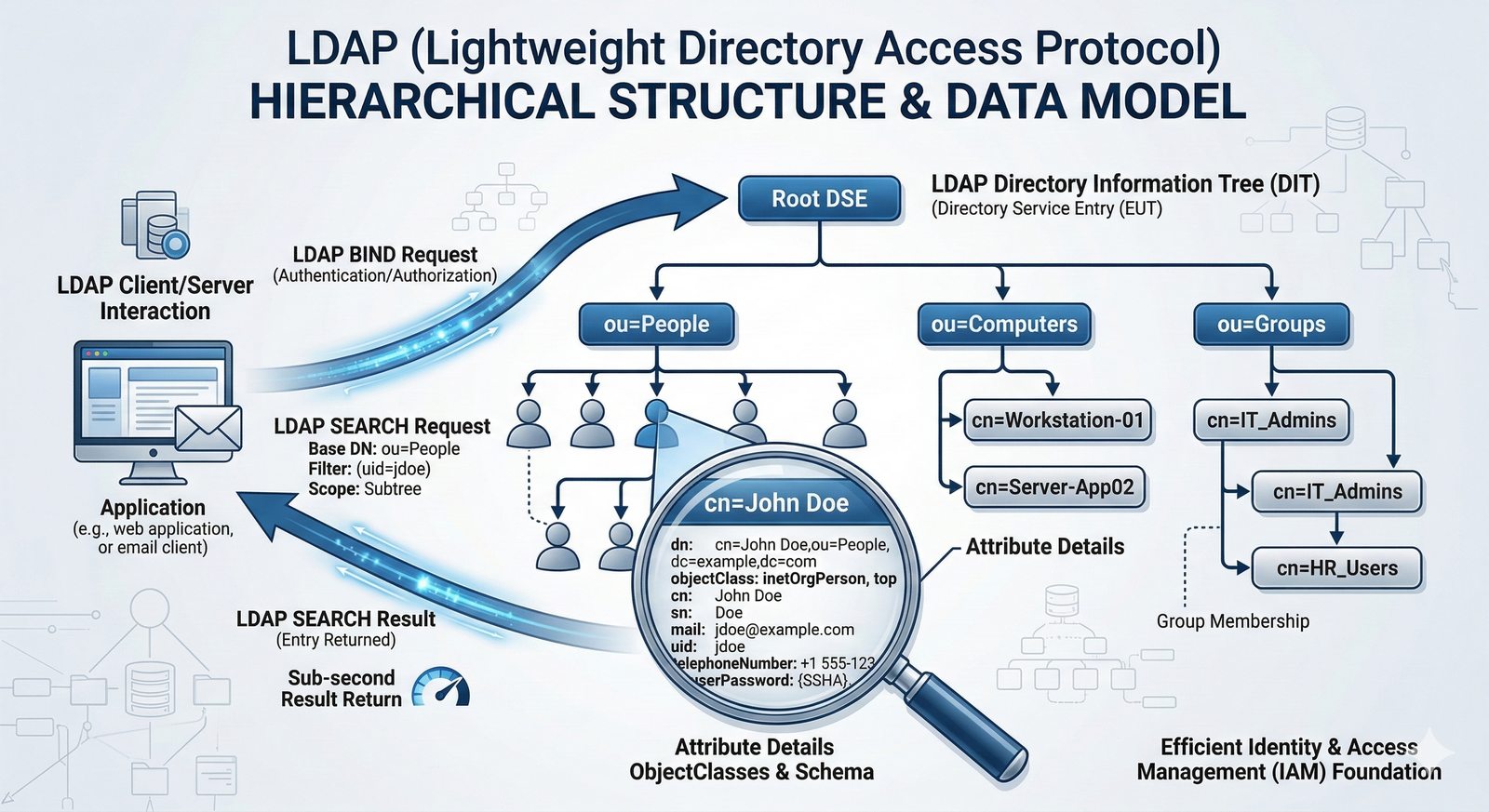
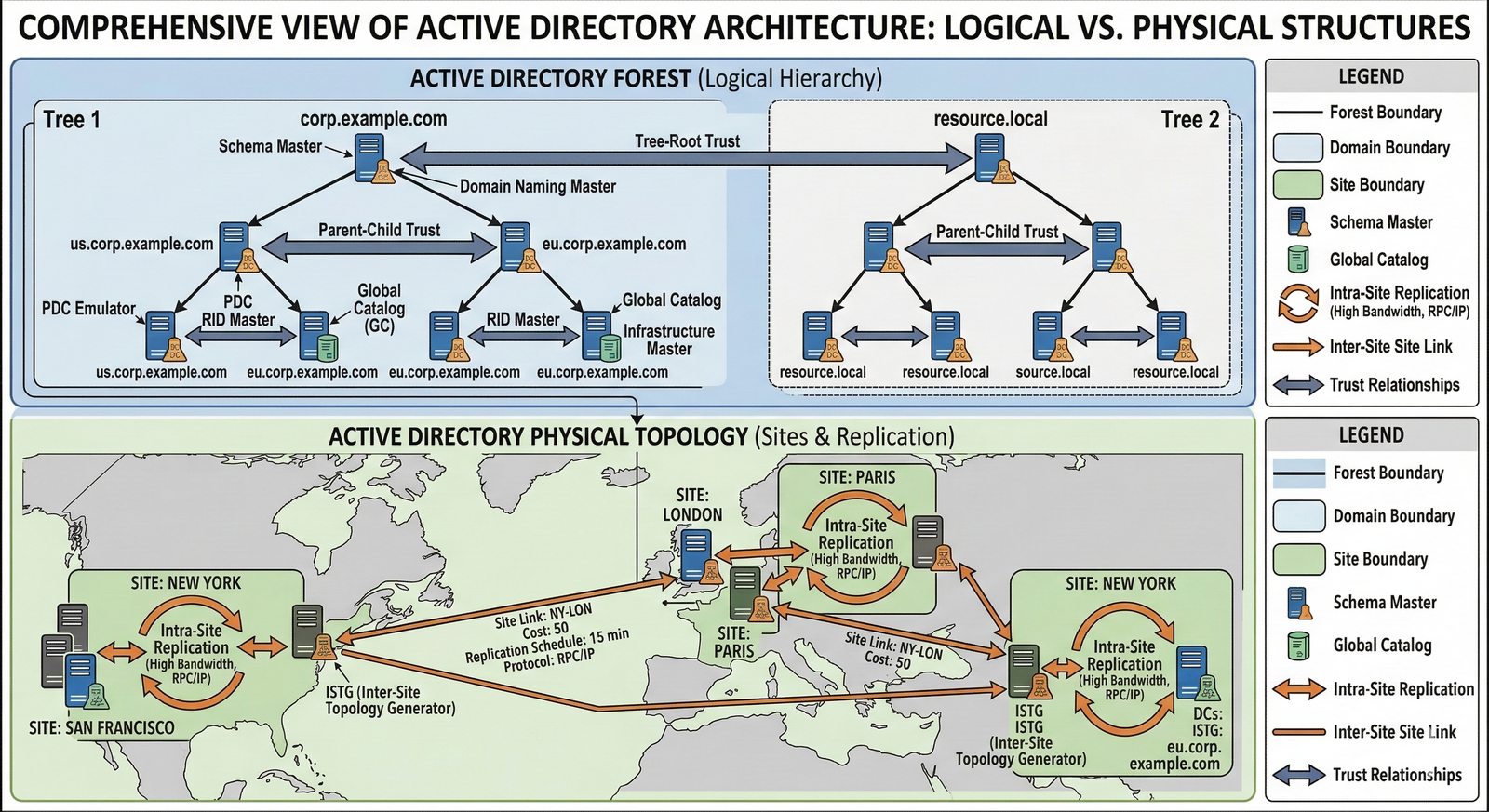
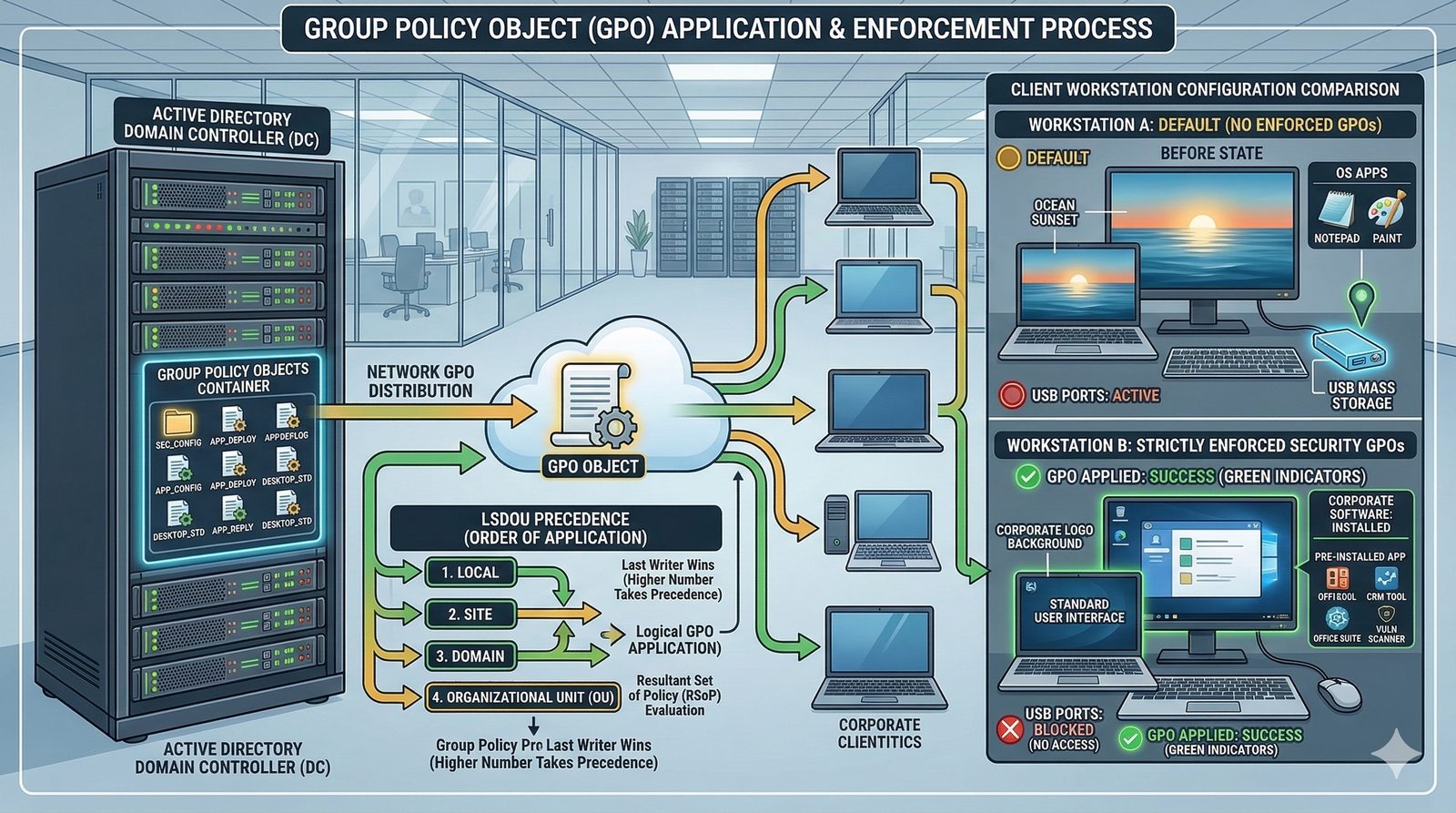
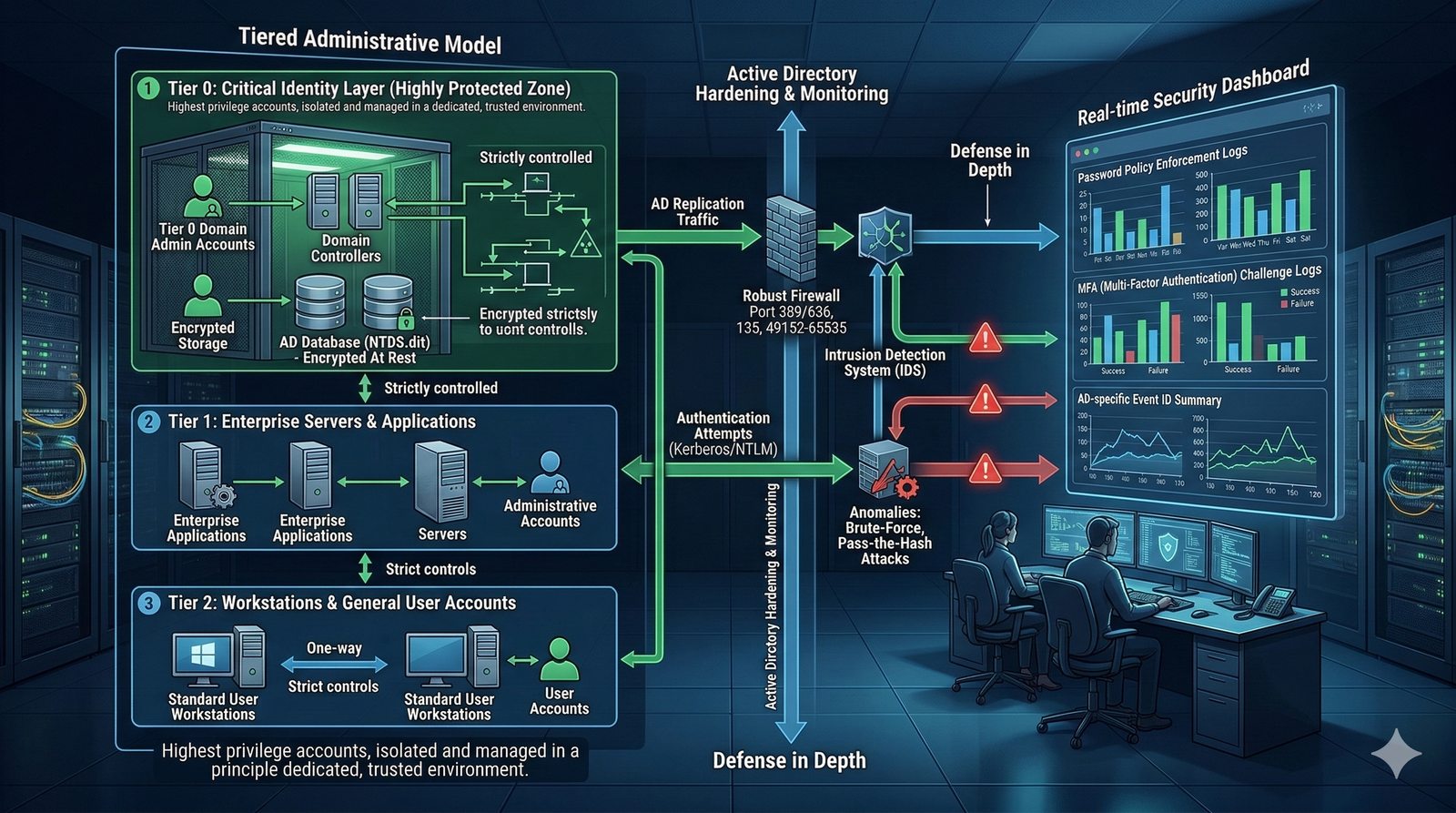
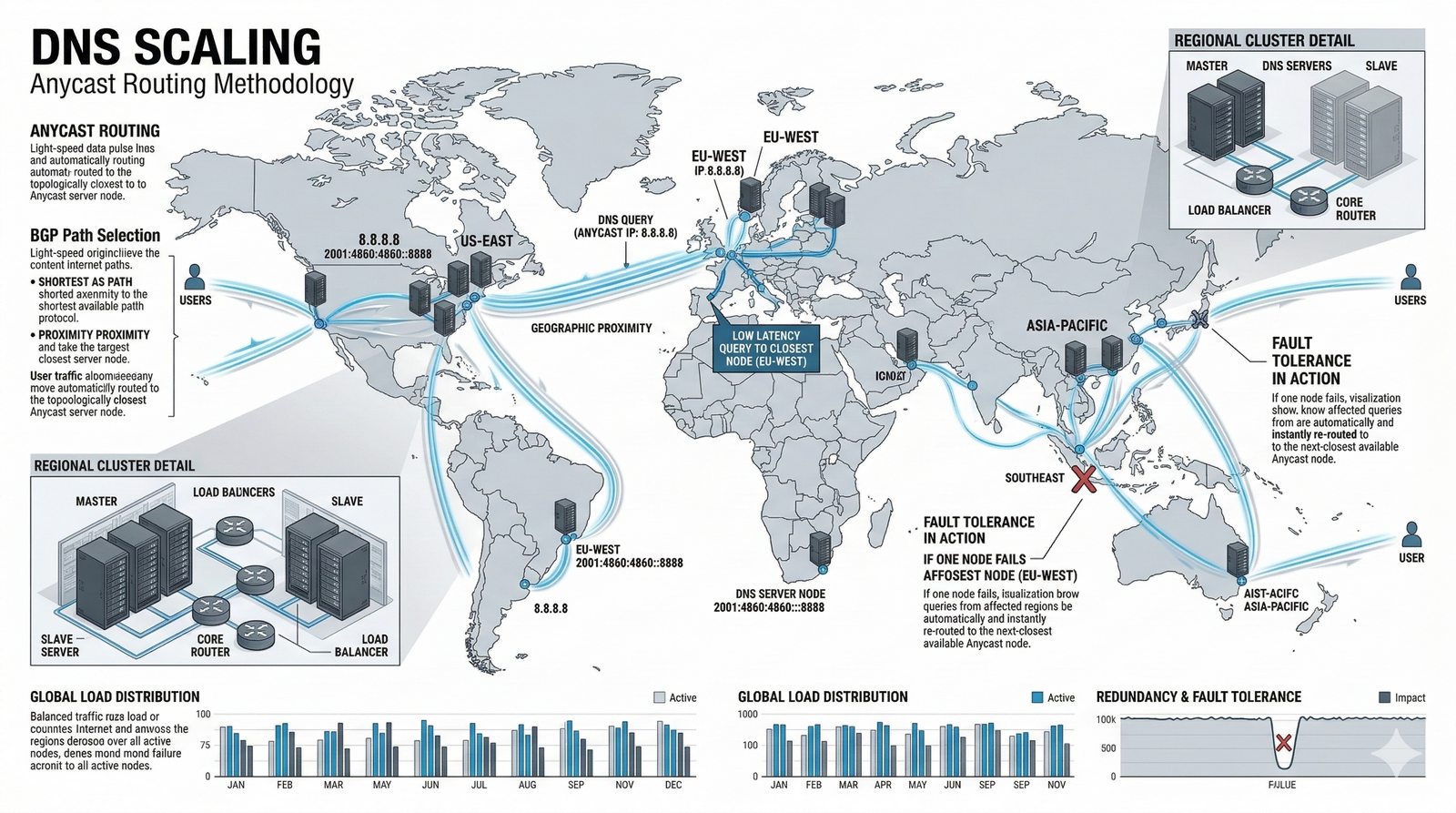
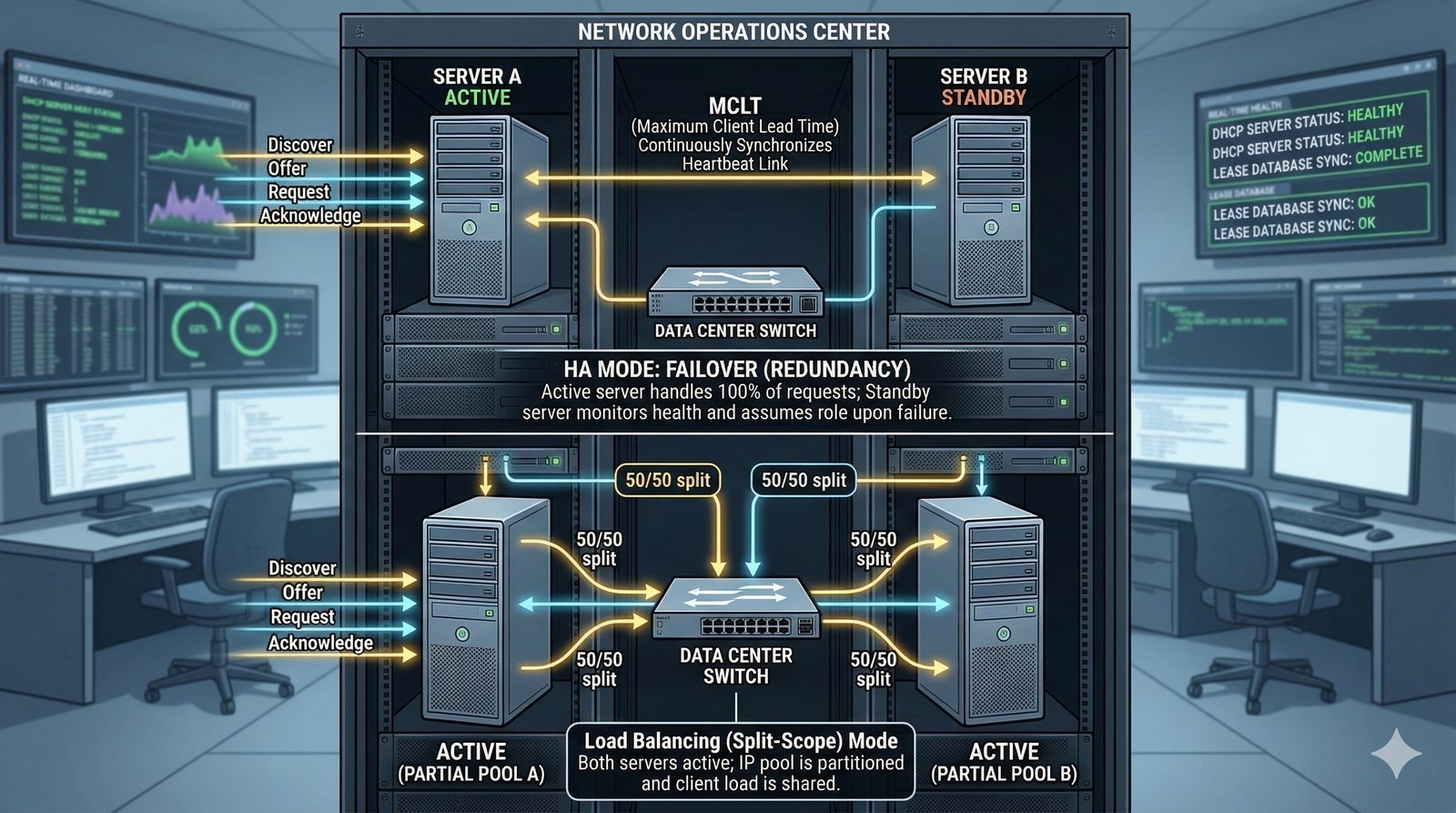
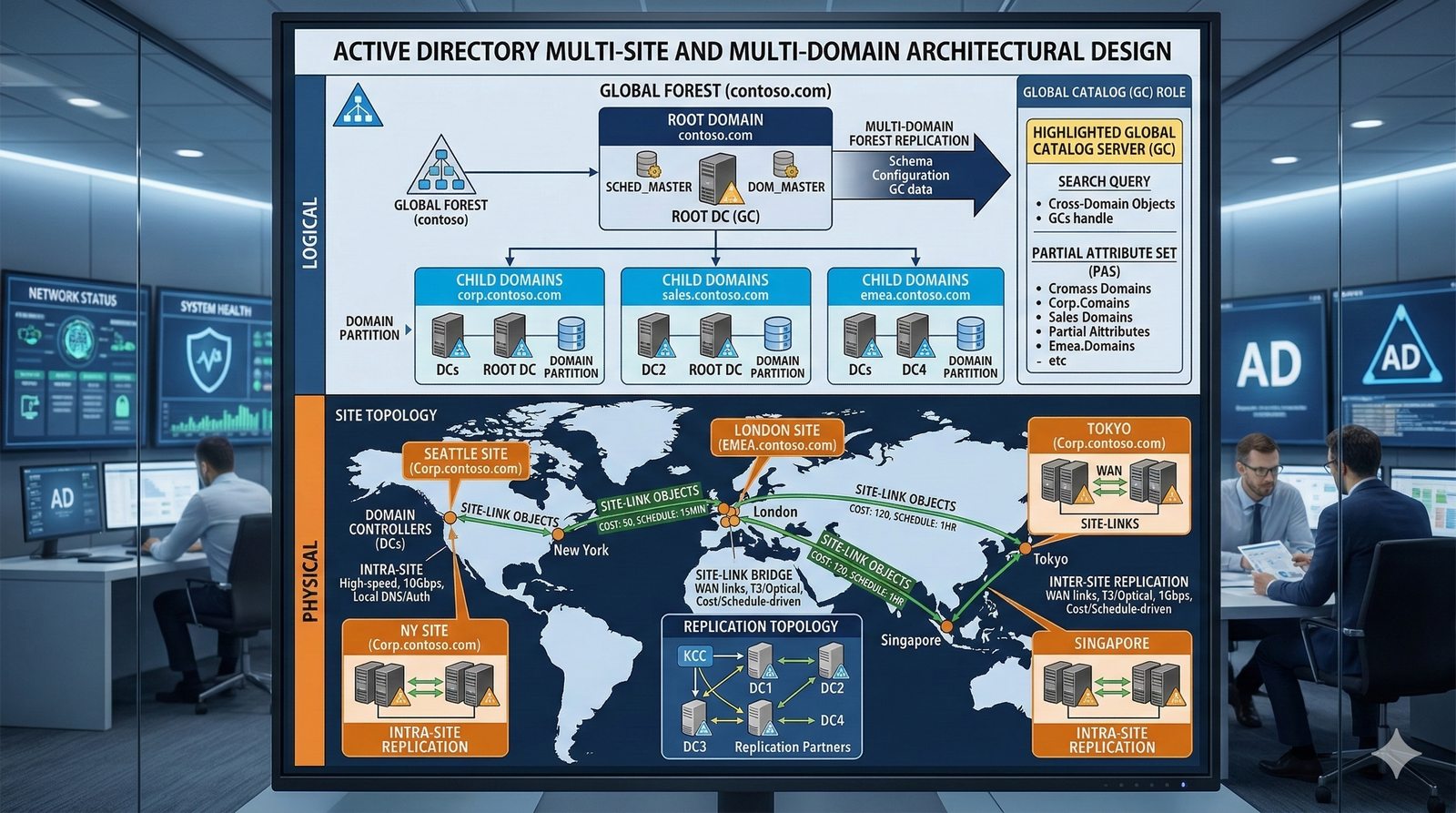
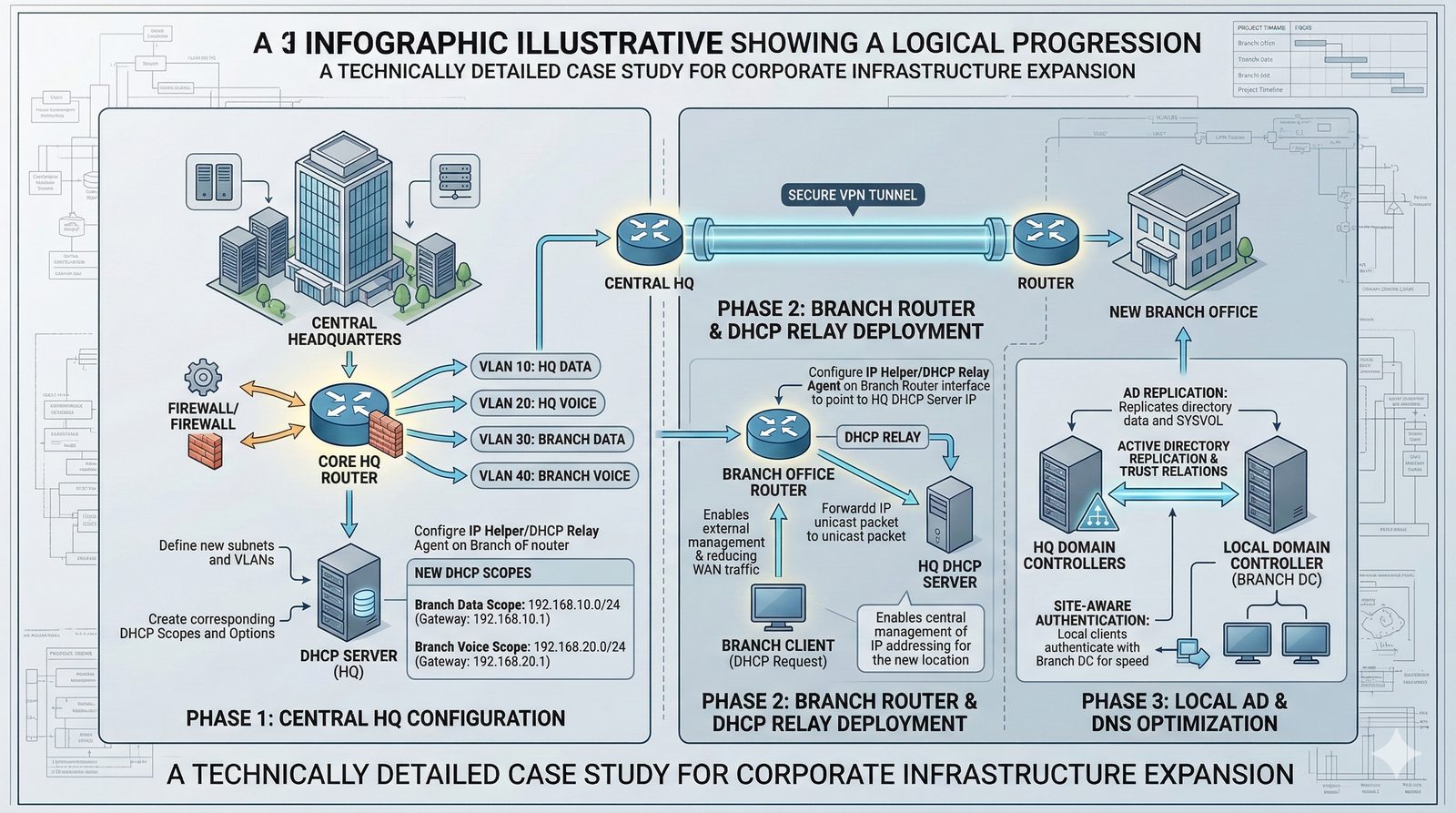
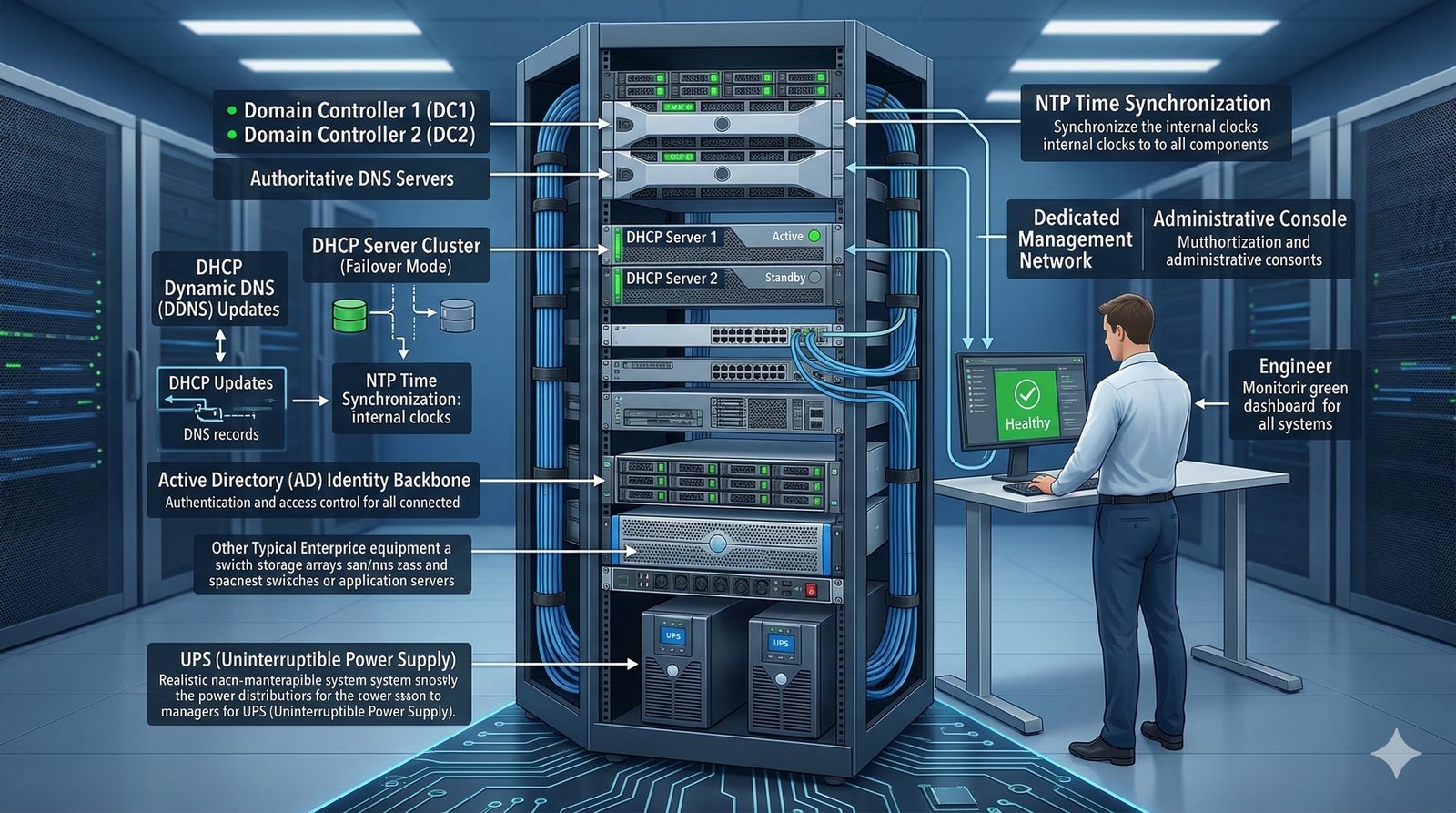
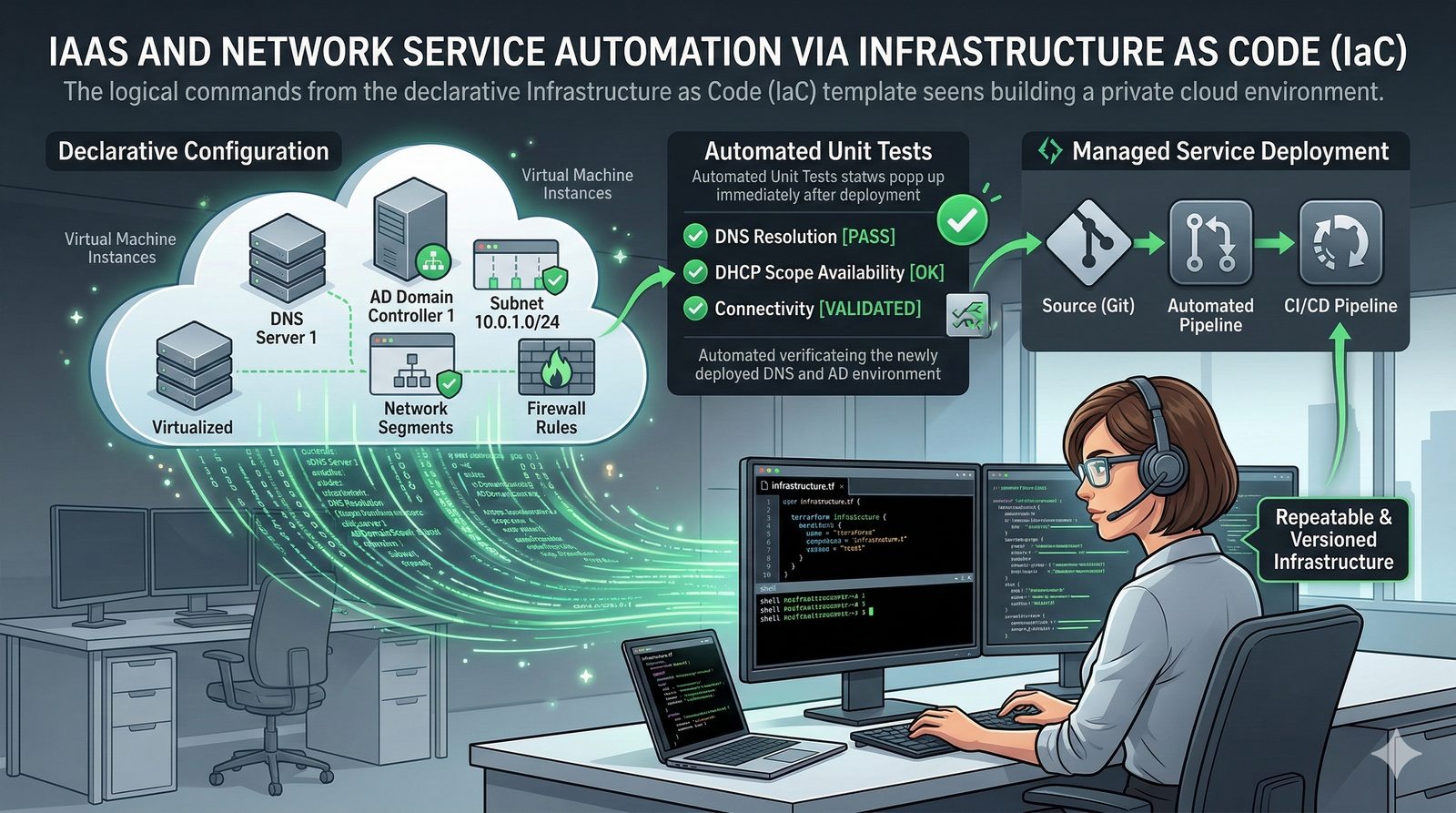
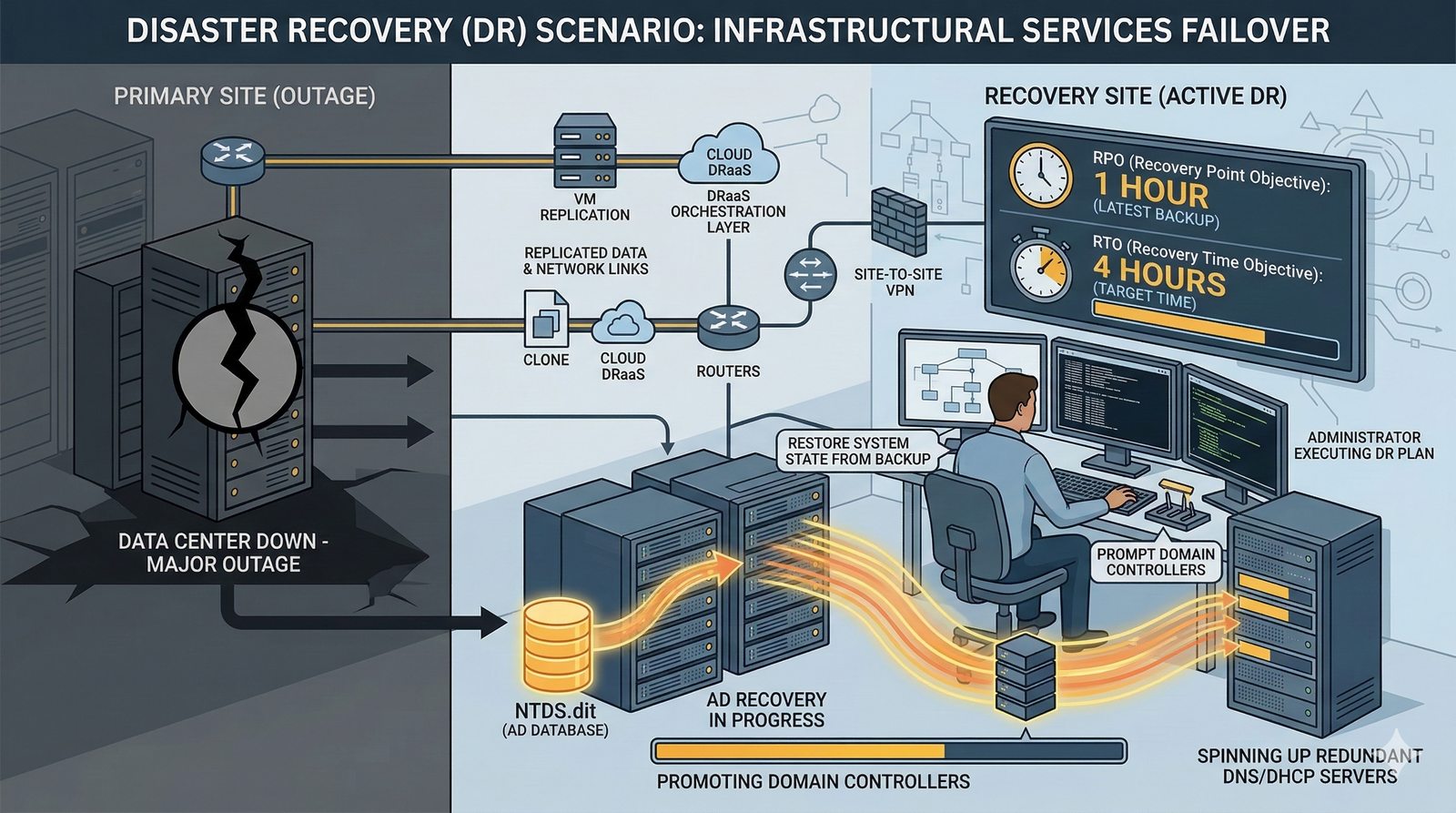
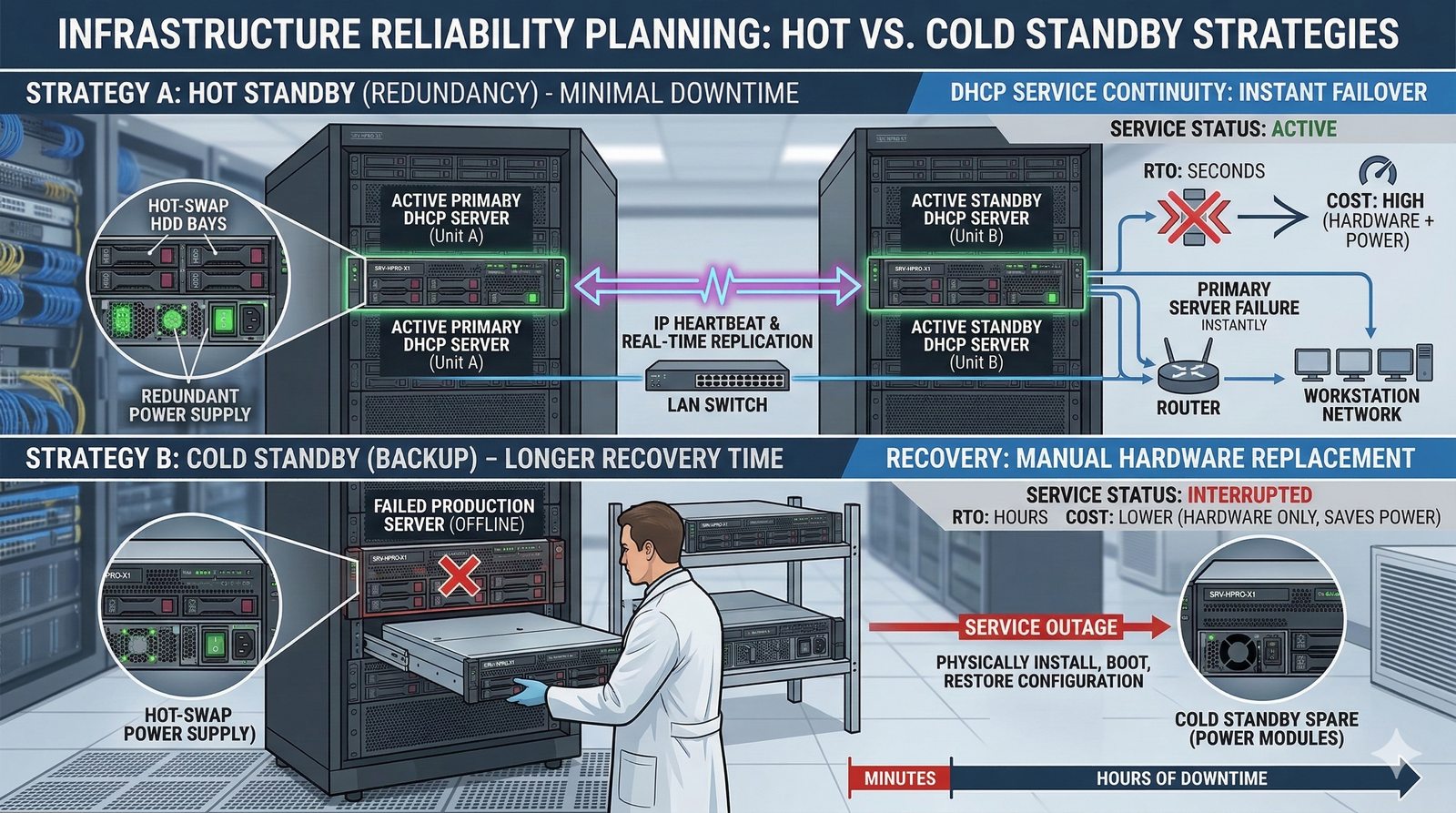
- System Nazw Domenowych (DNS, Domain Name System) to rozproszona, hierarchiczna baza danych, której głównym zadaniem jest tłumaczenie zrozumiałych dla ludzi nazw domen (np. www.example.com) na adresy IP (np. 93.184.216.34), które są niezbędne do nawiązania połączenia w sieci. DNS działa jak globalna książka telefoniczna dla Internetu, eliminując potrzebę zapamiętywania przez użytkowników skomplikowanych ciągów cyfr.