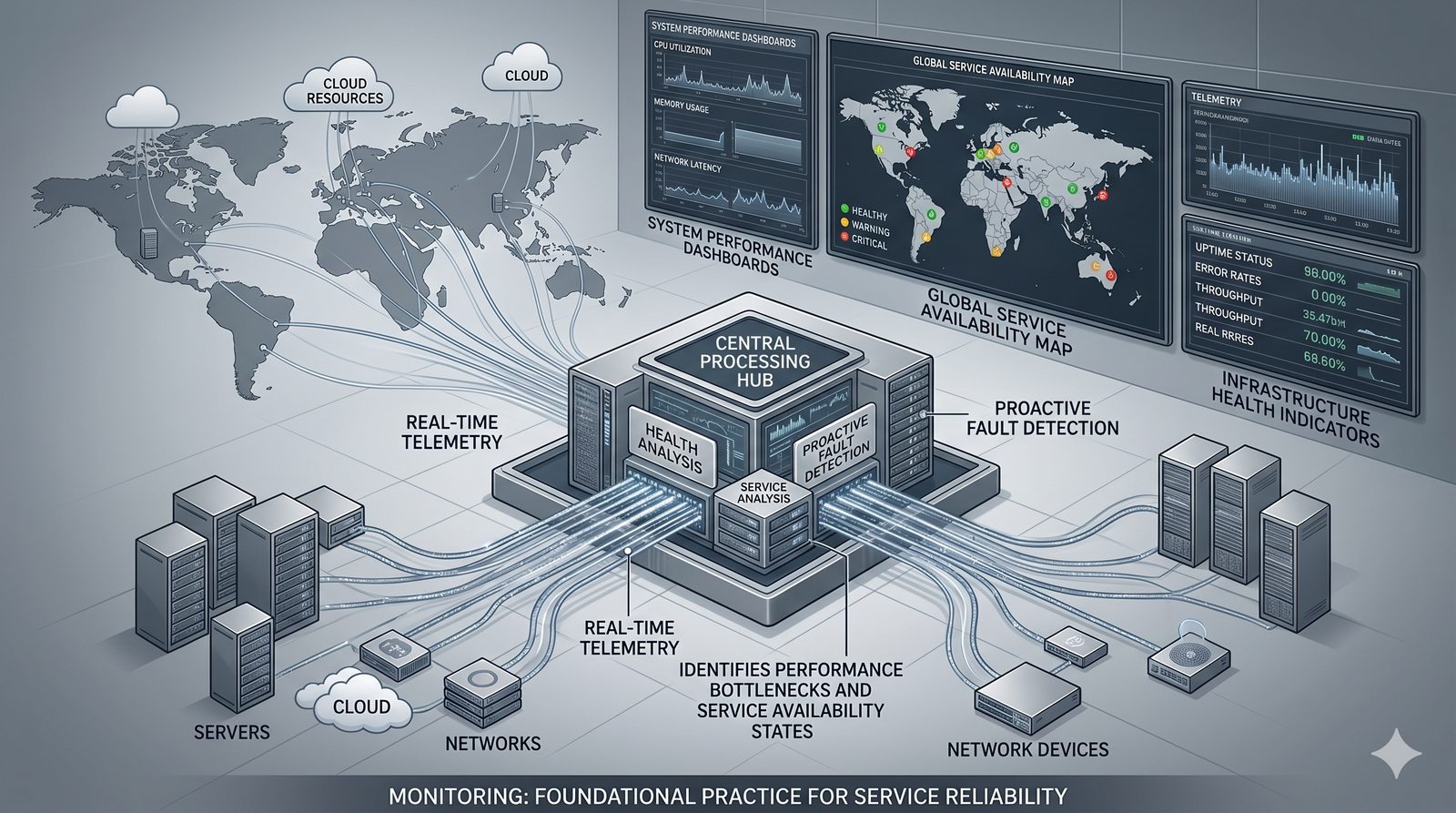
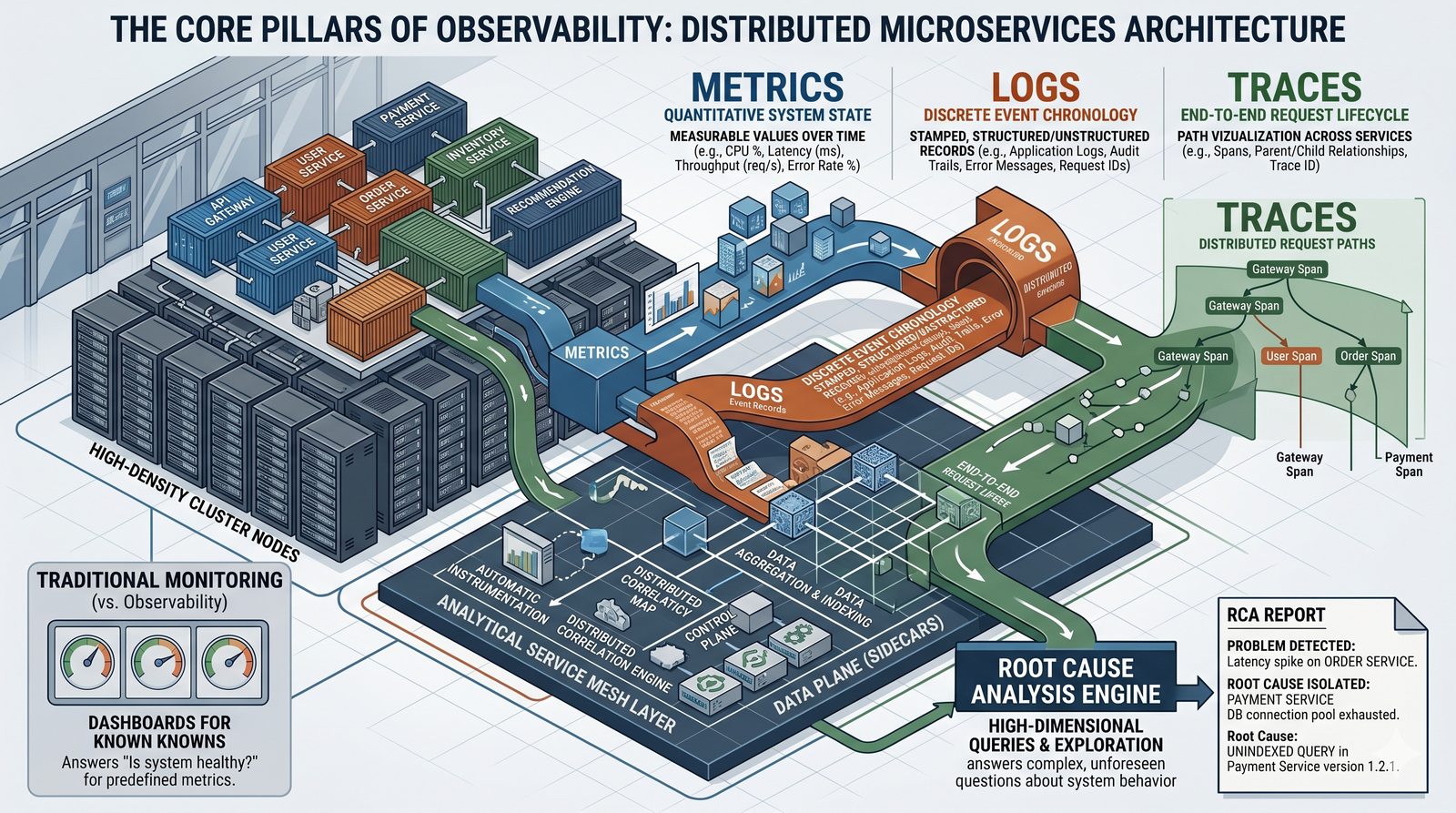
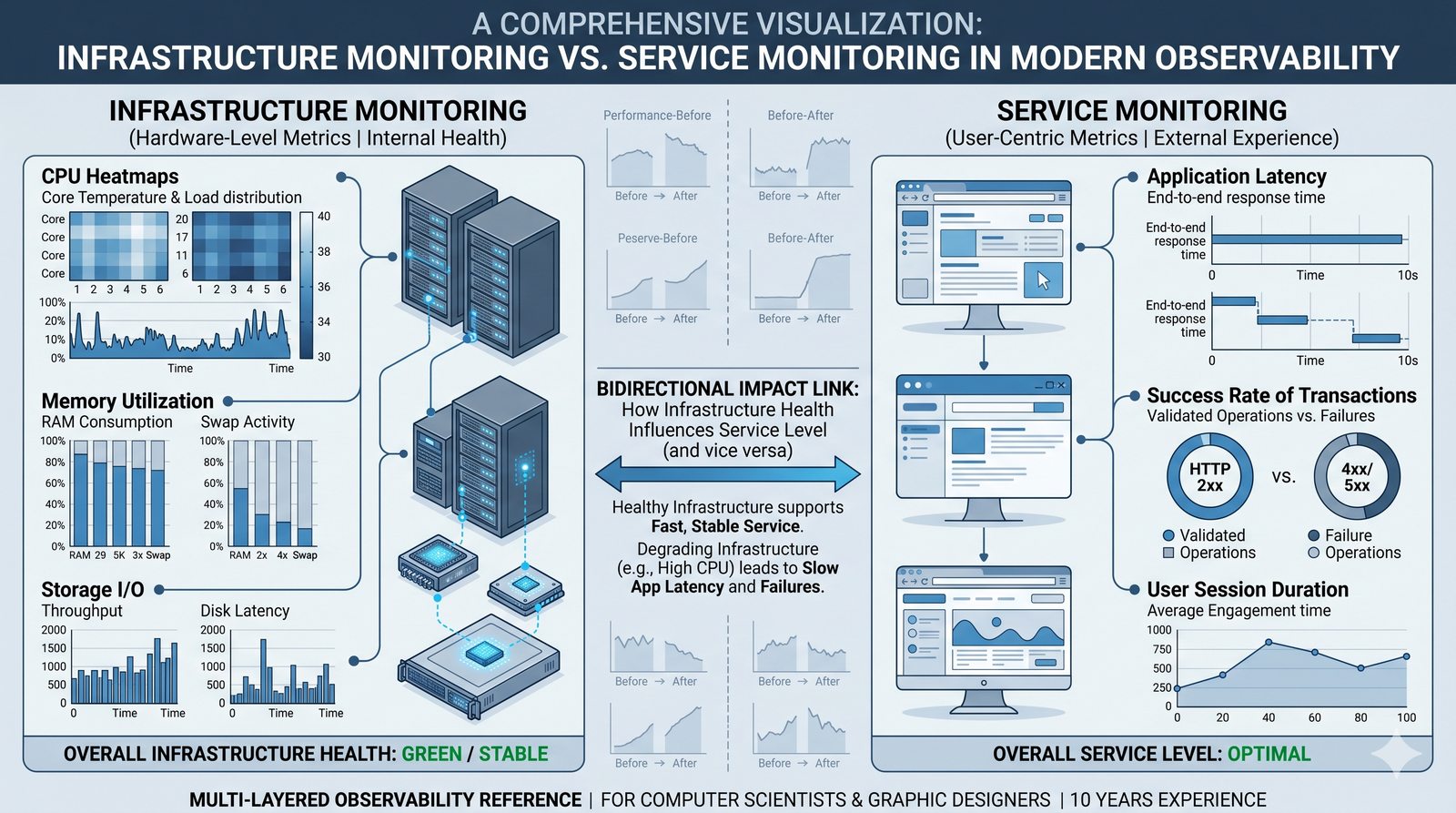
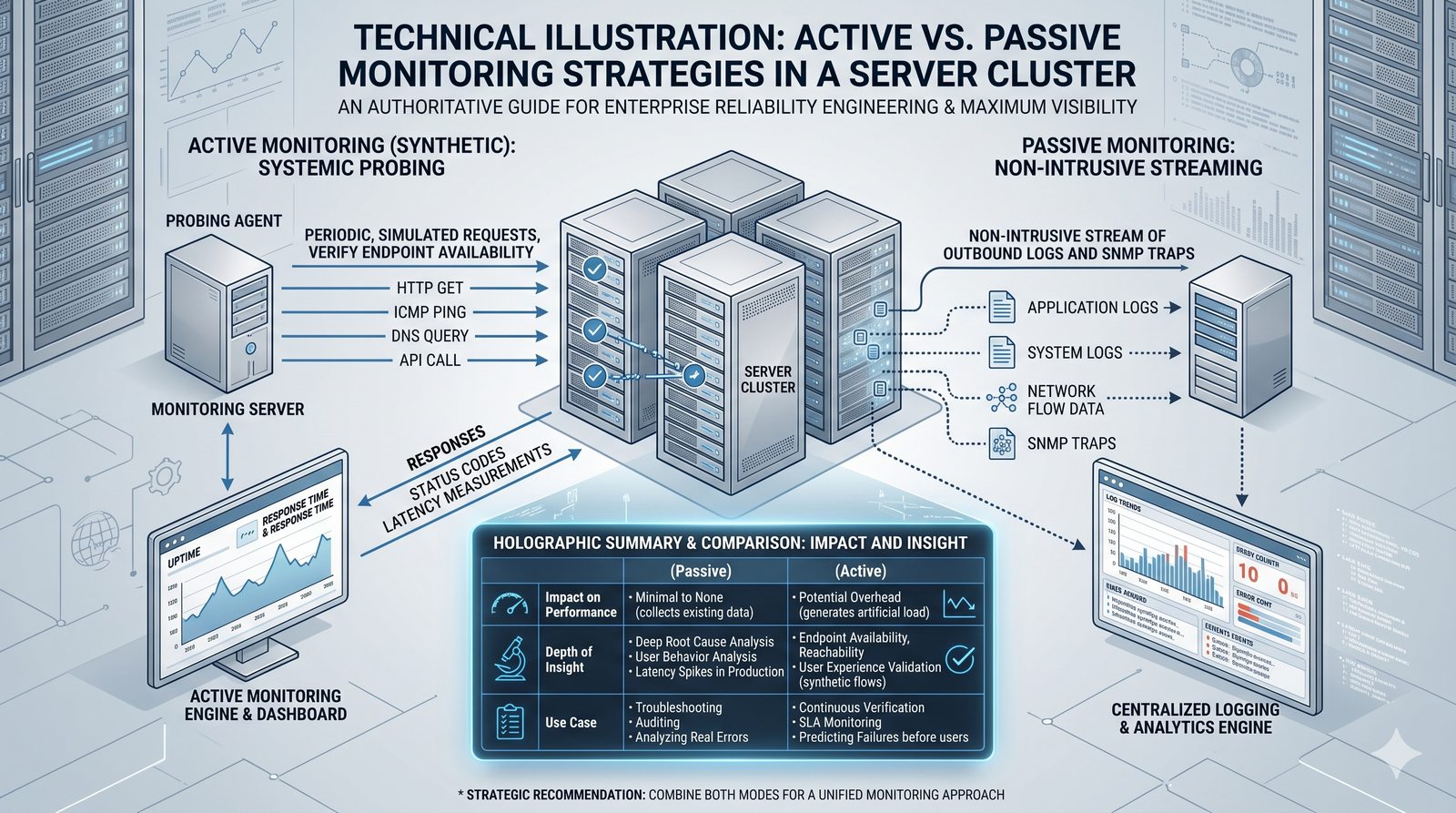
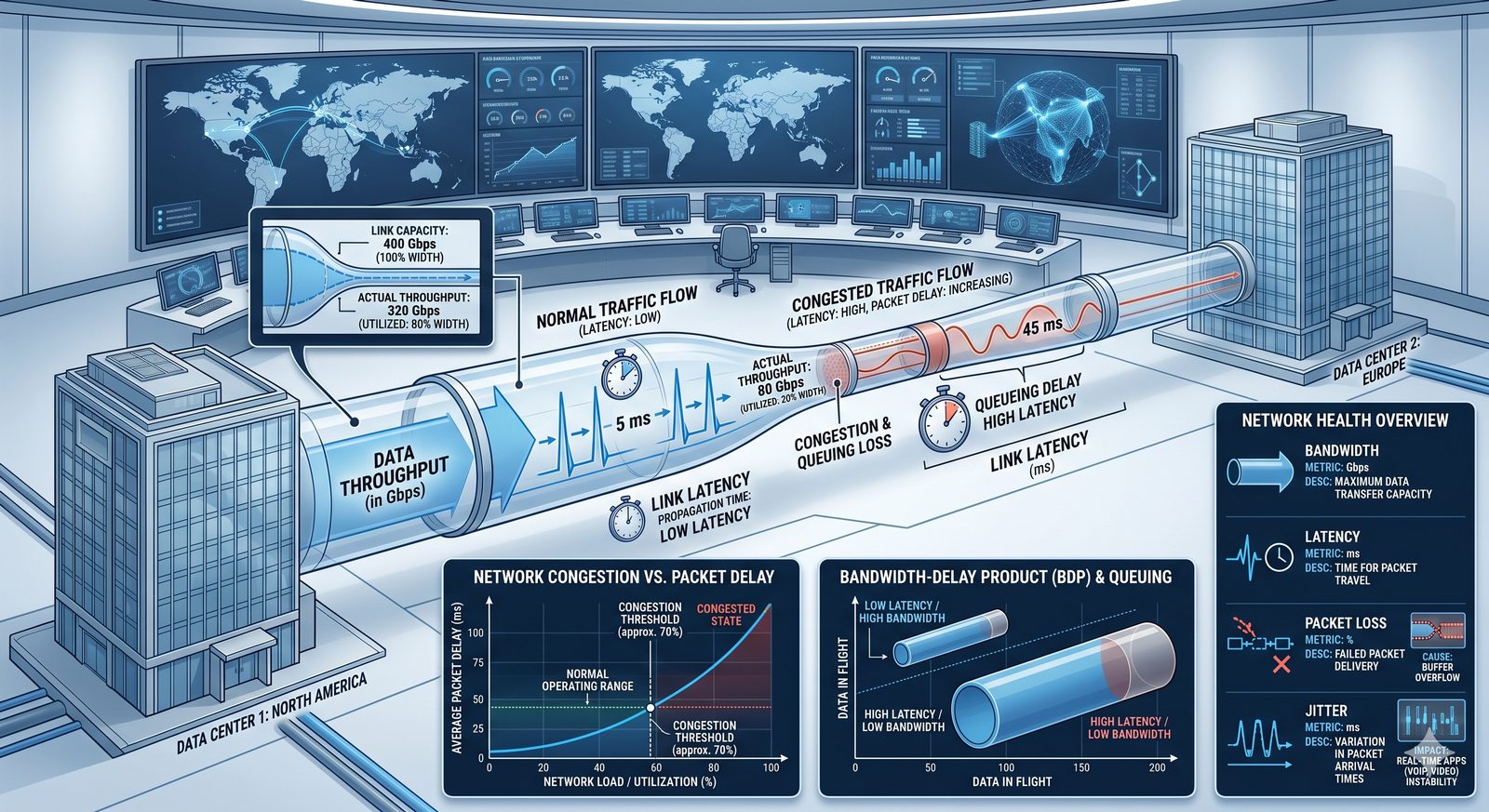
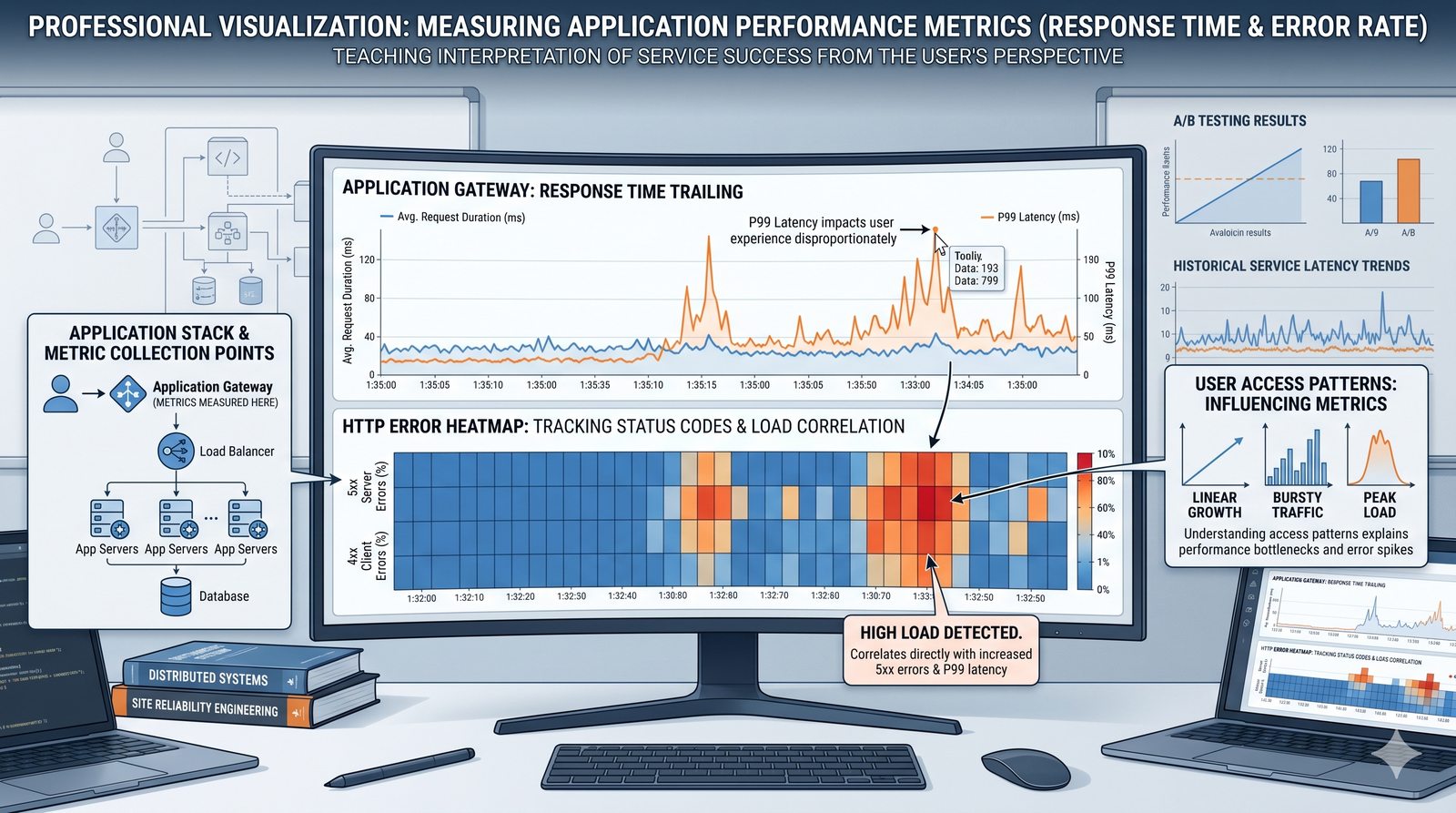
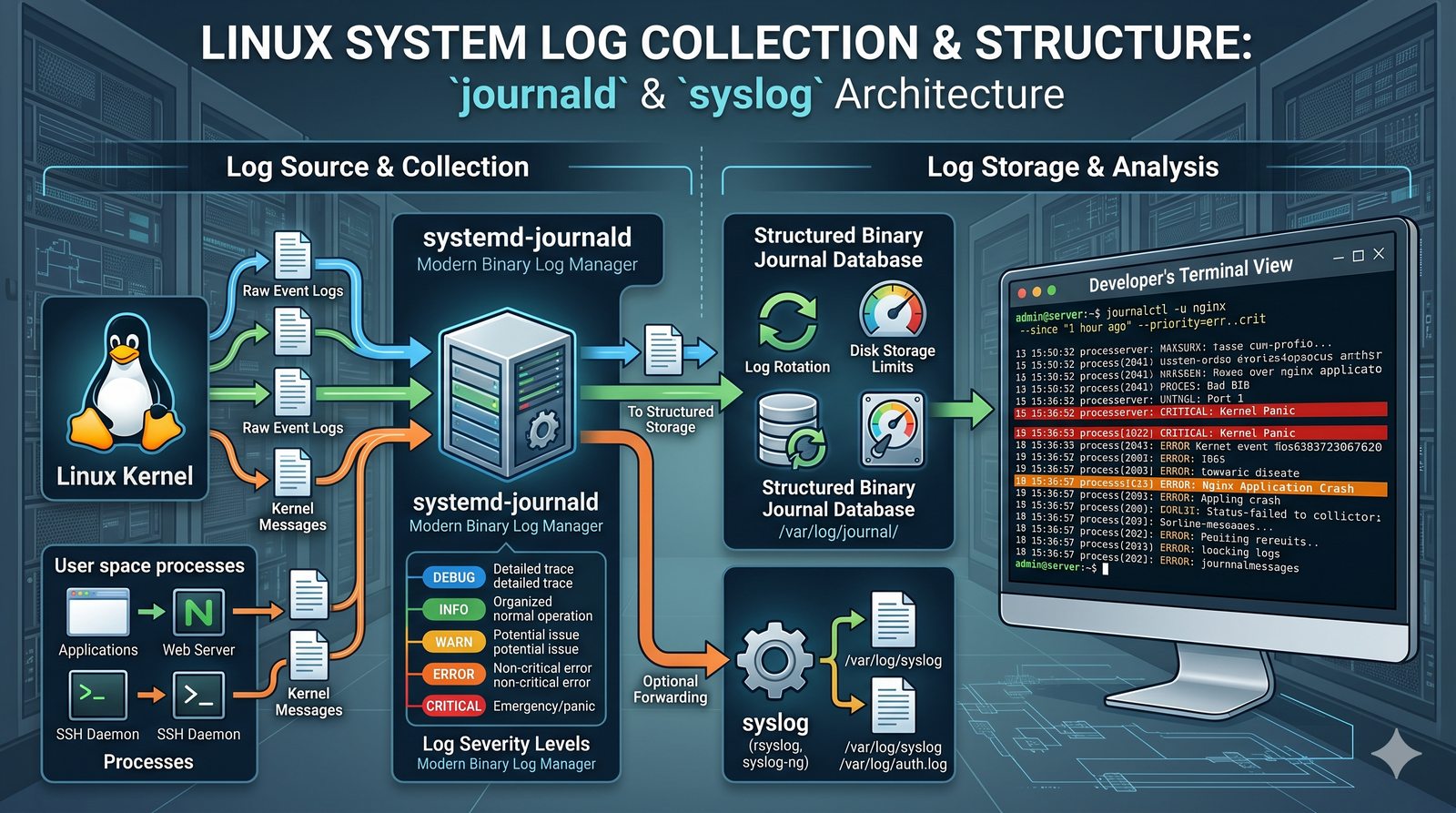
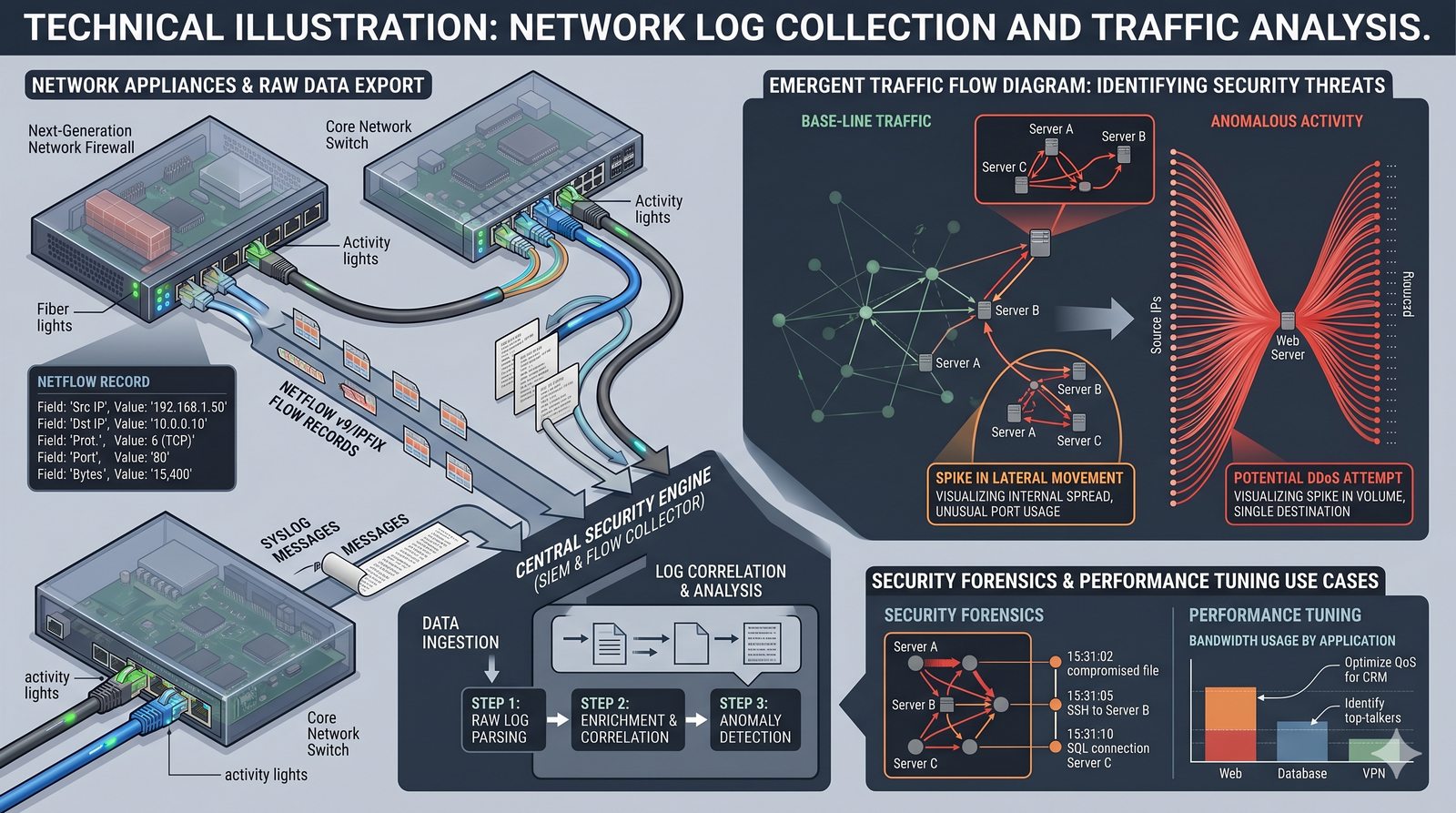
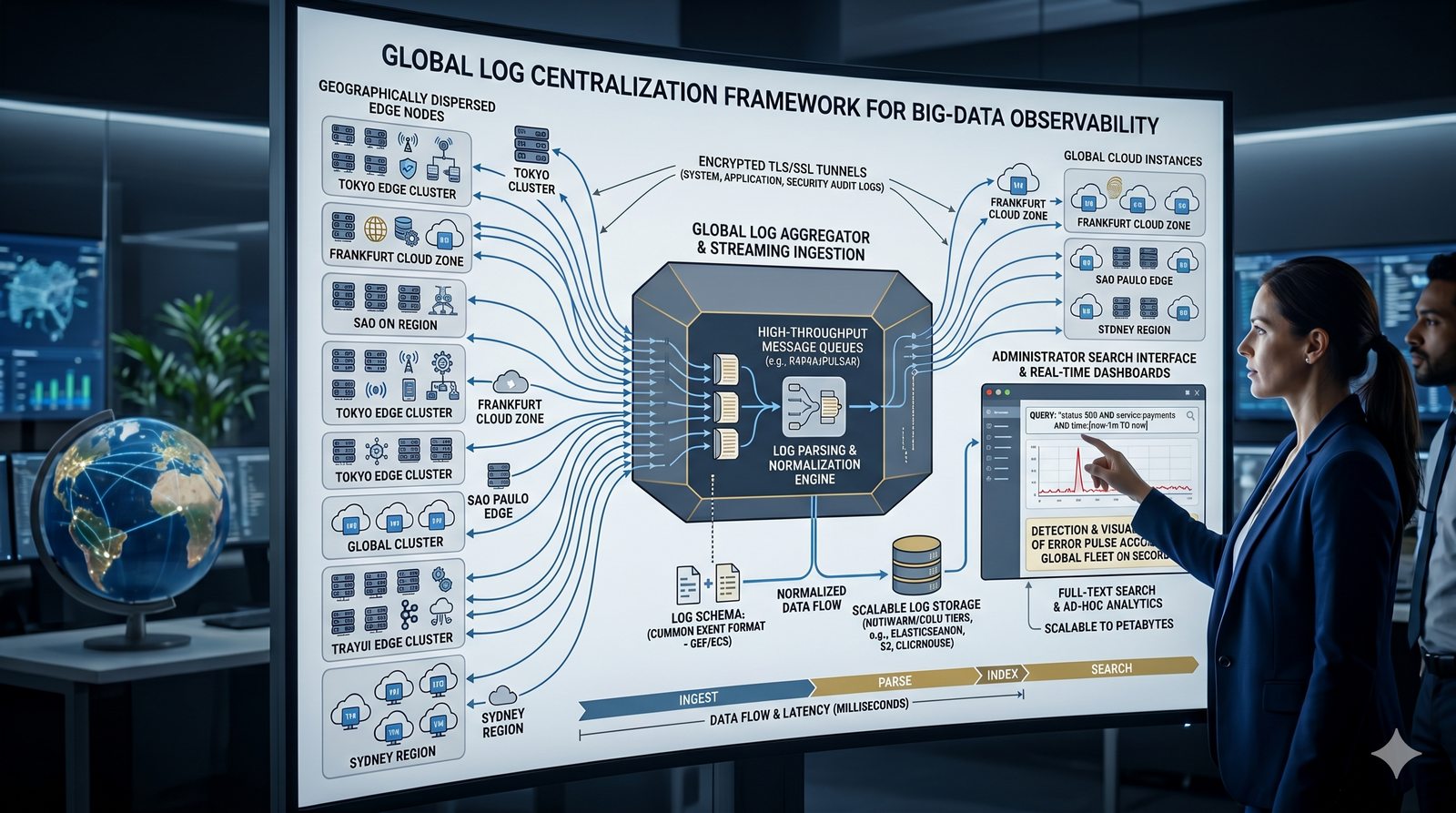
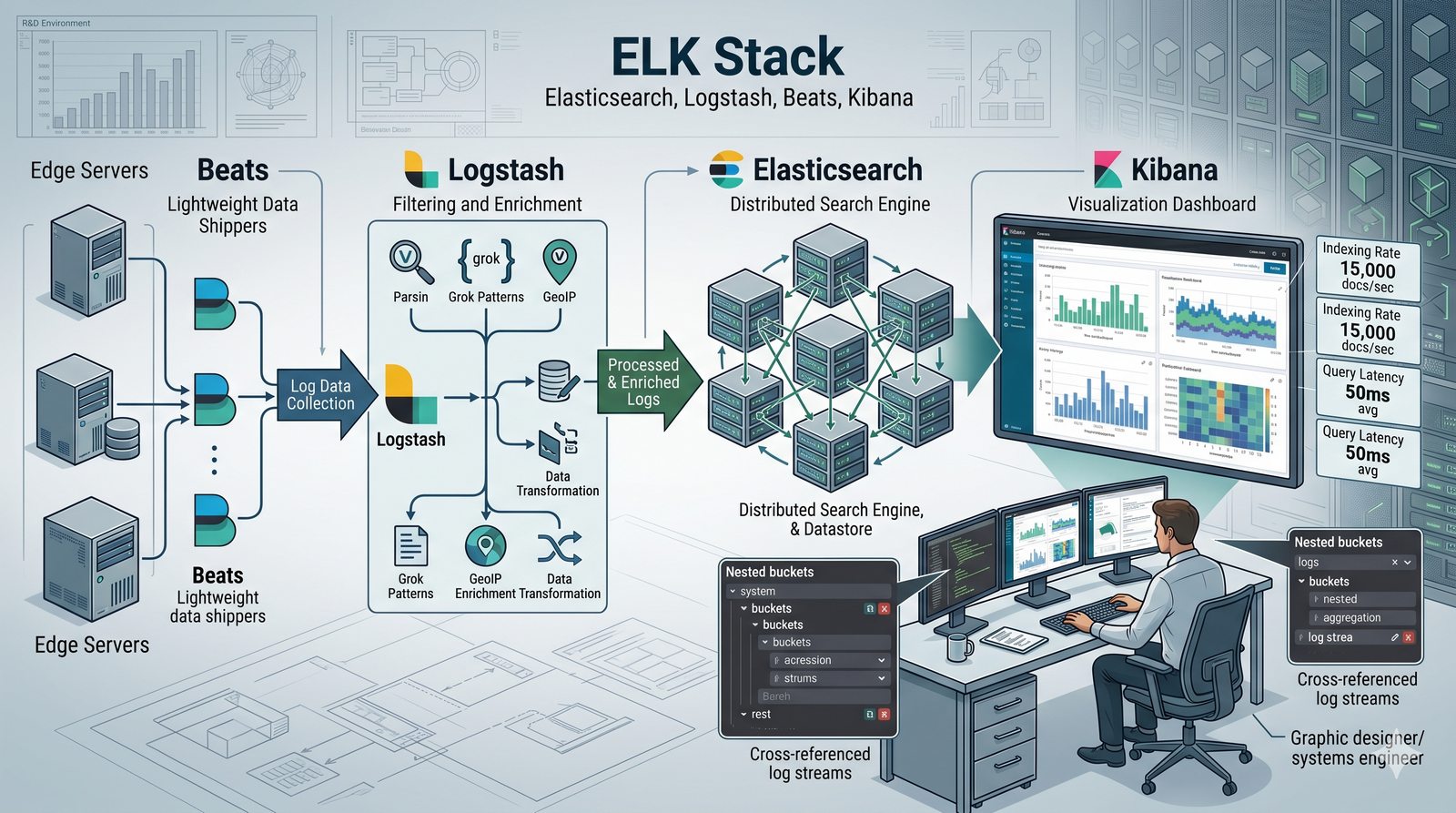
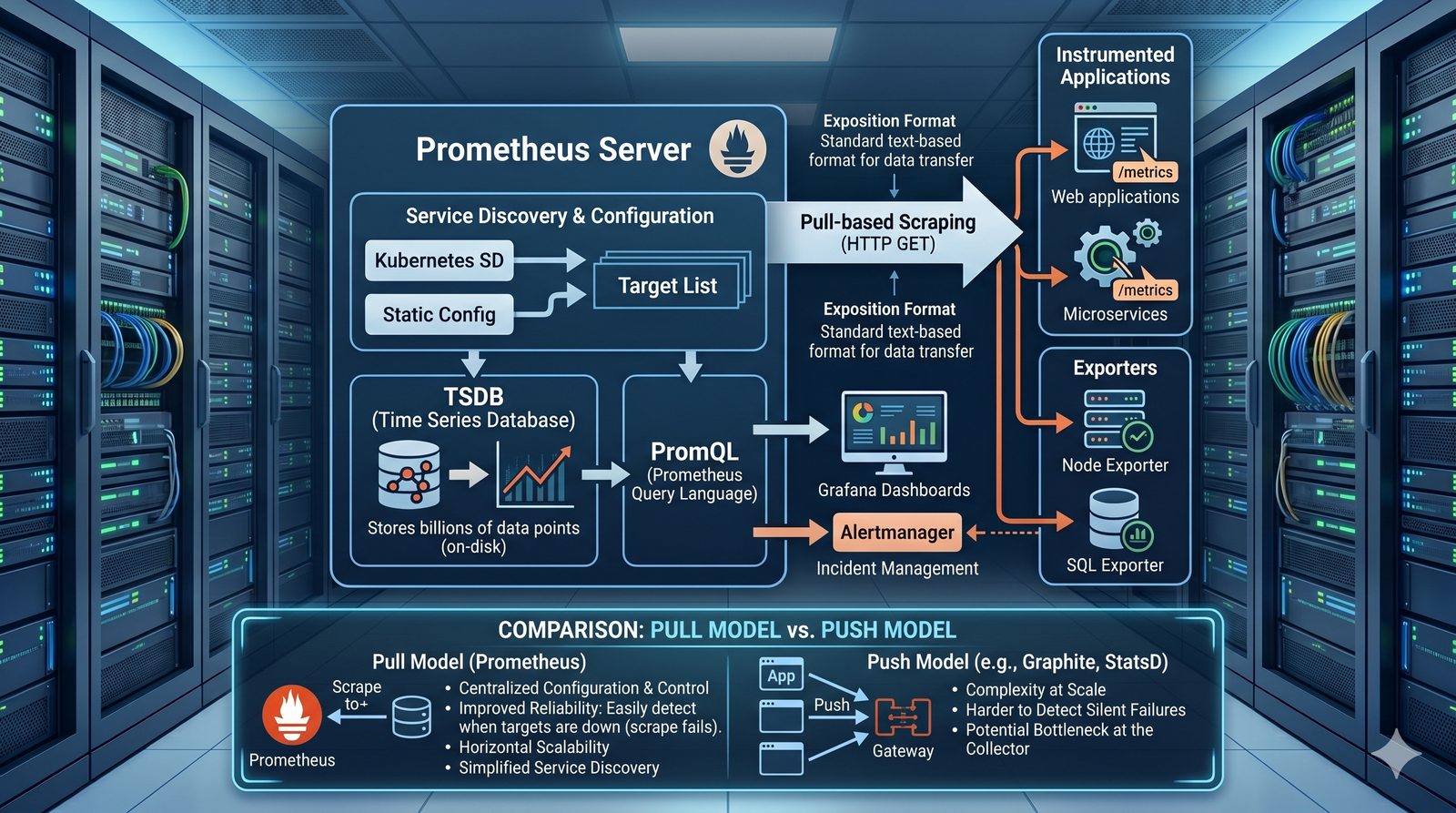
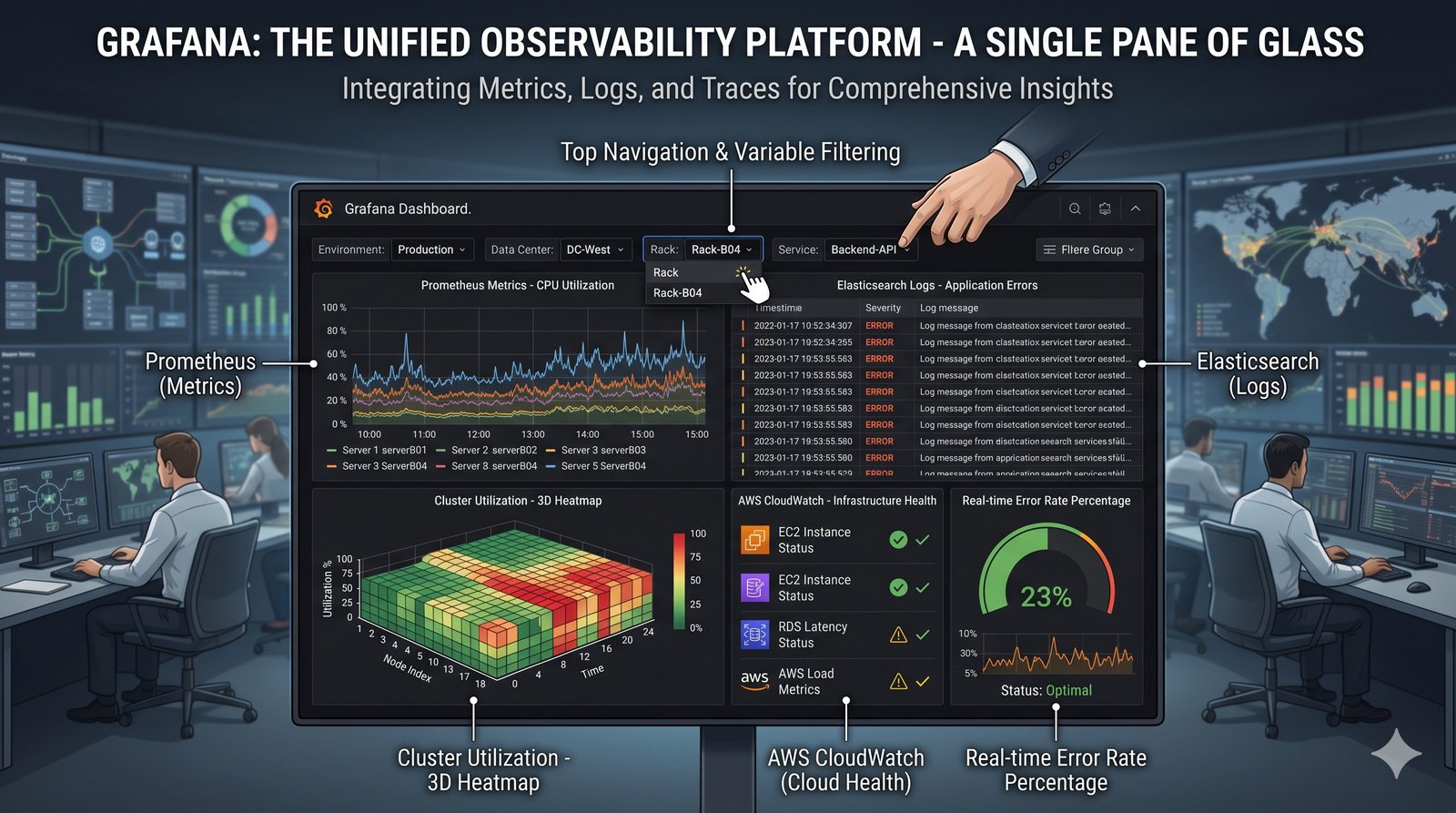
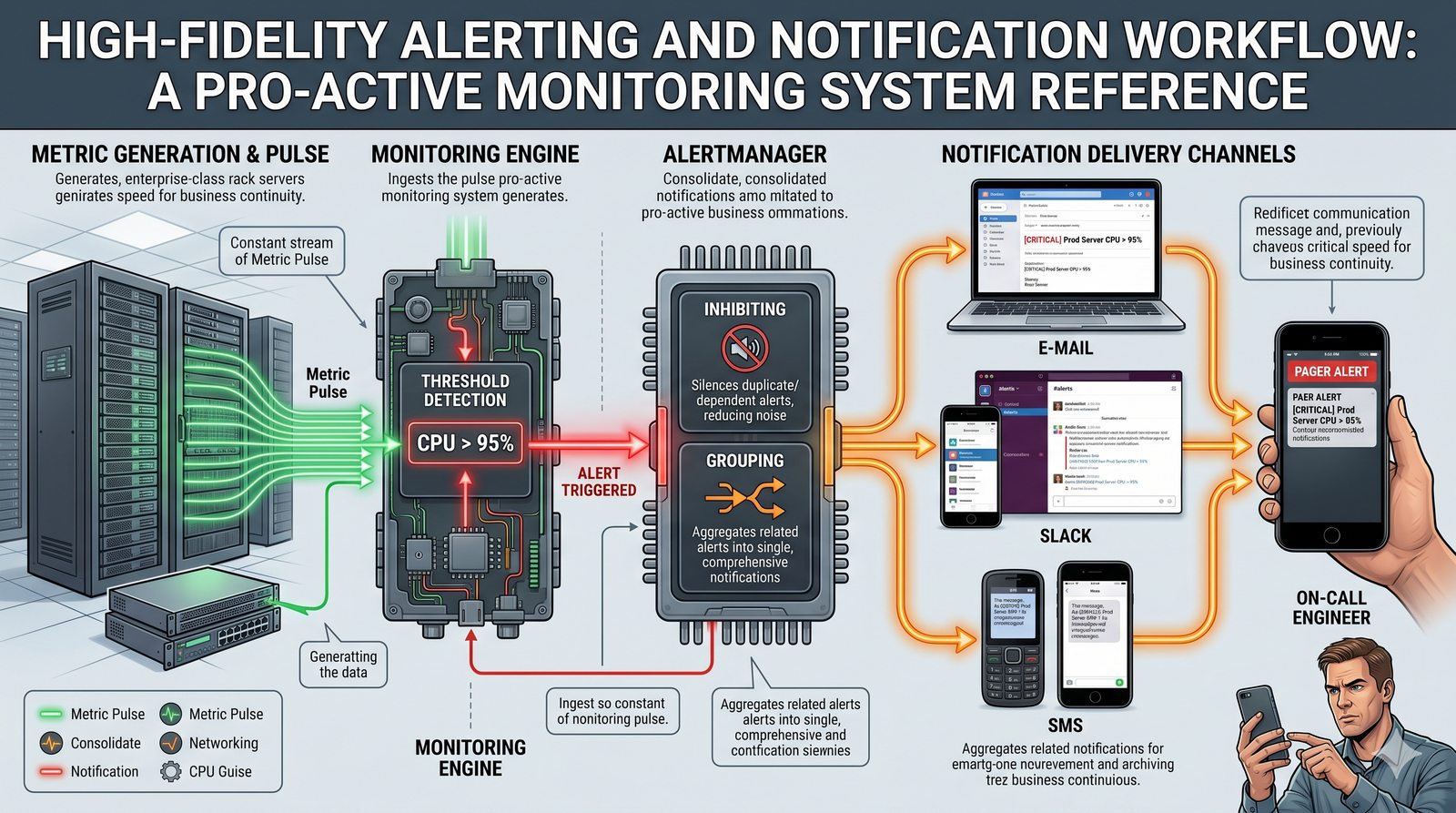
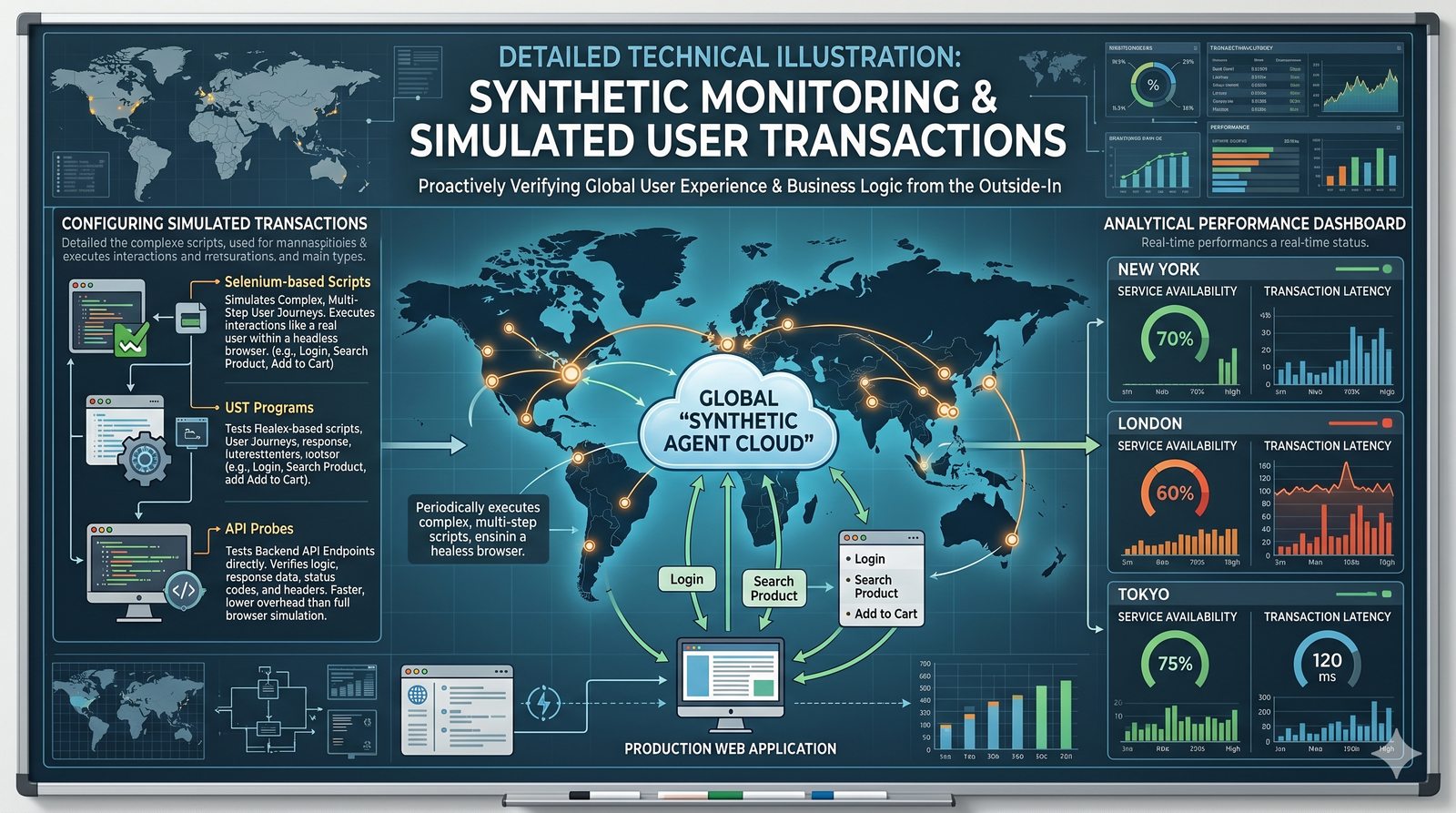
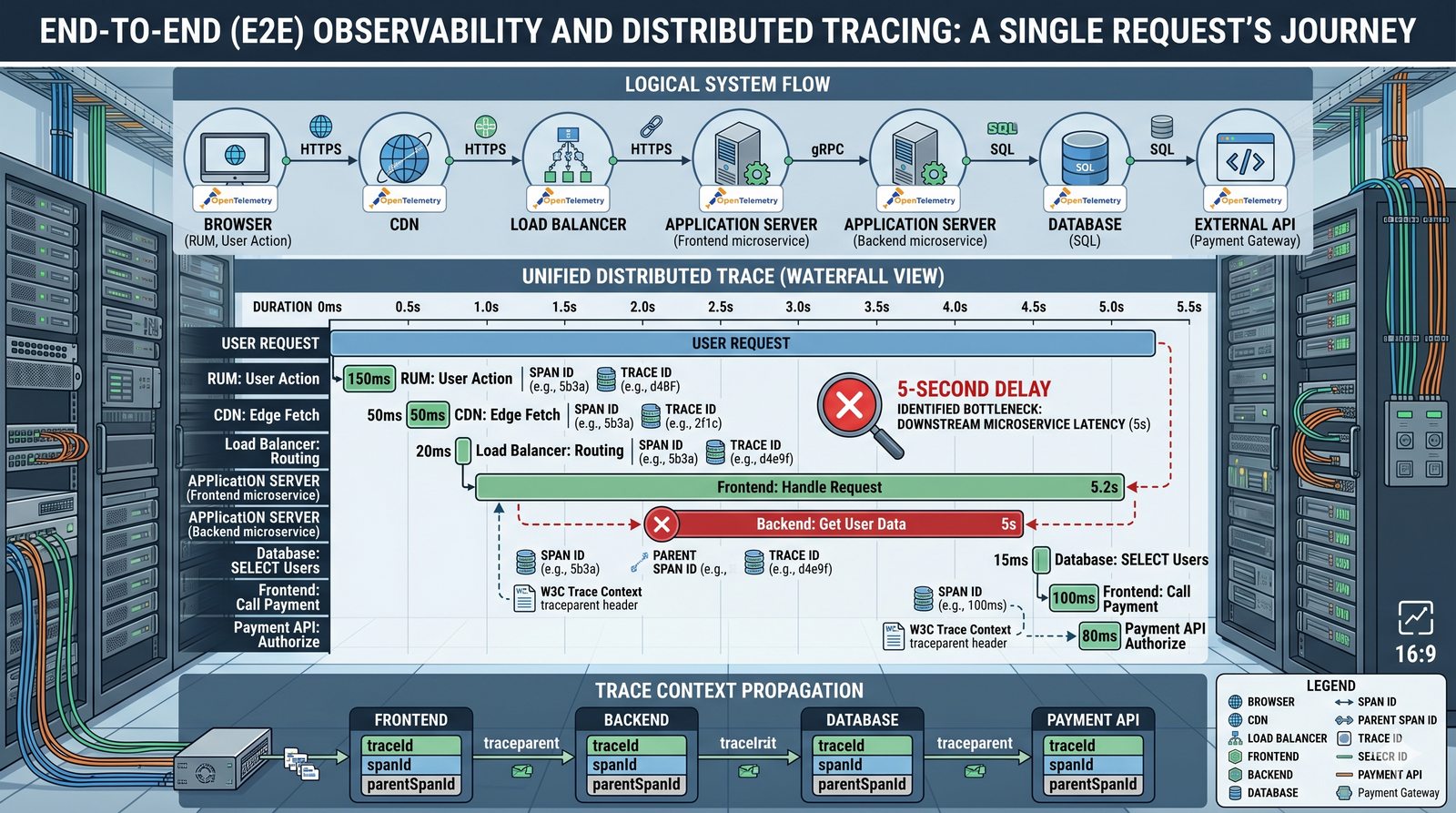
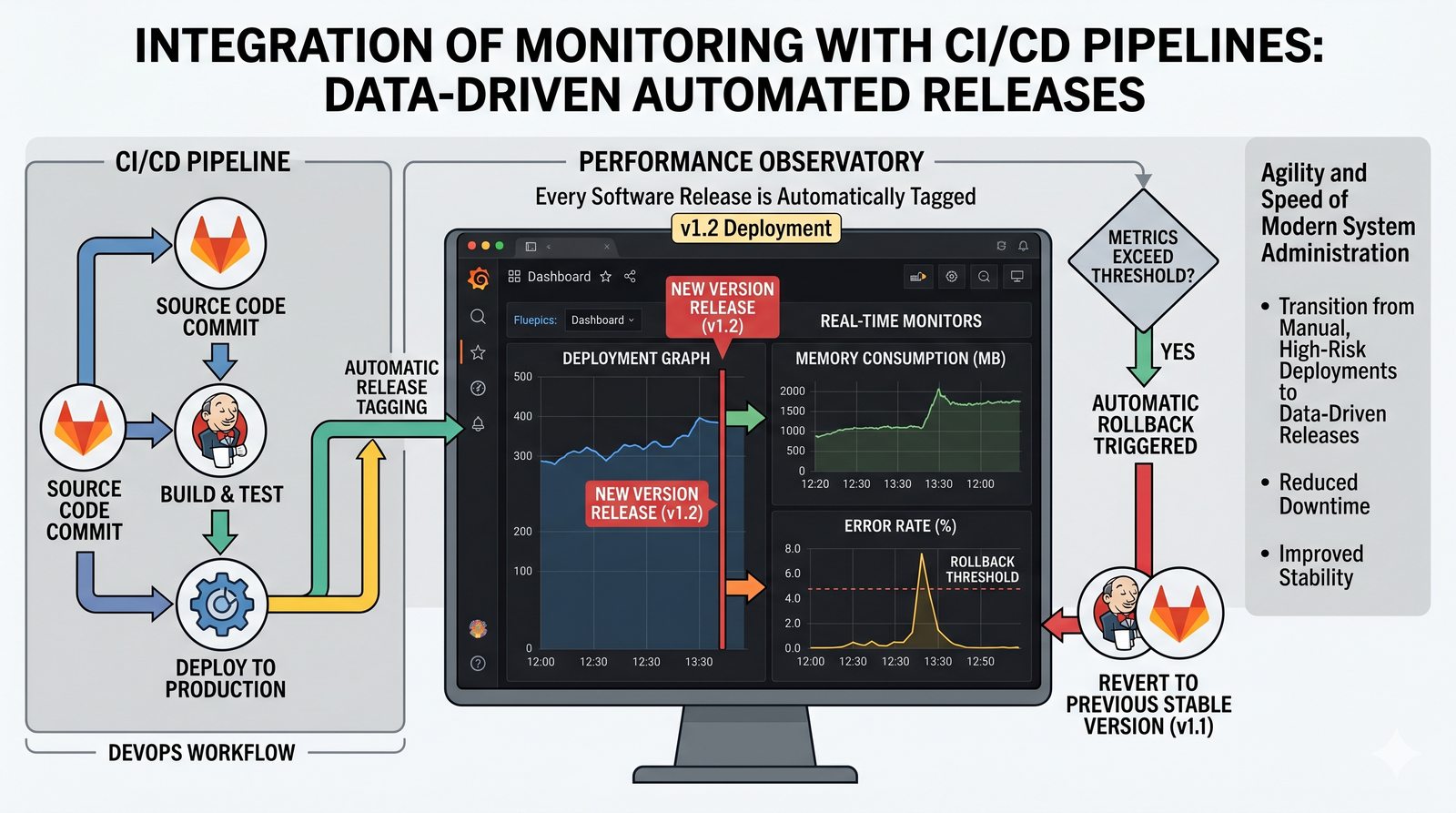
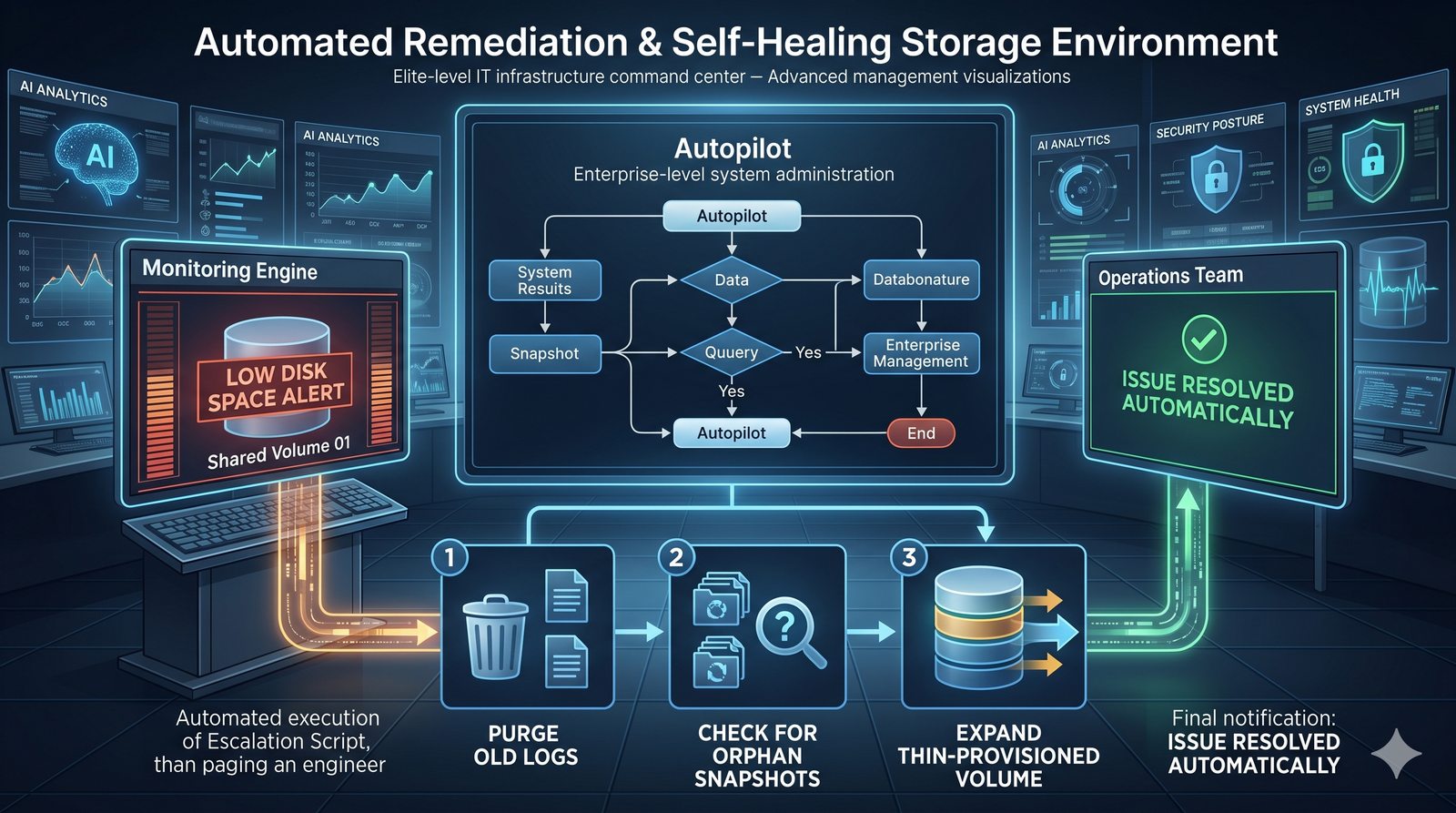
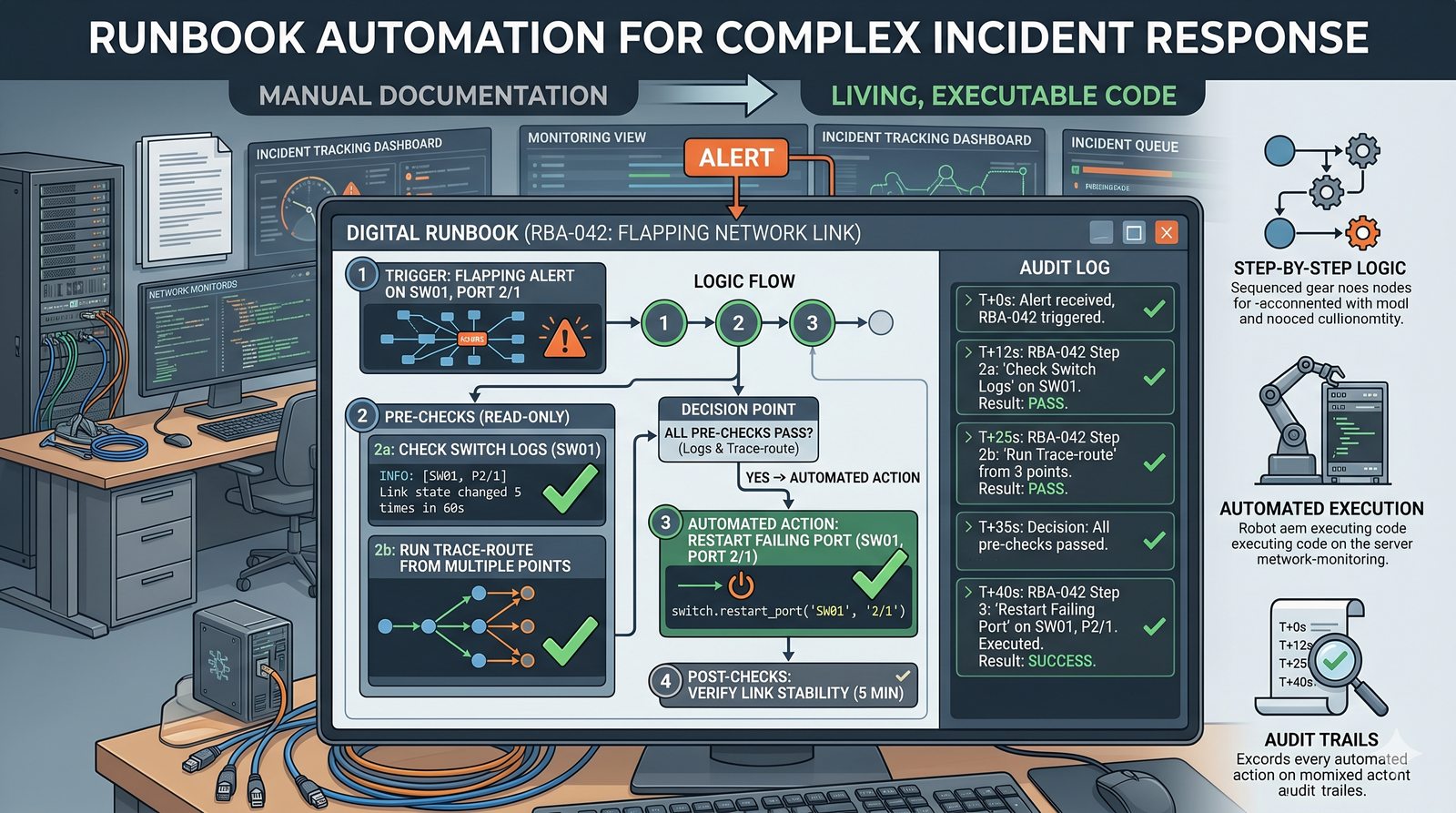
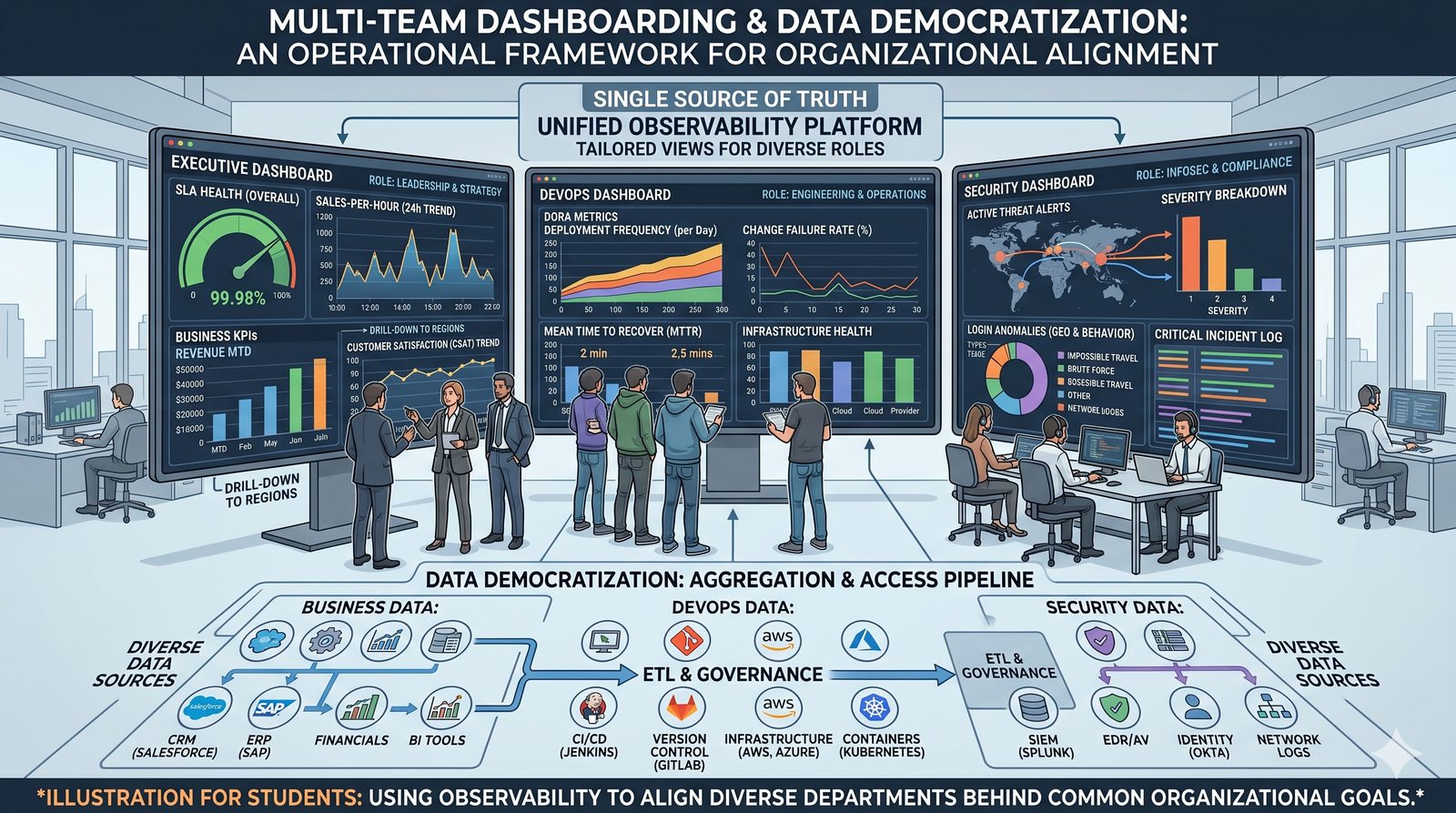
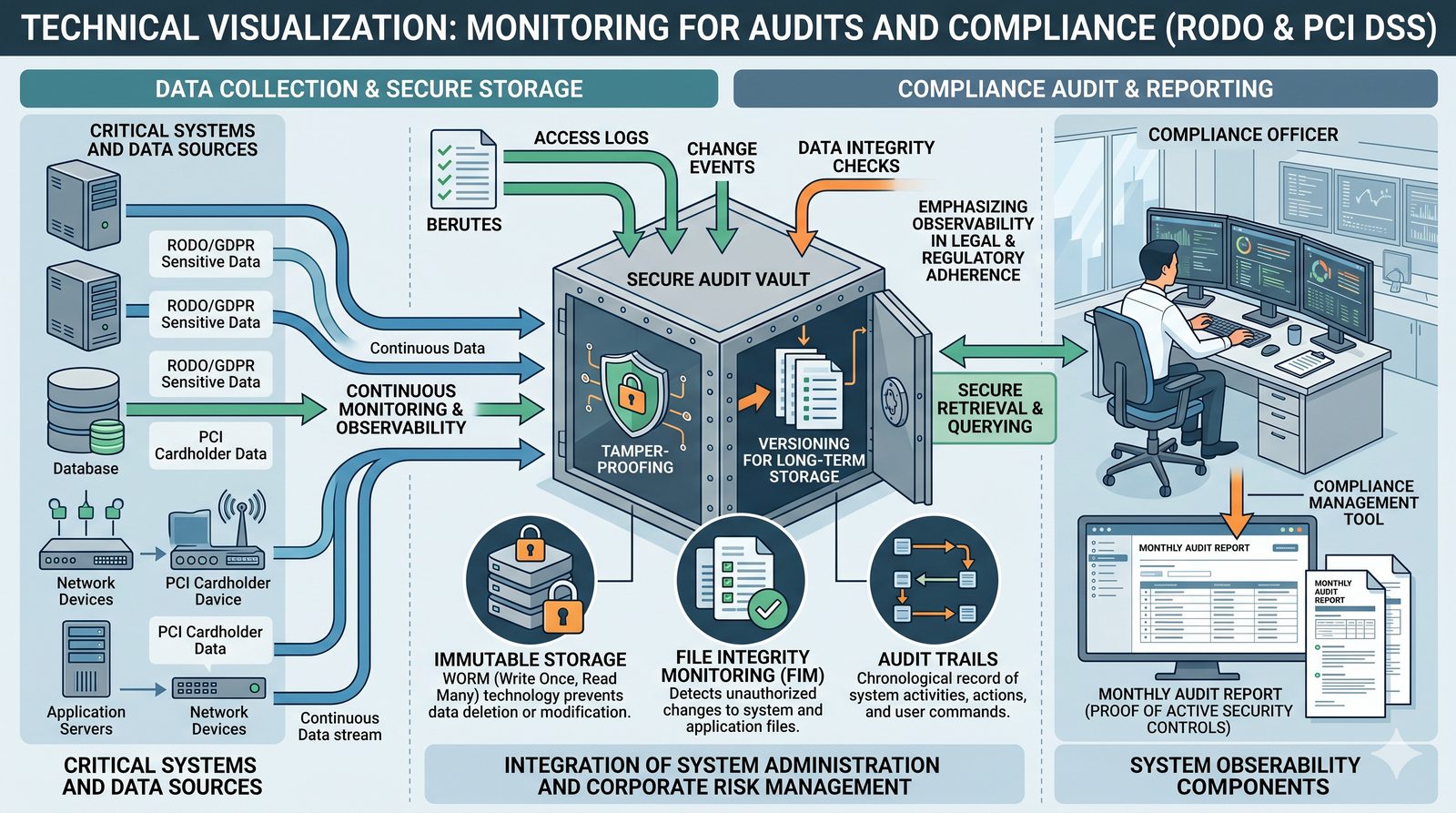
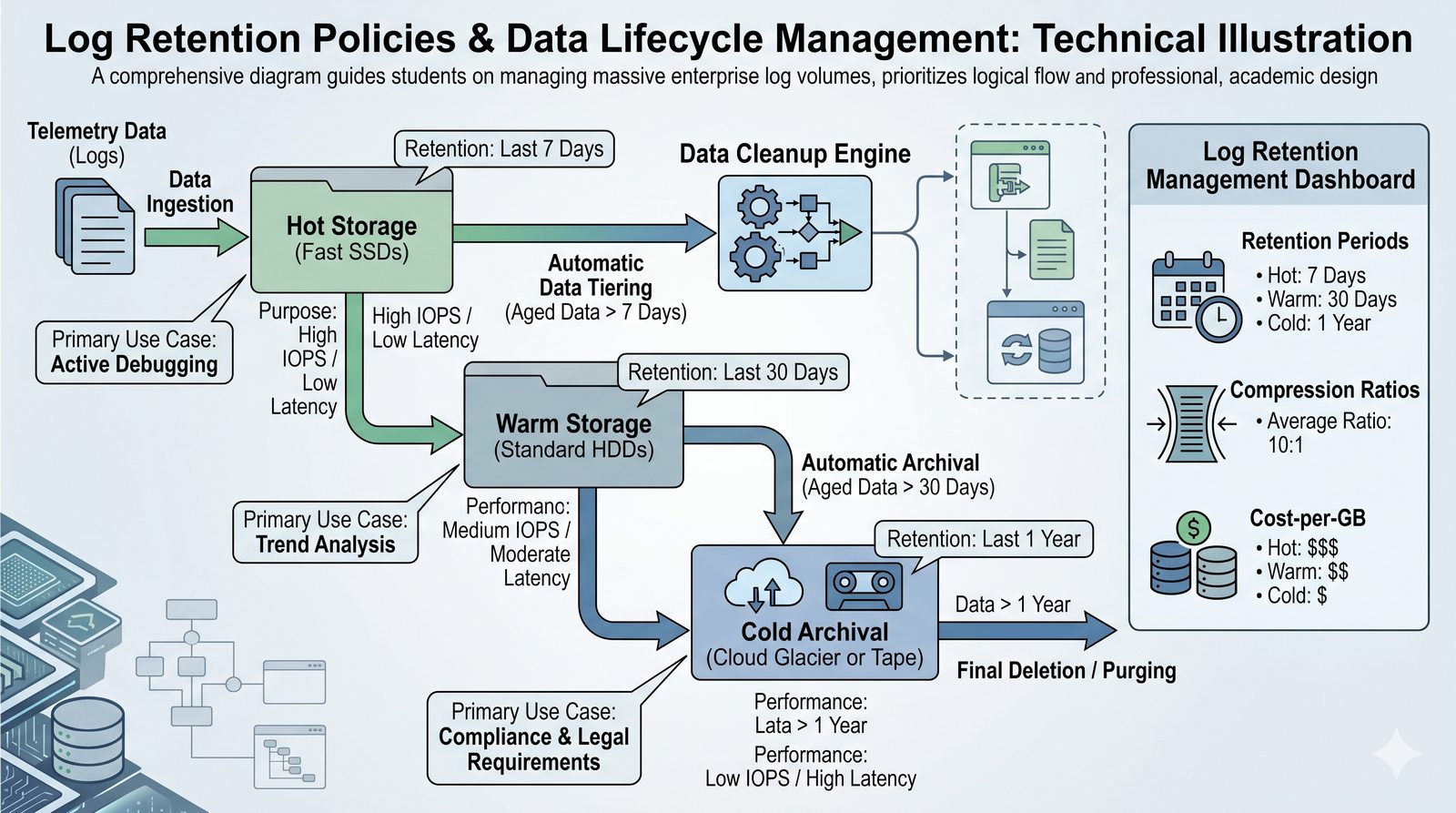
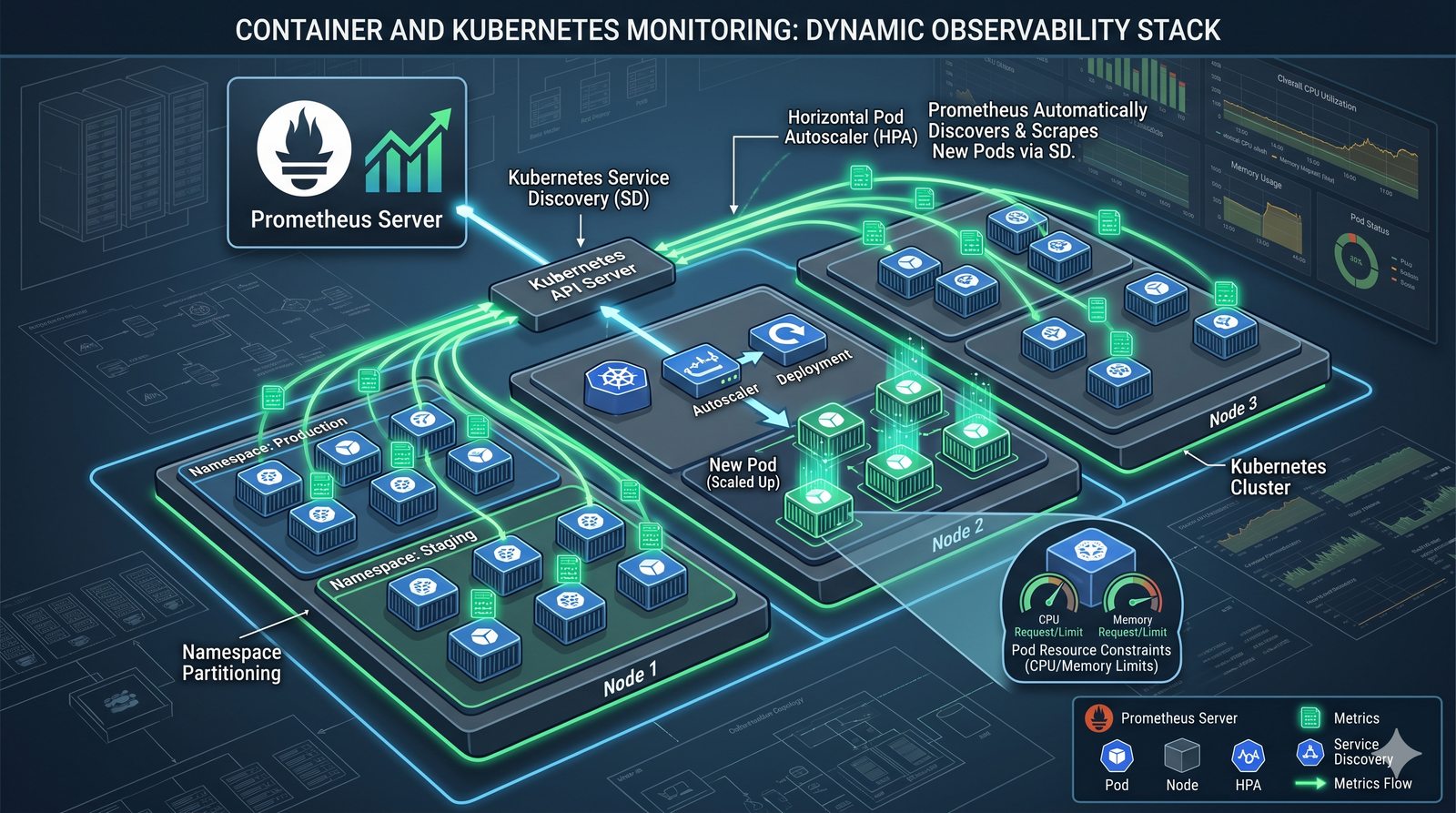
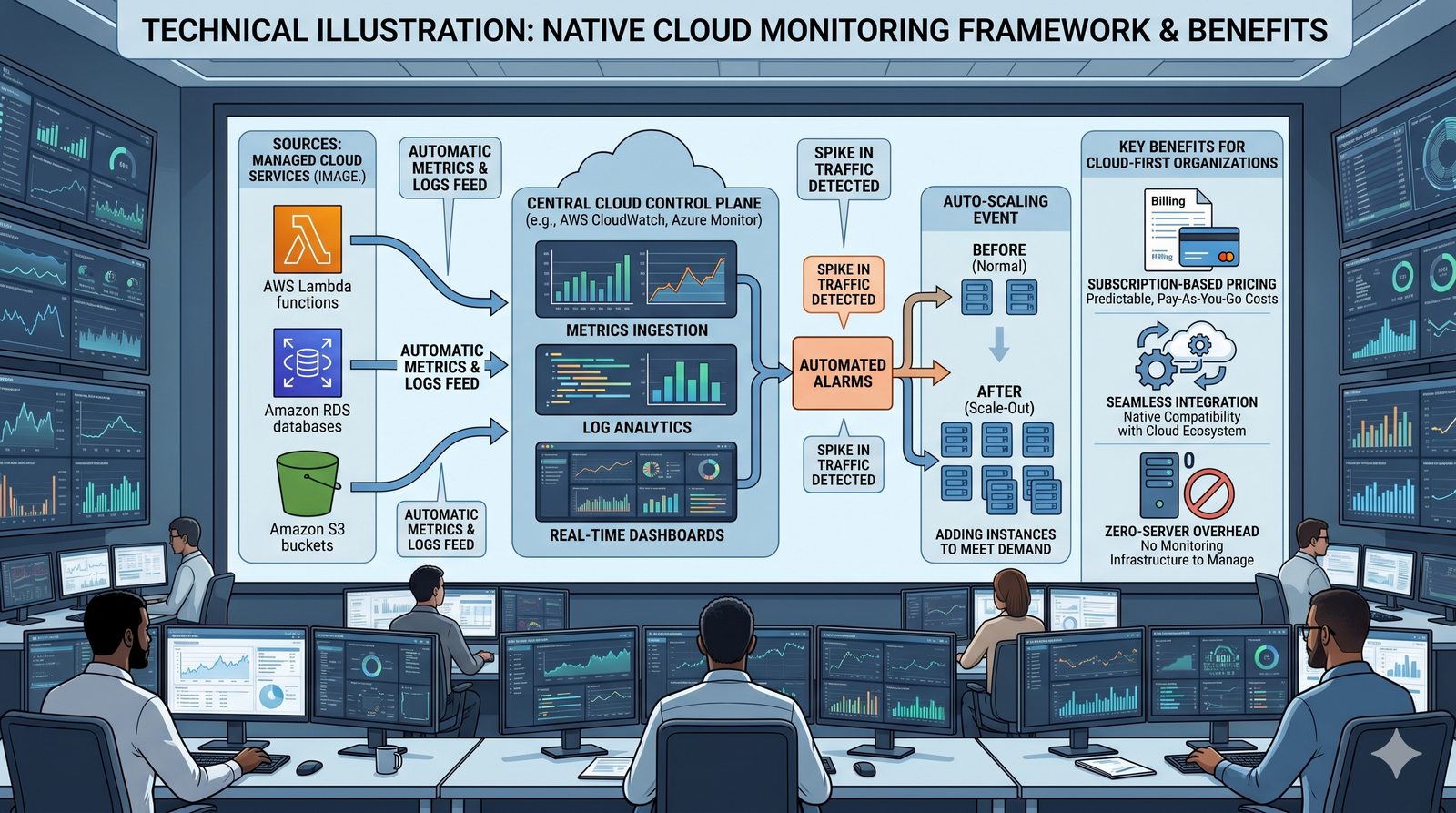
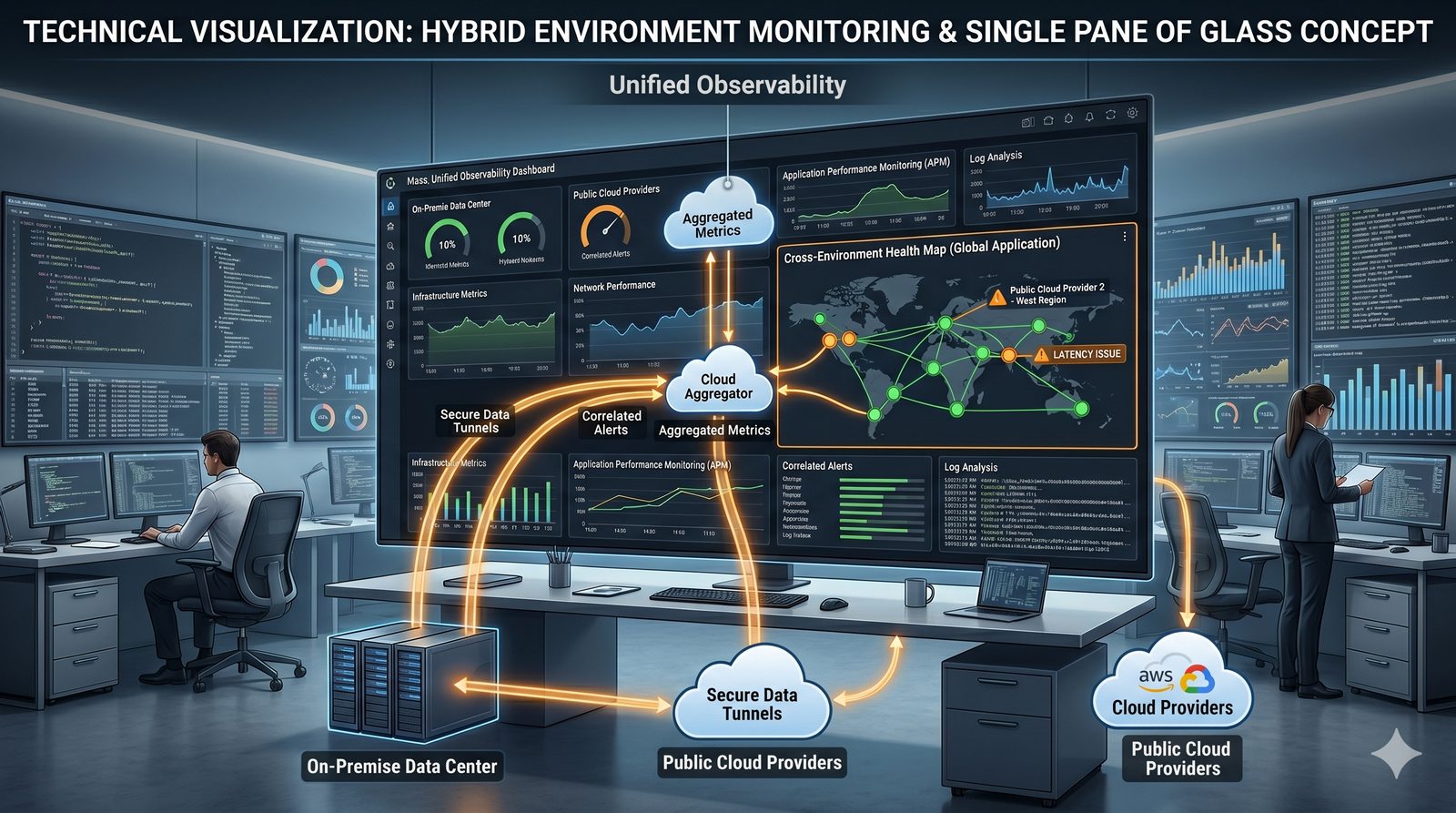
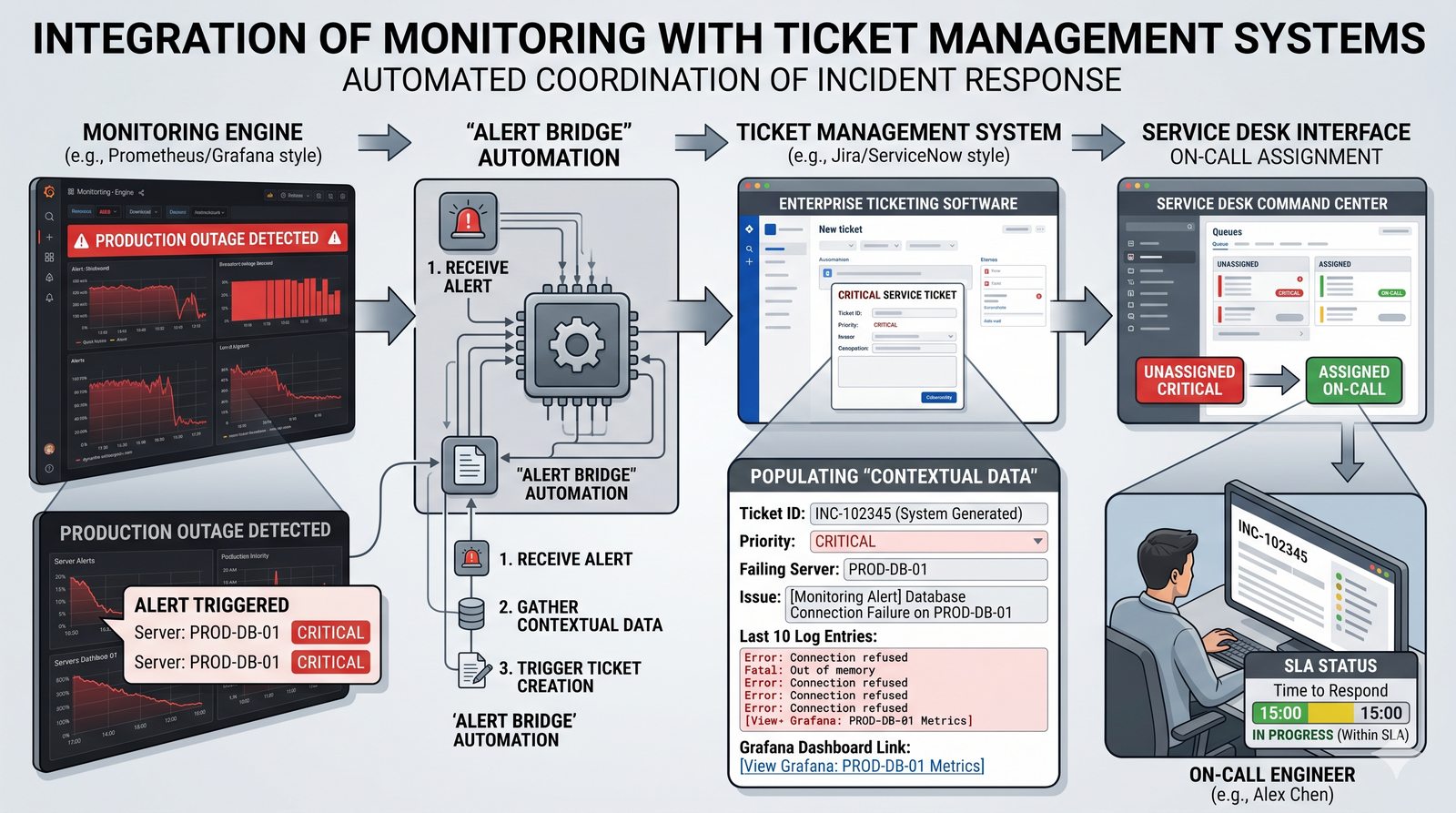
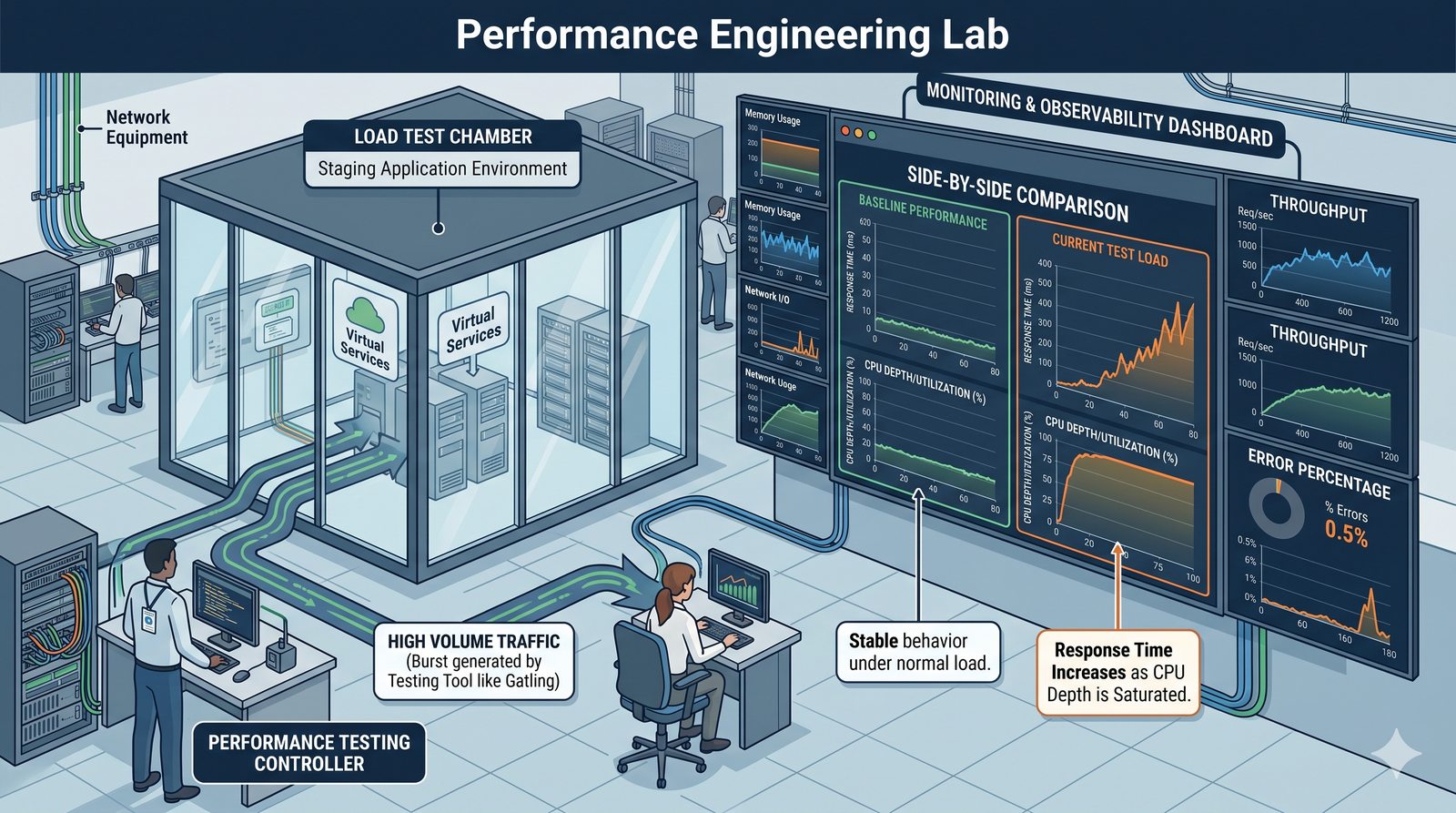
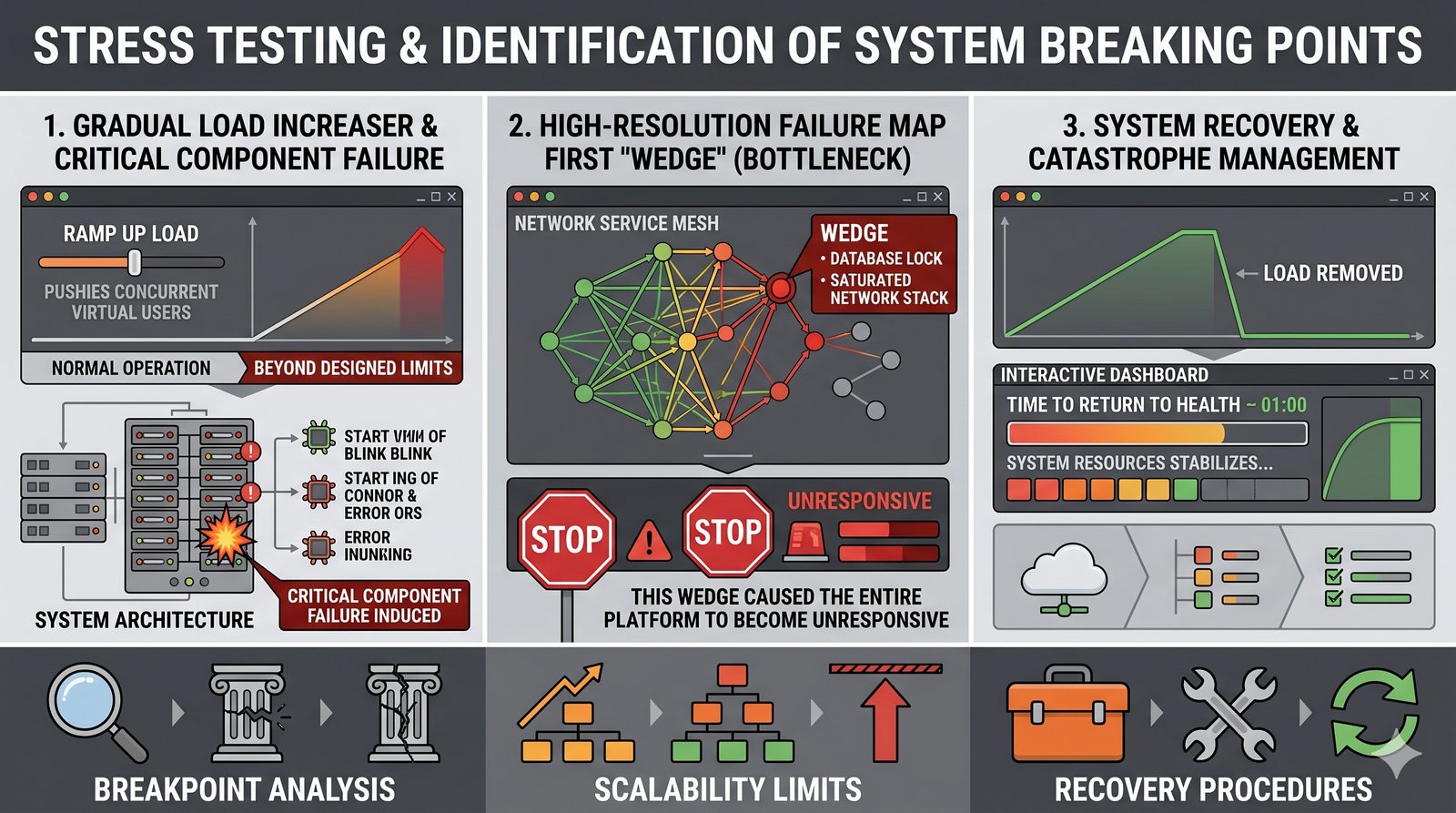
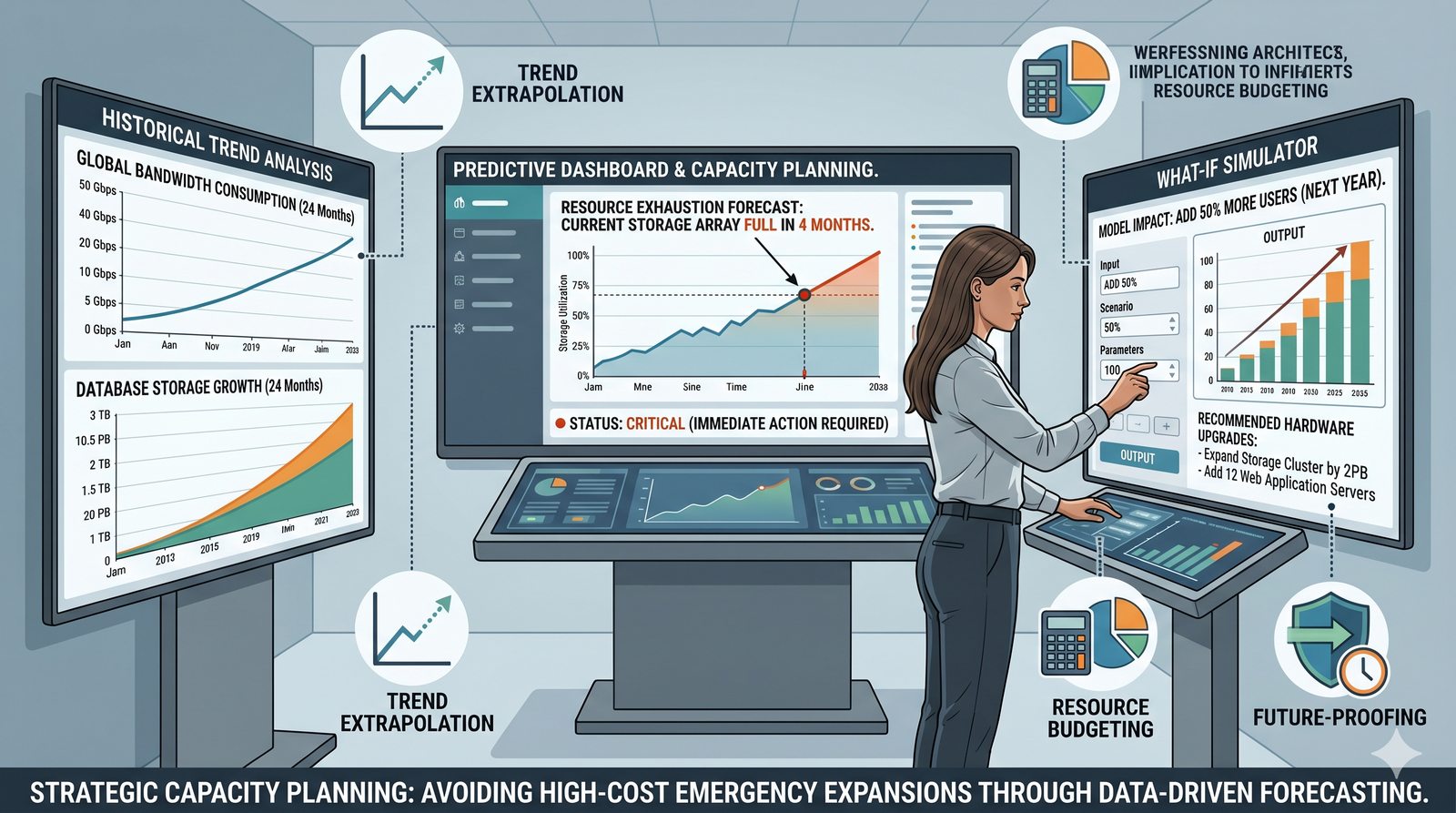
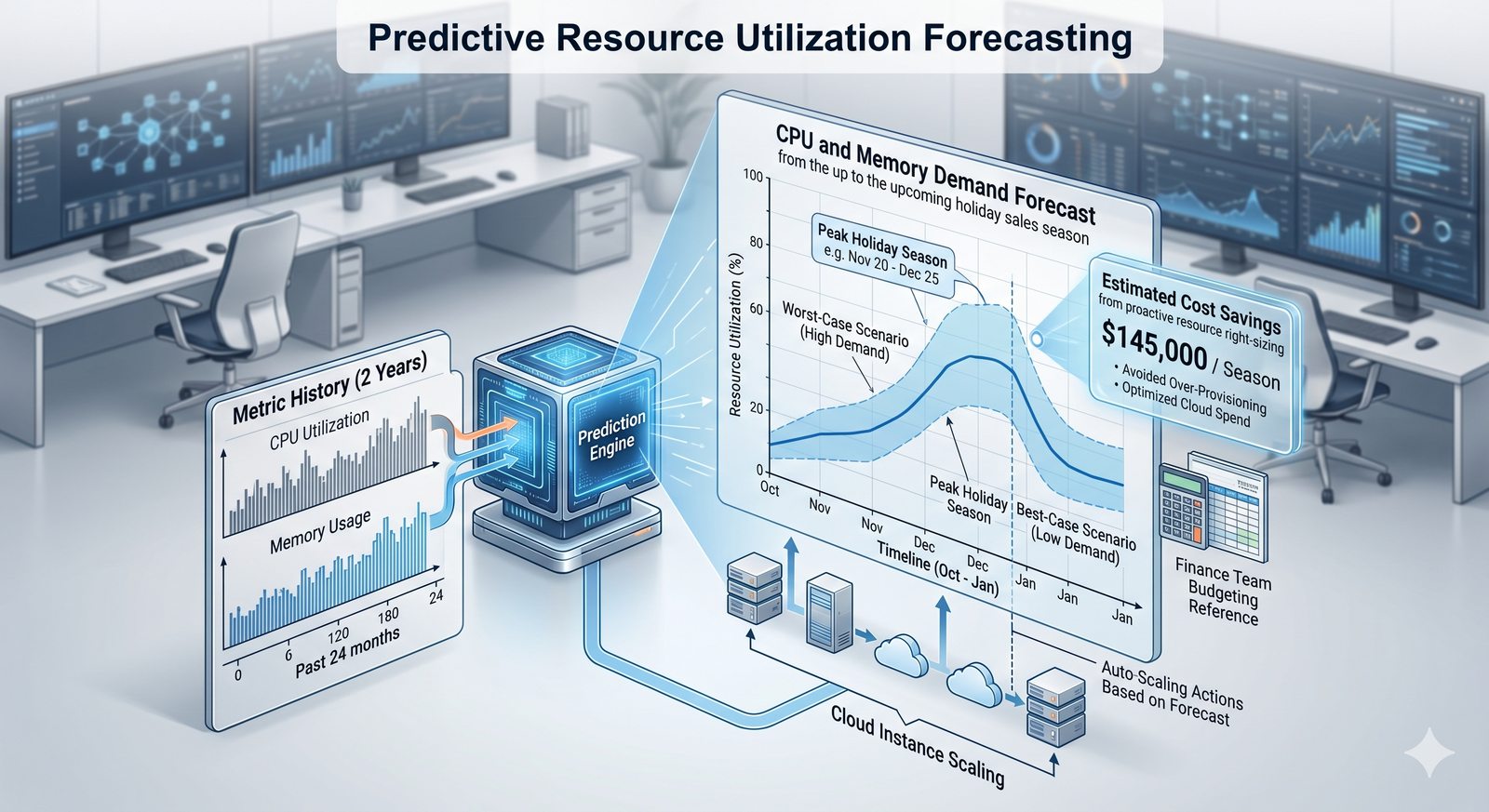
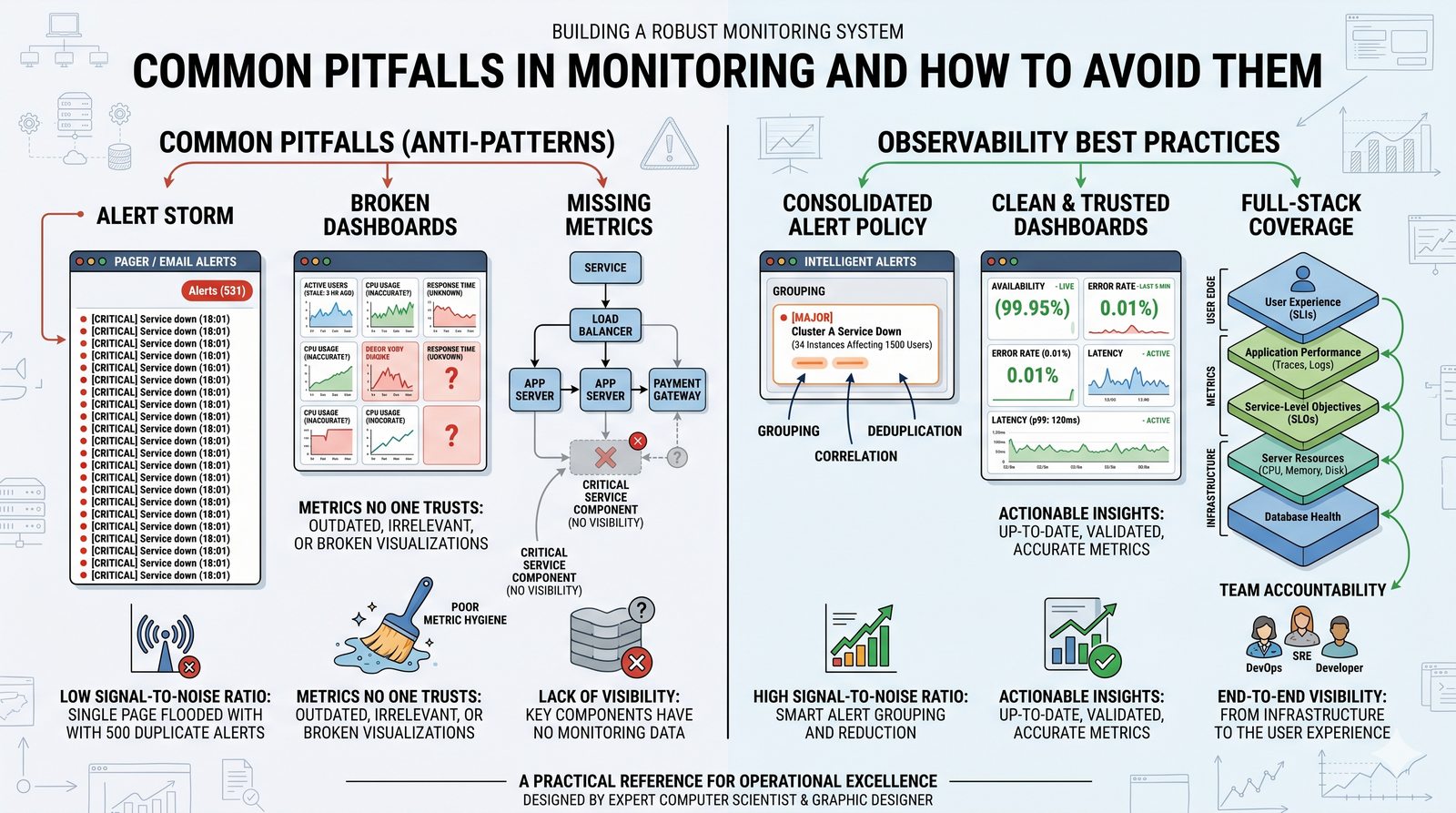
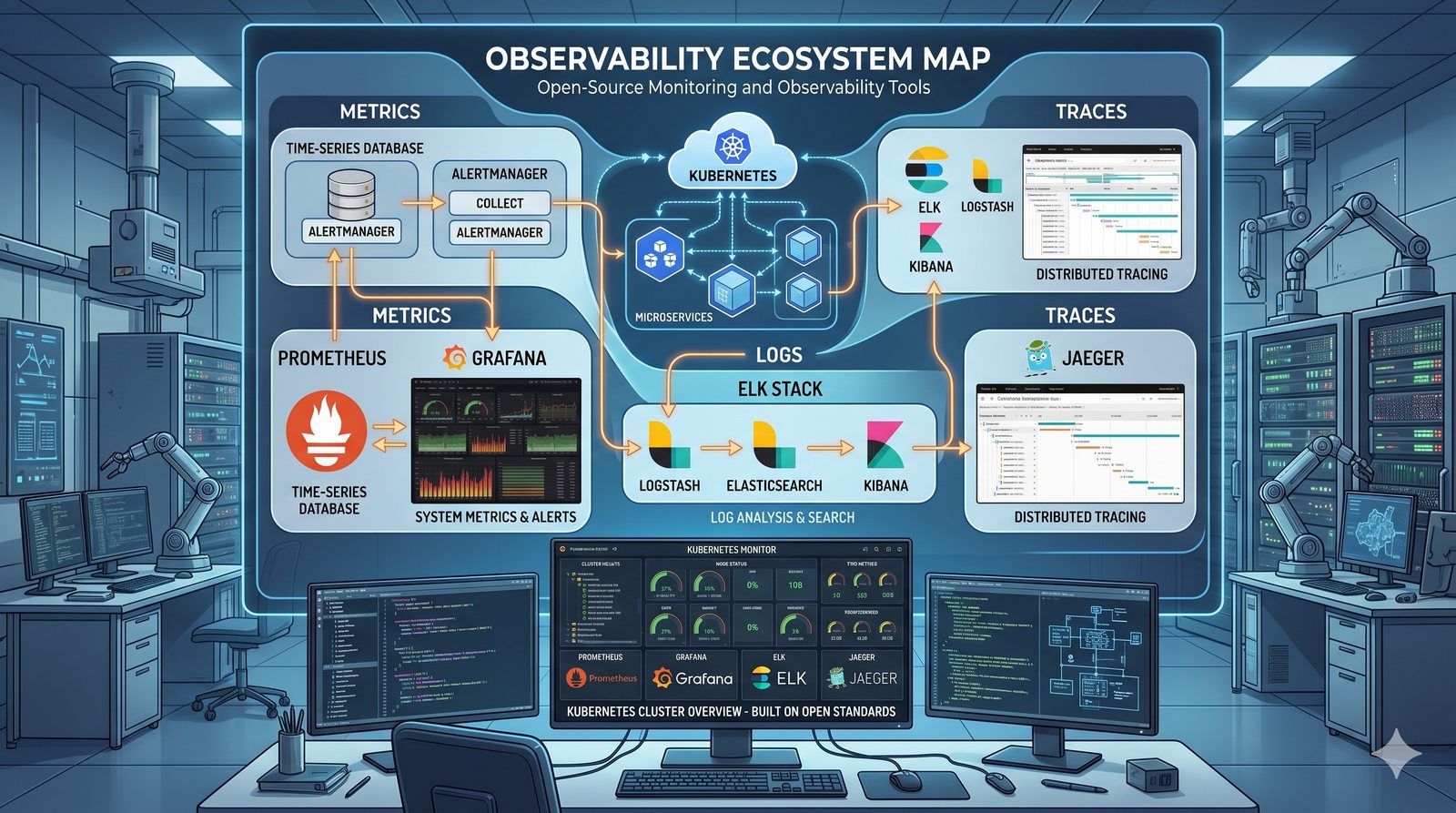
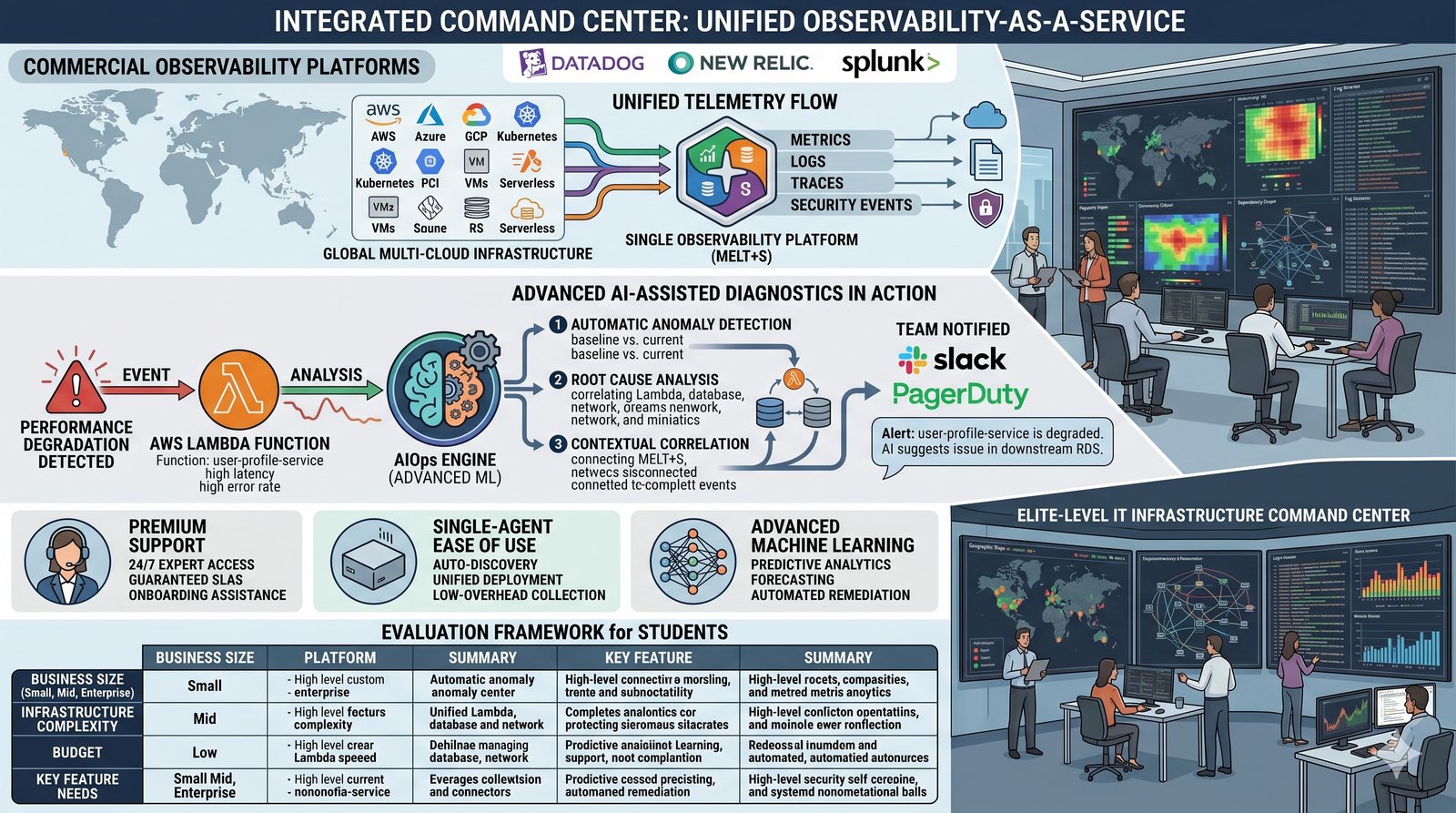
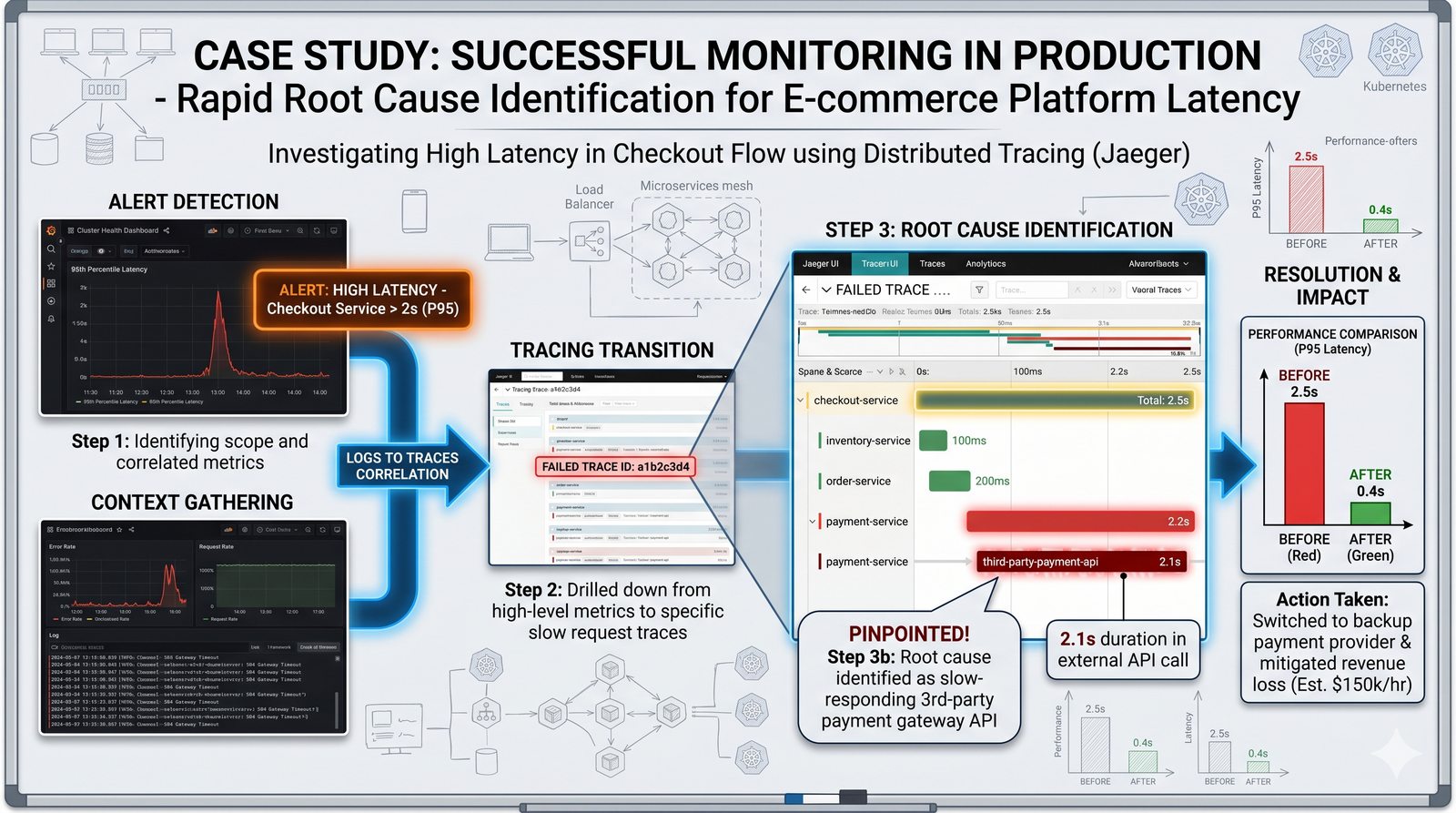
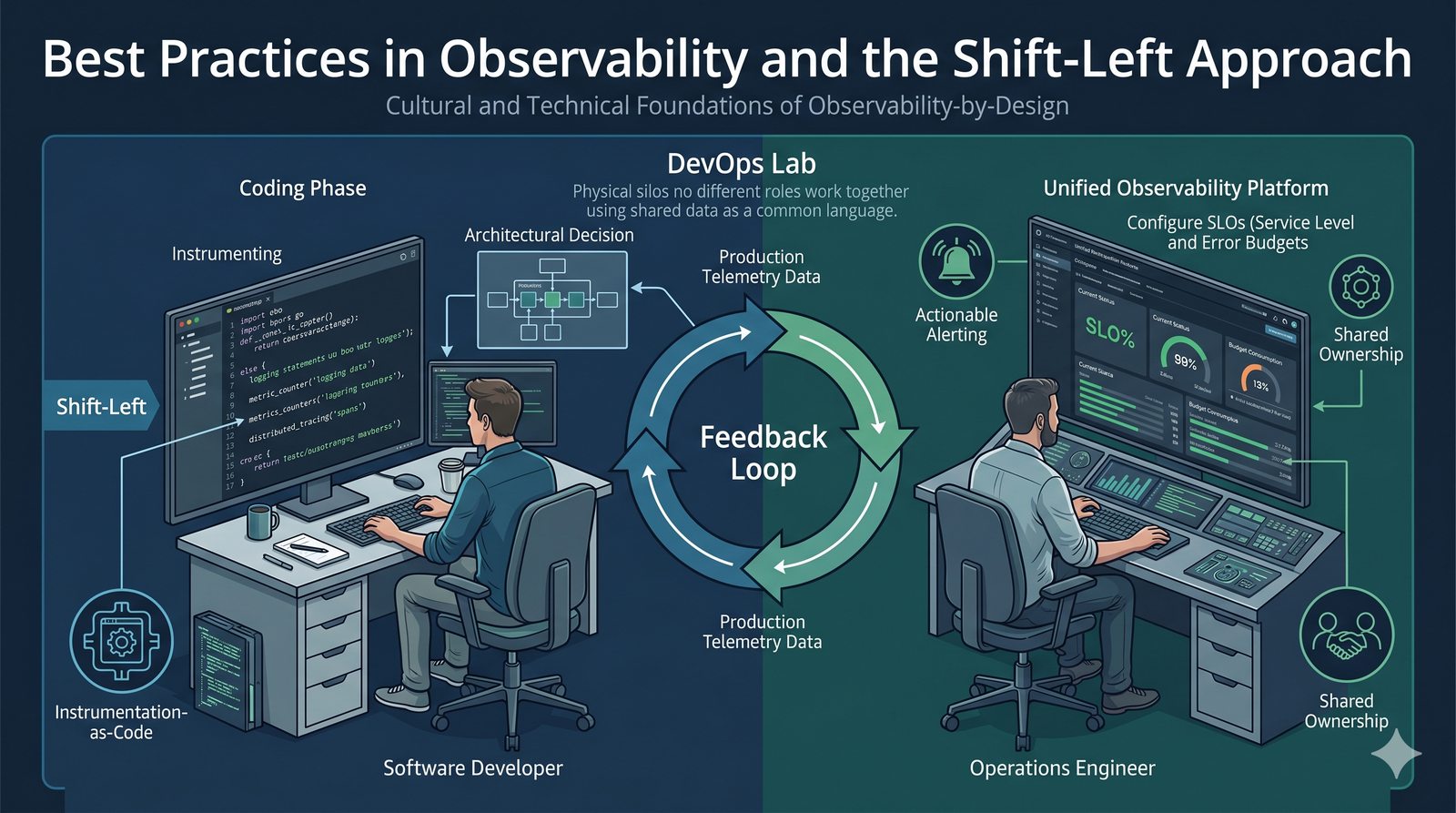
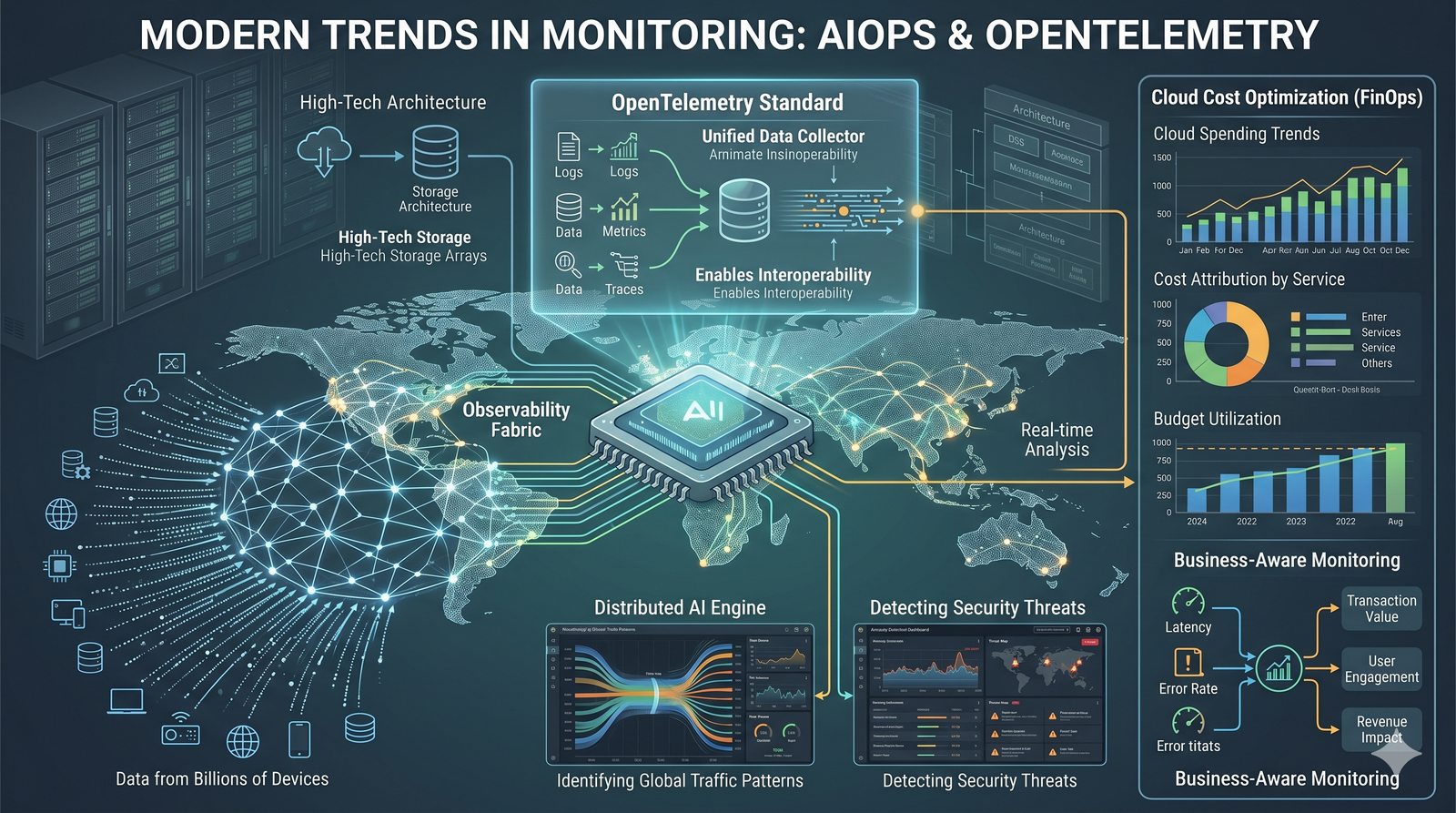
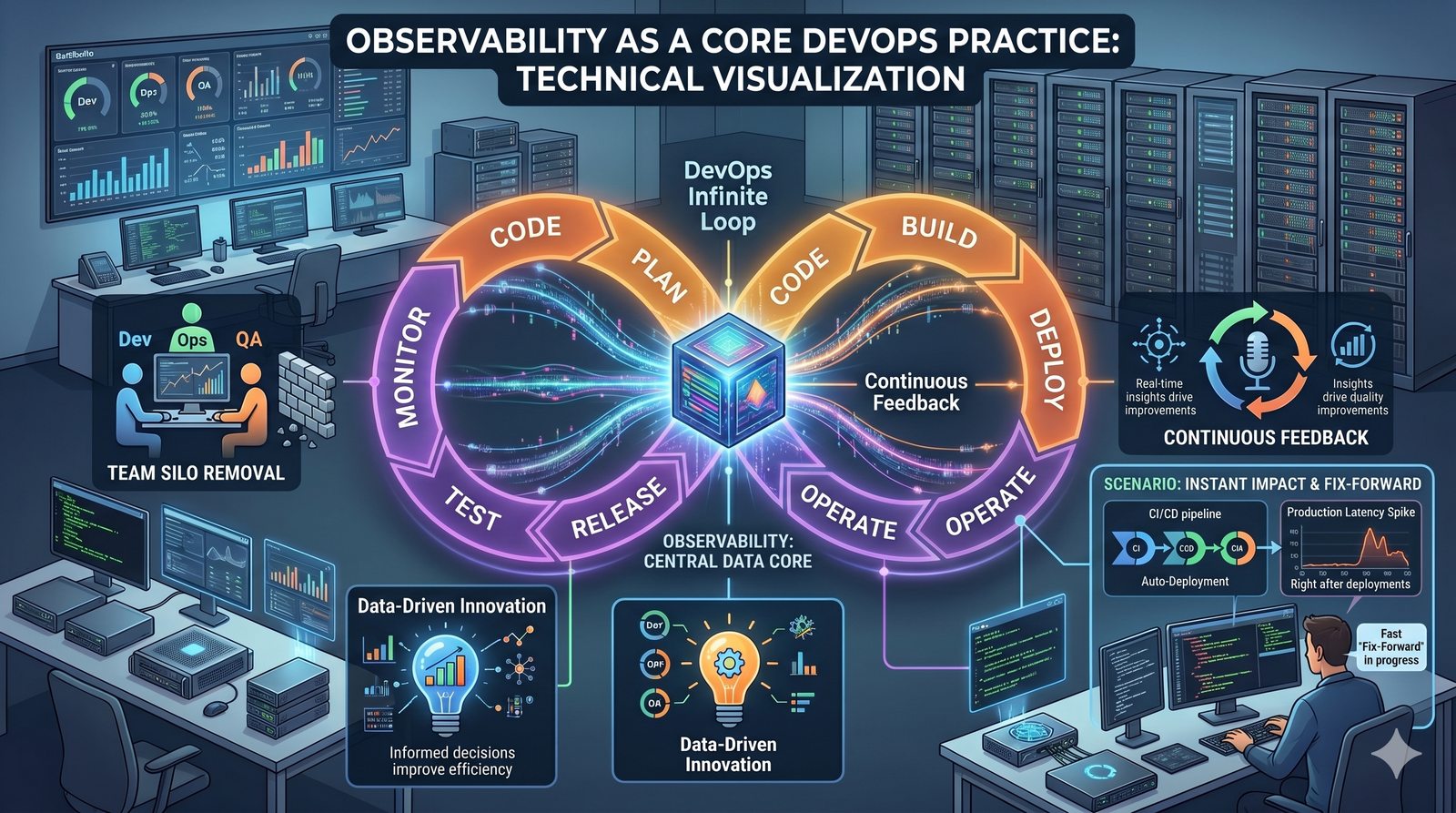
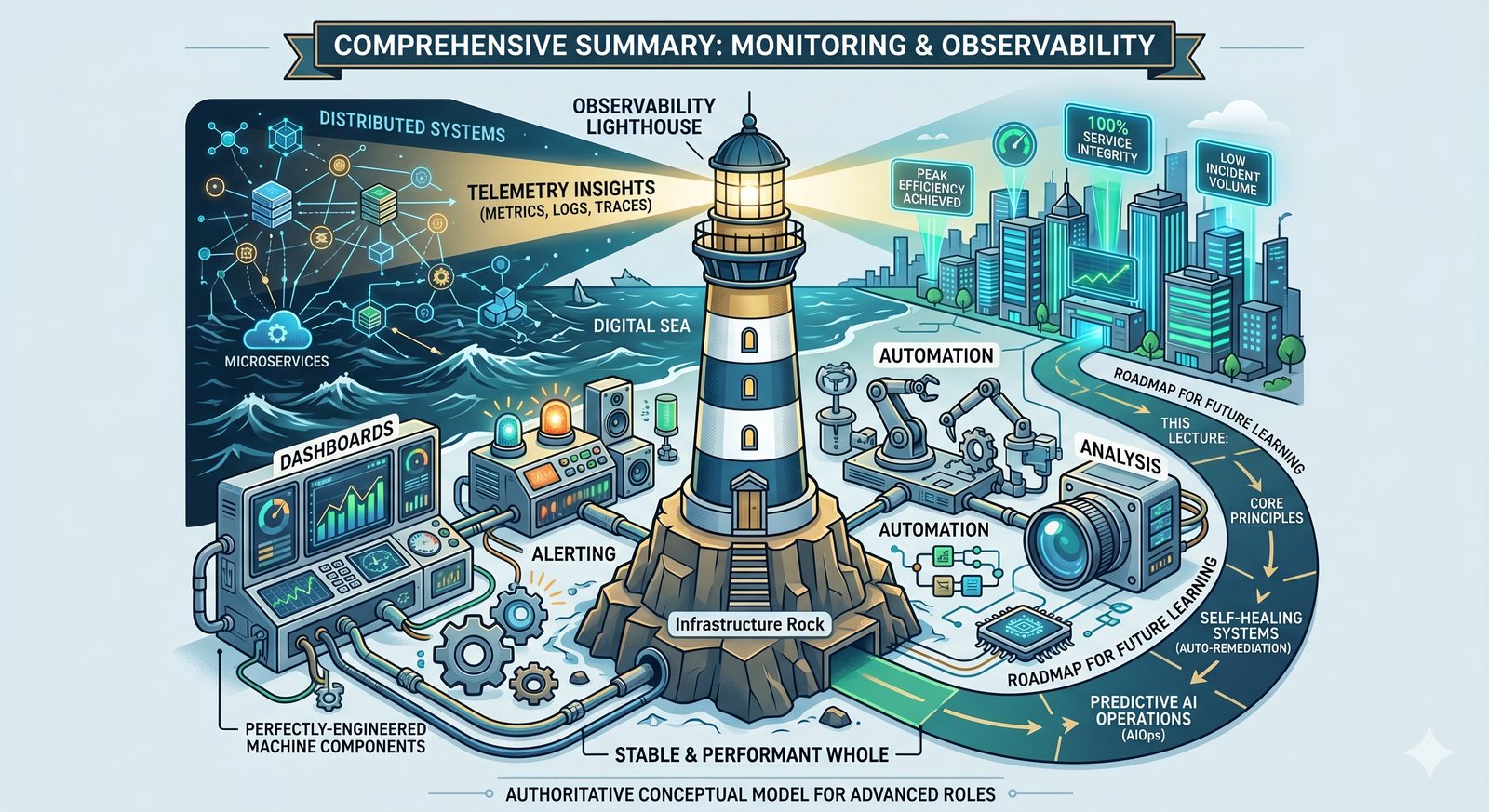
Monitorowanie w IT to proces systematycznego zbierania, analizowania i wizualizowania danych o stanie i wydajności systemów komputerowych, sieci i aplikacji.
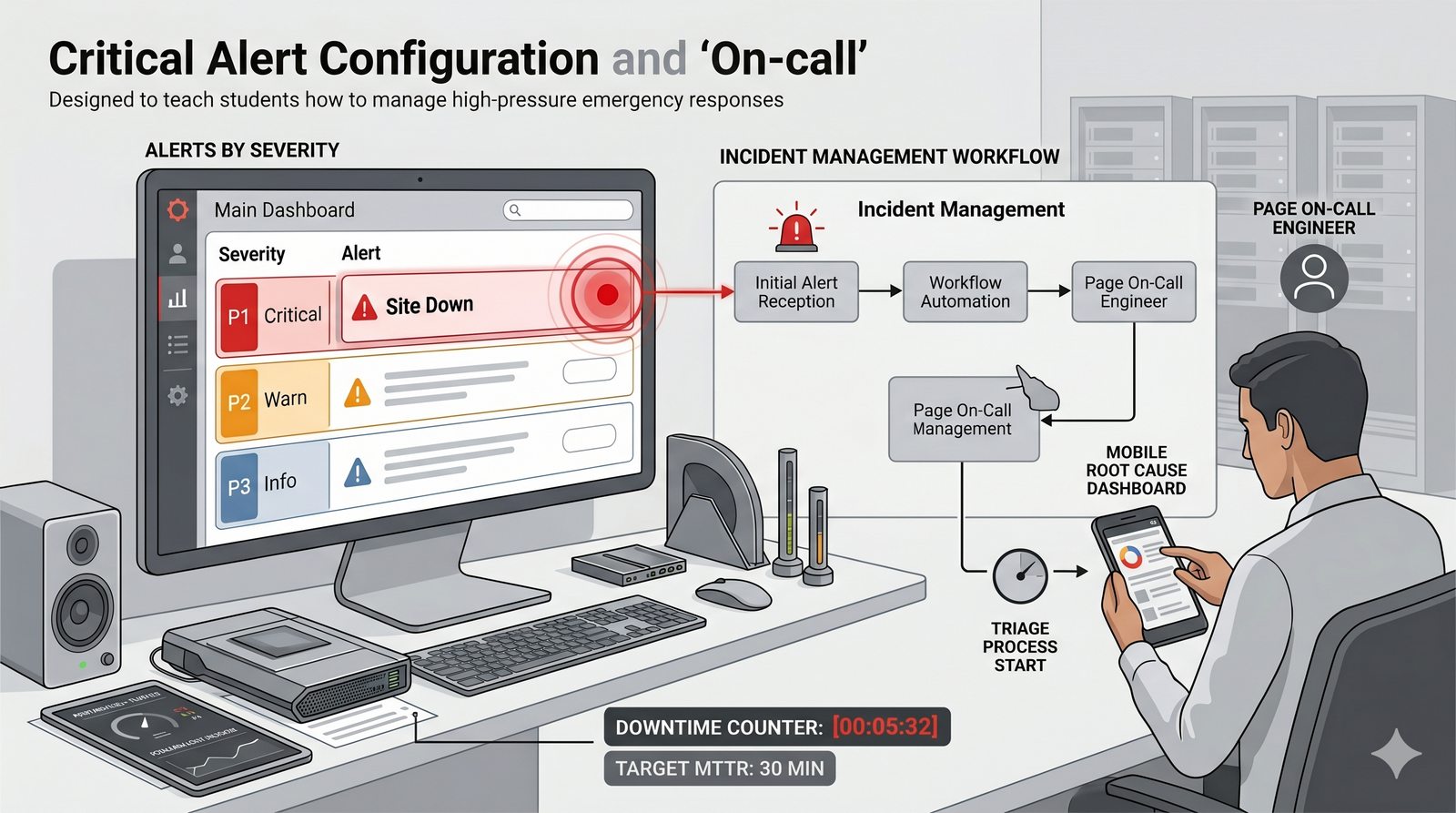
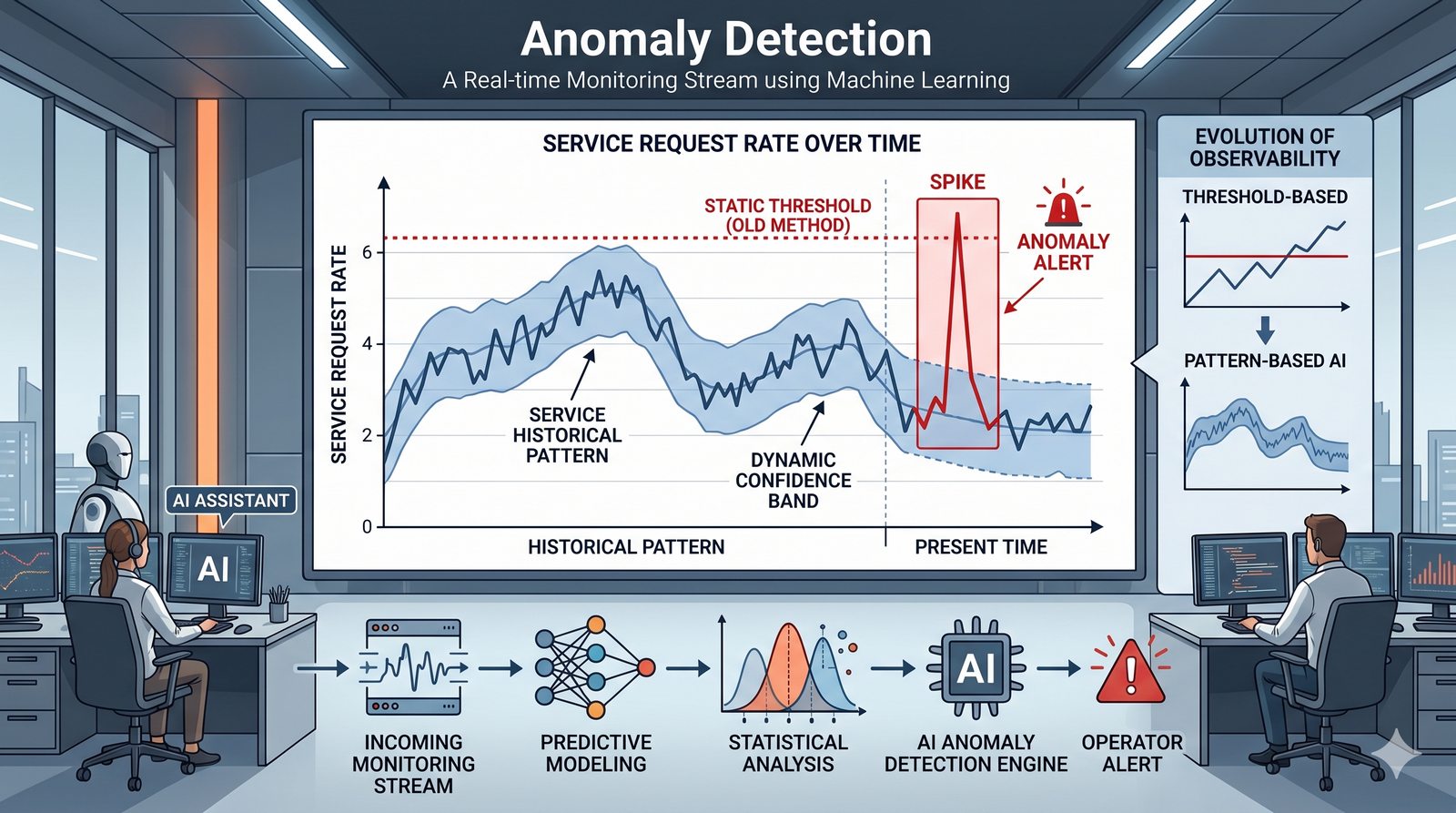
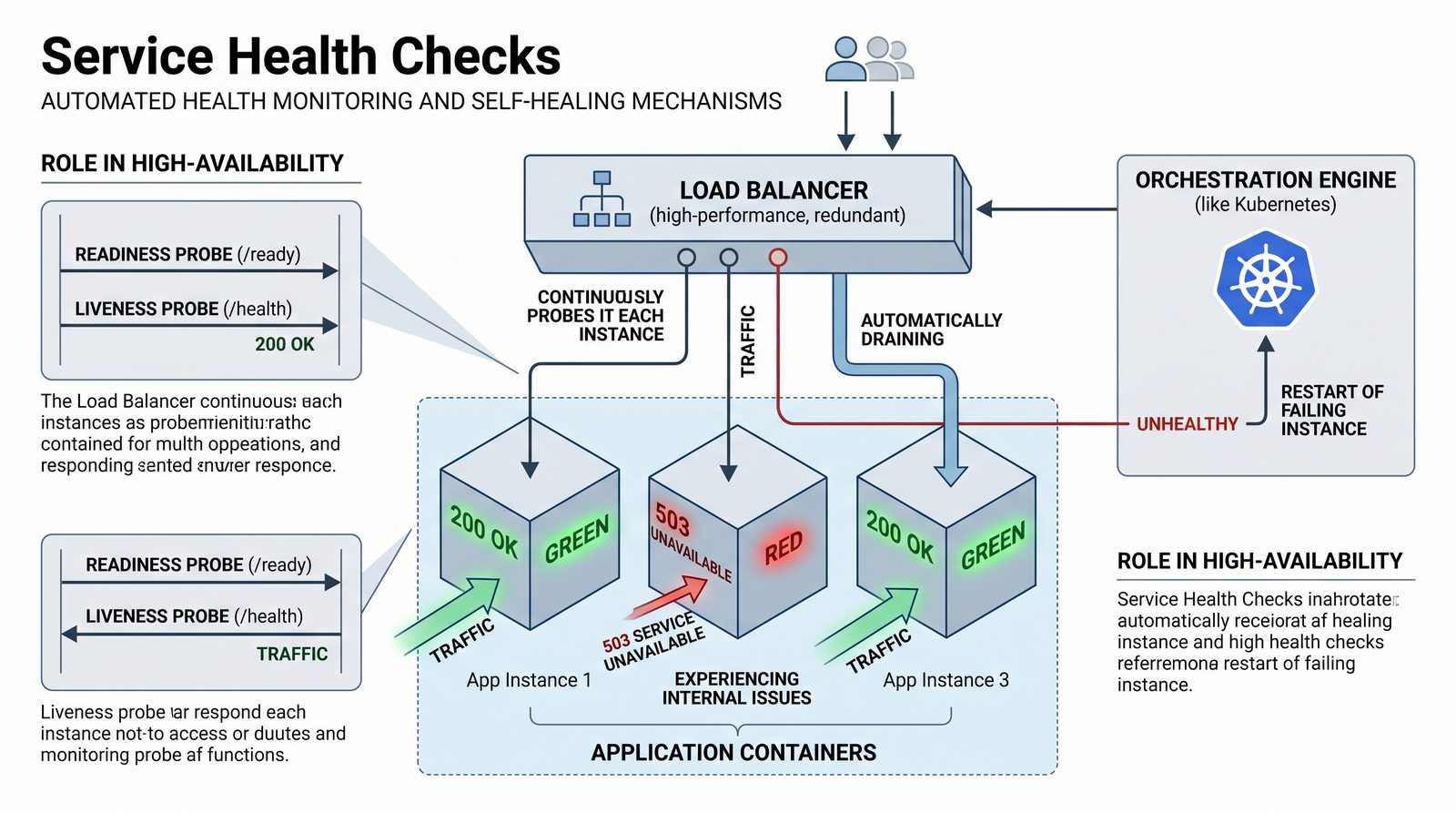
- Jego głównym celem jest zapewnienie, że usługi działają zgodnie z oczekiwaniami, oraz proaktywne wykrywanie problemów, zanim wpłyną one na użytkowników końcowych.
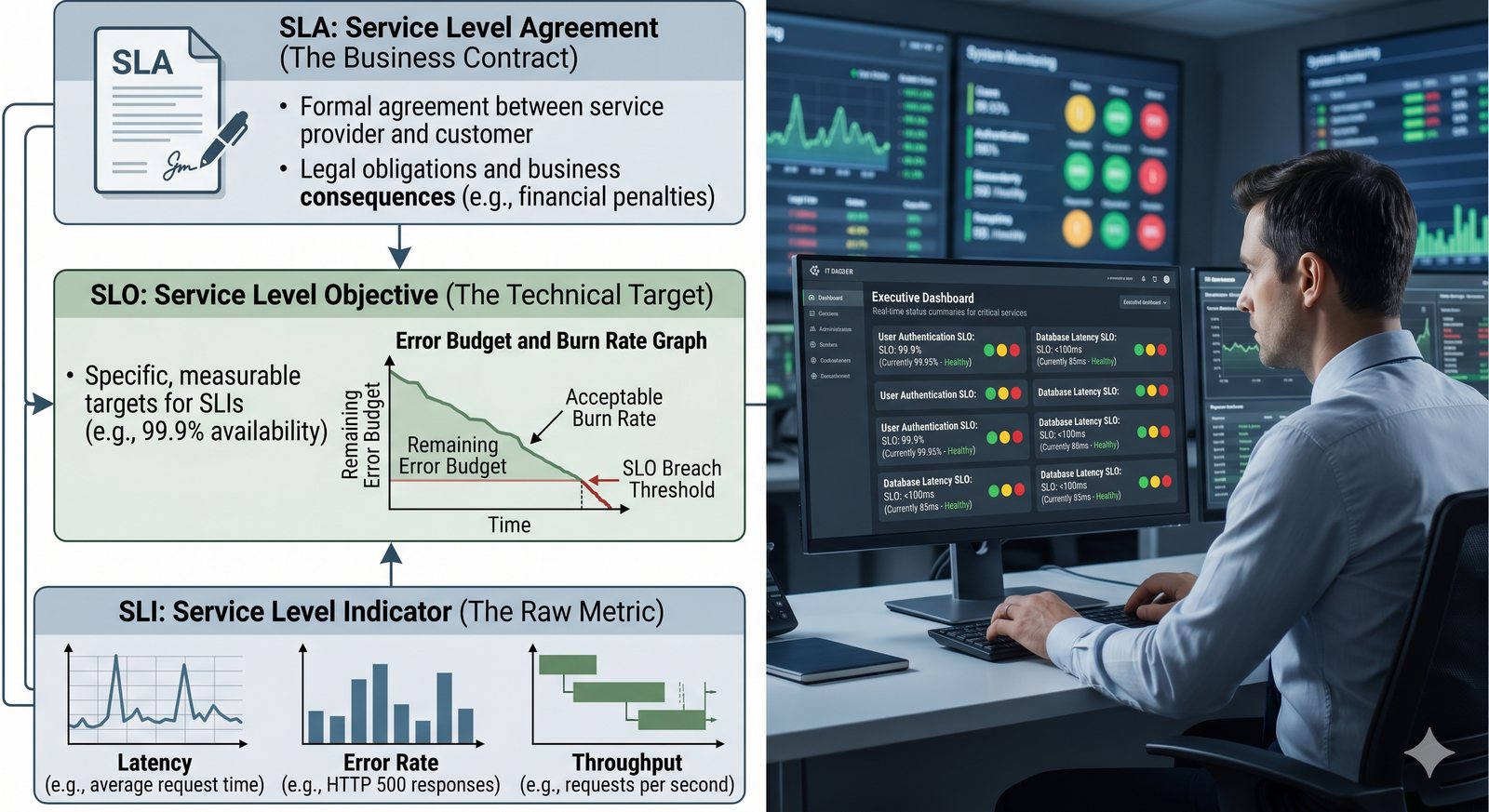
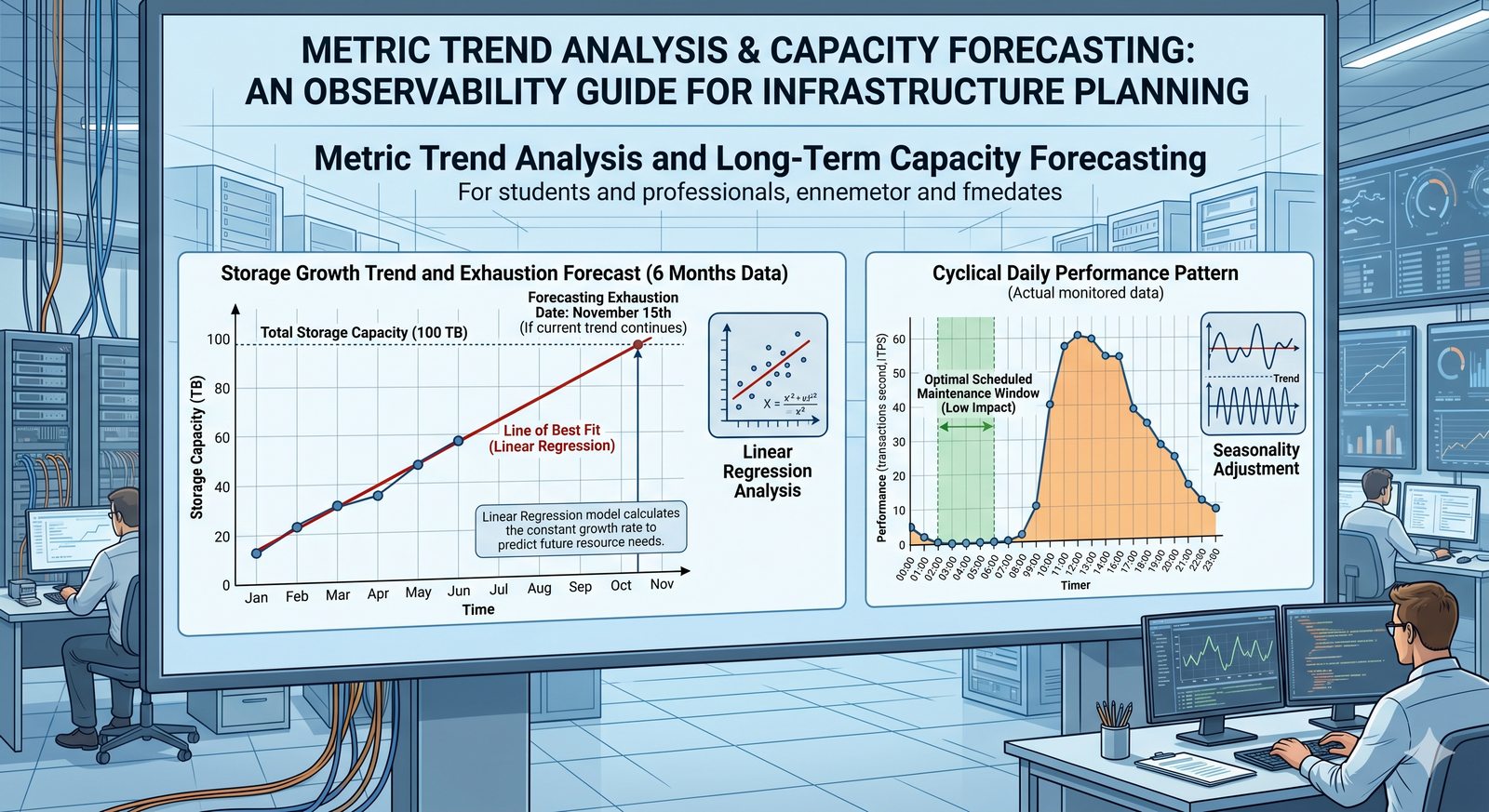
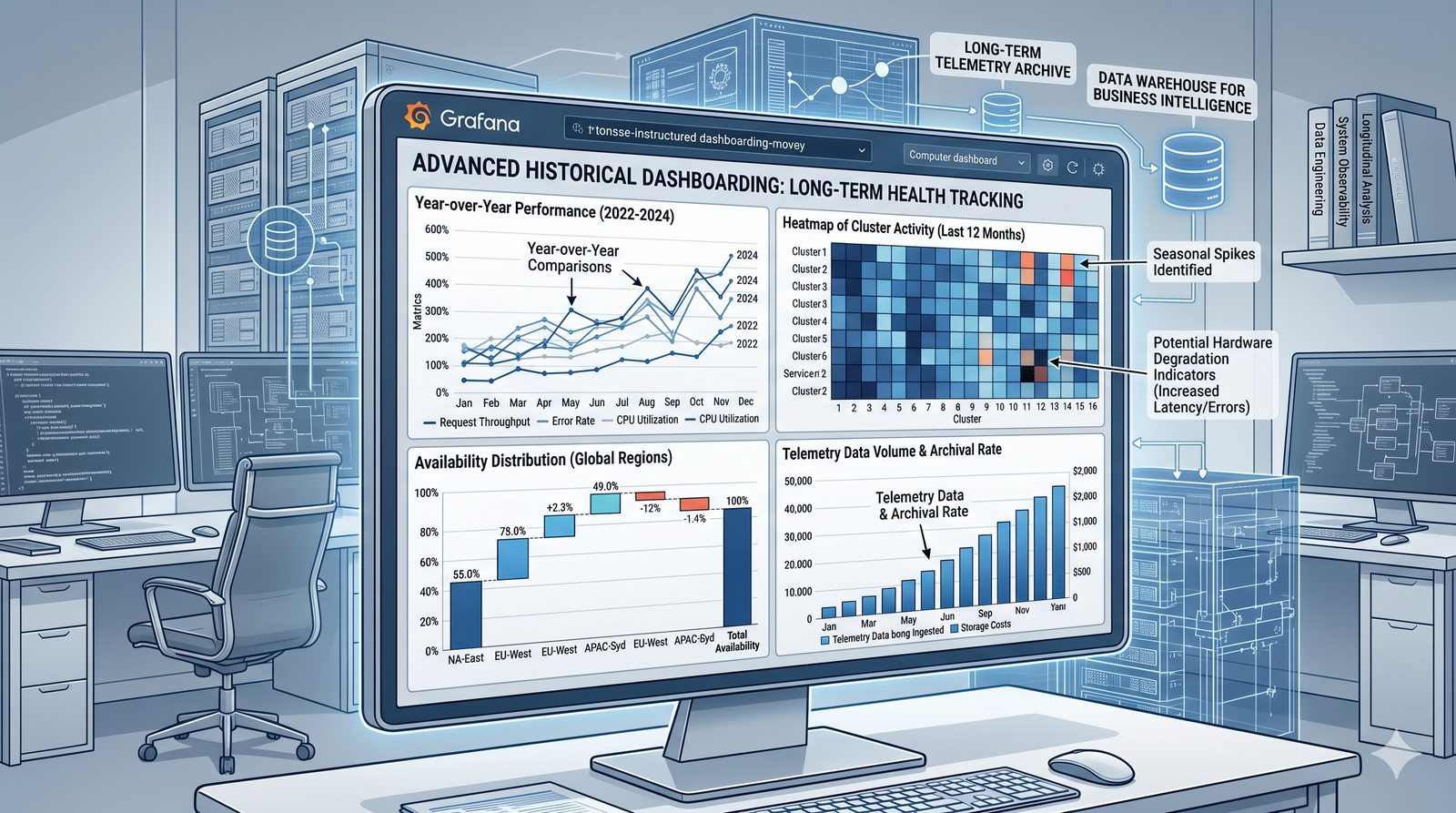
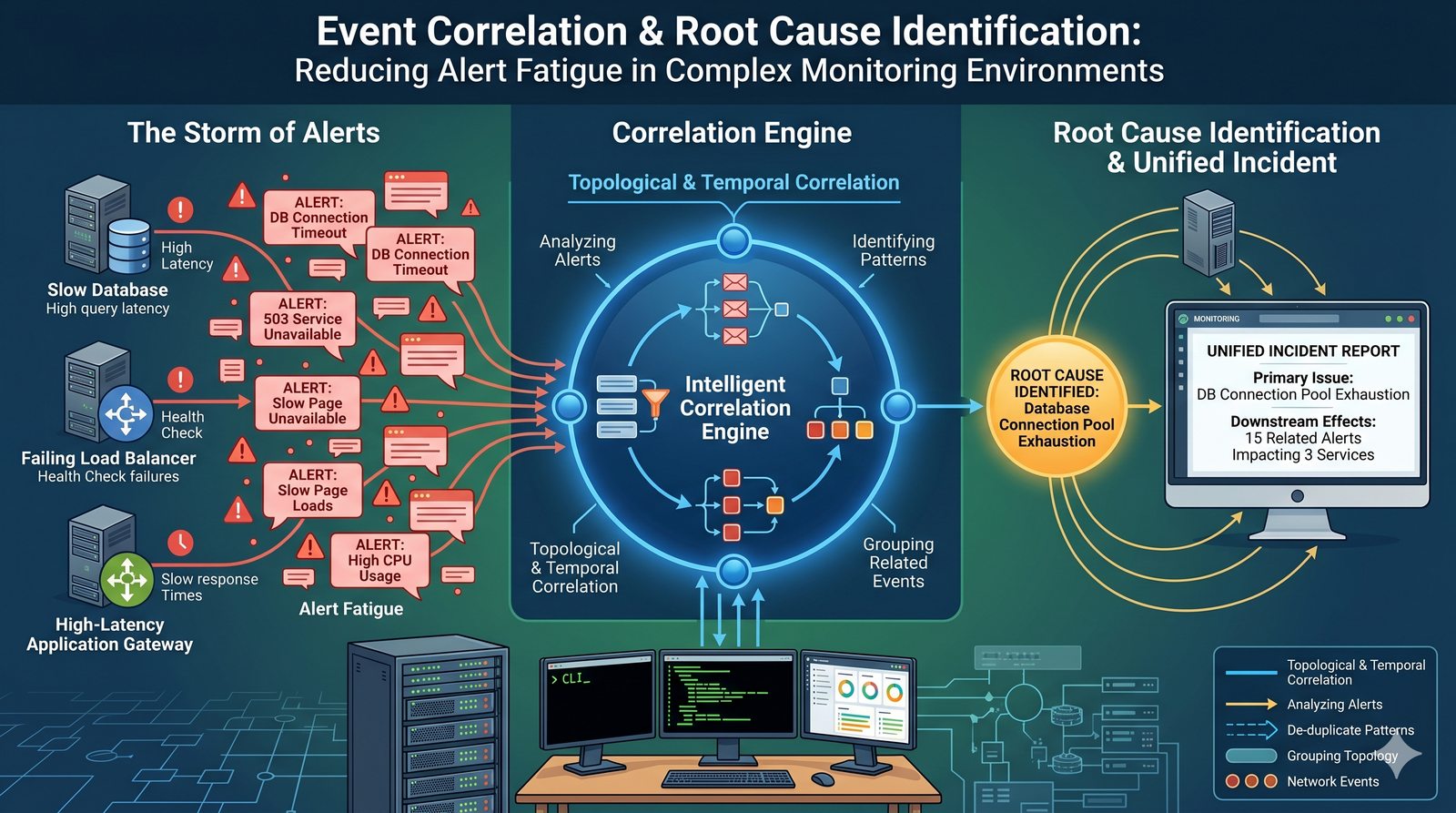
- Skuteczne monitorowanie pozwala na szybką identyfikację przyczyn awarii, optymalizację wydajności oraz planowanie przyszłej rozbudowy infrastruktury.
- Jest to fundamentalna praktyka, bez której zarządzanie złożonymi, nowoczesnymi środowiskami IT byłoby niemożliwe.