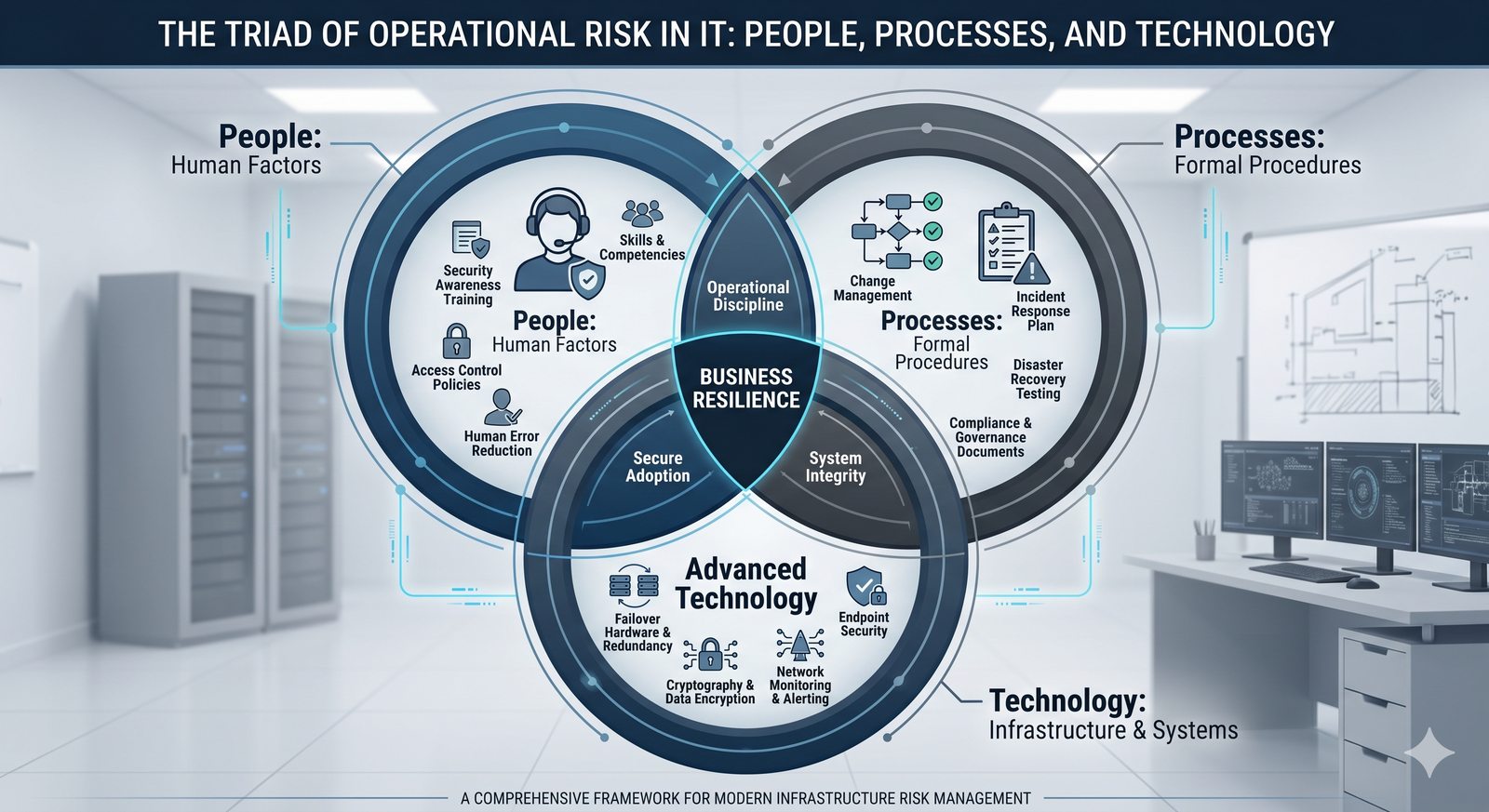
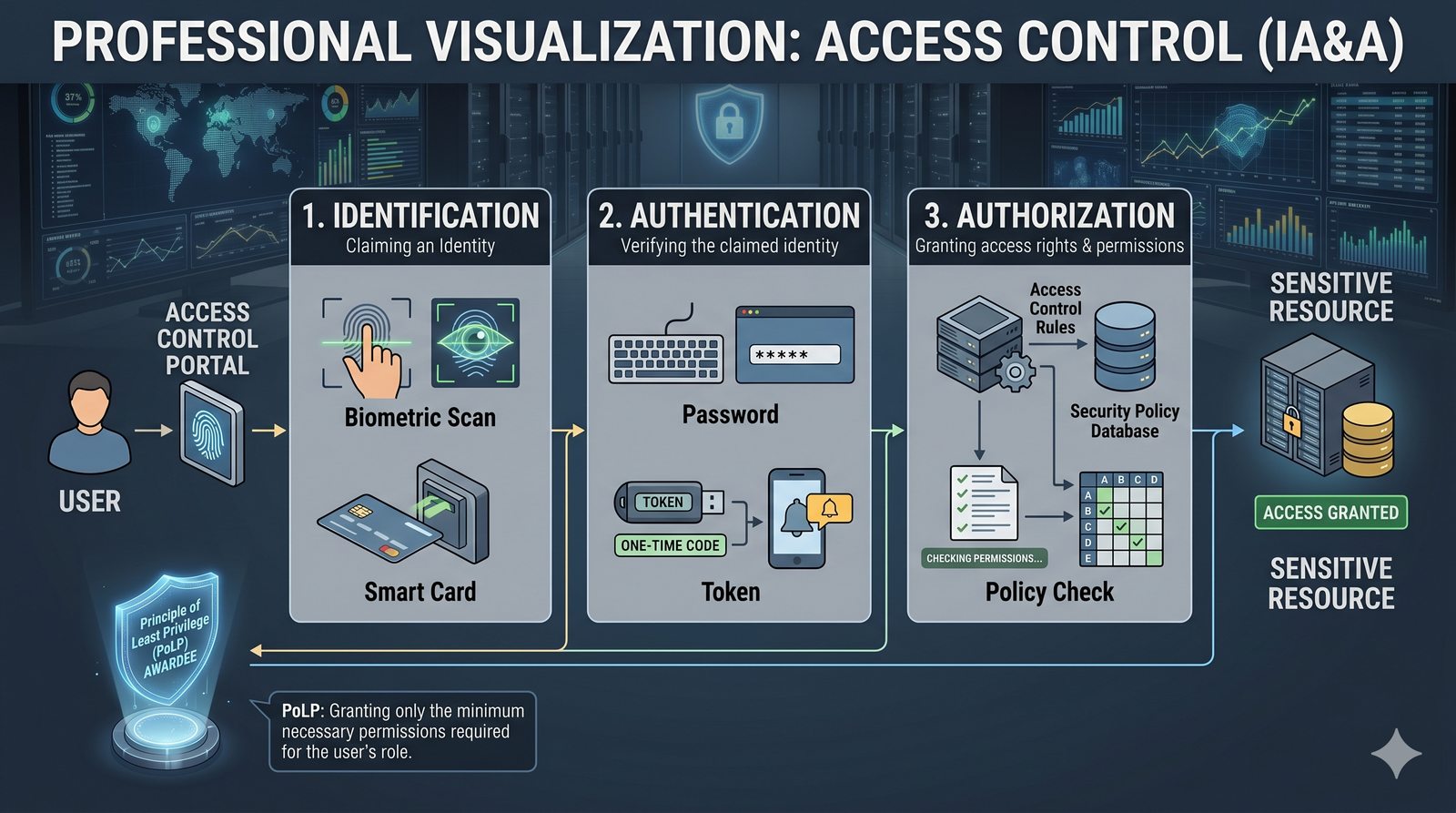
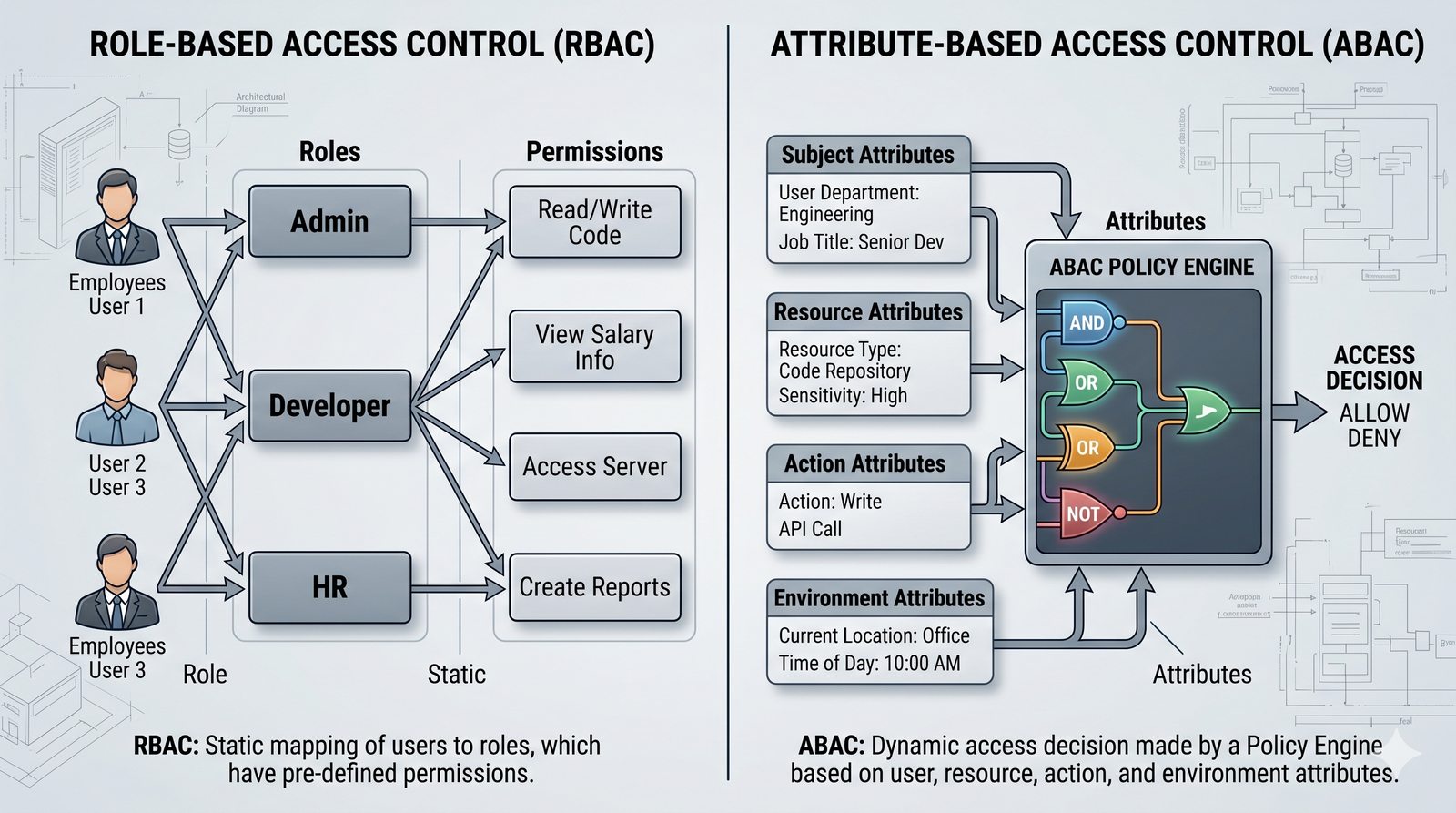
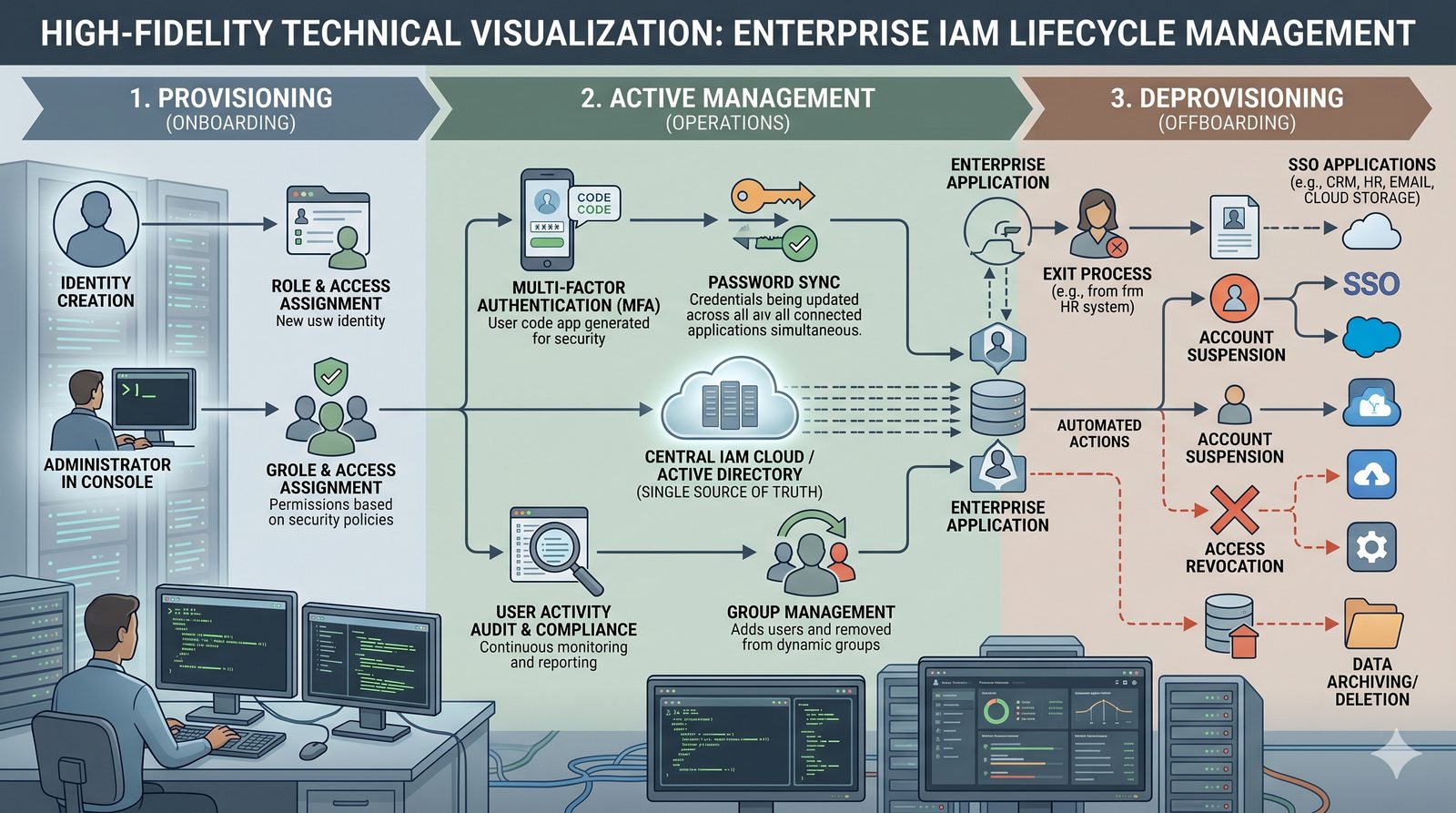
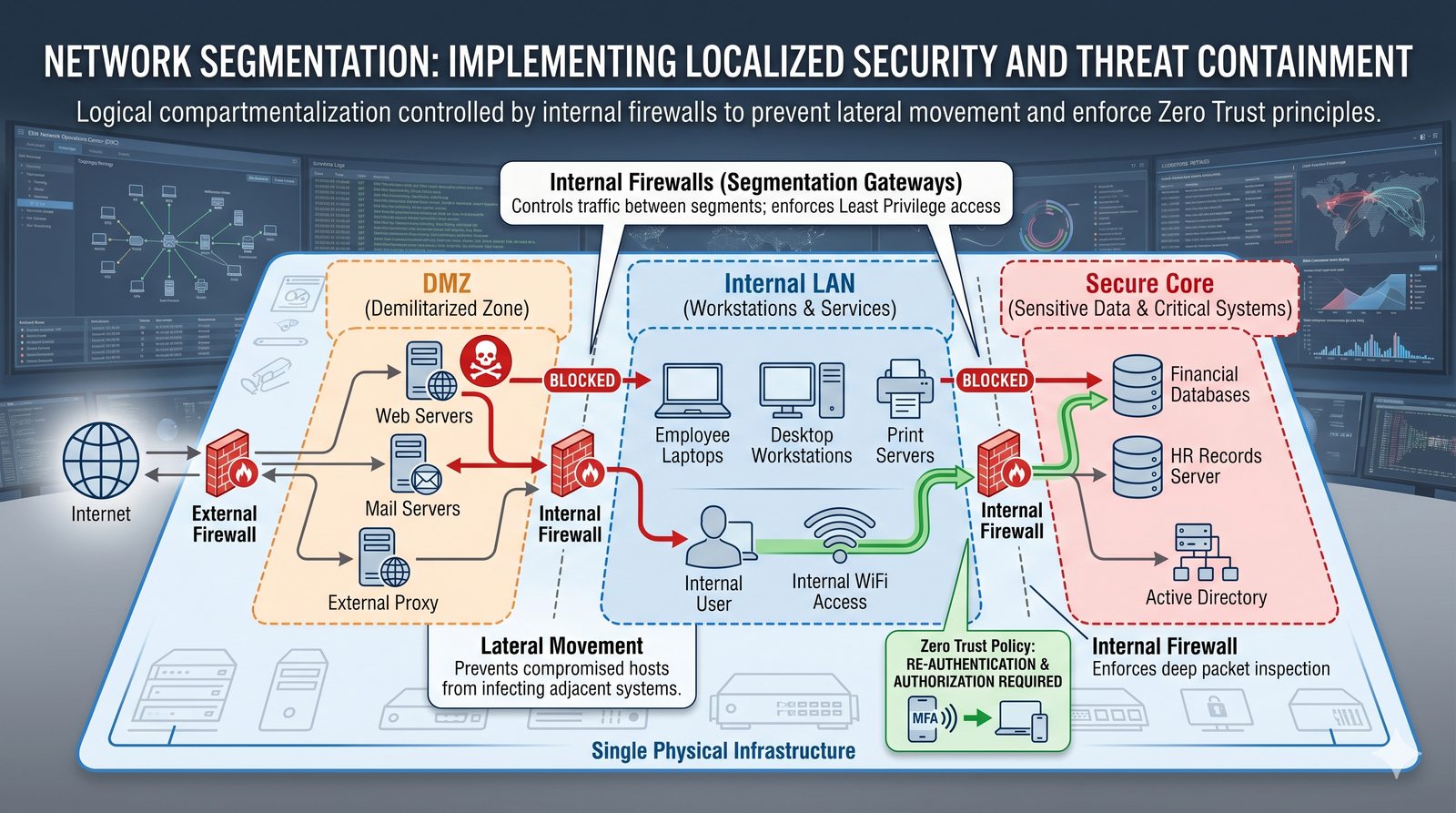
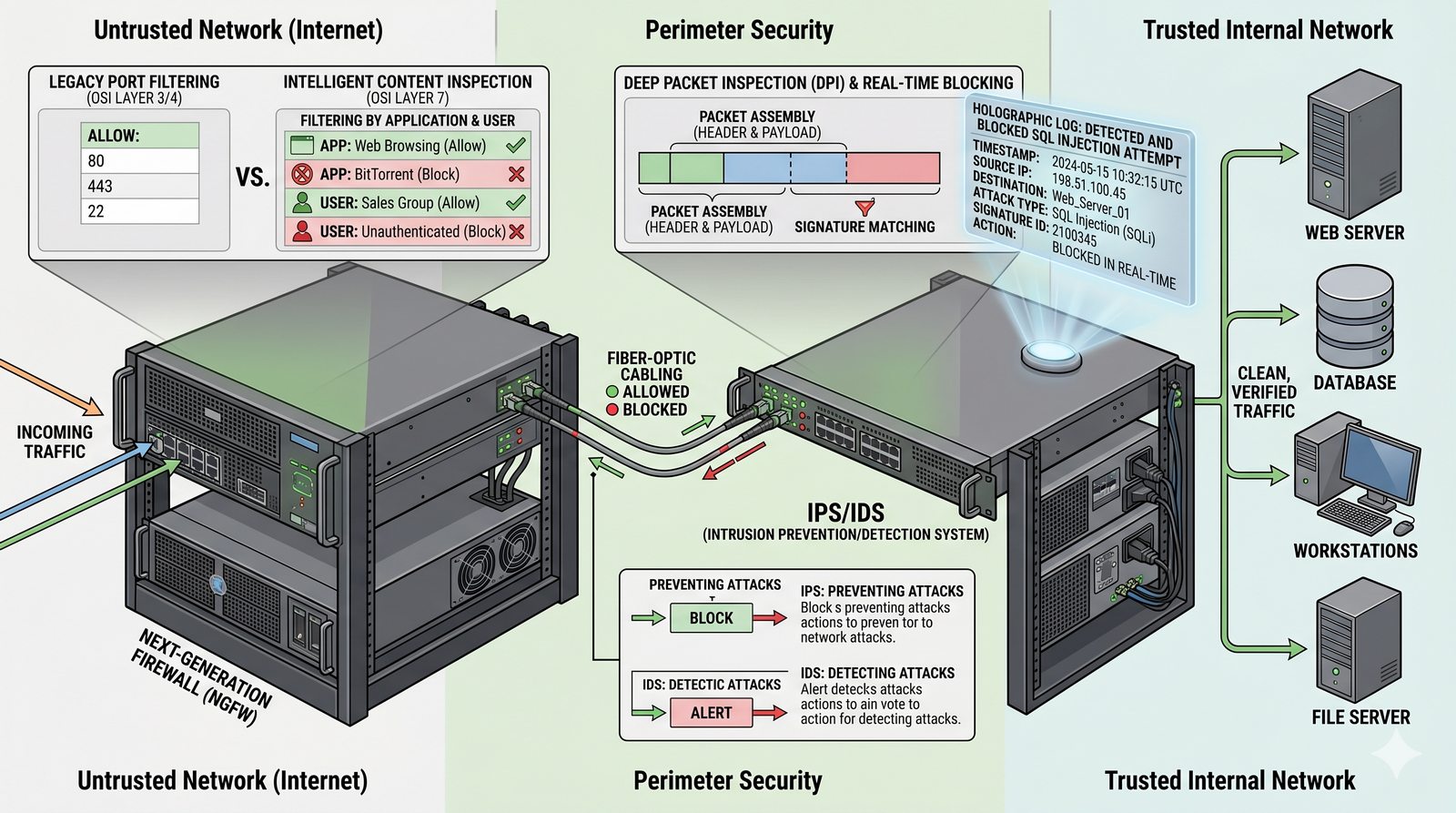
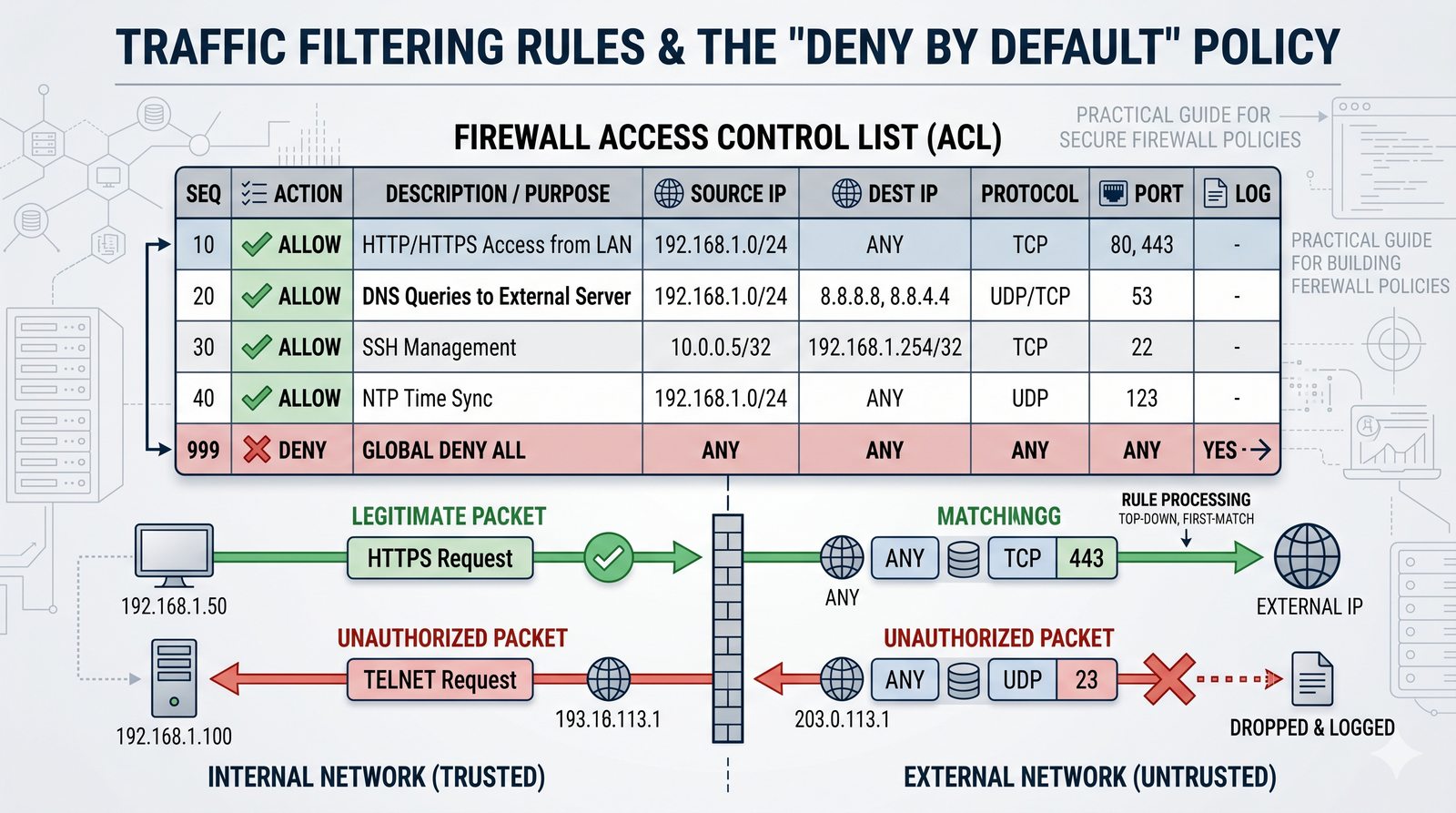
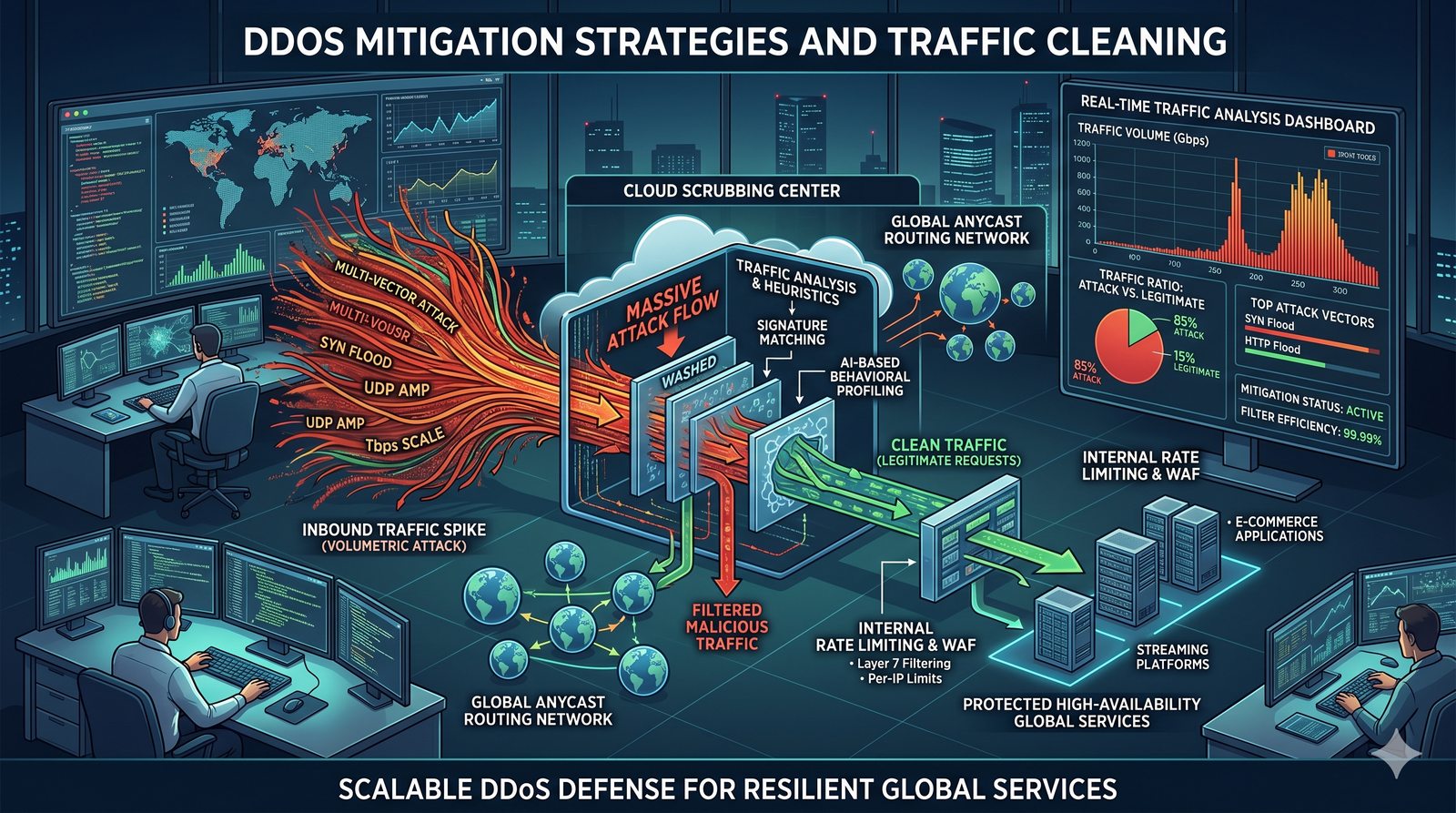
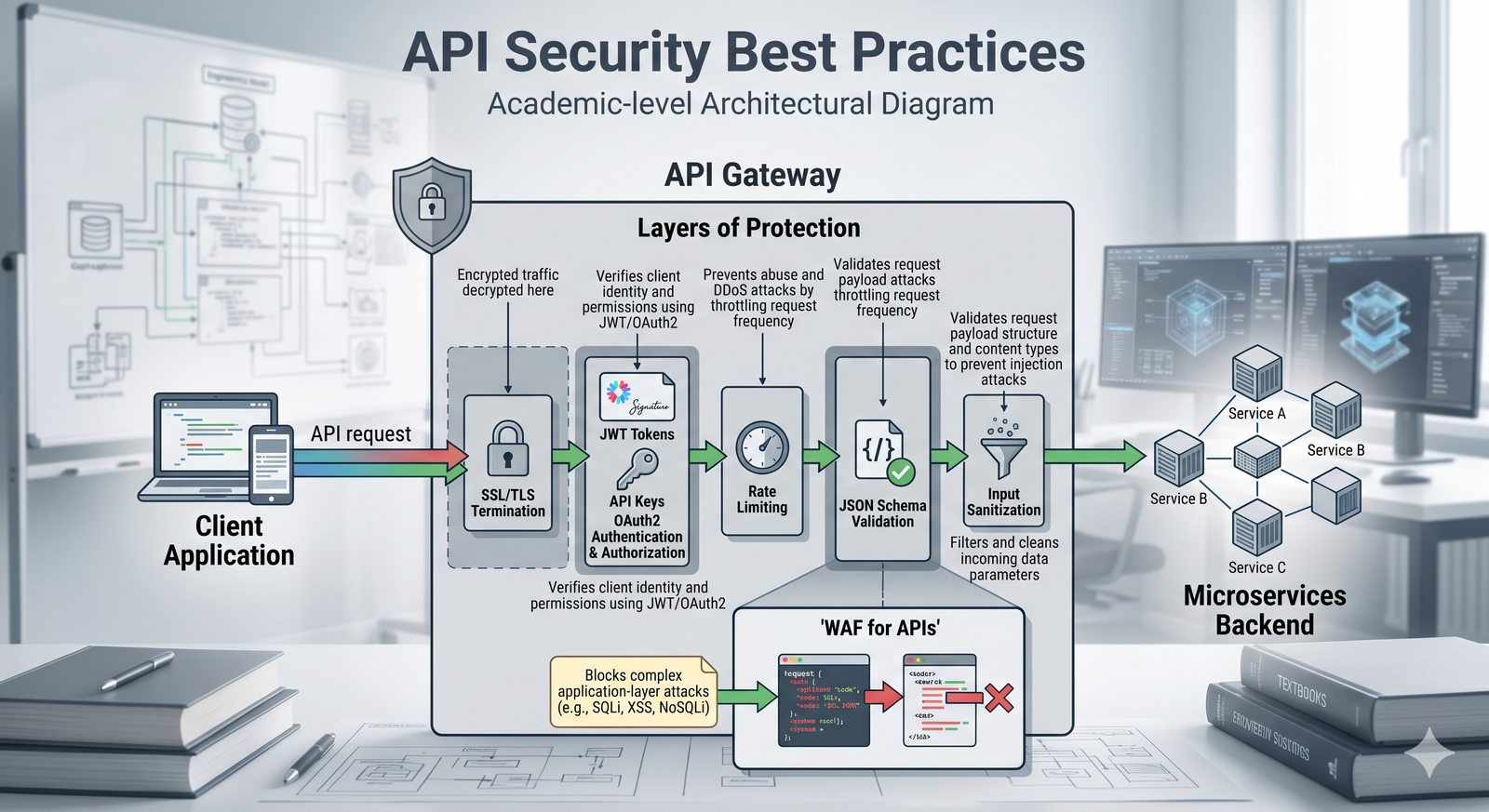
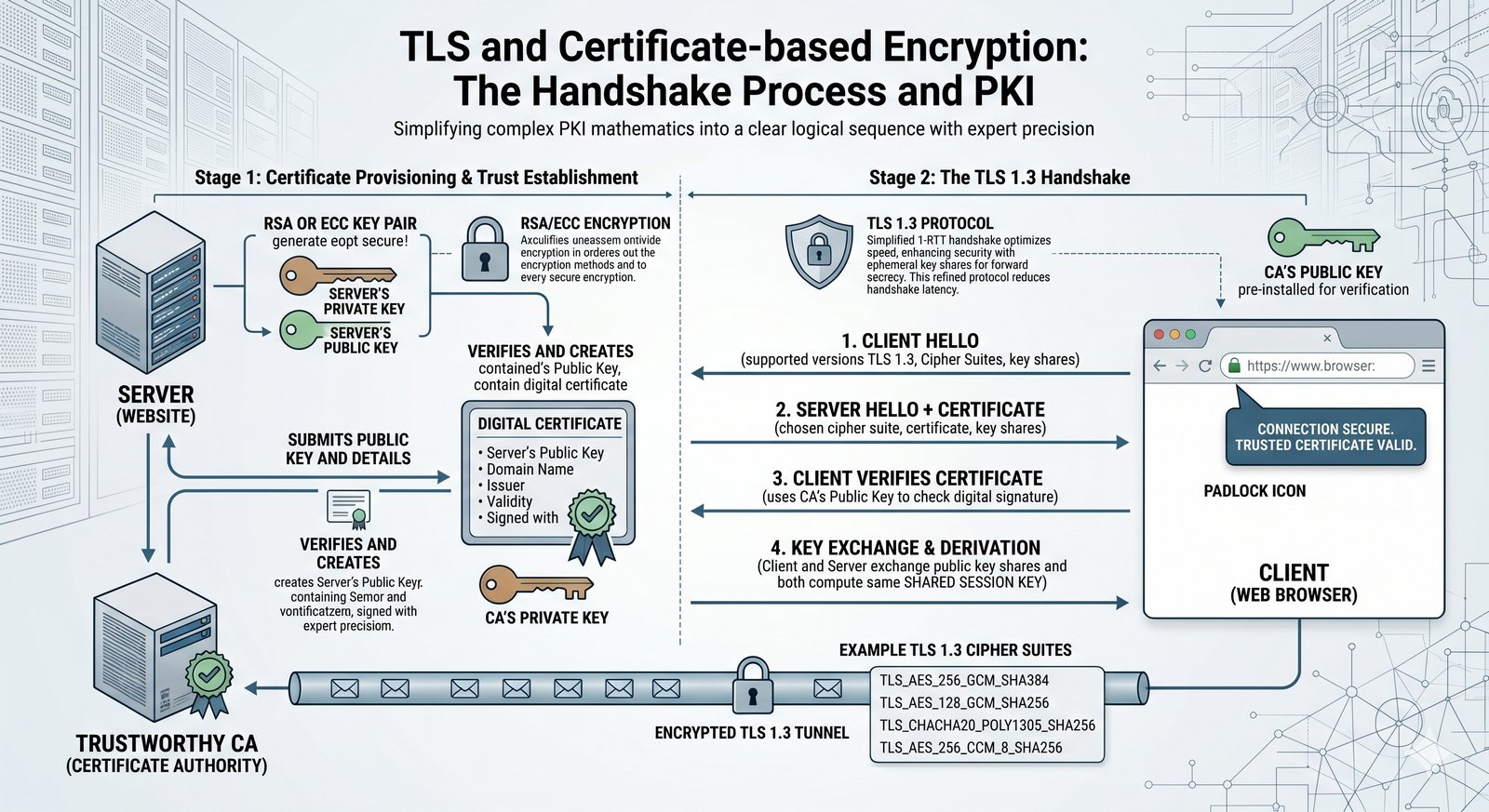
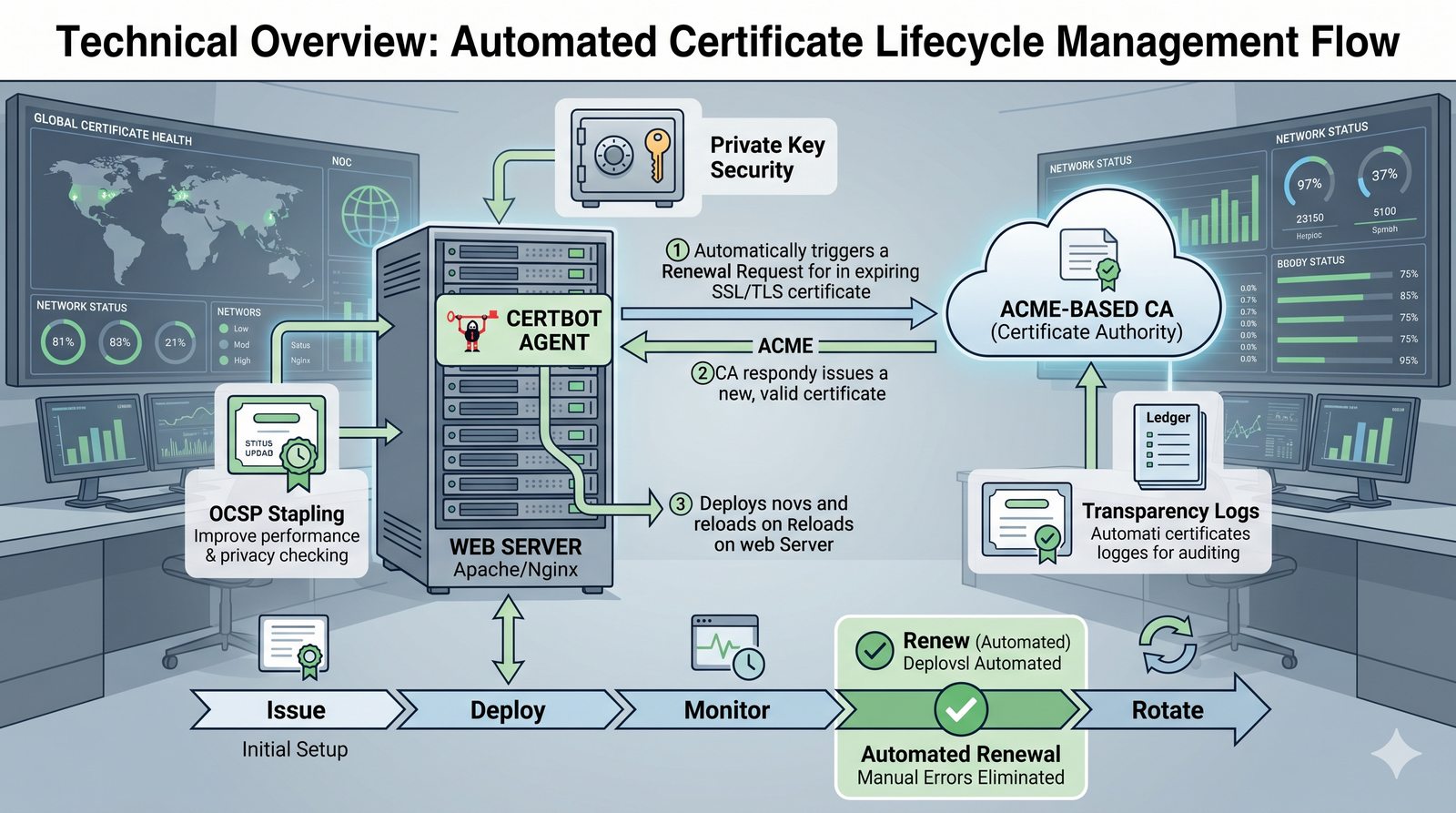
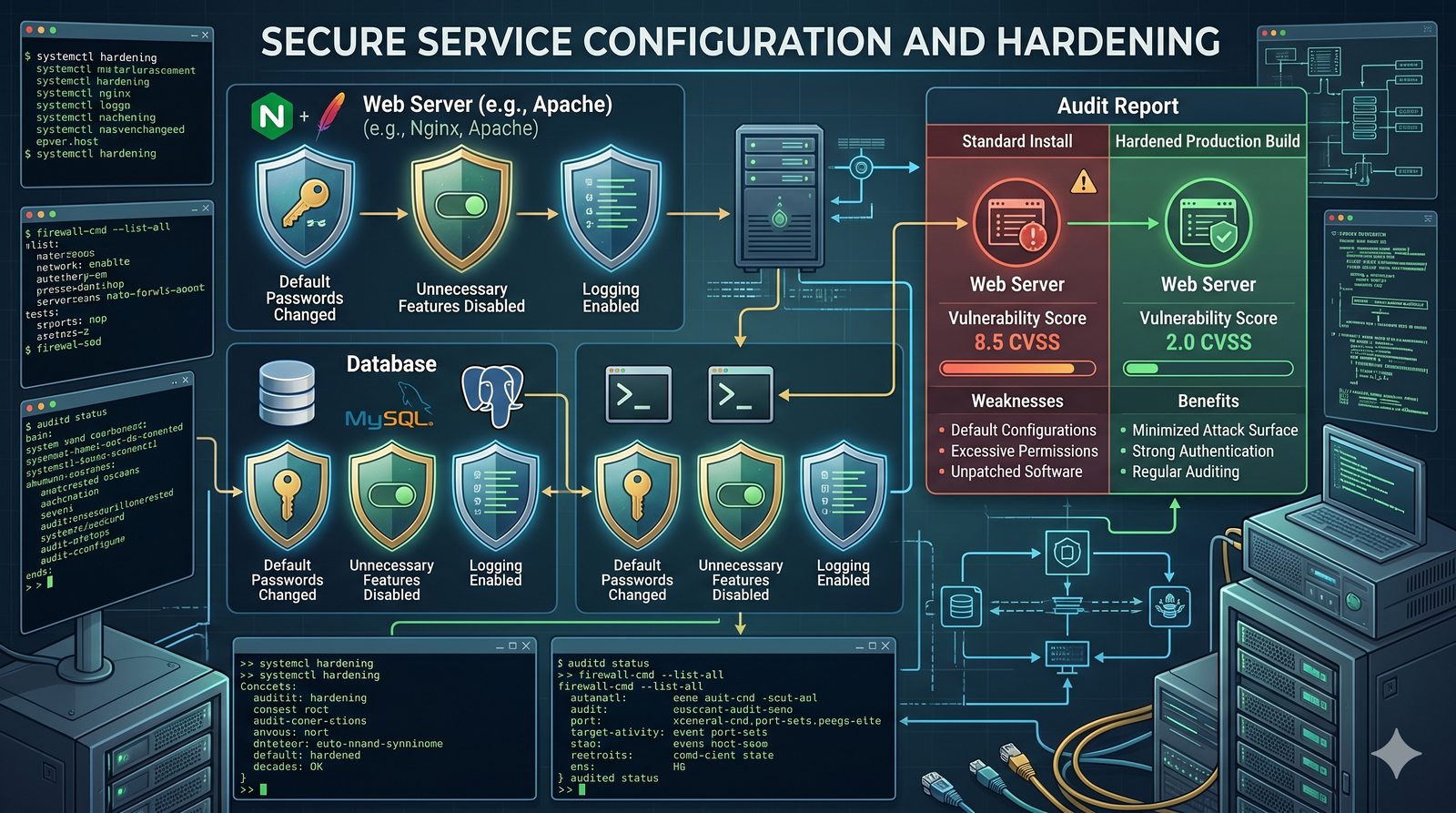
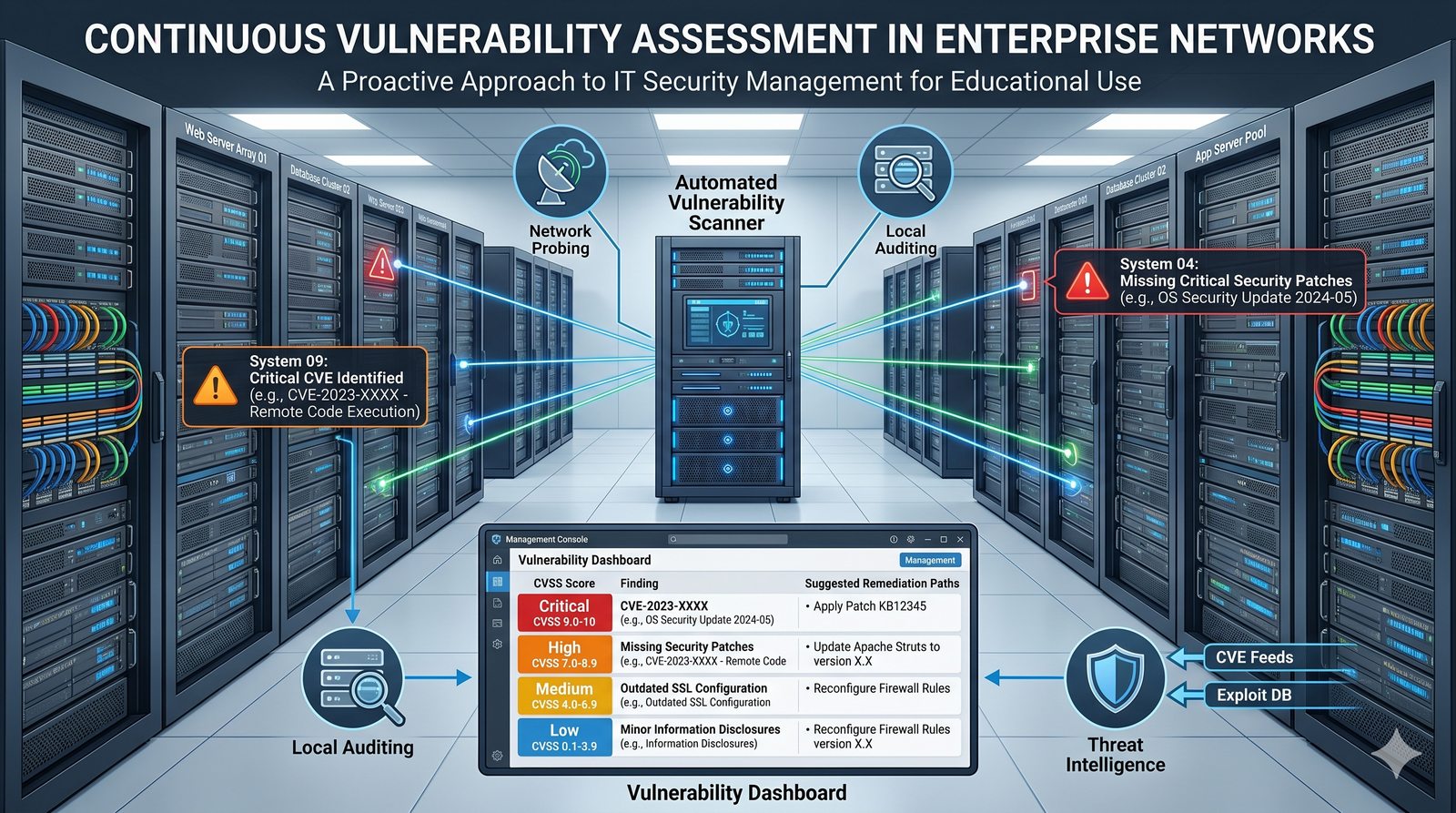
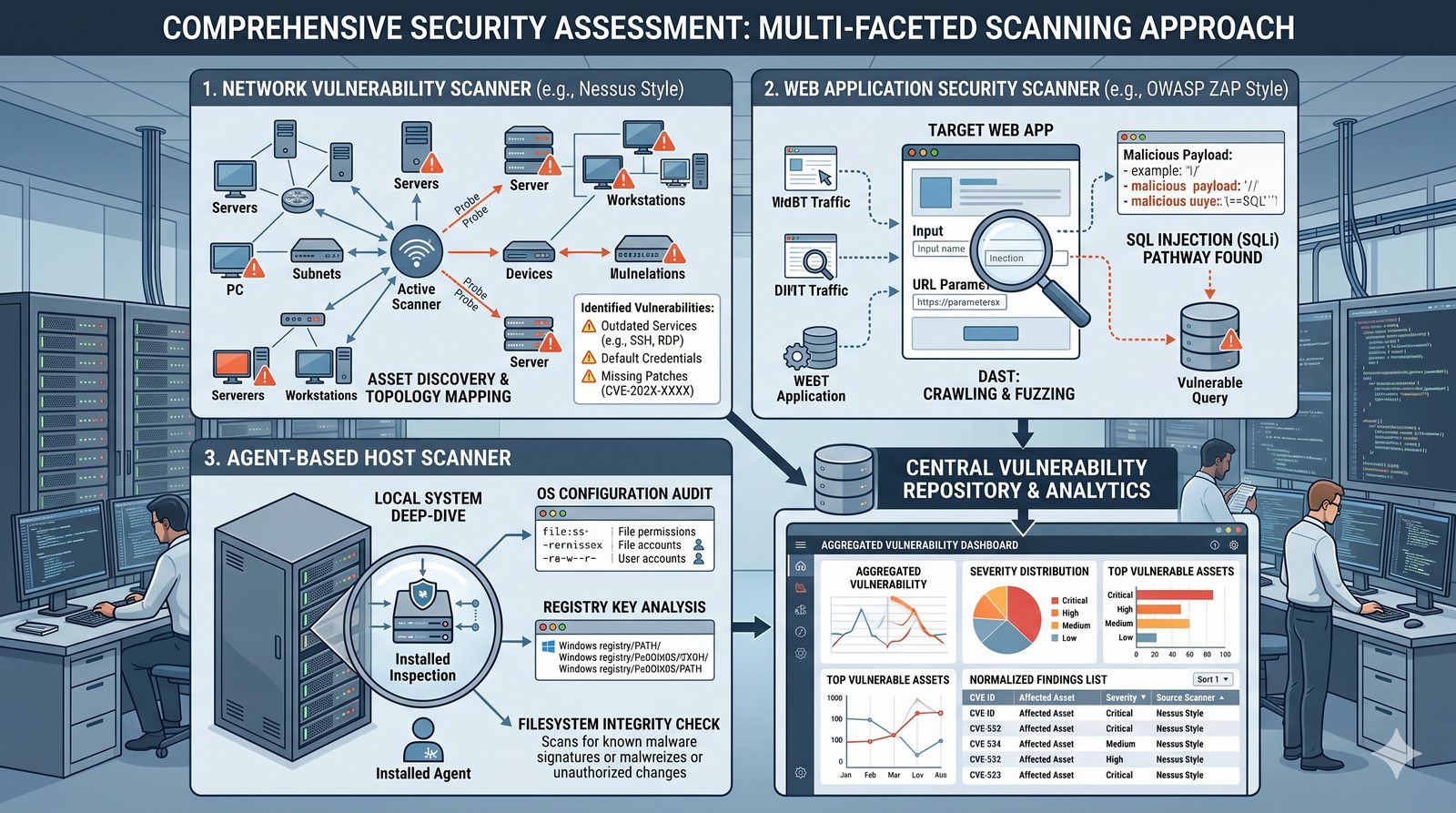
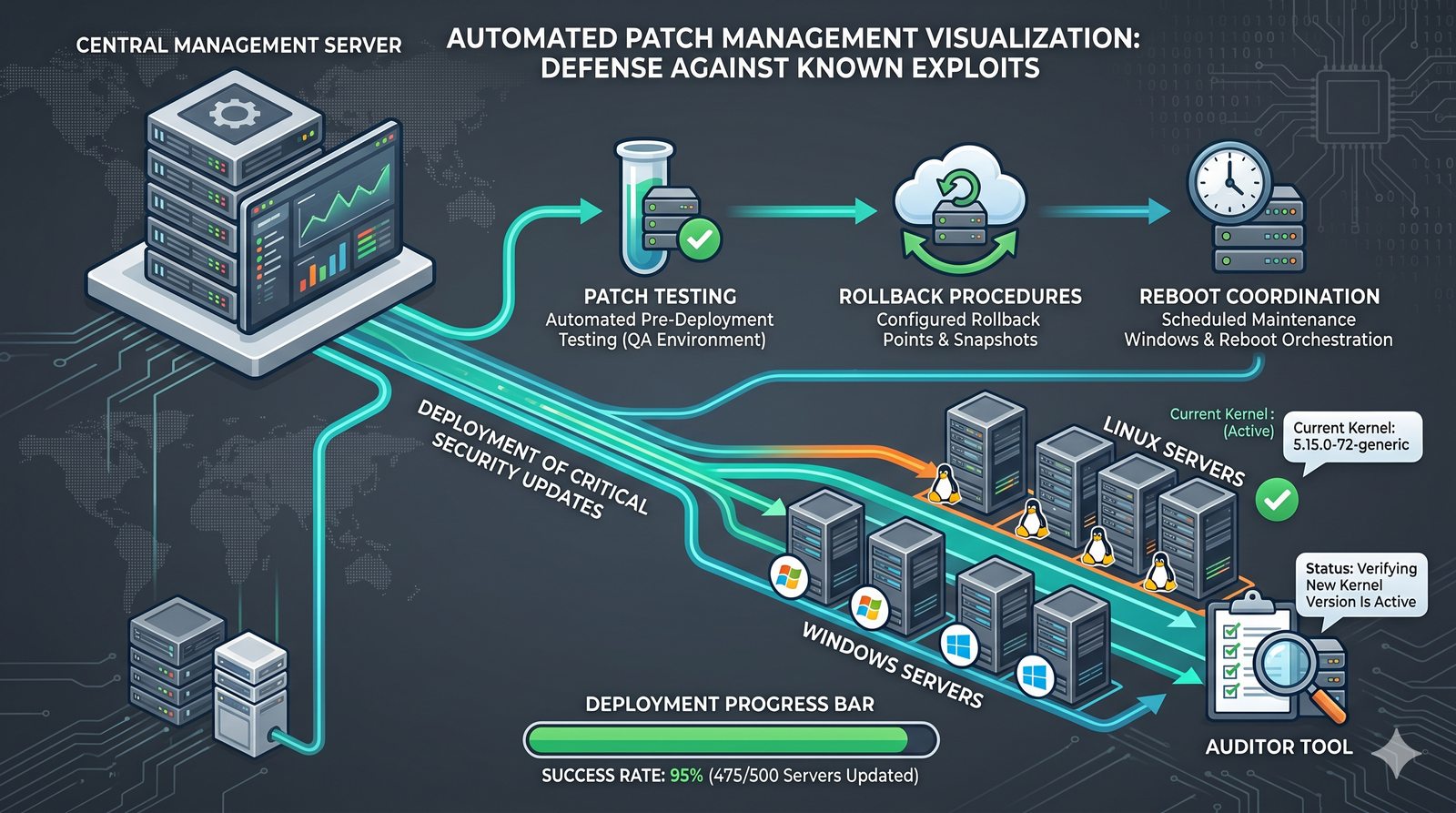
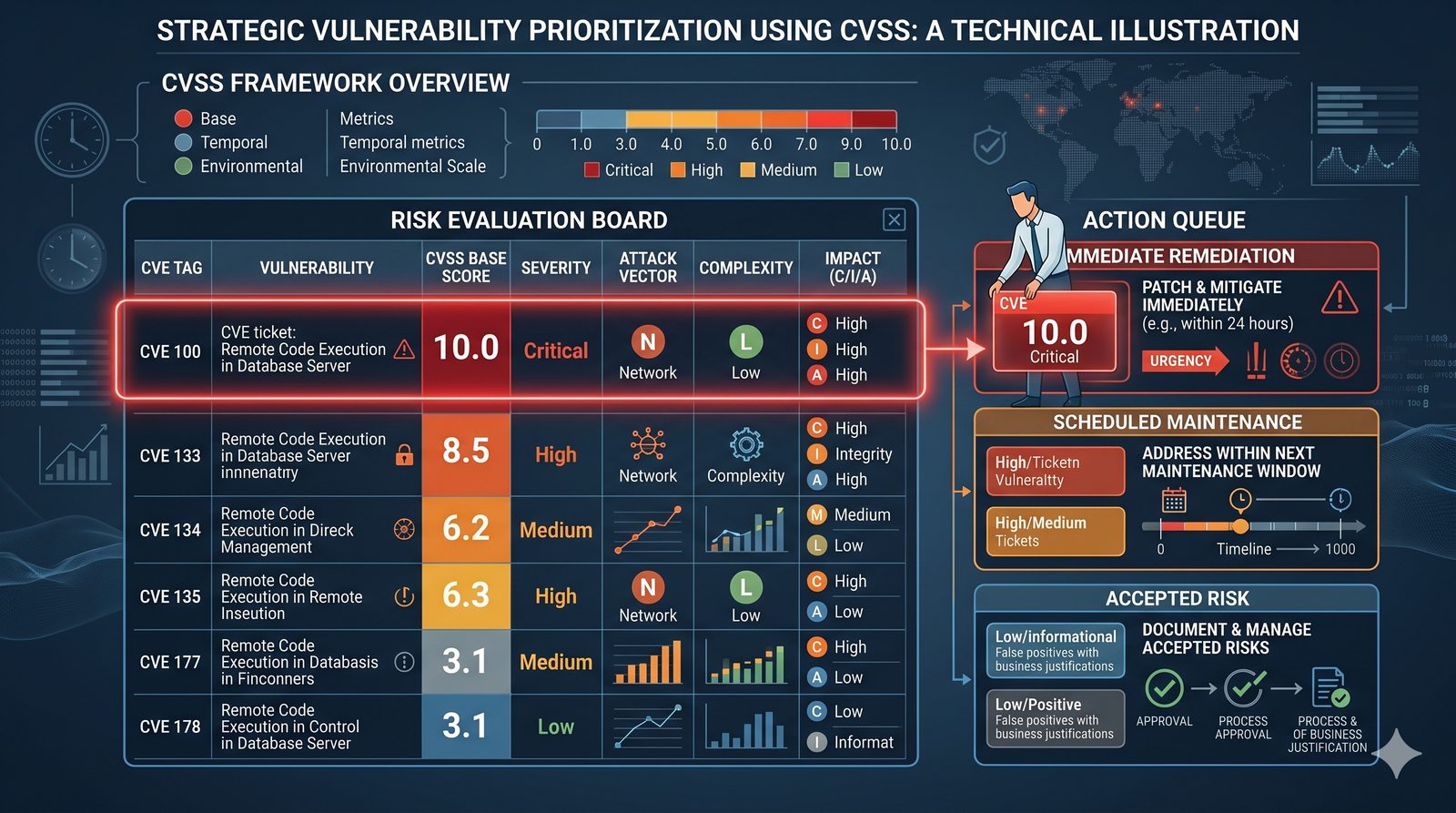
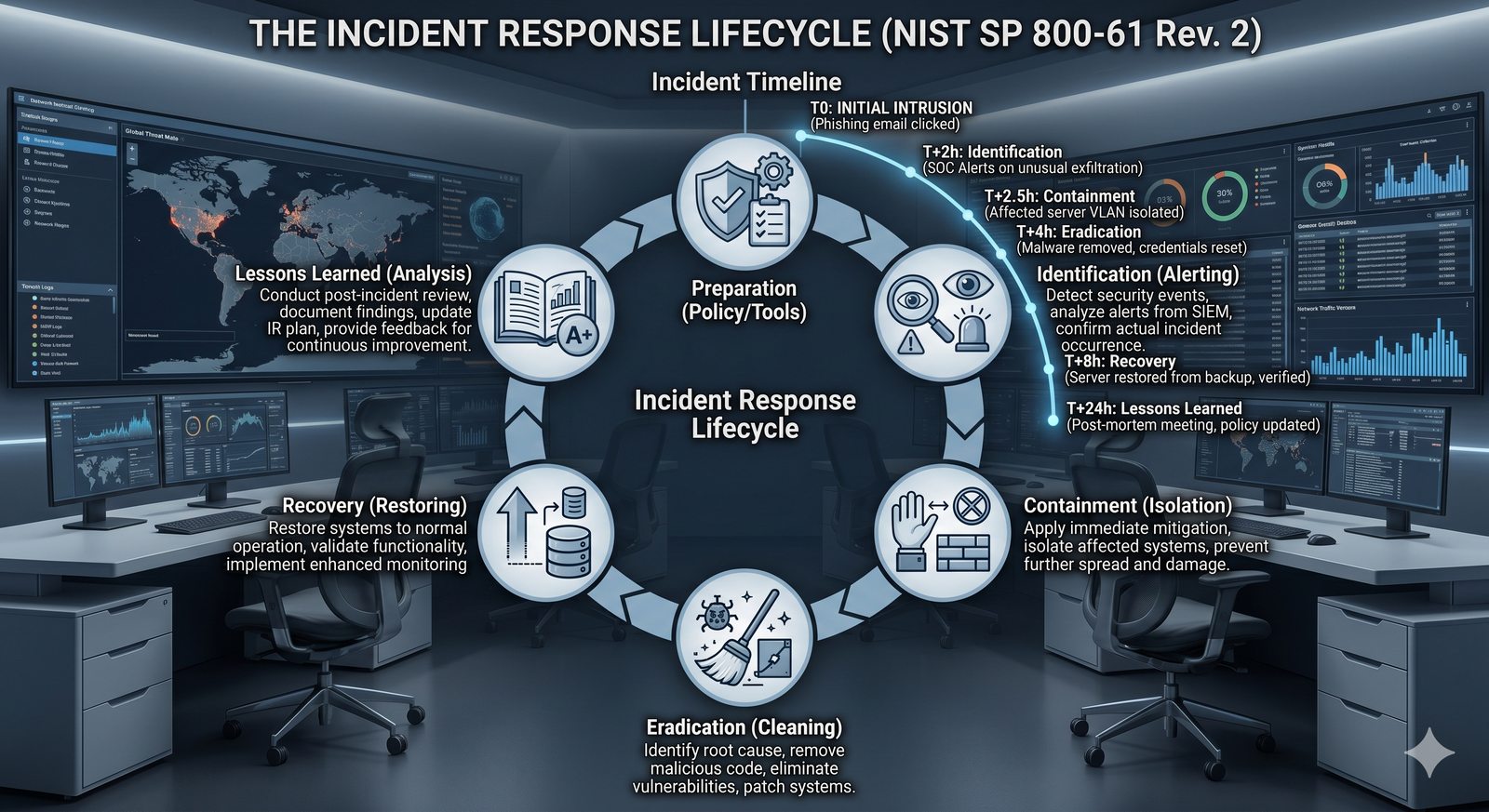
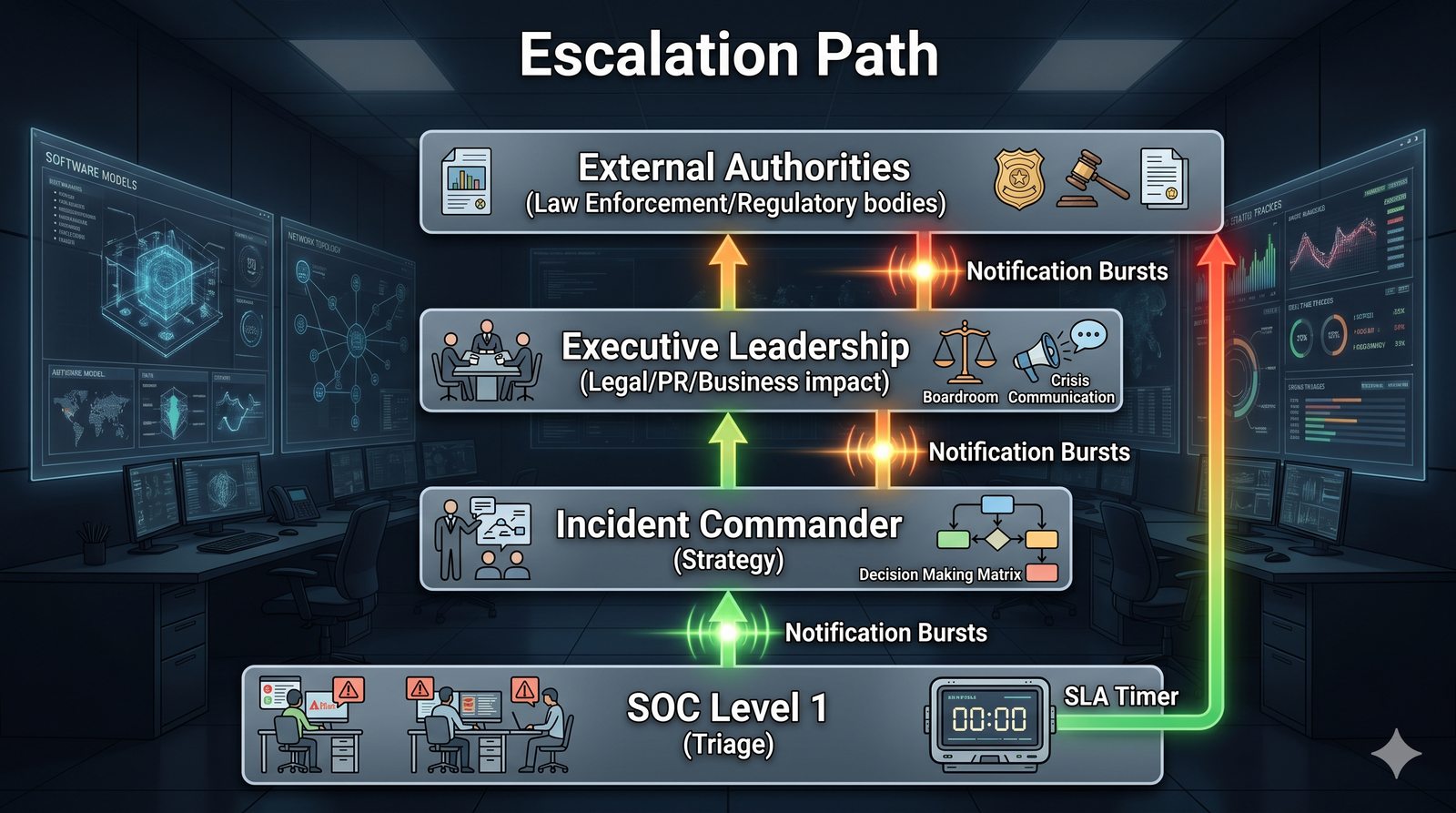
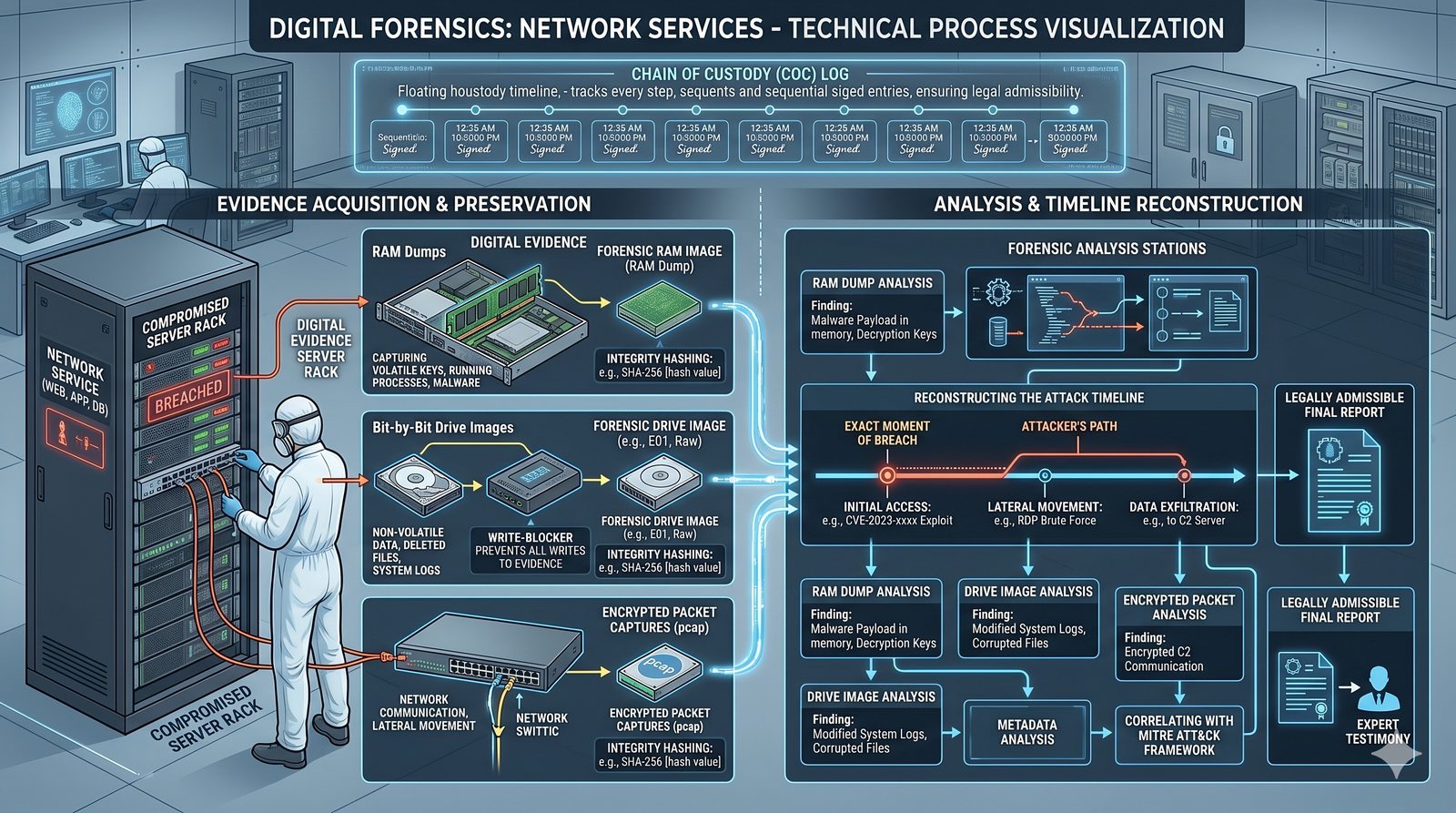
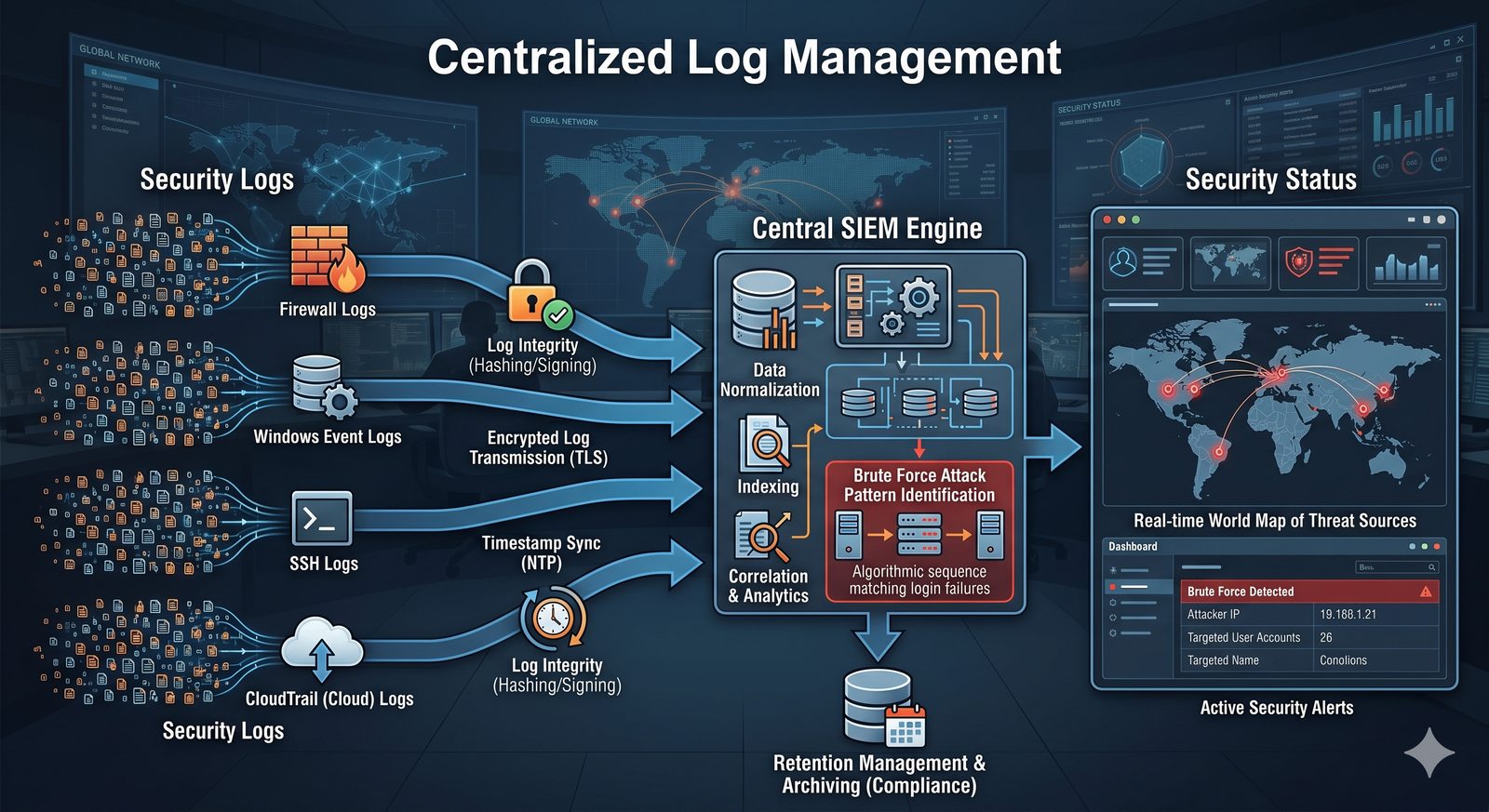
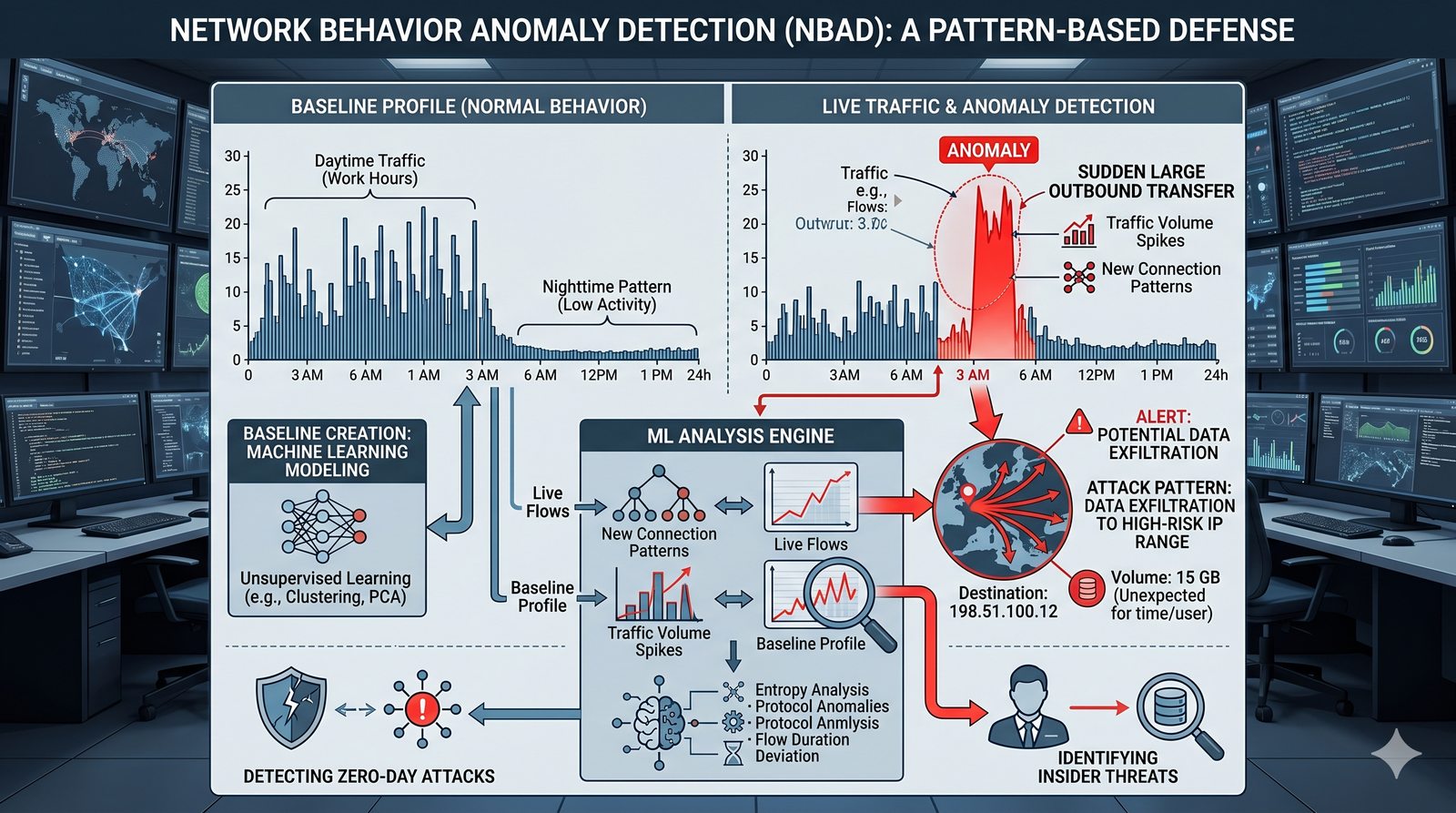
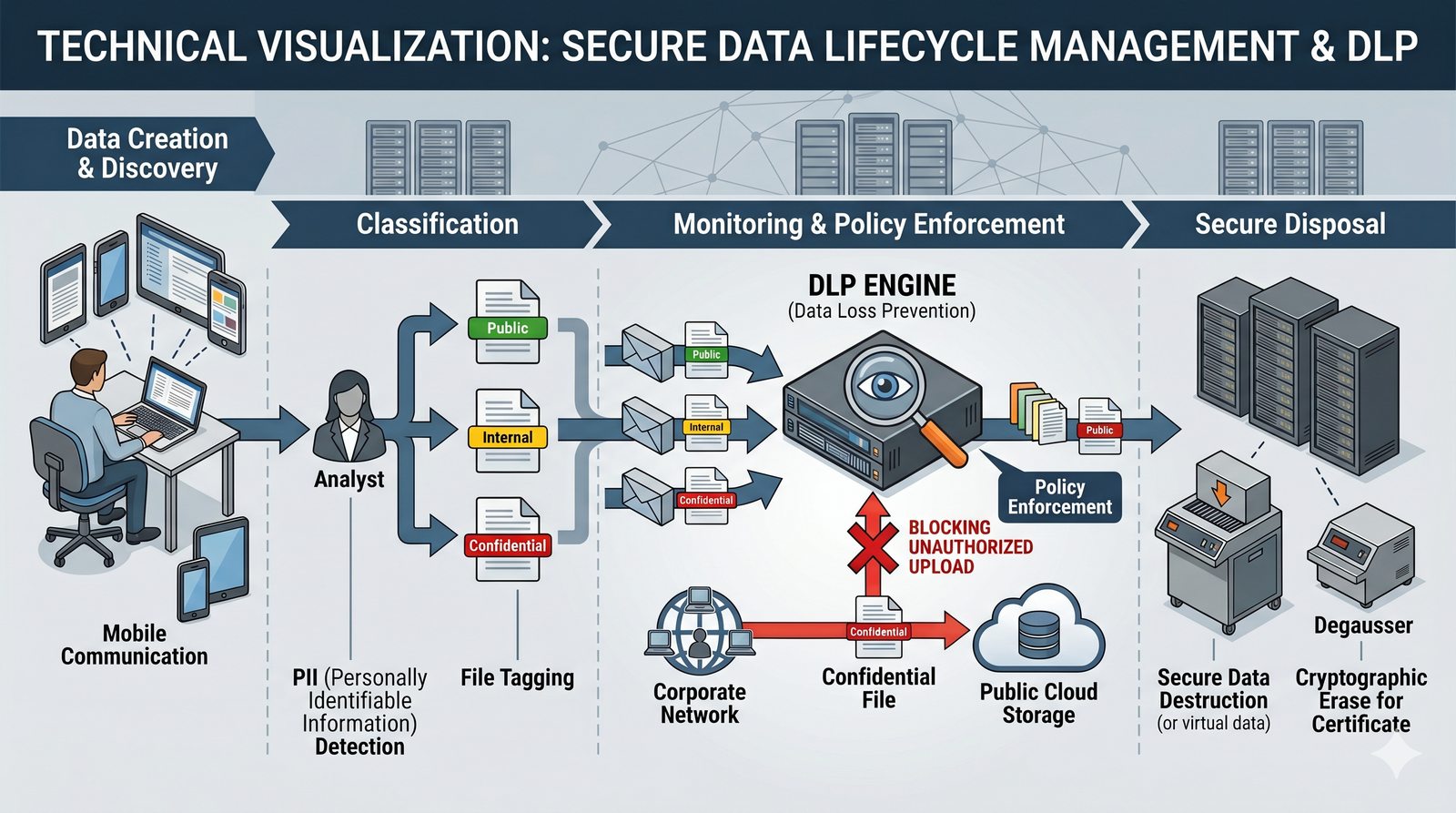
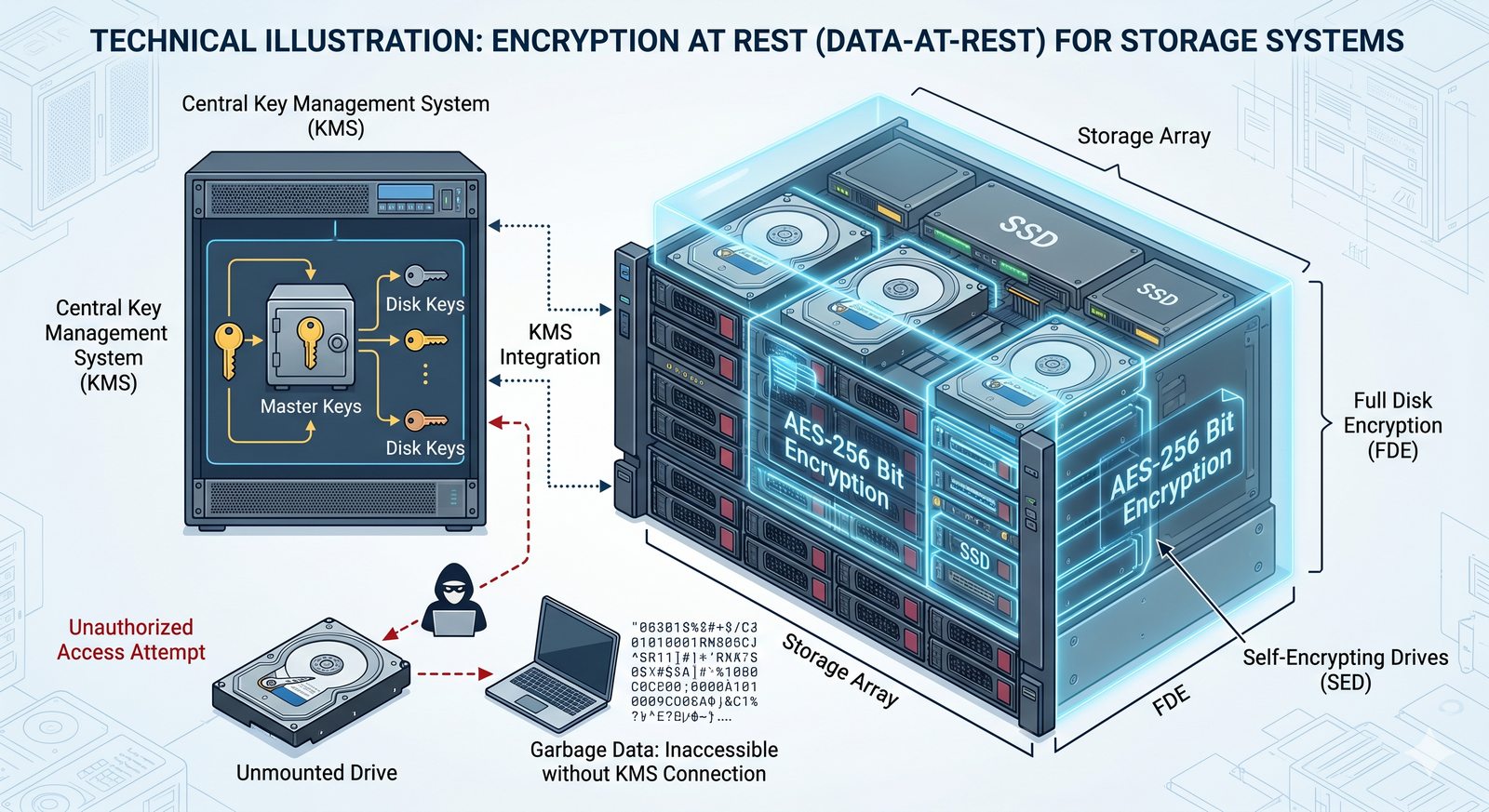
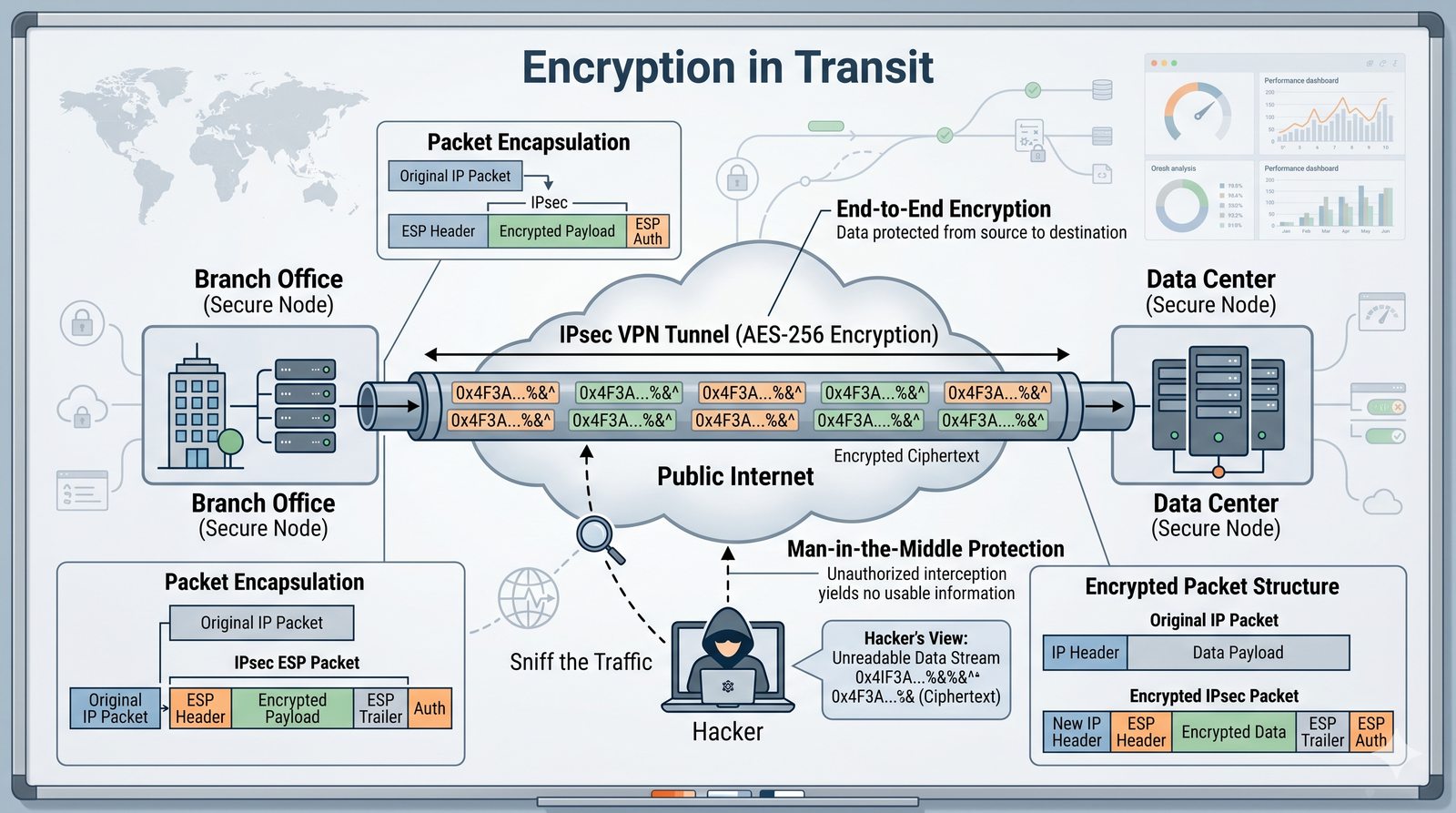
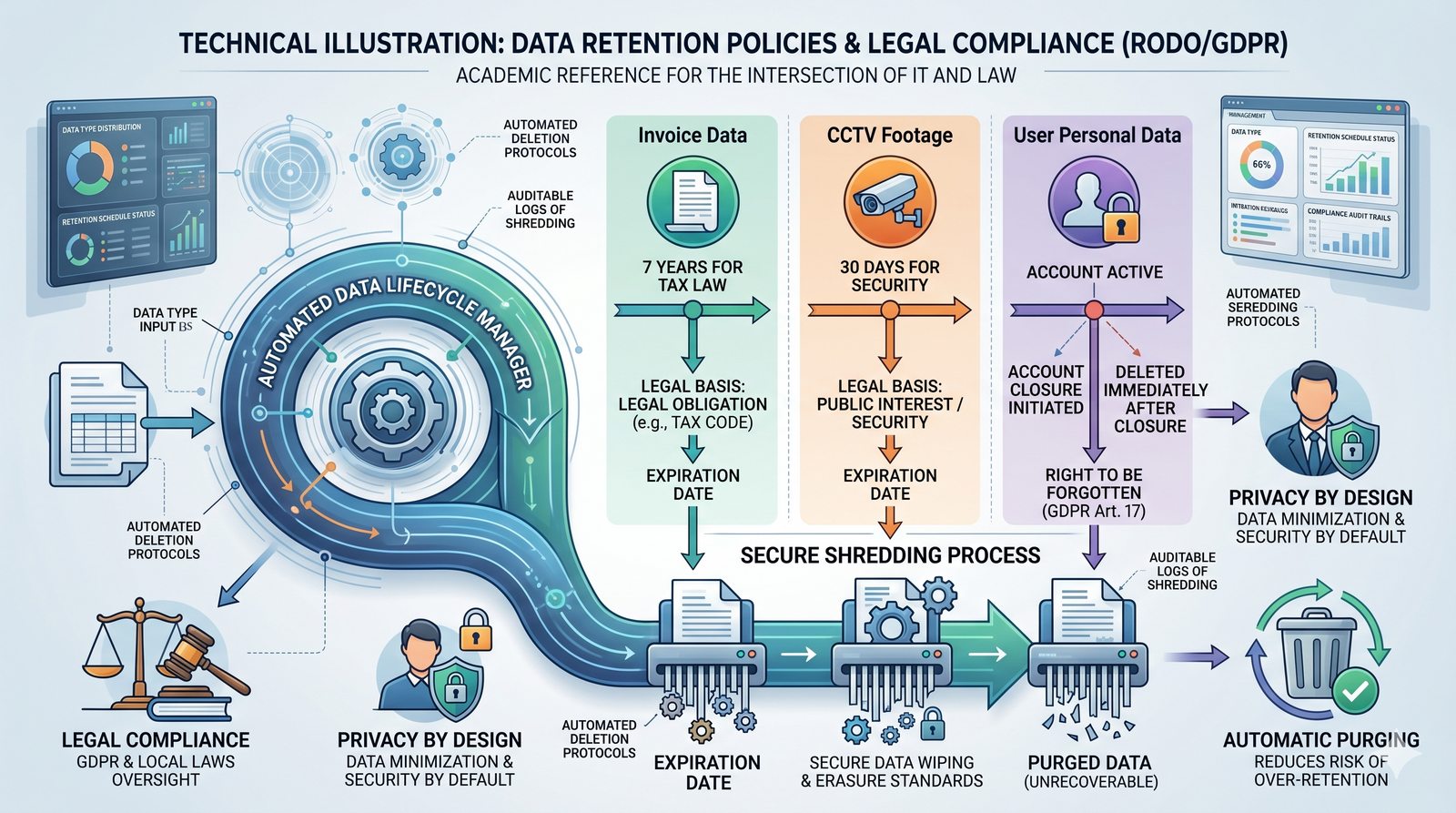
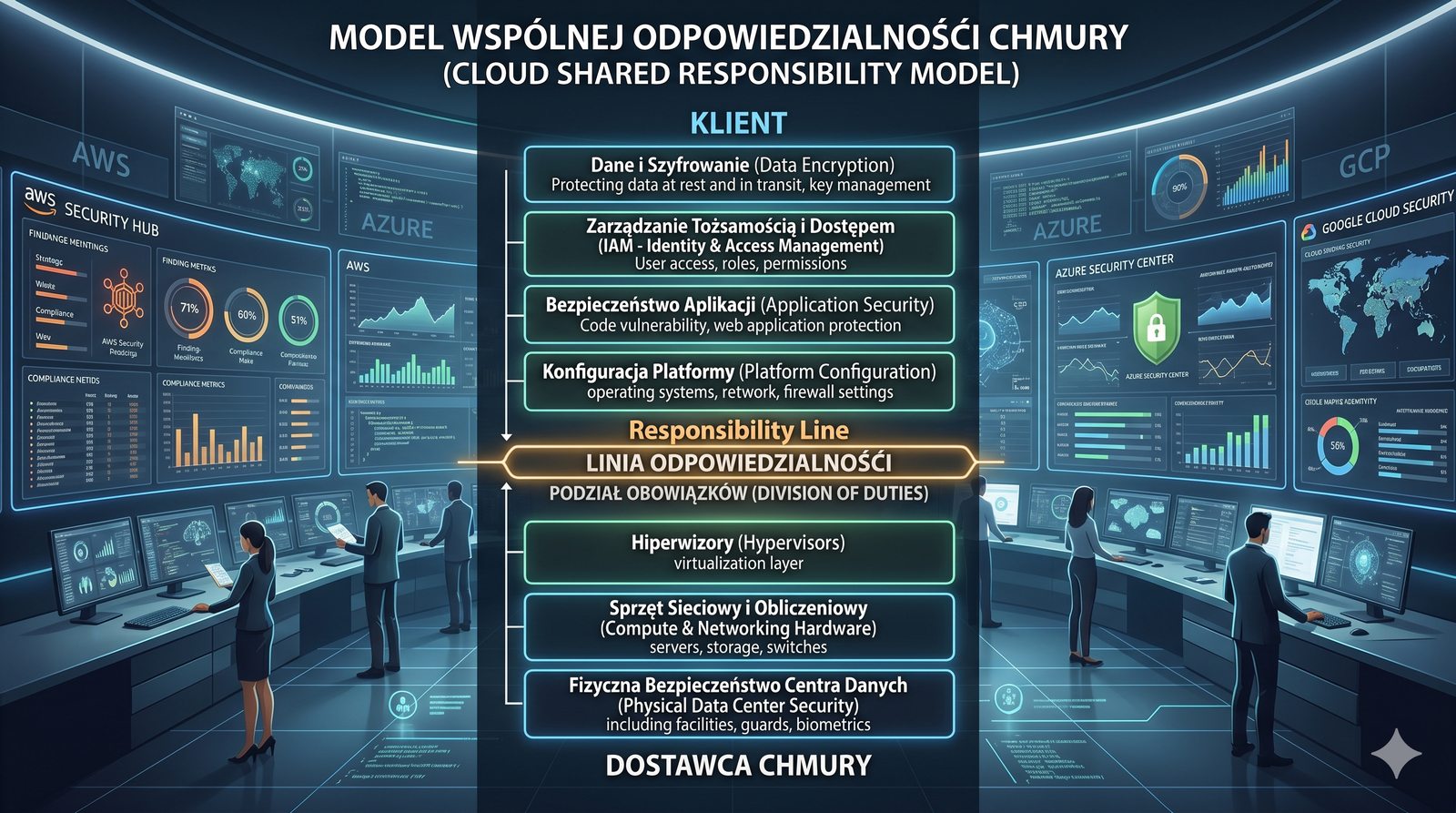
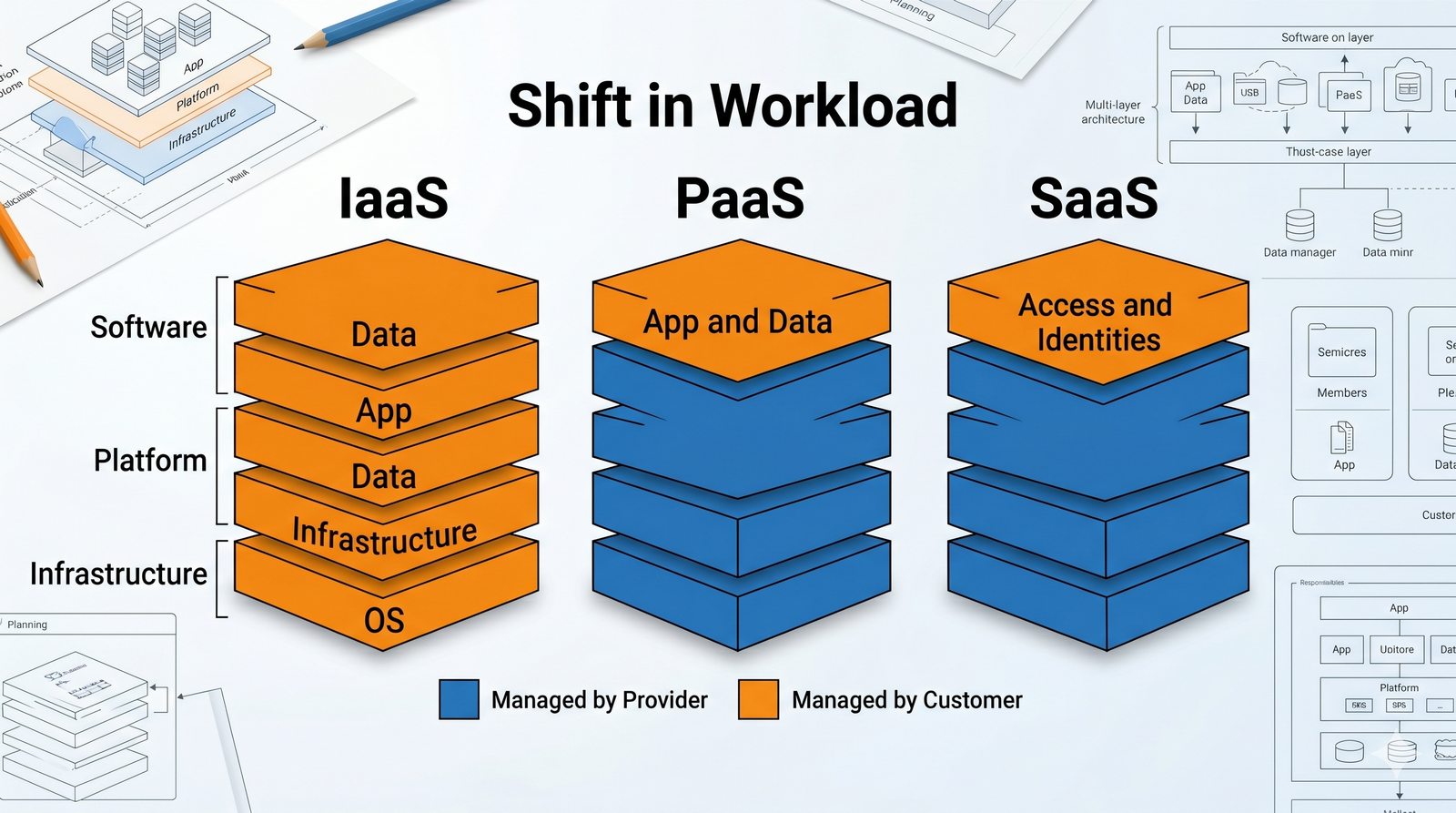
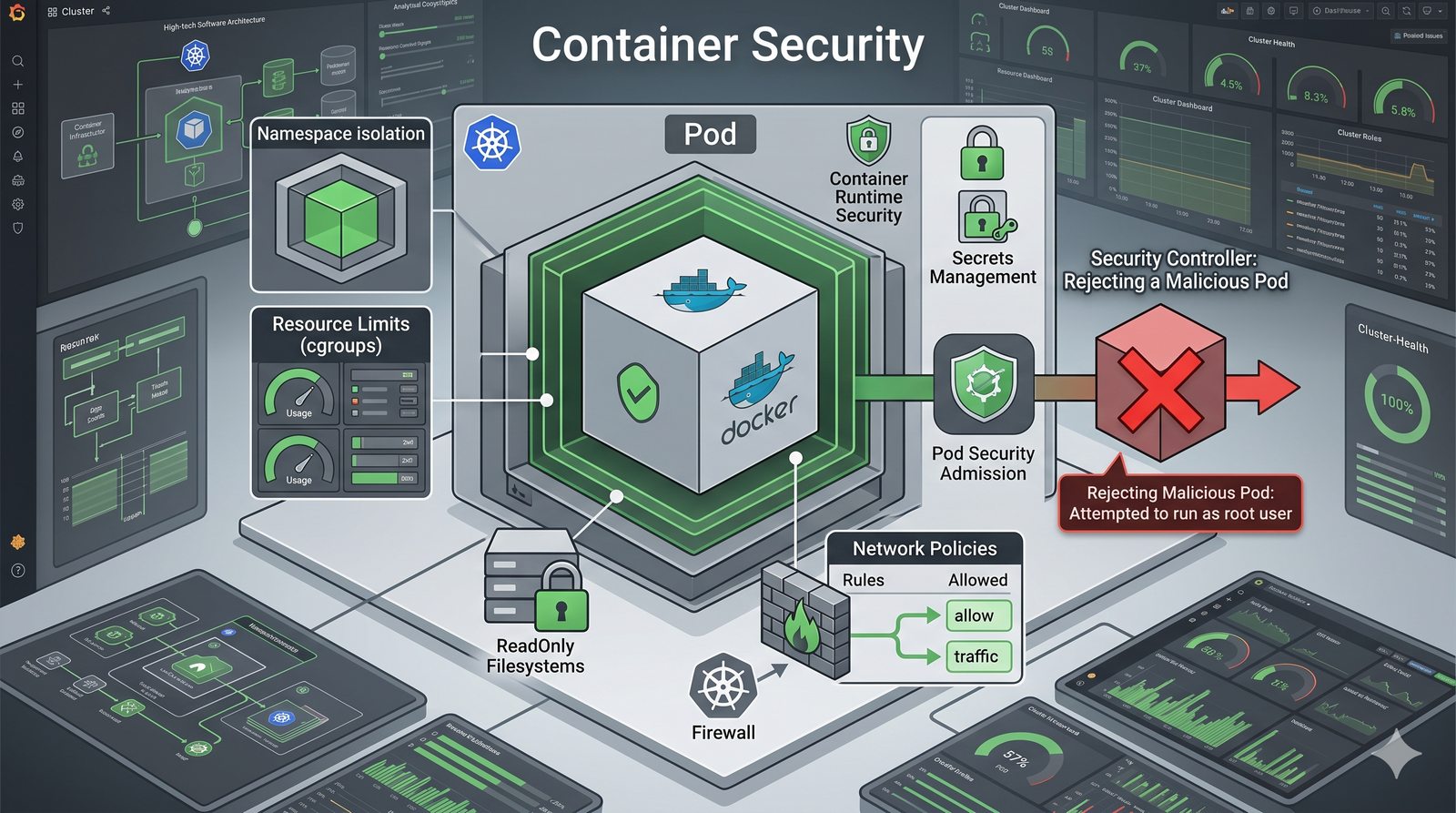
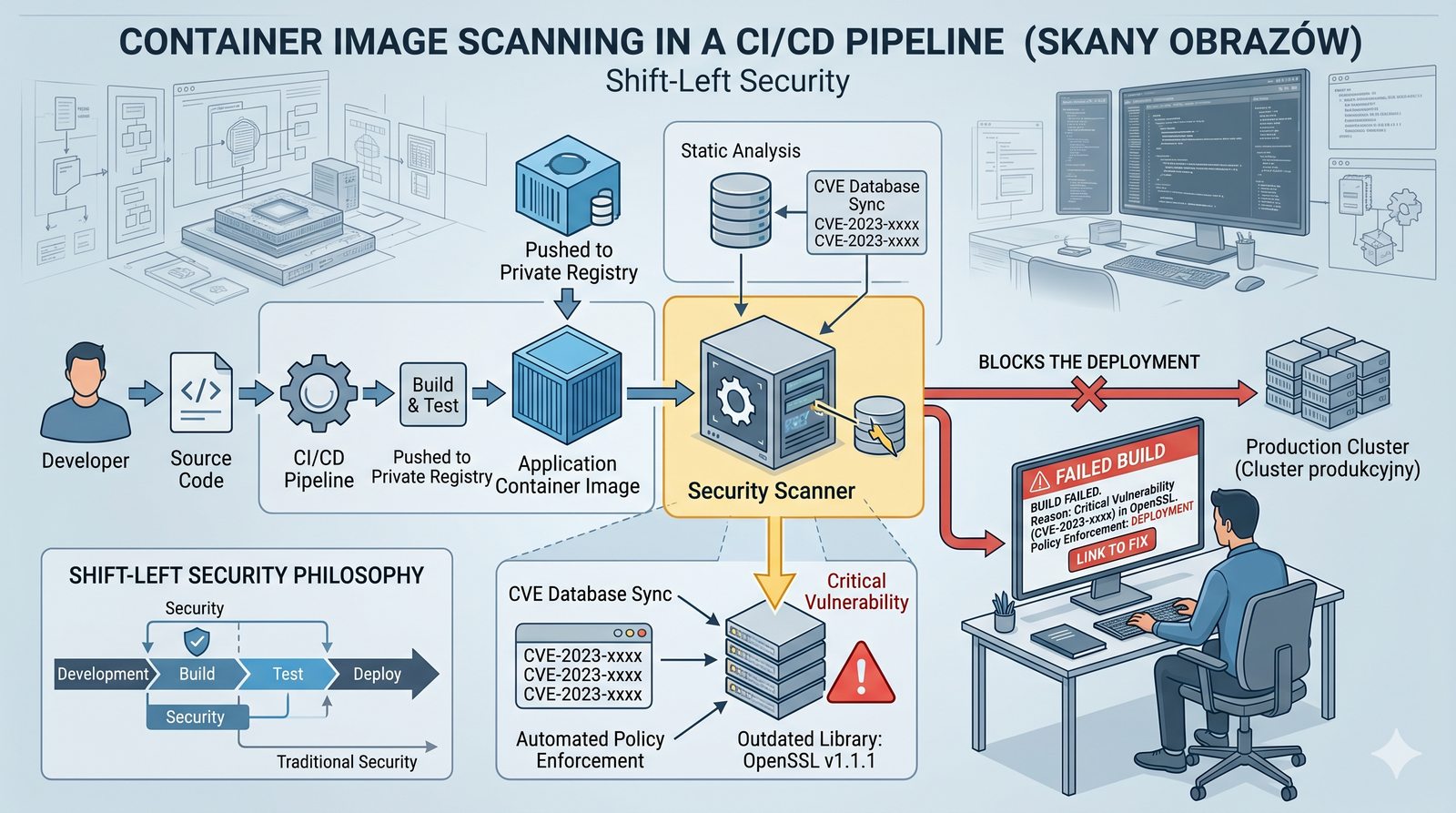
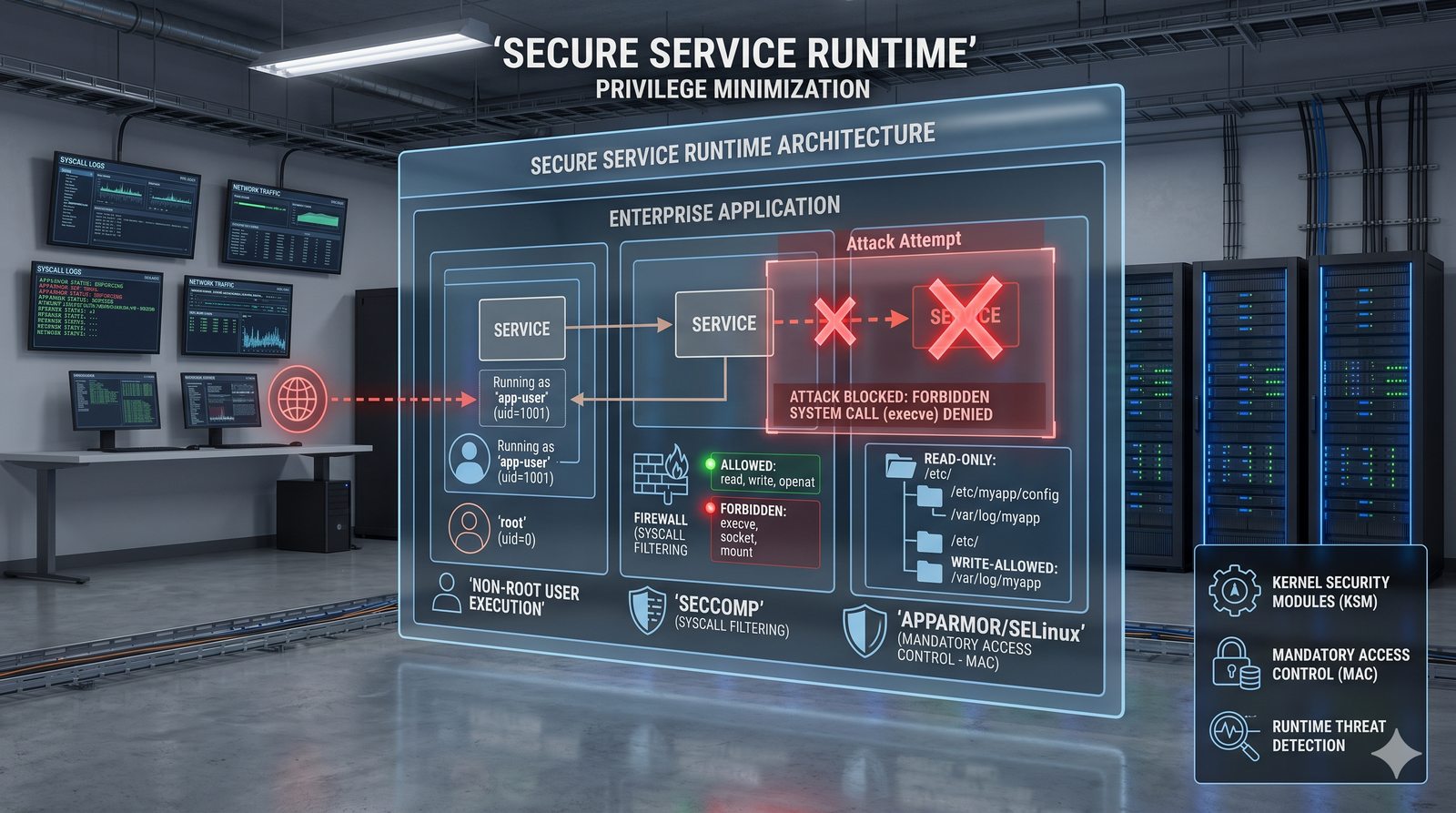
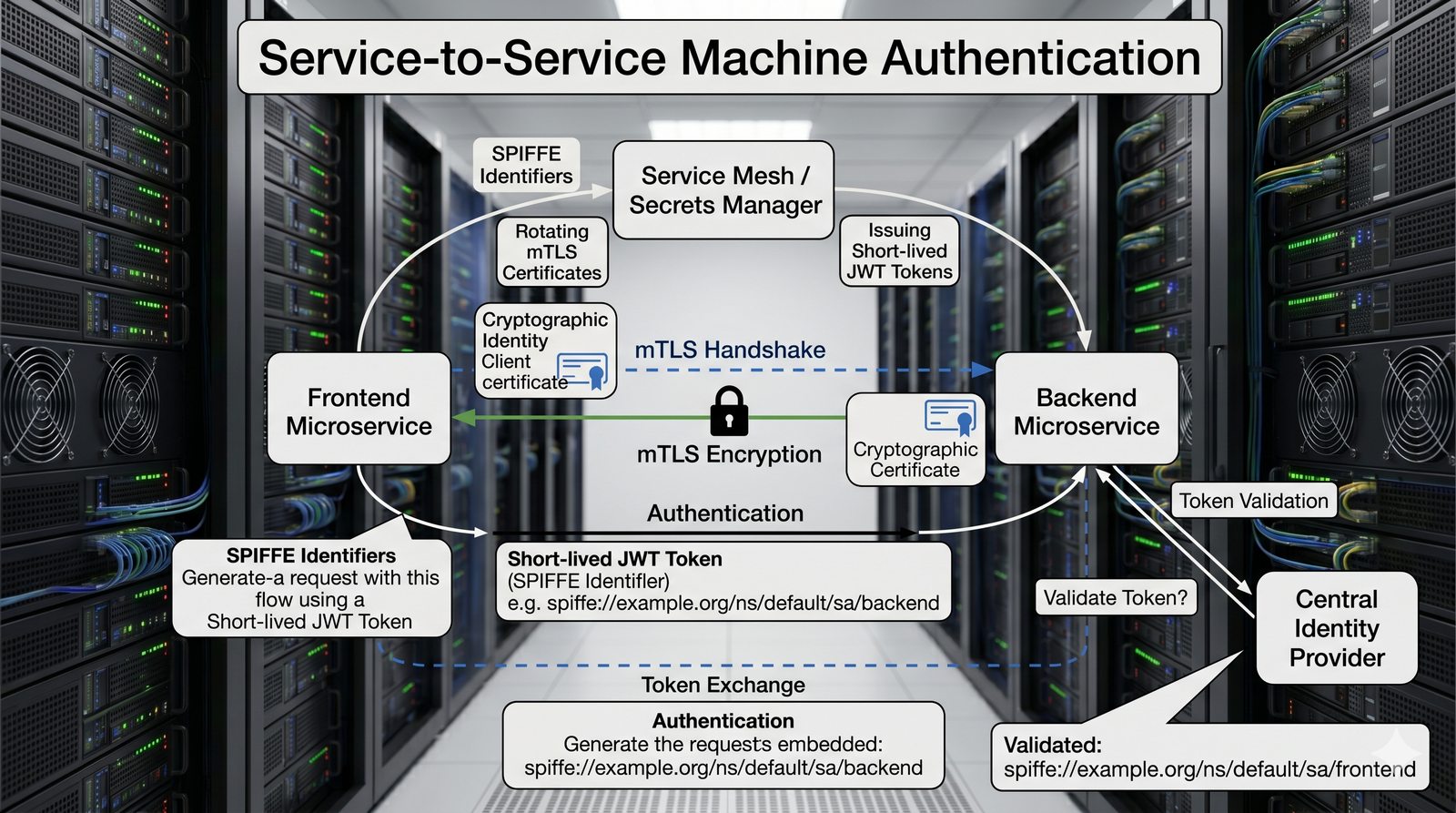
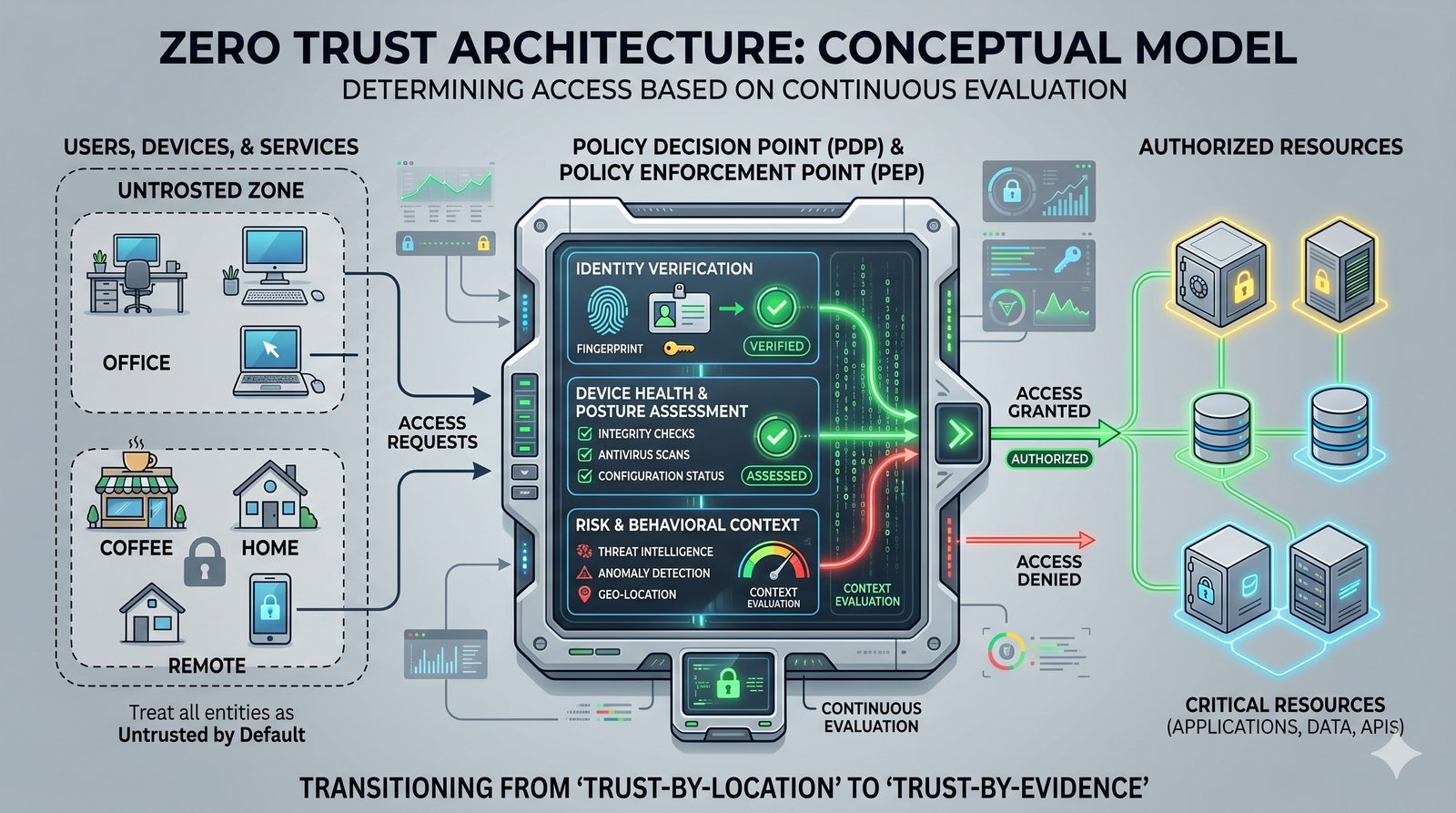
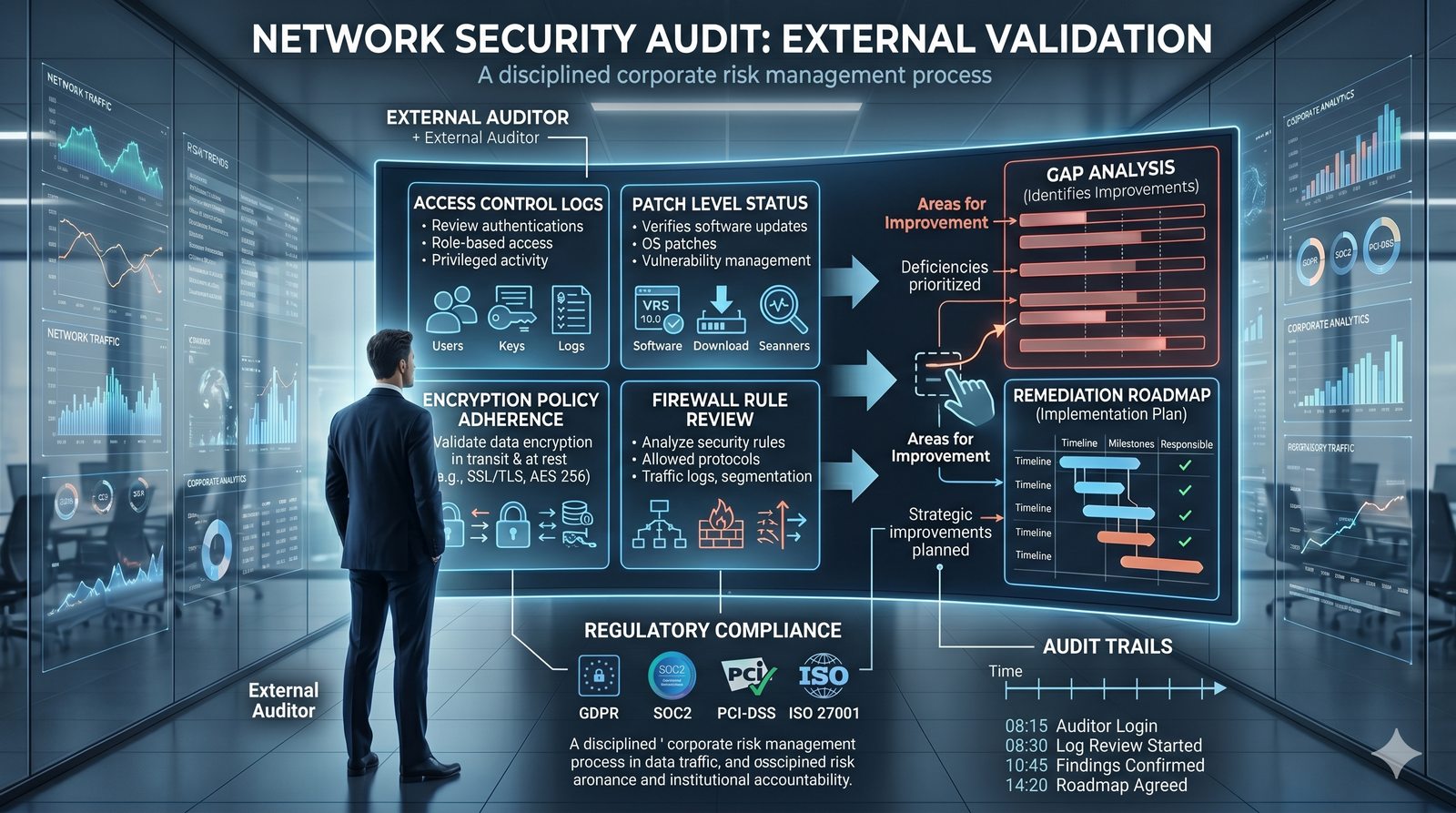
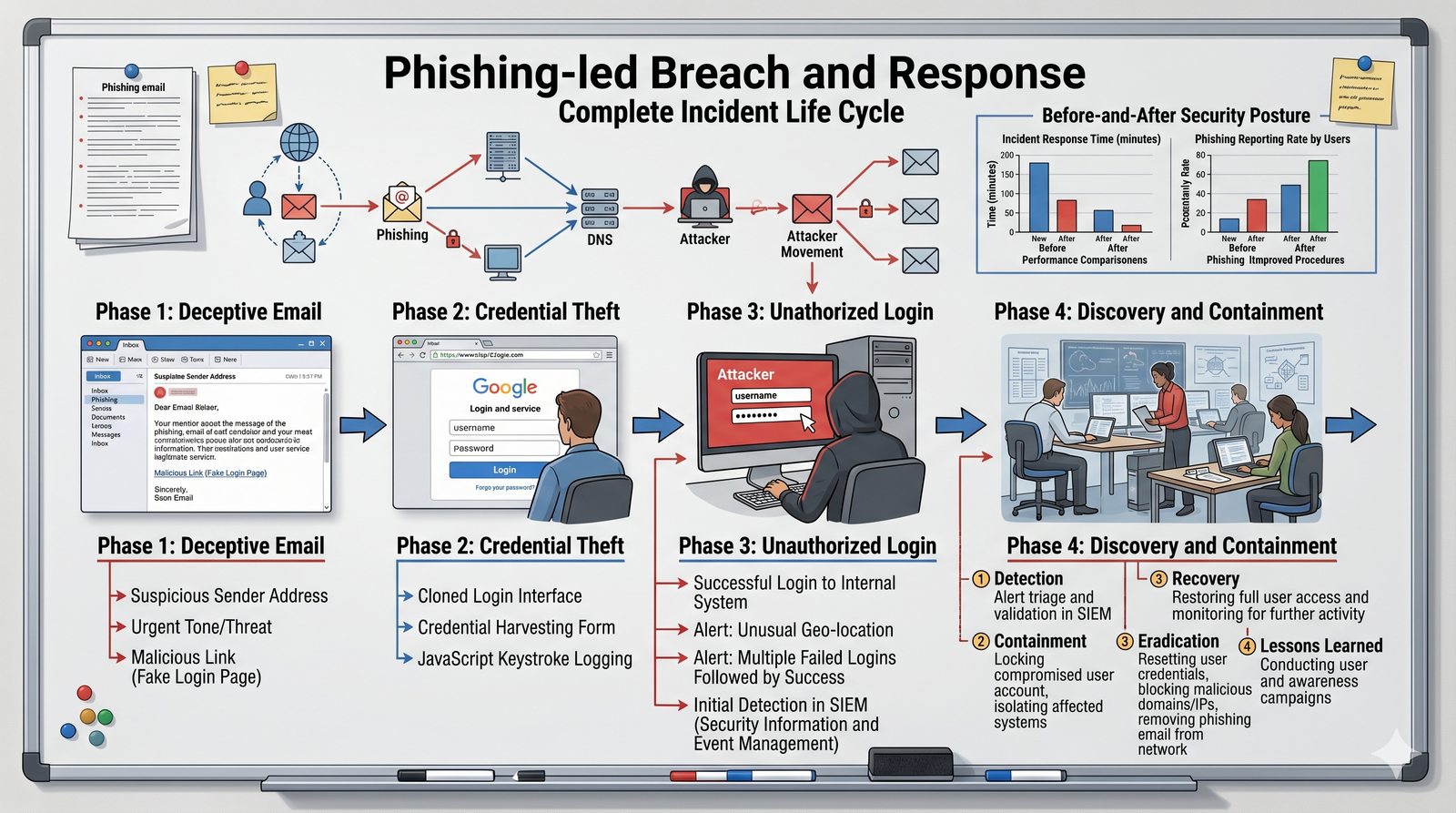
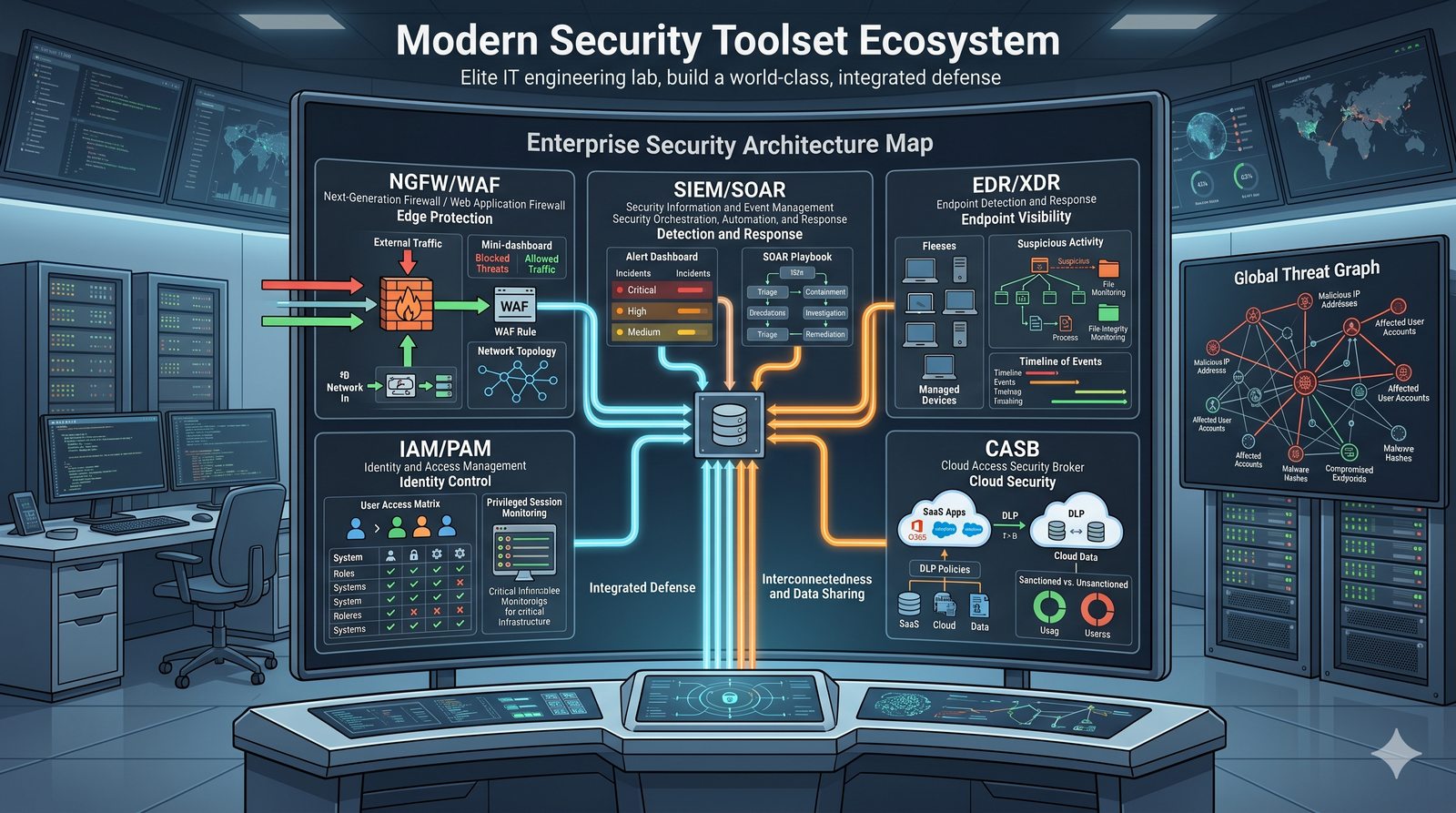
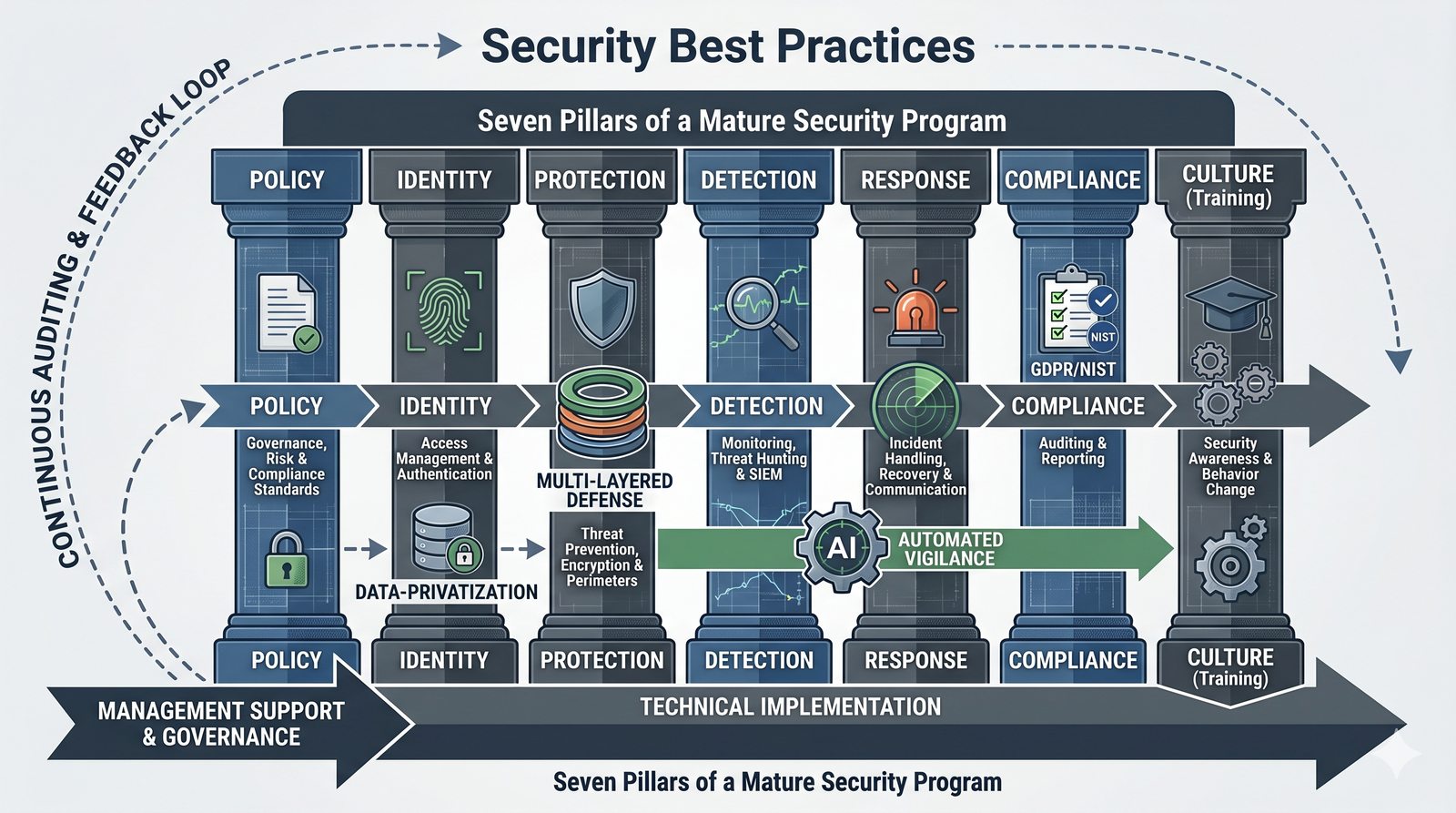
Kontrola dostępu to proces zapewniania, że użytkownicy mogą uzyskać dostęp tylko do tych zasobów, do których są upoważnieni.
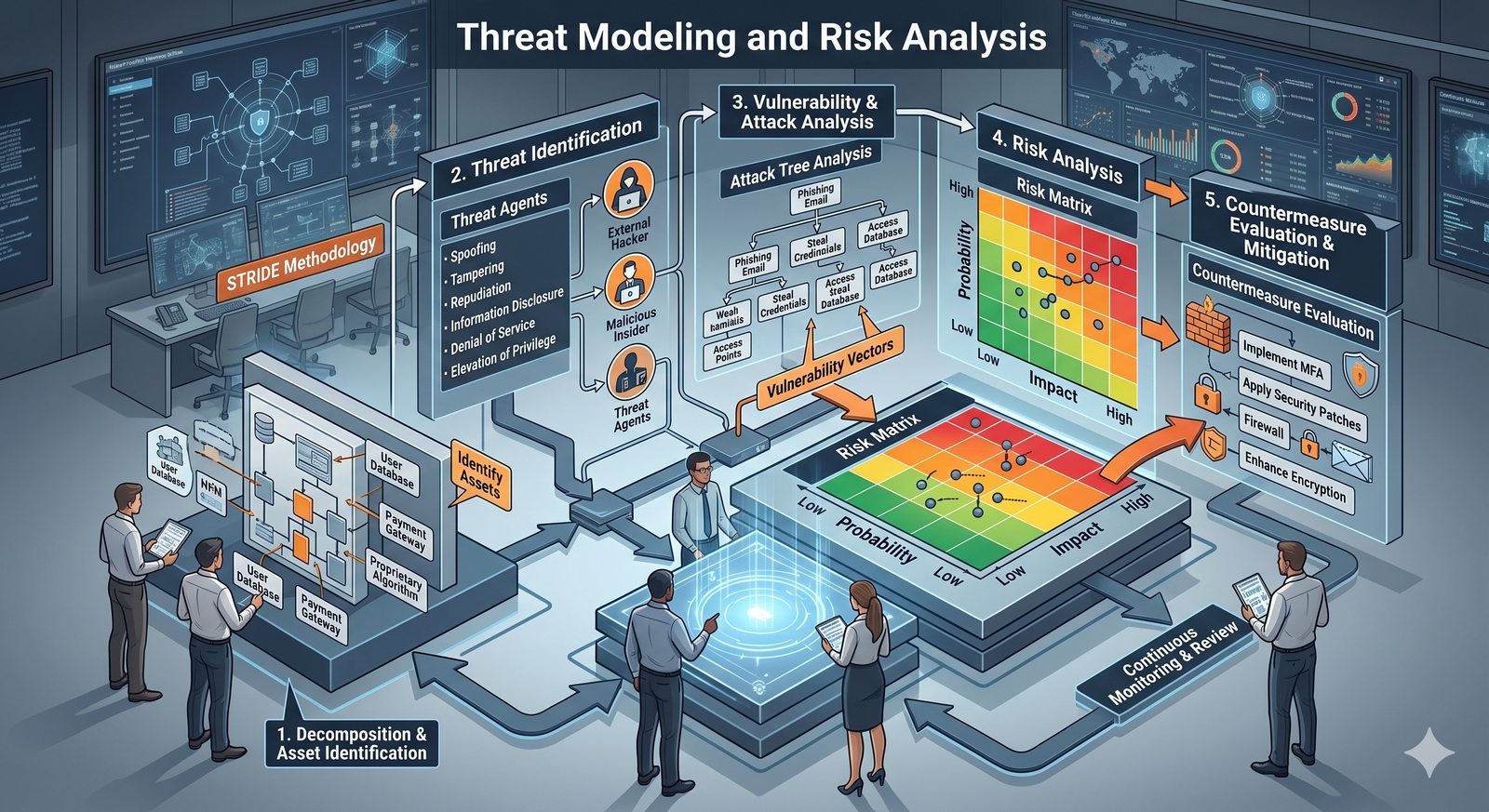
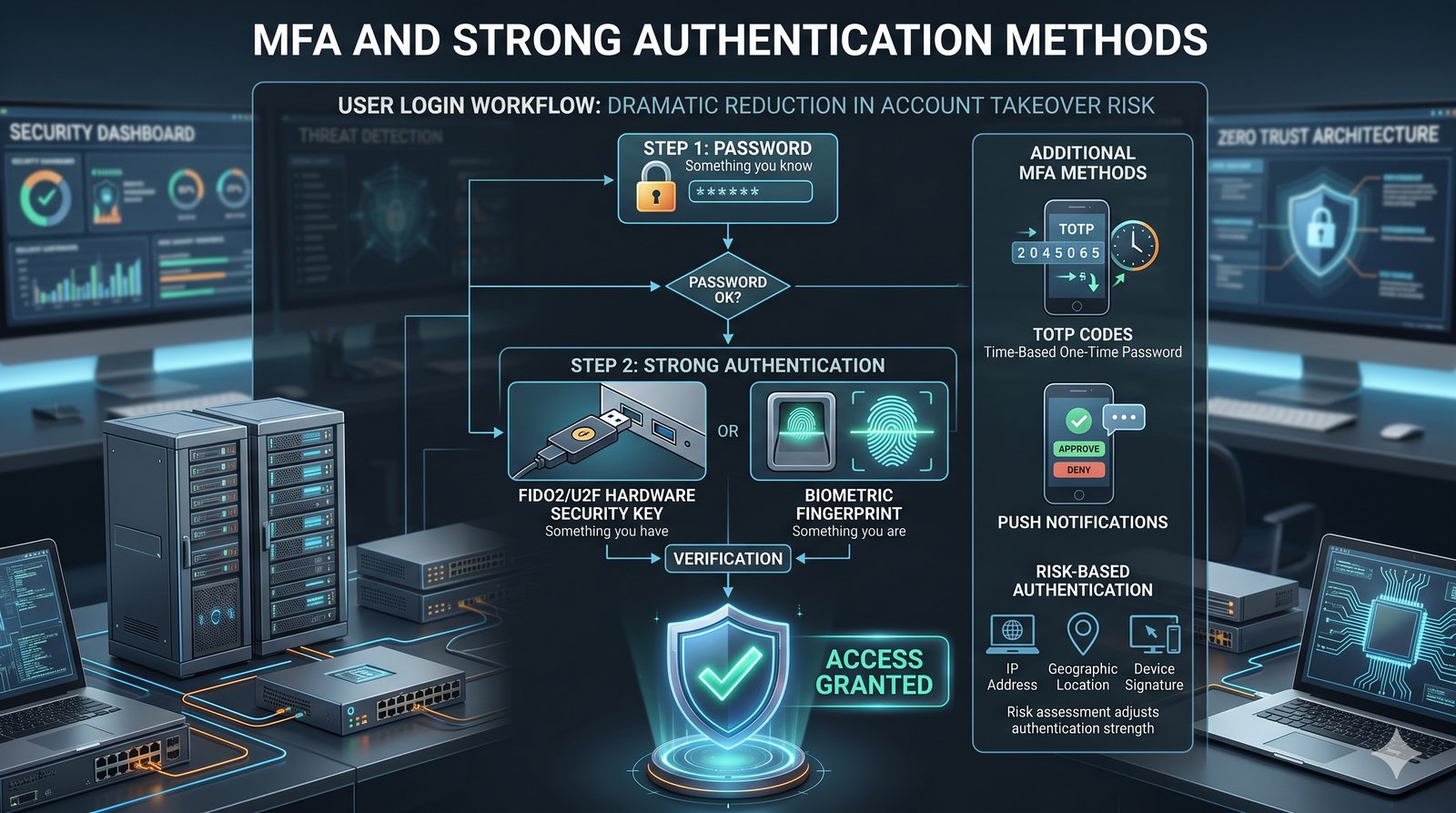
Opiera się ona na trzech fundamentalnych filarach: identyfikacji (kim jesteś?), uwierzytelnianiu (udowodnij, że jesteś tym, za kogo się podajesz) oraz autoryzacji (co wolno ci zrobić?).
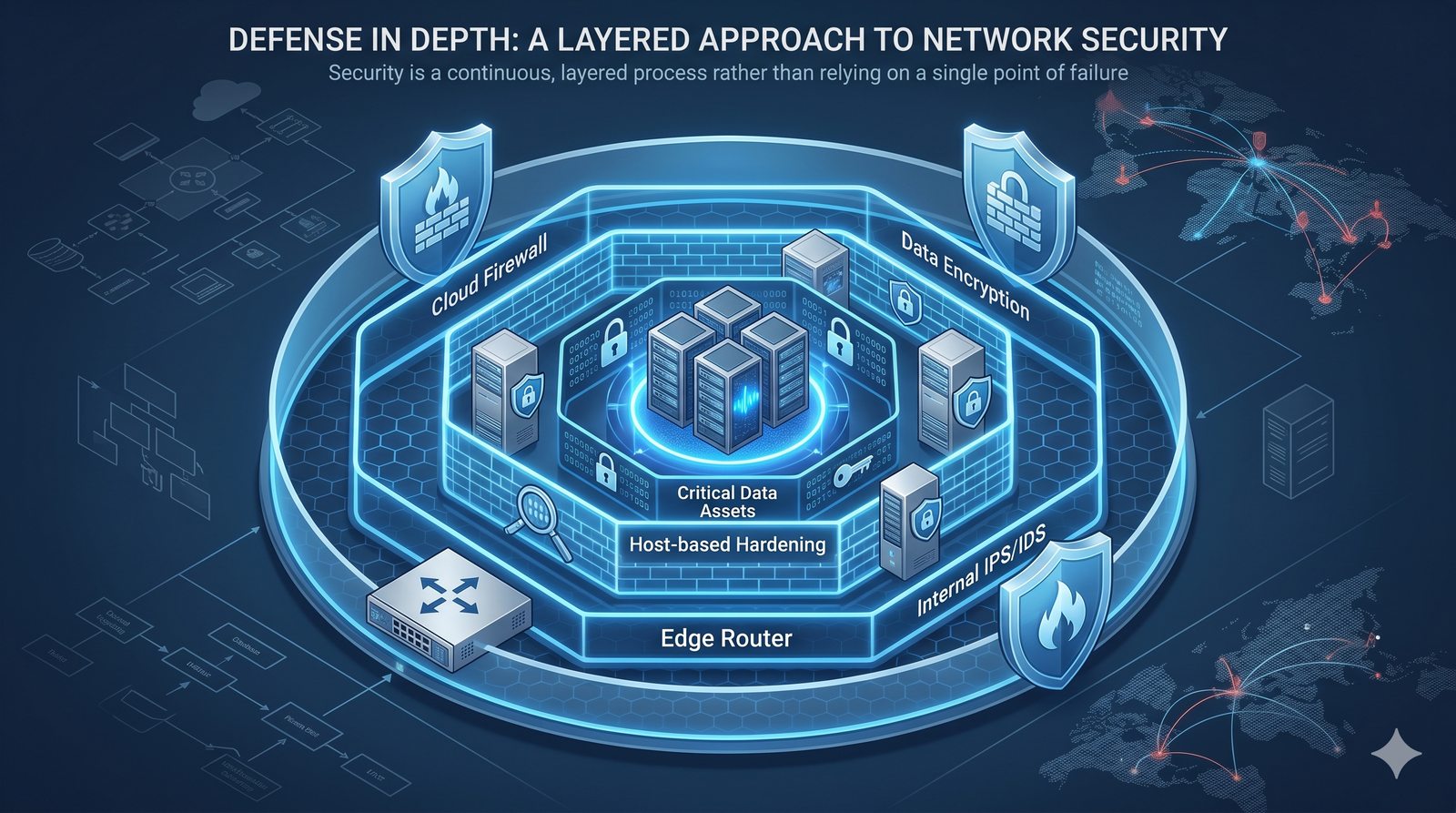
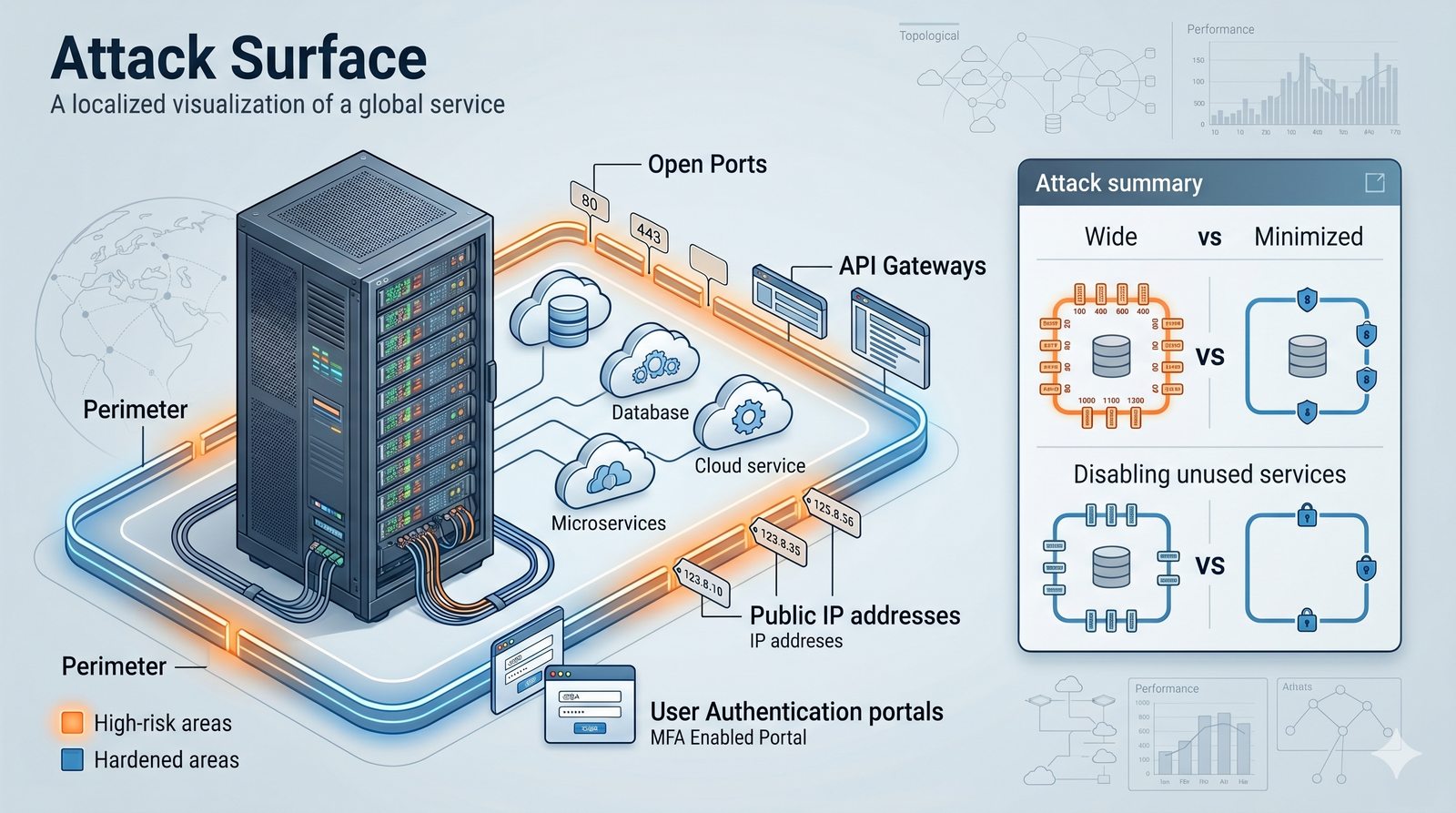
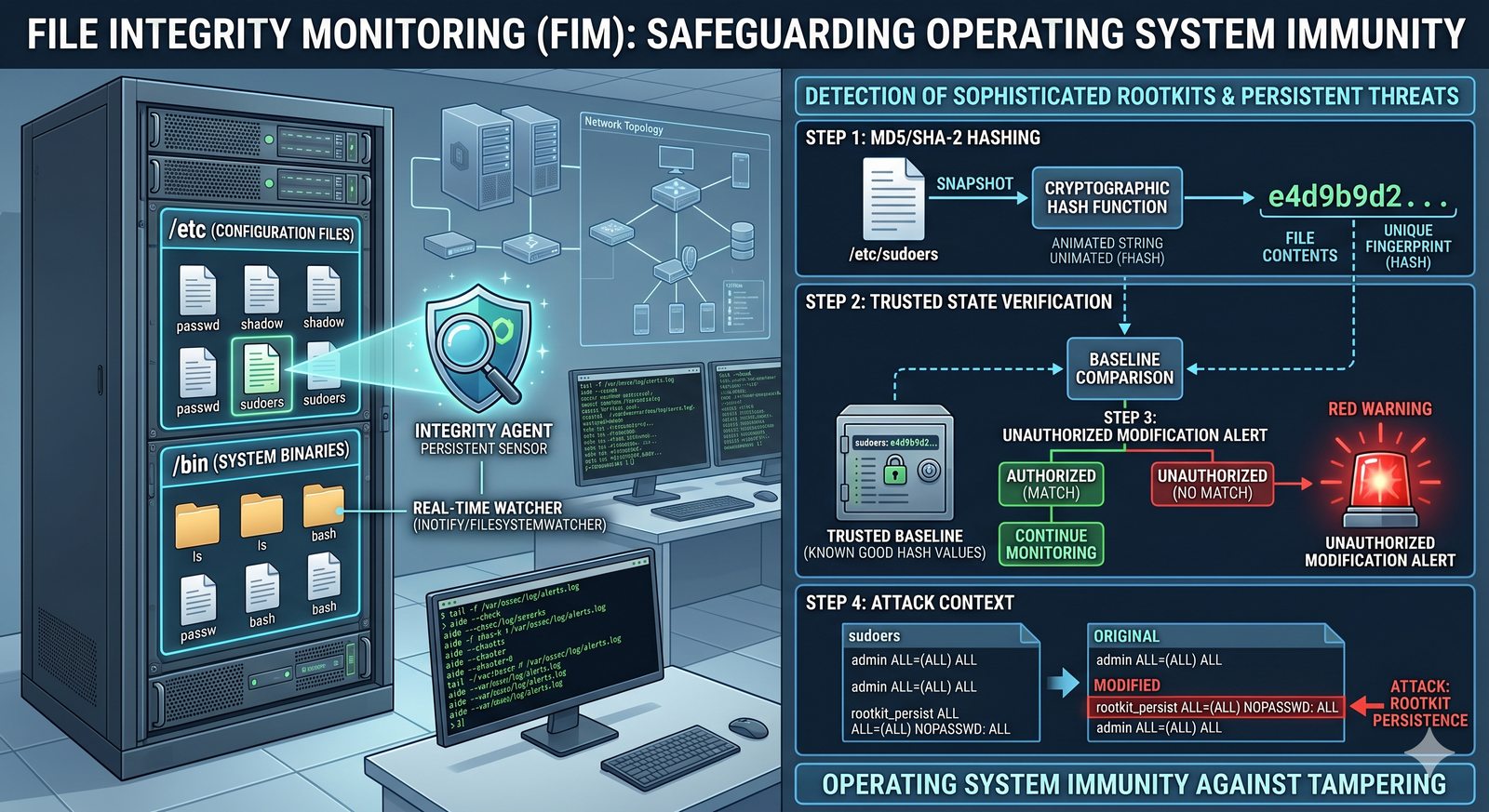
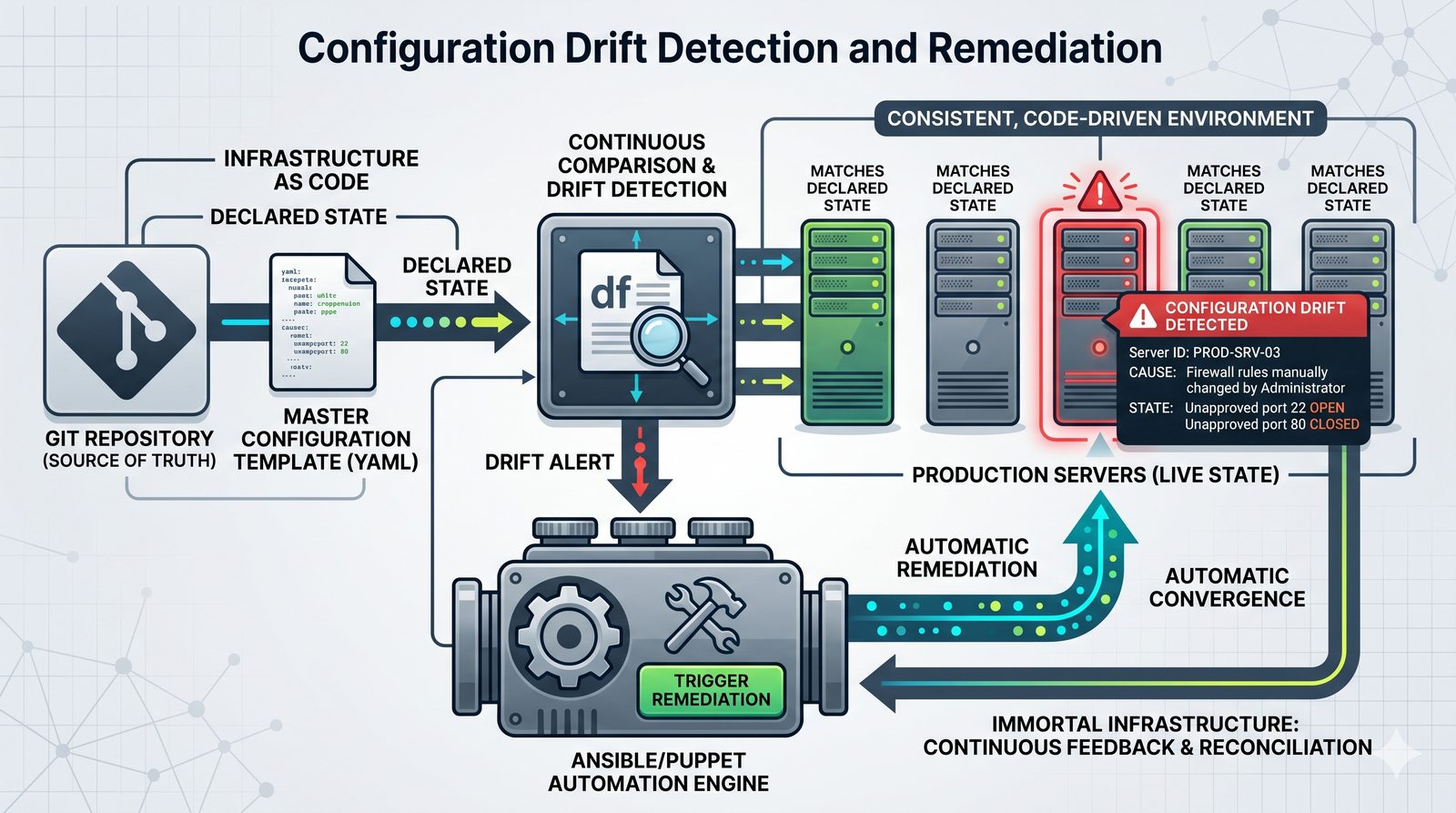
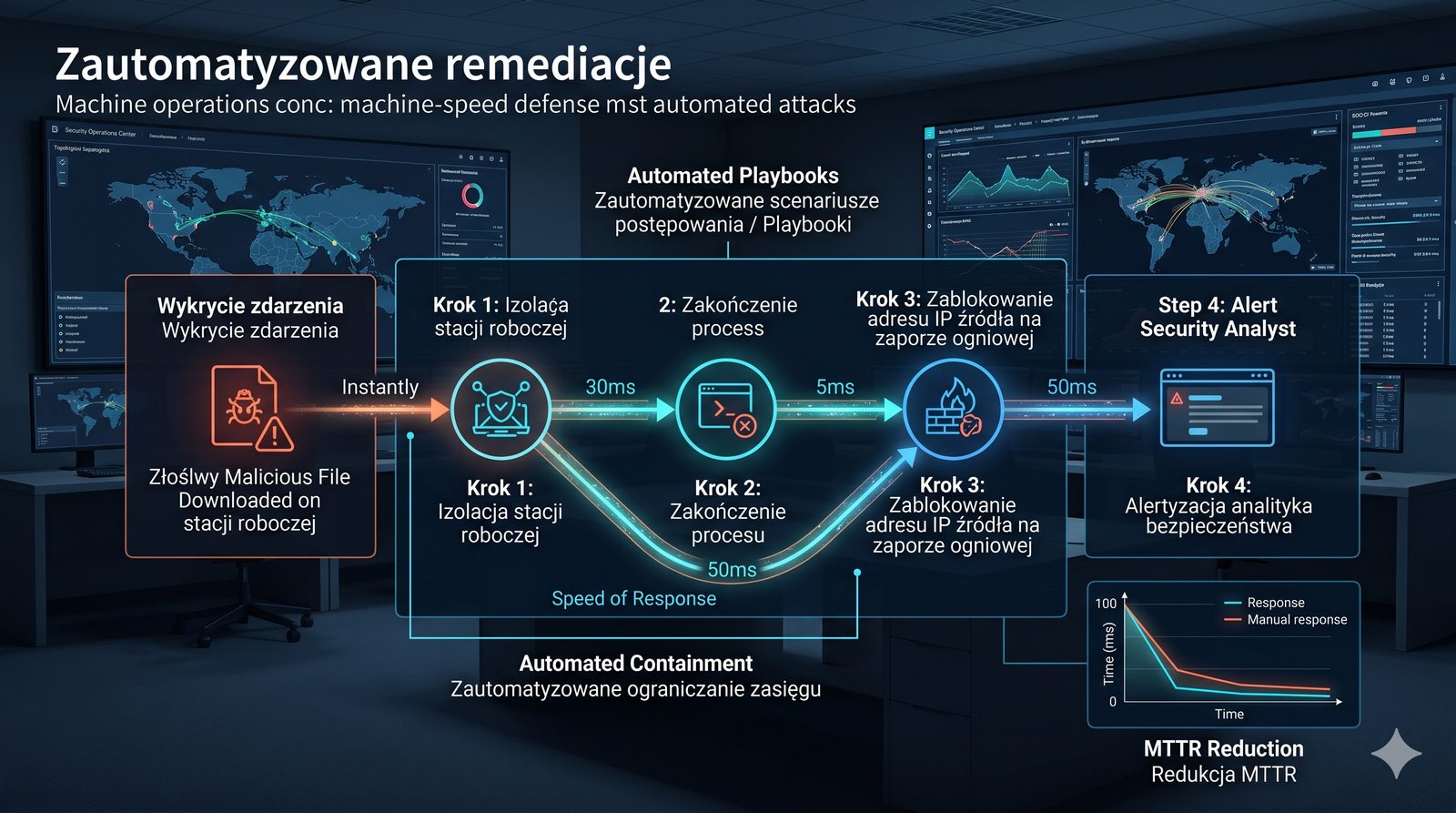
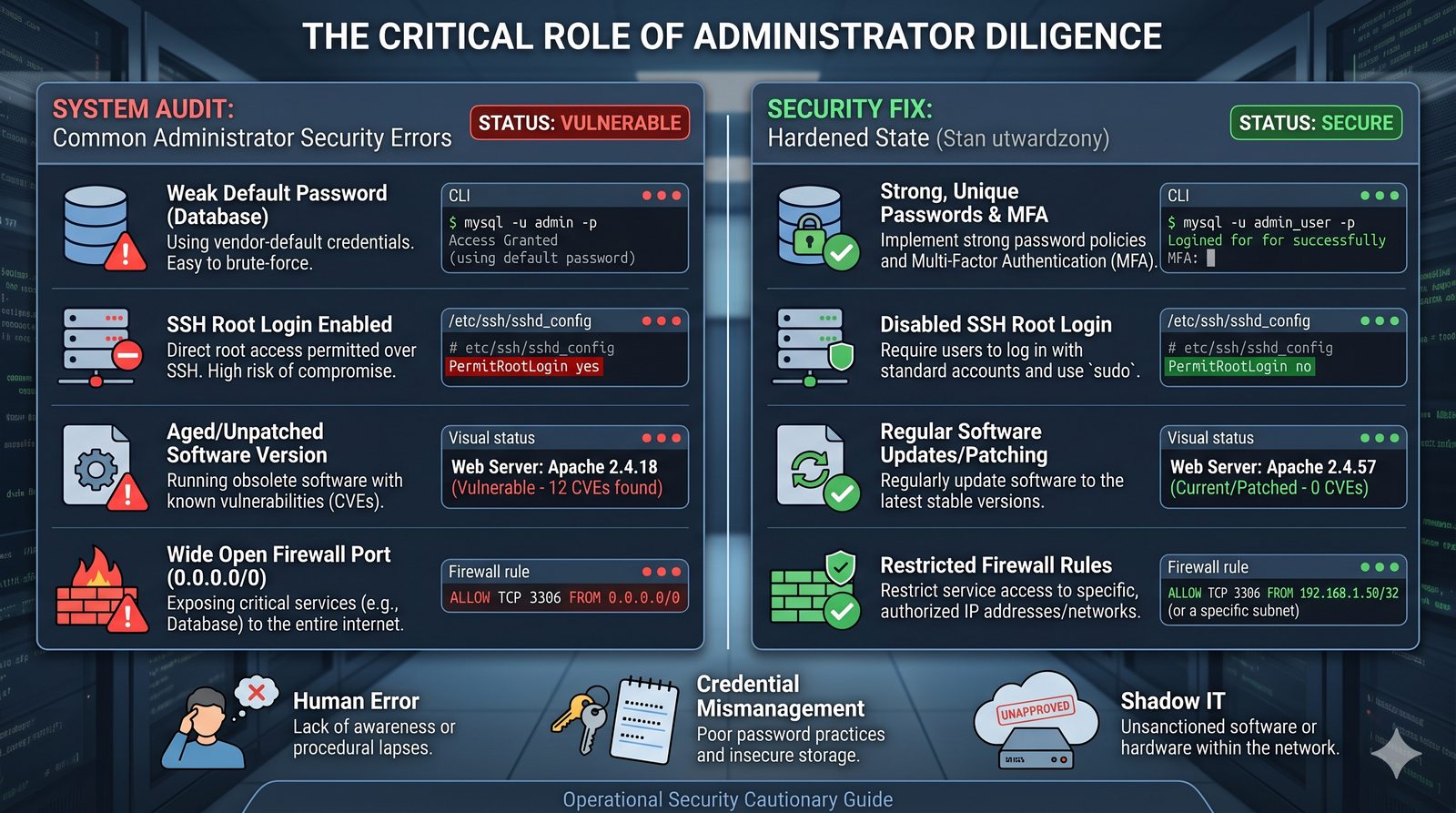
- Skuteczna kontrola dostępu wymaga wdrożenia zasady najmniejszych uprawnień (ang. principle of least privilege), która mówi, że każdy użytkownik i proces powinien mieć tylko minimalny zestaw uprawnień niezbędny do wykonania swoich zadań.